
Deep Learning Methods for Video to Text Converter Applications
with Phytorch Library
Komang Ayu Triana Indah
a
, Ida Bagus Putra Manuaba and I Komang Wiratama
Department of Electrical Engineering, Bali State Polytechnic, South Kuta, Badung, Bali, Indonesia
Keywords: Deep Learning, Video Converter, Phytorch Library.
Abstract: One of the core elements of the concept of computer vision consists of image classification, object detection
and segmentation. The multi-task deep learning method is implemented in the process of converting images
into text through a multi-layer process to express complex image understanding. In this study, the system will
convert the video into text and sentences. This synchronization is based on the Multitask Deep Learning
method that combines the Convolutional Neural Network (CNN) system in the image area, Recurrent Neural
Network (RNN) with LSTM (Long Short Term Memory) in the sentence area, CCN (Caption Content
Network) and RCN (Recurrent Convolutional Network) on the labeling process and the relationship between
objects as well as with a structured goal that aligns the two modalities through multimodal embedding.
PyTorch is an extension of the Torch Framework which was originally written in the Lua programming
language. The syntax that PyTorch uses is not much different in terms of functionality compared to other
frameworks. Testing the results of converting images into text based on Multi Task Deep Learning with the
RNN method using LSTM or BERT with scoring using f1-score, precision and recall. The results will be
plotted using AUC (Area Under The Curve) and ROC (Receivers Operating Characteristics)graphs.
1 INTRODUCTION
Computer vision is an automated process that
integrates a large number of processes for visual
perception, such as image acquisition, image
processing, recognition, and decision making.
Computer vision is expected to have a high level of
ability as a human visual. These capabilities include:
-Detection of objects, determine objects at the scene
and their boundaries
-Recognition, label the object.
-Description, assigns properties to the object.
-3D Inference, interprets a 3D scene from a 2D view.
-Interpreting motion, interpreting motion.
Computer vision combines cameras, edge or cloud-
based computing, software, and artificial intelligence
(AI) so the system can “see” and identify objects.
Intel has a comprehensive portfolio of AI deployment
technologies, including CPUs for general-purpose
processing, computer vision, and vision processing
units (VPUs) for acceleration. Computer vision
systems that are useful in a variety of environments
can quickly identify objects and people, analyze
a
https://orcid.org/0000-0003-3496-4484
audience demographics, inspect production outputs,
and many other things. (L. R. Jácome-Galarza, 2020).
2 DEEP LEARNING
Development of Deep Learning and Image
Processing methods through a system capable of
solving high-level image understanding problems to
change visual images in the context of sentences
The development of machine learning technology
with multi-task deep learning uses several methods
including the Convolutional Neural Network (CNN)
which functions to extract visual features in the form
of images, through the Recurrent Neural Network
(RNN), especially the LSTM type for captioning
various image areas of object elements by detecting
relationships between objects. object. (S. Bai et al,
2018).
42
Indah, K., Manuaba, I. and Wiratama, I.
Deep Learning Methods for Video to Text Converter Applications with Phytorch Library.
DOI: 10.5220/0011711300003575
In Proceedings of the 5th International Conference on Applied Science and Technology on Engineering Science (iCAST-ES 2022), pages 42-49
ISBN: 978-989-758-619-4; ISSN: 2975-8246
Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

2.1 Multi Task Learning
Multi Task Learning (MTL) is used in machine
learning applications, ranging from natural language
processing, speech recognition, computer vision, and
drug discovery. MTL comes in many forms: study
together, learn to learn, and learn by task are just a
few of the names used to refer to it. Generally, after
optimizing more than one function it effectively
performs multi-task learning (as opposed to task
learning. The most commonly used way to perform
multi-task learning in multi-task neural networks is
usually done by sharing hidden layer parameters
either hard or soft. hard parameters is the most
commonly used approach for MTL in neural
networks.(O. Sener and V. Koltun, 2018).
2.2 Deep Relationship Network
In MTL for computer vision, the approach often
shares convolution layers, while learning the task-
specific full connected layers by leveraging these
models with Deep Relationship Networks. In addition
to the shared structure and special layers, which can
be seen in Figure 1, they placed the previous matrix
on a fully connected layer, which allowed the model
to study the relationships between tasks, similar to
some Bayesian models.
Figure 1: Deep Relationship Network with convolutional
layers together and fully connected with prior matrices (X.
Liu, P. He, W. Chen, 2019).
2.3 Recurrent Neural Network (RNN)
Generative image modeling is a major problem in
unsupervised learning. Probabilistic density models
can be used for a variety of tasks that range from
image compression and reconstruction forms such as
image inpainting (eg, see Figure 1) and deblurring, to
the creation of new images. When the model is
conditioned on external information, possible
applications may also include creating images based
on text descriptions or simulating future frames in
planning tasks. One of the great advantages of
generative modeling is that there is practically a large
amount of image data available to study. However,
because the images are high-dimensional and highly
structured, estimating the natural image distribution
becomes very challenging. A glance at an image is
enough for a human to show and explain a large
amount of detail about a visual scene, however, this
ability becomes an elusive task for visual recognition
models. In this model the input process is a set of
pictures and descriptions of sentences that match the
following figure 2. (A. Karpathy and L. Fei-Fei,
2019).
Figure 2: Model Set of Drawings and Appropriate
Description (A. Karpathy and L. Fei-Fei, 2019).
One of the most important constraints in generative
modeling is building the original occlusion solution
model in Figure 2. Completion images are sampled
from Pixel RNN. This exchange has produced a wide
variety of generative models, each with its
advantages. Most of the work focuses on stochastic
latent variable models such as VAE which aim to
extract meaningful representations, but are often
accompanied by difficult inference steps that can
hinder their performance. One effective approach to
modeling the combined distribution of pixels in an
image is to display them as the product of a
conditional distribution. The resulting Pixeln RNN
consists of/up to twelve two-dimensional layer Long
Short Term Memory (LSTM) memories. The first
type is the Row LSTM layer where convolution is
applied along each row a similar technique is
described in (A. Karpathy and L. Fei-Fei, 2017).
Figure 3: Model Set of Drawings and Appropriate
Description.
Figure 3 can be explained as follows:
Left : To generate xi pixels one condition on all
previously created pixels to the left and above xi.
Deep Learning Methods for Video to Text Converter Applications with Phytorch Library
43

Center : To generate pixels in the multi-scale case, we
can also condition the sub-sampled image pixels (in
light blue).
Right : Connectivity diagram inside a masked
convolution. In the first layer, each RGB channel is
connected to the previous channel and to the context,
but is not connected to the channel itself. In the next
layer, the channel is also connected to the subtitle.
3 SYSTEM AND
ARCHITECTURAL MODEL
Author The architectural model of understanding
imagery in the context of language can be divided into
3 processes:
1. Detect Objects and text areas.
2. The overall system architecture framework which
is the relationship between object features, subject
features, caption features and context features.
3. Object and network proposal caption region As
represented in the following image simulation.
3.1 Objects and Text Areas
As shown in Figure 4 below, the initial process begins
with video extraction by determining object detection
and the detected text area on a scene graph. Then
determine the Caption Region, Relationship Region,
and Object Region. Furthermore, feature extraction
consisting of Caption Feature, Relationship Feature
and Object Feature and combining/processing
Relationship Feature, Caption Feature and
Relationshipo Context Feature with CCN (Caption
Context Network) method to produce Caption
Feature and Caption Context Feature in a Caption
Generation. The final part is to combine and process
the Subject Feature, Relationship Feature and Object
Feature with the RCN (Relationship Context
Network) method to produce Relationship Detection
and then extract the feature object to produce Object
Detection.(D. Shin and I. Kim,2018).
Figure 4: Object Detection Network and Text Region.
3.2 Dataset Exploration
Each The dataset used in this system uses the
Tensorflow platform, with the Inception3
Architecture and the encoders and decodercnn
methods. The Tensorflow dataset is a benchmark
dataset for object detection of image segmentation.
Detection of objects is done by regression (object
restriction) and classification.(S. Ren, K. He, R.
Girshick, 2017).
1. Setting up a Library / Data library (In research
using Pytorch)
2. Downloading Data
3. Loading Data
4. Distribution of Objects in the Tensorflow Dataset
5. Utilities function (object constraint area)
3.3 Preprocessing
At this stage there are four processes, namely:
1. Image Representation
Sentence description can create a reference to the
object and its attributes, so according to Girshick's
method to detect objects in each image with RCNN.
(L. R. Jácome-Galarza, 2020). CNNs were pre-
trained on ImageNet and tuned to 200 classes by
using the top detected locations in addition to the
entire image and calculating the representation based
on the Ib pixels within each bounding box as follows.
v = Wm[CNN✓c(Ib)] + bm, (1)
Where CNN(Ib) converts the pixels inside the
bounding box Ib into 4096 dimension activation of
the fully connected layer just before the classifier. (S.
Bai and S. An, 2018).
2. Sentence Representation
To establish the inter-modal relationship, then to
represent the words in the sentence in the same h-
dimensional embedding space as the image region.
The simplest approach might be to project each
shared word directly into this embedding. However,
this approach does not consider word order and
context information in sentences. To solve this
problem, Bidirectional Recurrent Neural Network
(BRNN) is used to calculate word representation.
BRNN takes a sequence of N words (encoded in a 1-
of-k representation) and transforms each into an h-
dimensional vector. However, the representation of
each word is enriched by the varying sized context
around that word. (S. Aditya, Y. Yang, C. Baral,
2017). Using index t = 1. . . N to indicate the position
iCAST-ES 2022 - International Conference on Applied Science and Technology on Engineering Science
44

of a word in a sentence, the exact form of BRNN is
the following equation:
xt = Ww t(2)
et = f(Wext + be) (3)
hf = f(et + Wf hf (4)
htb = f(et + Wbhtb+1 + bb) (5)
st = f(Wd(htf + htb) + bd) (6)
Here, t is an indicator column vector that has one in
the t-th word index in a vocabulary word. The W w
weight determines the word embedding matrix which
we initialize with the word2vec weights of dimension
300 and is retained because of the overfitting
problem. However, in practice we find little change
in final performance when this vector is trained, even
from random italization. (A. Van Den Oord, N.
Kalchbrenner, 2016).
3. Alignment Objective (Transforming Images and
Sentences Into a Collection of Vectors in the Same h-
Dimensional Space)
Since the control is at the picture and sentence level
as a whole, the picture-sentence score is formulated
as a function of the individual word-area scores.
Intuitively, a picture-sentence pair must have a high
match score if the words have convincing support in
the picture. Karpathy et al's model (X. Liu, P. He, W.
Chen, 2019) interprets the dot product vii T s t
between the i-th region and the t-th word as a measure
of similarity and uses it to determine the score
between k image and l sentence as: (A. Karpathy and
L. Fei-Fei, 2017).
4. This process is carried out by aligning the image
from the training set and the corresponding sentence.
We can interpret the quantity vi T s t as the non-
normalized log probability of the t-th word describing
the bounding box in the figure. However, in the end
to create a text snippet rather than a single word, by
aligning the extended and contiguous word order to a
single bounding box. Note that the nave solution of
assigning each word separately to the region with the
highest score is insufficient because it causes the
words to scatter inconsistently into different regions.
The data encoding process is carried out with the
ENDOCDERCNN (Encoding-Decoding CNN)
Algorithm as shown in Figure 5 below.
Figure 5: Data frame process flow with ENDOCDERCNN
algorithm.
3.4 Mapping Method with Pythorch
Library
The system is built on a web-based basis, which is
implemented using the Python Programming
Language and the PyTorch Library, as shown in
Figure 9 below. PyTorch is a development of the
Torch Framework which was originally written in the
Lua programming language. The syntax that PyTorch
uses is not too different from the functions in
compared to other frameworks, PyTorch has a neater
and simpler syntax. The following is an image of the
mapping process using PyTorch to classify video data
using CNN. PyTorch is a development of the Torch
Framework which was originally written in the Lua
programming language. The syntax that PyTorch uses
is not too different from the functions in compared to
other frameworks, PyTorch has a neater and simpler
syntax. The following is an image of the mapping
process using PyTorch to classify video data using
CNN. The data has gone through pre-processing and
feature extraction and is neatly stored in Ndarray
Numpy format with four dimensions measuring 1036
x 3 x 79 x 26. The ftrs.npy file has data features and
the lbls.npy file has the appropriate data labels. There
are 10 label classes with almost the same data for each
class. (X. Liu, P. He, 2019).
Figure 6: Basic Phytorch Workflow.
Modeling in PyTorch is not bound by any specific
rules. The model used is usually in the form of a class
with a forward(x) function to calculate the forward
Deep Learning Methods for Video to Text Converter Applications with Phytorch Library
45

propagation process. The torch.nn library is an
important part that stores Neural Network functions.
The model we use above is the CNN model with an
additional 1 fully connected layer. It can be seen that
we defined Conv2d, Maxpool2d and two linear
layers. The forward function is used for the forward
propagation process when data is inputted. It also
appears that we use the ReLU activation function for
each neuron.
4 PROCESS AND RESULT
ANALYSIS
Python Programming Language and done on Google
Collab platform. For an example of a 5 minute video,
the first step is to import the library needed to
understand the image, in this case using Tensor flow
version 2. Next, download the dataset that has been
stored on Google Drive. A short video dataset with a
duration of 5 minutes as shown in Figure 10 below.
Figure 7: CCTV video recording data with a duration of 5
minutes.
The next step is to extract the previously downloaded
dataset, then convert the mp4 video into an image
using opencv. In the process of compiling the dataset,
the dataset is created by describing each image in
written form, and the text generation process is still in
English according to the existing library.
In the process of making the dataset, namely
collecting images taken from CCTV recording
videos, then a description of each object in the image
is written and then stored in csv form to be loaded into
the tensorflow dataset. Load the csv into python for
inclusion in the tensorflow dataset then process the
Train Caption. In Figure 10, the following is an
example of an image dataset and its description.
Figure 8: Image dataset and description.
Preprocess using InceptionV3 convert the image
to the expected format of InceptionV3 by resizing the
image to 299 x 299 after normalizing the image so
that it is between the range -1 and 1. The next process
is to make CNN Encoder and CNN Train. For details
of the architecture above, we use a cnn encoder with
a pre-trained model using resnet-50 to encode the
image into an embedded image or feature vector.
After that, the embedded image is entered into the
RNN decoder. Texts also need to be pre-processed
and prepared for training. In this example, to generate
text, aim to build a model that predicts the next
sentence token from the previous token, So I convert
the text associated with any image into a tokenized
word list, before sending it to a PyTorch tensor which
we can use to train network. The next step is to divide
the data into train and validate and create a tensorflow
dataset using tf.data. These steps are performed by:
-Extract features from CNN InceptionV3 into
vector shapes (8, 8, 2048).
-Converts to shape (64, 2048).
-Enter via CNN Encoder.
-Features in the decoder with RNN (here GRU) to
generate images into writing.
After the process of sharing training data and
validation data, the next step is the model training
process. The two components of the model, namely
the encoder and decoder, train these components
together by passing the output of the encoder, which
is a vector of latent space, to the decoder, which, in
turn, is an iterative neural network. Example No. Of
Epochs = 1 Batch Size = 32 and so on.
Based on the results of the training model by
calculating losses from Epoch 1 to Epoch 100, we get
Real Captions and Predicted Captions as shown in
Figure 10 below.
iCAST-ES 2022 - International Conference on Applied Science and Technology on Engineering Science
46

Figure 9: Real Caption and Prediction Caption.
5 MODEL TRAINING AND
TESTING
Modeling in PyTorch is not bound by any specific
rules. The model used is usually in the form of a class
with a forward(x) function to calculate the forward
propagation process. The torch.nn library is an
important part that stores Neural Network functions.
The model we use above is the CNN model with an
additional 1 fully connected layer. It can be seen that
we defined Conv2d, Maxpool2d and two linear
layers. The forward function is used for the forward
propagation process when data is inputted.
5.1 Split Datase
We need to share the dataset that we have for training
and testing purposes. Data sharing can be done using
the help of the Scikit Learning library with a
proportion of 80% for training and 20% for testing.
The text must be aligned to the left with the
linespace set to single and in 9-point type. We need
to share the dataset that we have for training and
testing purposes. Data sharing can be done using the
help of the Scikit Learning library with a proportion
of 80% for training and 20% for testing.
5.2 Change to Tensor
The divided dataset is converted to a tensor and also
starts initializing the initial parameters of the Model,
such as optimization and evaluation algorithms. The
criterion variable stores the evaluation function used,
namely Cross Entropy. And the optimizer variable
stores the optimization function that will be used,
namely Adagrad. In the test using the epoch value of
1 to 100.
5.3 Testing Process
Testing is done inside torch.no_grad() to avoid
accidentally calling autograd. When the program is
run, an error value will be displayed during the
training process. The error value will decrease
indicating the training process is going well. After
training, the accuracy value will be displayed. For
data and epochs that have been defined, the author
gets an accuracy of about 40-50%. In testing the
training model, there is a comparison between the
epoch and loss of each feature. Epoch testing on
sample images is carried out from epochs 1 to 100,
with loss results as shown in Figures 12 to 14 below.
Figure 10: Epoch 1 to 36, Batch 0.
Figure 11: Epoch 37 to 72, Batch 0.
Deep Learning Methods for Video to Text Converter Applications with Phytorch Library
47
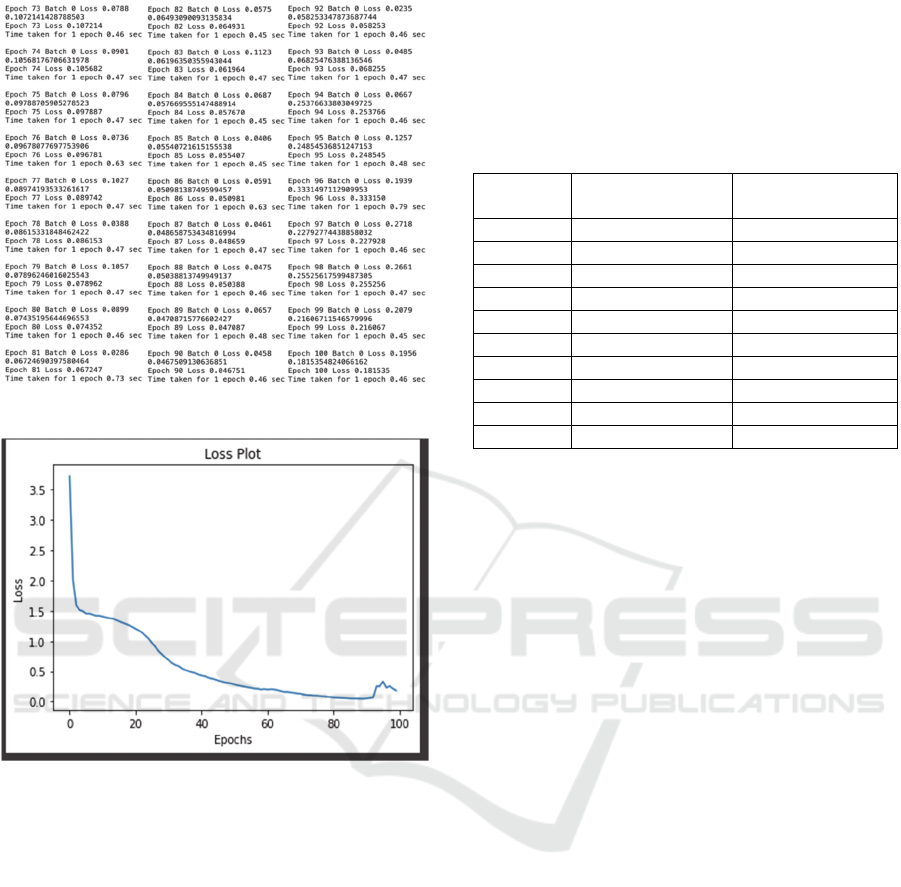
Figure 12: Epoch 73 to 100, Batch 0.
Figure 13: Comparison plot graph of label X for Epoch and
label Y for Loss.
Epoch is an iteration with reverse propagation, based
on previous research, the optimal number of epochs
is influenced by various factors such as learning rate,
optimizer, and amount of data. Based on the results of
the study, the epochs used were 10, 20, 30, 40, 50,
60,70, 80, 90, 100. In this study, epochs 1 to 100 were
used to obtain the largest total loss in epoch 1 of 3,581
and the smallest total loss. on epoch 91 is 0.0135.
Based on Figures 13, 14 and 15 through the following
epoch results, it can be seen that there is a correlation
between the accuracy and loss values in the training
data and the number of epochs or iterations. (A. Y. N.
Richard Socher, Andrej Karpathy, 2014) The larger
the epoch used, the higher the accuracy value on the
data train. Inversely proportional to the accuracy
value, the greater the epoch used, the lower the loss
value generated in the training data. Based on this, it
can be concluded that to reduce the loss value
obtained, it can be done by increasing the number of
epochs in the training process, so that the model will
produce a higher accuracy value. Based on the results
of the validation test for accuracy and loss for 100
epochs, the following optimization was obtained.
Table 1: Comparison Table Accuracy and Loss Validation.
Epoch
Accuracy
Validation
Loss
Validation
10 1.417357 1.3940
20 1.234550 1.1343
30 0.726811 0.6227
40 0.447890 0.5403
50 0.297522 0.3181
60 0.205348 0.1776
70 0.134186 0.1297
80 0.074352 0.0899
90 0.046751 0.0458
100 0.181535 0.1956
Accuracy is a matrix to evaluate the results of the
model classification. Accuracy is the division of the
model's predictions that are considered correct with
the predicted total. (D. Ariyoga, R. Rahmadi, and R.
A. Rajagede, 2021).
6 CONCLUSION
Implementation of multi-task deep learning in video
understanding to convert video into sentence text
consists of processing stages, namely object and text
area detection, determining Caption Region, Relation
Region, and Object Region which then extracts
features consisting of Caption Features, Relationship
Features and Object Features and combine/process
Relationship Features, Caption Features and Context
Relation Features with the CCN (Caption Context
Network) method and the RCN (Relationship Context
Network) method. The accuracy results obtained for
classifying accuracy validation against loss are
obtained from the results of research with 100 epochs,
the largest total loss is obtained in epoch 1 of 3.581
and the smallest total loss is at epoch 91, which is
0.0135.
REFERENCES
L. R. Jácome-Galarza, M. A. Realpe-Robalino, L. A.
Chamba-Eras, M. S. Viñán-Ludeña, and J. F. Sinche-
Freire, “Computer Vision for Image Understanding: A
Comprehensive Review,” Adv. Intell. syst. Comput.,
iCAST-ES 2022 - International Conference on Applied Science and Technology on Engineering Science
48

vol. 1066, no. September 2020, pp. 248–259, 2020, doi:
10.1007/978-3-030-32022-5_24.
S. Bai et al., “Natural language guided visual relationship
detection,” Math. problem. Eng., vol. 2020, no. 1, pp.
444–453, 2018, doi:10.1145/3219819.3220036.
M. Sundermeyer, R. Schlüter, and H. Ney, “LSTM neural
networks for language modeling,” 2012.
O. Sener and V. Koltun, “Multi-task learning as multi-
objective optimization,” 2018.
X. Liu, P. He, W. Chen, and J. Gao, “Multi-task deep neural
networks for natural language understanding,” arXiv,
pp. 4487–4496, 2019.
A. Van Den Oord, N. Kalchbrenner, and K. Kavukcuoglu,
“Pixel recurrent neural networks,” 2016.
A. Karpathy and L. Fei-Fei, “Deep Visual-Semantic
Alignments for Generating Image Descriptions,” IEEE
Trans. Pattern Anal. Mach. Intell., vol. 39, no. 4, pp.
664–676, 2017, doi:10.109/TPAMI.2016.2598339.
R. Staniute and D. ešok, “A systematic literature review on
image captioning,” Appl. Sci., vol. 9, no. 10, 2019,
doi:10.3390/app9102024.
D. Shin and I. Kim, “Deep Image Understanding Using
Multilayered Contexts,” Math. problem. Eng., vol.
2018, 2018, doi:10.1155/2018/5847460.
S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN:
Towards Real-Time Object Detection with Region
Proposal Networks,” IEEE Trans. Pattern Anal. Mach.
Intell., vol. 39, no. 6, pp. 1137–1149, 2017,
doi:10.109/TPAMI.2016.2577031.
L. R. Jácome-Galarza, M. A. Realpe-Robalino, L. A.
Chamba-Eras, M. S. Viñán-Ludeña, and J. F. Sinche-
Freire, “Computer Vision for Image Understanding: A
Comprehensive Review,” Adv. Intell. syst. Comput.,
vol. 1066, no. May, pp. 248–259, 2020, doi:
10.1007/978-3-030-32022-5_24.
S. Bai and S. An, “A survey on automatic image caption
generation,” Neurocomputing, vol. 311, pp. 291–304,
2018, doi:10.1016/j.neucom.2018.05.080.
S. Aditya, Y. Yang, C. Baral, Y. Aloimonos, and C.
Fermüller, “Image Understanding using vision and
reasoning through Scene Description Graph,” Comput.
vis. Image Underst., vol. 173, no. December, pp. 33–
45, 2018, doi:10.1016/j.cviu.2017.12.004.
A. Van Den Oord, N. Kalchbrenner, and K. Kavukcuoglu,
“Pixel recurrent neural networks,” 33rd Int. conf. Mach.
Learn. ICML 2016, vol. 4, pp. 2611–2620, 2016.
A. Y. N. Richard Socher, Andrej Karpathy, Quoc V. Le*,
Christopher D. Manning, “Grounded
Deep Learning Methods for Video to Text Converter Applications with Phytorch Library
49
