
Using Feature Analysis to Guide Risk Calculations of Cyber Incidents
Benjamin Aziz
a
and Alaa Mohasseb
b
School of Computing, University of Portsmouth, Portsmouth, U.K.
Keywords:
Cyber Security, Datasets, Risk Analysis, Text Mining, Machine Learning.
Abstract:
The prediction of incident features, for example through the use of text analysis and mining techniques, is
one method by which the risk underlying Cyber security incidents can be managed and contained. In this
paper, we define risk as the product of the probability of misjudging incident features and the impact such
misjudgment could have on incident responses. We apply our idea to a simple case study involving a dataset
of Cyber intrusion incidents in South Korean enterprises. We investigate a few problems. First, the prediction
of response actions to future incidents involving malware and second, the utilisation of the knowledge of the
response actions in guiding analysis to determine the type of malware or the name of the malicious code.
1 INTRODUCTION
The Internet has become the backbone for both pri-
vate and public sectors due to its importance in pro-
viding the main infrastructure of communication, data
transformation and services across every domain of
life. However, the frequent occurrences of Cyber in-
cidents, such as viruses, spyware, spam and other
malware programs coupled with their increasing com-
plexity over the years have caused financial losses for
worldwide organisations. In a recent report published
by the UK government and pwc (HM Government
and PWC, ), it was indicated that the cost of Cyber
security incidents is on average £1.46M-£3.14M to
large organisations and £75K-£311K to small organi-
sations, per year.
According to the same report, organisations are
increasingly spending more on information security
purposes in order to decrease the risk of Cyber inci-
dents. Risk, informally defined as anything that ad-
versely impacts an organisation’s business, cannot be
avoided completely, but can rather be managed (Ka-
plan and Garrick, 1981), and the prediction of in-
cident features, based on data mining and machine
learning techniques, can play a crucial role in man-
aging risk and reducing its impact.
For example, data mining and text analysis has
widely been used in literature to detect and classify
malware (e.g. (Suh-Lee et al., 2016; Kakavand et al.,
2015; Norouzi et al., 2016; Fan et al., 2015; Hel-
a
https://orcid.org/0000-0001-5089-2025
b
https://orcid.org/0000-0003-2671-2199
lal and Romdhane, 2016; Lu et al., 2010; Fan et al.,
2016; Rieck et al., 2011; Ding et al., 2013)) and mali-
cious code analysis (e.g. (Bahraminikoo et al., 2012;
Schultz et al., 2001; Shabtai et al., 2012)).
This paper introduces the idea that risk probabil-
ity can be derived from the accuracy measure of data
classification tools (Chinchor, 1992). Risk probability
is seen as the complement of accuracy, and therefore,
it can be combined with meaningful impact to derive
risk values in a classical manner. We show how this
idea can be used to evaluate the risk for a simple case
study of real data representing Cyber intrusion inci-
dents collected from a number of small and medium
Korean companies, where text classification tools are
trained using the current dataset to predict the values
of certain features.
The rest of the paper is structured as follows. In
Section 2, we give an overview of related work. In
Section 3, we give an overview of the Cyber intrusion
incidents dataset used in the case study. In Section 4,
we discuss the experimental study and the results ob-
tained. In Section 5, we introduce our idea that risk
can be defined based on the accuracy of the classifi-
cation algorithms for the class of problems being pre-
dicted. In Section 6, we apply our idea of calculating
risk based on prediction accuracy to the case study
dataset. Finally, in Section 7, we conclude the paper
and give directions for future work.
190
Aziz, B. and Mohasseb, A.
Using Feature Analysis to Guide Risk Calculations of Cyber Incidents.
DOI: 10.5220/0011561200003318
In Proceedings of the 18th International Conference on Web Information Systems and Technologies (WEBIST 2022), pages 190-195
ISBN: 978-989-758-613-2; ISSN: 2184-3252
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

2 RELATED WORK
The current internet technologies are plagued by Cy-
ber security challenges and threats. Hence, it became
a key element of every enterprise to protect business
and secure the underlay systems. As Cyber security
threats are growing to cause a venue of vulnerabil-
ity for each organisation, a considerable amount of
research has been conducted to consider the Cyber
security challenges from different perspectives. Nu-
merous amount of probabilistic and statistical meth-
ods for risk assessment have been proposed such as
(Sommestad et al., 2010; Shin et al., 2013; Cherdant-
seva et al., 2016; Ruan, 2017; Pat
´
e-Cornell et al.,
2018; Santini et al., 2019). However, recently, ma-
chine learning started to be applied widely in Cyber
security and risk applications; this is due to the effi-
cacy of machine learning techniques against the sta-
tistical risk models as demonstrated in (Kakushadze
and Yu, 2019).
Na
¨
ıve Bayes (NB), k-Nearest Neighbor and neu-
ral networks to filter spam. In addition, authors in (Lu
et al., 2019) showed that a Cyber security prediction
model with fewer prediction errors can be achieved by
applying the Grey Wolf Optimisation algorithm (Mir-
jalili et al., 2014) to optimise the SVM parameters.
Furthermore, authors in (Oprea et al., 2018) pro-
posed MADE (Malicious Activity Detection in Enter-
prises) to detect the malicious activities in the enter-
prise networks and score the risk of the external con-
nections based on the predicted probabilities. While
the combination of both supervised and unsupervised
learning has been investigated in (Sarkar et al., 2019)
in order to capture the Cyber security incidents such
as malware and malicious emails. The study showed
how the network structure of dark-web forums data
can be used to predict Cyber security incidents. More-
over, the way of highlighting risk factors of network
security incidents using data mining was presented in
(Gounder and Nahar, 2018). The authors showed that
rule mining could play a role in detecting anomaly
patterns and preventing their risk. In (Gai et al., 2016)
the authors’ proposed Decision Tree-based Risk Pre-
diction (DTRP) algorithm to reduce the risk of data
sharing among financial firms. The proposed ap-
proach aims to predict the hazardous conditions that
firms can be incurred due to information sharing. In
addition, in (Huang et al., 2017) a unified risk assess-
ment framework for SCADA networks was proposed.
The proposed framework adjusts the risk parameters
by learning from historical data and also incremen-
tally from online observations. While in (Feng et al.,
2017) a user-centric machine learning approach was
presented to classify the Cyber security incidents and
categorise them based on different risk levels. Au-
thors in (Cheong et al., 2019) presented a new ap-
proach to quantifying a company’s cyber security risk.
The newly proposed method is based on text analyt-
ics and the advanced autoencoder machine learning
technique. In (Figueira et al., 2020) a new predictive
model for risk analysis was proposed in which the risk
has been calculated based on the future threat proba-
bilities rather than historical frequencies. Recent sur-
veys in (Rawat et al., 2019; Torres et al., 2019) high-
light more detailed works related to applications of
machine learning techniques to Cyber security.
Although these studies provide important insights
into the area of risk assessment and cyber security,
such studies remain narrow in focus dealing only with
the correctly predicted incidents without taking into
account the risk impact of the wrongly predicted inci-
dents. Therefore, in this paper, we focus on defining
risk as the product of the probability of misjudging
incident features and the impact such misjudgment
could have on incident responses.
3 THE KAITS CYBER
INTRUSION DATASET
The dataset used in our case study represents Cyber
security intrusion incidents in five Small and Medium
Enterprises (SMEs) in South Korea, collected over a
period of ten months from 1 January 2017 until 31
October 2017 by the KAITS Industrial Technology
Security Hub (KAITS, ). As a public-private partner-
ship, the Hub aims to encourage the sharing of knowl-
edge, experience and expertise across Korean SMEs.
The data for each SME is stored in a separate file.
4643 entries (as a row) and the following six features
(i.e. metadata, labels) are included in the data :
• Date and Time of Occurrence: this is a value
representing the date and time of the incident’s oc-
currence.
• End Device: this is a value representing the name
of the end device affected in the incident.
• Malicious Code: this is a value representing the
name of the malicious code detected in the inci-
dent.
• Response: this is a value representing the response
action that was applied to the malicious code.
• Type of Malware: this is a value representing the
type of malware (malicious code) detected in the
incident.
• Detail: this is a free text value to describe any
other detail about the incident.
Using Feature Analysis to Guide Risk Calculations of Cyber Incidents
191

We focus in our case study next on two of the above
features, namely malicious code and response. In
addition to the above metadata, the dataset also con-
tains statistics on the technical responses to incidents
carried out by each of the five SMEs.
4 EXPERIMENTAL STUDY AND
RESULTS
The objective of the experimental study is to assess
the risk calculation of cyber incidents using feature
analysis. Four machine learning algorithms were used
for the classification process; J48 Decision tree (J48),
RandomForests (RF), Na
¨
ıve Bayes (NB) and Support
Vector Machine (SVM). The data distribution in the
KAITS dataset is shown in Table 1.
Table 1: The KAITS dataset data distribution.
Company Name Total Number of Incidents
Company 1(DF) 932
Company 2(MT) 633
Company 3(SE) 923
Company 4(EP) 448
Company 5(MS) 1707
The experiments were set up using 10-fold cross-
validation, and typical performance indicators were
used, such as accuracy, precision, recall, and F-
measure (Chinchor, 1992) and are calculated as
shown in the following formulæ:
Accuracy =
# of correct predictions (TP+TN)
# of predictions (TP+TN+FP+FN)
Precision =
T P
T P + FP
Recall =
T P
T P + FN
F = 2 ×
Precision × Recall
Precision + Recall
Where, True Positive (TP) is a positive instance clas-
sified correctly as positive, True Negative (TN) is
a negative instance classified correctly as negative,
False Positive (FP) is a negative instance classified
wrongly as positive and False Negative (FN) is pos-
itive instance classified wrongly as negative.
4.1 Results
In this section, we present the results of the accuracy
of the machine learning algorithms. These results are
summarised in Table 2
Table 2: Performance of the Classifiers for identifying the
types of response based on malicious code- Best results are
highlighted in bold.
Company Name J48 SVM RF NB
Company 1(DF) 83% 87% 82% 84%
Company 2(MT) 86% 87% 87% 85%
Company 3(SE) 89% 89% 89% 85%
Company 4(EP) 86% 91% 84% 87%
Company 5(MS) 93% 93% 93% 89%
The overall results for the identification of the dif-
ferent types of responses based on the given malicious
code indicated that SVM was the best classifier for
all five companies in terms of performance and accu-
racy. In addition, most classifiers could not identify
response categories such as “none”, “blocked” and
“deleted”.
5 A FEATURE
PREDICTION-BASED
FORMULA FOR RISK
We start by reiterating the classical formula for risk,
first suggested by IBM’s Robert Courtney, Jr. (Robert
H. Courtney, 1977):
risk = probability × impact
which states that risk is the product of probability and
impact. Based on this, we define M = {m
1
,...,m
k
}
as the set of impact levels that an organisation would
utilise. It is possible to assume further that M is or-
dered by some ordering relation ⊑
M
, which specifies
how the values m
1
,. . .,m
k
compare to one another, ei-
ther partially or totally. For example, M could refer to
some monetary values or some computational values
such as the increase/decrease in available processing
power or time.
We assume that a Cyber incident is described by
a set of features (labels), which represent the meta-
data for that incident. For example, in the dataset we
consider here, described in the next section, there are
six such features. We refer to such features by the
variables ℓ
1
,. . .,ℓ
k
. The impact of not predicting a
particular feature of an incident, ℓ, given that all the
other features are known, is defined using the follow-
ing function:
impact(ℓ) = m
ℓ
∈ M
WEBIST 2022 - 18th International Conference on Web Information Systems and Technologies
192

In other words, impact(ℓ) defines the impact on the
organisation in case the value of ℓ is predicted in-
correctly. For example, if ℓ represents the type of
response required, say from knowing the malicious
code in the incident, then m
ℓ
is the impact on the IT
infrastructure or the organisation of misjudging this
response.
The probability of making such misjudgment on a
feature ℓ is referred to by the value P
ℓ
defined as the
complement of accuracy:
P
ℓ
= 1 − Accuracy
ℓ
Where Accuracy
ℓ
is the accuracy value of the clas-
sification algorithm used in predicting ℓ. Accuracy,
itself, is defined by the following general formula
(Chinchor, 1992):
Accuracy = (number of correct predictions/
number of all predictions)
An example of P
ℓ
would be the probability of pre-
dicting wrongly the type of response given the mali-
cious code involved in an incident.
We can now define feature prediction-based risk,
resulting from the incorrect prediction of some inci-
dent feature ℓ, in terms of the following equation:
risk
ℓ
= P
ℓ
× m
ℓ
We demonstrate next the application of this definition
on a real case of a dataset representing Cyber intru-
sion incidents in Korean enterprises.
6 A RISK ANALYSIS OF THE
KAITS DATASET
We explain in the following sections, through the use
of a simple example from the KAITS dataset (KAITS,
), our approach to the calculation of risk within the
context of feature prediction in Cyber incidents.
6.1 Risk Probability
As we mentioned earlier, our main hypothesis rests
on the assumption that the incorrect prediction of an
incident’s feature represents a risk, e.g. due to all the
consequences (impact) that will result from such mis-
judgment. Therefore, the prediction accuracy mea-
sure can be used as a measure of risk probability.
We give here one example of measuring the accu-
racy of predicting the type of response to an incident
given the malicious code detected in that incident.
Based on the values of Table 2, which define the
Accuracy
response
variable, Table 3 presents the risk
probability values for each of these and hence defin-
ing the value of P
response
.
6.2 Impact
The KAITS dataset does not include any explicit in-
formation about the impact incurred as a result of the
incidents, other than statistics related to numbers and
types of responses. For our purposes, we shall as-
sume a simple model based on these to illustrate how
impact can be combined with the risk probabilities of
the previous section.
We assume that for each company, technical re-
sponse to an incident costs, on average, a single mon-
etary unit for that company, which we term c
i
(in other
words, company i’s single unit of currency). Table 4
represents one example of an impact factor resulting
from Cyber intrusion incidents, which is the average
cost per response to a ticket issued for servicing an
incident. The table contains the number of tickets
issued for each of the five companies based on the
statistics reported in the dataset.
6.3 Risk Calculation
Based on the probability of risk and the example im-
pact assumed, we can calculate a value for risk. Table
5 shows the risk values for each of the five companies
associated with the incorrect prediction of the type of
response from the malicious code based on the exam-
ple impact given. The table thus represents a calcula-
tion of risk
response
.
The rationale behind the data in this table is that
the incorrect prediction of the type of response to an
incident will lead to a misjudgment of the kind or
level of service required and therefore will lead to
no value in return for the cost in the worst-case sce-
nario. Hence the numbers in the table represent the
worst possible costs of incorrect predictions per al-
gorithm parameterised by each company’s currency.
These numbers can be interpreted as the limit of the
acceptable level when making a cybersecurity deci-
sion in the wrong way. However, the real value un-
derlying these data will be determined by the value of
the currencies themselves.
7 CONCLUSION
We demonstrated in this paper how risk can be de-
fined based on the probability of inaccurate predic-
tions of Cyber incident features, e.g. the kind of re-
sponses given the malicious code used in the incident,
and the impact those predictions can have in terms of
the number of responses served. Hence the quality of
prediction determines the risk probability. We used
a sample Cyber incidents dataset to demonstrate this
Using Feature Analysis to Guide Risk Calculations of Cyber Incidents
193
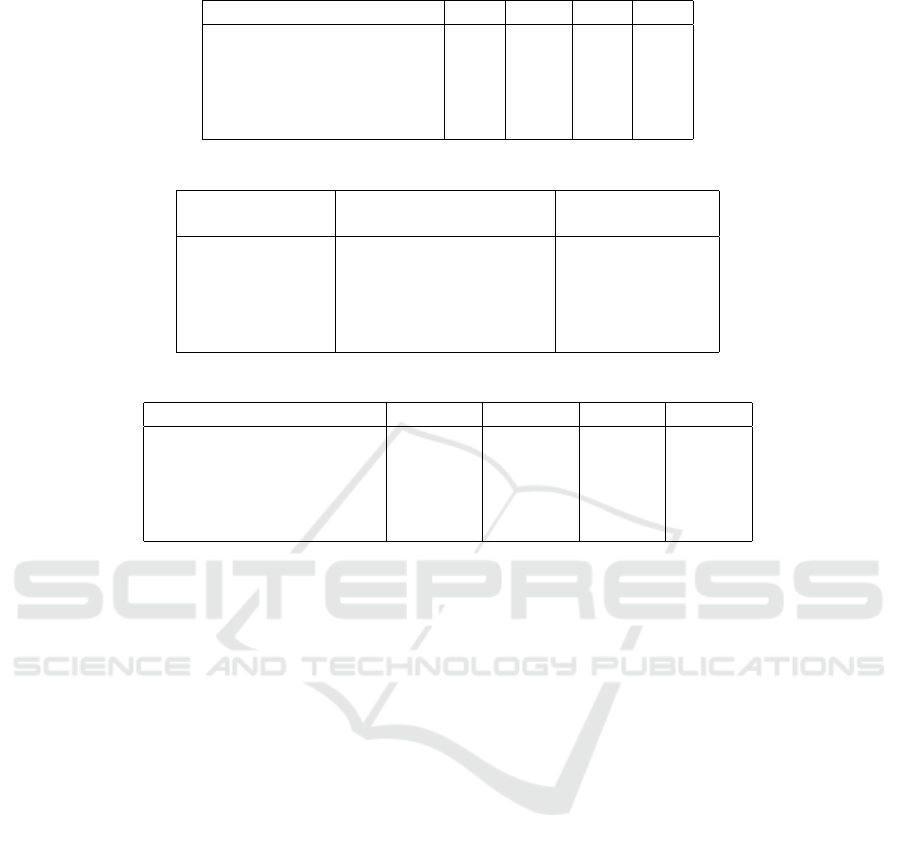
Table 3: Risk probability of the classifiers for identifying the types of response based on the malicious code.
Company Name/Algorithm J48 SVM RF NB
Company 1(DF) 17% 13% 18% 16%
Company 2(MT) 14% 13% 13% 15%
Company 3(SE) 11% 11% 11% 15%
Company 4(EP) 14% 9% 16% 13%
Company 5(MS) 7% 7% 7% 11%
Table 4: Example impact resulting from the incidents.
Company Name Number of response Assumed average
tickets served (KAITS, ) monetary cost
Company 1(DF) 3925 3925 × c
1
Company 2(MT) 13 13 × c
2
Company 3(SE) 27 27 × c
3
Company 4(EP) 88 88 × c
4
Company 5(MS) 19 19 × c
5
Table 5: Risk associated with the incorrect identification of the types of response based on malicious code.
Company Name/Algorithm J48 SVM RF NB
Company 1(DF) 667.25c
1
510.25c
1
706.5c
1
628c
1
Company 2(MT) 1.82c
2
1.69c
2
1.69c
2
1.95c
2
Company 3(SE) 2.97c
3
2.97c
3
2.97c
3
4.05c
3
Company 4(EP) 12.32c
4
7.92c
4
14.08c
4
11.44c
4
Company 5(MS) 1.33c
5
1.33c
5
1.33c
5
2.09c
5
concept by applying text analysis and classification
algorithms.
This approach is meaningful in that data predic-
tion is developed to further risk analysis. Considering
that risk analysis is gaining momentum in companies,
a proactive approach taken in this study will work as a
positive impetus for the development of the risk anal-
ysis domain. In the future, we plan to generalise this
idea to other domains that carry a notion of risk, e.g.
safety and reliability. This would then lead to more
comprehensive definitions of risk. We also plan to
extend the analysis to larger Cyber security datasets,
particularly those available on open platforms such as
VCDB (VERIZON, ), SecRepo (Mike Sconzo, ) and
CAIDA (Center for Applied Internet Data Analysis, ).
REFERENCES
Bahraminikoo, P., Yeganeh, M., and Babu, G. (2012). Uti-
lization data mining to detect spyware. IOSR Journal
of Computer Engineering (IOSRJCE), 4(3):01–04.
Center for Applied Internet Data Analysis. CAIDA Data.
Cheong, A., Cho, S., No, W. G., and Vasarhelyi, M. A.
(2019). If you cannot measure it, you cannot manage
it: Assessing the quality of cybersecurity risk disclo-
sure through textual imagification. SSRN.
Cherdantseva, Y., Burnap, P., Blyth, A., Eden, P., Jones,
K., Soulsby, H., and Stoddart, K. (2016). A review
of cyber security risk assessment methods for scada
systems. Computers & security, 56:1–27.
Chinchor, N. (1992). Muc-4 evaluation metrics. In Pro-
ceedings of the 4th Conference on Message Under-
standing, MUC4 ’92, pages 22–29, Stroudsburg, PA,
USA. Association for Computational Linguistics.
Ding, Y., Yuan, X., Tang, K., Xiao, X., and Zhang, Y.
(2013). A fast malware detection algorithm based on
objective-oriented association mining. computers &
security, 39:315–324.
Fan, C.-I., Hsiao, H.-W., Chou, C.-H., and Tseng, Y.-F.
(2015). Malware detection systems based on api log
data mining. In Computer Software and Applications
Conference (COMPSAC), 2015 IEEE 39th Annual,
volume 3, pages 255–260. IEEE.
Fan, Y., Ye, Y., and Chen, L. (2016). Malicious sequen-
tial pattern mining for automatic malware detection.
Expert Systems with Applications, 52:16–25.
Feng, C., Wu, S., and Liu, N. (2017). A user-centric ma-
chine learning framework for cyber security opera-
tions center. In 2017 IEEE International Conference
on Intelligence and Security Informatics (ISI), pages
173–175. IEEE.
Figueira, P. T., Bravo, C. L., and L
´
opez, J. L. R. (2020). Im-
proving information security risk analysis by includ-
ing threat-occurrence predictive models. Computers
& Security, 88:101609.
Gai, K., Qiu, M., and Elnagdy, S. A. (2016). Security-aware
information classifications using supervised learning
for cloud-based cyber risk management in financial
big data. In 2016 IEEE 2nd International Confer-
ence on Big Data Security on Cloud (BigDataSecu-
WEBIST 2022 - 18th International Conference on Web Information Systems and Technologies
194

rity), IEEE International Conference on High Perfor-
mance and Smart Computing (HPSC), and IEEE In-
ternational Conference on Intelligent Data and Secu-
rity (IDS), pages 197–202. IEEE.
Gounder, M. P. and Nahar, J. (2018). Practicality of
data mining for proficient network security manage-
ment. In 2018 5th Asia-Pacific World Congress on
Computer Science and Engineering (APWC on CSE),
pages 149–155. IEEE.
Hellal, A. and Romdhane, L. B. (2016). Minimal contrast
frequent pattern mining for malware detection. Com-
puters & Security, 62:19–32.
HM Government and PWC. 2015 Information Security
Breaches Survey. https://www.pwc.co.uk/assets/pdf/
2015-isbs-executive-summary-02.pdf.
Huang, K., Zhou, C., Tian, Y.-C., Tu, W., and Peng, Y.
(2017). Application of bayesian network to data-
driven cyber-security risk assessment in scada net-
works. In 2017 27th International Telecommunica-
tion Networks and Applications Conference (ITNAC),
pages 1–6. IEEE.
KAITS. Industrial Technology Security Hub. http://www.
kaits.or.kr/index.do.
Kakavand, M., Mustapha, N., Mustapha, A., and Abdullah,
M. T. (2015). A text mining-based anomaly detection
model in network security. Global Journal of Com-
puter Science and Technology.
Kakushadze, Z. and Yu, W. (2019). Machine learning risk
models. Journal of Risk & Control, 6(1):37–64.
Kaplan, S. and Garrick, B. J. (1981). On the quantitative
definition of risk. Risk analysis, 1(1):11–27.
Lu, H., Zhang, G., and Shen, Y. (2019). Cyber security
situation prediction model based on gwo-svm. In In-
ternational Conference on Innovative Mobile and In-
ternet Services in Ubiquitous Computing, pages 162–
171. Springer.
Lu, Y.-B., Din, S.-C., Zheng, C.-F., and Gao, B.-J. (2010).
Using multi-feature and classifier ensembles to im-
prove malware detection. Journal of CCIT, 39(2):57–
72.
Mike Sconzo. SecRepo.com - Samples of Security Related
Data.
Mirjalili, S., Mirjalili, S. M., and Lewis, A. (2014). Grey
wolf optimizer. Advances in Engineering Software,
69:46 – 61.
Norouzi, M., Souri, A., and Samad Zamini, M. (2016).
A data mining classification approach for behavioral
malware detection. Journal of Computer Networks
and Communications, 2016:1.
Oprea, A., Li, Z., Norris, R., and Bowers, K. (2018). Made:
Security analytics for enterprise threat detection. In
Proceedings of the 34th Annual Computer Security
Applications Conference, pages 124–136. ACM.
Pat
´
e-Cornell, M.-E., Kuypers, M., Smith, M., and Keller, P.
(2018). Cyber risk management for critical infrastruc-
ture: a risk analysis model and three case studies. Risk
Analysis, 38(2):226–241.
Rawat, D. B., Doku, R., and Garuba, M. (2019). Cyber-
security in big data era: From securing big data to
data-driven security. IEEE Transactions on Services
Computing.
Rieck, K., Trinius, P., Willems, C., and Holz, T. (2011). Au-
tomatic analysis of malware behavior using machine
learning. Journal of Computer Security, 19(4):639–
668.
Robert H. Courtney, J. (1977). Security Risk Assessment in
Electronic Data Processing Systems. In Proceedings
of the June 13-16, 1977, National Computer Confer-
ence, AFIPS ’77, pages 97–104, New York, NY, USA.
ACM.
Ruan, K. (2017). Introducing cybernomics: A unifying eco-
nomic framework for measuring cyber risk. Comput-
ers & Security, 65:77–89.
Santini, P., Gottardi, G., Baldi, M., and Chiaraluce, F.
(2019). A data-driven approach to cyber risk assess-
ment. Security and Communication Networks, 2019.
Sarkar, S., Almukaynizi, M., Shakarian, J., and Shakarian,
P. (2019). Mining user interaction patterns in the dark-
web to predict enterprise cyber incidents. Social Net-
work Analysis and Mining, 9(1):57.
Schultz, M. G., Eskin, E., Zadok, F., and Stolfo, S. J.
(2001). Data mining methods for detection of new
malicious executables. In Security and Privacy, 2001.
S&P 2001. Proceedings. 2001 IEEE Symposium on,
pages 38–49. IEEE.
Shabtai, A., Moskovitch, R., Feher, C., Dolev, S., and
Elovici, Y. (2012). Detecting unknown malicious code
by applying classification techniques on opcode pat-
terns. Security Informatics, 1(1):1.
Shin, J., Son, H., and Heo, G. (2013). Cyber security risk
analysis model composed with activity-quality and
architecture model. In International Conference on
Computer, Networks and Communication Engineer-
ing (ICCNCE 2013). Atlantis Press.
Sommestad, T., Ekstedt, M., and Johnson, P. (2010). A
probabilistic relational model for security risk analy-
sis. Computers & security, 29(6):659–679.
Suh-Lee, C., Jo, J.-Y., and Kim, Y. (2016). Text mining for
security threat detection discovering hidden informa-
tion in unstructured log messages. In Communications
and Network Security (CNS), 2016 IEEE Conference
on, pages 252–260. IEEE.
Torres, J. M., Comesa
˜
na, C. I., and Garc
´
ıa-Nieto, P. J.
(2019). Machine learning techniques applied to cyber-
security. International Journal of Machine Learning
and Cybernetics, pages 1–14.
VERIZON. VERIS Community Database.
Using Feature Analysis to Guide Risk Calculations of Cyber Incidents
195
