
Classifying the Reliability of the Microservices Architecture
Adrian Ramsingh
a
, Jeremy Singer
b
and Phil Trinder
c
School of Computing Science, University of Glasgow, Glasgow, U.K.
Keywords:
Microservices, Reliability, Web Architectures, Patterns, Bad Smells, Web Applications.
Abstract:
Microservices are popular for web applications as they offer better scalability and reliability than monolithic
architectures. Reliability is improved by loose coupling between individual microservices. However in pro-
duction systems some microservices are tightly coupled, or chained together. We classify the reliability of
microservices: if a minor microservice fails then the application continues to operate; if a critical microservice
fails, the entire application fails. Combining reliability (minor/critical) with the established classifications
of dependence (individual/chained) and state (stateful/stateless) defines a new three dimensional space: the
Microservices Dependency State Reliability (MDSR) classification. Using three web application case studies
(Hipster-Shop, Jupyter and WordPress) we identify microservice instances that exemplify the six points in
MDSR. We present a prototype static analyser that can identify all six classes in Flask web applications, and
apply it to seven applications. We explore case study examples that exhibit either a known reliability pattern
or a bad smell. We show that our prototype static analyser can identify three of six patterns/bad smells in
Flask web applications. Hence MDSR provides a structured classification of microservice software with the
potential to improve reliability. Finally, we evaluate the reliability implications of the different MDSR classes
by running the case study applications against a fault injector.
1 INTRODUCTION
Microservices are popular for web applications, since
they may offer better scalability and reliability than
monolithic components. Some microservices are
stateful, recording data, e.g. participants in a web
chat. Others are stateless, i.e. they simply accept re-
quests and purely process them.
Architectures with monolithic components are
prone to catastrophic failure, where user-visible
functionality is suddenly and permanently unavail-
able (Nikolaidis et al., 2004). It is common for the
failure of a single monolithic component to cause the
entire system to fail (a cascade failure).
In contrast microservice architectures potentially
provide improved reliability due to loose coupling of
services. If one microservice fails, others will remain
available. This may cause a reduction in throughput
but will most likely avoid catastrophic failure. In the
worst case scenario, the loose coupling of services en-
ables graceful failure (Soldani et al., 2018).
This is achieved based on the design principle that
a
https://orcid.org/0000-0003-3501-902X
b
https://orcid.org/0000-0001-9462-6802
c
https://orcid.org/0000-0003-0190-7010
microservices are implemented as standalone, inde-
pendent services (Jamshidi et al., 2018). However,
many large scale web applications include chains of
microservices where a set of services are closely de-
pendent, e.g. Netflix Titus (Ma et al., 2018).
Chained microservices are tightly coupled, e.g.
by high-frequency API-based interaction sequences.
Chained microservices make an application less reli-
able because if any of the services fail the entire chain
fails, and may induce catastrophic failure (Heorhiadi
et al., 2016). For example, in 2014 BBC experienced
a critical database overload that caused many criti-
cal microservices to fail one after another (Cooper,
2014). In 2015, Parse.ly experienced several cascad-
ing outages in its analytics data processing due to
a microservices message bus overload (Montalenti,
2015).
This paper makes the following research contribu-
tions.
(1) We combine a reliability (minor/critical) clas-
sification with the established classifications of de-
pendence (individual/chained) and state (stateful/s-
tateless). If a minor microservice fails the applica-
tion continues to function, although performance or
functionality may be reduced. If a critical microser-
Ramsingh, A., Singer, J. and Trinder, P.
Classifying the Reliability of the Microservices Architecture.
DOI: 10.5220/0011381700003318
In Proceedings of the 18th International Conference on Web Information Systems and Technologies (WEBIST 2022), pages 21-32
ISBN: 978-989-758-613-2; ISSN: 2184-3252
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
21

vice fails, the application fails catastrophically. Com-
bining reliability with state and dependence defines
a new three dimensional space: the Microservices
Dependency State Reliability (MDSR) classification.
As microservice chains are necessarily critical (Heo-
rhiadi et al., 2016), only six of the possible eight
points in the space are valid. We outline a proto-
type static analyser that can identify all six MDSR
classes. Applying the tool to 30 microservices from
seven small Flask web applications reveals interest-
ing statistics, e.g. the majority of services are chained
(70%), and critical (77%) (Section 4).
(2) Using three web applications we highlight
microservices that exemplify each point in MDSR.
The web applications are: (1) Hipster-Shop, a
Google demo application; (2) JPyL, a Jupyter Note-
book/Flask web stack; and (3) WordPress, a content
management system (Section 2).
(3) We show that each of the MDSR critical case
study microservices exhibits a known bad smell (Taibi
and Lenarduzzi, 2018). Likewise in each minor
MDSR class the case study microservices follow a de-
sign pattern (Taibi and Lenarduzzi, 2018). We show
that the prototype static analyser can identify three of
six patterns/bad smells in Flask web applications. The
analysis offers the opportunity to focus reliability en-
gineering efforts early in the development cycle. That
is, we propose static MDSR analysis as a complement
to dynamic Service Dependency Graph (SDG) analy-
sis (Ma et al., 2018) (Section 5).
(4) We explore reliability implications of differ-
ent MDSR microservice classes by running the three
web applications against a simple process level fault
injector. Specifically we show: (1) All applications
fail catastrophically if a critical microservice fails. (2)
Applications survive the failure of a minor microser-
vice, and successive failures of minor microservices.
(3) The failure of any chain of microservices in JPyL
& Hipster is catastrophic. (4) Individual microser-
vices do not necessarily have minor reliability impli-
cations (Section 6).
2 CASE STUDIES
We illustrate our new classification and analysis us-
ing three realistic microservice web applications.
Hipster-Shop is a popular Google microservices demo
web application; JPyL is a Jupyter/Flask microser-
vices web application; WordPress is a widely-used
Content Management System. The applications illus-
trate different aspects of real world microservice web
applications, e.g. Hipster-Shop implements microser-
vices in different languages, and both JPyL and Word-
Press combine monolithic and microservice compo-
nents.
2.1 Hipster-Shop
Key attractions of microservices are decentralization
and polyglotism. Here each service can be sepa-
rately developed with appropriate programming lan-
guages and tools, promoting agile development (Zim-
mermann, 2017). Many developers claim this is why
they prefer microservices (IBM, 2021).
The Hipster-Shop case study illustrates polyglot
development with services developed in Python, Go
and Java and communication via gRPC remote pro-
cedure calls. Hipster-Shop is an e-commerce applica-
tion with 10 microservices (Figure 1) used by Google
to demonstrate tools like Kubernetes Engine (Google,
2021). Users can perform activities like viewing prod-
ucts, adding items to cart and making purchases
1
.
Figure 1: Hipster-Shop Architecture.
2.2 JPyL: Jupyter/Python/Linux
Migrating from a monolithic architecture towards a
full microservices architecture is a gradual process.
It is common for developers to initially integrate one
or more microservice tiers that function alongside
monolithic components, in a hybrid approach known
as microlith (Soldani et al., 2018).
JPyL is a microlith web stack that combines the
popular Flask microservices web tier with monolithic
Jupyter components (Figure 2). The Flask tier has
seven microservices and is fairly conventional as out-
lined in Figure 2.
Some are supported by a data store, e.g. current
geolocation and IP address rely on the userdata mi-
croservice that interfaces with a MySQL database.
Data is displayed on the webpage via reverse proxy
and port configuration microservices on port 10125.
Crucially for reliability a backup URL port can be ini-
tiated via redirect if the original port service is inter-
rupted.
1
https://github.com/GoogleCloudPlatform/
microservices-demo
WEBIST 2022 - 18th International Conference on Web Information Systems and Technologies
22
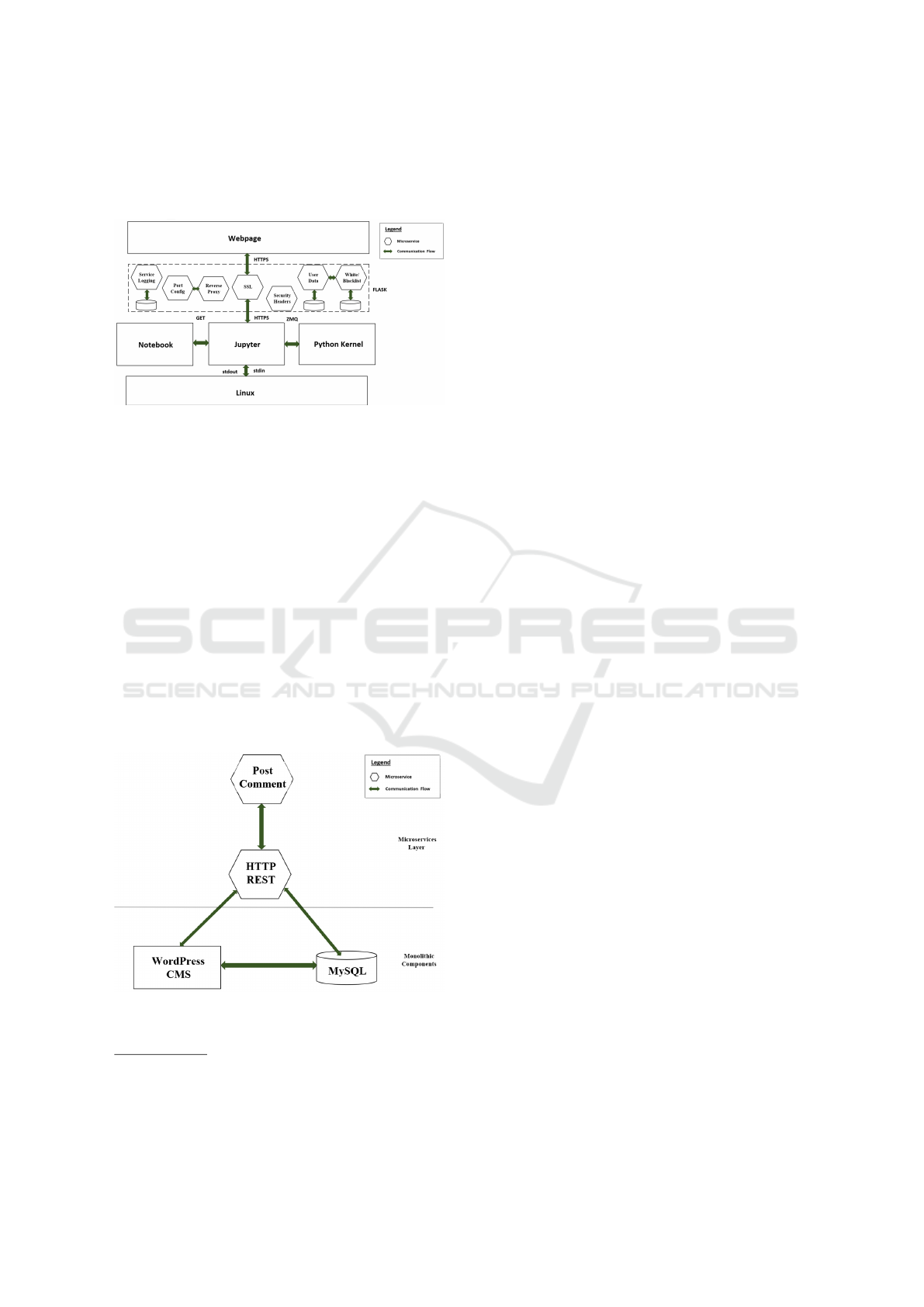
Each service is handled by a specific set of Flask
microservices
2
. For example, security headers are
processed by a Python Talisman microservice.
Figure 2: JPyL Application Architecture.
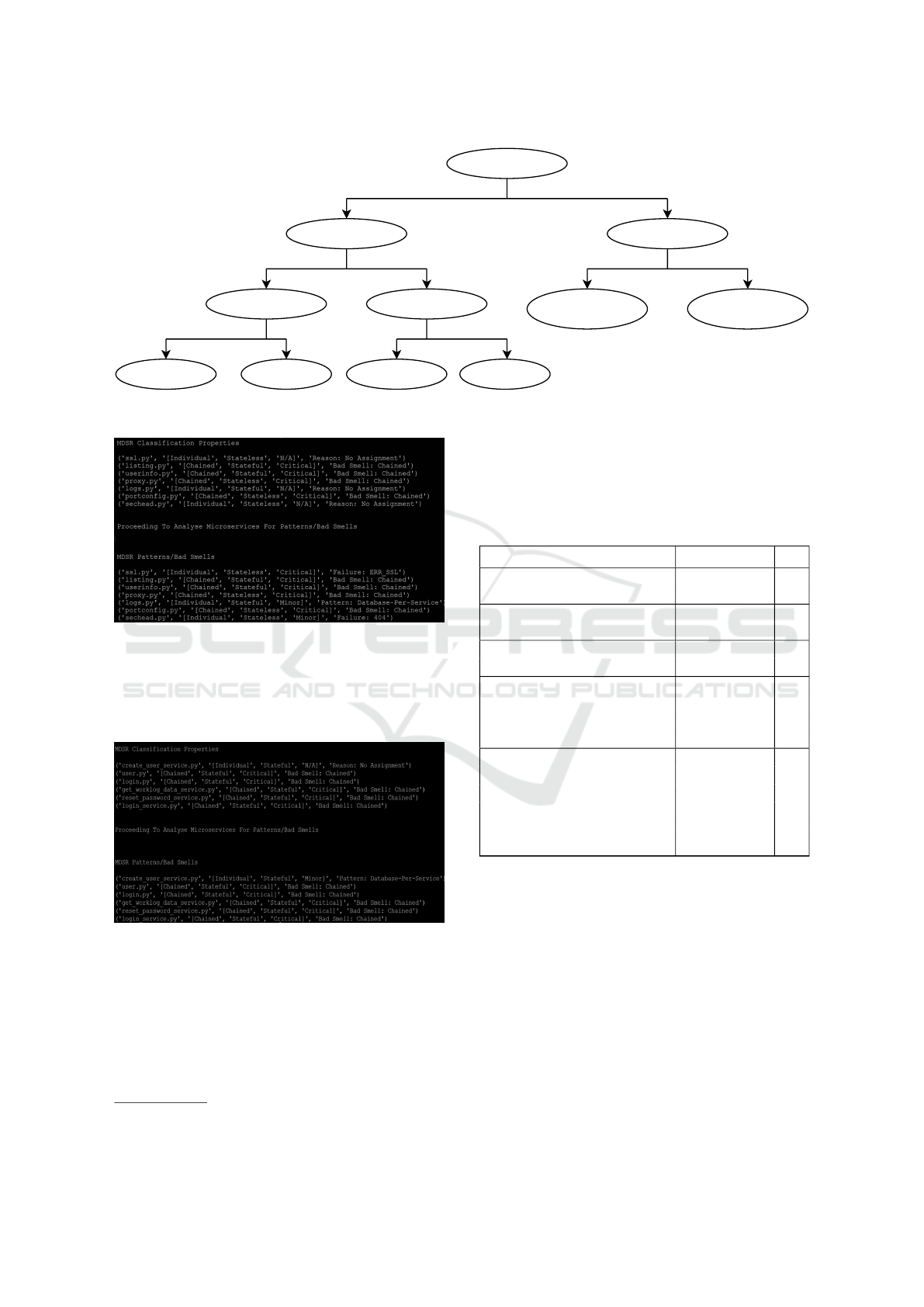
2.3 WordPress
WordPress is an open source Content Management
System (CMS) used for many websites (Patel et al.,
2011). As a standalone application WordPress has a
monolithic architecture with core CMS components
that communicate with a MySQL database. Mi-
croservices can be integrated with WordPress to pro-
vide plugins for additional features, e.g. to post com-
ments, allow subscription memberships or search in-
dexes (Cabot, 2018).
The application we study integrates microservice
endpoints that allow users to post comments
3
. The
service uses WordPress HTTP REST. It facilitates
communication between the microservice and the
monolithic components as shown in Figure 3.
Figure 3: WordPress Application Architecture.
2
https://bitbucket.org/latent12/microproject/src/master/
jpyl/
3
https://bitbucket.org/latent12/microproject/src/master/
wordpress/
3 RELATED WORK
3.1 Existing Classifications
Lewis and Fowler identify three microservices design
principles (Lewis and Fowler, 2015). (1) Independent
services — each service should run in its own process
and be deployed in its own container like one service
per Docker container. (2) Single functionality — one
business function per service. This is referred to as
the Single Responsibility Principle (SRP). (3) Com-
munication — often using a REST API or message
brokers.
Others have added other principles like reliabil-
ity (Heorhiadi et al., 2016), and advocate using de-
sign patterns like timeouts, bounded retries, circuit
breakers and bulkheads to mitigate failures (Heo-
rhiadi et al., 2016). However most assume that all
microservices are individual, but in reality there are
many types of microservices.
Microservices are commonly classified by their
properties and we outline some key properties below,
and summarise in Table 1.
3.1.1 Dependence
This property classifies a microservice by how tightly
coupled it is with other microservices (Heorhiadi
et al., 2016; Ma et al., 2018; Ghirotti et al., 2018).
Coupling is the degree of dependence between soft-
ware components like microservices, and there are
different types like content, data and control cou-
pling (Offutt et al., 1993). Software architects seek
loose coupling, and this is often achieved for mi-
croservices through data coupling.
Individual microservices are loosely coupled to
other microservices and communication with other
microservices is typically via infrequent remote API
calls. Many individual microservices express com-
putations at a high level of abstraction, and provide
their own built-in runtimes, functionalities and data
stores (Salah et al., 2016). Examples for JPyL in-
clude the SSL and Service Logging services (Fig-
ure 2) while Hipster-Shop includes Frontend and Ad-
service microservices (Figure 1).
In contrast chained microservices are tightly cou-
pled with one or more other microservices. A chained
microservice is reliant on some form of constant com-
munication or a chain of calls with another service to
function (Heorhiadi et al., 2016; Rossi, 2018). This is
often due to control coupling where the chained ser-
vices must request and marshal data between them-
selves (Offutt et al., 1993).
In JPyL, the Reverse Proxy service is dependent
on the Port Configuration service to display data on
Classifying the Reliability of the Microservices Architecture
23

the webpage through port 10125. Specifically the Re-
verse Proxy must access the Port Configuration to de-
termine which backup URL port to use.
3.1.2 State
This property classifies a microservice by whether
it preserves state between service requests. State-
ful microservices require data storage, for example to
record transactions or current actors (Wu, 2017). In
JPyL the Service Logging microservice is stateful: it
logs the status of all microservices in the application
in a MySQL database (Figure 2). Other microservices
are Stateless, i.e. they maintain no session state. Such
services typically accept requests, process them in a
pure fashion, and respond accordingly. In JPyL the
SSL microservice is stateless: it processes https re-
quests but maintains no session data.
3.1.3 Combining & Inheriting Properties
Microservices may have any combination of prop-
erties, e.g. individual/stateful or chained/stateless.
Properties may be inherited from other chained mi-
croservices, e.g. if any microservice is stateful then
the entire chain is stateful. In Hipster-Shop although
both Checkout and Payment microservices are state-
less, their chain with Cart Services is stateful as Cart
Services is stateful (Table 6).
3.2 Microservices Reliability
There are substantial studies of the reliability of mi-
croservice software in both the academic (Heorhiadi
et al., 2016; Zhou et al., 2018; Toffetti et al., 2015)
and grey literature (Wolff, 2018; Gupta and Pal-
vankar, 2020). These reveal that reliability in the mi-
croservices architecture is not always attainable be-
cause the reliability design principle is not always
followed. This principle states that a microservice
should be fault tolerant so that in the case of failure,
its impact on other services will be negligible (Power
and Kotonya, 2018).
However, developers do not always implement the
necessary design patterns or follow the Fowler and
Lewis design principles (Section 3.1) to prevent mi-
croservices failure. Even if they do, they remain un-
aware whether their microservice can actually toler-
ate failures until it actually occurs (Heorhiadi et al.,
2016). Thus, the impact of a microservices failure
on an application is not always readily known before-
hand.
Table 1: Microservices Classification Criteria.
Classification Properties Description
Dependence Individual Loosely Coupled.
Limited communi-
cation with other
microservices.
Chained Tightly Coupled. Con-
stant communication
with other microser-
vices required.
State Stateless No data store. Does not
maintain state.
Stateful Utilises data store.
Maintains state.
Reliability Critical Supports core function-
ality. Service fail-
ure means that the ap-
plication becomes sud-
denly and permanently
unavailable.
Minor Supports non-essential
functionality. Applica-
tion continues to func-
tion despite service fail-
ure. Degradation in
performance or grace-
ful failure over a period
of time.
3.3 Patterns and Bad Smells
Some design patterns capture reusable solutions to
common microservice design challenges (Taibi and
Lenarduzzi, 2018). For example the Database-Per-
Service pattern prevents tight coupling by ensuring
that multiple microservices are not dependent on a
single data store. Instead, each service accesses its
own private store (Taibi et al., 2018), eliminating the
single data store as a single point of failure (SPOF).
Some of the microservices patterns utilised in our
evaluation are summarised in Table 2
Table 2: Microservices Patterns Description.
Pattern Description
Database-Per-Design Microservice ac-
cesses its own
private data store.
API-Gateway Microservice com-
munication occurs
through an API.
Single Responsibility Principle Microservice per-
forms a single
functionality.
While design patterns like Database-Per-Service
help, they are not universal solutions. For ex-
ample a single atomic operation often spans mul-
WEBIST 2022 - 18th International Conference on Web Information Systems and Technologies
24

tiple microservices, and here additional techniques
are required to ensure consistency across the data
stores (Rudrabhatla, 2018).
Likewise microservice bad smells identify com-
mon designs that may cause issues (Taibi and Lenar-
duzzi, 2018). Indeed (Heorhiadi et al., 2016) and
the Fowler and Lewis design principles consider all
chained microservices as bad smells and prone to
reliability issues. Some of the microservices bad
smells found in our evaluation are summarised in Ta-
ble 3. Microservices Greedy, Shared Persistency and
Cyclic Dependency are listed in (Taibi and Lenar-
duzzi, 2018), Chained Services is mentioned by (Heo-
rhiadi et al., 2016) and SRP Violation is a well-known
microservice bad smell.
Table 3: Microservices Bad Smells.
Bad Smell Description
SRP Viola-
tion
Microservice performs more than one
functionality.
Reason: Microservice becomes more
critical. Increases the probability of
catastrophic failure in the application.
Microservices
Greedy
Microservices created for every feature
in an application.
Reason: More microservices could lead
to more points of failure.
Shared Per-
sistency
Different microservices access the same
data storage.
Reason: Single Point of Failure
(SPOF).
Chained
Services
Microservices that depend on commu-
nication or data marshalling from other
microservices.
Reason: Tight Coupling.
Cyclic
Dependency
Where there are cycles in the call graph,
e.g. A to B, B to C and C to A. A subset
of Chained Services.
Reason: Too much dependency.
3.4 Failures in Microservices
Even if the microservices design principles are fol-
lowed, failure is to be expected. There are two major
reasons for these failures (Zhou et al., 2018). Func-
tional Failures due to poor implementation e.g. a
SQL column missing error is returned upon some data
request. Environmental Failures due to misconfigu-
ration of the infrastructure necessary to run the mi-
croservices effciently e.g. microservices processing
of requests is slow due to insufficient memory being
made available in the Docker environment.
Partial failures are typically temporary and re-
covery is automatic, e.g. a microservice without a
load balancer may be briefly overloaded (Zhou et al.,
2018). Downtime can often be minimised if replace-
ment microservice instance(s) are activated automat-
ically (Toffetti et al., 2015). Partial failure is consid-
ered acceptable in the design of microservices appli-
cations.
In contrast, catastrophic failure is considered un-
acceptable as it can lead to long downtimes with-
out manual intervention (Nikolaidis et al., 2004). In
microservices, catastrophic failures are often termed
Interaction Failures (Zhou et al., 2018). Common
causes are incorrect coordination or communication
failure between microservices, e.g. asynchronous
message delivery lacking sequence control or a mi-
croservice receiving an unexpected output in its call
chain. The errors may be replicated in several mi-
croservice instances (Zhou et al., 2018), so even
switching workload from a failed instance doesn’t
help as the new instance fails in the same way.
Chained microservices are especially prone to in-
teraction faults because they violate the Single Re-
sponsibility Principle (SRP) and lead to brittle archi-
tectures (Heorhiadi et al., 2016). Moreover adding
more microservices to the chain increases coupling
and the likelihood of catastrophic failure (Rossi,
2018). If one service in the chain fails, there will be
a cascade of failures of all services in the chain (Heo-
rhiadi et al., 2016).
A limitation of (Heorhiadi et al., 2016) and the
Lewis and Fowler design principles is that they con-
sider only dependence. We extend their work by si-
multaneously classifying dependence, state and relia-
bility.
3.5 Detecting Failures
Failures in microservice-based applications may arise
from the microservices, or from the infrastructure ser-
vices like libraries, containers like Docker, develop-
ment frameworks like Flask, etc. Here we focus on
failures in the microservices, and detecting these fail-
ures is often challenging.
A common approach is to configure a collection of
microservices indicators (KPIs) to continuously mon-
itor for the causes of failure. The KPIs are typically
time series, e.g. the response time of a microservice
to requests from other services. The microservice is
identified as failing if it fails to meet the expected
KPI (Meng et al., 2020).
Service Dependency Graphs (SDGs) can be used
to dynamically detect microservices bad smells by
mapping their node relationships (Ma et al., 2018).
However, diagnosing the severity and reason for a
failure in a large system is challenging. The diagno-
sis usually requires domain and site-reliability knowl-
edge as well as automated observability support (Has-
Classifying the Reliability of the Microservices Architecture
25

selbring and Steinacker, 2017). Not all companies
have such resources.
4 CLASSIFYING RELIABILITY
4.1 Critical vs Minor Reliability
To analyse the reliability of a microservice architec-
ture we consider a microservice reliability property
alongside the established properties of state and de-
pendency.
Critical microservices provide core functionality
to the application, and if such a service fails, the en-
tire application fails catastrophically even if there are
several instances of the microservice. In JPyL, the
chained PortConfig to ReverseProxy services are crit-
ical because if the PortConfig service fails, the Re-
verseProxy service will not be able to determine the
port to display data or access the URL backup port.
As with other properties criticality is inherited within
chains, so if any microservice is critical then the entire
chain is critical.
Minor microservices provide non-essential func-
tionality. The application continues to operate if they
fail, although performance and/or functionality may
be reduced. In Hipster-Shop, the Adservice microser-
vice is minor because if it fails, the server returns a
404 status code indicating that the service is temporar-
ily unavailable. The rest of the application continues
to function normally.
It would also be possible to consider partial fail-
ures that eventually affect the operation of the sys-
tem (Cristian, 1991). However, given the challenges
of distinguishing between partial failures with differ-
ent severities we adopt a binary minor/critical clas-
sification. As partial failures are considered as gray
failures, severe partial failures are classified as criti-
cal, and low severity failures are classified as minor.
4.2 MDSR Classification
Combining reliability with the state and dependency
classifications defines a three-dimensional space:
our new Microservices Dependency State Reliability
(MDSR) Classification Tree as shown in Figure 4. It
can also be represented in tabular form as in Tables 5
and 6.
In MDSR chained microservices are necessarily
critical as argued in (Heorhiadi et al., 2016), and con-
firmed in our evaluation (Section 6) even for chains
that attempt to recover reliability using microservice
patterns. As examples we implement a Database-Per-
Service pattern for the chained/stateful UserData &
White/Black Listing service and an API Gateway pat-
tern for the chained/stateless/ Product Catalog & Rec-
ommended service. In both cases the application fails
catastrophically despite reporting only a ”404 Service
Not Found” error.
The fourth rows of Tables 5 and 6 show exam-
ple microservices from the case study applications for
each of the six MDSR classes. For example the indi-
vidual/stateful/minor exemplar is JPyL’s Service Log-
ging microservice. The fifth rows of the tables show
the error reported if the service fails.
4.3 Semi-automatic Classification
Static analysis of a set of microservices can automat-
ically propose MDSR classifications for many mi-
croservices in an application. We demonstrate the
principle with a prototype analyser that classifies all
Python/Flask microservices in a source project
4
. The
analyser tokenises the Python/Flask code, and identi-
fies properties using keyword matches. As examples,
the presence of keywords like ”SQL” or ”JSON” clas-
sifies a service as stateful; the presence of ”request”,
”requests”, ”requests.get”, ”get” Flask keywords, or
use of the ”POST” or ”GET” methods classifies a ser-
vice as chained as they indicate a service is pushing
data or requesting information from other microser-
vices. Reliability is determined by the type of pattern
or bad smell detected as discussed in Sections 5.2 &
5.3. Figure 5 shows a screenshot of the tool’s output
for JPyL.
The prototype analyser identifies all six MDSR
classes. The analyser may, however, propose an in-
correct classification, for example a stateless service
may be incorrectly classified as stateful if a keyword
like ”SQL” appears in a comment. Similarly, a state-
ful microservice could be classified as stateless if it
uses a persistent store that is not included in the cur-
rent set of keywords.
Despite these limitations the analyser is effective
in classifying microservices. For example Tables 5
and 6 show how it correctly classifies all of the JPyL
microservices. We have also applied the analyser to a
total of 30 microservices in a further six small Flask
web application projects
5
. Manual inspection of 3 of
the projects validates the properties identified by the
4
https://bitbucket.org/latent12/microproject/src/master/
analyser/
5
GitHub Links: https://github.com/IBM/worklog/tree/
master/app, https://github.com/IBM/Flask-microservice,
https://github.com/bakrianoo/Flask-elastic-microservice,
https://github.com/airavata/Blitzkrieg, https://github.
com/michaellitherland/Flask-microservice-demo,
https://github.com/umermansoor/microservices
WEBIST 2022 - 18th International Conference on Web Information Systems and Technologies
26
Microservice
Individual Chained
Stateful Stateless Stateful/
Critical
Stateless/
Critical
Critical MinorMinor Critical
Figure 4: MDSR Classification Tree.
Figure 5: MDSR Analyser JPyL Output.
analyser. As a further example the analyser output for
the IBM worklog application is shown in Figure 6,
and corresponds to the use case diagram provided by
IBM
6
.
Figure 6: MDSR Analyser IBM Worklogs Output.
Table 4 shows the number and percentage of each
MDSR class of microservice that the analyser detects
in the seven web applications, and key observations
are as follows. The majority of services are chained
(70%), and most are stateful (73%). 50% of services
are from a single MDSR classification, i.e. chained/s-
tateful/critical. Perhaps most startling is that 77% of
6
https://github.com/IBM/worklog/blob/master/designs/
services are critical. We speculate that this reflects
that the designers of these small web applications
have not designed them to be reliable.
Table 4: MDSR Classifications of 7 small Flask Applica-
tions containing 30 Microservices.
Classification No. Services %
Individual 9 30
Chained 21 70
Stateful 22 73
Stateless 8 27
Critical 23 77
Minor 7 23
Individual/Stateful 7 23
Individual/Stateless 2 7
Chained/Stateful 15 50
Chained/Stateless 6 20
Individual/Stateful/Critical 2 7
Individual/Stateless/Critical 1 3
Chained/Stateful/Critical 15 50
Chained/Stateless/Critical 6 20
Individual/Stateful/Minor 5 17
Individual/Stateless/Minor 1 3
5 IDENTIFYING RELIABILITY
MDSR analysis provides information about the ex-
pected reliability of microservices and chains of mi-
croservices in an architecture. In general reliability
engineering should focus on the 77% of critical mi-
croservices identified by the analysis in Table 4. More
specifically the analysis can help identify design pat-
terns and bad smells in the architecture. To illustrate,
the sixth row of the Patterns and Bad Smell tables
(Tables 5 & 6) identify the microservice pattern or
bad smell associated with each point in the classifica-
Classifying the Reliability of the Microservices Architecture
27

tion space. Of the patterns and bad smells enumerated
in (Taibi and Lenarduzzi, 2018) (and summarised in
Tables 2 & 3) the case studies exhibit four out of eight
patterns and three out of eleven bad smells.
Static analysis enables the early identification of
patterns and bad smells, allowing developers to an-
ticipate the types of failures, and their likely impact.
Potentially this information allows developers to trou-
bleshoot problems faster and prevent long application
downtimes.
5.1 MDSR Patterns & Implications
The sixth row of the MDSR Patterns table (Table 5)
identifies the microservice pattern exhibited by the
case study example microservice, or microservice
chain. In our case study applications, individual/state-
ful microservices and individual/stateless microser-
vices have only minor reliability implications if they
implement a pattern as shown in Table 5. For exam-
ple JPyL Service Logging is individual/stateful/minor
and implements the Database-Per-Service pattern.
5.2 MDSR Bad Smells & Implications
The sixth row of the MDSR Bad Smells table (Ta-
ble 6) identifies the microservice bad smell exhibited
by the case study example microservice, or microser-
vice chain. Considering the Patterns and Bad Smells
tables together (Tables 5 and 6) we see that the ex-
ample case study microservices at each point in the
MDSR classification exhibit either a design pattern
or a bad smell.This is expected as microservice best
practice applies patterns, while bad smells indicates
places where design principles have not, or cannot be
applied (Heorhiadi et al., 2016).
Bad smells identified by MDSR can be considered
for refactoring to improve reliability. That is, most
critical microservices are associated with known bad
smells as shown in Table 6. For example the indi-
vidual/stateless/critical SSL microservice in JPyL is
an instance of Microservices Greedy, where there is
a proliferation of microservices. Of course SSL need
not be implemented as a microservice.
A key element of MDSR is that chained microser-
vices remain critical, even if they implement good de-
sign patterns. For example, the chained/stateful/crit-
ical UserData & White/Black Listing microservices
implement the Database-Per-Service pattern but still
fail catastrophically as we show in Section 6.
5.3 Semi-automatic Pattern/Bad Smell
Detection
The prototype MDSR analyser can detect the
Database-Per-Service pattern, and both chained mi-
croservices and Shared Persistency bad smells.
Shared Persistency is detected by determining
whether any microservices share a data store. Cur-
rently the user must provide the analyser with the
names of the data stores used in the application, e.g.
jpyl micro in JPyL. An enhanced analyser could parse
the Flask code and extract the data store names from
connection statements. The analyser counts the num-
ber of times each data store name appears in the mi-
croservices in the given directory. If the count is
greater than 1, the microservices have a shared per-
sistency bad smell. Microservices with a unique per-
sistent store name implement a Database-Per-Service
pattern.
There are some bad smells that the analyser isn’t
able to detect. Some of these, like Cyclic Dependency
could be detected dynamically, perhaps using SDGs
to examine the connection between services and the
rate of communication (Ma et al., 2018; Omer and
Schill, 2011). Other bad smells likely require human
analysis, like Microservices Greedy and SRP viola-
tion.
The analyser also inspects Flask error handling
codes to classify the reliability of a microservice. For
example if a service returns a 404 error indicating that
the service is not found or temporarily unavailable the
failure is considered minor. In contrast a code like 415
indicates that there is a SSL Protocol Violation, and
the service is critical because even if other services
are available, the application cannot accept https re-
quests, and has failed catastrophically.
Table 7 shows the number and percentage of bad
smells and patterns detected by the analyser in the
seven web applications. Key observations are as fol-
lows. (1) 17% of services implement Database-Per-
Service. (2) As 70% of the services are chained (Ta-
ble 4), they are the most common bad smells. This
accords with, and provides evidence for, the claim in
(Heorhiadi et al., 2016) that developers do not always
implement reliability patterns.
6 EVALUATING RELIABILITY
We execute the Hipster, JPyL & WordPress web ap-
plications against a simple fault injector to investi-
gate the reliability implications of different MDSR
classes. All applications are executed on a typical
server, i.e. a 16 core Intel server with 2TB of RAM
WEBIST 2022 - 18th International Conference on Web Information Systems and Technologies
28
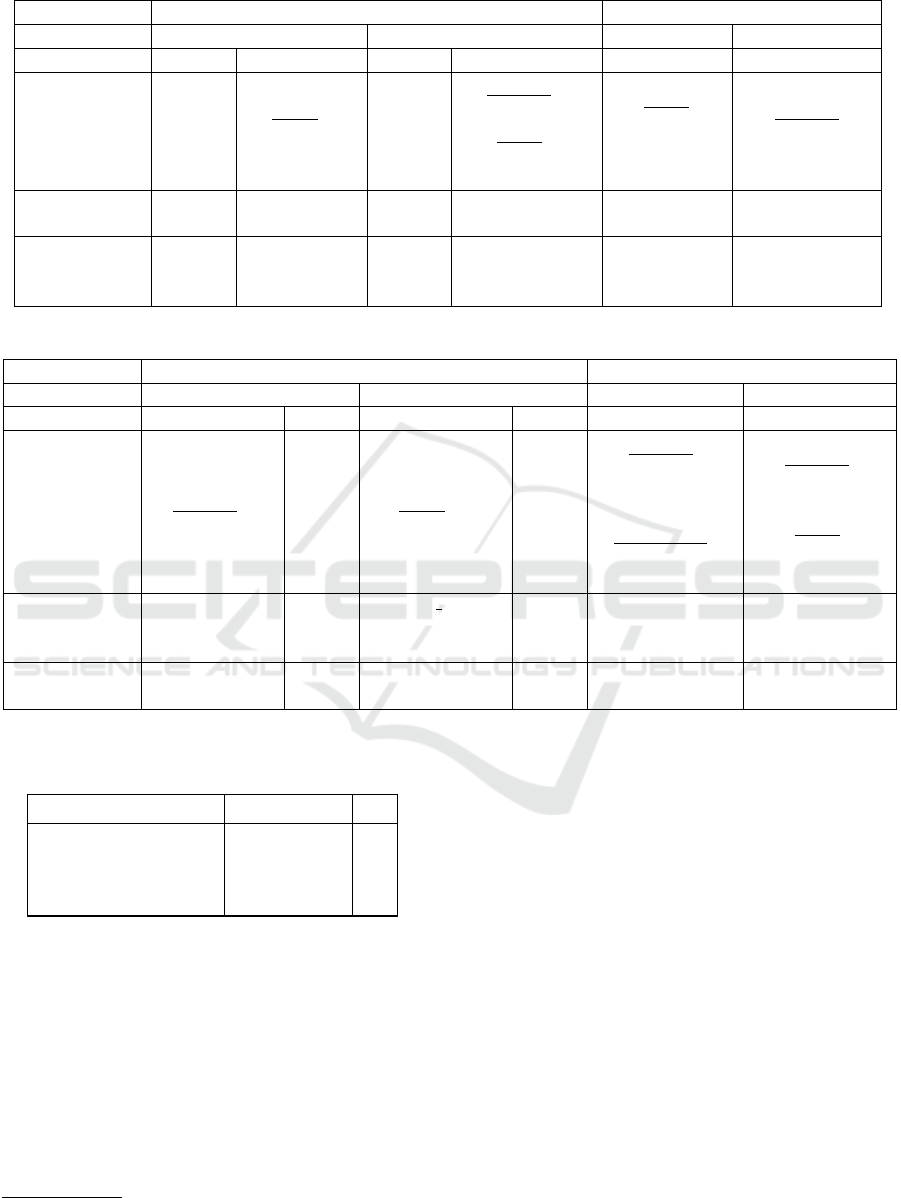
Table 5: MDSR Pattern Classification.
Individual Chained
Stateful Stateless Stateful Stateless
Critical Minor
Critical
Minor Critical Critical
Microservices
JPyL
Service
Logging
Hipster
Adservice
JPyL
Security
Headers
JPyL
UserData,
White/Black
Listing
Hipster
Recommend,
ProductCatalog
Failure
Impact
404 Service
Not Found
404 Service
Not Found
404 Service
Not Found
404 Service
Not Found
Pattern
Database-Per
Service
Single
Responsibility
Principle (SRP)
Database-Per
Service
API
Gateway
Table 6: MDSR Bad Smell Classification.
Individual Chained
Stateful Stateless Stateful Stateless
Critical Minor Critical Minor Critical Critical
Microservices
Hipster
Frontend
JPyL
SSL
Hipster
Payment,
Checkout,
Cart
WordPress
Comments
HTTP REST
Hipster
Shipping,
Checkout
JPyL
PortConfig,
ReverseProxy
Failure
Impact
500
Internal Server
Error
ERR SSL
Protocol Failure
Error
Database
Connection
Error
500
Internal Server
Error
Bad
Smells
SRP
Violation
Microservices
Greedy
Chained, Shared
Persistency
Chained, Cyclic
Dependency
Table 7: MDSR Patterns/Bad Smells found in 7 small Flask
Applications containing 30 Microservices.
Patterns/Bad Smells No. Services %
Database-Per-Service 5 17
Shared Persistency 2 7
Chained Services 21 70
Other 2 6
running Ubuntu 18.04. Hipster uses Minikube 1.19.0
and multiple languages including Python 3.6, Go 1.10
and C# 8.0. JPyL uses Jupyter Server 6.1, Python 3.6,
MySQL 5.7 and Flask 1.1.2. WordPress v5.7.2 uses
PHP 7.2 and MySQL 5.7. The code for all applica-
tions, tools and experiments are available
7
.
6.1 Critical Microservice Failures
Catastrophic failure is a major challenge for web
applications and our case study applications are no
7
https://bitbucket.org/latent12/microproject/src/master/
exception. To investigate the failure of critical
microservices we target the chained/stateful/critical
HTTP REST microservice in WordPress, the individ-
ual/stateless/critical SSL microservice in JPyL & the
chained/stateful/critical Cart Service in Hipster.
Figures 7, 8 & 9 plot throughput (Request KB/s)
against time. The red line in each box plot is the me-
dian throughput from three executions. Once estab-
lished, all services have throughputs of approximately
600KB/s. When the fault injector kills the critical mi-
croservice at 43s the applications fail almost instanta-
neously: by 50s throughput is 0KB/s.
6.2 Minor/Individual Failures
Our first investigation of the failure of minor mi-
croservices uses an individual microservice. Specif-
ically we target the individual/stateful/minor Service
Logging microservice in JPyL. Recall that, although
stateful, this microservice has a private store follow-
Classifying the Reliability of the Microservices Architecture
29

Figure 7: A JPyL Critical Failure (SSL) at 43s.
Figure 8: A WordPress Critical Failure (HTTP REST &
Comment) at 43s.
Figure 9: Hipster Critical Failure (Cart & Payment Ser-
vices) at 43s.
ing the Database-per-service design pattern.
As before, Figure 10 plots JPyL throughput (Re-
quest KB/s) against time, and the service is running
at around 600KB/s. Once the fault injector kills the
critical microservice at 43s the application continues
to serve pages, but throughput falls dramatically but
briefly to around 2KB/s. By 50s the application is
able to recover to a throughput of around 520KB/s.
Figure 10: JPyL Minor/Individual Failure (Service Log-
ging) at 43s.
6.3 Critical/Chained Failures
We next investigate the failure of critical/chained
chained microservices. Specifically we target the
chained/stateful/critical User Data & White/Black
Listing microservices in JPyL and the chained/state-
less/critical Product Catalog & Recommended mi-
croservices in Hipster. Both microservice chains im-
plement patterns that aim to recover reliability (Sec-
tion 4).
As before Figure 11 plots JPyL throughput (Re-
quest KB/s) against time, and the service is running at
around 600KB/s. Once the fault injector kills the pair
of microservices at 43s the application reports a 404
Service Not Found error and continues to serve pages.
However the throughput has fallen to around 2KB/s.
That is the application is barely able to accept client
requests or even load in a browser quickly. A sim-
ilar failure is reported for Hipster when the Product
Catalog service fails (Figure 12).
For realistic workloads the failure of chained/crit-
ical microservices even with pattern implementations
has caused the applications to fail catastrophically!
6.4 Multiple Microservices Failure
Even if an application survives the failure of a sin-
gle minor microservice, how will it cope when mul-
tiple microservices fail successively? To investigate
the failure of multiple microservices in JPyL we tar-
get three microservices i.e. Service Logging, Security
Headers & User Data – White/Black Listing. Specifi-
cally the fault injector kills these microservices in or-
der at approximately 16s, 32s and 48s into the execu-
tion.
Figure 13 plots JPyL throughput (Request KB/s)
against time, and the service is running at around
600KB/s. When the fault injector kills the in-
WEBIST 2022 - 18th International Conference on Web Information Systems and Technologies
30
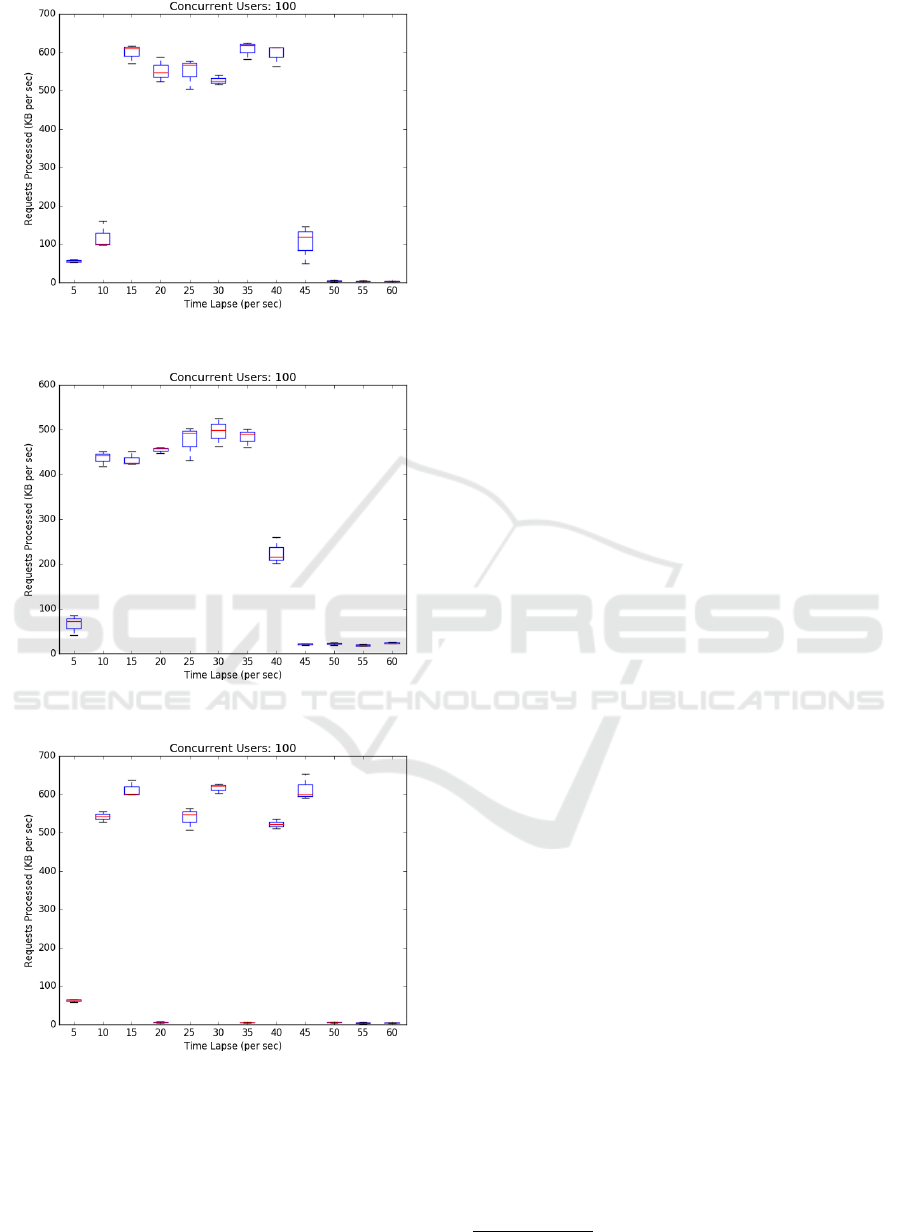
Figure 11: JPyL Chained (User Data & White-Blacklisting)
at 43s.
Figure 12: Hipster Chained (Product & Recommended) at
43s.
Figure 13: JPyL Multiple Minor Failures at 16s, 32s, 48s.
dividual/minor microservices the throughput drops
briefly to around 2KB/s, but then recovers to around
600KB/s. As before, when the chained/critical mi-
croservice fails at 48s the application fails catastroph-
ically.
6.5 Evaluation Summary
The key findings from our evaluation are as follows.
(1) All case study applications fail catastrophically
if a critical microservice fails ( 7, 8 & 9). (2) JPyL
survives the failure of an individual/minor microser-
vice (Figure 10), and even the successive failure of
two individual/minor microservices (up to 40s in Fig-
ure 13) (3) The failure of any chain of microservices
in JPyL & Hipster is catastrophic: throughput being
dramatically reduced (by 98%) (Figures 11, 12 and
after 48s in Figure 13). (4) Individual microservices
do not necessarily have minor reliability implications,
e.g. the Hipster Frontend is individual/stateful/critical
and the JPyl SSL is individual/stateless/critical (Fig-
ure 7).
7 CONCLUSION
Microservices are commonly classified based on their
dependence (chained/individual) or state (stateful/s-
tateless). We add a binary reliability classification,
and combine it with the other classifications to define
a three dimensional space: the MDSR Classification
in Figure 4 (Section 4). Using three established web
applications we exhibit microservices that exemplify
the six MDSR classes. We outline a prototype static
analyser that can statically identify all six classes in
Flask web applications, and apply it to seven small
web applications. Analysing the applications reveals
that the majority of services are chained (70%), state-
ful (73%) and critical (77%) (Table 4). We speculate
that the high percentage of critical services indicates
that the applications are not designed for reliability.
We demonstrate that each of the MDSR critical
case study microservices exhibits a known bad smell;
and that each minor MDSR class in the case study mi-
croservices follows a design pattern (Taibi and Lenar-
duzzi, 2018). Across, the seven applications we find
that 70% consist of the chained services bad smell
by default while only 17% were implemented for re-
siliency as they consist of the Database-Per-Service
pattern. Hence MDSR provides a framework to anal-
yse the properties of microservices and chains of mi-
croservices in a system, identifying components to be
considered for refactoring to improve reliability (Sec-
tion 5).
In future work we plan to apply the MDSR classi-
fication to larger microservice systems, e.g. to Death
Star
8
. It would be interesting to see whether MDSR
could be extended to also classify failures in infras-
tructure services.
8
https://github.com/djmgit/DeathStar
Classifying the Reliability of the Microservices Architecture
31

We also seek to enhance the analyser to make it
more automatic, e.g. to automatically detect more
persistent stores. Perhaps the analyser could sug-
gest when some microservice resilience patterns, like
bulkhead or load balancer, are implemented to reduce
criticality? Finally we would like to investigate the
potential of combining static MDSR analysis with dy-
namic SDG analysis.
REFERENCES
Cabot, J. (2018). Wordpress: A content management
system to democratize publishing. IEEE Software,
35(3):89–92.
Cooper, R. (2014). BBC online outage on saturday 19th july
2014. https://www.bbc.co.uk/blogs/internet/entries/
a37b0470-47d4-3991-82bb-a7d5b8803771.
Cristian, F. (1991). Understanding fault-tolerant distributed
systems. Comm. ACM, 34(2):56–78.
Ghirotti, S. E., Reilly, T., and Rentz, A. (2018). Tracking
and controlling microservice dependencies. Comm.
ACM, 61(11):98–104.
Google (2021). Hipster-shop microservices demo.
https://github.com/GoogleCloudPlatform/
microservices-demo.
Gupta, D. and Palvankar, M. (2020). Pitfalls and challenges
faced during a microservices architecture implemen-
tation. Technical report.
Hasselbring, W. and Steinacker, G. (2017). Microservice
architectures for scalability, agility and reliability in
e-commerce. In IEEE Intl Conf on Software Architec-
ture Workshops, pages 243–246.
Heorhiadi, V., Rajagopalan, S., Jamjoom, H., Reiter, M. K.,
and Sekar, V. (2016). Gremlin: Systematic resilience
testing of microservices. In IEEE 36th Intl Conf on
Distributed Computing Systems, pages 57–66.
IBM (2021). Microservices in the enterprise, 2021: Real
benefits, worth the challenges. Technical report, Tech-
nical report, IBM.
Jamshidi, P., Pahl, C., Mendonc¸a, N. C., Lewis, J., and
Tilkov, S. (2018). Microservices: The journey so far
and challenges ahead. IEEE Software, 35(3):24–35.
Lewis, J. and Fowler, M. (2015). Microservices: A defini-
tion of a new architectural term. https://martinfowler.
com/articles/microservices.html.
Ma, S.-P., Fan, C.-Y., Chuang, Y., Lee, W.-T., Lee, S.-J., and
Hsueh, N.-L. (2018). Using service dependency graph
to analyze and test microservices. In IEEE 42nd An-
nual Computer Software and Applications Conf, vol-
ume 2, pages 81–86.
Meng, Y., Zhang, S., Sun, Y., Zhang, R., Hu, Z., Zhang,
Y., Jia, C., Wang, Z., and Pei, D. (2020). Localizing
failure root causes in a microservice through causality
inference. In IEEE/ACM 28th Intl Symp on Quality of
Service (IWQoS), pages 1–10.
Montalenti, A. (2015). Kafkapocalypse: a post-
mortem on our service outage. https://blog.parse.ly/
kafkapocalypse/.
Nikolaidis, E., Chen, S., Cudney, H., Haftka, R. T., and
Rosca, R. (2004). Comparison of probability and pos-
sibility for design against catastrophic failure under
uncertainty. J. Mech. Des., 126(3):386–394.
Offutt, A. J., Harrold, M. J., and Kolte, P. (1993). A soft-
ware metric system for module coupling. J. Systems
and Software, 20(3):295–308.
Omer, A. M. and Schill, A. (2011). Automatic management
of cyclic dependency among web services. In 2011
14th IEEE Intl Conf on Computational Science and
Engineering, pages 44–51.
Patel, S. K., Rathod, V., and Prajapati, J. B. (2011). Per-
formance analysis of content management systems-
joomla, drupal and wordpress. Intl J. Computer Ap-
plications, 21(4):39–43.
Power, A. and Kotonya, G. (2018). A microservices archi-
tecture for reactive and proactive fault tolerance in IoT
systems. In IEEE 19th Intl Symposium on” A World
of Wireless, Mobile and Multimedia Networks”, pages
588–599.
Rossi, D. (2018). Consistency and availability in microser-
vice architectures. In Intl Conf on Web Information
Systems and Technologies, pages 39–55.
Rudrabhatla, C. K. (2018). Comparison of event choreogra-
phy and orchestration techniques in microservice ar-
chitecture. Intl J. Advanced Computer Science and
Applications, 9(8):18–22.
Salah, T., Zemerly, M. J., Yeun, C. Y., Al-Qutayri, M., and
Al-Hammadi, Y. (2016). The evolution of distributed
systems towards microservices architecture. In Proc.
11th Intl Conf for Internet Technology and Secured
Transactions, pages 318–325.
Soldani, J., Tamburri, D. A., and Van Den Heuvel, W.-J.
(2018). The pains and gains of microservices: A sys-
tematic grey literature review. J. Systems and Soft-
ware, 146:215–232.
Taibi, D. and Lenarduzzi, V. (2018). On the definition of
microservice bad smells. IEEE Software, 35(3):56–
62.
Taibi, D., Lenarduzzi, V., and Pahl, C. (2018). Architec-
tural patterns for microservices: A systematic map-
ping study. In CLOSER, pages 221–232.
Toffetti, G., Brunner, S., Bl
¨
ochlinger, M., Dudouet, F.,
and Edmonds, A. (2015). An architecture for self-
managing microservices. In Proceedings of the 1st
Intl Workshop on Automated Incident Management in
Cloud, pages 19–24.
Wolff, E. (2018). Why microservices fail: An experience
report. Technical report.
Wu, A. (2017). Taking the cloud-native approach with mi-
croservices. Ma-genic/Google Cloud Platform.
Zhou, X., Peng, X., Xie, T., Sun, J., Ji, C., Li, W., and
Ding, D. (2018). Fault analysis and debugging of mi-
croservice systems: Industrial survey, benchmark sys-
tem, and empirical study. IEEE Trans. on Software
Engineering.
Zimmermann, O. (2017). Microservices tenets. Computer
Science-Research and Development, 32(3):301–310.
WEBIST 2022 - 18th International Conference on Web Information Systems and Technologies
32
