
Class-conditional Importance Weighting for Deep Learning with Noisy
Labels
Bhalaji Nagarajan
1,† a
, Ricardo Marques
1,† b
, Marcos Mejia
1 c
and Petia Radeva
1,2,∗ d
1
Dept. de Matem
`
atiques i Inform
`
atica, Universitat de Barcelona, Barcelona, Spain
2
Computer Vision Center, Cerdanyola (Barcelona), Spain
Keywords:
Noisy Labeling, Loss Correction, Class-conditional Importance Weighting, Learning with Noisy Labels.
Abstract:
Large-scale accurate labels are very important to the Deep Neural Networks to train them and assure high per-
formance. However, it is very expensive to create a clean dataset since usually it relies on human interaction.
To this purpose, the labelling process is made cheap with a trade-off of having noisy labels. Learning with
Noisy Labels is an active area of research being at the same time very challenging. The recent advances in
Self-supervised learning and robust loss functions have helped in advancing noisy label research. In this paper,
we propose a loss correction method that relies on dynamic weights computed based on the model training.
We extend the existing Contrast to Divide algorithm coupled with DivideMix using a new class-conditional
weighted scheme. We validate the method using the standard noise experiments and achieved encouraging
results.
1 INTRODUCTION
Deep Neural Networks (DNNs) tend to show an in-
credible upshot in performance when trained with
large-scale labeled data under supervised environ-
ments (Krizhevsky et al., 2012). The strong and
implicit assumption in training any DNN is that the
dataset is clean and reliable. However, in real-world
it is difficult to meet this assumption owing to the ex-
pensive cost and the time required to create such large
high-quality datasets (Liao et al., 2021). The labelling
cost is reduced substantially by crowd-sourcing the
labelling process or by using an automated labelling
system. However, this inherently leads to having er-
rors in the labels.
Recent advances in DNNs show that it is possi-
ble to create learning algorithms that abide to less
accurate training data (Sun et al., 2017; Pham et al.,
2021; Ghiasi et al., 2021). However the DNNs have
a tendency to overfit on the label noise (Zhang et al.,
2021a). There are two common approaches to tackle
the problem of overfitting on noisy labels - Semi-
a
https://orcid.org/0000-0003-2473-2057
b
https://orcid.org/0000-0001-8261-4409
c
https://orcid.org/0000-0002-6839-8436
d
https://orcid.org/0000-0003-0047-5172
∗
IAPR Fellow
†
Joint first authors
Supervised Learning (SSL) and Learning with Noisy
Labels (LNL) (Zheltonozhskii et al., 2021). SSL uses
scarce high-quality labelled data to learn representa-
tions of large amount of unlabelled data (Hendrycks
et al., 2019). LNL approach uses less expensive anno-
tations, but uses noisy labels as a trade-off (Natarajan
et al., 2013). Both approaches are closely related to
each other and are often used in combination to help
DNNs learn from less accurate samples (Zheltonozh-
skii et al., 2021; Li et al., 2020; Chen et al., 2021).
LNL has been already studied both in machine and
deep learning (Fr
´
enay and Verleysen, 2013; Fr
´
enay
et al., 2014; Nigam et al., 2020; Cordeiro and
Carneiro, 2020). The objective of any LNL algorithm
is to find the best estimator for a dataset distribution
learnt from the original distribution with noise. It is
necessary for the DNN to learn the noise structure and
estimate the parameters accordingly. In many LNL
approaches, there is short ‘warm-up’ phase where su-
pervised learning or self-learning is used before deal-
ing with the label noise. By using the warm up, it
is possible to model the loss into a Mixture Model
(Arazo et al., 2019). The main reasoning for using
this phase is based on the behaviour of DNNs to learn
the clean samples faster than the noisy samples (Arpit
et al., 2017).
The next phase of LNL deals with adapting the
noise of the distribution and achieve robust classi-
Nagarajan, B., Marques, R., Mejia, M. and Radeva, P.
Class-conditional Importance Weighting for Deep Learning with Noisy Labels.
DOI: 10.5220/0010996400003124
In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2022) - Volume 5: VISAPP, pages
679-686
ISBN: 978-989-758-555-5; ISSN: 2184-4321
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
679

fiers. Several strategies have been proposed to make
the LNL network learn the dataset distribution with-
out the noise (Algan and Ulusoy, 2021). The com-
monly used Cross-Entropy Loss and Mean Absolute
Error are not robust to the underlying noise (Ma et al.,
2020) and it is important for the objective functions to
be robust to the noise of the underlying distribution.
Loss correction methods help in increasing the robust-
ness of losses by modifying the loss functions based
on the weights of the labels. In this paper, we pro-
pose a class-conditional loss correction method based
on the importance of classes. The loss is adapted dur-
ing each step of the training using weights computed
from the classifier scores. This adjustment is carried
out such that the classes that are weakly learned are
emphasized better during the learning process. To
validate the proposed method, we use the Contrast to
Divide framework (Zheltonozhskii et al., 2021) and
correct the loss during the training phase. Below, we
outline the main contributions of this work.
• First, we propose the weighed version of the loss
function for LNL. By weighting the unlabeled
part of the training data, it is made possible to give
more importance to the less learnt or hard to learn
classes.
• Second, we do an extensive analysis of various
components in the loss function and study the pro-
gression of the LNL framework. Moreover, we
show improvement with respect to the state of art
on LNL on a public dataset.
The rest of the paper is organized as follows. In
Section 2, we briefly discuss the related work. We
present the details of the proposed technique in Sec-
tion 3. The experiments and evaluations used to val-
idate the proposed method is explained in Section 4
followed by conclusion in Section 5.
2 RELATED WORK
There are several works in the literature on learning
with noisy labels. In this section, we briefly review
the recent literature that are relevant to our proposed
method.
2.1 Learning with Noisy Labels
There are several classes of LNL algorithms, broadly
falling into loss modifications and noise detection
schemes. Some methods use label correction (Xiao
et al., 2015; Li et al., 2017), where the noisy labels
are corrected using inferences made by DNNs, which
are in-turn trained only on clean labels, while other
methods use loss correction schemes. In this class
of algorithms, the network aims at increasing its ro-
bustness towards noise by modifying the loss function
(Han et al., 2018; Ma et al., 2020). A computationally
efficient method based on noise similarity labels was
used instead of learning from noisy class labels and
was able to reduce the noise rate (Wu et al., 2021).
In general, similarity-based approaches have been ef-
fective in many LNL algorithms where using a noise
transition matrix serves as a bridge between the clean
and noisy samples (Hsu and Kira, 2015; Hsu et al.,
2019; Wu et al., 2020).
The loss correction methods are based on modify-
ing the loss function with weights during the training
of DNNs. Common problems with the existing loss
functions are over-fitting of noise and under-learning.
Importance weighting schemes have been effective in
making the losses more robust to noise (Liu and Tao,
2015; Zhang and Sabuncu, 2018; Yu et al., 2019;
Zhang and Pfister, 2021). The Symmetric Cross En-
tropy loss was created using a Reverse Cross Entropy
term along with the Cross Entropy term to make the
loss more robust to noise and achieve better learn-
ing of the samples (Wang et al., 2019). Normaliza-
tion techniques proved to make the commonly used
loss functions more robust to noise and also by us-
ing two robust loss functions to create an Active Pas-
sive Loss helped in boosting each other’s performance
(Ma et al., 2020). Backward and forward noise tran-
sition matrices, which are based on matrix inversion
and multiplication were pre-computed and shew to
increase the robustness of the loss function (Patrini
et al., 2017). In the above discussed methods, the
basic assumption in a relabeling approach is to have
clean labels, which is also a limitation of these algo-
rithms.
Another variation of LNL algorithms focuses
on new learning schemes adapted to noisy labels
(Malach and Shalev-Shwartz, 2017; Yu et al., 2019).
DivideMix (Li et al., 2020) uses a co-teaching strat-
egy to learn two networks simultaneously, so that one
network learns from the other networks’ confident
samples. This algorithm uses a loss to fit a Gaus-
sian Mixture Model in order to divide the samples
into labeled and unlabeled set. A Beta-mixture model
was also used to model the losses for learning the
noise in an unsupervised manner (Arazo et al., 2019).
Selective Negative Learning and Positive Learning
were used to selectively apply positive learning on
expected-to-be-clean data, which is obtained by Neg-
ative Learning, where complimentary labels were
used instead of the actual labels (Kim et al., 2019).
This approach proved to be very effective compared
to the normal positive selection of samples. Early
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
680

Learning Regularization (Liu et al., 2020) learned the
clean samples first, followed by noisy samples in later
epochs. This method was beneficial as it prevented
the network from memorization of the noisy samples.
Data augmentation is also an effective means to com-
bat the noisy label problem (Berthelot et al., 2019b;
Li et al., 2020; Berthelot et al., 2019a; Sohn et al.,
2020). AugDesc (Nishi et al., 2021) used weak aug-
mentations to learn the loss and strong augmentations
to improve the generalizations.
Most of the literature presented above, uses a com-
bination of different LNL schemes to make the net-
work robust to noise. In this paper, we propose a loss
correction scheme on top of the already effective Di-
videMix and Contrast to Divide learning schemes to
enhance the learning of models.
2.2 Self-supervised and
Semi-supervised Learning
Semi-supervised learning algorithms utilize the un-
labeled data by performing providing pseudo-labels
to the unlabeled data and adding constraints to the
objective functions. Regularization could be consis-
tency regularization or entropy minimization. Mix-
Match (Berthelot et al., 2019b) combined both the
regularization methods to produce labels to the unla-
beled classes. ReMixMatch (Berthelot et al., 2019a)
and FixMatch (Sohn et al., 2020) were adaptations of
MixMatch, which used weakly augmented images to
produce labels and predict against the strongly aug-
mented images. It is also beneficial to remove wrong
labels that have high levels of noise. By using only a
portion of the training set which is correct, the same
performance could be achieved (Ding et al., 2018;
Kong et al., 2019).
Self-Supervised Learning (SSL) algorithms learn
representations in a task-agnostic environment so that
the representations are meaningful irrespectively of
the labels. Contrastive loss has been vital in the recent
success of SSL algorithms, which clusters data points
based on the (dis-)similarity of classes (Wang and
Liu, 2021). By using these representations, any down-
stream task could be well learned by the DNNs. SSL
algorithms have been widely used in solving the noisy
label problems. Since the networks are learned with-
out labels, they are able to produce features that are
robust to noise (Cheng et al., 2021). Data re-labeling
helps in increasing the effectiveness of DNNs. The
performance was boosted by using a parallel network
to learn the portion of clean labels (Mandal et al.,
2020). Supervised learning and self-supervised learn-
ing can also be used together as a co-learning scheme
as this could maximize the learning behaviour using
both the constraints (Tan et al., 2021; Huang et al.,
2021). Contrastive DivideMix (Zhang et al., 2021b)
fuses the contrastive and semi-supervised learning al-
gorithms.
DivideMix (Li et al., 2020) uses a semi-supervised
training phase. It uses the MixMatch algorithm to per-
form label co-refinement and co-guessing on labeled
and unlabeled samples. This works on per-sample
loss behaviour and has been an effective technique
to model the noise. One of the bottleneck in this
method is the warm-up phase. This was overcome
using the Contrast to Divide (Zheltonozhskii et al.,
2021) method. Instead of using a supervised learning
in DivideMix, this algorithm used a self-supervised
learning method. In our proposed approach, we add
an importance weighting scheme that would enable
the algorithms to focus selectively on the classes.
3 IMPORTANCE WEIGHTING
In this section, we first brief the rationale behind the
approach. We provide background information fol-
lowed by the proposed weighted scheme.
3.1 Rationale
Our approach is motivated by the observation that
learning is unbalanced across classes, that is, after a
given number of epochs, the accuracy of the model
tends to vary significantly over different classes.
Our hypothesis is that, by focusing the learning ef-
fort in those classes for which the model is cur-
rently less efficient, the overall accuracy of the model
can be improved. To test this hypothesis, we pro-
pose to enhance the DivideMix algorithm (Li et al.,
2020) with a class-conditional importance weighting
scheme which assigns a larger weight to the classes
for which the model has a poorer performance.
3.2 Background
At each epoch, the DivideMix algorithm, on which
we build, separates the training set into two disjoint
sets: a set X containing potentially clean data, and a
set U containing potentially noisy data. This separa-
tion between clean and noisy data is made by fitting
a Gaussian mixture model to the softmax output of a
pretrained network (Li et al., 2020). The loss function
used for training thus combines the losses on both the
potentially clean and noisy sets, and is given by (Li
et al., 2020):
L = L
X
+ λ
u
L
U
+ λ
r
L
reg
, (1)
Class-conditional Importance Weighting for Deep Learning with Noisy Labels
681

where L
X
is the cross-entropy loss over the aug-
mented and mixed clean data X
0
; L
U
is a mean
squared error loss over the augmented and mixed
noisy data U
0
; and finally, L
reg
is a regularization term
used to encourage the model to evenly distribute its
predictions across all classes.
The loss L
U
of the noisy data is defined as:
L
U
=
1
|U
0
|
∑
(x,p)∈U
0
||p − p
θ
(x)||
2
2
,
where |U
0
| is the number of noisy samples at the cur-
rent epoch, p is the label assigned to each noisy sam-
ple x through co-guessing (Li et al., 2020), and p
θ
(x)
is the model prediction for x given the current model
parameters θ. The regularization term L
reg
, in its turn,
is given by:
L
reg
=
∑
c
π
c
log
π
c
1
|S|
∑
x∈S
p
c
θ
(x)
!
−1
, (2)
where S = X
0
+ U
0
, and π
c
= 1/C is a uniform prior
distribution over the probability of each class in S .
Providing a uniform prior distribution π
c
= 1/C in
Equation (2) causes the loss to be minimal when the
model yields exactly the same number of predictions
for all classes in the data set.
3.3 Class-conditional Importance
Weighted Loss
We now describe the approach taken to assign a
weight for each class. Let f be a vector of C elements,
C being the number of classes in the data set. Each el-
ement f
c
∈ f is given by f
c
= 1 − F
c
1
, where F
c
1
repre-
sents the F
1
score for a particular class c at the current
epoch. The vector f is then smoothed over a window
of n
e
epochs, yielding f
0
. Then, the weight vector w is
computed as:
w =
max(λ
w
,f
0
)
|
max(λ
w
,f
0
)
|
×C, (3)
where λ
w
is a hyperparameter which has the role
of limiting how far the resulting weights can devi-
ate from the value 1. Hence, the resulting weights
w = {w
1
,...,w
C
} of Equation (3) take a larger value
for those classes for which the F
1
score is smaller.
Furthermore, to account for the importance of
each class in the learning phase, we introduce the
weights w (Equation (3)) in the loss function L
U
of
the unlabeled set (Equation (3.2)), yielding:
L
U
=
1
|U
0
|
∑
(x,p)∈U
0
w
c
||p − p
θ
(x)||
2
2
, (4)
where w
c
is the weight of class c, and c is the class of
the image x. Finally, to apply the weights to the reg-
ularization loss L
reg
, we simply replace the uniform
prior distribution π
c
= 1/C used in DivideMix (Equa-
tion (2)) by a non-uniform prior based on the weights
w, such that:
π
c
=
w
c
C
, (5)
where w
c
is the class weight according to Equa-
tion (3), and C is the number of classes in the dataset.
This way, when the model performs poorly for a given
class due to not choosing that same class as many
times as it should, using the prior specified in Equa-
tion (5) will encourage the model to increase the num-
ber of prediction for this same class. Figure 1 shows
the pipeline of our proposed approach.
4 EXPERIMENTS
We evaluate our proposed framework following the
common methodology in synthetic noise benchmarks.
We use CIFAR-10 (Krizhevsky and Hinton, 2009) to
validate the method, varying the amount of injected
noise. We measure the performance of the networks
using accuracy as an evaluation metric. We provide
the accuracy over five runs for each noise ratio, fol-
lowing the results presented in Contrast to Divide
(Zheltonozhskii et al., 2021).
4.1 Implementation Details
Similarly to (Li et al., 2020), we used a PreAct
ResNet-18 architecture (He et al., 2016) for Di-
videMix. Moreover, we coupled DivideMix with
Contrast to Divide (C2D), which has been shown to
considerably boost the original DivideMix algorithm
(Zheltonozhskii et al., 2021). As regards the injected
noise in the CIFAR-10 data set, we used two types
of label noise: symmetric and asymmetric. Given
a target noise ratio, the symmetric noise is gener-
ated by randomly substituting the original label by a
randomly selected new label chosen with a uniform
probability over the rest of the class labels. Regard-
ing the asymmetric noise, we follow (Zheltonozhskii
et al., 2021) who designed the noise so as to mimic
the structure of real-world noise labels substituting
the labels with those of the most similar classes. In
each experiment, the networks are optimized during
360 epochs.
Regarding the λ
r
hyperparameter, we follow (Li
et al., 2020) and set its value to 1. To compute the
weights per class, we set λ
w
= 0.1 in Equation (3), and
use a smoothing window of 5 epochs (i.e., n
e
= 5).
The problem of selecting λ
u
is discussed below.
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
682
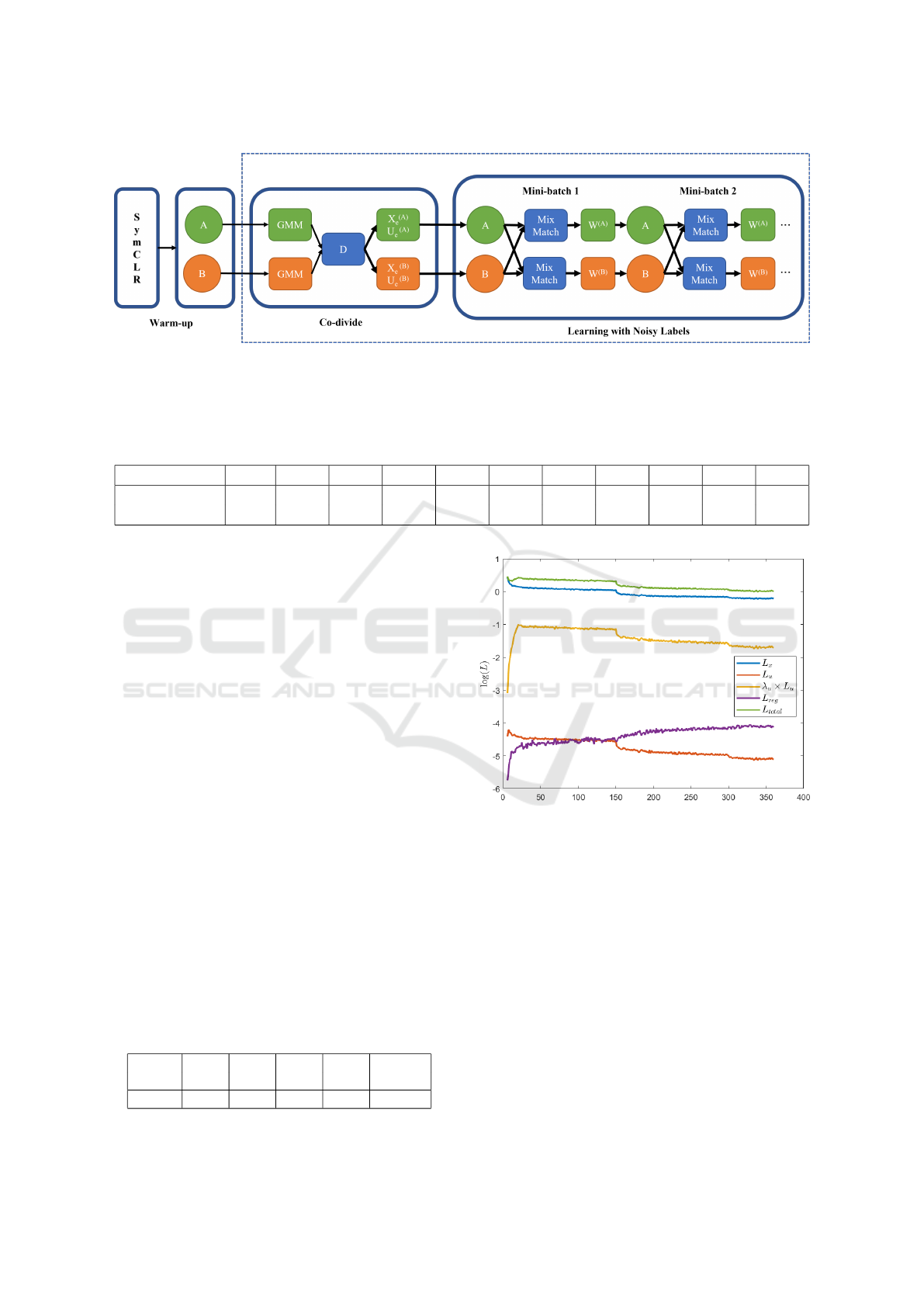
Figure 1: Pipeline of our proposed approach. The symCLR component pre-trains networks A and B. Then, these undergo
the DivideMix warm-up phase where the two networks are trained on all the data set during a small number of epochs using
standard cross-entropy loss. Then, at each epoch, the co-divide is applied to divide the data set in two disjoint sets, yielding
the set of the clean and of the noisy labels (X and U, respectively). For each mini-batch, networks A and B are then trained
separately using MixMatch and our proposed weighting scheme.
Table 1: Study of the optimal λ
u
value. The table shows the peak and final accuracy on CIFAR-10 for 5 ≤ λ
u
≤ 50.
Method 5 10 15 20 25 30 35 40 45 50
Weighted C2D Peak 91.73 92.45 92.92 93.50 93.50 93.60 93.58 93.69 93.52 93.66
+DM (90%) Final 91.45 92.35 92.73 93.33 93.48 93.53 93.47 93.28 93.42 93.57
4.1.1 Selection of λ
u
As in (Li et al., 2020) and (Zheltonozhskii et al.,
2021), the performance of our proposed approach can
vary significantly depending on the used parameter
λ
u
, i.e., the hyperparameter specifying the weight of
the unsupervised loss L
U
in the final loss (see Equa-
tion (1)). Therefore, in Table 1, we provide a detailed
analysis of the effect of this hyperparameter on the
final accuracy reached by our method when consider-
ing 90% of symmetric noise. The results show that
the optimal λ
u
for our method with a noise ratio of
90% is of 40. This value is roughly in-line with the
one (50) reported by (Li et al., 2020).
Following a similar approach, we collected a set
of selected λ
u
values for each considered noise ra-
tio value. We can observe that the optimal λ
u
value
found seems to decrease with the noise ratio present
in the dataset. This seems to indicate that, the larger
the amount of noisy labels present in the used dataset,
the more relevant the loss L
U
of the unlabeled data
becomes in the learning process. The set of selected
λ
u
values for each considered noise ratio value are
shown in Table 2. These values are used henceforth in
all experiments for each corresponding noise value.
Table 2: Table with the selected λ
u
values for each noise
ratio.
Noise
20% 50% 80% 90%
40%
Ratio (asym)
λ
u
0 25 30 40 0
Figure 2: Different terms of the loss function as a function
of the epoch. The plot was generated for CIFAR-10 with
80% of symmetric noise and λ
u
= 30.
At this stage, it is interesting to analyze the role of
the λ
u
hyperparameter in the total loss value of Equa-
tion (1). Figure 2 depicts the different terms of the
used loss function. We can observe that the hyperpa-
rameter λ
u
acts as a scaling factor which brings L
U
(in
red) up to a magnitude in which it can actually influ-
ence the final loss function shape (in orange the prod-
uct λ
u
× L
U
, and in green the final loss, denoted by
L
total
in Figure 2). It is also apparent from the curves
that the loss of the labeled data (L
X
, in blue) is the one
that dominates the total loss shape. Finally, the reg-
ularization loss L
reg
seems to have a rather marginal
role on the overall optimization process.
Class-conditional Importance Weighting for Deep Learning with Noisy Labels
683
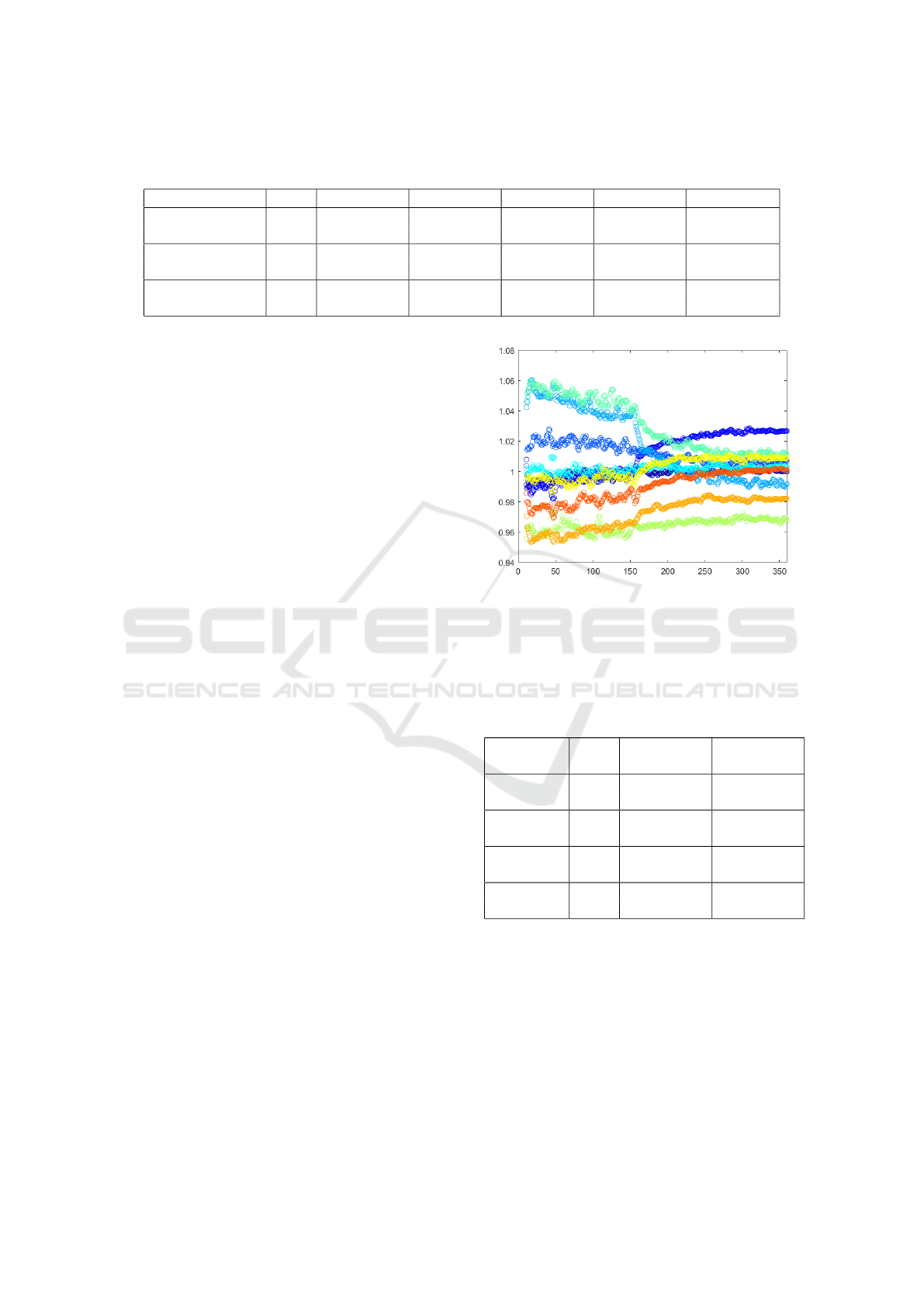
Table 3: Peak and final accuracy (%, mean ± std over five runs) on CIFAR-10. DivideMix and C2D+DM results are obtained
from literature.
Method 20% 50% 80% 90% 40% (asym)
DivideMix
Peak 96.1 94.6 93.2 76.0 -
Final 95.7 94.4 92.9 75.4 -
C2D+DM
Peak 96.43±0.07 95.32±0.12 94.40±0.04 93.57±0.09 93.45±0.07
Final 96.23±0.09 95.15±0.16 94.30±0.12 93.42±0.04 90.75±0.35
Weighted Peak 96.50±0.07 95.79±0.06 94.40±0.05 93.70±0.16 93.62±0.09
C2D+DM (ours) Final 96.40±0.21 95.56±0.07 94.24±0.09 93.54±0.13 92.83±0.21
4.2 Results and Analysis
The results for the application of our proposed
method to the CIFAR-10 dataset are shown in Table 3,
where a comparison with the results of the original
method is provided. The results show that, when us-
ing our importance weighting scheme, the accuracy
results generally improve over that of C2D+DM, and
it never performs worse. Indeed, except for a noise
level of 80%, our method delivers consistent improve-
ments over its non-weighted counterpart. This con-
firms our hypothesis that the overall efficiency of the
algorithm can be improved by focusing the learning
effort in those classes that the model is having more
difficulty to learn. Moreover, it also validates our
weighting strategy based on the F
1
score proposed in
Equation (3).
A detailed illustration of the weights values
throughout the learning process is provided in Fig-
ure 3. It shows that the weights for a given class re-
main coherent through the learning phase, since we
are able to clearly identify each class (corresponding
to a particular color) through the weights plot. They
also show that the weights for each class converge to a
particular value, which is determined by the F
1
score
that the model is able to get for each particular class
as the learning progresses.
4.3 Ablation Study
In this section, we study the effect of weights in the
L
U
and L
reg
terms individually. We show the results
of this ablation study in Table 4. They show that when
the weights are applied to only one of the two con-
sidered terms (L
U
and L
reg
), the accuracy is inferior
to the case in which the weights are included in both
losses.
5 CONCLUSIONS
In this paper, we propose a class-conditional dynam-
ically weighted Contrast to Divide algorithm, where
Figure 3: Illustration of the weights assigned to each class
(y-axis) during 355 training epochs (x-axis, 5 warm-up
epochs + 355 of DivideMix). The results are generated us-
ing the weights of a single network. Each color corresponds
to a different class in the dataset (total of 10).
Table 4: Ablation study. The entries for C2D+DM and
weighted C2D+DM is mean over five runs, whereas the
other two are mean over two runs.
Method
80% 90%
(λ
u
= 30) (λ
u
= 40)
C2D+DM
Peak 94.40±0.04 93.57±0.09
Final 94.30±0.12 93.42±0.04
Weights in Peak 94.23±0.12 93.68±0.09
L
U
Only Final 94.11±0.16 93.51±0.16
Weights in Peak 94.28±0.06 93.58±0.09
L
reg
Only Final 94.11±0.05 93.37±0.11
Weighted Peak 94.40±0.05 93.70±0.16
C2D+DM Final 94.24±0.09 93.54±0.13
the weights emphasize the learning behaviour of in-
dividual classes. Here, we use a per-class importance
weighting scheme based on F1-score obtained in each
epoch. Our importance weighting approach proved to
outperform the state of the art for the CIFAR-10 data
set in all the noise rates. We studied the behavior of λ
u
in different noise rates and also analysed the weights
throughout the learning process. The results prove the
effectiveness of the proposed scheme on an existing
state of the art LNL approach.
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
684

Although, the algorithm has shown performance
improvements, it is important to study the behaviour
in more complex data sets such as CIFAR-100, Cloth-
ing 1M and WebVision. In this paper, we have used
F1-score to create the weights, however, other meth-
ods have to be studied to compute the weights per
class, which can eventually improve the results pre-
sented here. This information regarding the perfor-
mance per class (i.e., F
1
score or other) can be used
to improve other stages of the original DivideMix al-
gorithm, such as, for example, the division between
clean and noisy data.
ACKNOWLEDGEMENTS
This work was partially funded by TIN2018-095232-
B-C21, SGR-2017 1742, Greenhabit EIT Digital
program and CERCA Programme / Generalitat de
Catalunya. Bhalaji Nagarajan acknowledges the sup-
port of FPI Becas, MICINN, Spain. We acknowledge
the support of NVIDIA Corporation with the donation
of the Titan Xp GPUs.
REFERENCES
Algan, G. and Ulusoy, I. (2021). Image classification with
deep learning in the presence of noisy labels: A sur-
vey. Knowledge-Based Systems, 215:106771.
Arazo, E., Ortego, D., Albert, P., O’Connor, N., and
McGuinness, K. (2019). Unsupervised label noise
modeling and loss correction. In International Con-
ference on Machine Learning, pages 312–321. PMLR.
Arpit, D., Jastrzebski, S., Ballas, N., Krueger, D., Bengio,
E., Kanwal, M. S., Maharaj, T., Fischer, A., Courville,
A., Bengio, Y., et al. (2017). A closer look at mem-
orization in deep networks. In International Confer-
ence on Machine Learning, pages 233–242. PMLR.
Berthelot, D., Carlini, N., Cubuk, E. D., Kurakin, A.,
Sohn, K., Zhang, H., and Raffel, C. (2019a).
Remixmatch: Semi-supervised learning with distri-
bution alignment and augmentation anchoring. arXiv
preprint arXiv:1911.09785.
Berthelot, D., Carlini, N., Goodfellow, I., Papernot, N.,
Oliver, A., and Raffel, C. A. (2019b). Mixmatch:
A holistic approach to semi-supervised learning. Ad-
vances in Neural Information Processing Systems, 32.
Chen, Y., Shen, X., Hu, S. X., and Suykens, J. A. (2021).
Boosting co-teaching with compression regularization
for label noise. In Proceedings of the IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition,
pages 2688–2692.
Cheng, H., Zhu, Z., Sun, X., and Liu, Y. (2021). Demys-
tifying how self-supervised features improve training
from noisy labels. arXiv preprint arXiv:2110.09022.
Cordeiro, F. R. and Carneiro, G. (2020). A survey on
deep learning with noisy labels: How to train your
model when you cannot trust on the annotations? In
2020 33rd SIBGRAPI Conference on Graphics, Pat-
terns and Images (SIBGRAPI), pages 9–16. IEEE.
Ding, Y., Wang, L., Fan, D., and Gong, B. (2018). A semi-
supervised two-stage approach to learning from noisy
labels. In 2018 IEEE Winter Conference on Applica-
tions of Computer Vision (WACV), pages 1215–1224.
IEEE.
Fr
´
enay, B., Kab
´
an, A., et al. (2014). A comprehensive in-
troduction to label noise. In ESANN. Citeseer.
Fr
´
enay, B. and Verleysen, M. (2013). Classification in the
presence of label noise: a survey. IEEE transactions
on neural networks and learning systems, 25(5):845–
869.
Ghiasi, G., Zoph, B., Cubuk, E. D., Le, Q. V., and Lin, T.-
Y. (2021). Multi-task self-training for learning gen-
eral representations. In Proceedings of the IEEE/CVF
International Conference on Computer Vision, pages
8856–8865.
Han, B., Yao, J., Niu, G., Zhou, M., Tsang, I., Zhang, Y.,
and Sugiyama, M. (2018). Masking: A new perspec-
tive of noisy supervision. Advances in Neural Infor-
mation Processing Systems, 31:5836–5846.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In 2016 IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR), pages 770–778.
Hendrycks, D., Mazeika, M., Kadavath, S., and Song, D.
(2019). Using self-supervised learning can improve
model robustness and uncertainty. Advances in Neural
Information Processing Systems, 32:15663–15674.
Hsu, Y.-C. and Kira, Z. (2015). Neural network-based
clustering using pairwise constraints. arXiv preprint
arXiv:1511.06321.
Hsu, Y.-C., Lv, Z., Schlosser, J., Odom, P., and Kira, Z.
(2019). Multi-class classification without multi-class
labels. arXiv preprint arXiv:1901.00544.
Huang, L., Zhang, C., and Zhang, H. (2021). Self-adaptive
training: Bridging the supervised and self-supervised
learning. arXiv preprint arXiv:2101.08732.
Kim, Y., Yim, J., Yun, J., and Kim, J. (2019). Nlnl: Neg-
ative learning for noisy labels. In Proceedings of the
IEEE/CVF International Conference on Computer Vi-
sion, pages 101–110.
Kong, K., Lee, J., Kwak, Y., Kang, M., Kim, S. G., and
Song, W.-J. (2019). Recycling: Semi-supervised
learning with noisy labels in deep neural networks.
IEEE Access, 7:66998–67005.
Krizhevsky, A. and Hinton, G. (2009). Learning multiple
layers of features from tiny images. Technical report,
University of Toronto, Toronto, Ontario.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). Im-
agenet classification with deep convolutional neural
networks. Advances in neural information processing
systems, 25:1097–1105.
Li, J., Socher, R., and Hoi, S. C. (2020). Dividemix:
Learning with noisy labels as semi-supervised learn-
ing. arXiv preprint arXiv:2002.07394.
Class-conditional Importance Weighting for Deep Learning with Noisy Labels
685

Li, Y., Yang, J., Song, Y., Cao, L., Luo, J., and Li, L.-J.
(2017). Learning from noisy labels with distillation.
In Proceedings of the IEEE International Conference
on Computer Vision, pages 1910–1918.
Liao, Y.-H., Kar, A., and Fidler, S. (2021). Towards
good practices for efficiently annotating large-scale
image classification datasets. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition, pages 4350–4359.
Liu, S., Niles-Weed, J., Razavian, N., and Fernandez-
Granda, C. (2020). Early-learning regularization pre-
vents memorization of noisy labels. Advances in Neu-
ral Information Processing Systems, 33.
Liu, T. and Tao, D. (2015). Classification with noisy labels
by importance reweighting. IEEE Transactions on
pattern analysis and machine intelligence, 38(3):447–
461.
Ma, X., Huang, H., Wang, Y., Romano, S., Erfani, S., and
Bailey, J. (2020). Normalized loss functions for deep
learning with noisy labels. In International Confer-
ence on Machine Learning, pages 6543–6553. PMLR.
Malach, E. and Shalev-Shwartz, S. (2017). Decoupling”
when to update” from” how to update”. Advances in
Neural Information Processing Systems, 30:960–970.
Mandal, D., Bharadwaj, S., and Biswas, S. (2020). A novel
self-supervised re-labeling approach for training with
noisy labels. In Proceedings of the IEEE/CVF Win-
ter Conference on Applications of Computer Vision,
pages 1381–1390.
Natarajan, N., Dhillon, I. S., Ravikumar, P. K., and Tewari,
A. (2013). Learning with noisy labels. Advances
in neural information processing systems, 26:1196–
1204.
Nigam, N., Dutta, T., and Gupta, H. P. (2020). Impact of
noisy labels in learning techniques: a survey. In Ad-
vances in data and information sciences, pages 403–
411. Springer.
Nishi, K., Ding, Y., Rich, A., and Hollerer, T. (2021). Aug-
mentation strategies for learning with noisy labels. In
Proceedings of the IEEE/CVF Conference on Com-
puter Vision and Pattern Recognition, pages 8022–
8031.
Patrini, G., Rozza, A., Krishna Menon, A., Nock, R., and
Qu, L. (2017). Making deep neural networks robust
to label noise: A loss correction approach. In Pro-
ceedings of the IEEE conference on computer vision
and pattern recognition, pages 1944–1952.
Pham, H., Dai, Z., Xie, Q., and Le, Q. V. (2021). Meta
pseudo labels. In Proceedings of the IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition,
pages 11557–11568.
Sohn, K., Berthelot, D., Li, C.-L., Zhang, Z., Carlini, N.,
Cubuk, E. D., Kurakin, A., Zhang, H., and Raffel, C.
(2020). Fixmatch: Simplifying semi-supervised learn-
ing with consistency and confidence. arXiv preprint
arXiv:2001.07685.
Sun, C., Shrivastava, A., Singh, S., and Gupta, A. (2017).
Revisiting unreasonable effectiveness of data in deep
learning era. In Proceedings of the IEEE international
conference on computer vision, pages 843–852.
Tan, C., Xia, J., Wu, L., and Li, S. Z. (2021). Co-learning:
Learning from noisy labels with self-supervision. In
Proceedings of the 29th ACM International Confer-
ence on Multimedia, pages 1405–1413.
Wang, F. and Liu, H. (2021). Understanding the behaviour
of contrastive loss. In Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recogni-
tion, pages 2495–2504.
Wang, Y., Ma, X., Chen, Z., Luo, Y., Yi, J., and Bailey, J.
(2019). Symmetric cross entropy for robust learning
with noisy labels. In Proceedings of the IEEE/CVF
International Conference on Computer Vision, pages
322–330.
Wu, S., Xia, X., Liu, T., Han, B., Gong, M., Wang, N.,
Liu, H., and Niu, G. (2020). Multi-class classifica-
tion from noisy-similarity-labeled data. arXiv preprint
arXiv:2002.06508.
Wu, S., Xia, X., Liu, T., Han, B., Gong, M., Wang, N., Liu,
H., and Niu, G. (2021). Class2simi: A noise reduc-
tion perspective on learning with noisy labels. In In-
ternational Conference on Machine Learning, pages
11285–11295. PMLR.
Xiao, T., Xia, T., Yang, Y., Huang, C., and Wang, X. (2015).
Learning from massive noisy labeled data for image
classification. In Proceedings of the IEEE conference
on computer vision and pattern recognition, pages
2691–2699.
Yu, X., Han, B., Yao, J., Niu, G., Tsang, I., and Sugiyama,
M. (2019). How does disagreement help generaliza-
tion against label corruption? In International Confer-
ence on Machine Learning, pages 7164–7173. PMLR.
Zhang, C., Bengio, S., Hardt, M., Recht, B., and Vinyals,
O. (2021a). Understanding deep learning (still) re-
quires rethinking generalization. Communications of
the ACM, 64(3):107–115.
Zhang, X., Liu, Z., Xiao, K., Shen, T., Huang, J., Yang, W.,
Samaras, D., and Han, X. (2021b). Codim: Learn-
ing with noisy labels via contrastive semi-supervised
learning. arXiv preprint arXiv:2111.11652.
Zhang, Z. and Pfister, T. (2021). Learning fast sample re-
weighting without reward data. In Proceedings of the
IEEE/CVF International Conference on Computer Vi-
sion, pages 725–734.
Zhang, Z. and Sabuncu, M. R. (2018). Generalized cross
entropy loss for training deep neural networks with
noisy labels. In 32nd Conference on Neural Informa-
tion Processing Systems (NeurIPS).
Zheltonozhskii, E., Baskin, C., Mendelson, A., Bronstein,
A. M., and Litany, O. (2021). Contrast to divide: Self-
supervised pre-training for learning with noisy labels.
arXiv preprint arXiv:2103.13646.
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
686
