
Preliminary Results on the Use of Classification Trees to Predict
Non-suicidal Self-injury with Data Collected through a Mobile App
Chiara Capra
1,2
, Pere Marti-Puig
1
, Daniel Vega Moreno
3
, Laia Llunas
2
, Stella Nicolaou
3
,
Carlos Schmidt
3
and Jordi Solé-Casals
1
1
Data and Signal Processing Research Group, Universitat de Vic-Universitat Central de Catalunya,
carrer de la Laura 13, Vic, Spain
2
beHIT, carrer de Mata 1, Barcelona, Spain
3
Department of Psychiatry & Mental Health, Hospital d’Igualada, Fundació Sanitària Igualada, Igualada, Spain
Keywords: Machine Learning, Digital Mental Health, Non-suicidal Self-injury, Applied AI.
Abstract: Machine learning (ML) integrated with technology has been a breakthrough in mental health, bringing clinical
improvements both for the patient and for the clinician. Among these, real-time patient symptoms’ tracking
through ecological momentary assessment (EMA) data can be a valuable tool to forecast symptomatology at
the individual-patient level for specific disorders, among which non suicidal self-injury. We aimed at applying
classification trees to predict non-suicidal self-injury (NSSI) with EMA data collected through a mobile app.
A database of 40 patients diagnosed with borderline personality disorder (BPD) with NSSI (N=22), and a
subclinical group of students with NSSI (N=19) was analysed. EMA data was collected by the Sinjur app.
Two classification trees were used as models. For the first tree, training results reported 69,7% of accuracy,
whereas test results reported 59,3% of accuracy, 87,5% of sensitivity and 58,78% of specificity. For the
second tree, training results reported 67,9% of accuracy, whereas test results reported 65,2% of accuracy,
85% of sensitivity and 64,8% of specificity. We concluded that real-time patient monitoring via a mobile app
can be a valuable tool for making technology-based predictions at the individual patient level. This promising
data needs to be built upon in future studies and needs major translation in the everyday clinical practice to
demonstrate its real-world efficacy and later, to be translated to the enterprise world.
1 INTRODUCTION
The advent of machine learning (ML) integrated with
cutting-edge technology has been a breakthrough in
mental health, bringing major clinical improvements
through the whole patient’s journey process,
including diagnosis, symptoms and therapy tracking,
communication between patient and clinical
professional and therapy outcome. Among these,
real-time patient monitoring with ecological
momentary assessment (EMA) data can be an
effective tool to forecast patient’s symptomatology
for specific disorders, such non-suicidal self-injury
(NSSI).
NSSI is defined as the deliberate intention of
harming one own’s body without wanting to engage
in a suicidal act (Zetterqvist, 2015). In the last decade,
NSSI has been recognised as a significant psychiatric
phenomenon, and it has been inserted in the latest
version of the DSM V as a “new condition for further
study” as well insa cross-pathology symptom which
has increased especially during the COVID-19
pandemic. Literature on NSSI has provided evidence
of the key risk factors which predict NSSI, including
perceived social support throughout adolescence,
depressogenic cognitions (Wolff et al., 2013) and
most importantly, emotion dysregulation (Wolff et
al., 2019). EMA studies have directly investigated
interpersonal functions in individuals with NSS. In
this regard, a recent study conducted Briones-
Buixassa et al. (2021) utilised EMA data to
investigate the associations between decentering as a
moderator for NSSI protection and engagement as
well as momentary negative affect, captured real-time
through EMA data and NSSI.
Although emerging research has provided
evidence of relevant variables which contribute to
engagement in NSSI, such as the aforementioned
linkages between decentring measures, negative
affect and NSS; no studies have shown the
278
Capra, C., Marti-Puig, P., Moreno, D., Llunas, L., Nicolaou, S., Schmidt, C. and Solé-Casals, J.
Preliminary Results on the Use of Classification Trees to Predict Non-suicidal Self-injury with Data Collected through a Mobile App.
DOI: 10.5220/0010978500003123
In Proceedings of the 15th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2022) - Volume 4: BIOSIGNALS, pages 278-282
ISBN: 978-989-758-552-4; ISSN: 2184-4305
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

importance of computational methodologies
integrated with ground-breaking technology to
forecast relapse in symptomatology in everyday
clinical practice. Up to date, no research has applied
ML techniques to EMA, in order to predict and
prevent real-time NSSI. Thus, we aimed at expanding
upon Briones-Buixassa et al. (2021) study and apply
classifier analysis to forecast NSSI symptomatology
to provide evidence of its implication in everyday
clinical practice and the usefulness of digital
platforms for specific mental health disorders for
remote interventions.
2 METHODS
2.1 Participants
A database of 64 adult patients, ranging from 18 and
33 years and diagnosed with borderline personality
disorder (BPD) with NSSI (N=22), and a subclinical
group of university students with NSSI (N=19) was
analysed. The database was comprised of three main
groups divided as the following: subjects who
reported NSSI (≥ 5 NSSI events in the previous 12
months), including a) a subclinical group of college
students (STD group; N = 19) and b) a clinical group
of BPD patients (BPD group; N = 22). The subgroup
of college students was not undergoing any type of
psychological treatment at the time of the study and
underwent the Structured Clinical Interview for Axis
II personality disorders (SCID-II) to exclude any
BPD diagnosis.
2.2 Materials
2.2.1 Sinjur App
The Sinjur app was developed for the purpose of this
study. Sinjur app aims to help patients suffering from
NSSI through system based on cognitive behavioural
therapy. The app collects EMA data based on
Experience Sampling Method (ESM), through three
main sections, including “emotions”, “activity diary”
and “self-injuries”. The app was configured to send
participants reminder notifications 3 times a day to
engage in the app and register data.
2.2.2 EMA Data
For this study, we focused on emotions only. More
specifically, negative, and positive affect were
considered. Participants were asked to provide their
emotional states by choosing through a list of
emotions presented in the app, including happy,
frustrated, guilty, sad, angry, relaxed, and worried.
All these emotions are listed in Table 1, together with
the code used for each of them in the classification
mode. Following to this, participants were also asked
to rate their emotions’ intensity by choosing between
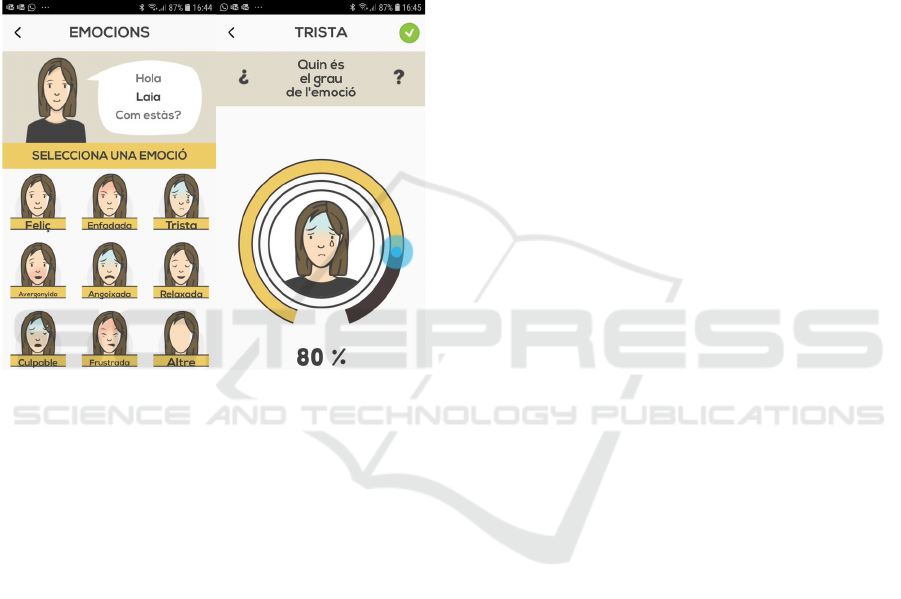
a range from 0 to 100. Figure 1, on the left, shows the
screenshot of the application with the list of emotions,
while on the right shows a screenshot detailing how
to report the patient's chosen emotion rating. For each
data registration, number of times of engagement in
NSSI was asked, as well as method of NSSI,
including burning and cutting. If participants engaged
in NSSI they were asked to indicate their emotion
after the NSSI and its intensity.
Table 1: List of features collected with the app, together
with the code used in the classification trees.
Emotion (original name in Catalan) Feature
code
Happy (feliç)
f
1
Sad (trista)
f
2
Embarrassed (avergonyida)
f
3
Distressed (angoixada)
f
4
Relaxed (relaxada)
f
5
Guilty (culpable)
f
6
Frustrated (frustrada)
f
7
# binge eating
f
8
# self-harm thoughts
f
9
# times taking drugs
f
10
# times having sex
f
11
# arguments with others
f
12
2.3 Procedures
Firstly, all participants underwent a demographical,
clinical and NSSI screening. Only subjects who
reported more than 5 NSSI acts in the previous 12
months were taken into account to participate in the
study, among which 19 out of 180 subjects qualified
for the current study. All the participants of the three
groups (STD, BPD, and HC groups) were asked to
complete both a clinical and a self-report assessment.
At the same time, they were given instructions on
how to use the Sinjur app and reminded to register
relevant data anytime they received a notification, as
well as every time they engaged in self-injury.
2.4 Machine Learning Model
Tree-structured classification techniques have been
widely used in medical applications. The reason for
Preliminary Results on the Use of Classification Trees to Predict Non-suicidal Self-injury with Data Collected through a Mobile App
279
this is the ease of interpretation and applicability
provided by these models. Therefore, the
classification model used in this work will be based
on a CART tree (Breiman, Friedman, Olshen &
Stone, 2017) (Lewis, 2000). A decision tree is a way
of representing the knowledge obtained in an
inductive learning process. It is a supervised
classification method, which means that it uses
already labelled data from which knowledge will be
extracted. The feature space is subdivided by using a
set of conditions, and the resulting structure is the
tree.
Figure 1: On the left, a screenshot with the list of emotions
to report to the system. On the right, a detail on how to
report the grade of the emotion by means of a sliding button
(the text in the app is in Catalan).
A tree consists of nodes of two types, internal nodes,
and end nodes (also known as leaves). Each internal
node contains a question about a particular feature f
of the type “Is f greater than or equal to a threshold or
not?”, and provides two children (subdivision), one
for each possible answer, depending on whether f ≥
threshold or f < threshold. On the other hand, end
nodes are those that are assigned to a single class at
the bottom of the tree, so there are no further
subdivisions from them.
The construction of a tree is the learning stage of
the method and consists in analysing a set of available
features (f
1
,f
2
,…,f
n
) and obtaining logical rules
adapted to the already available labelled examples. In
our case, the features are a set of 12 feelings or
answers to simple questions, as explained in Section
2.2.2, and the following classes: class 1
(corresponding to positive NSSI) and class zero
(corresponding to negative NSSI).
The construction process is recursive and starts by
considering all possible partitions and taking the one
with the best separation. Then the optimal
partitioning is applied, and the previous step is
repeated to all the internal nodes. A key point in this
process is how the best separation is defined. In a
general way, the best separation is the one that divides
the data into groups such that there is a dominant
class. To measure that, the algorithm in our
experiments uses the Gini diversity index, which is
one of the possible impurity measures (Yuan, Wu &
Zhang, 2021). The Gini diversity index is a measure
of how often a randomly chosen item from a set
would be incorrectly labelled if it were randomly
labelled according to the distribution of labels in the
subset. The Gini impurity can be calculated by
summing the probability of each item being chosen
multiplied by the probability of an error in the
categorization of that item (1). It reaches its minimum
(zero) when all cases in the node correspond to a
single target category.
𝐺
𝑓
=𝑃
(
𝑓
<
𝑗
)
𝐺(𝑐|
𝑓
<
𝑗
)+𝑃
(
𝑓
≥
𝑗
)
(1
)
where:
𝐺𝑐
𝑓
=𝑃𝑐=1
𝑓
𝑃𝑐 ≠ 1
𝑓
+𝑃𝑐=−1𝑓
𝑃𝑐 ≠ −1𝑓
=1−𝑃(𝑐
|
𝑓
)
(2
)
Thus, the importance of the characteristics is
established. The first-level characteristics are the
most important. Similarly, the lower-level features
are the less important ones. If the algorithm keeps
some of the available features out of the tree
definition, it means that these features are irrelevant
to the classification model. And this is one of the most
interesting capabilities of trees, because it means that
the model can be interpreted in terms of the features
used in it and the features discarded by it. Hence, by
analysing the structure of the tree we can infer the
interest of each of the chosen explanatory variables.
3 RESULTS
Two different experiments were carried out. In the
first case, a very small tree was used to elucidate the
most important features. Then, a second, larger tree
was used to improve the previous result without
losing the interpretability of the model. In all cases,
the database was balanced by dividing the positive
BIOSIGNALS 2022 - 15th International Conference on Bio-inspired Systems and Signal Processing
280
class into two halves, one for the training step and one
for the test step. Then, for the negative class, the same
number of examples as the positive class were
randomly taken to train the model, while all
remaining samples were used in the testing step.
Therefore, the training was performed with 50% of
the samples from one class and 50% of the samples
from the other class.
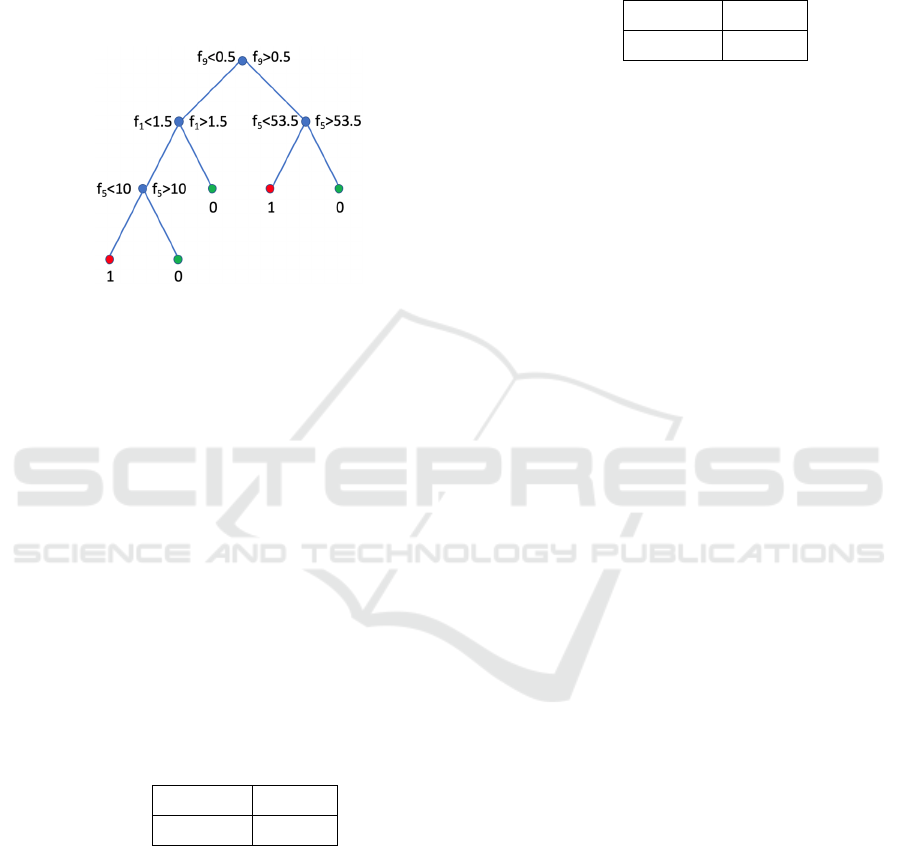
Figure 2: Coarse classification tree. The algorithm only
selected three different features to model the data. See
Appendix 1 for the coding of the features.
However, all the remaining samples from both classes
were used in the test, so it contained many more
samples from the negative class.
3.1 Coarse Tree
The coarse tree was defined to have a maximum
number of 4 splits, and the split criterion to be the
Gini's diversity index. The accuracy for the training
step was 67.9%, and for the test step, 59.3%. Figure 2
depicts the final tree derived from the model.
The confusion matrix is shown in Table 2. From
it we can calculate the sensitivity or true positive rate,
and the specificity or true negative rate, which are
87.5% and 58.78% respectively
Table 2: Confusion matrix for test step of the coarse tree.
True class
0 1185 831
1 5 35
0 1
Predicted class
3.2 Larger Tree
The second tree was defined to have a maximum
number of 20 splits. Again, the split criterion was the
Gini's diversity index. The accuracy for the training
step remained the same, at 67.9%, but for the test step,
it increased to 65.2%.
The confusion matrix is shown in Table 3. The
new values of sensitivity and specificity are 85% and
64.8% respectively, and the obtained tree is depicted
in Figure 3.
Table 3: Confusion matrix for test step of the larger tree.
True class
0 1307 709
1 6 34
0 1
Predicted class
4 DISCUSSION
The two models selected the number of NSSI
thoughts (f
9
) as the most important feature to predict
non-suicidal self-injury. This is something expected
but also confirmed by our experiments. When not
having NSSI thoughts, subjects tended to report
positive affect, and more specifically tended to be
more relaxed (f
5
) and happier (f
1
). These are the next
most important features for the models, indicating
that being relaxed or happier will, to certain degree,
impede the subject to cause a self-injury.
The first model only relies in these emotions,
while the second model, having the same structure of
the first one for the first leaves, includes the emotion
of distress (f
4
) and the number of times having sex
(f
11
) as important features. When participants
reported less happiness, they tended to engage in
NSSI and report consequent feelings of distress. In
this case, subjects tended to engage in multiple sexual
intercourses, as a possible indicator of coping
mechanism to deal with NSSI thoughts. The second
model helped us to decrease the number of false
positives, from 831 to 709, while maintaining almost
the same false negatives from 5 to 6, as can be seen
in Table 1 and Table 2.
Despite the accuracy in the training was far from
perfect, it’s important to note that the prediction (test
step) obtained a better result, even if the model was
trained with only 50% of the samples of the
underrepresented class. It’s also interesting to note
that the sensitivity or true positive rate is equal or
higher than 85% in both models. This means that the
model is able to predict when the subject will cause a
self-injury with an 85% of success, only using the
information collected by the app. The fact that the
specificity or true negative rate is lower (about 60%
for the coarse tree and about 65% for the larger tree)
it’s not an important issue because in that case the
model is predicting a self-injury that will probably not
Preliminary Results on the Use of Classification Trees to Predict Non-suicidal Self-injury with Data Collected through a Mobile App
281

occur. As the app will be more responsive in these
cases, we are also reducing the likelihood of self-
harm.
Figure 3: Larger classification tree. Now the algorithm
selected five different features to model the data. See Table
1 for the decoding of the features.
Nonetheless, we suggest that a more detailed
exploration of results should be carried out and that,
further research should apply these models to bigger
databases to obtain more accurate results, especially
if aiming at integrating them with cutting-edge
technology. Also new classification models should be
addressed, such as neural networks or SVM.
However, although recent research has focused on
the usefulness of apps for direct patient’s support
(Torous 2021), little attention has given to digital
platforms for clinical support to automatise prompt
interventions through the app itself. In our study, we
provide evidence that EMA data can be a valuable
data for real-time prediction of NSSI as well as
knowing whether the patients are about to engage in
disruptive coping mechanism to deal with NSSI, such
as having several sexual intercourses, as reported. In
this case, we propose that apps like Sinjur may help
in reducing the risk of self-injurious thoughts and
subsequent behaviours.
5 CONCLUSIONS
Giving the growing yet little research in the field of
digital mental health, our findings shade a light on the
great advantage of ML applications to predict real-
time NSSI at the individual patient level.
Nonetheless, this promising data needs to be built
upon in future studies and needs major translation in
the everyday clinical practice to demonstrate its real-
world efficacy and later, to be translated to the
enterprise world.
ACKNOWLEDGEMENTS
We thank the Agency for Management of University
and Research Grants (AGAUR) of the Catalan
Government for their support to Chiara Capra
(Industrial Doctorate programme).
REFERENCES
Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J.
(2017). Classification and regression trees. Routledge.
Briones-Buixassa, L., Alí, I., Schmidt, C., Nicolaou, S.,
Pascual, J.C., Soler, J., & Vega, D. (2021). Predicting
Non-Suicidal Self-Injury in Young Adults with and
without Borderline Personality Disorder: A Multilevel
Approach Combining Ecological Momentary
Assessment and Self-Report Measures. Psychiatric
Quarterly, 92(22).
Lewis, R. J. (2000). An introduction to classification and
regression tree (CART) analysis. In Annual meeting of
the society for academic emergency medicine in San
Francisco, California (Vol. 14).
Snir, A., Rafaeli, E., Gadassi, R., Berenson, K., & Downey,
G. (2015). Explicit and inferred motives for nonsuicidal
selfinjurious acts and urges in borderline and avoidant
personality disorders. Personal Disord, 6(3), 267–77.
Turner, B.J., Cobb, R.J., Gratz, K.L., Chapman, A.L.
(2016). The role of interpersonal conflict and perceived
social support in nonsuicidal self-injury in daily life. J
Abnorm Psychol, 125(4), 588-98.
John Torous, Sandra Bucci, Imogen H. Bell, Lars V.
Kessing, Maria Faurholt-Jepsen, … & Firth, J. (2021).
The growing field of digital psychiatry: current
evidence and the future of apps, social media, chatbots,
and virtual reality. World Psychiatry, 20, 3.
Wolff, J.C., Fraizer, A., Esposito-Smythers, C., Burke, T.,
Sloan, E., & Spirito. A. (2013). Cognitive and Social
Factors Associated with NSSI and Suicide Attempts in
Psychiatrically Hospitalized Adolescents. J Abnorm
Child Psychol., 41(6): 1005–1013.
Wolff, J.C., Thompson, E., Thomas, S.A., Nesi, J., Bettis,
A.H., & Ransford, B. (2019). Emotion dysregulation
and nonsuicidal self-injury: a systematic review and
meta-analysis. Eur Psychiatry, 59, 25-36.
Yuan, Y., Wu, L. & Zhang, X. (2021). Gini-Impurity Index
Analysis. IEEE Transactions on Information Forensics
and Security, vol. 16, pp. 3154-3169
Zetterqvist, M. (2015). The DSM-5 diagnosis of
nonsuicidal self-injury disorder: a review of the
empirical literature. Child Adolesc Psychiatry Ment
Health, 9, 31.
BIOSIGNALS 2022 - 15th International Conference on Bio-inspired Systems and Signal Processing
282
