
Unsupervised Image Decomposition with Phase-Correlation Networks
Angel Villar-Corrales
a
and Sven Behnke
b
Autonomous Intelligent Systems, University of Bonn, Germany
Keywords:
Object-Centric Representation Learning, Unsupervised Image Decomposition, Frequency-Domain Neural
Networks, Phase Correlation.
Abstract:
The ability to decompose scenes into their object components is a desired property for autonomous agents,
allowing them to reason and act in their surroundings. Recently, different methods have been proposed to
learn object-centric representations from data in an unsupervised manner. These methods often rely on latent
representations learned by deep neural networks, hence requiring high computational costs and large amounts
of curated data. Such models are also difficult to interpret. To address these challenges, we propose the Phase-
Correlation Decomposition Network (PCDNet), a novel model that decomposes a scene into its object compo-
nents, which are represented as transformed versions of a set of learned object prototypes. The core building
block in PCDNet is the Phase-Correlation Cell (PC Cell), which exploits the frequency-domain representation
of the images in order to estimate the transformation between an object prototype and its transformed version
in the image. In our experiments, we show how PCDNet outperforms state-of-the-art methods for unsuper-
vised object discovery and segmentation on simple benchmark datasets and on more challenging data, while
using a small number of learnable parameters and being fully interpretable. Code and models to reproduce
our experiments can be found in https://github.com/AIS-Bonn/Unsupervised-Decomposition-PCDNet.
1 INTRODUCTION
Humans understand the world by decomposing
scenes into objects that can interact with each other.
Analogously, autonomous systems’ reasoning and
scene understanding capabilities could benefit from
decomposing scenes into objects and modeling each
of these independently. This approach has been
proven beneficial to perform a wide variety of com-
puter vision tasks without explicit supervision, in-
cluding unsupervised object detection (Eslami et al.,
2016), future frame prediction (Weis et al., 2021; Gr-
eff et al., 2019), and object tracking (He et al., 2019;
Veerapaneni et al., 2020).
Recent works propose extracting object-centric
representations without the need for explicit super-
vision through the use of deep variational auto-
encoders (Kingma and Welling, 2014) (VAEs) with
spatial attention mechanisms (Burgess et al., 2019;
Crawford and Pineau, 2019). However, training these
models often presents several difficulties, such as long
training times, requiring a large number of trainable
parameters, or the need for large curated datasets.
a
https://orcid.org/0000-0001-5805-2098
b
https://orcid.org/0000-0002-5040-7525
Furthermore, these methods suffer from the inherent
lack of interpretability which is characteristic of deep
neural networks (DNNs).
To address the aforementioned issues, we propose
a novel image decomposition framework: the Phase-
Correlation Decomposition Network (PCDNet). Our
method assumes that an image is formed as an ar-
rangement of multiple objects, each belonging to one
of a finite number of different classes. Following this
assumption, PCDNet decomposes an image into its
object components, which are represented as trans-
formed versions of a set of learned object prototypes.
The core building block of the PCDNet frame-
work is the Phase Correlation Cell (PC Cell). This
is a differentiable module that exploits the frequency-
domain representations of an image and a prototype to
estimate the transformation parameters that best align
a prototype to its corresponding object in the image.
The PC Cell localizes the object prototype in the im-
age by applying the phase-correlation method (Alba
et al., 2012), i.e., finding the peaks in the cross-
correlation matrix between the input image and the
prototype. Then, the PC Cell aligns the prototype to
its corresponding object in the image by performing
the estimated phase shift in the frequency domain.
224
Villar-Corrales, A. and Behnke, S.
Unsupervised Image Decomposition with Phase-Correlation Networks.
DOI: 10.5220/0010919100003124
In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2022) - Volume 4: VISAPP, pages
224-235
ISBN: 978-989-758-555-5; ISSN: 2184-4321
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
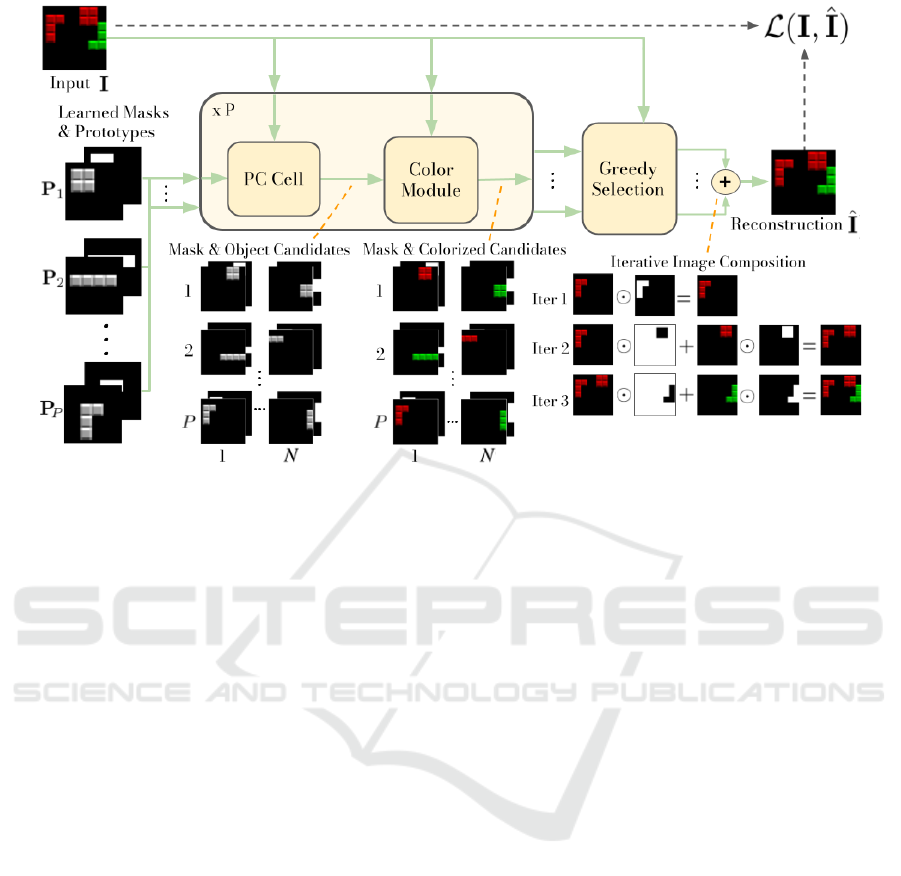
Figure 1: PCDNet decomposition framework. First, the Phase Correlation (PC) Cell estimates the N translation parameters
that best align each learned prototype to the objects in the image, and uses them to obtain (P × N) object and mask candi-
dates. Second, the color module assigns a color to each of the transformed prototypes. Finally, a greedy selection algorithm
reconstructs the input image by iteratively combining the colorized object candidates that minimize the reconstruction error.
PCDNet is trained by first decomposing an image
into its object components, and then reconstructing
the input by recombining the estimated object com-
ponents following the “dead leaves” model approach,
i.e., as a superposition of different objects. The strong
inductive biases introduced by the network structure
allow our method to learn fully interpretable proto-
typical object-centric representations without any ex-
ternal supervision while keeping the number of learn-
able parameters small. Furthermore, our method also
disentangles the position and color of each object in a
human-interpretable manner.
In summary, the contributions of our work are as
follows:
• We propose the PCDNet model, which decom-
poses an image into its object components, which
are represented as transformed versions of a set of
learned object prototypes.
• Our proposed model exploits the frequency-
domain representation of images so as to disentan-
gle object appearance, position, and color without
the need for any external supervision.
• Our experimental results show that our proposed
framework outperforms recent methods for joined
unsupervised object discovery, image decompo-
sition, and segmentation on benchmark datasets,
while significantly reducing the number of learn-
able parameters, allowing for high throughput,
and maintaining interpretability.
2 RELATED WORK
2.1 Object-Centric Representation
Learning
The field of representation learning (Bengio et al.,
2013) has seen much attention in the last decade, giv-
ing rise to great advances in learning hierarchical rep-
resentations (Paschalidou et al., 2020; Stanic et al.,
2021) or in disentangling the underlying factors of
variation in the data (Locatello et al., 2019; Burgess
et al., 2018). Despite these successes, these methods
often rely on learning representations at a scene level,
rather than learning in an object-centric manner, i.e.,
simultaneously learning representations that address
multiple, possibly repeating, objects.
In the last few years, several methods have been
proposed to perform object-centric image decompo-
sition in an unsupervised manner.
A first approach to object-centric decomposition
combines VAEs with attention mechanisms to decom-
pose a scene into object-centric representations. The
object representations are then decoded to reconstruct
the input image. These methods can be further di-
Unsupervised Image Decomposition with Phase-Correlation Networks
225

vided into two different groups depending on the class
of latent representations used. On the one hand, some
methods (Eslami et al., 2016; Kosiorek et al., 2018;
Stanic et al., 2021; He et al., 2019) explicitly en-
code the input into factored latent variables, which
represent specific properties such as appearance, po-
sition, and presence. On the other hand, other mod-
els (Burgess et al., 2019; Weis et al., 2021; Locatello
et al., 2020; Goyal et al., 2020) decompose the image
into unconstrained per-object latent representations.
Recently, several proposed methods (Greff et al.,
2019; Engelcke et al., 2020; Engelcke et al., 2021;
Veerapaneni et al., 2020; Lin et al., 2020) use param-
eterized spatial mixture models with variational infer-
ence to decode object-centric latent variables.
Despite these recent advances in unsupervised
object-centric learning, most existing methods rely on
DNNs and attention mechanisms to encode the input
images into latent representations, hence requiring a
large number of learnable parameters and high com-
putational costs. Furthermore, these approaches suf-
fer from the inherent lack of interpretability charac-
teristic of DNNs. Our proposed method exploits the
strong inductive biases introduced by our scene com-
position model in order to decompose an image into
object-centric components without the need for deep
encoders, using only a small number of learnable pa-
rameters, and being fully interpretable.
2.2 Layered Models
The idea of representing an image as a superposition
of different layers has been studied since the introduc-
tion of the “dead leaves” model by (Matheron, 1968).
This model has been extended to handle natural im-
ages and scale-invariant representations (Lee et al.,
2001), as well as video sequences (Jojic and Frey,
2001). More recently, several works (Yang et al.,
2017; Lin et al., 2018; Zhang et al., 2020; Aksoy
et al., 2017; Arandjelovi
´
c and Zisserman, 2019; Sbai
et al., 2020) combine deep neural networks and ideas
from layered image formation for different generative
tasks, such as editing or image composition. How-
ever, the aforementioned approaches are limited to
foreground/background layered decomposition, or to
represent the images with a small number of layers.
The work most similar to ours was recently pre-
sented by (Monnier et al., 2021). The authors propose
a model to decompose an image into overlapping lay-
ers, each containing an object from a predefined set
of categories. The object layers are obtained with a
cascade of spatial transformer networks, which learn
transformations that align object sprites to the input
image.
While we also follow a layered image formation,
our PCDNet model is not limited to a small number
of layers, hence being able to represent scenes with
multiple objects. PCDNet represents each object in
its own layer, and uses learned alpha masks to model
occlusions and superposition between layers.
2.3 Frequency-domain Neural
Networks
Signal analysis and manipulation in the frequency do-
main is one of the most widely used tools in the field
of signal processing (Proakis and Manolakis, 2004).
However, frequency-domain methods are not so de-
veloped for solving computer vision tasks with neu-
ral networks. They mostly focus on specific applica-
tions such as compression (Xu et al., 2020; Gueguen
et al., 2018), image super-resolution and denois-
ing (Fritsche et al., 2019; Villar-Corrales et al., 2021;
Kumar et al., 2017), or accelerating the calculation of
convolutions (Mathieu et al., 2014; Ko et al., 2017).
In recent years, a particular family of frequency-
domain neural networks—the phase-correlation net-
works—has received interest from the research com-
munity and has shown promise for tasks such as fu-
ture frame prediction (Farazi et al., 2021; Wolter
et al., 2020) and motion segmentation (Farazi and
Behnke, 2020). Phase-correlation networks compute
normalized cross-correlations in the frequency do-
main and operate with the phase of complex signals in
order to estimate motion and transformation parame-
ters between consecutive frames, which can be used
to obtain accurate future frame predictions requir-
ing few learnable parameters. Despite these recent
successes, phase-correlation networks remain unex-
plored beyond the tasks of video prediction and mo-
tion estimation. Our proposed method presents a first
attempt at applying phase correlation networks for
the tasks of scene decomposition and unsupervised
object-centric representation learning.
3 PHASE-CORRELATION
DECOMPOSITION NETWORK
In this section, we present our image decomposition
model: PCDNet. Given an input image I, PCDNet
aims at its decomposition into N independent objects
O = {O
1
,O
2
,...,O
N
}. In this work, we assume that
these objects belong to one out of a finite number P of
classes, and that there is a known upper bound to the
total number of objects present in an image (N
max
).
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
226
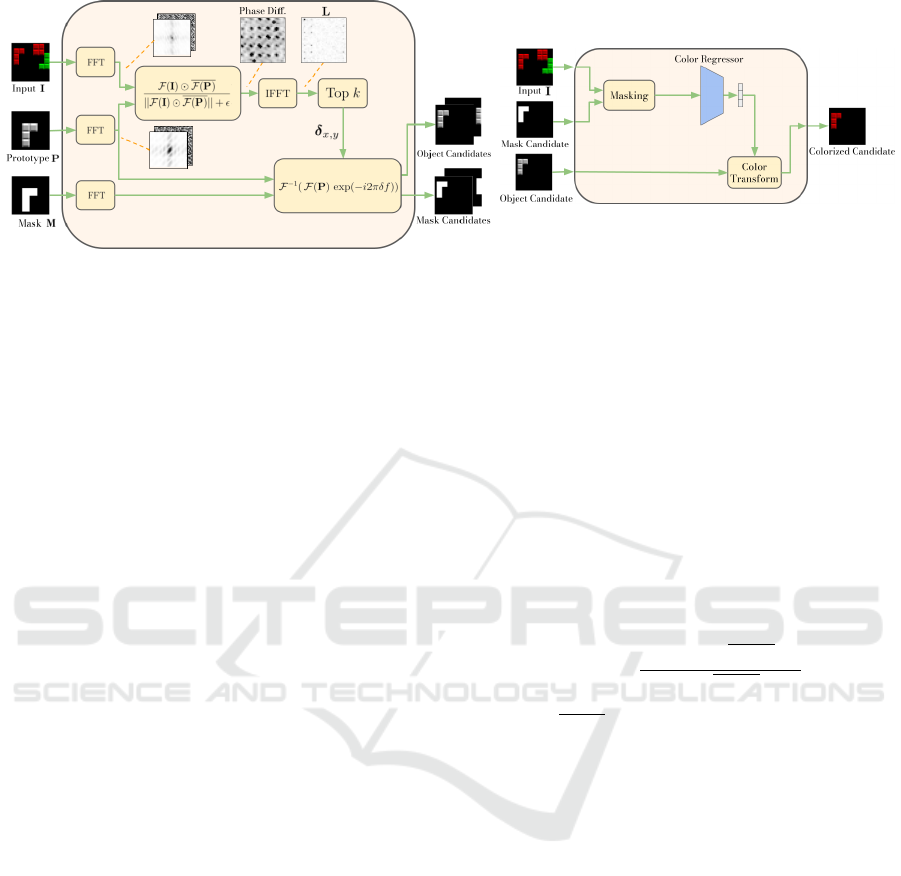
(a) PC Cell
(b) Color Module
Figure 2: (a): Inner structure of the PC Cell. First, the translation parameters are estimated by finding the correlation peaks
between the object prototype and the input image. Second, the prototype is shifted by phase shifting in the frequency domain.
(b): The Color Module estimates color parameters from the input and aligns the color channels of a translated object prototype.
Inspired by recent works in prototypical learning
and clustering (Monnier et al., 2020), we design our
model such that the objects in the image can be repre-
sented as transformed versions of a finite set of object
prototypes P = {P
1
,P
2
,...,P
P
}. Each object proto-
type P
i
∈ R
H,W
is learned along with a correspond-
ing alpha mask M
i
∈ R
H,W
, which is used to model
occlusions and superposition of objects. Throughout
this work, we consider object prototypes to be in gray-
scale and of smaller size than the input image. PCD-
Net simultaneously learns suitable object prototypes,
alpha masks and transformation parameters in order
to accurately decompose an image into object-centric
components.
An overview of the PCDNet framework is dis-
played in Figure 1. First, the PC Cell (Section 3.1) es-
timates the candidate transformation parameters that
best align the object prototypes to the objects in the
image, and generates object candidates based on the
estimated parameters. Second, a Color Module (Sec-
tion 3.2) transforms the object candidates by applying
a learned color transformation. Finally, a greedy se-
lection algorithm (Section 3.3) reconstructs the input
image by iteratively selecting the object candidates
that minimize the reconstruction error.
3.1 Phase-correlation Cell
The first module of our image decomposition frame-
work is the PC Cell, as depicted in Figure 1. This
module first estimates the regions of an image where a
particular object might be located, and then shifts the
prototype to the estimated object location. Inspired
by traditional image registration methods (Reddy and
Chatterji, 1996; Alba et al., 2012), we adopt an ap-
proach based on phase correlation. This method esti-
mates the relative displacement between two images
by computing the normalized cross-correlation in the
frequency domain.
Given an image I and an object prototype P, the
PC Cell first transforms both inputs into the frequency
domain using the Fast Fourier Transform (FFT, F ).
Second, it computes the phase differences between
the frequency representations of image and prototype,
which can be efficiently computed as an element-wise
division in the frequency domain. Then, a localization
matrix L is found by applying the inverse FFT (F
−1
)
on the normalized phase differences:
L = F
−1
F (I) F (P)
||F (I) F (P)|| + ε
, (1)
where F (P) denotes the complex conjugate of
F (P), is the Hadamard product, || · || is the modu-
lus operator, and ε is a small constant to avoid division
by zero. Finally, the estimated relative pixel displace-
ment (δ
x,y
= (δ
x
,δ
y
)) can then be found by locating
the correlation peak in L:
δ
x,y
= arg max(L) . (2)
In practical scenarios, we do not know in advance
which objects are present in the image or whether
there are more than one objects from the same class.
To account for this uncertainty, we pick the largest
N
max
correlation values from L and consider them as
candidate locations for an object.
Finally, given the estimated translation parame-
ters, the PC Cell relies on the Fourier shift theorem
to align the object prototypes and the corresponding
alpha masks to the objects in the image. Given the
translation parameters δ
x
and δ
y
, an object prototype
is shifted using
T = F
−1
(F (P)exp(−i2π(δ
x
f
x
+ δ
y
f
y
)), (3)
Unsupervised Image Decomposition with Phase-Correlation Networks
227

where f
x
and f
y
denote the frequencies along the
horizontal and vertical directions, respectively.
Figure 2a depicts the inner structure of the PC
Cell, illustrating each of the phase correlation steps
and displaying some intermediate representations, in-
cluding the magnitude and phase components of each
input, the normalized cross-correlation matrix, and
the localization matrix L.
3.2 Color Module
The PC Cell module outputs translated versions of
the object prototypes and their corresponding alpha
masks. However, these translated templates need not
match the color of the object represented in the image.
This issue is solved by the Color Module, which is il-
lustrated in Figure 2b. It learns color parameters from
the input image, and transforms the translated proto-
types according to the estimated color parameters.
Given the input image and the translated object
prototype and mask, the color module first obtains a
masked version of the image containing only the rele-
vant object. This is achieved through an element-wise
product of the image with the translated alpha mask.
The masked object is fed to a neural network, which
learns the color parameters (one for gray-scale and
three for RGB images). Finally, these learned param-
eters are applied to the translated object prototypes
with a channel-wise affine transform. Further details
about the color module are given in Appendix 5.
3.3 Greedy Selection
The PC Cell and color modules produce T = N
max
×
P translated and colorized candidate objects (T =
{T
1
,...,T
T
}) and their corresponding translated alpha
masks ({M
1
,...,M
T
}). The final module of the PCD-
Net framework selects, among all candidates, the ob-
jects that minimize the reconstruction error with re-
spect to the input image.
The number of possible object combinations
grows exponentially with the maximum number of
objects and the number of object candidates (T
N
max
),
which quickly makes it infeasible to evaluate all pos-
sible combinations. Therefore, similarly to (Monnier
et al., 2021), we propose a greedy algorithm that se-
lects in a sequential manner the objects that minimize
the reconstruction loss. The greedy nature of the al-
gorithm reduces the number of possible object com-
binations to T × N
max
, hence scaling to images with a
large number of objects and prototypes.
The greedy object selection algorithm operates as
follows. At the first iteration, we select the object that
minimizes the reconstruction loss with respect to the
input, and add it to the list of selected objects. Then,
for each subsequent iteration, we greedily select the
object that, combined with the previously selected
ones, minimizes the reconstruction error. This error
is computed using Equation (4), which corresponds
to the mean squared error between the input image (I)
and a combination of the selected candidates (G(T )).
The objects are combined recursively in an over-
lapping manner, as shown in Equation (5), so that the
first selected object (T
1
) corresponds to the one clos-
est to the viewer, whereas the last selected object (T
N
)
is located the furthest from the viewer:
E(I,T ) = ||I − G(T )||
2
2
(4)
G(T ) = T
i+1
(1 − M
i
) + T
i
M
i
∀i ∈ {N − 1, ...,1}. (5)
An example of this image composition is dis-
played in Figure 1. This reconstruction approach in-
herently models relative depths, allowing for a simple,
yet effective, modeling of occlusions between objects.
3.4 Training and Implementation
Details
We train PCDNet in an end-to-end manner to recon-
struct an image as a combination of transformed ob-
ject prototypes. The training is performed by mini-
mizing the reconstruction error (L
MSE
), while regu-
larizing the prototypes to with respect to the `
1
norm
(L
L1
), and enforcing smooth alpha masks with a total
variation regularizer (Rudin and Osher, 1994) (L
TV
).
Specifically, we minimize the following loss function:
L = L
MSE
+ λ
L1
L
L1
+ λ
TV
L
TV
, (6)
L
MSE
= ||I − G(T
0
)||
2
2
, (7)
L
L1
=
1
P
∑
P∈P
||P||
1
, (8)
L
TV
=
1
P
∑
M∈M
∑
i, j
|M
i+1, j
− M
i, j
| + |M
i, j+1
− M
i, j
|,
(9)
where T
0
are the object candidates selected by
the greedy algorithm, P are the learned object pro-
totypes, and M the corresponding alpha masks. Min-
imizing Equation (6) decreases the reconstruction er-
ror between the combination of selected candidates
(G(T
0
)) and the input image while keeping the proto-
types compact, and the alpha masks smooth.
In our experiments, we noticed that the initializa-
tion and update strategy of the object prototypes is
of paramount importance for the correct performance
of the PCDNet model. The prototypes are initialized
with a small constant value (e.g., 0.2), whereas the
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
228

Table 1: Object discovery evaluation results on the Tetrominoes dataset. PCDNet outperforms SOTA methods, while using
a small number of learned parameters. Moreover, our PCDNet has the highest throughput out of all evaluated methods. For
each metric, the best result is highlighted in boldface, whereas the second best is underlined.
Model ARI (%) ↑ Params ↓ Imgs/s ↑
Slot MLP (Locatello et al., 2020) 35.1 – –
Slot Attention (Locatello et al., 2020) 99.5 229,188 18.36
ULID (Monnier et al., 2021) 99.6 659,755 52.31
IODINE (Greff et al., 2019) 99.2 408,036 16.64
PCDNet (ours) 99.7 28,130 58.96
Figure 3: Object prototypes (top) and alpha masks (bottom)
learned on the Tetrominoes dataset. Our model is able to
discover in an unsupervised manner all 19 pieces.
center pixel is assigned an initial value of one, enforc-
ing the prototypes to emerge centered in the frame.
During the first training iterations, we notice that
the greedy algorithm selects some prototypes with a
higher frequency that others, hence learning much
faster. In practice, this prevents other prototypes from
learning relevant object representations, since they are
not updated often enough. To reduce the impact of un-
even prototype discovery, we add, with a certain prob-
ability, some uniform random noise to the prototypes
during the first training iterations. This prevents the
greedy algorithm from always selecting, and hence
updating, the same object prototypes and masks.
In datasets with a background, we add a special
prototype to model a static background. In these
cases, the input images are reconstructed by overlap-
ping the objects selected by the greedy algorithm on
top of the background prototype. This background
prototype is initialized by averaging all training im-
ages, and its values are refined during training.
4 EXPERIMENTAL RESULTS
In this section, we quantitatively and qualitatively
evaluate our PCDNet framework for the tasks of unsu-
pervised object discovery and segmentation. PCDNet
is implemented in Python using the PyTorch frame-
work (Paszke et al., 2017). A detailed report of the
hyper-parameters used is given in Appendix 5.
4.1 Tetrominoes Dataset
We evaluate PCDNet for image decomposition and
object discovery on the Tetrominoes dataset (Greff
et al., 2019). This dataset contains 60.000 training
images and 320 test images of size 35×35, each com-
posed of three non-overlapping Tetris-like sprites over
a black background. The sprites belong to one out of
19 configurations and have one of six random colors.
Figure 3 displays the 19 learned object prototypes
and their corresponding alpha masks from the Tetro-
minoes dataset. We clearly observe how PCDNet ac-
curately discovers the shape of the different pieces
and their tiled texture.
Figure 4 depicts qualitative results for unsuper-
vised object detection and segmentation. In the first
three rows, PCDNet successfully decomposes the im-
ages into their object components and precisely seg-
ments the objects into semantic and instance masks.
The bottom row shows an example in which the
greedy selection algorithm leads to a failure case.
For a fair quantitative comparison with previous
works, we evaluate our PCDNet model for object seg-
mentation using the Adjusted Rand Index (Hubert and
Arabie, 1985) (ARI) on the ground truth foreground
pixels. ARI is a clustering metric that measures the
similarity between two set assignments, ignoring la-
bel permutations, and ranges from 0 (random assign-
ment) to 1 (perfect clustering). We compare the per-
formance of our approach with several existing meth-
ods: Slot MLP and Slot Attention (Locatello et al.,
2020), IODINE (Greff et al., 2019) and Unsupervised
Layered Image Decomposition (Monnier et al., 2021)
(ULID).
Table 1 summarizes the evaluation results for
object discovery on the Tetrominoes dataset. We
observe that PCDNet outperforms SOTA models,
achieving 99.7% ARI on the Tetrominoes dataset.
PCDNet uses only a small percentage of learnable pa-
rameters compared to other methods (e.g., only 6% of
the parameters from IODINE), and has the highest in-
ference throughput (images/s). Additionally, unlike
Unsupervised Image Decomposition with Phase-Correlation Networks
229

(a)
(b)
(c)
(d)
(e)
(f) (g)
Figure 4: Qualitative decomposition and segmentation results on the Tetrominoes dataset. Last row shows a failure case. (a):
Original image. (b): PCDNet Reconstruction. (c)-(e): Colorized transformed object prototypes. (f): Semantic segmentation
masks. Colors correspond to the prototype frames in Figure 3. (g): Instance segmentation masks.
Figure 5: Object prototypes learned on the Space Invaders
dataset. PCDNet discovers prototypes corresponding to the
different elements from the game, e.g., aliens and ships.
other approaches, PCDNet obtains disentangled rep-
resentations for the object appearance, position, and
color in a human-interpretable manner.
4.2 Space Invaders Dataset
In this experiment, we use replays from humans play-
ing the Atari game Space Invaders, extracted from the
Atari Grand Challenge dataset (Kurin et al., 2017).
PCDNet is trained to decompose the Space Invaders
images into 50 objects, belonging to one of 14 learned
prototypes of size 20 × 20.
Figure 6 depicts a qualitative comparison between
our PCDNet model with SPACE (Lin et al., 2020) and
Slot Attention (Locatello et al., 2020).
Slot Attention achieves an almost perfect recon-
struction of the input image. However, it fails to de-
compose the image into its object components, uni-
formly scattering the object representations across
different slots. In Figure 6 (d) one can observe that
one of the slots simultaneously encodes information
from several different objects. SPACE successfully
decomposes the image into different object compo-
nents, which are recognized as foreground objects.
Nevertheless, the reconstructions appear blurred and
several objects are not correct. PCDNet achieves
the best results among all compared methods. Our
model successfully decomposes the input image into
accurate object-centric representations. Additionally,
PCDNet learns semantic understanding of the objects.
Figure 6 depicts a segmentation of an image from the
Space Invaders dataset. Further qualitative results on
the Space Invaders dataset are reported in Appendix 5.
4.3 NGSIM Dataset
In this third experiment, we apply our PCDNet model
to discover vehicle prototypes from real traffic cam-
era footage from the Next Generation Simulation
(NGSIM) dataset (Alexiadis, 2006). We decompose
each frame into up to 33 different objects, belonging
to one of 30 learned vehicle prototypes.
Figure 7 depicts qualitative results on the NGSIM
dataset. We see how PCDNet is applicable to real-
world data, accurately reconstructing the input image,
while learning prototypes for different types of vehi-
cles. Interestingly, we notice how PCDNet learns the
car shade as part of the prototype. This is a reasonable
observation, since the shades are projected towards
the bottom of the image throughout the whole video.
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
230

Figure 6: Comparison of different object-centric models on the Space Invaders dataset. PCDNet is the only one among
the compared methods which successfully decomposes the image into accurate object components, and that has semantic
knowledge of the objects. The color of each object corresponds to the frame of the corresponding prototype in Figure 5.
Figure 7: Object discovery on the NGSIM dataset. PCDNet learns different vehicle prototypes in an unsupervised manner.
5 CONCLUSION
We proposed PCDNet, a novel image composition
model that decomposes an image, in a fully unsuper-
vised manner, into its object components, which are
represented as transformed versions of a set of learned
object prototypes. PCDNet exploits the frequency-
domain representation of images to estimate the trans-
lation parameters that best align the prototypes to the
objects in the image. The structured network used by
PCDNet allows for an interpretable image decompo-
sition, which disentangles object appearance, position
and color without any external supervision. In our ex-
periments, we show how our proposed model outper-
forms existing methods for unsupervised object dis-
Unsupervised Image Decomposition with Phase-Correlation Networks
231

covery and segmentation on a benchmark synthetic
dataset, while significantly reducing the number of
learnable parameters, having a superior throughput,
and being fully interpretable. Furthermore, we also
show that the PCDNet model can also be applied for
unsupervised prototypical object discovery on more
challenging synthetic and real datasets. We hope that
our work paves the way towards further research on
phase correlation networks for unsupervised object-
centric representation learning.
ACKNOWLEDGMENTS
This work was funded by grant BE 2556/18-2 (Re-
search Unit FOR 2535 Anticipating Human Behavior)
of the German Research Foundation (DFG).
REFERENCES
Akiba, T., Sano, S., Yanase, T., Ohta, T., and Koyama, M.
(2019). Optuna: A next-generation hyperparameter
optimization framework. In 25th ACM SIGKDD Inter-
national Conference on Knowledge Discovery & Data
Mining, pages 2623–2631.
Aksoy, Y., Aydin, T. O., Smoli
´
c, A., and Pollefeys, M.
(2017). Unmixing-based soft color segmentation for
image manipulation. ACM Transactions on Graphics
(TOG), 36(2):1–19.
Alba, A., Aguilar-Ponce, R. M., Vigueras-G
´
omez, J. F., and
Arce-Santana, E. (2012). Phase correlation based im-
age alignment with subpixel accuracy. In Mexican
International Conference on Artificial Intelligence,
pages 171–182. Springer.
Alexiadis, V. (2006). Video-based vehicle trajectory data
collection. In Transportation Research Board 86th
Annual Meeting.
Arandjelovi
´
c, R. and Zisserman, A. (2019). Object discov-
ery with a copy-pasting GAN. arXiv:1905.11369.
Bengio, Y., Courville, A., and Vincent, P. (2013). Represen-
tation learning: A review and new perspectives. IEEE
Transactions on Pattern Analysis and Machine Intel-
ligence (PAMI), 35(8):1798–1828.
Burgess, C. P., Higgins, I., Pal, A., Matthey, L., Watters, N.,
Desjardins, G., and Lerchner, A. (2018). Understand-
ing disentangling in β-vae. CoRR, abs/1804.03599.
Burgess, C. P., Matthey, L., Watters, N., Kabra, R., Higgins,
I., Botvinick, M., and Lerchner, A. (2019). Monet:
Unsupervised scene decomposition and representa-
tion. arXiv:1901.11390.
Crawford, E. and Pineau, J. (2019). Spatially invariant un-
supervised object detection with convolutional neu-
ral networks. In Conference on Artificial Intelligence
(AAAI), volume 33, pages 3412–3420.
Engelcke, M., Jones, O. P., and Posner, I. (2021). Genesis-
v2: Inferring unordered object representations without
iterative refinement. In International Conference on
Neural Information Processing Systems (NeurIPS).
Engelcke, M., Kosiorek, A. R., Jones, O. P., and Posner, I.
(2020). Genesis: Generative scene inference and sam-
pling with object-centric latent representations. In In-
ternational Conference on Learning Representations
(ICLR).
Eslami, S. A., Heess, N., Weber, T., Tassa, Y., Szepesvari,
D., Kavukcuoglu, K., and Hinton, G. E. (2016). At-
tend, infer, repeat: Fast scene understanding with gen-
erative models. In International Conference on Neural
Information Processing Systems (NeurIPS).
Farazi, H. and Behnke, S. (2020). Motion segmentation
using frequency domain transformer networks. In
European Symposium on Artificial Neural Networks,
Computational Intelligence and Machine Learning
(ESANN).
Farazi, H., Nogga, J., and Behnke, S. (2021). Local fre-
quency domain transformer networks for video pre-
diction. In European Symposium on Artificial Neural
Networks, Computational Intelligence and Machine
Learning (ESANN).
Fritsche, M., Gu, S., and Timofte, R. (2019). Fre-
quency separation for real-world super-resolution. In
IEEE/CVF International Conference on Computer Vi-
sion Workshop (ICCVW), pages 3599–3608.
Goyal, A., Lamb, A., Hoffmann, J., Sodhani, S., Levine, S.,
Bengio, Y., and Sch
¨
olkopf, B. (2020). Recurrent inde-
pendent mechanisms. In International Conference on
Learning Representations (ICLR).
Greff, K., Kaufman, R. L., Kabra, R., Watters, N., Burgess,
C., Zoran, D., Matthey, L., Botvinick, M., and Ler-
chner, A. (2019). Multi-object representation learn-
ing with iterative variational inference. In Inter-
national Conference on Machine Learning (ICML),
pages 2424–2433.
Gueguen, L., Sergeev, A., Kadlec, B., Liu, R., and Yosin-
ski, J. (2018). Faster neural networks straight from
JPEG. In International Conference on Neural In-
formation Processing Systems (NeurIPS), volume 31,
pages 3933–3944.
He, Z., Li, J., Liu, D., He, H., and Barber, D. (2019). Track-
ing by animation: Unsupervised learning of multi-
object attentive trackers. In IEEE/CVF Conference
on Computer Vision and Pattern Recognition (CVPR),
pages 1318–1327.
Hubert, L. and Arabie, P. (1985). Comparing partitions.
Journal of Classification, 2(1):193–218.
Jaderberg, M., Simonyan, K., Zisserman, A., and
Kavukcuoglu, K. (2015). Spatial transformer net-
works. In International Conference on Neural Infor-
mation Processing Systems (NeurIPS).
Jojic, N. and Frey, B. J. (2001). Learning flexible sprites
in video layers. In IEEE Computer Society Confer-
ence on Computer Vision and Pattern Recognition.
(CVPR).
Kingma, D. P. and Ba, J. (2015). A method for stochastic
optimization. In International Conference on Learn-
ing Representations (ICLR).
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
232

Kingma, D. P. and Welling, M. (2014). Auto-encoding vari-
ational Bayes. In International Conference on Learn-
ing Representations (ICLR).
Ko, J. H., Mudassar, B., Na, T., and Mukhopad-
hyay, S. (2017). Design of an energy-efficient ac-
celerator for training of convolutional neural net-
works using frequency-domain computation. In
54th ACM/EDAC/IEEE Design Automation Confer-
ence (DAC).
Kosiorek, A. R., Kim, H., Posner, I., and Teh, Y. W. (2018).
Sequential attend, infer, repeat: Generative modelling
of moving objects. In International Conference on
Neural Information Processing Systems (NeurIPS).
Kosiorek, A. R., Sabour, S., Teh, Y. W., and Hinton, G. E.
(2019). Stacked capsule autoencoders. In Interna-
tional Conference on Neural Information Processing
Systems (NeurIPS).
Kumar, N., Verma, R., and Sethi, A. (2017). Convolutional
neural networks for wavelet domain super resolution.
Pattern Recognition Letters, 90:65–71.
Kurin, V., Nowozin, S., Hofmann, K., Beyer, L., and
Leibe, B. (2017). The Atari grand challenge dataset.
arXiv:1705.10998.
Lee, A. B., Mumford, D., and Huang, J. (2001). Occlu-
sion models for natural images: A statistical study of a
scale-invariant dead leaves model. International Jour-
nal of Computer Vision, 41(1):35–59.
Lin, C.-H., Yumer, E., Wang, O., Shechtman, E., and Lucey,
S. (2018). St-gan: Spatial transformer generative ad-
versarial networks for image compositing. In IEEE
Conference on Computer Vision and Pattern Recogni-
tion (CVPR), pages 9455–9464.
Lin, Z., Wu, Y.-F., Peri, S. V., Sun, W., Singh, G., Deng, F.,
Jiang, J., and Ahn, S. (2020). Space: Unsupervised
object-oriented scene representation via spatial atten-
tion and decomposition. In International Conference
on Learning Representations (ICLR).
Locatello, F., Bauer, S., Lucic, M., Raetsch, G., Gelly, S.,
Sch
¨
olkopf, B., and Bachem, O. (2019). Challenging
common assumptions in the unsupervised learning of
disentangled representations. In International Confer-
ence on Machine Learning (ICML), pages 4114–4124.
Locatello, F., Weissenborn, D., Unterthiner, T., Mahendran,
A., Heigold, G., Uszkoreit, J., Dosovitskiy, A., and
Kipf, T. (2020). Object-centric learning with slot at-
tention. In International Conference on Neural Infor-
mation Processing Systems (NeurIPS).
Matheron, G. (1968). Sch
´
ema bool
´
een s
´
equentiel de par-
tition al
´
eatoire. N-83 CMM, Paris School of Mines
publications.
Mathieu, M., Henaff, M., and LeCun, Y. (2014). Fast train-
ing of convolutional networks through FFTs. In In-
ternational Conference on Learning Representations
(ICLR).
Monnier, T., Groueix, T., and Aubry, M. (2020). Deep
transformation-invariant clustering. In International
Conference on Neural Information Processing Sys-
tems (NeurIPS).
Monnier, T., Vincent, E., Ponce, J., and Aubry, M. (2021).
Unsupervised Layered Image Decomposition into Ob-
ject Prototypes. In IEEE/CVF International Confer-
ence on Computer Vision (ICCV).
Paschalidou, D., Gool, L. V., and Geiger, A. (2020). Learn-
ing unsupervised hierarchical part decomposition of
3D objects from a single RGB image. In IEEE/CVF
Conference on Computer Vision and Pattern Recogni-
tion (CVPR), pages 1060–1070.
Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E.,
DeVito, Z., Lin, Z., Desmaison, A., Antiga, L., and
Lerer, A. (2017). Automatic differentiation in Py-
Torch. In International Conference on Neural Infor-
mation Processing Systems Workshops (NeurIPS-W).
Proakis, J. G. and Manolakis, D. G. (2004). Digital signal
processing. PHI Publication: New Delhi, India.
Reddy, B. S. and Chatterji, B. N. (1996). An FFT-based
technique for translation, rotation, and scale-invariant
image registration. IEEE Transactions on Image Pro-
cessing, 5(8):1266–1271.
Rudin, L. I. and Osher, S. (1994). Total variation based im-
age restoration with free local constraints. In Proceed-
ings of 1st International Conference on Image Pro-
cessing, volume 1, pages 31–35. IEEE.
Sbai, O., Couprie, C., and Aubry, M. (2020). Unsupervised
image decomposition in vector layers. In IEEE In-
ternational Conference on Image Processing (ICIP),
pages 1576–1580. IEEE.
Stanic, A., Van Steenkiste, S., and Schmidhuber, J. (2021).
Hierarchical relational inference. In Conference on
Artificial Intelligence (AAAI), pages 9730–9738.
Veerapaneni, R., Co-Reyes, J. D., Chang, M., Janner, M.,
Finn, C., Wu, J., Tenenbaum, J., and Levine, S.
(2020). Entity abstraction in visual model-based rein-
forcement learning. In Conference on Robot Learning
(CoRL), pages 1439–1456. PMLR.
Villar-Corrales, A., Schirrmacher, F., and Riess, C.
(2021). Deep learning architectural designs for super-
resolution of noisy images. In IEEE International
Conference on Acoustics, Speech and Signal Process-
ing (ICASSP), pages 1635–1639.
Weis, M. A., Chitta, K., Sharma, Y., Brendel, W., Bethge,
M., Geiger, A., and Ecker, A. S. (2021). Benchmark-
ing unsupervised object representations for video se-
quences. volume 22, pages 1–61.
Wolter, M., Yao, A., and Behnke, S. (2020). Object-
centered fourier motion estimation and segment-
transformation prediction. In European Symposium
on Artificial Neural Networks, Computational Intelli-
gence and Machine Learning (ESANN).
Xu, K., Qin, M., Sun, F., Wang, Y., Chen, Y.-K., and Ren,
F. (2020). Learning in the frequency domain. In
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 1740–1749.
Yang, J., Kannan, A., Batra, D., and Parikh, D. (2017). LR-
GAN: Layered recursive generative adversarial net-
works for image generation. arXiv:1703.01560.
Zhang, Y., Tsang, I. W., Luo, Y., Hu, C.-H., Lu, X., and Yu,
X. (2020). Copy and paste GAN: Face hallucination
from shaded thumbnails. In IEEE/CVF Conference
on Computer Vision and Pattern Recognition (CVPR),
pages 7355–7364.
Unsupervised Image Decomposition with Phase-Correlation Networks
233

APPENDIX
Model and Training Details
Table 2: Hyper-parameter values used for each dataset.
Param. Tetrominoes Space
Invaders
NGSIM
LR 0.003 0.001 0.013
Scheduler 0.1 / 5 0.1 / 5 0.6 / 2
λ
L1
10
−3
0 10
−5
λ
TV
10
−3
0 10
−2
Batch size 64 3 3
Training Details
We train our experiments with an NVIDIA RTX 3090
GPU with 24 GB RAM using the Adam (Kingma and
Ba, 2015) update rule. Additionally, we use a learning
rate scheduler that linearly decreases the learning rate.
We determine the values of our hyper-parameters us-
ing Optuna (Akiba et al., 2019)
1
. The selected hyper-
parameter values for each dataset are listed on Ta-
ble 2. We report the learning rate (LR), learning rate
scheduler parameters (LR factor / epochs), batch size,
and regularizer weights (λ
L1
and λ
TV
).
The object prototypes are initialized with a con-
stant value of 0.2 and with the center pixel set to one.
This enforces the object prototypes to emerge cen-
tered. To prevent the greedy algorithm from always
selecting the same prototypes during the first itera-
tions, we add uniform random noise U[−0.5, 0.5) to
the prototypes with a probability of 80%.
Color Module
The color module, depicted in Figure 2b, is imple-
mented in a similar fashion to a Spatial Transformer
Network (Jaderberg et al., 2015) (STN). The masked
image is fed to a neural network, which extracts cer-
tain color parameters corresponding to the masked
object. The architecture of this network is summa-
rized in Table 3. The extracted color parameters
are applied to the translated object prototypes with
a channel-wise affine transform. Our color module
shares similarities with other color transformation ap-
proaches (Kosiorek et al., 2019). Despite applying the
same affine channel transform, our method differs in
the way the color parameters are computed.
1
Hyper-parameter ranges and further details
can be found in https://github.com/AIS-Bonn/
Unsupervised-Decomposition-PCDNet
Table 3: Implementation details of the Color Module CNN.
Layer Dimension
Input 3 × H ×W
Conv. (3 × 3) + ReLU 12 × H ×W
Batch Norm. 12 × H ×W
Conv. (3 × 3) + ReLU 12 × H ×W
Batch Norm. 12 × H ×W
Global Avg. Pooling 12 × 1 × 1
Flatten 12
Fully Connected 3
Greedy Selection Algorithm
Algorithm 1 illustrates the greedy selection algorithm
used to select the colorized object candidates that best
reconstruct the input image.
Qualitative Results
Figure 8 displays PCDNet segmentation results on the
Space Invaders dataset. Figure 9 depicts further qual-
itative comparisons on the Space Invaders dataset be-
tween PCDNet, SPACE (Lin et al., 2020) and Slot At-
tention (Locatello et al., 2020). Figure 10 depicts sev-
eral object prototypes and their corresponding alpha
masks learned by PCDNet on the NGSIM dataset.
Algorithm 1: Greedy Selection Algorithm.
procedure GREEDY SELECTION ALGORITHM
Inputs:
I ← Input image
T = [T
1
,...,T
T
] ← Object Candidates
N
max
← Max. number of objects
Returns:
O = [O
1
,...,O
N
max
] ← Selected objects
Algorithm:
O ← [ ]
for i in range [1, N
max
] do
E ← [ ]
for t in range [1, T ] do
E
t
= ||I − G(O, T
t
)||
2
2
q = argmin(E)
O ← [O, T
q
]
return O
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
234

Figure 8: Additional PCDNet unsupervised segmentation qualitative results on the Space Invaders dataset.
Figure 9: Additional qualitative comparison on the Space Invaders dataset.
Figure 10: Several vehicle prototypes (top) and their corresponding alpha masks (bottom) learned on the NGSIM dataset.
Unsupervised Image Decomposition with Phase-Correlation Networks
235
