
Value-based Consent Model: A Design Thinking Approach for
Enabling Informed Consent in Medical Data Research
Simon Geller
1a
, Sebastian Müller
2b
, Simon Scheider
1c
, Christiane Woopen
2,3 d
and Sven Meister
1,4 e
1
Healthcare, Fraunhofer Institute of Software and Systems Engineering, Emil-Figge-Straße 91, 44227 Dortmund, Germany
2
ceres, University of Cologne, Albertus-Magnus-Platz, 50923 Cologne, Germany
3
Center for Life Ethics, University Bonn, Schaumburg-Lippe-Str. 7, 53113 Bonn, Germany
4
Department of Health/School of Medicine, Witten/Herdecke University, Alfred-Herrhausen-Straße 50, 58455 Witten,
Germany
Keywords: Consent Model, Electronic Health Records, Big Data, Autonomy, Moral Values, Medical Research, Privacy,
Meta Consent.
Abstract: Due to new technological innovations, the increase in lifestyle products, and the digitalisation of healthcare
the volume of personal health data is constantly growing. However, in order to use, re-use, and link
personalised health data and, thus, unlock their potential benefits in health research, the authors of the data
need to voluntarily give their informed consent. That is a major challenge to health data research, because the
classic informed consent process requires the immense administrative burden to ask for consent, every time
personal health data is accessed. In this paper we argue that all alternative consent models that have been
developed to tackle this problem, either do not reduce administrative burdens significantly or do not conform
to the informed consent ideal. That is why we used the design thinking approach to develop an alternative
consent model that we call the value-based consent model. This model has the potential to reduce
administrative burdens while empowering research subjects to autonomously translate their values into
consent decisions.
1 INTRODUCTION
In medical data research an informed consent (IC) is
a process in which research subjects are given
information about specific studies and then
voluntarily permits research agents to access and use
their health data like x-ray images, clinical history,
drug prescriptions, and much more to conduct the
study. By informing research subjects in advance
about research objectives, potential advantages and
disadvantages, funding, and other relevant factors,
and by granting them the right to revoke their consent
at any time, the autonomy of subjects in medical
research is structurally protected (Kleinig, J., 2009).
However, the rise of big data in medical research
comes along with two challenges for the IC process.
First, it is impossible to inform subjects about the
a
https://orcid.org/0000-0002-6342-851X
b
https://orcid.org/0000-0001-9281-1246
c
https://orcid.org/0000-0003-4704-2833
d
https://orcid.org/0000-0002-7148-6808
e
https://orcid.org/0000-0003-0522-986X
scope, the methods, and the risks of research projects
that are going to access health data in the far future.
Second, to transfer the classic notion of IC into the
medical big data context, researchers would have to
repeat the consent process for each new data use and
each one of the research subjects would have to
repeatedly give their consent. It is easy to see that
with increased quantities of research requests both the
educational and the administrative burden on the part
of the researchers as well as the consent burden on the
part of the research subjects becomes impractical
(Ruyter et al., 2010; Mittelstadt and Floridi, 2016). To
face these challenges, a number of digital alternatives
to the analogue IC model have been introduced
recently (e.g., Helgesson, 2012; Kaye et al., 2015;
Ploug and Holm 2016). All of these models try to find
an equilibrium between the data subjects’ autonomy
Geller, S., Müller, S., Scheider, S., Woopen, C. and Meister, S.
Value-based Consent Model: A Design Thinking Approach for Enabling Informed Consent in Medical Data Research.
DOI: 10.5220/0010828000003123
In Proceedings of the 15th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2022) - Volume 5: HEALTHINF, pages 81-92
ISBN: 978-989-758-552-4; ISSN: 2184-4305
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
81

and potential data efficiency benefits by introducing
various interpretations of the research scope that
subjects are able to consent to. They also try to
consider the various national and international laws
concerning medical data privacy like the EU GDPR
or the US HIPAA. Whether these IC models are able
to adequately preserve the research subjects’
autonomy is discussed critically and repeatedly
challenged (e.g., Caulfield and Kaye, 2009; Cheung,
2018; Manson, 2020).
In this paper, we will use the design thinking
method to analyse current IC approaches in the digital
health data research context and come up with a
suitable alternative IC model. First, we analyse the IC
models most commonly discussed in literature and
identify both normative and technical benefits and
risks for researchers and research subjects. Since
some of the identified risks may jeopardise the
research subjects’ autonomy in real live consent
situations, we come up with a new consent model that
we will call value-based consent model and that is
built on the Danish meta consent model by Ploug and
Holm, (2016), the idea of a cascade consent model
that was proposed by the German Ethics Council
(Deutscher Ethikrat, 2017), and the matrix model,
introduced by Christiane Woopen (2020). Its
innovation is the possibility for research subjects to
express consent preferences for different types of
research categories such as research scope, research
agent, funding, and many more in advance and, at the
same time, to manually introduce exceptions from
this setting. We call these exceptions dynamic
categories. They can be introduced in cases, where
settings in the meta consent conflict with each other.
This modification prevents automated consent
decisions that do not match a subjects' personal
values. Additionally, we promote the subjects’ right
to withdraw from its research participation by
introducing the possibility to transparently oversee all
consent decisions already made for past, present, and
future research studies in a so-called consent history
and to opt out of single studies before they start. This
way, the value-based consent model promotes value-
based consent decisions while supressing machine-
based consent decisions.
2 STATE OF THE ART
To understand what informed consent actually is and
how its elements can be justified, it is best to take a
closer look at the status of humans as self-determined
moral beings. This status is often justified by the
human capability to autonomously set and pursue
moral ends (Kant, 2011). In this context, Autonomy
is not so much a single momentum of purposeful
action as it is a process that comprises the capability
to, first, create and reflect personal desires, motives
and ideals, second, to form and change concrete
behavioural intentions and put those intentions into
actions and, third, to assess the foreseeable
consequences of actions (Woopen and Müller, 2021).
To ensure that subjects in medical research are
respected in their nature as morally autonomous
beings the IC must consider all three parts of the self-
determination process. It must enable people to form
and reflect their own preferences and desires
(Frankfurt, 1971). That includes the ability to project
individual changes in preferences and ostensible
choice inconsistencies into the IC architecture.
Furthermore, the IC must take the bounded
rationality (Schlaile et al., 2018) of human beings
into account. Due to cognitive and physical
limitations as well as constraints in terms of time,
economic and social resources, the human ability to
assess all foreseeable consequences of one’s actions
is per se limited. Nonetheless, the quality and quantity
of information as well as its medium of
communication should enable research subjects to
make self-determined decisions. That includes the
necessity to receiving detailed information about
studies subjects are asked to participate in and the
structural ability to easily act on that very information
by consenting to, withdrawing from, or rejecting
research requests. An IC doesn’t serve its purpose if
these criteria are not met and subjects are not able to
form and change their preferences, retrieve relevant
information, and change their consent decisions.
Especially in the digital research context, the last
issue is most relevant. Jürgen Habermas identifies a
threat to autonomy in the pragmatic tendency to
replace complex decision-making processes with
mere technical processes. In such cases, it is no longer
the autonomous citizens within a society who define
social meaning through their own decisions and
discourses, but the few people who develop a
technology that makes important decisions for the
people (Habermas, 2004). Decisions about which
research projects are covered by a broad consent and
which studies are rejected due to hierarchical meta
structures, are part of that problem. Three criteria can
be derived from the discussion so far: an IC model
that transfers the ethical and legal reasons to conduct
the IC into the realm of medical health data research
can be considered to be adequate when research
subjects (i) are informed about crucial characteristics
of a research project before their participation, (ii) are
informed about foreseeable personal and social
HEALTHINF 2022 - 15th International Conference on Health Informatics
82

consequences of their research participation as well
as the limitations to that assessment, (iii) can easily
incorporate personal moral developments and social
changes in their decision-making process and adjust
their consent accordingly.
2.1 Specific Consent Model
With specific consent, subjects authorise research
agents to access a well-defined set of data for one
specific research purpose. In contrast to the confusing
perception given by the phrase ‘data donation’, which
is often used in such contexts, participants do not lose
their right to authorise or deny data access. They can
withdraw their consent at any time, even after
research has been conducted. Moreover, any data
access and use beyond the specific research purpose
needs new consent. The specific consent model
enables potential research subjects to use the specific
consent type in a digital format (Ploug and Holm,
2016). The information process can be provided by an
interface and support subjects in many ways. For
example, information can be made available in many
languages, its transfer can be supported audio-
visually, and the research subjects’ understanding of
the research in question can be checked with the help
of interactive elements (De Sutter et al., 2020). It is
also important to stress that in this model, information
can be altered to fit the subjects’ needs (Ploug and
Holm, 2016). Apart from that, the specific consent
model does not allow researchers to collect contact
data for follow-up studies. Some researchers argue
that this characteristic can cause tremendous
administrative burdens (Helgesson, 2012). Thus, a
consent model that enables subjects to use specific
consent only would demand a lot of efforts from
potential research subjects since it is plausible to
belief that the number of specific consent requests for
medical data research will increase significantly in
the near future (Mittelstadt and Floridi, 2016). In
consideration of the overwhelming numbers of
consent requests, we assume that study drop-outs and
blanked rejections have to be perceived as likely.
2.2 Broad Consent Model
In contrast, the broad consent can be introduced to
widen the research purpose subjects can consent to.
The definition of what an adequate scope of research
should look like is by no means fixed, but open for
debate. It may, for example, refer to the development
of different image recognition algorithms only and
authorise access to skin cancer images exclusively.
But it may also include a consent to grant access to all
related files in the EHR for the purpose of cancer
research in general. As a result, the broad consent
model reduces the number of research requests and,
therefore, the administrative expenses in correlation
to the extension of the research scope (Manson,
2020). However, a serious issue with the broad
consent model is that at the time the consent is given,
the quantity and quality of future studies conducted
with this data is unknown. The problem is that it is
not possible to inform subjects about the research
scope, the personal benefits and risks, the research
agents, or the funding of future research studies
whose design may not even have been invented today
(Caulfield and Kaye, 2009; Caplan, 2009).
Consequently, subjects cannot know, how their
involvement in research may affect future societies and
their future self. Moreover, not every broad consent
attaches an expiring date to the consents which means
that subjects can consent to a broad use of their data
and when research methods or governance policies
changes in the future, the consent will still hold (Ploug
and Holm, 2020). Attached to this problem is the issue,
that it is inconvenient to make use of the right to
withdraw consent, if subjects do not know in which
research projects their data is being used (Ploug und
Holm, 2016). Advocates of a broad consent model
argue that subjects can be well informed about the fact
that they do not have all relevant information on future
research projects (Taupitz and Weigel, 2012). As long
as transparent governance structures are put in place,
they belief that the broad consent model meet the IC
ideal (Manson, 2020).
2.3 Open Consent Model
The open consent model was implemented in the
Harvard Personal Genome Project, in which subjects
were able to consent to the public release of their
genome data after passing a very detailed test about
the properties of genes, the research areas genes are
used in, and all possible disadvantages that might
come along with public data use. The complexity of
the test gives the impression that the few who are able
to pass it are sufficiently informed to make an
autonomous decision (Angrist, 2009). The open or
blanked consent model enables subjects to grant
everyone the access to a specific set of health data
without any limitations regarding access time and
frequency, data use, or agency (Wendler, 2013).
Thus, the administrative burden of obtaining re-
consent is minimal. Because it is difficult to imagine
that regular data subjects are able to reach a level of
enlightenment where they can overview the most
important effects their open consent might have on
Value-based Consent Model: A Design Thinking Approach for Enabling Informed Consent in Medical Data Research
83

their personal live and the society, most experts
disqualify this model for broad social application
(Cheung, 2018).
2.4 Dynamic Consent Model
The dynamic consent model as well as the meta
consent model try to mediate the extremes of the
former consent models. The dynamic consent enables
subjects to repeatedly give specific consents to
researchers to use their personal health data for
medical studies (Steinsbekk et al., 2013). While the
subjects’ data is stored permanently and does not
need to be deleted after each study, subjects can
actively oversee all research in which their data has
been used. Because the data is stored permanently,
subjects can be selected for research based on special
attributes like clinical history, blood type, social
media use, and so on. Empirical data indicates that
people are more likely to grant their consent to
research projects if research requests are managed
with a dynamic rather than a broad consent model
(Stoeklé et al., 2019). While advocates argue that the
administrative burden of the dynamic consent model
is likely to be smaller than in the specific consent
model, critics doubt that, because the program
constantly sends requests to potential subjects
followed by a long waiting period for responses
(Manson, 2019). In addition, Ploug and Holm assume
that people who are often confronted with consent
requests will stop reading the consent information and
give their consent or refusal out of habit. The authors
call that phenomenon “consent fatigue” (Ploug and
Holm, 2016). To the best of our knowledge this
phenomenon has not yet been empirically proven.
2.5 Meta Consent Model
The meta consent model can be thought of as a filter
program. It gives subjects the opportunity to set their
preferences regarding the study categories “type of
consent” (blanked refusal, broad consent, blanked
consent, specific consent), “type of data” (e.g., EHR,
gene material, tissue etc.), and “research context”
(e.g., commercial or non-commercial research,
funding situation, national or international research)
(Ploug and Holm, 2015; 2016). Blanked refusal
means that subjects refuse to consent to a given
research category in general. Subjects might, for
example, deny commercial agents access to their data.
By entering their preference settings in the meta
consent form, subjects can choose how they are going
to be asked for consent in the future. Now, if the same
subjects prefer to support all research concerning
cancer, they can give broad consent to cancer
research. This way, a study request on skin cancer
research that wants to use skin images to train a skin
cancer recognition software can do so without asking
for specific consent. The same way, a research project
on lung cancer can use the subjects’ EHR. As the
example suggests, in the meta consent model subjects
can choose alternative consent types for different
research categories. Unfortunately, there are cases
where consent choices on the meta level contradict
each other. If a for-profit organisation wants to do
cancer research, it is not obvious how the meta
consent form of the subjects in the example above can
generate a consent. For these cases, Ploug and Holm
introduce a prioritisation of consent decisions that
automatically solves technical inconsistencies.
Blanked refusal is prioritised over specific consent
over broad consent over blanked consent. For the
case above, the blanked refusal to private businesses
is weighted higher than the broad consent to support
cancer research. The meta consent model has
empirically been proven to gain trust among Danish
research subjects (Ploug and Holm, 2017).
There are some problems with the meta consent
model as well. First, the meta consent model has a
higher administrative burden than the broad consent
model because the system needs to send consent
requests constantly and waits for individual answers
(Manson, 2020). Second, human preferences are not
as ordered and consistent as the automated conflict
solution suggests. Preferences and desires do not need
to be complete or transitive to acknowledge the moral
autonomy of research subjects (Sunstein, 1996).
Subjects might, for example, not consent to value
blanked refusal over broad consent in a specific case.
Referring to the introduction of this article, we belief
this momentum to be particularly problematic
because consent decisions are actively delegated to an
automated mechanism that is not controlled by the
research subjects. Finally, it is important to note that
a meta-consent model can be shaped with a variety of
meta criteria to choose from and priority rules to
govern conflicts. Ploug and Holm introduced only
one of many ways to design such a model.
3 RESEARCH DESIGN
We applied a design thinking approach as
methodological framework to our research. The
method of design thinking is increasingly applied in
various scientific domains, particularly information
systems research. It is characterizable as a systematic
approach to find solutions for complex issues with the
HEALTHINF 2022 - 15th International Conference on Health Informatics
84
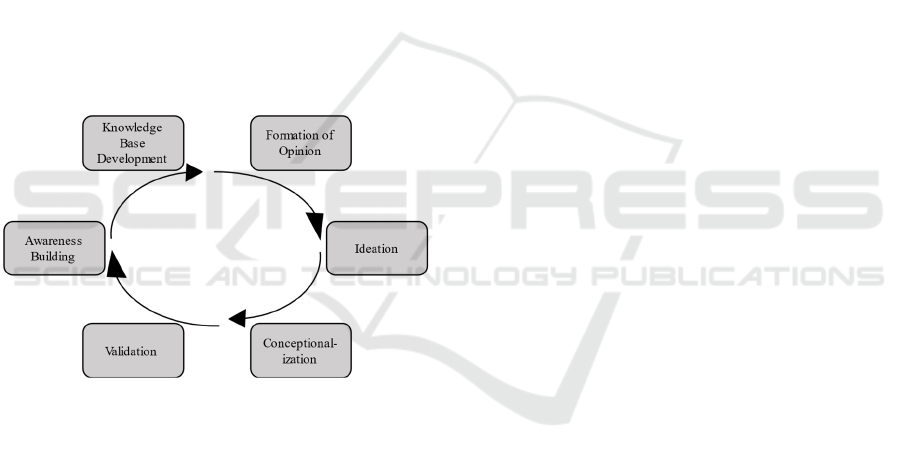
aid of multidisciplinary researchers (Wylant, 2008;
Plattner et al., 2011; Wölbling et al., 2012). In this
context, a common model by HPI School of Design
Thinking outlines an iterative process encompassing
six dedicated steps. These steps are passed iteratively
in multiple loops and carried out in a sequential order
while allowing to return to previous steps within an
iteration. The original process model consists of the
steps ‘understand’, ‘observe’, ‘define the point of
view’, ‘ideate’, ‘prototype’, and ‘test’ (HPI School of
Design Thinking, n.d.). For our research design,
however, we performed several adaptations. Similar
to the proposed framework, we defined six steps and
maintained both the sequential order including the
possibility of backward stepping within an iteration
and the iterative nature of the overall methodological
process. Likewise, our research methodology consists
of the steps: (1) awareness building, (2) knowledge
base development, (3) formation of opinion, (4)
ideation, (5) conceptualization, and (6) validation.
Our adapted iterative approach contains an embedded
loop from the last to the first step to ensure agility of
the research process.
Figure 1: Design thinking Steps.
We carried out the steps depicted in Figure 1
iteratively with a project team of 12 researchers, who
contributed their expertise from the research fields
ethics, law, economics, social sciences, information
technology, healthcare, price and service
management, education, and media research. In the
first step, awareness building, each researcher
developed an own understanding for phenomena
related to a given domain under investigation. In the
second step, each researcher relied on individual and
self-selected methods for knowledge base
development, typically a literature analysis, to acquire
comprehensive information about the phenomenon
under investigation. Naturally, this step differed
among researchers since it is subject to the
researchers’ expertise in terms of the domains
relevant for phenomena elicitations. The creation of a
knowledge base allowed each researcher the
formation of an opinion based on own expertise
established over the time of the project. Such
expertise was used by the researchers in the phase of
ideation to generate novel ideas for consent models.
In conceptualization, these ideas were concretized in
several group meetings, five workshops, and weekly
small group meetings over a period of nine month. As
a result of this step, the first two authors of this article
developed first blueprints for consent models,
typically emphasizing certain aspects, e.g., legal or
ethical issues. The final phase of each iteration, called
validation, was carried out in plenums with all
researchers of the project team. Such plenums took
place according to fixed schedules and terminated an
iteration. All researchers presented and shared their
ideas on state of art consent models and the consent
model development. Subsequently, (dis-) advantages,
problems, and opportunities were discussed as well as
potential (dis-) similarities among model proposals.
In a new iteration, the first two authors tried to refine
their consent model based on the feedback received
by the group. Naturally, this involved further
awareness building and an extension of the
knowledge base. Our findings generated through this
process allowed us to systematically compare the
models, which is presented in section 4. Among
others, this systematic comparison has led to the
further development of Ploug and Holms meta
consent model into a new meta consent model
variation that is the value-based consent model.
4 COMPARISON OF THE
CONSENT MODELS
As we have discussed in part 2 there are many issues
with the current IC models that can either severely
limit Big Data research or critically diminish the
autonomy of research subjects. The specific consent
model incorporates the fundamental elements of the
classic notion of IC the best. But, compared to the
alternatives, it carries the highest burdens for
researchers and research subjects. The broad consent
model and the open consent model both reduce or
minimise these burdens at the expenses of the
research subjects’ autonomy. Autonomy can be
restricted by inconvenient refusal options and by
static broad consent types for an unknown number of
studies with an unknown quality. The dynamic
consent and the meta consent model try to smoothen
this gradual autonomy issues by introducing more
convenient choice architectures. Unfortunately, the
Value-based Consent Model: A Design Thinking Approach for Enabling Informed Consent in Medical Data Research
85
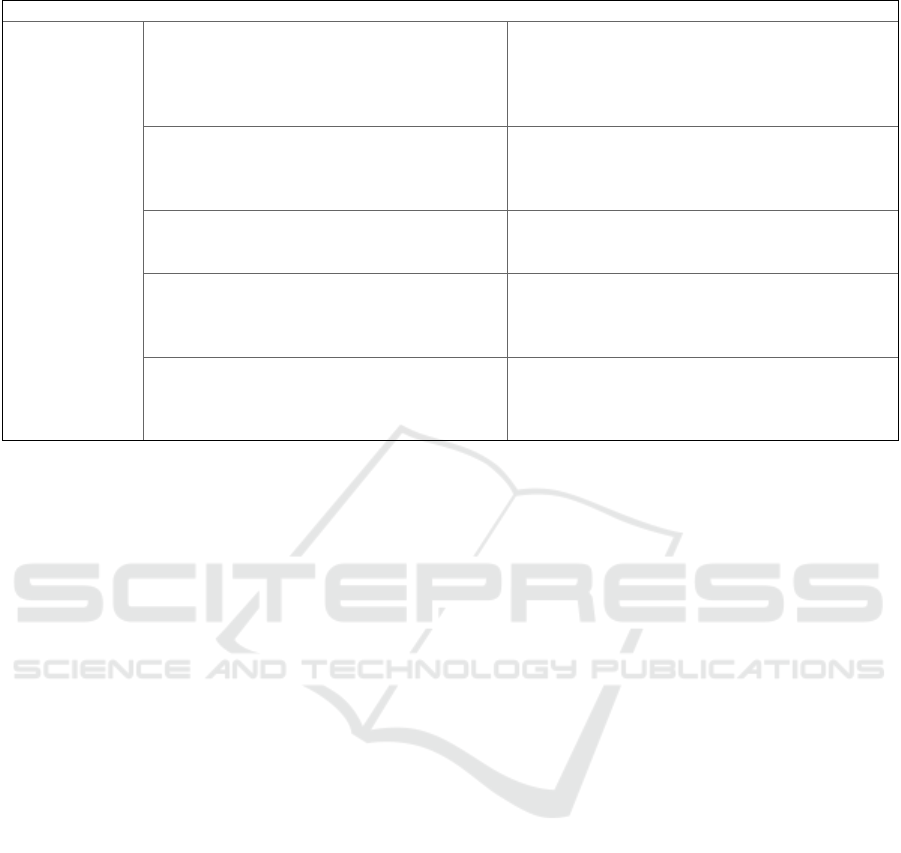
Table 1: Benefits vs. risks and burdens of contemporary consent models.
Consent Model Benefit Risks and
b
urdens
Specific Consent -genuine implementation of the IC ideal
(Ploug and Holm, 2016; De Sutter et al., 2020)
-huge financial and administrative burden
(Helgesson, 2012; Manson, 2019)
-burden of being informed numerous times
(Steinsbekk et al., 2013)
-Risk of stud
y
dro
p
outs
(
Steins
b
ekk et al., 2013
)
Broad Consent -reduced administrative burden compared to
specific consent (Manson, 2020)
-subjects are not informed in detail about the
studies they consent to (Caulfield and Kaye, 2009;
Caplan, 2009)
-model may scare potential research subjects away
Blanked/ Open
Consent
-minimal administrative burden
(Angrist, 2009)
-does not comply with IC ideal in broad public
settings (Cheung, 2018)
-
p
ossibilities to intervene are minimal
Dynamic
Consent
-simplified way to contact and re-contact
research subjects (Steinsbekk et al., 2013)
-reduced administrative burden compared to
s
pecific consent (Steinsbekk et al., 2013)
-the ‘Re-Consent’ option might scare potential
research subjects off (Steinsbekk et al., 2013)
Meta Consent -model produces procedurally consistent
consent decisions (Ploug and Holm, 2016)
-subjects can express preferences comparatively
accurate (Ploug and Holm, 2016)
-subjects might give consent to studies that they
prefer not to consent to (Ploug and Holm, 2016)
-higher administrative burden compared to the
broad consent model (Manson, 2019)
first one is still burdensome in administration and
potentially foster a consent fatigue. The latter might
technically generate consents that do not reflect the
informed decisions of the subjects. Table 1
summarise the benefits and burdens of all consent
models as discussed before. This table relates to the
present analysis and is not exhaustive.
Based on the comparison above, we belief that a
meta consent model approach is the best solution, so
far, to realise the IC ideal in the context of medical
data research. It enables research subjects to affect the
frequency and type of research requests they receive
and it also acknowledges their ability to form and
express personal preferences concerning research
categories like research objectives, research agents,
and funding in general.
However, we recognise that the limitations of
Ploug and Holms model jeopardise the IC ideal, for it
creates the option to generate technical consents that,
eventually, do not correspond with the subjects’
actual intentions. It does so by providing only
technical solutions to resolve conflicting consent
types, by allowing subjects to choose between a few
categories within the meta consent form only, and by
not facilitating the subjects’ ability to identify and
subsequently correct potentially erroneous consents.
To overcome those issues and to come closer to the
IC ideal without increasing administrative burdens
disproportionately, we propose an extended version
of the meta consent model that we will call value-
based consent model.
5 THE VALUE-BASED CONSENT
MODEL
So far, it has become evident that an exclusive
specific consent model is too demanding to be used in
a medical data research setting and that all the other
consent models sacrifice important elements of the IC
ideal in their efforts to make medical research more
efficient. The meta consent model is least affected by
this critique. It struggles primarily with the scope of
preferences subjects can choose from and the
technical solution to conflicts of preference
incoherencies. To overcome these problems, we
propose to adapt the meta consent model by
introducing additional consent and refusal options
that enables research subjects to translate their values
into a fine-grained preference matrix that better
reflect their preferences on how to be approached for
IC requests.
The idea to adopt the meta consent model in a way
that better matches the EU General Data Protection
Regulation(GDPR) as well as the autonomous
decision-making process of research subjects have
already been elaborated in political statements
elsewhere (Deutscher Ethikrat, 2017;
Datenethikkomission, 2019; Woopen, 2020). We also
introduce a learning strategy – dynamic categories –
that enables the value-based consent model to favour
individual values over technical choice consistencies.
The interplay between both mechanisms, the adapted
version of the meta consent form that we call value-
HEALTHINF 2022 - 15th International Conference on Health Informatics
86
based consent structure, and the dynamic categories,
enable subjects to autonomously translate their
personal values into preferences and IC decisions and
to adjust those decisions at any time.
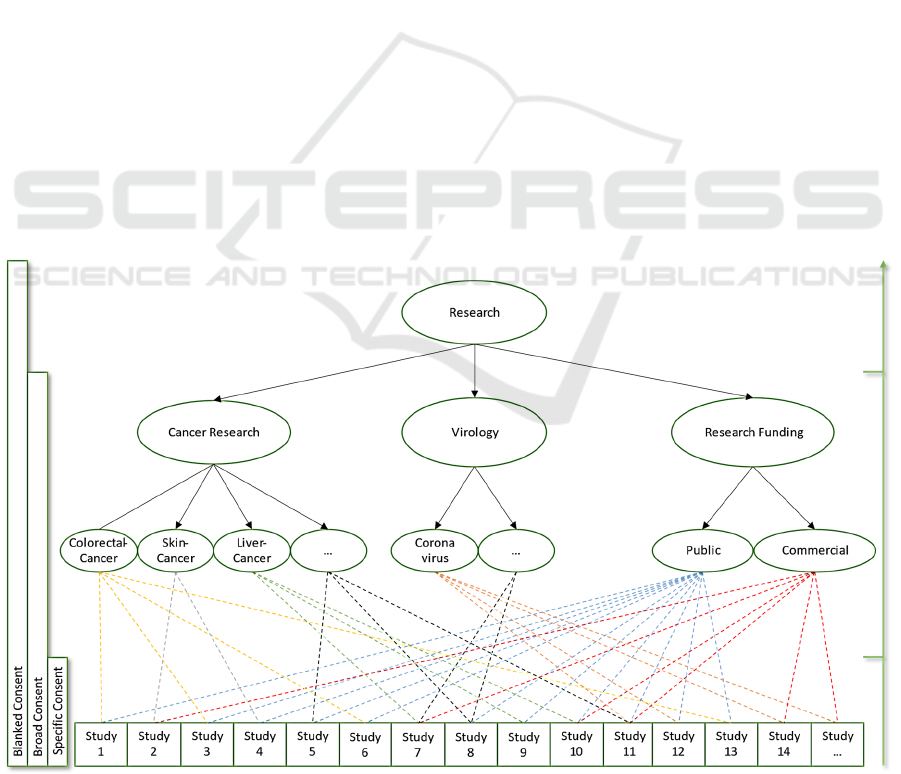
5.1 Research Categories
For the possibility to use broader consent types such
as broad consent and blanked refusal, as it is common
in the original meta consent model, we propose an
adjustment of the meta consent form (Ploug and
Holm, 2016). In doing so, we also define the term
research category, which can denote single research
fields as well as other characteristics of medical
studies such as ‘research objective’, ‘type of data’ and
‘type of context’. All of those are part of the meta
consent model by Ploug and Holm (2016). Because
every study has a research objective, a source of
funding, research agents like hospitals or research
groups, and so on, it can always be characterised with
a specific set of research categories. For example, a
study that seeks the data of research subjects to
develop an image recognition algorithm for skin
cancer can be characterised by its objective (skin
cancer research), the type of data that is being
processed (images of benign/malignant moles), and
contextual parameters (e.g., funded by the Ministry of
Health). Each research category is composed of
many subcategories. For example, the objective ‘skin
cancer’ research is a subcategory of ‘cancer research’
which has other subcategories as well like ‘neoplasms
of digestive organs’ or ‘neoplasm of breast’. The
category ‘skin cancer’ may in turn have further
subcategories like ‘melanoma’ or ‘basal-cell
carcinoma’. All study requests can be represented as
sets of research categories. For example, a study
dealing with the analysis of skin images with a
repeated data query conducted over 5 years in the
field of skin cancer research on behalf of the public
could look like this:
Study (x) = {…, Virology:false, SkinCancer:true,
DataType-SkinImages:true,
MultipleDataRetrieval:true,
ResearchAgend-PrivateCompany:false,
…}
Now, for a fine-grained adaptation of the broad
consent and its counterpart the broad refusal,
research subjects are able to consent to studies that
correspond to research categories on different super
and sub-levels. If broad consent is given in one
research category, the consent affects all
subcategories if no other consent decision has been
made. In contrast to the classic meta consent model,
however, subjects have the option of manually
consent or refuse to individual subcategories. For
example, research subjects may choose to give their
consent to all research projects that want to use their
Figure 2: Representation of the linkage between studies and research categories.
Value-based Consent Model: A Design Thinking Approach for Enabling Informed Consent in Medical Data Research
87

data for ‘cancer research’. By giving broad consent to
this research category, subjects also consent to all its
associated subcategories. If some subjects like to
make other decisions in certain subcategories like
‘skin cancer’ research, they can select another option
in those subcategories. Due to the inheritance of
consent decisions to respective subcategories the
fine-grained preferences of the research subjects can
be represented in a tree structure and all its
components.
Figure 2 shows the linkage of different studies to
their research categories in a tree structure. The
blanked consent option enables subjects to consent to
any research request regardless of the research
category it belongs to. At this time this option is
legally prohibited in the EU and only listed for the
sake of completeness.
What level of differentiation of medical research
areas, data types, funding models and more can
commonly be understood in an IC process and,
therefore, what exact set of research categories are
needed to improve the IC process for research
subjects cannot be determined theoretically. We will
come back to this issue in the limitations.
5.2 Additional Refusal Types
In order to enable subjects to translate their values
into a new fine-grained adaptation of the old meta
consent form, this subsection explicates some refusal
types that have already been in use in other consent
models.
5.2.1 Specific, Broad and Blanked Refusal
One new way for subjects to communicate their
preferences in the value-based consent model is to
choose a refusal to certain research categories and its
subcategories. The specific refusal that is already
implied in the specific consent model allows subjects
to refuse to participate in specific studies and in
studies that share certain research categories. For
example, if subjects are not comfortable to authorise
the research team of Google to access their health data
in one particular case, they can use the specific
refusal. If the same subjects are uncomfortable with
Google in general using their data for research, they
can make a broad refusal for Google to use their data
in any further studies. Analogously, to the broad
consent, the broad refusal affects multiple studies
belonging to that research category at once.
Likewise, the blanked refusal expresses the
preference to deny data access to any kind of medical
data research, whatsoever. This refusal type differs
from the blanked refusal option that is known to the
meta consent model in that it refers to the entire
preference tree (Section 5.3).
5.2.2 Legal Obligation for Data Processing
For reasons of transparency, it could be useful to
communicate legal acts of obliged health data access.
For example, when the Centre for Disease Control
and Prevention accesses its citizens EHR files to
count new COVID-19 cases and evaluate counter
measures, it is entitled to do so by law. Noteworthy,
communicating legal obligations for data processing
does not embody a novel governmental power, but
rather makes such operations more transparent.
5.3 Value-based Consent Structure
As in Ploug and Holm (2016) original meta consent
form, in the value-based consent model subjects have
the option to express their consent preferences for
each research category and subcategory. In contrast
we present the adapted version in a hierarchical tree
structure which simplifies the representation of
multidimensional research categories and allows
subjects to combine different consent and refusal
types within these dimensions.
Figure 3: Preference Tree.
Figure 3 shows that some research categories are
described as ‘open’. The term ‘open’ simply means
that the subjects have not made a consent decision in
this category yet. If, at the time a research agent sends
out a study’s request, all the relating research
categories are still ‘open’, a specific consent request
will be forwarded to the subjects. Whereby, the
subjects are made aware that they could set a consent
decision in the value-based consent structure. A
specific consent option means, that requests should be
forwarded directly to the research subjects as specific
consent requests, whereas the broad consent option
reflects the broad consent decision to grant a consent
HEALTHINF 2022 - 15th International Conference on Health Informatics
88

to all corresponding research requests. In addition, we
introduce a prioritisation of consent decisions for
subcategories and supercategories in which consent
and refusal decisions in a subcategory override the
corresponding supercategory. For example, research
subjects may choose to give broad refusal to the
research category ‘cancer research’ which will mark
all subcategories like ‘skin cancer research’ as
refusal. Now, if subjects like to set exceptions, they
can choose to give a different consent option to
specific subcategories. This makes it possible to
express global decisions such as ‘All except these’ as
well as ‘None except these’ through the consent tree.
The opportunity to add exceptions to a broad refusal
option is actively suppressed by the prioritisation
logic of the meta consent model by Ploug and Holm
(2016).
5.4 Dynamic Categories
In the meta-consent form as well as in the value-based
consent structure it is very likely that two or more
preferences conflict with each other on a regular
basis. For the skin cancer research case, such a
conflict may arise for subjects who have given a
broad consent to cancer research but broad refusal to
commercial research agents. Now, if Google wants to
conduct skin cancer research, it is not clear whether
the consent or the refusal should be more important.
The issue of conflicting consent types not only occurs
in cases in which broad consent and broad refusal
conflict with each other, but also in those where
specific consent preferences and broad consent
decisions preferences contradict each other. To solve
this issue Ploug and Holm introduce a prioritisation
schema, as described in section 2.5. According to
their schema, the leaner decision is preferred and
applied as soon as two preference definitions in the
meta-consent form contradict each other, whereby the
refusal is given the highest priority:
Blanked Refusal > Specific Consent > Broad
Consent > Blanked Consent
In line with this prioritization logic, the refusal
towards commercial research agents like Google
would be of a higher priority than the cancer research
consent and Googles cancer research request would
be denied. This prioritisation does not correspond to
the IC ideal, since the subjects cannot decide which
of the respective preference they would favour in a
conflict. On a more technical level, the scheme will
likely generate refusal decisions for research studies
in which subjects would have liked to participate. To
eliminate this problem, we replace the static
prioritization logic with what we call dynamic
categories.
Dynamic categories enable subjects to
individually decide how to deal with conflicting
preference choices. In cases in which consent
decisions conflict with each other, the affected
research request triggers a request for specific
consent. Subjects are notified that the request has
been generated by conflicting preference choices in
the value-based consent structure. After reading the
consent information and approving or rejecting the
specific consent request, subjects are given the option
to give a broad consent or a broad refusal to all future
study requests that trigger the very same conflict.
That means that any case of conflict enables subjects
to create exceptional broad consent or broad refusal
rules which is the dynamic category. For the Google
cancer study case, subjects are notified about the
conflicting preferences and can choose, either to treat
every conflict of this kind as specific consent request
or to generate a new dynamic category that solves the
conflict for all studies that share the same research
categories. In the first case, a different study on skin
cancer that is conducted by Google would be brought
forward as a new specific consent request. In the
second case and in dependence to the previous
decision, subjects either consent or refuse their
participation in forthcoming cancer studies that are
conducted by commercial agents like Google, Pfizer,
or Nestle without having to go through a new IC
process. For the dynamic categories, only broad
consent and refusal options are available, since a
specific consent choice would generate the same
effect as the absence of the dynamic category.
Since dynamic categories can only be generated
when consent decisions conflict in the value-based
consent structure, it is evident that they are deleted
when all underlying contradictions cease to exist. As
soon as subjects alter the structure in a way that the
conflicts that establish a dynamic category are
removed, the subjects are being notified. In addition,
subjects can change their consent or refusal decisions
or delete the dynamic category at any time.
There are two ways in which research categories
can overlap. First, there are conflict-free overlaps
which are overlaps of any number of research
categories for which the same consent or refusal type
has been chosen and any number of research
categories for which the decision is still open.
Second, there are overlaps that are characterised by
conflicting consent decisions. The following four
conflict cases are conceivable:
1. Broad or blanked consent with broad or blanked
refusal
Value-based Consent Model: A Design Thinking Approach for Enabling Informed Consent in Medical Data Research
89

2. Broad or blanked consent with specific consent
preference
3. Broad or blanked refusal with specific consent
preference
4. Broad or blanked consent with broad or blanked
refusal with specific consent preference.
The procedure to solve those conflicts is always
the same. A specific consent request is sent to the
subjects who then can give a specific consent or
refusal and create a dynamic category by choosing a
broad consent or refusal decision for all cases alike.
5.5 Opt out and Reconsideration
Options
We introduced an opt out and a reconsideration
opportunity to the value-based consent model, that
enables research subjects to revoke or change their
consent decisions up to the point of data retrieval. We
belief this option to be necessary to effectively
exercise the right to withdrawal consent in a fast-
moving research field that is medical data research.
For this purpose, a consent history is available that
entails a list of all research requests that have been
given a consent or a refusal to. Subjects can use their
consent history to modify specific consent decisions
as well as the specific consent or refusal decisions that
derived through broad consent and broad refusal
settings. For example, research subjects that decide to
give broad consent to commercial research agents
and to skin cancer research at first, might, at a later
time, read the list of all research studies that they have
given their consent to and realise that they consented
to participate in the research of a company that they
would rather not have given consent to. In the value-
based consent model the subjects can opt out in such
situations without further ado as long as the data has
not been retrieved jet. The other way around it is also
possible that subjects have given a broad refusal to
commercial agents, but by looking on the list of
refused research studies they may realise that they
want to support a specific skin cancer study by
Google. As long as this study is not due, the subjects
can alter their former broad consent decision in such
cases by using the option to reconsider the study for
the specific consent process. It is also possible to opt
out of a specific consent that is characterised by
multiple data retrievals over a fixed period of time. In
the consent history a specific consent of such kind is
tagged prominently so that research subjects can
easily distinguish it from other consent types. To
revoke a consent, subjects can simply opt out of the
data retrieval that is scheduled next.
The opt out and the reconsider option is a
transparency feature that communicates the relation
between subjects and all relevant research studies
openly. The oversight of the consent history and, thus,
the impact of broad consent and broad refusal
options on specific research requests promotes the
competence of subjects to translate their values into
consent preferences adequately. In all alternative
models that offer broad consent options, subjects may
face the problem of not being able to imagine, which
specific research projects may serve an abstract
research objection, which specific agents are affected
by a broad consent decision or which type of data
might be risky to share in a given research context.
With this transparent structure, the value-based
consent model ensures that subjects will become
increasingly better at understanding research
categories. A remarkable side effect of the opt out
feature is, that it excludes the original notion of a
blanked consent type. Even the broadest consent
decision like the decision to give consent to all
research objectives, research agents, and all other
research categories, whatsoever, does not equal the
classic blanked consent decision because subjects are
always able to change their decision based on
transparently communicated research activities and
opt out of individual research projects.
6 DISCUSSION
In this article we used the design thinking approach
to develop the value-based consent model. The value-
based consent model enables consent requests for the
use of personal health data in medical research
projects to be answered via the value-based consent
structure and additional dynamic categories. In this
process, the research categories of each study are
matched with the selected consent preferences of each
subject. In contrast to the original meta consent form
by Ploug and Holm, the new structure enables
subjects to choose two additional refusal options:
specific refusal and broad refusal. We believe that
representing the super and sub research categories in
a tree structure (see Figure 2) is also more accessible
than the matrix notation used by Ploug and Holm. The
dynamic categories, then, transfer the power to decide
how to deal with conflicting consent preferences from
a technical static prioritization logic to the research
subjects themselves. By adding a transparent consent
history that can be used to audit all former and current
consent decisions and to opt out or reconsider consent
choices, subjects are also able to increase their
HEALTHINF 2022 - 15th International Conference on Health Informatics
90

medical and digital literacy and adjust their consent
choices to their personal values.
All these changes establish a digital IC process
that converges with the ideal presented at the
beginning. (i) By informing subjects continuously
and transparently about past, current and future
studies in a learning friendly environment, the value-
based consent model supports the subject’s digital
and medical literacy, thus, enables them to build their
consent decisions on the latest insides and educated
assessments. (ii) Based on the easily accessible and
comprehensive information provided by the value-
based consent model and with access to the advice of
medically trained personnel who always needs to
accompany consent processes subjects are
empowered to understand the risks and consequences
of research participation and the limits of that
assessment. Finally, (iii) the differentiated choice
architecture, the simple to use intervention options,
and the consent history give subjects the opportunity
to incorporate newly gained experiences and personal
value shifts in the IC decision-making process.
However, there is also the issue of the
administrative burdens of digital IC models for
secondary use of research data. We have referred to
empirical studies that indicate that research subjects
are less likely to engage in medical data research that
is governed by broad or open consent models. In
contrast subjects place more trust in IC processes that
are governed by a dynamic consent model or a meta
consent model. Since the value-based consent model
is comparatively more transparent and does not
patronise subjects with priority rules, we assume that
subjects would prefer it over other models. If this was
the case, the comparatively large number of subjects
that would potentially use the new IC model would
reduce the challenges of the recruitment process and,
therefore, the administrative burden. The hypothesis
needs to be proven empirically in future studies.
6.1 Limitations
The effectiveness and the usability of the value-based
consent model has not been evaluated empirically so
far. Since the meta consent form is less complex than
the value-based consent structure and since the new
model incorporates a number of new refusal options
empirical studies on the application of the meta
consent model that have been conducted so far cannot
substitute the gap. Another limitation is the
configuration of the value-based consent structure. In
their work, Ploug and Holm pointed out that the meta
consent form can be extended to contain more meta
categories to choose from. However, the number and
type of research categories it should contain in order
to allow subjects to make autonomous decisions
without being either overwhelming or patronised, has
not yet been determined. This issue needs to be
addressed in further empirical studies as well.
ACKNOWLEDGEMENT
This work is funded by German Federal Ministry of
Education and Research (BMBF) (grant 16SV8500,
‘ViCon - Virtual Consent Assistant for an informed
and sovereign consent’).
REFERENCES
Angrist, M. (2009). Eyes wide open: The personal genome
project, citizen science and veracity in informed consent.
Personalized Medicine, 6(6), 691–699.
https://doi.org/10.2217/pme.09.48
Benke, K., & Benke, G. (2018). Artificial intelligence and big
data in public health. International Journal of
Environmental Research and Public Health, 15(12).
https://doi.org/10.3390/ijerph15122796
Caplan, A. L. (2009). What No One Knows Cannot Hurt
You: The Limits of Informed Consent in the Emerging
World of Biobanking, in: Solbakk, J. H., Holm, S., &
Hofmann, B. (ed.) The Ethics of Research Biobanking
(2pp.5-32). Dordrecht: Springer. https://doi.org/
10.1007/978-0-387-93872-1
Caulfield, T., & Kaye, J. (2009). Broad consent in
biobanking: Reflections on seemingly insurmountable
dilemmas. Medical Law International, 10(2), 85–100.
https://doi.org/10.1177/096853320901000201
Cheung, A. S. Y. (2018). Moving beyond consent for citizen
science in big data health and medical research.
Northwestern Journal of Technology and Intellectual
Property, 16(1).
Datenethikkomission (2019). Gutachten der Datenethik-
kommission Available at: https://www.bmi.bund.de/
SharedDocs/downloads/DE/publikationen/themen/it-
digitalpolitik/gutachten-datenethikkommission.pdf;
jsessionid=9E1A40B6C43577B2234D8CF241C2241A.
2_cid373?__blob=publicationFile&v=6 [Accessed
September 9, 2021].
Deutscher Ethikrat (2017). Big Data und Gesundheit -
Datensouveränität als informationelle Freiheits-
gestaltung Available at: https://www.ethikrat.org/
fileadmin/Publikationen/Stellungnahmen/deutsch/stellu
ngnahme-big-data-und-gesundheit.pdf [Accessed
September 9, 2021].
Frankfurt, H. G. (1971). Freedom of the will and the concept
of a person. The Journal of Philosophy, 68(1), 5-20.
https://doi.org/10.2307/2024717
Habermas, J. (2004). Freiheit und determinismus. Deutsche
Zeitschrift Für Philosophie, 52(6), 871–890.
https://doi.org/10.1524/dzph.2004.52.6.871
Value-based Consent Model: A Design Thinking Approach for Enabling Informed Consent in Medical Data Research
91

Helgesson, G. (2012). In defense of broad consent.
Cambridge Quarterly of Healthcare Ethics, 21(1), 40–
50. https://doi.org/10.1017 /S096318011100048X
HPI School of Design Thinking (n.d.) The six phases of the
Design Thinking process. Available at:
https://hpi.de/en/school-of-design-thinking/design-
thinking/background/design-thinking-process.html
[Accessed: September 08, 2021].
Kant, I. (2011). Groundwork of the metaphysics of morals: A
German-English edition (M. J. Gregor, Trans.) (J.
Timmermann, Ed.). Cambridge: University Press.
https://doi.org/10.1017/CBO9780511973741
Kaye, J., Whitley, E. A., Lund D., Morrison, M., Teare, H.,
& Melham, K. (2015). Dynamic consent: A patient
interface for twenty-first century research networks.
European Journal of Human Genetics, 23(2), 141–146.
https://doi.org/10.1038/ejhg.2014.71
Kleinig, J. (2009). The nature of consent In F. Miller & A.
Wertheimer (ed.), The ethics of consent (pp. 3–22).
Oxford: University Press. https://doi.org/10.1093/
acprof:oso/9780195335149.003.0001
Manson, N. C. (2019). The biobank consent debate: Why
‚meta-consent‘ is not the solution? Journal of Medical
Ethics, 45(5), 291-294. http://dx.doi.org/10.1136/
medethics-2018-105007
Manson, N. C. (2020). The case against meta-consent: Not
only do Ploug and Holm not answer it, they make it even
stronger. Journal of Medical Ethics, 46(9), 627–628.
https://doi.org/10.1136/medethics-2019-105955
Mittelstadt, B. D., & Floridi, L. (2016). The ethics of big data:
Current and foreseeable issues in biomedical contexts.
Science and Engineering Ethics, 22(2), 303–341.
https://doi.org/10.1007 /s11948-015-9652-2
Plattner, H., Meinel, C., & Leifer, L. (2011). Design
Thinking: Understand - improve - apply. Understanding
Innovation. Berlin: Springer. http://sub-hh.ciando.com/
book/?bok_id=232558 https://doi.org/10.1007/978-3-
642-13757-0
Ploug, T., & Holm, S. (2015). Meta consent: A flexible and
autonomous way of obtaining informed consent for
secondary research. BMJ, 350, h2146. https://doi.org/
10.1136/bmj.h2146
Ploug, T., & Holm, S. (2016). Meta consent - a flexible
solution to the problem of secondary use of health data.
Bioethics, 30(9), 721–732. https://doi.org/10.1111/
bioe.12286
Ploug, T., & Holm, S. (2017). Eliciting meta consent for
future secondary research use of health data using a
smartphone application - a proof of concept study in the
danish population. BMC Medical Ethics, 18(1), 1–8.
https://doi.org/10.1186/s12910-017-0209-6
Ploug, T., & Holm, S. (2020). The ‚expiry problem‘ of broad
consent for biobank research - and why a meta consent
model solves it. Journal of Medical Ethics, 46(9), 629–
631. https://doi.org/10.1136/medethics-2020-106117
Ruyter, K. W., LÕuk, K., Jorqui, M., Kvalheim, V.,
Cekanauskaite, A., & Townend, D. (2010). From
research exemption to research norm: Recognising an
alternative to consent for large scale biobank research.
Medical Law International, 10(4), 287–313.
https://doi.org/10.1177/096853321001000403
Schlaile, M. P., Klein, K., & Böck, W. (2018). From bounded
morality to consumer social responsibility: A
transdisciplinary approach to socially responsible
consumption and its obstacles. Journal of Business
Ethics, 149(3), 561–588. https://doi.org/10.1007/
s10551-016-3096-8
Steinsbekk, K. S., Kåre Myskja, B., & Solberg, B. (2013).
Broad consent versus dynamic consent in biobank
research: Is passive participation an ethical problem?
European Journal of Human Genetics, 21(9), 897–902.
https://doi.org/10.1038/ejhg.2012.282
Stoeklé, H.‑C., Turrini, M., Charlier, P., Deleuze, J.‑F.,
Hervé, C., & Vogt, G. (2019). Genetic Data, Two-Sided
Markets and Dynamic Consent: United States Versus
France. Science and Engineering Ethics, 25(5), 1597–
1602. https://doi.org/10.1007/s11948-019-00085-4
Sunstein, C. R. (1996). Social Norms and Social Roles.
Columbia Law Review, 96(4), 903. https://doi.org/
10.2307/1123430
Sutter, E. de, Zaçe, D., Boccia, S., Di Pietro, M. L., Geerts,
D., Borry, P., & Huys, I. (2020). Implementation of
electronic informed consent in biomedical research and
stakeholders‘ perspectives: Systematic review. Journal
of Medical Internet Research, 22(10), e19129.
https://doi.org/10.2196/19129
Taupitz, J., & Weigel, J. (2012). The necessity of broad
consent and complementary regulations for the
protection of personal data in biobanks: What can we
learn from the german case? Public Health Genomics,
15(5), 263–271. https://doi.org/10.1159/000336604
Wendler, D. (2013). Broad versus blanket consent for
research with human biological samples. The Hastings
Center Report, 43(5), 3–4. https://doi.org/10.1002/
hast.200
Wölbling, A., Krämer, K., Buss, C. N., Dribbisch, K., LoBue,
P., & Taherivand, A. (2012). Design Thinking: An
Innovative Concept for Developing User-Centered
Software. In Maedche, A., Botzenhardt, A., & Neer, L.
(ed.), Management for Professionals. Software for
People (pp. 121–136). Berlin: Springer. https://doi.org/
10.1007/978-3-642-31371-4_7
Woopen C. (2020). Stellungnahme zum Gesetzesentwurf der
Bundesregierung "Entwurf eines Gesetzes zum Schutz
elektronischer Patientendaten in der
Telematikinfrastruktur. Deutscher Bundestag BT-
Drucksache 19/18793. Deutscher Bundestag. Available
at: https://www.bundestag.de/resource/blob/698068/
d2839c2cc2c1ec321bbb843df38362a3/19_14_0165-26-
_ESVe-Prof-Woopen_PDSG-data.pdf [Accessed
September 9, 2021].
Woopen, C., & Müller, S. (2021). Die Digitalisierung als
Herausforderung für die Bestimmung des Selbst im
Gesundheitswesen. In C. Piallat (ed.), Der Wert der
Digitalisierung: Gemeinwohl in der digitalen Welt
(pp. 123–146). Bielefeld: transcript Verlag.
Wylant, B. (2008). Design Thinking and the Experience of
Innovation. Design Issues, 24(2), 3–14.
https://doi.org/10.1162/desi.2008.24.2.3
HEALTHINF 2022 - 15th International Conference on Health Informatics
92
