
Self-supervised Learning in Symbolic Classification
Xenia Naidenova
11
and Sergey Kurbatov
22
1
Military medical academy, Lebedev Street, Saint Petersburg, Russia
2
Research Centre of Electronic Computer Engineering, Moscow, Russia
Keywords: Self-learning, intelligent agent, good classification test, internal learning context, external learning context.
Abstract: A new approach to modelling self-supervised learning for automated constructing and improving algorithms
of inferring logical rules from examples is advanced. As a concrete model, we consider the process of inferring
good maximally redundant classification tests or minimal formal concepts. The concepts of external and
internal learning contexts are introduced. A model of an intelligent agent capable of improving its learning
process is considered. It is shown that the same learning algorithm can be used in both external and internal
learning contexts.
1
INTRODUCTION
Self-learning embodies one of the essential properties
of the human intelligence related to an internal
evaluation of the quality of mental processes. Vukman
and Demetriou (2011, p. 37) suggest that the mind has
a three-level hierarchical structure. The first level
interfaces directly with the environment and it
includes several specialized capacity systems
addressed to representing and processing different
domains of the environment. The remaining two levels
cover goal elaborating mechanisms, assessments of
the proximity to the goal, algorithms defining the
ability to present and process information on the first
level, and (third level) the hypercognitive processes
related to self-consciousness and self- regulation.
Empirical research of Vukman and Demetriou
(2011, p. 38) has revealed that the first level covers 6
specific domains of thought: (1) the categorical
system (deals with similarity-difference relations and
classifications); (2) the quantitative system (deals
with quantitative variations and relations in the
environment); (3) the causal system for revealing
cause-effect relations; (4) the system for evaluating
spatial orientation and representation of the
environment in images; (5) the system of formal logic
(deals with the truth/falsity and the validity/invalidity
of the flow of information); (6) the system for
evaluating the social relations.
1
https://orcid.org/0000-0003-2377-7093
2
https://orcid.org/0000-0002-0037-9335
The second level is responsible for the complexity
and efficiency of information processing at the first
level at any given time. Operations of this level set
the speed of information processing, realize the
control of thinking processes, and direct the attention
to important stimulus and prohibit irrelevant ones.
This level also includes working memory.
The hypercognition includes self-awareness and
self-regulation of knowledge and strategies operating
as the interface between (a) mind and reality, and (b)
any of the various systems and processes of mind. The
hypercognitive level has two components: the
working hypercognition and the long term
hypercognition. The first component is responsible
for setting goals, planning, and monitoring the
achievement of goals, including responsibility for
updating goals and sub-goals. The self-consciousness
is an integral part of the hypercognitive system. The
component of long-term hypercognition involves the
internal representation of past cognitive experience.
Our analysis of modern research has been
implemented in the following directions: modeling of
self-learning (self-supervised learning) and learning
in robots and robotic systems. In artificial
intelligence, the theory of self-learning is still in the
formation, the practical results are obtained mainly in
the modeling of robot management. In the second
direction, it is particularly interesting the principles
and technologies of creating a robot that can move in
Naidenova, X. and Kurbatov, S.
Self-supervised Learning in Symbolic Classification.
DOI: 10.5220/0010732700003101
In Proceedings of the 2nd International Conference on Big Data, Modelling and Machine Learning (BML 2021), pages 289-294
ISBN: 978-989-758-559-3
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
289

the environment, manipulate objects and avoid
obstacles (Pillai, 2017). The self-learning robot
should be aware of its own localization and have an
internal reflection of spatial situation. It is declared by
the author (Pillai & Leonard, 2017) that the robot
should be self-esteemed and self-managed on the
basis of previous experience. It must constantly adapt
its spatial and semantic models, improving the
performance of its tasks. Some concepts and
algorithms are proposed to evaluate the robot's own
movement (Self-Supervised Visual Ego Motion
Learning) (Sofman, Line et al., 2017). Note that such
a robot has not yet been implemented but the concept
of self-learning proposed by the author coincides with
the concept of self-learning offered by us.
In (Pathak, Agraval, et al., 2017), the role of
curiosity in self-learning is analyzed and the concept
of self-learning with the phenomenon of curiosity is
developed.
In (Shaukat, Burroughe & Gao, 2015), a robot’s
internal evaluation of its future path cost is proposed
on the basis of the probabilistic Bayesian method.
In some works, the authors propose the use of
robot’s manipulation reflection in learning algorithms
for improving and accelerating robot’s training. For
example, industrial Robot of Japanese Company
Fanuc uses a method known as "training with
reinforcement" to grab objects by a manipulator. In
this process, a robot fixes its work on video and uses
this video for correcting own activity. Domestic
development of robots is based on the use of artificial
neural networks (Pavlovsky & Savitsky, 2016;
Pavlovsky V.E. & Pavlovsky V.V., 2016; Pavlovsky
et al., 2016).
In paper (Bretan et al., 2019), the authors
introduce “Collaborative Network Training” – a self-
supervised method for training neural networks for
learning robots. This method covers task objective
functions, generates continuous-space actions, and
performs an optimization for achieving a desired task.
Also, the method allows learning parameters when a
process for measuring performance is available, but
labelled data is unavailable. The method involves
three randomly initialized independent networks that
use ranking to train one another on a single task.
Major improvements in time and data efficiency to
learn robot are achieved in (Berscheid, Rühr &
Kröger, 2019). Using a relatively small, fully-
convolutional neural network, it is possible predict
grasp and gripper parameters with great advantages in
training as well as inference performance. Motivated
by the small random grasp success rate of around 3%,
the grasp space was explored in a systematic manner.
The final system was learned with 23000 grasp
attempts in around 60h, improving current solutions
by an order of magnitude. The authors measured a
grasp success rate of (96.6±1.0) %.
To model a self-learning process, we focus on the
logical or symbolic supervised methods of machine
learning. This mode of learning covers mining logical
rules and dependencies from data: “if-then” rules,
decision trees, functional, and associative
dependencies. This learning is also used for
extracting concept from data sets, constructing rough
sets, hierarchical classification of objects, mining
ontology from data, generating hypotheses, and some
others (Kotsiantis, 2007; Naidenova, 2012). It has
been proven in (Naidenova, 1996) that the tasks of
mining all logical dependencies from data sets are
reduced to approximating a given classification
(partitioning) on a given set of object descriptions.
The search for the best approximation of a given
object classification leads to the definition of a
concept of good classification (diagnostic) test firstly
introduced in (Naidenova & Polegaeva, 1986). A
good classification test has a dual nature. On the one
hand, it makes up a logical expression in the form of
implication, associative or functional dependency. On
the other hand, it generates the partition of a training
set of objects equivalent to a given classification
(partitioning) of this set or the partition that is the
nearest one to the given classification with respect to
the inclusion relation between partitions
(Cosmadakis, Kanellakis & Spiratos, 1986,
Naidenova, 2012). It means that inferring good
classification tests gives the least possible number of
functional or implicative dependencies.
Table 1: Example of dataset (adopted, (Ganascia, 1989)).
n
dex of object
Height
Color of
hair
Color o
f
eyes
Class
1 Low Blon
d
Blue 1
2 Low Brown Blue 2
3 Tall Brown Hazel 2
4TallBlon
d
Hazel 2
5TallBrown Blue 2
6 Low Blon
d
Hazel 2
7TallRe
d
Blue 1
8TallBlon
d
Blue 1
It means also that good classification tests have
the most possible generalization properties with
respect to object class descriptions. We consider two
ways for giving classifications: (1) by a target
attribute KL or (2) by value v of a target attribute. In
Table 1, an example of object classification is given.
The target attribute partitions a given set of
objects into disjoint classes the number of which is
BML 2021 - INTERNATIONAL CONFERENCE ON BIG DATA, MODELLING AND MACHINE LEARNING (BML’21)
290

equal to the number of values of this attribute. The
target value of attribute partitions a given set of
objects into two disjoint classes: the objects in
description of which the target value appears (positive
objects); all the other objects (negative objects). The
problem of machine learning to approximate a given
classification consists in solving the following tasks:
Given attribute KL, to infer logical rules of the
form:
A B C → KL or D S → KL or …or A S Q V →
KL,
where A, B, C, D, Q, S, V – the names of
attributes.
Given value v of attribute KL, to infer logical rules
of the form:
if ((value of attribute А = “а”) & (value of
attribute В = “b”) & …, then (value of attribute KL =
“v”).
Rules of the first form are functional
dependencies as they are determined in the relational
data base theory. Rules of the second form are
implicative dependencies. The left parts of rules can
be considered as the descriptions of given
classifications or classes of objects. In our approach
to logical rules mining, the left parts of these rules
constitute classification tests. Implicative assertions
describe regular relationships connecting objects,
properties, and classes of objects. Knowing the
implication enables one to mine a whole class of
implicative assertions including not only simple
implication (a, b, c → d), but also forbidden assertion
(a, b, c → false (never)), diagnostic assertion (x, d →
a; x, b → not a; d, b → false), assertion of alternatives
(a or b → true (always); a, b → false), compatibility
(a, b, c → VA, where VA is the occurrence’s
frequency of rule).
We propose, in this paper, an idea of a deeper
level of self-learning allowing to manage the process
of inferring good tests in terms of its effectiveness
through an internal monitoring and evaluation of this
process and the development of rules for choosing the
best strategies (algorithms), and learning
characteristics.
Let's call a set of given objects with a class-
partitioning an external or application context. The
internal or reconfiguration level implements the
analysis and evaluation of the process of inferring
classification rules in the external context allowing to
identify the relationships between the external
contexts (sub-contexts) and the parameters of
learning process.
2
SOFTWARE AGENT CAPABLE
OF SELF-LEARNING
In the tasks of logical rule inference, the objects in the
external context (training samples) are described in
terms of their properties (features, attributes) and they
are specified by splitting into classes. The task of
learning is to find rules in each given context in order
to repeat the classification of objects represented by
splitting objects into disjoint classes. The learning
algorithms have a number of convenient properties
for self-monitoring the process of inferring tests
(Naidenova & Parkhomenko, 2020): a) external
context is decomposed into sub-contexts in which
good tests are inferred independently; b) sub-contexts
are chosen based on analysing their characteristics; c)
the choice of sub-context determines the speed and
efficiency of classification task. The strategies to
select sub-contexts and learning algorithms are easy
to describe with the use of special multi-valued
attributes.
Decomposition of context into sub-contexts
allows to reduce the problem of large dimension to
ones of smaller dimension and thereby to decrease the
computational complexity of the classification
problem.
Let us now introduce an intellectual agent
implementing the following functions.
First, the agent needs to memorize the situations
of learning and the activity associated with them (at
the application (external) level). Then the agent has to
evaluate the learning process in terms of its
effectiveness, temporal parameters, the number of
sub-contexts to be considered, the consistency
between the parameters of external contexts (sub-
contexts) and the parameters of the learning process.
Generalizing and simplifying the above, let's
assume
that the internal context necessarily contains:
1.
Description of selected sub-context in terms
of its properties.
2.
Description of selected learning steps.
3.
Internal estimation of learning process with
the use of some given criteria of its efficiency.
3
THE STRUCTURE OF
INTERNAL CONTEXT
Let K be the descriptions of external sub-context via
its properties, А = {A1, A2, ….An} be the
descriptions of algorithms of good tests inferring via
their properties in this sub-context, R = {R1, R2,
….Rm} be the rules for selecting sub-contexts, and
Self-supervised Learning in Symbolic Classification
291
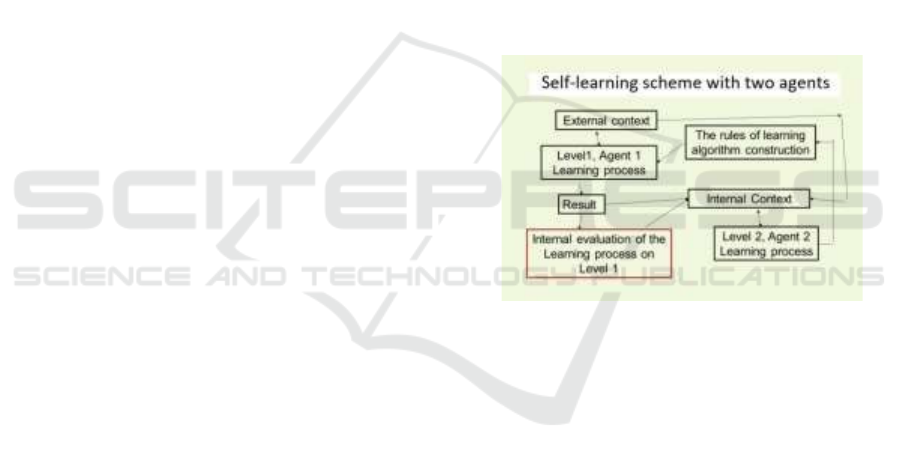
V= {V1, V2, …, Vq) be the set of rule for evaluating
the process of good test inferring.
Then the internal context is described by the direct
product of sets K, A, R and its mapping on V: K × A×
R → V. A and R describe the learning process, V is an
internal evaluation of the learning process.
In order this assessment to be feasible as an
internal evaluation, the self-learning agent must have
some special functions of analysing the processes
taking place in it. One of these functions can be a
counter of the number of sub-contexts processed
during good test inferring, a counter of time requested
for processing sub-context, the calculator of the
relationship between the number of received good
tests in sub-context and some of its quantitative
characteristics (number of objects, number of
attributes, number of different attribute values), etc.
There are more simple variants of the internal
context:
K × A → V and K × R → V.
Now, to infer the logical rules for distinguishing
the variants of learning in the external context
evaluated as good ones from the variants evaluated as
not good ones, we can use any algorithms of inferring
good classification tests in the internal context.
A few algorithms for good test inferring have been
elaborated: ASTRA, DIAGARA, NIAGARA, and
INGOMAR (Naidenova, 2006; Naidenova &
Parkhomenko, 2020).
On the basis of internal learning, the agent can
select rules for more successful learning in solving
the main problem in the application context.
The internal context is a memory of the agent, the
rules extracted from the internal context represent the
agent's knowledge about the effectiveness of its
actions in the external context.
The practical implementation of self-learning in
this work is not developed. In the simplest case, we
can separate two processes in time: accumulating data
and forming an internal context (with an assessment
of the quality of learning) and building rules for
choosing sub-contexts by their characteristics. Once
these rules are received, they can be used to learn in
an external context and form a new internal one.
The internal context for choosing sub-contexts
can contain the following information:
1.
The number of objects in sub-context.
2.
The number of values of attributes in sub-
context.
3.
The number of essential values of attributes
(Naidenova & Parkhomenko, 2020) in sub-
context.
4.
The number of essential objects in sub- context
(1Naidenova & Parkhomenko, 2020).
5.
The number of already obtained good tests
covered by sub-context.
6.
The number of values of attributes (objects)
uncovered by already obtained good tests in sub-
context.
7.
Some relationships between the characteristics of
sub-contexts listed above.
8.
The strategies (rules) to select sub- contexts.
9.
The evaluation of the process of external learning
(it gives the partition of accumulated data).
As a result of learning in this internal context we
obtain the rules revealing the connection between the
characteristics of sub-contexts and the strategies of
selecting them. Strategy can be: selecting sub-context
with the smallest number of essential values of some
attributes; selecting sub-context with the smallest
number of essential objects and some others.
Actions in the internal and external contexts can
be represented as actions of two agents functioning in
turn or in parallel and exchange data (Figure 1).
Figure 1. The interaction of two agents
Agent A1 transmits the data (the descriptions of
contexts, algorithms, rules for selecting sub-contexts)
to Agent A2. Agent A2 acts in the internal context
(obtained from agent A1) and passes to agent A1 the
rules, the latter applies these rules to select the best
variant of learning with each new external sub-
context.
For Agent A2, the internal context (memory)
should not be empty, but this agent (as well as Agent
A1) can work in an incremental mode of learning. A
few incremental algorithms for good test inferring in
symbolic contexts are proposed in (Naidenova, 2006;
Naidenova & Parkhomenko, 2020).
4
CONCLUSIONS
The results of this article are the following. A model
of self-learning was proposed allowing to manage the
process of inferring good tests in terms of its
BML 2021 - INTERNATIONAL CONFERENCE ON BIG DATA, MODELLING AND MACHINE LEARNING (BML’21)
292

effectiveness through an internal evaluation of the
learning process and the development of rules for
choosing the best strategies, algorithms, and learning
characteristics. The concepts of internal and external
learning contexts were formulated. The structure of
the internal context was proposed. A model of
intelligent agent, capable of improving own learning
process of inferring good classification tests in the
external context was advanced.
It was shown that the same learning algorithm can
be used for supervised learning in the external and
internal contexts. The model of self-learning
proposed in this article is closely related to the
especially important research in artificial intelligence:
forming internal criteria of the learning process
efficiency, modelling on-line plausible deductive-
inductive reasoning on the level of self- learning.
ACKNOWLEDGEMENTS
The research was partially supported by Russian
Foundation for Basic Research, research project №
18-07-00098A
REFERENCES
Berscheid, L., Rühr, T., and Kröger, T., 2019. Improving
data efficiency of self-supervised learning for robotic
grasping. arXiv:1303.00228v1[csRo] 1 Mar (2019).
Bicocchi, N., Fontana, D., Zambonelli, F., 2019. CAMeL:
A Self-adaptive framework for enriching context-aware
middle-wares with machine learning capabilities.
Hindawi Mobile Information Systems, V., Article ID
1209850 (2019). http://doi.org/10.1155/2019/1209850
Bretan, M., Oore, S., Sanan, S., and Heck, L., 2019. Robot
learning by collaborative Network Training: a self-
supervised Method using ranking. AAMAS, pp. 1333-
1340, Montreal, Canada.
Cosmadakis, P., Kanellakis, C., Spiratis, N., 1986. Partition
semantic for relations. Journal of Computer and System
Sciences, 33(2), 203-233.
Ganascia, J.-G., 1989. EKAW-89 tutorial notes: Machine
Learning. In J. Boose, J.-G. Ganascia (Eds. EKAW’89:
Third European Workshop on Knowledge Acquisition
for Knowledge-Based Systems, (pp. 287-293). Paris,
France.
Kotsiantis, S.B., 2007. Supervised Machine Learning: A
Review of Classification Techniques. Informatica, 31,
249-268. Retrieved from https://datajobs.com/data-
science-repo/Supervised-Learning-[SB-Kotsiantis].pdf
Naidenova, X., 1996. Reducing machine learning tasks
to the approximation of a given classification on a
given set of examples. In Proceeding of the 5th
National Conference on Artificial Intelligence, vol. 1,
pp. 275-279. Kasan, Tatarstan.
Naidenova, X., 2006. An incremental learning algorithm
for inferring logical rules from examples in the
framework of the common reasoning process. In
Triantaphyllou, E., & Felici, G. (eds.), Data mining and
knowledge discovery approaches based on rule
induction techniques (pp. 89–146). Springer, New
York.
Naidenova, X., 2012. Good classification tests as formal
concepts. In F. Domenach, D. Ignatov, and J. Poelmans
(eds.), LNAI 7212, pp. 211-226. Springer-Verlag,
Berlin Heidelberg.
Naidenova, X., Parkhomenko, V., 2020. Contribution to
attributive and object sub-contexts in inferring good
maximally redundant tests. Discrete Applied
Mathematics, 279, 217-231.
Naidenova, X., Polegaeva, J., 1986. An algorithm for
finding the best diagnostics tests. In G. E. Mintz, and
P.P. Lorents (eds.), The application of mathematical logic
methods, (pp. 63-67). Institute of Cybernetics,
National
Acad. of Sciences of Estonia, Tallinn, Estonia.
Pavlovsky, V. E., Savitsky, A.V., 2016. Neuro-net
algorithm for Quadro-Copter control on typical
trajectories. Nonlinear World, 13(6), 47-53 (in
Russian).
Pavlovsky, V.E., Pavlovsky, V.V., 2016. Technologies
SLAM for mobile robot: state and perspectives.
Mechatronics, automation, management, 17(6), 384-
394 (in Russian) (2016).
Pavlovsky, V.E., Smolin, V. S., Aliseychik A.P et al., 2016.
Intelligent technology to control the behaviour of the
robotic manipulator MANGO. In Proceedings of the
15th National Conference on Artificial Intelligence
with International Participation (CAI-2016), V. 3, 302-
311. UNIVERSUM, Smolensk, Russia (in Russian).
Pathak, D. Agraval, P. Efros, A.A., and Darrell, T.,
2017.
Curiosity-driven exploration by self-supervised prediction.
In Proceedings. of the 34th International Conference on
Machine Learning, (pp. 12). Retrieved from
https://pathak22.github.io/noreward-rl/
Pillai, S., 2017. Towards richer and self-supervised
perception in robots. PhD Thesis Proposal. Retrieved
from
http://people.csail.mit.edu/spillai/data/papers/2017-
phdthesis-proposal-nocover.pdf
Pillai, S. and Leonard, J., 2017. Towards Visual Ego-
motion Learning in Robots. Submitted to IEEE/RSJ Intl.
Conf. on Intelligent Robots and Systems (IROS).
Retrieved from
http://people.csail.mit.edu/spillai/learning-
egomotion/learning-egomotion.pdf
Shaukat, A., Burroughes, G., Gao, Y., 2015. Self
reconfigurable robotics architecture utilizing fuzzy and
deliberative reasoning. In Proceedings of the SAI
Intelligent Systems Conference, pp. 258-265. IEEE,
London, UK (2015).
Sofman, B., Line, E. et al., 2017. Improving Robot
Navigation Through Self-Supervised Online Learning.
Self-supervised Learning in Symbolic Classification
293

Journal of Field Robotics, 23(11-12), 1059-1075. Doi:
10.1002/rob.20169
Vukman K.B., Demetriou A., 2011. Cognitive ability, self-
understanding, and personality: dynamic interactions in
adulthood. Anthropos 1-2 (221-222), 35-50.
BML 2021 - INTERNATIONAL CONFERENCE ON BIG DATA, MODELLING AND MACHINE LEARNING (BML’21)
294
