
Towards Tracking Provenance from Machine Learning Notebooks
Dominik Kerzel
1 a
, Sheeba Samuel
1,2 b
and Birgitta K
¨
onig-Ries
1,2 c
1
Heinz Nixdorf Chair for Distributed Information Systems, Friedrich Schiller University Jena, Germany
2
Michael Stifel Center Jena, Friedrich Schiller University Jena, Germany
Keywords:
Machine Learning, Information Extraction, Provenance, Jupyter Notebook, Reproducibility.
Abstract:
Machine learning (ML) pipelines are constructed to automate every step of ML tasks, transforming raw data
into engineered features, which are then used for training models. Even though ML pipelines provide benefits
in terms of flexibility, extensibility, and scalability, there are many challenges when it comes to their repro-
ducibility and data dependencies. Therefore, it is crucial to track and manage metadata and provenance of
ML pipelines, including code, model, and data. The provenance information can be used by data scientists
in developing and deploying ML models. It improves understanding complex ML pipelines and facilitates
analyzing, debugging, and reproducing ML experiments. In this paper, we discuss ML use cases, challenges,
and design goals of an ML provenance management tool to automatically expose the metadata. We introduce
MLProvLab, a JupyterLab extension, to automatically identify the relationships between data and models in
ML scripts. The tool is designed to help data scientists and ML practitioners track, capture, compare, and
visualize the provenance of machine learning notebooks.
1 INTRODUCTION
ML algorithms train models on sample data to allow
predictions and thus support decision-making. A ma-
chine learning pipeline consists of several steps to
train a model and is used to manage and automate
ML processes. These steps are iterated several times
to improve evaluation metrics (e.g., accuracy, preci-
sion) of the model and achieve better results. Con-
sequently, there is a constant change in each phase of
the ML pipeline, resulting in significant differences in
the outcome. This makes ML pipelines more complex
to reproduce and understand.
Provenance and metadata play vital roles in the
reproducibility of results. The provenance of a data
product is the description of the entities and the pro-
cesses/steps together with the data and parameters
that led to its creation (Herschel et al., 2017). Meta-
data is the data about data. Missing information about
the development of proposed methods, data, and re-
sults can influence reproducibility. In ML, it is crucial
to understand the data lineage to recognize why some
predictions were made. It should be clear which data
was explicitly used, how it got manipulated, and what
a
https://orcid.org/0000-0002-0680-5753
b
https://orcid.org/0000-0002-7981-8504
c
https://orcid.org/0000-0002-2382-9722
changes were made over time. To make scientific ex-
periments reproducible, it is important to track infor-
mation on the evolution of the code and its structure
(Definition Provenance), the execution environment,
including the system, external dependencies (Deploy-
ment Provenance), and the execution itself like vari-
able values, outputs, run time information, etc. (Ex-
ecution Provenance) (Pimentel et al., 2015). Defini-
tion, deployment, and execution provenance can also
be used for enabling reproducibility of ML pipelines.
In this paper, we describe metadata and prove-
nance management for end-to-end ML pipelines. We
discuss which provenance information is required for
the reproducibility of ML experiments. We present
the design goals for our tool that support reproducibil-
ity and provenance management of ML models. In
this regard, we introduce our proof of concept, called
MLProvLab, which supports the design goals and
provides a framework to capture, manage, compare,
and visualize the provenance in notebook code envi-
ronments, i.e., JupyterLab
1
(Kluyver et al., 2016). We
discuss our evaluation plan and future work to support
metadata and provenance management of end-to-end
ML pipelines.
1
https://jupyterlab.readthedocs.io
274
Kerzel, D., Samuel, S. and König-Ries, B.
Towards Tracking Provenance from Machine Learning Notebooks.
DOI: 10.5220/0010681400003064
In Proceedings of the 13th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2021) - Volume 1: KDIR, pages 274-281
ISBN: 978-989-758-533-3; ISSN: 2184-3228
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

2 BACKGROUND AND RELATED
WORK
With the fast development of ML algorithms and the
easy accessibility of ML frameworks and infrastruc-
ture, there is a growing need for provenance and
model management from the ML community. There
exists increasing attention on reproducibility not only
in fields like biology, chemistry (Baker, 2016; Samuel
and K
¨
onig-Ries, 2021), but also in ML and AI (Hut-
son, 2018; Raff, 2019). Schelter et al. (Schel-
ter et al., 2018) present an overview of conceptual,
data management, and engineering challenges in the
ML model management. Automatically tracking and
querying model metadata is one of the data manage-
ment challenges with respect to the provenance man-
agement of ML. However, many existing ML frame-
works have not been designed to automatically track
provenance.
In recent years, several tools have been developed
as metadata capturing systems (Vartak et al., 2016;
Zaharia et al., 2018). Versioning tools like Git help
in managing definition provenance. However, they
do not capture information on ML model metadata.
Tools like noWorkflow (Pimentel et al., 2015) provide
tracking and capturing provenance of python scripts
in general. On the other hand, other approaches are
deeply tied to the data and the models used in machine
learning itself (Ormenisan et al., 2020a; Ormenisan
et al., 2020b; Baylor et al., 2017; Olorisade et al.,
2017; Vartak et al., 2016; Zaharia et al., 2018; Na-
maki et al., 2020). ModelDB (Vartak et al., 2016)
is one such system that provides a feature to manage
ML models with metadata logging of metrics, arti-
facts, tags, and user information. Some approaches
directly look into the file system and collect prove-
nance data based on file changes (Ormenisan et al.,
2020a). This can help understand how files are specif-
ically used in model creation. Some systems track de-
tailed provenance data by depending on the users to
understand their complex schema and integrate their
code with the corresponding API provided by the sys-
tem (Schelter et al., 2017). In general, these prove-
nance capturing systems require the user to actively
configure their code, e.g., annotate hyperparameters,
functions, and operations. But often, users omit to
configure and annotate their code due to extra time
and effort required. Therefore, tools that automati-
cally extract and manage metadata have an advantage
over systems that require human intervention.
Vamsa (Namaki et al., 2020), available as a
command-line application, tracks provenance from
Python scripts without requiring any changes to users’
code. For this, the tool depends on an external knowl-
edge base containing APIs of various ML libraries
that need to be added manually. However, this tool
does not provide user interactivity. Project Jupyter
(Kluyver et al., 2016) provides different tools like
Jupyter notebooks and JupyterLab, which are widely
used in developing ML pipelines. They are used by
beginners, experts, and practitioners to write simple
to complex ML scripts in their everyday work. How-
ever, these notebooks do not directly provide general
provenance capturing features, let alone ML model
management. ProvBook (Samuel and K
¨
onig-Ries,
2018) is a recent tool developed as an extension for
Jupyter notebooks to capture, manage, query, com-
pare, and visualize user history with interactivity. It
is essential to provide provenance management with-
out changing the code environment for the user. It
is also important that such platforms provide meta-
data management to all their users irrespective of their
skills and experience in ML. JupyterLab is a great ba-
sis for such projects as has been shown in other works
(Kery et al., 2019). Hence, in this paper, we target the
users of JupyterLab and allow automatic provenance
extraction from ML notebooks and user interactivity.
3 PROVENANCE OF ML
PIPELINES
In this section, we briefly describe the ML pipeline
and explain the metadata and provenance information
required for the reproducibility of ML scripts. Meta-
data and provenance management of ML pipelines is
the problem of tracking and managing metadata and
provenance of ML steps and models so that they can
be reproduced, analyzed, compared, and shared after-
ward.
An ML pipeline, which is a multi-step process, auto-
mates the workflow to produce an ML model
2
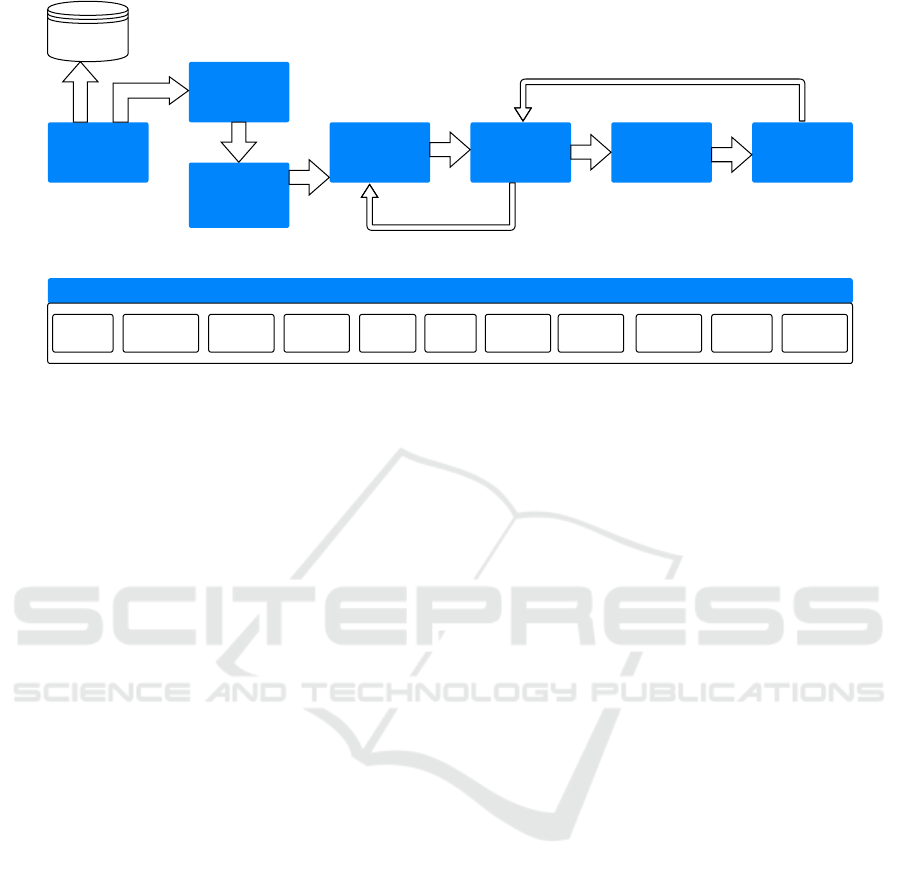
. Fig-
ure 1 shows the different stages and the provenance
required for an end-to-end ML pipeline. The pipeline
consists of the following stages: data discovery, col-
lection, preprocessing, cleaning, feature engineering,
model building, training, and evaluation, deployment,
and monitoring. In a manual workflow, where no ad-
ditional ML infrastructure is required, these steps are
often performed in notebooks or scripts. The note-
book/script is either executed locally or remotely to
produce an ML model, which is the output of the
pipeline. After the data discovery phase, raw data
which is collected from different sources needs to be
brought in the form ready for an ML task. For this
2
https://cloud.google.com/architecture/
data-preprocessing-for-ml-with-tf-transform-pt1
Towards Tracking Provenance from Machine Learning Notebooks
275
Data Discovery
Data Collection
Data
Preprocessing,
Cleaning &
Visualization
Feature
Engineering
Model Building
& Training
Model
Deployment
Model
Monitoring &
Maintaining
Provenance of end-to-end ML pipeline
Raw Data FeaturesLibraries Models
Feature
Metadata
Preprocessing
Details
Model
Metadata
Execution
History
Algorithm
Train/Test
Datasets
Output
Files
ML Pipeline
Figure 1: Provenance of end-to-end ML pipeline.
transformation, the raw data needs to be converted to
processed data which involves data engineering op-
erations. The processed data is then tuned to create
engineered features for the ML model using feature
engineering. The preprocessing stage contains sev-
eral sub-steps, which are essential but often ignored
by scientists for provenance documentation. Cor-
rupted, invalid, or missing values need to be removed
or corrected from the raw data in the data cleaning
step. In the next step, the data points are selected
and partitioned to create training, validation, and test
datasets, using different techniques like random sam-
pling, stratified partitioning, etc. Based on different
ML problems, this phase involves further operations
like tuning, extraction, selection, and construction of
features using different methods and algorithms. Af-
ter the data and feature engineering stages, the train-
ing, evaluation, and test sets are used to train the
model. The trained model is then deployed. This is
later then monitored and maintained.
In ML, the building and training of models is
an iterative process. It requires several iterations to
achieve results that satisfy acceptance criteria like
accuracy, precision, etc. This workflow is ad-hoc,
and there exist several challenges in managing mod-
els build over several iterations. Reproducibility is
a time-consuming task, especially for ML pipelines,
where model building and training can span hours or
days. Hence, it is essential for data scientists to track
and manage not only the results but also the parameter
combinations used in the various stages of previous
ML experiments. The paper (Olorisade et al., 2017)
presents a set of factors that affect reproducibility in
ML-based studies focusing on text mining. Another
paper (Pineau et al., 2020) introduces a checklist re-
quired for reproducibility in the submission process
of an ML publication. Inspired by these works, we
describe here a set of factors required for provenance
management of ML applications developed in note-
book code environments.
The provenance of the complete ML pipeline
needs to be tracked to answer questions like How was
the model trained?, Which are the hyperparameters
used?, Which features were used?, Where did the fea-
tures come from?, Where did the bias come from?,
etc (Samuel et al., 2021). Raw data, preprocess-
ing details, train/evaluation/test datasets, methods, al-
gorithms, features, feature metadata, model, model
metadata, execution history, random seeds, execution
environment information, etc. are some of the im-
portant artifacts that need to be tracked for the repro-
ducibility of an end-to-end ML pipeline (Fig. 1). The
metadata, e.g., the location, version, size, and purpose
of the datasets used, should also be tracked. This is
helpful to identify any discrepancy that could occur in
the result in the later experiments if there is a change
in the datasets in the original location. The data trans-
formation operations which convert raw data to en-
gineered features are often overlooked during their
documentation and publication. The provenance in-
formation in this step is crucial. Another important
factor is to track how the dataset is partitioned to cre-
ate training, validation, and test datasets. Algorithms,
code, and the parameters used in the model build-
ing and training stage need to be captured. Random-
ization plays a crucial role in many ML algorithms,
which can affect the end result. Therefore, it is crucial
to set or use pseudo-random alternatives that allow
deterministic behavior and thus produce same results
and allow reproducibility. Execution environment
like software and hardware information are other im-
portant provenance data. This includes information
KDIR 2021 - 13th International Conference on Knowledge Discovery and Information Retrieval
276
on the programming language, kernel, versions, op-
erating system, and machine type (CPU, GPU, cloud,
etc.). The execution history, which explains what hap-
pened in each run of an ML pipeline, is another criti-
cal piece of information required by data scientists for
the reproducibility of ML models.
4 DESIGN GOALS
We list here the design goals and the features for
the proposed tool in JupyterLab for the metadata
and provenance management of an end-to-end ML
pipeline:
Support the provenance lifecycle. The provenance
enabled life cycle management of ML experiments is
the key factor required for reproducibility. Hence the
tool should support the following provenance criteria:
• Tracking: The provenance information should
be automatically extracted from the notebook and
provided to users. This information includes the
data, intermediate results, parameters, methods,
algorithms, steps, execution history, and final re-
sults of the ML pipeline as mentioned in Sec-
tion 3. In addition, the tool should also automati-
cally identify the dependencies between variables,
functions, etc., among different cells of a note-
book.
• Storage: The tool should provide an efficient way
to store the collected provenance.
• Querying: The collected provenance data should
be made available to query. This would help users
to answer questions like ‘Which dataset was used
for building the ML model?’.
• Compare: The tool should provide users the fea-
ture to compare different versions of the execution
of notebooks. This will help to compare results
from the original one.
• Visualization: To support usability, users should
be able to visualize the provenance in a way that
they can understand how and why the result has
been derived.
Support Reproducibility. The provenance infor-
mation should help not only the user but also others to
repeat and reproduce the results. With different ver-
sions of code, data, and execution history, we envision
the tool to provide the ability to reproduce the note-
book to run the ML pipeline for getting the original
results.
Support Collaboration. We expect collaboration
support among researchers by sharing the Jupyter
notebooks along with the provenance information of
the ML pipeline.
Support Semantic Annotation and Interoperabil-
ity. To aid interoperability, the tool should be able
to support semantic annotation of ML pipelines us-
ing ontologies. We intend to describe the provenance
information using the REPRODUCE-ME ontology
(Samuel, 2019).
Support Exporting Provenance in Different For-
mats. According to the FAIR data principles, even if
the data is deleted or removed for privacy concerns,
the metadata should be made available (Wilkinson
et al., 2016). Hence, we intend to provide support
for exporting the provenance information. The prove-
nance information can be exported in different for-
mats, e.g., JSON, JSON-LD, RDF, so that the data is
available for querying.
Ease of Use. The tool should be able to support dif-
ferent target groups, including beginners, experts, etc.
Users should also have the possibility to interact with
the tool.
Support Extensibility. We intend to design the tool
in a way that new features can be easily added. The
tool can be extended with additional functionalities to
support each phase of the ML pipeline.
5 MLProvLab
We introduce our proof of concept for the provenance
management of end-to-end ML pipelines in a note-
book code environment. We present our tool, ML-
ProvLab, a JupyterLab extension, to track, compare,
and visualize the provenance of ML notebooks, as
motivated by our design goals. The tool is available
as an open source extension for Jupyter notebooks
3
.
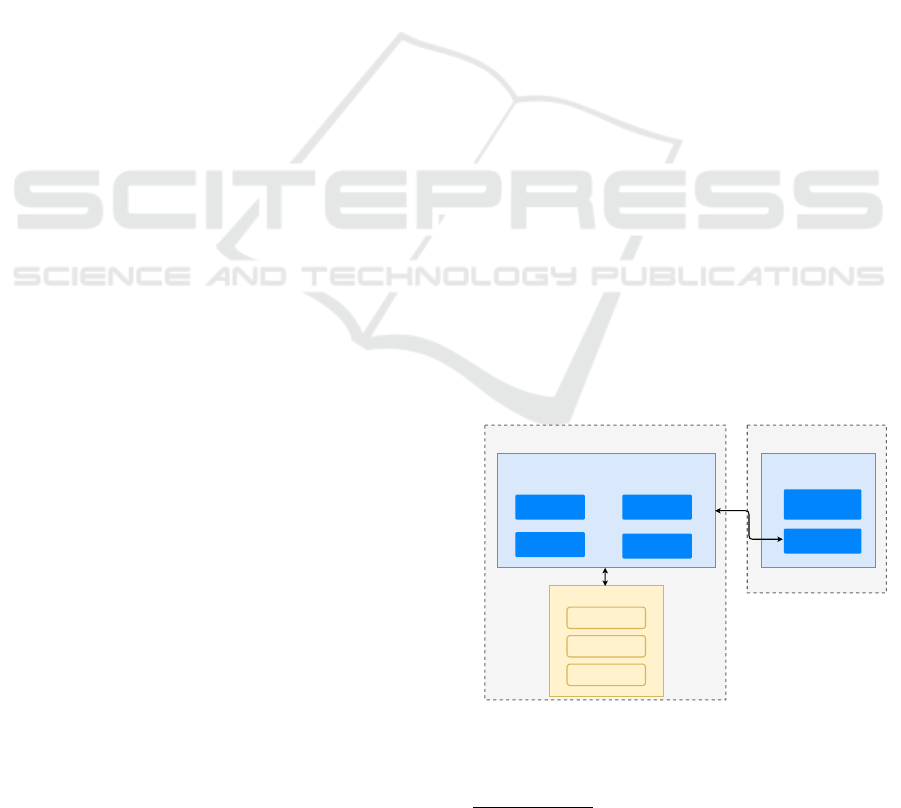
JupyterLab Frontend JupyterLab Backend
MLProvLab Frontend
Other Jupyter Plugins
UI Widgets
Notebook
Interaction
Kernel
Messaging
MLProvLab Backend
Provenance
Capture
Provenance
Export
Provenance
Comparison
Provenance
Visualization
AST Generation
& Analysis
HTTP API
Figure 2: Architecture of MLProvLab.
Architecture. The MLProvLab tool is developed
as an extension of JupyterLab so that it is available
3
https://github.com/fusion-jena/MLProvLab
Towards Tracking Provenance from Machine Learning Notebooks
277
for data practitioners, researchers, and data scientists
to support them in their daily work. JupyterLab is
an open-source development environment for Jupyter
Notebooks. Figure 2 shows the architecture of ML-
ProvLab, which consists of a backend and a frontend
plugin. The frontend mainly interacts with the core
messaging plugin to get information from the kernel
and the notebook panel. General visualization wid-
gets are added in the frontend to display data to easily
integrate it into the IDE layout. The MLProvLab tool
is invoked to analyze the executed code with the help
of an Abstract Syntax Tree (AST) and string pattern
matching techniques to get data provenance. Fig-
Cell Execution
AST
Generation &
Analysis
Request
information
from kernel
Save
provenance to
notebook
metadata
Update
visualization
Figure 3: Workflow of MLProvLab.
Figure 4: MLProvLab Toolbar button in JupyterLab.
ure 3 shows the workflow of MLProvLab. The tool
defines event listeners that listen to different user ac-
tions like the execution, the addition and deletion of a
cell. It generates an AST and analyses it, and then re-
quests information from the kernel. The provenance
information captured is saved to notebook metadata,
and the visualization is updated.
Provenance Capture. MLProvLab collects and
stores the provenance of a new user session triggered
by the restart of a kernel as well as old user sessions
(kernels). We call the lifetime of a kernel an epoch.
Epochs are created for every new kernel and stored
Figure 5: Main widget of MLProvLab.
in the provenance object in the notebook metadata.
When the tool listens to the cell execution event, the
code of the cell is sent back to the backend, which
uses the Tornado web server
4
. We use AST for ana-
lyzing the code. Based on the information from the
AST, we collect information on the definition and us-
ages of variables, functions, and classes. We also
track the import statements to extract information on
the libraries and modules used along with their ver-
sion information. In addition, the tool also tracks
loops and conditions. We perform additional opera-
tions to find data sources for ML provenance manage-
ment using string matching. Finally, we track every
defined variable declared in the cell, the dependen-
cies of variables that are not defined in the evaluated
cell, used datasets and the corresponding variables,
imported libraries, and modules, etc., as mentioned in
Section 3. For the information collected using AST,
we create a new object which contains the name of
the called entity, a list of names with used entities,
and other useful parameters such as position in code,
etc. These are then combined and transferred back to
the frontend, where it is inserted into a similar struc-
tured object. This also contains the execution count
of the cell, cell id, outputs, and the executed code. In-
formation request from the kernel about the defined
variables in the cell is also added. This gives a snap-
shot of the state and its containing data. The newly
created object is then stored in the corresponding or-
der into the epoch where it was executed. This is then
visualized to the user. In the first version of our tool,
we include tracking, exporting, and visualization of
4
https://www.tornadoweb.org
KDIR 2021 - 13th International Conference on Knowledge Discovery and Information Retrieval
278
the provenance information of ML notebooks.
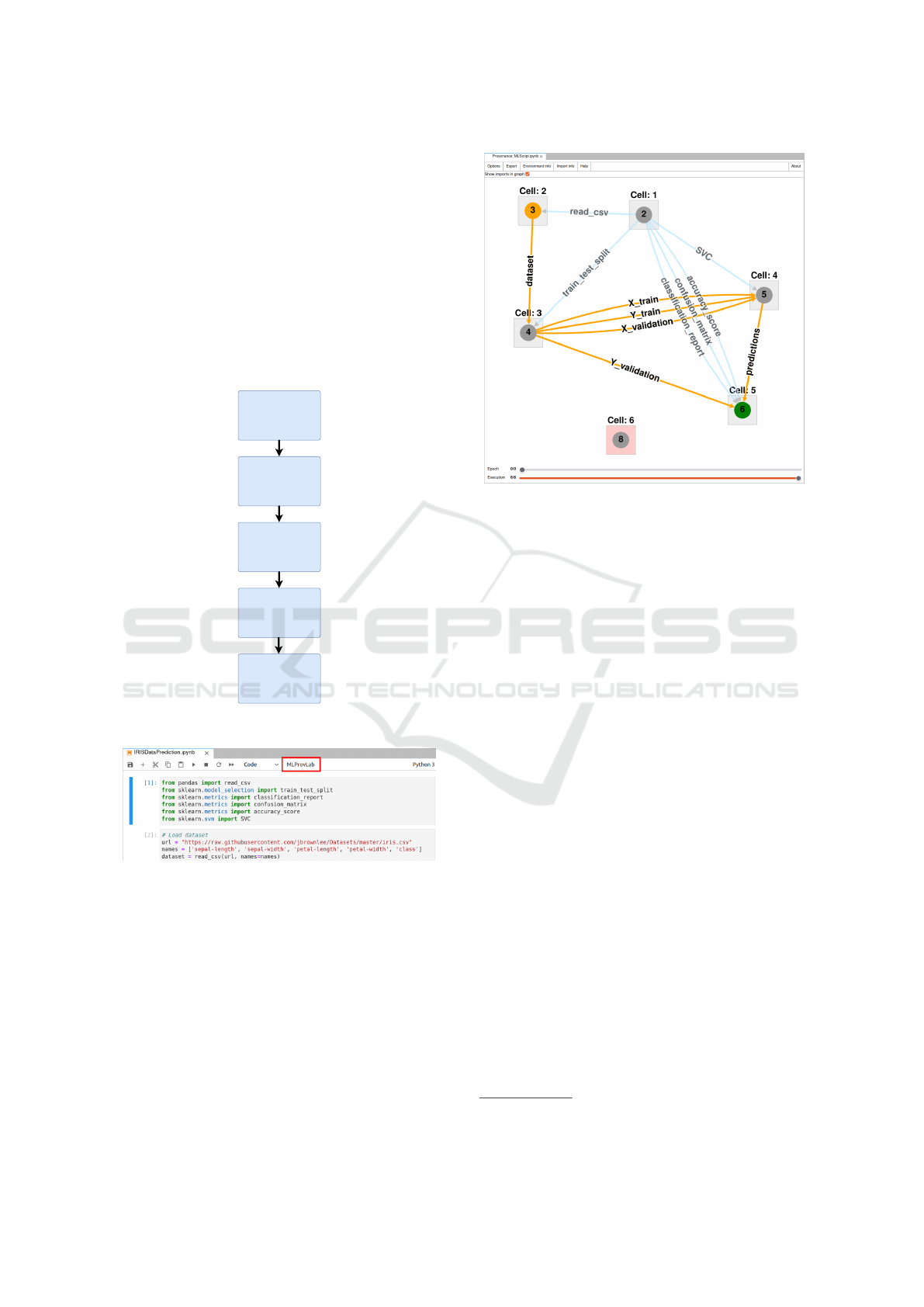
Provenance Visualization. MLProvLab uses a
provenance graph to visualize the provenance of the
notebook, including the execution order of cells and
the data dependencies between cells. A new node is
created in the graph for every new cell. New edges
are created to connect the cell nodes. MLProvLab
provides users the flexibility to chose the visualiza-
tion based on the execution order of cells or the data
dependencies between cells. Colors of the nodes and
edges are updated accordingly based on the content of
the cells, possible outputs, and data sources.
Figure 4 shows the MLProvLab extension in
JupyterLab. The tool can be invoked using the ‘ML-
ProvLab’ button in the notebook toolbar. By invok-
ing the button, the main widget is opened containing
the provenance graph. Figure 5 shows the provenance
visualization graph of a sample ML notebook. The
data sources and execution provenance are shown in
the graph. Two sliders are provided at the bottom of
the widget. The ‘Epoch’ slider provides the history
of the execution of the Jupyter Notebook every time
a new user session of the kernel is started. The ‘Exe-
cution’ slides provide the history of the execution of
the Jupyter Notebook every time an event on the cell
of the notebook is registered. The tool also shows
the number of user sessions, executions, and execu-
tion time. Users are provided with a general menu
with several options to customize the graph to get ad-
ditional provenance information. The graph is built
using Cytoscape.js (Franz et al., 2016). Cytoscape.js
is well optimized and can display a large number of
nodes and edges with little impact on performance.
With its features, users can zoom in and out and get
more information on each graph node.
For each cell in the notebook, a corresponding
node is created in the graph. Detailed information on
the latest execution of the cell is obtained based on
the selected time frame on the bottom of the widget.
Cells that contain data sources are displayed in or-
ange. While the cells that contain output are colored
green. Users can also change options in the menu
bar to show the imported libraries and modules. It
also shows in which cells the libraries and modules
are used and provides information on those imported
but not used in the notebook. Further provenance in-
formation can be visualized through a radial context
menu. It can be opened by a right-click on a node or
an edge. Clicking on a node, the user can select to vi-
sualize the definition provenance. This gives detailed
information on the used datasets, functions, variables,
etc. Users can also compare the definition provenance
from previous runs as well. Figure 6 provides the in-
formation of this widget. The data displayed is the
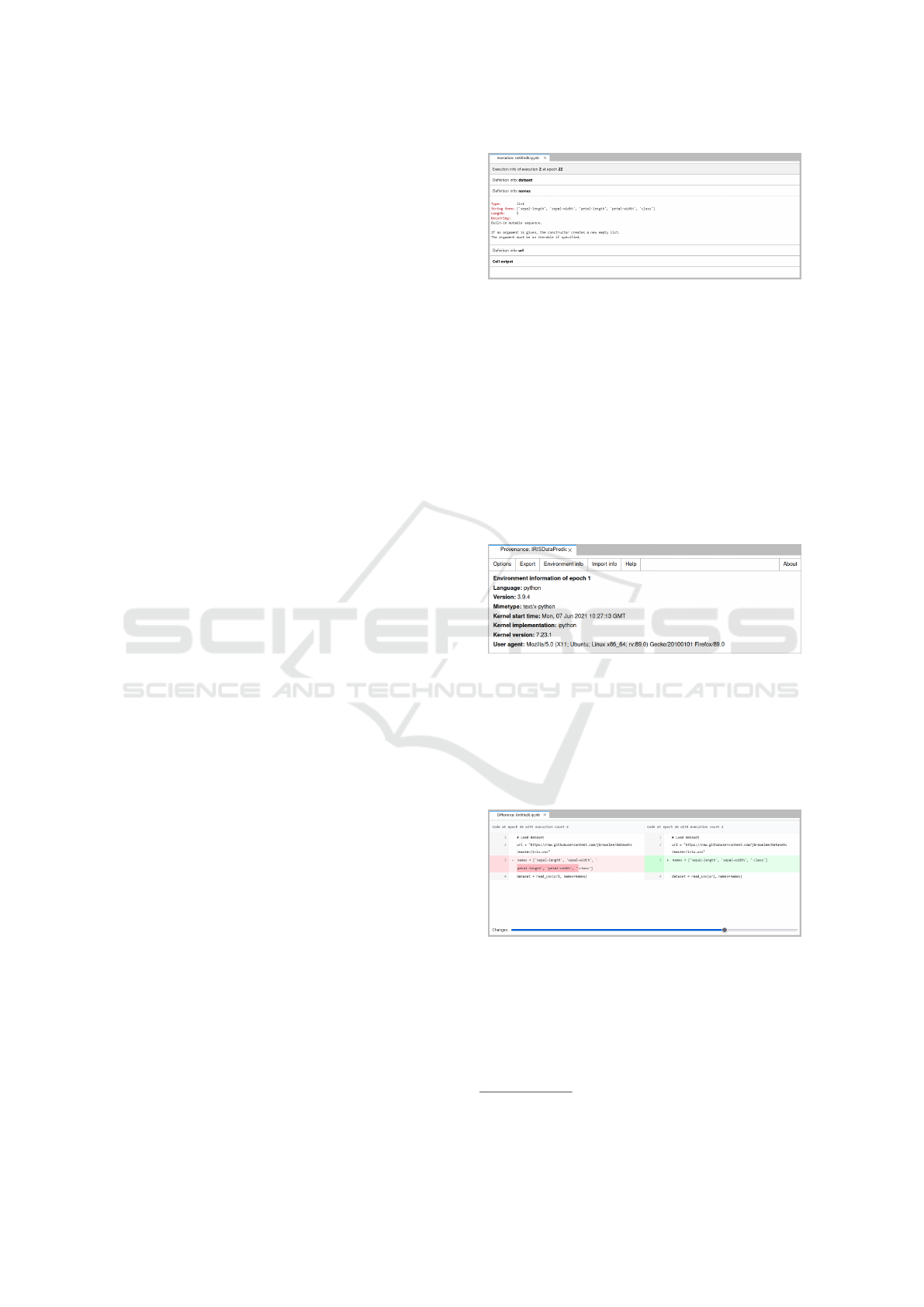
Figure 6: Definition and execution provenance widget.
plain text gathered from an information request to the
kernel for each definition after a cell execution. Click-
ing on an edge gives users information on the specific
variable. Edges that connect the cells with the depen-
dencies are colored orange for data sources and blue
for libraries and modules. This makes it easier for the
user to track the whole flow of data from the input
to the final output (Fig. 5). Figure 7 shows the exe-
cution environment information of the ML notebook.
This includes information about the system, kernel,
the used programming language, and its version for
the currently selected epoch.
Figure 7: Execution environment information widget.
Provenance Comparison. Figure 8 shows the code
difference widget for cells in a notebook. Users can
explore the changes that were made to the code of a
cell. With the slider on the bottom, users can select
the previous ML experiments. This is visualized us-
ing the react-diff-view
5
component.
Figure 8: Code difference widget.
Provenance Export. Users can export the prove-
nance information of the ML notebook. Users can
also clear the provenance history. However, users are
provided with an alert to export the provenance before
removing the provenance history from the notebook.
The provenance information is currently available in
5
https://github.com/otakustay/react-diff-view
Towards Tracking Provenance from Machine Learning Notebooks
279

JSON format. In the future, we plan to make this in-
formation available in other formats, including JSON-
LD, RDF, etc., for semantic interoperability.
The MLProvLab tool will be released as an open-
source extension for JupyterLab with an MIT license.
Since it is a work-in-progress tool, we aim to imple-
ment all the features of the provenance management
of end-to-end ML pipeline as discussed in Section 4
in our future work. We could use ML itself to ana-
lyze the work that is being tracked to give informa-
tion about how the performance is or where problems
could emerge. We plan to use logs and logging met-
rics for more information on gathering the provenance
of ML models. We plan to do an extensive user evalu-
ation to understand the user behavior and improve the
tool. We also plan to do a performance-based evalua-
tion with the publicly available notebooks in GitHub.
6 CONCLUSIONS
Jupyter notebooks are widely used by data scientists
and ML practitioners to write simple to complex ML
experiments. Our goal is to provide metadata and
provenance management of the ML pipeline in note-
book code environments. In this paper, we introduced
the design goals and features required for the prove-
nance management of the ML pipeline. Working to-
wards this goal, we introduced MLProvLab, an ex-
tension in JupyterLab, to track, manage, compare, and
visualize the provenance of ML scripts. Through ML-
ProvLab, we efficiently and automatically track the
provenance metadata, including datasets and modules
used. We provide users the facility to compare differ-
ent runs of ML experiments, thereby ensuring a way
to help them make their decisions. The tool helps re-
searchers and data scientists to collect more informa-
tion on their experimentation and interact with them.
This tool is designed so that the user need not to
change their scripts or configure with additional anno-
tations. In our future work, we aim to analyze meta-
data in more detail. We aim to track data sources by
hooking into the file system or the underlying func-
tions in the programming language itself. This will be
integrated in a way that the user experience and per-
formance are not compromised. We plan to use this
provenance information to replay and rerun a note-
book.
ACKNOWLEDGEMENTS
The authors thank the Carl Zeiss Foundation for the
financial support of the project ‘A Virtual Werkstatt
for Digitization in the Sciences (K3)’ within the scope
of the program line ‘Breakthroughs: Exploring Intel-
ligent Systems for Digitization - explore the basics,
use applications’ and University of Jena for the IM-
PULSE funding: IP-2020-10.
REFERENCES
Baker, M. (2016). 1,500 scientists lift the lid on repro-
ducibility. Nature News, 533(7604):452.
Baylor, D., Breck, E., Cheng, H., Fiedel, N., Foo, C. Y.,
Haque, Z., Haykal, S., Ispir, M., Jain, V., Koc, L.,
Koo, C. Y., Lew, L., Mewald, C., Modi, A. N.,
Polyzotis, N., Ramesh, S., Roy, S., Whang, S. E.,
Wicke, M., Wilkiewicz, J., Zhang, X., and Zinkevich,
M. (2017). TFX: A tensorflow-based production-
scale machine learning platform. In Proceedings of
the 23rd ACM SIGKDD International Conference on
Knowledge Discovery and Data Mining, Halifax, NS,
Canada, August 13 - 17, 2017, pages 1387–1395.
Franz, M., Lopes, C. T., Huck, G., Dong, Y., Sumer, O., and
Bader, G. D. (2016). Cytoscape. js: a graph theory
library for visualisation and analysis. Bioinformatics,
32(2):309–311.
Herschel, M., Diestelk
¨
amper, R., and Ben Lahmar, H.
(2017). A survey on provenance: What for? what
form? what from? The VLDB Journal, 26(6):881–
906.
Hutson, M. (2018). Artificial intelligence faces repro-
ducibility crisis. Science, 359(6377):725–726.
Kery, M. B., John, B. E., O’Flaherty, P., Horvath, A., and
Myers, B. A. (2019). Towards Effective Foraging by
Data Scientists to Find Past Analysis Choices. In
Proceedings of the 2019 CHI Conference on Human
Factors in Computing Systems, pages 1–13, Glasgow
Scotland Uk. ACM.
Kluyver, T., Ragan-Kelley, B., et al. (2016). Jupyter
notebooks-a publishing format for reproducible com-
putational workflows. In ELPUB, pages 87–90.
Namaki, M. H., Floratou, A., Psallidas, F., Krishnan, S.,
Agrawal, A., Wu, Y., Zhu, Y., and Weimer, M.
(2020). Vamsa: Automated provenance tracking in
data science scripts. In Proceedings of the 26th
ACM SIGKDD International Conference on Knowl-
edge Discovery & Data Mining, pages 1542–1551.
Olorisade, B. K., Brereton, P., and Andras, P. (2017). Re-
producibility in machine learning-based studies: An
example of text mining.
Ormenisan, A. A., Ismail, M., Haridi, S., and Dowling, J.
(2020a). Implicit provenance for machine learning ar-
tifacts. Proceedings of MLSys, 20.
Ormenisan, A. A., Meister, M., Buso, F., Andersson, R.,
Haridi, S., and Dowling, J. (2020b). Time travel and
provenance for machine learning pipelines. In Tala-
gala, N. and Young, J., editors, 2020 USENIX Confer-
ence on Operational Machine Learning, OpML 2020,
July 28 - August 7, 2020. USENIX Association.
KDIR 2021 - 13th International Conference on Knowledge Discovery and Information Retrieval
280

Pimentel, J. a. F. N., Braganholo, V., Murta, L., and Freire,
J. (2015). Collecting and analyzing provenance on in-
teractive notebooks: When ipython meets no work-
flow. In Proceedings of the 7th USENIX Confer-
ence on Theory and Practice of Provenance, TaPP’15,
page 10, USA. USENIX Association.
Pineau, J., Vincent-Lamarre, P., Sinha, K., Larivi
`
ere, V.,
Beygelzimer, A., d’Alch
´
e Buc, F., Fox, E., and
Larochelle, H. (2020). Improving reproducibility
in machine learning research (a report from the
neurips 2019 reproducibility program). arXiv preprint
arXiv:2003.12206.
Raff, E. (2019). A step toward quantifying independently
reproducible machine learning research. In Advances
in Neural Information Processing Systems 32: An-
nual Conference on Neural Information Processing
Systems 2019, NeurIPS 2019, 8-14 December 2019,
Vancouver, BC, Canada, pages 5486–5496.
Samuel, S. (2019). A provenance-based semantic ap-
proach to support understandability, reproducibility,
and reuse of scientific experiments. PhD thesis, Uni-
versity of Jena, Germany.
Samuel, S. and K
¨
onig-Ries, B. (2021). Understanding ex-
periments and research practices for reproducibility:
an exploratory study. PeerJ, 9:e11140.
Samuel, S. and K
¨
onig-Ries, B. (2018). Provbook:
Provenance-based semantic enrichment of interactive
notebooks for reproducibility. In International Se-
mantic Web Conference (P&D/Industry/BlueSky).
Samuel, S., L
¨
offler, F., and K
¨
onig-Ries, B. (2021). Ma-
chine learning pipelines: Provenance, reproducibility
and FAIR data principles. In Glavic, B., Braganholo,
V., and Koop, D., editors, Provenance and Annota-
tion of Data and Processes - 8th and 9th International
Provenance and Annotation Workshop, IPAW 2020 +
IPAW 2021, Virtual Event, July 19-22, 2021, Proceed-
ings, volume 12839 of Lecture Notes in Computer Sci-
ence, pages 226–230. Springer.
Schelter, S., Biessmann, F., Januschowski, T., Salinas, D.,
Seufert, S., and Szarvas, G. (2018). On challenges
in machine learning model management. IEEE Data
Eng. Bull., 41:5–15.
Schelter, S., Boese, J.-H., Kirschnick, J., Klein, T., and
Seufert, S. (2017). Automatically tracking metadata
and provenance of machine learning experiments. In
Machine Learning Systems Workshop at NIPS, pages
27–29.
Vartak, M., Subramanyam, H., Lee, W.-E., Viswanathan,
S., Husnoo, S., Madden, S., and Zaharia, M. (2016).
Modeldb: a system for machine learning model man-
agement. In Proceedings of the Workshop on Human-
In-the-Loop Data Analytics, pages 1–3.
Wilkinson, M. D. et al. (2016). The FAIR Guiding Princi-
ples for scientific data management and stewardship.
Scientific data, 3.
Zaharia, M., Chen, A., Davidson, A., Ghodsi, A., Hong,
S. A., Konwinski, A., Murching, S., Nykodym, T.,
Ogilvie, P., Parkhe, M., Xie, F., and Zumar, C.
(2018). Accelerating the machine learning lifecycle
with mlflow. IEEE Data Eng. Bull., 41(4):39–45.
Towards Tracking Provenance from Machine Learning Notebooks
281
