
DA4RDM: Data Analysis for Research Data Management Systems
M. Amin Yazdi
a
, David Schimmel
b
, Marcel Nellesen
c
, Marius Politze
d
and Matthias Müller
e
IT Center, RWTH Aachen University, Aachen, Germany
Keywords:
Pre-processing Pipeline, Web Application, Research Data Management, Data Analysis, Process Mining,
Requirement Engineering.
Abstract:
Research Data Management (RDM) systems are becoming an essential part of every researcher’s academic ca-
reer. Often, researchers use various resources and web applications to handle their research data, causing com-
plications for maintaining data and assessing research projects against FAIR principles. Consequently, RDM
platforms help researchers with data administration tasks while providing the necessary tools for managing
research projects. Furthermore, user engagement with such RDM platforms leaves traces of user interaction
with research data; thus, studying user behaviors over research data becomes an exciting territory. However,
running periodic data analysis studies proves to be a time-consuming and challenging task and requires the
help of scientific staff to run pre-and post-processing pipelines per use case in order to be able to produce re-
sults that are usable by domain experts. This paper introduces Data Analysis for Research Data Management
systems (DA4RDM) as a scalable web application that supports reusing pre-defined pre-and post-processing
pipelines to enable domain experts to utilize the system without the need for scientific expertise. We use
real data acquired from an RDM system, explain the tool’s applicability, and present the preliminary findings,
demonstrating its use cases and capabilities.
1 INTRODUCTION
In the era of digitalization, researchers frequently face
the challenges of managing their research data to
present their findings to other scholars and ultimately
enable the reusing of research data. The Research
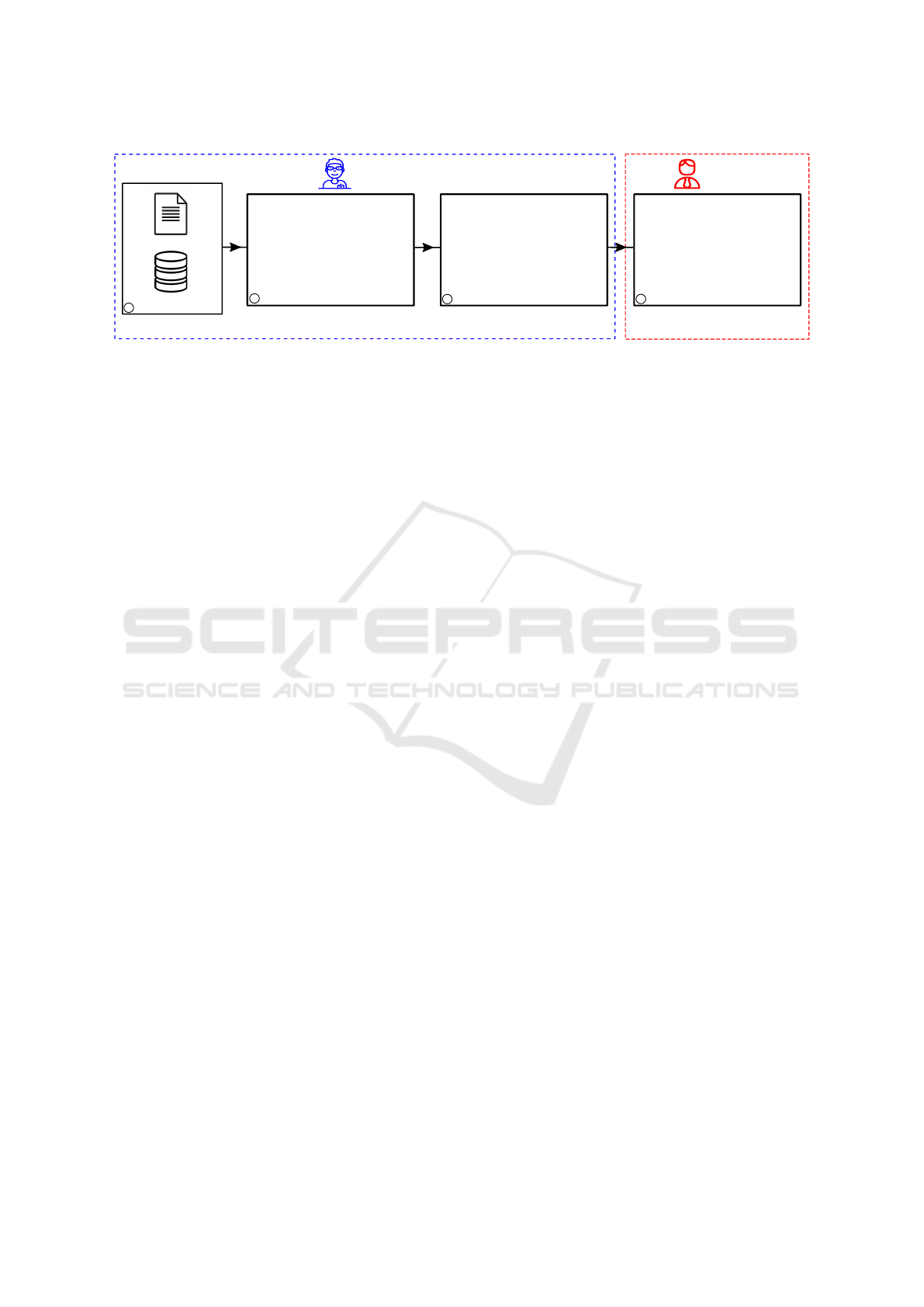
Data Life Cycle (RDLC) in figure 1 represents the
stages that every researcher faces during his/her aca-
demic career (Yazdi, 2019). Every RDLC stage in-
cludes several sub-activities, and each University pro-
vides various IT solutions per activity. On the one
hand, RDLC navigates researchs throughout their re-
search processes, and on the other hand, RDM sys-
tems encourage researchers to follow the FAIR prin-
ciples. The FAIR principle is a set of guidelines
and standards to increase transparency and impact of
research results by making the research data Find-
able, Accessible, Interoperable, and Reusable (FAIR)
(Wilkinson et al., 2016). Thus, data FAIRness en-
ables humans or machines understand the semantics
a
https://orcid.org/0000-0002-0628-4644
b
https://orcid.org/0000-0002-1719-8928
c
https://orcid.org/0000-0002-1830-5780
d
https://orcid.org/0000-0003-3175-0659
e
https://orcid.org/0000-0003-2545-5258
and purpose of the data (Gargiulo et al., 2021).
Accordingly, there is a need for a system to sup-
port researchers throughout the RDLC and promote
FAIR guidelines for research projects. Collaborative
Scientific Integration Environment (Coscine) is a soft-
ware platform at RWTH Aachen University to help
researchers throughout RDLC and guide them toward
FAIRness principles (Politze et al., 2020). Currently,
Coscine enables the integration of multiple data re-
sources and handles metadata management for re-
search projects. The users of this platform can define
research projects, invite other researchers to projects,
integrate multiple storage resources, and define spe-
cialized metadata schema to describe research data
while storing and archiving data. Coscine aims to pro-
vide a centralized web platform for RDLC activities
while encouraging users to adhere to FAIR principles.
RDM systems provide the means for managing
metadata and studying the RDLC process via dis-
covering user interactions with research data. Al-
though metadata management assists scholars in un-
derstanding the semantics of research data, investi-
gating user interactions assists Principal Investigators
(PI) and domain experts to discover bottlenecks in
the respective processes and to capture implicit user
Yazdi, M., Schimmel, D., Nellesen, M., Politze, M. and Müller, M.
DA4RDM: Data Analysis for Research Data Management Systems.
DOI: 10.5220/0010678700003064
In Proceedings of the 13th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2021) - Volume 3: KMIS, pages 177-183
ISBN: 978-989-758-533-3; ISSN: 2184-3228
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
177

Figure 1: Presumed research data life cycle.
requirements (Yazdi and Politze, 2020). By collect-
ing and capturing the footprints of user engagement,
we can discover non-trivial changes to the research
data and reveal insightful information, which facil-
itates further analytical investigations. Process and
data mining techniques can effectively discover non-
trivial process models and empower data-centric stud-
ies (van der Aalst, 2016). However, despite avail-
able process and data mining tools, most solutions are
either offline tools or developed for specialized use
cases and are too advanced for users without technical
expertise (Kebede and Dumas, 2015; Malkawi et al.,
2020; Celik and Akçetin, 2018). Thus, we need a soft-
ware solution that can support the full spectrum of
data preparation, pre-and post-processing pipelines,
modeling, and even action suggestions for RDM sys-
tems. DA4RDM, on the contrary, enables us to con-
nect to live data sources, run project-specific data pre-
processing pipelines, discover process models, and al-
lows for further scalability and adaptability of our sys-
tem.
In the remainder of this paper, in section 2, we
elaborate on the characteristics and functionalities of
the DA4RDM, then in section 3, we review a system
under study and demonstrate the findings. In section
4, we address the challenges and possible future work,
and lastly, in section 5 we give a brief summary of our
work.
2 DA4RDM WEB APPLICATION
DA4RDM is based on the Flask web framework, and
it consists of 4 modules. As illustrated in figure 2,
module 1 configures a data source, module 2 pro-
vides data cleansing tools, module 3 enables trans-
forming data according to projects’ scope, and mod-
ule 4 presents the findings with customizable post-
processing and data modelings. The actual imple-
mentation for the DA4RDM web application is also
publicly available on GitLab
1
.
2.1 Characteristics
DA4RDM is developed with the following character-
istics and properties:
2.1.1 Scalability
DA4RDM provides web services for connecting data
sources, customizing and executing project-specific
pre-processing pipelines, and allows for integrating
python packages for process and data mining projects.
The current implementation of DA4RDM has embed-
ded the PM4PY python package (Berti et al., 2019)
into the existing service infrastructure for process dis-
covery tasks.
2.1.2 Extendability
As shown in figure 2, the modular construction of the
DA4RDM allows for the integration or extension of
third-party Python packages to satisfy the needs of a
data analysis study. For instance, by extending the
appropriate modules for data emulation, outlier de-
tection, or data balancing and normalization, we can
define and perform various data modeling projects.
2.1.3 Accessibility
We split the accessibility of DA4RDM into two
parts. Firstly, the pipeline needs to be configured
by a data scientist. It includes connecting to a data
source, specifying a suitable data query, and setting
the pre-processing pipeline per project. Once a pre-
processing pipeline is defined, the steps are stored for
later re-use as predefined projects. Secondly, a non-
technical user can reuse a predefined project and ap-
ply additional web-based filters, attributes, and algo-
rithms on top of data, supporting post-processing the
data models without programming knowledge. Thus,
the DA4RDM client application enables principal in-
vestigators to analyze the RDM system without tech-
nical background knowledge.
2.2 Functionalities
In the following section, we elaborate on the function-
alities of the DA4RDM web application. We have di-
vided the functionality of DA4RDM into three main
1
https://git.rwth-aachen.de/AminYazdi/da4rdm
KMIS 2021 - 13th International Conference on Knowledge Management and Information Systems
178
CSV, XML, XES,...
Data base
Missing Values Detection
Data Imputation
Emulation
Duplicates Detection
Typos Detection
Outlier Detection
Syntax Error Detection
Grouping
Data Type Conversion
Concatination
Balancing
Normalization
Reporting
Visualizations
Validation
Data Cockpit
Filters
Process Discovery
1
2
3
4
Source Config
Data Cleansing Data Transformation
Data Analysis
Data Scientist
Principal
Investigator
Data Pre-processing Pipeline
Client Application
Figure 2: The DA4RDM overarching infrastructure and its modules.
parts, namely data source, data pre-processing, and
process analysis.
2.2.1 Data Source
The data source module allows for the supply of un-
processed data for the DA4RDM. As shown in step 1
of figure 2, the data input module currently supports
uploading local files in CSV, XES formats, or a di-
rect connection to a relational database table. In the
data source user interface (see figure 3a), users can
provide additional parameters for each data source to
further specify a file configuration or a database query
command. Despite local data storage, every fresh exe-
cution of pre-processing pipeline fetches the latest in-
stance of a specified data source. Moreover, this mod-
ule is responsible for serializing data structure into
Panda data-frame, allowing for data modifications re-
quired for later steps in the process. Note that XES
file formats are standardized XML data-types used by
Process Mining algorithms; thus, DA4RDM handles
converting input data into XES format and preparing
for process mining algorithms.
2.2.2 Data Pre-processing
The data pre-processing interface shown in figure 3b
is responsible for data cleansing and transformation.
The user interface allows for selecting a pre-defined
data source and a pre-processing pipeline to initial-
ize a data-driven study. Although the pre-processing
pipeline is heavily dependent on the input data prop-
erties and objectives of a data analysis project, this
tool allows for reusing a pipeline on top of opera-
tional data. Consequently, a data scientist specifies a
data source, consequently develops or modifies a pre-
processing pipeline according to his/her needs by uti-
lizing methods mentioned in steps 2 and 3 of figure 2
to adhere to a data structure or a use-case in hand.
Moreover, DA4RDM creates a user session main-
taining the designated data source and pre-processing
pipeline outcomes to ensure a continuous workflow
throughout the client application.
2.2.3 Process Analysis
The process analysis shown in figure 3c provides the
toolset and user interface required by principal in-
vestigators enabling them to further investigate data
without technical knowledge. At this stage, users
can utilize a few process mining algorithms provided
by the Pm4py library to discover the process mod-
els and study particular user journey scenarios based
on either frequency or performance analysis. Users
of DA4RDM can conveniently specify the main event
attributes (timestamp, case id, and activity) necessary
for a process discovery based on the existing data fea-
tures. Moreover, the filter module allows for further
narrowing the analysis over a specified dataset. Ad-
ditionally, the information module provides essential
statistics of the selected dataset for specified crite-
ria and filters. The results section provides a visu-
alization of the discovered model according to a cho-
sen algorithms such as Alpha miner, Heuristic miner,
Inductive miner, or Directly Follows Graph (DFG)
(van der Aalst, 2016).
3 SYSTEM UNDER STUDY
In the following section, we demonstrate the benefits
of DA4RDM for an RDM system. We begin by elab-
orating on the data collection method and its prop-
erties over the Coscine platform as an RDM-system
under study and then demonstrate the procedures in-
volved to enable principal investigators to utilize data
and deduce valuable insights.
3.1 Coscine Platform
As mentioned earlier, Coscine is a platform to assist
researchers with data management tasks and guide a
DA4RDM: Data Analysis for Research Data Management Systems
179
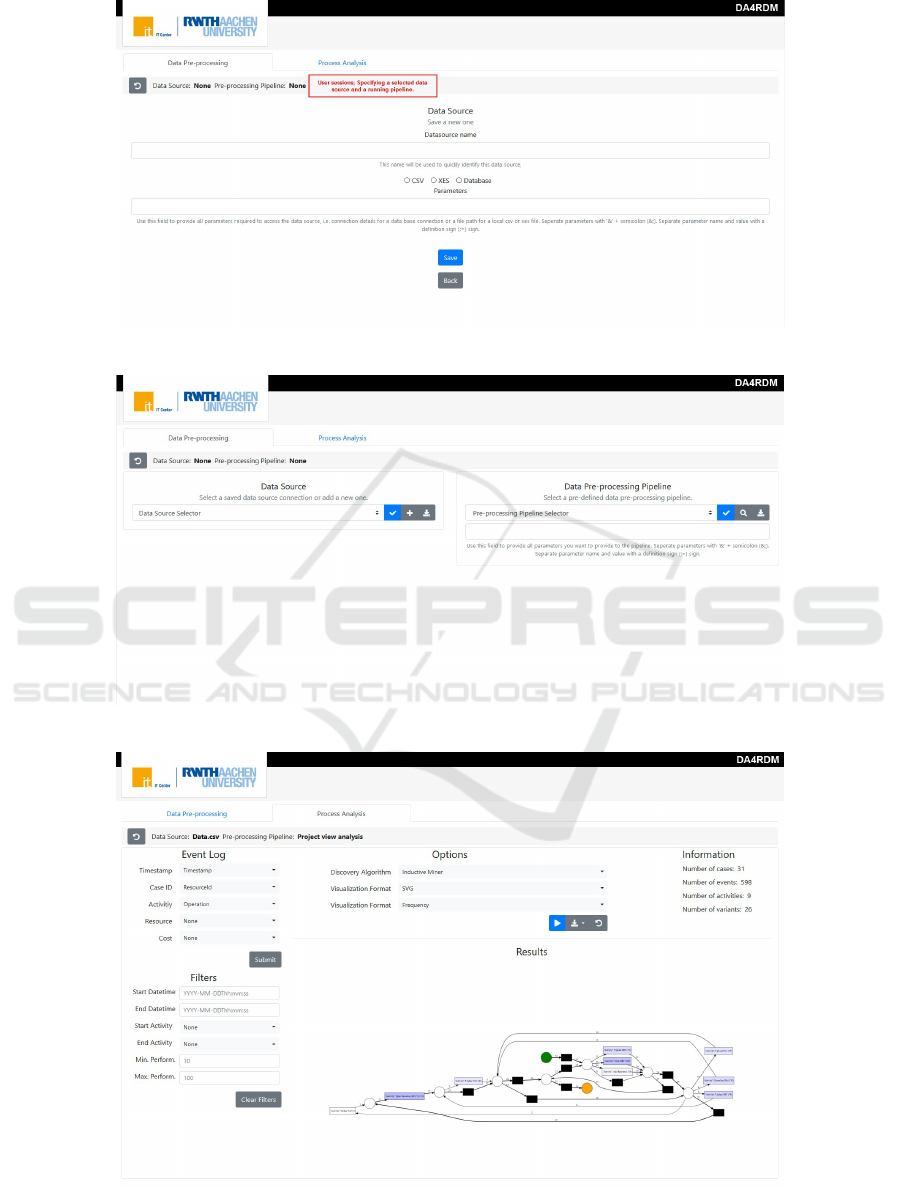
(a) UI for configuration of a data source using either a local file or a database.
(b) UI for selection of a data source and a pre-defined pre-processing pipeline.
(c) UI for Process analysis over a selected data source and pre-processing pipeline.
Figure 3: User interfaces for DA4RDM web application.
KMIS 2021 - 13th International Conference on Knowledge Management and Information Systems
180

Table 1: Sample of transformed data objects into features and labels, enabling further data analysis using DA4RDM.
Id Operation Timestamp UserId RoleId SessionId ProjectId PID MetadataSchema MetadataComp. License Discipline Organizations
... ... ... ... ... ... ... ... ... ... ... ... ...
1021 View Project 1579108918 29613-d8... be29c-4e... 4b15f... 4e9f-97... NULL NULL NULL MIT Mechanical Eng. ETH, Darmstadt
1022 View Resource 1579109840 29613-d8... be29c-4e... 4b15f... 4e9f-97... ef9175... EngMeta NULL MIT Mechanical Eng. ETH, Darmstadt
1023 Update Metadata 1579109897 29613-d8... be29c-4e... 4b15f... 4e9f-97... Xn3on4... EngMeta 73% MIT Mechanical Eng. ETH, Darmstadt
... ... ... ... ... ... ... ... ... ... ... ... ...
research project toward the FAIR maturity paradigm.
In addition, researchers may use Coscine to store their
research data, provide specialized metadata, and col-
laborate within research projects. Coscine is under
active development and benefits from the microser-
vices software architecture model. Various APIs and
applications are employed to interact with the system
such that each API is distinguishable by topic. For
instance, all requests handling file modifications are
processed by the same API.
3.2 Data Model
Coscine allows us to collect user-based RDM activ-
ities while formalizing appropriate data objects and
relationships between attributes. The obtained infor-
mation is a set of user requests received by the server-
side and processed according to particular application
domains. Coscine generates and captures this data
in a serialized JSON object format due to its ease
of scalability to incorporate supplementary attributes
and entities without a need for extending database ta-
bles. The data fields include detailed insights into the
sequence of actions and respective RDM-relevant en-
tities. For instance, the listing 1 represents a JSON
object triggered by a user, attempting to update meta-
data of a research data entries; respectively, we can
deduce meta information from a single user action
such as its PID, selected metadata schema, percent-
age of metadata provided, discipline, and additional
associated properties.
{
"Operation":"Update Metadata",
"Timestamp":"1579109897",
"UserId":"29613-d8..." ,
"RoleId":"be29c-4e...",
"SessionId":"4b15f...",
"ProjectId":"4e9f-97...",
"PID":"ef9175...",
"MetadataSchema":"EngMeta",
"MetadataCompletness":"70%",
"License":"MIT",
"Discipline":["Mechanical Engineering"],
"Organizations":["ETH", "Darmstadt"]
}
Listing 1: Sample JSON object captured on Coscine upon
user action.
Subsequently, DA4RDM provides the means to
utilize a produced dataset by Coscine or any other
RDM system via the user interface shown in figure 3b.
It allows selecting a preprocessing pipeline to evalu-
ate and transform data samples into a new data for-
mat, suitable for a data modeling algorithm. Accord-
ingly all JSON objects are collected and stored in a
relational database ready for importing to DA4RDM.
Table 1 is an example of a dataset converted into
columns of features and labels ready for running in-
depth process mining analysis using the DA4RDM in-
terface displayed in figure 3c.
3.3 Privacy
Concerning responsible data mining principles, it
is essential to maintain privacy within user-based
datasets (Rafiei et al., 2018). Accordingly, Coscine,
as a system under study, generates and contains no
human-readable names. Instead, GUIDs are used as
unique identifiers to enable analyzing a user’s actions
and user behavior study without compromising users’
identity. Moreover, by relying on server-side event
logs, we eliminate the need for a client-side logger,
which may cause unnecessary complications or in-
clude undesired sensitive information.
3.4 Preliminary Findings
The following section elaborates on the qualitative
and quantitative findings from two case studies using
DA4RDM that are also shown in figure 4. Initially,
we investigated user activities over resource PIDs
and then analyzed overall system performance for re-
search projects on Coscine. The goal is to demon-
strate the preliminary applications of DA4RDM in
its initial stages by discovering process models for
non-trivial user interaction paths and identifying non-
functional requirements in the system.
In the first use case, we ran frequency analysis us-
ing inductive miner over resource PIDs and discov-
ered a Petri-net model for the most typical user jour-
ney paths over interacting with different resources and
research data. We refer our readers to (Kindler et al.,
2006) for further explanation of Petri-net modeling.
On the top right section of figure 3c, DA4RDM re-
ports brief statistics over the number of cases, events,
activities, and variations of activities. With the help of
DA4RDM: Data Analysis for Research Data Management Systems
181
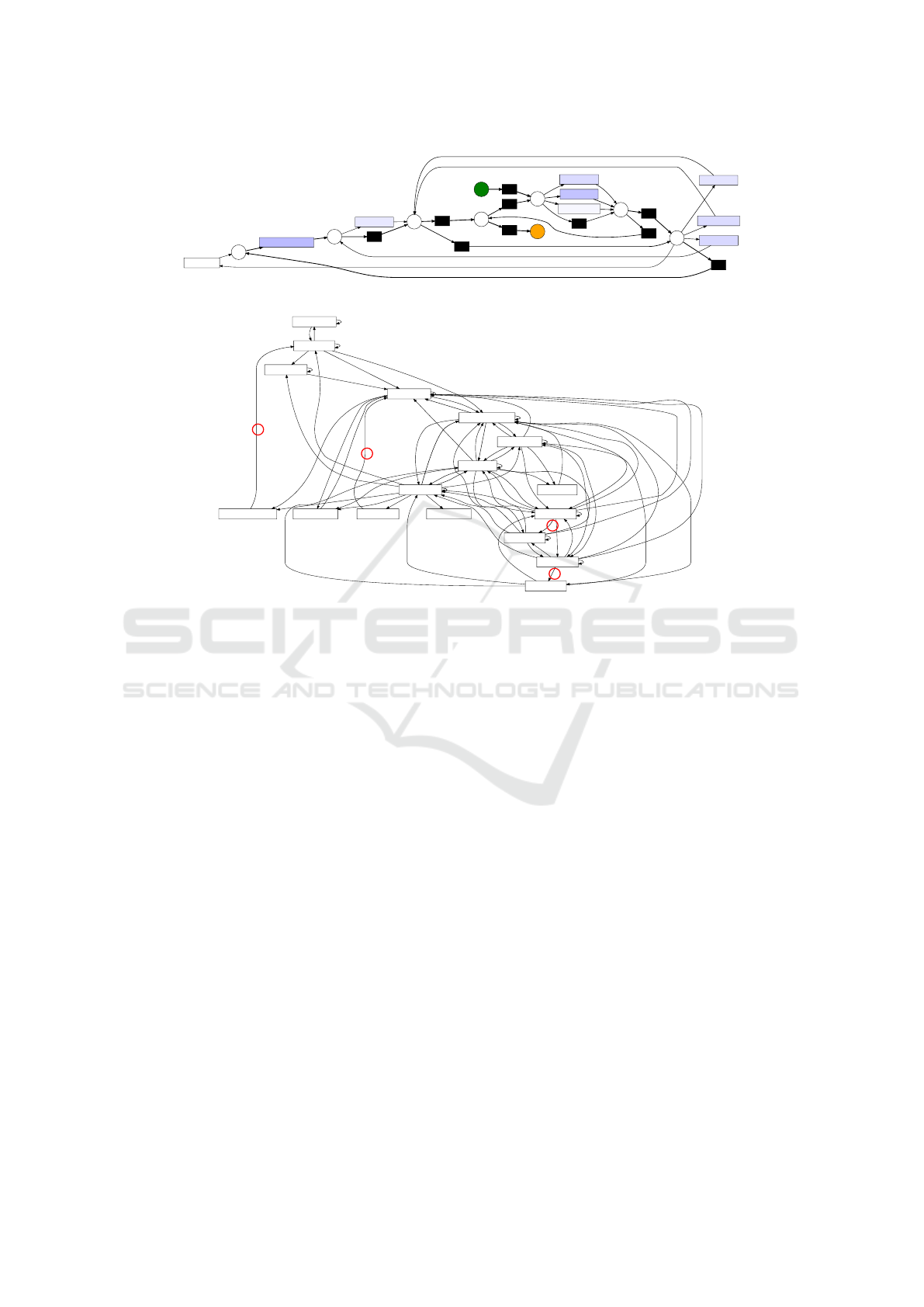
'Activity': 'Delete File' (3)
2
11
'Activity': 'Upload MD' (73)
11
16
'Activity': 'Download File' (70)
8
27
'Activity': 'Open Resource (RCV)' (135)
27
'Activity': 'Update File' (46)
3
31
'Activity': 'Update MD' (78)
6
31
'Activity': 'View MD' (120)
16
'Activity': 'Add Resource' (18)
18
28
'Activity': 'Upload File' (55)
10
27
28
21
18
1
31
3
27
27
11
11
16
18
31
21
16
28
2
8
27
6
10
28
18
(a) Frequency analysis using Petri-net model for all involving activities over resource PIDs.
17s
'Activity': 'Add Member' (0s) 1s
'Activity': 'View Users' (0s)
9s
'Activity': 'Add Project' (0s)
'Activity': 'Open Project' (0s)
34s
'Activity': 'Add Resource' (0s)
18s
'Activity': 'Change Role' (0s) 1s
1s
'Activity': 'Open User Management' (0s)
'Activity': 'Delete File' (0s)
'Activity': 'Open Resource (RCV)' (0s)
3s
'Activity': 'Delete Project' (0s)
'Activity': 'Download File' (0s)
1s
35s
7s
7s
'Activity': 'Update MD' (0s)
2s
'Activity': 'Upload MD' (0s)
4s
'Activity': 'View MD' (0s)
14s1s
13s
7s
2s
'Activity': 'View Project' (0s)
10s
38s
30s
'Activity': 'Update File' (0s)
1s
12s
34s
5s
22s
1s
4s
1s
4s
7s
5s
35s
10s
'Activity': 'Upload File' (0s)
1s
1s
8s
3s
4s
6s
2s
2s
6s
3s
2s
1s
2s
21s
9s
2s
5s
2s
2s
19s
11s
8s
1s
7s
27s
25s
1s15s
1s
3s
2s
1m
18s 6s
35s
2s
9s
2s
16s
4s
1s
(b) Performance analysis using Data-Follow-Graph for all research projects. Red circles
indicate violated KPIs in the system.
Figure 4: Discovered process models using the Inductive Miner via DA4RDM web application.
DA4RDM illustrated in figure 4a, we discovered that
the number of execution for the Open Resource(RCV)
activity is oddly excessive with respect to the num-
ber of incoming and outgoing transitions, indicating
the existence of loops in the code and the necessity
to refactor code in order to avoid unnecessary server-
side requests.
In the second use case, we investigated the overall
performance of the RDM system shown in figure 4b
using DFG process model and evaluated the findings
(shown in red circles) with the help of a domain expert
against key performance indicators. Despite the ex-
pected complex and unstructured process model due
to the freedom of user interaction within the system,
DA4RDM successfully assisted us in identifying bot-
tlenecks in the system that were previously unknown.
For instance, the transition from Open User Manage-
ment to View Users actions should not take longer
than a few seconds, or the process of creating new
projects (transition from Add Project to Open Project)
on Coscine was discovered to take over 70 seconds.
Accordingly, discovering the evidence of software ex-
ecution bottlenecks resulted in gaining the developer
teams’ attention, and also, as shown in figure 4b, the
performance for this process is greatly improved.
The empirical study over real data, implies that the
cyclic order of operations within the RDLC shown in
figure 1 may not reflect the reality of how researchers
interact with research data. Furthermore, despite the
limited data sample size, both use cases manifest
DA4RDM capabilities and how the web application
could be extended to serve non-technical users to in-
vestigate their research projects against certain crite-
ria by extending the data modeling technique or visu-
alization for a target use case.
4 CHALLENGES AND FUTURE
WORK
In order to evaluate the functionality of DA4RDM
with a real dataset while developing DA4RDM, we
spent a considerable amount of time finding a suitable
method for obtaining and extracting event logs from
Coscine as an evolving RDM system. Nevertheless,
DA4RDM is designed to be independent of its input
data model and allows for data processing according
to foreseeable use cases. Additionally, the current im-
KMIS 2021 - 13th International Conference on Knowledge Management and Information Systems
182

plementation only allows for a single source of truth
for data input which is a limitation for RDM systems
where the datasets are scattered in multiple locations.
The seen complex process model shown in figure 4b
results from actual user behavior in an environment
where users are free to interact with a system with-
out a specific order. Thus, there is a need to extend
DA4RDM with a pre-processing pipeline suggested
by the authors in (Yazdi et al., 2021) to abstract event
logs to achieve structured and simple process mod-
els. We have to acknowledge that Coscine is a de-
veloping RDM platform and is currently in its pilot
phase; hence the sample dataset available is limited
to its beta users, and the current preliminary findings
may not entirely reflect the actual user behavior in a
mature RDM system.
The future work includes adding additional in-
terfaces for conformance checking of the user pro-
cess, identifying unfinished user journeys and trig-
gering automatic actions, and extending the collected
dataset to produce a FAIR maturity dashboard for ev-
ery research project and suggest user actions to in-
crease research data FAIRness. Although the current
DA4RDM UI allows for a PI to interact with the sys-
tem, the post-processing of data models proved to be
too advanced; therefore, we may need to pre-scope
the available features of our web application for the
target audience.
5 CONCLUSION
In this paper, we discussed the benefits of DA4RDM
for an RDM system. We began with a technical re-
view of the developed web application, its charac-
teristics, and functionalities. Furthermore, we elab-
orated on an RDM platform (Coscine) as a candidate
system under study and the approach used to obtain
a real dataset for the goal of data modeling and anal-
ysis. Preliminary findings demonstrated the benefits
of such a system toward user behavior studies and
discovering non-functional requirements. Although
the extracted data from Coscine is entirely based on
a service layer, DA4RDM is showing to be adapt-
able to any log format according to the needs of a
data modeling algorithm. Therefore, the contributions
of DA4RDM are to allow for a scalable web appli-
cation that enables non-technical staff to reuse pre-
defined pre-and post-processing pipelines to execute
data-driven studies without technical or scientific ex-
pertise.
REFERENCES
Berti, A., van Zelst, S. J., and van der Aalst, W. (2019).
Process mining for python (pm4py): bridging the gap
between process-and data science. arXiv preprint
arXiv:1905.06169.
Celik, U. and Akçetin, E. (2018). Process mining tools
comparison. Online Academic Journal of Information
Technology, 9:97–104.
Gargiulo, P., Galimberti, P., Tammaro, A. M., and Zane, A.
(2021). Fair rdm (research data management): Italian
initiatives towards eosc implementation. In IRCDL,
pages 42–52.
Kebede, M. and Dumas, M. (2015). Comparative evaluation
of process mining tools. University of Tartu.
Kindler, E., Rubin, V., and Schäfer, W. (2006). Process
mining and petri net synthesis. In International Con-
ference on Business Process Management, pages 105–
116. Springer.
Malkawi, R., Saifan, A. A., Alhendawi, N., and Bani-
Ismaeel, A. (2020). Data mining tools evaluation
based on their quality attributes. International Journal
of Advanced Science and Technology, 29(3):13867–
13890.
Politze, M., Claus, F., Brenger, B., Yazdi, M. A., Heinrichs,
B., and Schwarz, A. (2020). How to manage it re-
sources in research projects? towards a collaborative
scientific integration environment. European Journal
of Higher Education IT, 2.
Rafiei, M., von Waldthausen, L., and van der Aalst, W. M.
(2018). Ensuring confidentiality in process min-
ing. Proceedings of the 8th International Sympo-
sium on Data-driven Process Discovery and Analysis-
SIMPDA, 18:3–17.
van der Aalst, W. (2016). Process mining: data science in
action. Springer.
Wilkinson, M. D., Dumontier, M., Aalbersberg, I. J., Apple-
ton, G., Axton, M., Baak, A., Blomberg, N., Boiten,
J.-W., da Silva Santos, L. B., Bourne, P. E., et al.
(2016). The fair guiding principles for scientific data
management and stewardship. Scientific data, 3(1):1–
9.
Yazdi, M. A. (2019). Enabling operational support in the
research data life cycle. In Proceedings of the First
International Conference on Process Mining, pages
1–10.
Yazdi, M. A., Farhadi, P., and Heinrichs, B. (2021). Event
log abstraction in client-server applications. In IC3K
2021: Proceedings of the 13th International Joint
Conference on Knowledge Discovery, Knowledge
Engineering and Knowledge Management: KDIR.
SciTePress.
Yazdi, M. A. and Politze, M. (2020). Reverse engineering:
The university distributed services. In Proceedings of
the Future Technologies Conference, pages 223–238.
Springer.
DA4RDM: Data Analysis for Research Data Management Systems
183
