
A Statement Report on the Use of Multiple Embeddings
for Visual Analytics of Multivariate Networks
Daniel Witschard
a
, Ilir Jusufi
b
, Rafael M. Martins
c
and Andreas Kerren
d
Department of Computer Science and Media Technology, Linnaeus University, V
¨
axj
¨
o, Sweden
Keywords:
Multivariate Network, Visualization, Visual Analytics, Embedding, Methodology.
Abstract:
The visualization of large multivariate networks (MVN) continues to be a great challenge and will probably
remain so for a foreseeable future. The field of Multivariate Network Embedding seeks to meet this challenge
by providing MVN-specific embedding technologies that targets different properties such as network topology
or attribute values for nodes or links. Although many steps forward have been taken, the goal of efficiently
embedding all aspects of a MVN remains distant. This position paper contrasts the current trend of finding
new ways of jointly embedding several properties with the alternative strategy of instead using, and combining,
already existing state-of-the-art single scope embedding technologies. From this comparison, we argue that
the latter strategy provides a more generic and flexible approach with several advantages. Hence, we hope to
convince the visual analytics community to invest more work in resolving some of the key issues that would
make this methodology possible.
1 INTRODUCTION
A large amount of research effort has been put into
the problem of visualization and visual analytics (VA)
regarding large multivariate networks (MVNs). This
is a complex and challenging problem both from a
pure visualization perspective as well as from a com-
putational perspective. While the field of MVN visu-
alization is well-studied—and there exist several ap-
proaches for displaying and interacting with MVNs
(Kerren et al., 2014; Martins et al., 2017; Nobre et al.,
2019)—the size of many MVNs (for example so-
cial networks such as Twitter and Facebook) exceed
the limits of what can be efficiently handled by such
methods directly. This means that in many cases, ef-
fective pre-processing and extensive computations are
vital steps before visualization even becomes feasible.
Furthermore, there is a constant need for more effi-
cient analysis algorithms from a computational per-
spective. Hence, methods for effective representa-
tions and efficient calculations for MVNs would be
beneficial from both a visualization perspective and
a VA perspective. It is our conviction that combined
a
https://orcid.org/0000-0001-6150-0787
b
https://orcid.org/0000-0001-6745-4398
c
https://orcid.org/0000-0002-2901-935X
d
https://orcid.org/0000-0002-0519-2537
forces from these two areas are needed to achieve the
progress needed.
Embeddings are relatively low-dimensional vec-
tor representations of the embedded items and embed-
ding algorithms exist for different types of data. (E.g.,
the nodes of a network or the words of a text corpus).
The main goal of the emdedding algorithm is usually
to produce embeddings in a way so that items that
are similar (from some chosen aspect) in the original
data set are embedded in vectors that lie close to each
other in the embedding space (with regard to some
chosen distance metric). Therefore embeddings can,
for instance, be used for efficient similarity compu-
tations over a data set. From a technical viewpoint
there are several arguments to suggest that embedding
technology is probably a suitable candidate for meet-
ing the challenge of MVN visualization and MVN vi-
sual analytics. The main argument for this is that it
has already proven to be an efficient and successful
strategy within other problem areas (Goyal and Fer-
rara, 2017; Toshevska et al., 2020) In recent years,
several embedding techniques specific to MVNs have
been introduced (Cui et al., 2019) allowing for new
and ingenious progress (see Figure 1). Therefore, it
is not surprising that a lot of effort is currently be-
ing put into exploring ways to create new and better
MVN embeddings. In this scenario, a common ap-
proach is to try to simultaneously embed several prop-
Witschard, D., Jusufi, I., Martins, R. and Kerren, A.
A Statement Report on the Use of Multiple Embeddings for Visual Analytics of Multivariate Networks.
DOI: 10.5220/0010314602190223
In Proceedings of the 16th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2021) - Volume 3: IVAPP, pages
219-223
ISBN: 978-989-758-488-6
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
219
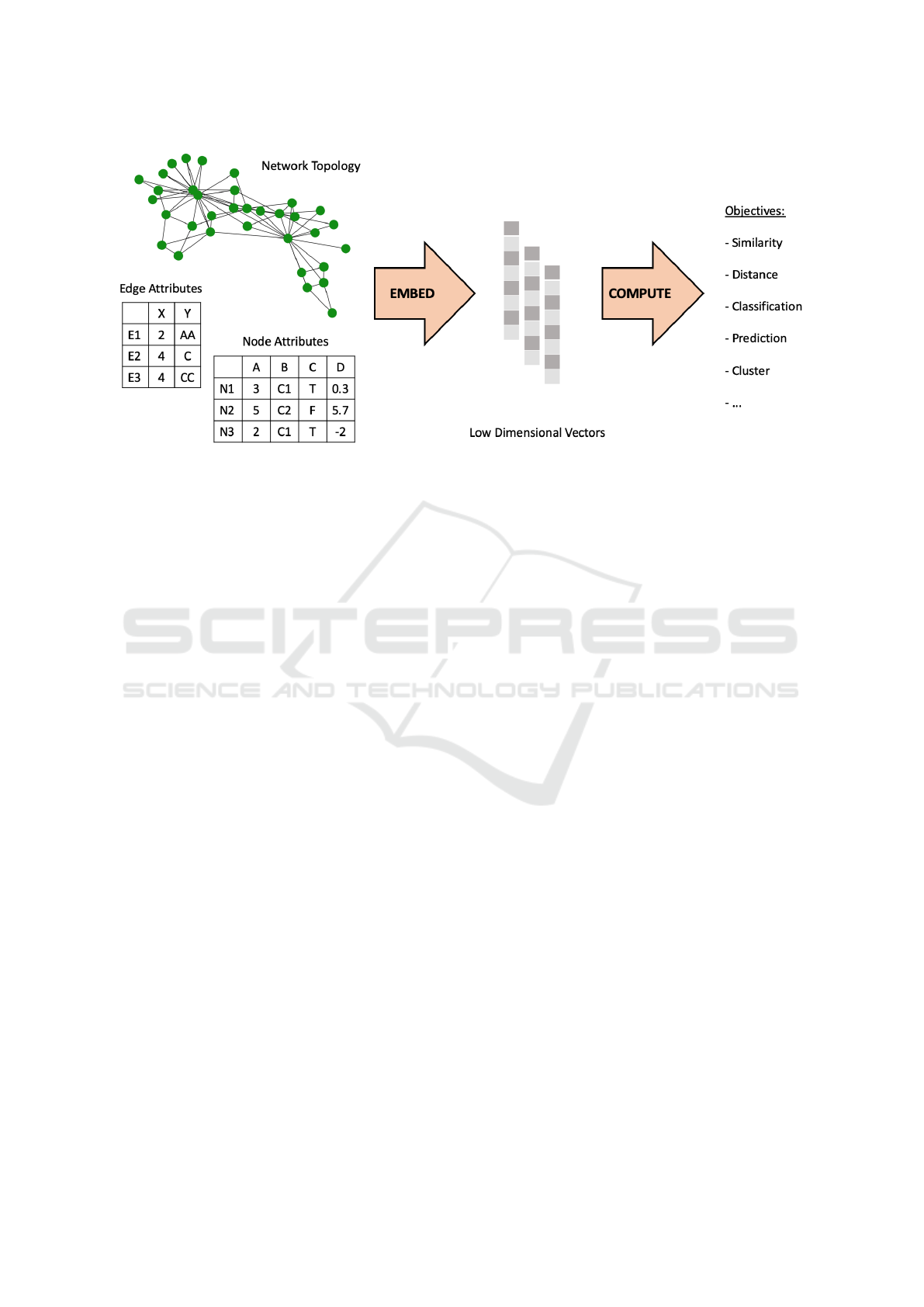
Figure 1: Embeddings have become important tools for MVN analysis and made the way for substantial progress. Technolo-
gies for embedding properties such as network topology and attributes on nodes or edges have enabled more computationally-
efficient ways to support common objectives and tasks.
erties (by this we mean different characteristics of the
MVN such as network topology, attributes on nodes
or edges etc.) using so-called content-enhanced rep-
resentation learning or similar techniques (Hamilton
et al., 2018; Sun et al., 2016; Lerique et al., 2020).
While this has proven successful for some applica-
tions, we would like to point out that the typical multi-
property MVN embedding technology is quite narrow
in its scope regarding the amount of properties it can
capture (typically only two). Hence, the quest for
the—highly desirable—algorithm capable of captur-
ing all properties of the MVN at once still remains an
open challenge, at least for the foreseeable future.
In this paper, we therefore argue for an alternative
approach, and take the position that there seems to be
a currently unexploited way that could hopefully lead
towards the goal of comprehensive and efficient MVN
embeddings. The alternative strategy that we pro-
pose is to seek novel ways to combine and leverage
the plethora of already-existing state-of-the-art em-
bedding technologies, also from other fields that do
not necessarily target MVNs. Furthermore, we argue
that this should be done in a way that will allow for
exploitation of:
1. the benefits of single focus,
2. the flexibility of separation, and
3. the power of combination.
These three concepts are outlined in the following
sections and provide the overall structure of this pa-
per. To make our reasoning more concrete, and hope-
fully easier to follow, we will assume that the embed-
dings we discuss are used for similarity calculations
(which is a common case), but our arguments are not
dependent on this.
2 THE BENEFITS OF SINGLE
FOCUS
Embedding algorithms are typically quite complex in
their structure (Cui et al., 2019) (for example, it is not
uncommon that they are based on model training and
loss function minimization.) Therefore, calculating
good embeddings for even a single property is usu-
ally a non-trivial task in itself, with many challenges.
The case of simultaneously embedding two or more
properties (see Figure 2) can, in general, be viewed as
a joint optimization problem, so that more complex-
ity is added on top of the already existing one. Fur-
thermore, joint optimization problems usually contain
some amount of trade-off between objectives since it
may be hard, or impossible, to find a common optima
(Ngatchou et al., 2005). It is therefore reasonable to
argue that an embedding algorithm that targets a sin-
gle property will have the potential for higher-quality
similarity calculations (for that specific property) than
an algorithm that tries to bundle it together with oth-
ers. There is, of course, no strict guarantee that that
will be the case for all situations and for all data sets.
Thus, we claim that it is likely that the highest
quality for similarity calculations, as measured on a
per-property basis, will be obtained by algorithms that
target only a single property. Furthermore, we note
that this line of reasoning deliberately opens the pos-
sibility to use algorithms that do not specifically tar-
IVAPP 2021 - 12th International Conference on Information Visualization Theory and Applications
220
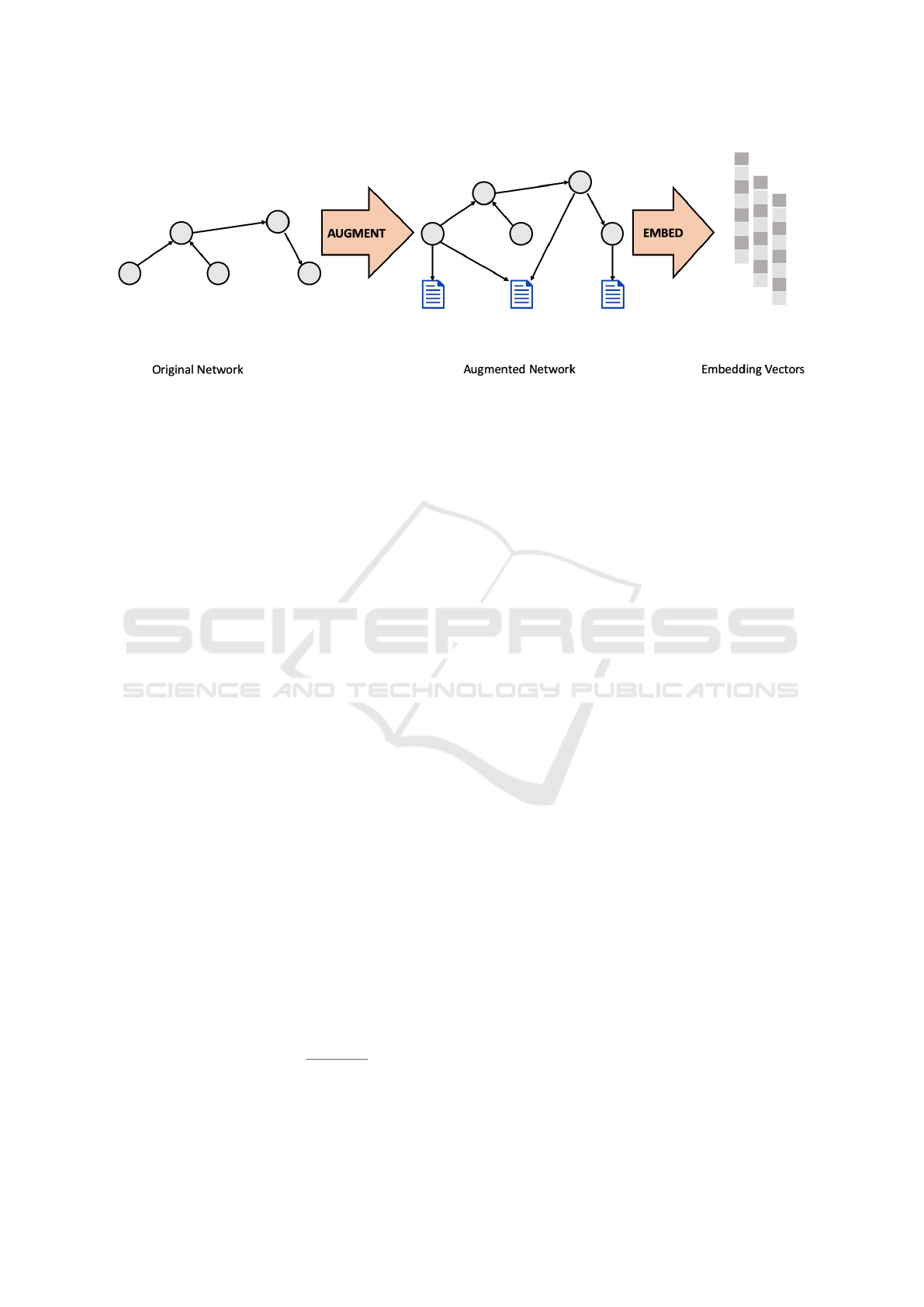
Figure 2: In the CENE framework (Sun et al., 2016), the original MVN is extended by adding new nodes. For each text
attribute on an existing node, a new child node (of a different type) is added with links to its parent node(s). The resulting
augmented (multimodal) network, now containing two different types of nodes and two different types of links, is then used
in the embedding algorithm for joint optimization of network structure and textual content.
get MVNs. This is highly desirable and precisely
our goal, since a state-of-the-art algorithm from the
field of word/text embedding, for example, might also
work perfectly well for embedding any text attributes
of an underlying MVN. In other words, the main idea
here would be to apply property-by-property embed-
ding using single-focus embedding methods (as they
would, in theory, produce the best results), and to find
a clever way to combine them, as discussed in Sec-
tion 4.
3 THE FLEXIBILITY OF
SEPARATION
Even for algorithms that do not encounter the prob-
lem of simultaneous minimization of loss functions,
mentioned above, there is still a disadvantage in the
fact that the resulting similarities can only be evalu-
ated in combination, and not in separation. While this
may be a desirable in some cases, it is also a drawback
since, as with (Sun et al., 2016), a combined embed-
ding of network topology and text attributes provides
for detection of nodes that lie “near” each other and
have similar text content, but it does not provide for
comparison of nodes that have similar text content but
lie far apart in the network (cf. Figure 2). However, if
the embeddings had been separated into one for each
property, it would have provided for any combination
of the separate similarities, including inverted similar-
ity. This would allow users to pose interesting ques-
tions such as “Show me all the items that are similar
with regard to property A and dissimilar with regard
to property B”. Thus, we claim that a combined set
of single focus embeddings will always provide for
a wider, and more flexible, range of similarity calcu-
lations than a joint embedding of the same set. In
fact, the range of possible similarity calculations of
a joint property embedding will always be a subset of
the range of possibilities of the set of the same proper-
ties embedded one by one. When considering the use
of VA techniques and user domain expertise, this ap-
proach becomes even more powerful compared to the
joint embedding, as it would allow for a more flexible
and complex exploration of the underlying data.
4 THE POWER OF
COMBINATION
For many of the properties that could be of interest
for MVN embedding (e.g., network topology, textual
content, or categorical attributes of nodes) there actu-
ally already exist several state-of-the-art embedding
methods, each with their own strengths and weak-
nesses. Therefore, instead of trying to make a choice
for the best one (which can be subjective and may
vary from case to case), a feasible strategy would be
to try to leverage them all in an ensemble combina-
tion. This is a well-known strategy in many other ar-
eas (Dong et al., 2020), relying for example on the
fact that a well-chosen combination of different clas-
sifiers often has the potential to outperform any of the
individual contributing classifiers.
Another argument to support this claim is the fact
that a combination may hold a larger exploitable po-
tential, since what has been missed by one classifier
may be compensated for by another. This effect is es-
pecially strong for situations when the classifiers have
a low level of inter-dependency, and hence it is desir-
able to combine different technologies. Furthermore,
it is not unusual to obtain synergy effects for ensem-
A Statement Report on the Use of Multiple Embeddings for Visual Analytics of Multivariate Networks
221
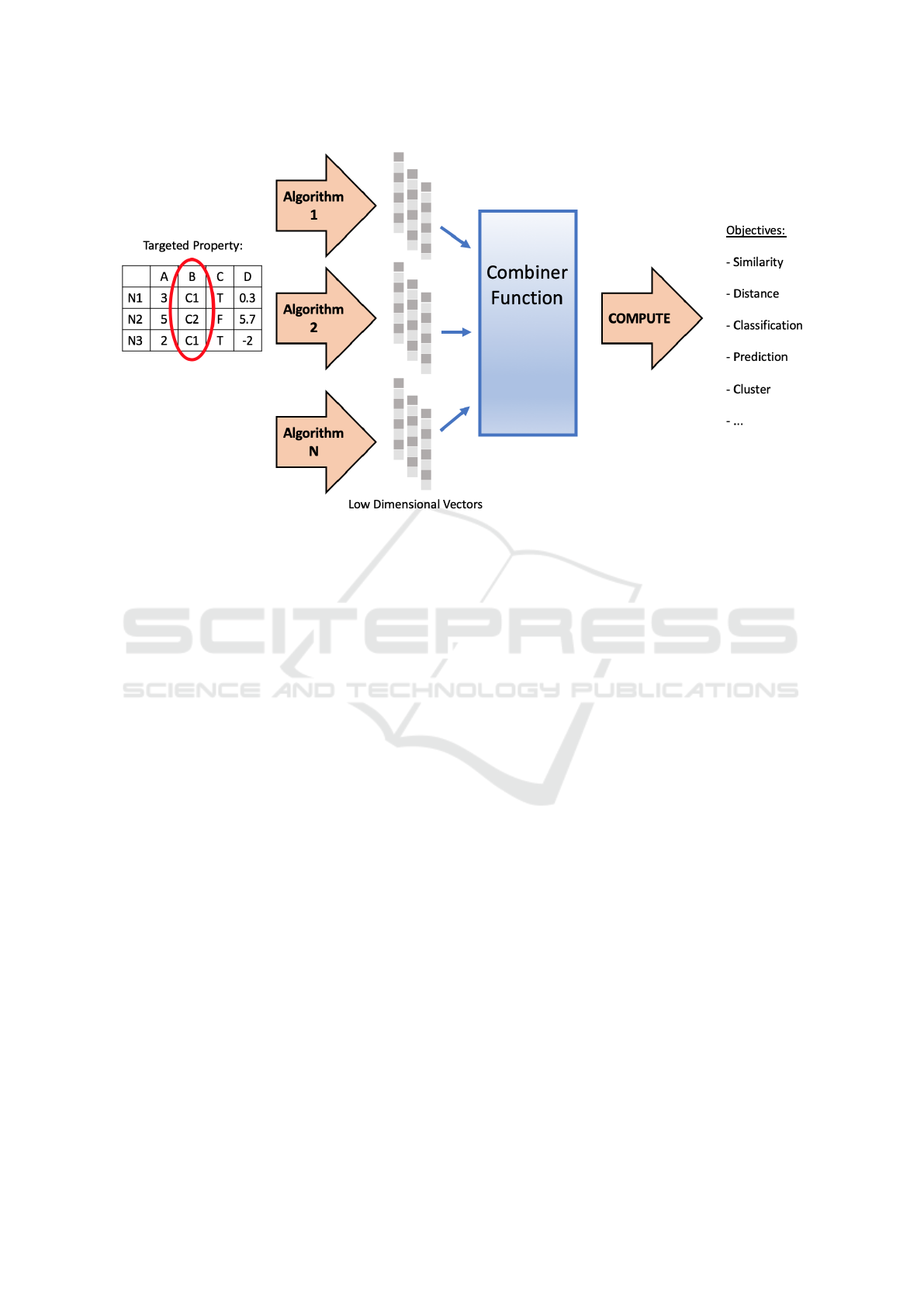
Figure 3: Applying the general idea of ensemble analysis to embeddings. A selected property is embedded by several different
algorithms (or the same algorithm with different settings) and the results are combined to hopefully achieve a higher quality.
ble combinations such that the quality of the com-
bined result is significantly higher than for any of the
contributing parts taken by itself (Opitz and Maclin,
1999). By applying the same line of reasoning, with
some modifications, to embeddings we believe that it
is possible to use the general idea of ensemble analy-
sis as a valid strategy also for this case (see Figure 3
for details).
5 CONCLUSIONS AND EARLY
RESULTS
In line with the reasoning above, we conclude that
trying to find ways to simultaneously embed several
different properties of an MVN is a challenging task
with some inevitable disadvantages. Therefore, a fea-
sible strategy, that will likely provide for the highest
quality and the maximal flexibility, is to instead em-
bed properties one-by-one using state-of-the-art algo-
rithms that target the data type of the specific property.
Furthermore, if several state-of-the-art algorithms ex-
ist for a specific property, their respective yields could
probably be combined for even higher quality by us-
ing ensemble calculations. From our perspective, the
main pros of this approach are listed in the following:
• It gives a straight-forward method to obtain and
combine embeddings of many important aspects
of MVNs.
• Using an “all-embedding” approach allows for
building homogeneous and effective pipelines for
back-end calculations and processing.
• Advances from other areas can be readily reused
within the field of MVN visualization and VA.
In contrast, the major cons of our approach might be:
• Tailor-made multi-feature embeddings may still
be a better choice for specific applications.
• An “all-embedding” strategy is not necessarily the
best for MVN analysis.
• Ensemble analysis is not a trivial task, and it will
have to be adapted to the specific circumstances
of each situation.
Taking all aspects into account, our overall conclusion
is that the pros out-weight the cons, and with this pa-
per we hope to convince the VA community to invest
more work and time to develop
• novel approaches for combining existing embed-
ding technologies in a MVN context,
• generic approaches for analyzing the quality and
yield from embeddings of different data types, and
• generic approaches for assessing the performance
of different ensemble strategies when facing
several state-of-the-art algorithms.
To give further credibility to our claims we conclude
by giving some early results from our work show-
ing that the general ideas from ensemble analysis can
IVAPP 2021 - 12th International Conference on Information Visualization Theory and Applications
222

indeed be applied to embeddings. In our test setup
we have used some 3000 article abstracts from the
IEEE conferences and embedded them in five differ-
ent ways using paragraph-sized text embedding tech-
nologies. Performing all-to-all similarity calculations
and verifying the results with regards to a small, man-
ually labeled, ground-truth set indicates that an en-
semble approach yields better quality than any of the
single embeddings taken by themselves (Witschard
et al., 2020). However, much work remains to be done
to fully understand the general rules behind this pro-
cess. Nevertheless, these promising first results, to-
gether with the generalizability of the approach to any
embedding type, encourage us to use this as a foun-
dation for attempting a general framework for MVN
embedding.
REFERENCES
Cui, P., Wang, X., Pei, J., and Zhu, W. (2019). A survey on
network embedding. IEEE Transactions on Knowl-
edge and Data Engineering, 31(5):833–852.
Dong, X., Yu, Z., Cao, W., Shi, Y., and Ma, Q. (2020). A
survey on ensemble learning. Frontiers of Computer
Science, 14(2):241–258.
Goyal, P. and Ferrara, E. (2017). Graph embedding tech-
niques, applications, and performance: A survey.
arXiv:1705.02801.
Hamilton, W. L., Ying, R., and Leskovec, J. (2018). Rep-
resentation learning on graphs: Methods and applica-
tions. arXiv:1709.05584.
Kerren, A., Purchase, H. C., and Ward, M. O. (2014). Multi-
variate Network Visualization. Springer International
Publisher.
Lerique, S., Abitbol, J. L., and Karsai, M. (2020). Joint
embedding of structure and features via graph convo-
lutional networks. Applied Network Science.
Martins, R. M., Kruiger, J. F., Minghim, R., Telea, A. C.,
and Kerren, A. (2017). MVN-Reduce: Dimensional-
ity Reduction for the Visual Analysis of Multivariate
Networks. In Kozlikova, B., Schreck, T., and Wis-
chgoll, T., editors, EuroVis 2017 - Short Papers. The
Eurographics Association.
Ngatchou, P., Zarei, A., and El-Sharkawi, A. (2005). Pareto
multi objective optimization. In Proceedings of the
13th International Conference on, Intelligent Systems
Application to Power Systems, pages 84–91. IEEE.
Nobre, C., Meyer, M., Streit, M., and Lex, A. (2019). The
state of the art in visualizing multivariate networks.
EUROVIS, Volume 38, Number 3.
Opitz, D. and Maclin, R. (1999). Popular ensemble meth-
ods: An empirical study. Journal of Artificial Intelli-
gence Research.
Sun, X., Guo, J., Ding, X., and Liu, T. (2016). A general
framework for content-enhanced network representa-
tion learning. arXiv:1610.02906.
Toshevska, M., Stojanovska, F., and Kalajdjieski, J. (2020).
Comparative analysis of word embeddings for captur-
ing word similarities. arXiv:2005.03812.
Witschard, D., Jusufi, I., Martins, R. M., and Kerren, A.
(2020). Multiple embeddings for multivariate net-
work analysis. Poster abstract presented at 6th an-
nual Big Data Conference at Linnaeus University, in
V
¨
axj
¨
o, Sweden.
A Statement Report on the Use of Multiple Embeddings for Visual Analytics of Multivariate Networks
223
