
Improving Mental Health using Machine Learning to Assist Humans in
the Moderation of Forum Posts
Dong Wang
1
, Julie Weeds
1
and Ian Comley
2
1
Department of Informatics, University of Sussex, Brighton, BN1 9RH, U.K.
2
MeeTwo Education Ltd, 17 Princelet Street, London, E1 6QH, U.K.
Keywords:
Machine Learning, Natural Language Processing, Mental Health, Online Forum Moderation,
Data Augmentation, BERT, LSTM.
Abstract:
This work investigates the potential for the application of machine learning and natural language processing
technology in an online application designed to help teenagers talk about their mental health issues. Specifi-
cally, we investigate whether automatic classification methods can be applied with sufficient accuracy to assist
humans in the moderation of posts and replies to an online forum. Using real data from an existing application,
we outline the specific problems of lack of data, class imbalance and multiple rejection reasons. We inves-
tigate a number of machine learning architectures including a state-of-the-art transfer learning architecture,
BERT, which has performed well elsewhere despite limited training data, due to its use of pre-training on a
very large general corpus. Evaluating on real data, we demonstrate that further large performance gains can be
made through the use of automatic data augmentation techniques (synonym replacement, synonym insertion,
random swap and random deletion). Using a combination of data augmentation and transfer learning, perfor-
mance of the automatic classification rivals human performance at the task, thus demonstrating the feasibility
of deploying these techniques in a live system.
1 INTRODUCTION
Mental health problems are now very common in the
UK. Approximately 1 in 4 people in the UK will expe-
rience a mental health problem each year (McManus
et al., 2009). Further, in England alone, 1 in 6 people
report experiencing a common mental health problem
(such as anxiety and depression) in any given week
(McManus et al., 2016). This pressing need to help
people with mental health problems has given rise to
the growing number of initiatives and organizations
working in the area. MeeTwo Education is a social
enterprise which has, since 2016, been working to re-
duce the number of mental health issues experienced
by young people. Their strategy is to provide an on-
line app where young people can safely share prob-
lems and receive advice and support from both pro-
fessionals and peers.
The users in the MeeTwo scenario can be, due
to age and personal nature of posts, very vulnera-
ble. Thus it is essential that they are protected from
the potential negative impacts of un-moderated posts
to this online forum. For example, the forum pro-
hibits posts containing offensive language or cyber-
bullying as well as posts containing personal infor-
mation, since these could let other users identify an
individual, posing dangers to them in the non-virtual
world. Furthermore, posts which indicate that a user
is in danger, for example potentially suicidal, are redi-
rected to a trained professional rather than being left
to peers. Currently, all posts to the MeeTwo forum
are moderated by trained human moderators. But, as
the number of users and associated posts increases,
so does the workload for moderators. This increases
the cost to run the service and potentially, the delay
between a post being made by a user and it appear-
ing online, which has a negative impact on the ex-
perience of users. We posit that whilst a fully auto-
mated moderation system is unlikely to be able to deal
with complex edge cases, there is scope for employ-
ing a semi-automated moderation system which pre-
labels posts before they are presented to human mod-
erators. Such a semi-automated system could greatly
reduce the workload of human moderators, accelerate
the moderation process, avoid some low-level human
errors and ultimately enhance the experience of users.
The potential benefits of semi-automated moder-
ation are not limited to the specific use-case consid-
Wang, D., Weeds, J. and Comley, I.
Improving Mental Health using Machine Learning to Assist Humans in the Moderation of Forum Posts.
DOI: 10.5220/0008988401870197
In Proceedings of the 13th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2020) - Volume 5: HEALTHINF, pages 187-197
ISBN: 978-989-758-398-8; ISSN: 2184-4305
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
187

ered so far. More generally, most of the posts and
comments on any websites, online forums or social
media have the chance of containing some improper
content. Following on from earlier research with sim-
ilar results, a survey of over 4000 Americans in 2017
found that roughly 40% of their respondent had per-
sonally experienced some form of online harassment
(from offensive name-calling to stalking and sexual
harassment) and over 60% of them consider it to be
a serious problem (Duggan, 2017). Many companies
and non-profit organisations only have a limited bud-
get for hiring human moderators and, thus, a semi-
automated moderation model may be useful. With an
automated system pre-reviewing the content, a human
is only required to check cases which the system can-
not place with high probability in either “accepted” or
“rejected” categories. In the long-term, the accuracy
of such a system may become equal or even better
than that of a human moderator, who may be prone to
slips of concentration or inconsistency. In this case,
the system might be viewed as an automated modera-
tion model which is able to directly ‘accept’ to ‘reject’
the posts. In any case, the workload of human moder-
ators is decreased and user experience is increased.
Here, specifically, we explore the feasibility of
building a semi-automated moderation model that is
able to reduce the moderation workload and accel-
erate the moderation speed in the MeeTwo scenario.
To ensure high accuracy, the aim is to assist human
moderators, rather them replace them, in moderat-
ing the posts and replies on the MeeTwo platform.
Working in a real-world scenario means that there
are challenges not always present in academic stud-
ies using large datasets which are carefully controlled
and balanced. The dataset provided by MeeTwo has
been collected over two years of operation and is of
medium-size, containing around 22K labelled posts,
where the average length of post is 45 words. The
dataset is also very unbalanced with regard to the
numbers of accepted and rejected posts. Only a mi-
nority of posts, less than 10%, have the label “reject”.
The lack of “reject” data makes it more challenging
to reliably train machine learning models which can
generalise to unseen data.
Another challenge in studying negative online be-
haviour is the myriad of forms it can take and the lack
of a clear, common definition (Saleem et al., 2017).
Some previous work has explored different forms
of online behaviour including hate speech (Gagliar-
done et al., 2015), online harassment (Cheng et al.,
2015), and cyber-bullying (Pieschl et al., 2015). In
the real-world dataset explored here, there are mul-
tiple reasons for posts being labelled with “reject”.
This makes it much harder to build a general model
which can successfully make a binary classification
decision. Here, we investigate building multiple clas-
sifiers for the most commonly occurring rejection cat-
egories. However, breaking down the categories in
this way further exacerbates the problems caused by
a lack of data.
Various machine learning (ML) researchers (Shri-
vastava et al., 2017; Park et al., 2019) have demon-
strated the effectiveness of data augmentation tech-
niques in increasing the amount of training data avail-
able and, thus, the generalizability of the models
learnt. As will be discussed further in Section 2,
researchers in the area of Natural Language Pro-
cessing (NLP) have also recently started looking for
ways to augment linguistic datasets. Most recently,
transfer learning models, e.g., BERT (Devlin et al.,
2018), have been developed where a general language
model can be trained on very large unlabelled cor-
pus and then leveraged in domain-specific scenarios
with small amounts of labelled training data. Here,
we investigate the applicability of both data augmen-
tation methods and transfer learning methods in a
real-world scenario where accuracy and user trust are
paramount. We evaluate the effectiveness of these
techniques, comparing with more conventional NLP
technology: 1) Logistic Regression (LR) classifier
applied to Term Frequency - Inverse Document Fre-
quency (TF-IDF) document representations, and 2)
Long Short Term Memory (LSTM) networks applied
to general-purpose words embeddings.
The contributions of this research are as follows.
We demonstrate that NLP and ML technology has
come of age and can now be successfully deployed in
challenging real-world scenarios in the area of Health
Informatics. More specifically, we show that a com-
bination of training data augmentation and transfer
learning methods can yield highly accurate classifi-
cation models despite small and unbalanced datasets.
Furthermore, we show that data augmentation tech-
niques that insert and replace synonyms which have
been discovered automatically from corpora outper-
form dictionary-based techniques. Accuracy of our
models in classifying previously unseen posts, across
4 different rejection reason categories, is close to hu-
man performance. Thus, a live system, which uses
these models to pre-label posts, will be effective in
increasing the consistency of moderation and in re-
ducing human-time to moderate.
2 RELATED WORK
Wulczyn et al. (2017) demonstrate that the perfor-
mance of a machine learning model can be close to
HEALTHINF 2020 - 13th International Conference on Health Informatics
188

humans on comments moderation. They use an N-
gram word representation to represent a large dataset
of 115K Wikipedia comments which have been la-
belled as personal attack (“reject”) or not (“accept”).
The classification architectures compared are linear
regression (LR) and a simple feed-forward neural net-
work or multiple layer perceptron (MLP). They show
that MLP performs better on detecting the personal
attack comments and that it achieves 1% absolute less
than humans.
Other researchers (Pavlopoulos et al., 2017) have
investigated applying more complex neural networks
or deep learning models to the moderation of com-
ments. Here, experiments based on the 115K
Wikipedia comments and a Gazzetta dataset (1.45M
training comments) show that Recurrent Neural Net-
work (RNN) models outperform Convolutional Neu-
ral Network (CNN) models as well as a word-list
baseline. Furthermore, more complex RNN models
using an attention mechanism lead to further perfor-
mance increases. Despite near human performance,
they also conclude that it is more realistic to build
a semi-automated system to assist human moderators
rather than replace them.
However, the complex neural network models
investigated in the aforementioned research require
large labelled datasets in order to achieve such im-
pressive results. These datasets also contain a reason-
able balance of examples for both classes and only a
single rejection reason. Thus, we cannot necessarily
expect such good results on a real world dataset which
is small, unbalanced and containing multiple rejection
reasons.
Data augmentation as a method to increase the
number of training examples and thus boost model
performance has been extensively researched in com-
puter vision (Shrivastava et al., 2017) and more re-
cently in NLP (Park et al., 2019). In computer vision,
it is now standard to rotate, reflect and crop images
as these transformations are unlikely to affect a clas-
sification decision as to whether an image contains,
say, a face or not. In NLP, the synonyms replacement
method (Kobayashi, 2018) has been shown to be an
effective method for data augmentation. Other possi-
ble data augmentation methods for NLP, explored by
Wei et al. (2018) include synonyms insertion, random
swap and random deletion. They combined synonyms
replacement, synonyms insertion, random swap and
random deletion together and find them effective on 5
NLP tasks.
Many of these aforementioned data augmentation
techniques rely on a source of linguistic knowledge
about the semantics of words. For example, both
Kobayashi et al. (2018) and Wei et al.(2019) use
synonyms which are randomly selected from Word-
Net (Fellbaum, 1998). However, there is an exten-
sive literature in NLP on the automatic discovery of
semantically related words, stemming from the distri-
butional hypothesis (Harris, 1954) which states that
words which have similar meanings are used in sim-
ilar contexts. Automatic methods for discovering
synonyms have an advantage over dictionary-based
methods in that they can be tailored to a specific do-
main. They can therefore be expected to have bet-
ter coverage of the vocabulary and domain-specific
meanings (McCarthy et al., 2004). Currently, two
of the most popular methods for constructing general
purpose or domain-specific word representations are
Word2Vec (Mikolov et al., 2013) and GloVe (Pen-
nington, 2014). These methods owe their popular-
ity due to their ability to represent word meaning in
a low-dimensional space (typically around 300 di-
mensions). However, like all word representation
methods based on the distributional hypothesis, it is
well known (Weeds et al., 2004) that they conflate
different semantic relationships (e.g., synonymy, hy-
ponymy, antonymy, meronymy and topicality) and
whether they can be used successfully in data aug-
mentation remains an empirical question, which we
explore here.
Another potential data augmentation technique,
not explored here, exploits machine translation tech-
nology (Yu et al., 2018): alternative training examples
can be generated by translating a text from English to
some other language (e.g., French) and then translat-
ing it back into English. However, this method relies
on an external service (e.g., the Google Translate API)
or a fully implemented machine translation model,
making it considerably more time-consuming to pro-
duce a similar sized augmented dataset than when us-
ing the simpler methods described above.
Most recently in NLP, there has been a lot of in-
terest in transfer learning models (Howard and Ruder,
2018; Devlin et al., 2018; Peters et al., 2018; Radford
et al., 2013). Rather than augmenting a small domain-
specific training set, these models rely on building a
large general-purpose language model (through pre-
training on unlabelled data) and then transferring this
knowledge to a domain-specific task (through fine-
tuning on small amounts of labelled data). Univer-
sal Language Model Fine-tuning (ULMFiT) (Howard
and Ruder, 2018) was shown to outperform the state-
of-art on six classification tasks. Furthermore, perfor-
mance with 100 labelled examples matched the per-
formance of training on 10K from scratch (Howard
and Ruder, 2018), thus making it particularly useful
in scenarios with limited amounts of labelled data.
Subsequently, Bidirectional Encoder Representations
Improving Mental Health using Machine Learning to Assist Humans in the Moderation of Forum Posts
189

from Transformers (BERT) (Devlin et al., 2018) have
been shown to beat ULMFiT and achieve a new state
of art in many NLP tasks. The architecture of BERT
differs from other recent deep learning architectures
(Peters et al., 2018; Radford et al., 2013) in its use of
transformers (rather than LSTMs) and in its inherent
bidirectionality. It also uses a fully connected layer
for both the encoder and decoder networks. Stacked
self-attention and point-wise architecture are used in
the encoder and decoder parts (Vaswani et al., 2017).
The encoder has 6 identical layers which take the in-
put embeddings and produce a 512-dimensional out-
put. The decoder takes that vector and finally outputs
the probabilities. An attention function is used to map
a set of key-value and query pairs to an output vector.
The network linearly projects the queries, keys and
values in order to make a multi-head attention. Thus,
the embedding of each word in a sequence captures
contextual information about words in other positions
in the sequence.
Pre-training of the BERT model also differs from
pre-existing models, which have tended to use a
continuous bag-of-words (CBOW) model in training,
through its use of masked language models (MLM).
The MLM model randomly masks some percentage
(15%) of input tokens, replacing them with 80% prob-
ability of [MASK], 10% probability of a random
word and 10% probability of unchanging; the model
must then predict those masked tokens (Devlin et al.,
2018). The difference between MLM and CBOW is
that the MLM model randomly masks some percent-
age of input tokens while the CBOW model contin-
uously masks tokens withion a fixed window. This
means that in every round of training, a MLM model
is able to consider the information of the whole in-
put while a CBOW model is only able to consider the
information of that fixed window.
After pre-training, a BERT model can be fine-
tuned for a variety of NLP tasks with the simple ad-
dition of a single output layer. Recently, pre-trained
BERT has been released making it simple and cheap
to deploy in real-world scenarios. However, its per-
formance on a real-world problem such as ours, rather
than standard NLP tasks from the academic literature,
has yet to be seen.
3 DATASET
The data for this research was supplied free-of-charge
by MeeTwo Education Ltd. At the time of the study,
the dataset contained around 22487 labelled posts
made by over 1000 users. Each post is associated
with a user profile, which includes a user’s id, gender,
birth month, birth year and general location. User ids
were anonymised by MeeTwo in the dataset so that
they are meaningless strings and cannot be used to
identify individuals. Further, personal details from
rejected posts were also removed at source and data
encryption was used to futher safe-guard the dataset.
Any rejected posts are labelled with “reject” together
with the reasons for rejection.
The dataset is a heavily imbalanced dataset; 1654
out of 22487 posts are labelled “reject” and the re-
mainder are labelled “accept”. There are also 37 dif-
ferent categories or reasons for rejection observed in
the dataset. Most of the categories of rejected posts
contain very few posts. Here we focus on the 4 cat-
egories which contain more than 100 posts, which
are Suicidal Ideation, Not Right for MeeTwo, Unclear
and Offensive posts. The corresponding frequencies
of each of these categories is shown in Table 1.
Table 1: Rejection reasons occurring more than 100 times
in the MeeTwo dataset.
Rejection Reasons Frequency
Suicidal Ideation 453
Not right for MeeTwo 353
Unclear 225
Offensive 109
One of 33 other reasons 514
Total Rejected posts 1654
Figure 1: WordClouds for different rejection reasons. Top
left: Suicidal, top right: Unclear, bottom left: NotRight,
bottom right: Offensive.
The posts in the dataset range in length from 1
word to 140 words, with an average length of 45
words. Figure 1 shows the most frequently occur-
ring words (ignoring stop words) in each of the 4
chosen categories of rejected posts. We see that two
of the rejection categories (Suicidal Ideation and Of-
fensive) appear to have clearly related words associ-
ated with them. For example, in Suicidal Ideation
posts, the most frequent content words include ‘life’,
‘kill’, ‘end’, ‘die’ and ‘hate’. Looking at Offensive
posts, many of the most frequently occurring words
HEALTHINF 2020 - 13th International Conference on Health Informatics
190

are well-known swear words. In contrast, the other
two rejection categories (Unclear and NotRight) do
not have such obvious clearly related words. For ex-
ample, the most frequent words in both of these cate-
gories include ‘still’, ‘help’, ‘girl’ and ‘good’, which
are likely to also occur in other categories and in ac-
cepted posts. Consequently, these categories of re-
jected posts are likely to be harder to identify.
4 METHOD
There are two main parts to our method. First, the
training dataset is automatically augmented. Second,
binary classification models are trained for each of
the rejection categories. Due to the small number
of posts in each category, it is not possible to create
separate training, validation and testing sets for each
category. Therefore, hyper-parameter optimisation is
carried out on a single category Suicidal Ideation and
the other three categories are reserved for testing.
In Section 4.1, we discuss augmentation tech-
niques in more detail: introducing 4 potential aug-
mentation techniques which we use in our experi-
ments. In Section 4.2, we discuss machine learning
architectures for classification in more detail: intro-
ducing 3 potential models of increasing complexity
(Logistic Regression, LSTM, BERT).
4.1 Data Augmentation
The point of data augmentation is to improve a
model’s performance on unseen data. In general, the
number of training examples is increased by taking
existing examples and carrying out simple transfor-
mations which we do not expect to affect the label.
All of the techniques described below have two pa-
rameters α and n: α controls how similar a trans-
formed example will be to the original example, and
n controls how many times the transformation is ap-
plied to a single example and, thus, also the size of
the resulting augmented dataset, which will be n + 1
times the size of the original training set. We will now
describe each technique in detail. Table 2 shows ex-
amples of using these 4 methods.
• Synonyms Replacement(SR): Randomly select
a proportion (α) of the words in each sentence and
replace them by their closest synonyms i.e., most
similar words. For example, if α = 0.2 we will
replace 20% of the words in each post. If n = 2,
then we will do this twice to each post resulting in
2 new posts for each of the original posts.
• Synonyms Insertion(SI): Randomly select a pro-
portion (α) of the words in each sentence and in-
sert their most similar words at a random position
in the same sentence.
• Random Deletion(RD): Randomly delete a pro-
portion (α) of the words in each sentence.
• Random Swap(RS): Randomly select a propor-
tion (α) of words in each sentence and swap their
position with another randomly selected word in
the sentence.
We experiment with two ways of generating syn-
onyms for words: WordNet and word2vec. WordNet
(Fellbaum, 1998) is a lexical database which groups
words into sets of synonyms called synsets. It is
straightforward to lookup the synonyms of a word
in WordNet, but these will be based on lexicogra-
phers’ knowledge of general usage and will not re-
flect the dominant sense within the domain. If a word
has multiple synonyms, one of them is chosen at ran-
dom. In the first example in Table 2, we see that the
word ‘school’ is replaced by the WordNet synonym
‘civilise’. This is unlikely to be the intended sense
of ‘school’ in the MeeTwo dataset. In fact, the word
‘civilise’ is not used in any of the MeeTwo posts and
therefore this training example is of very limited use.
Word2vec (Mikolov et al., 2013) is a continu-
ous space model based on neural networks which
generates distributed word embeddings that can be
used in downstream NLP tasks. In order to use
word2vec to generate synonyms we first prepare the
in-domain training corpus (using the nltk library to
carry out case normalisation, tokenisation and stop-
word & punctuation removal). We then use the
gensim library to build a word2vec model with de-
fault parameters (sg=0, window=5, size=100) and
also to find the most similar word to a given word,
according to cosine similarity between embeddings.
Crucially, the word2vec model is trained on the
dataset, so all the words it generates must be in that
vocabulary. In the second example in Table 2, we
see that ‘go’ is replaced by ‘bring’, which occurs 546
times in the MeeTwo dataset.
4.2 Classification
Machine learning classifiers for document classifica-
tion take a numerical representation of the text as
input and output the most likely label for the docu-
ment. In its simplest form, the numerical represen-
tation of a post might be a vector which associates
each word in the vocabulary with a weight according
to its perceived importance in the post (e.g., based on
frequency). For more sophisticated machine learning
approaches, the numerical representation might be a
sequence of word embeddings. Here, we investigate
Improving Mental Health using Machine Learning to Assist Humans in the Moderation of Forum Posts
191

Table 2: Examples of different data augmentation techniques applied to the text “I cant push myself to go to school”.
Method alpha num synonyms text
Original Text “I cant push myself to go to school”
SR 0.15 1 word2vec “i cant push myself to bring to school”
SR 0.15 1 WordNet “i cant push myself to bring to civilise”
SI 0.15 1 word2vec “i cant push myself bring to go to school”
SI 0.15 1 WordNet “i cant tug push myself to go to school”
RD 0.15 1 “i cant myself to go to school”
RS 0.15 1 “school cant push myself to go to i”
three different classifiers: Logistic Regression(LR),
LSTM and BERT. Specifically, the input to the LR is
a TF-IDF document representation; the input to the
LSTM is a sequence of GloVe word embeddings; and
the input to BERT is a sequence of words, since this
model handles both the representation and the classifi-
cation internally. We now describe each classification
technique in more detail.
4.2.1 Architecture 1: TF-IDF and Logistic
Regression
In this architecture, a post is represented as a vector of
its TF-IDF values. For a given post, term frequency
(TF) is the frequency of a word in that post. IDF
is the inverse document frequency of the word i.e.,
the log reciprocal of the number of posts containing
that word. Thus, TF-IDF, which is the product of TF
and IDF, assigns higher weights to words which oc-
cur more frequently in an individual post and less fre-
quently in other posts.
Logistic regression (LR) is a simple classification
method, widely used in statistics and machine learn-
ing. It uses a logistic function to model a binary vari-
able. Having less parameters, it is not as sensitive to
the amount of training data as more complex machine
learning methods. Here, we use the TF-IDF embed-
ding as the input to LR. The output of the classifier is
the probability of each class label.
In our implementation, we first use python’s nltk
library to pre-process the data, carrying out tokeni-
sation, case normalisation, stopword and punctua-
tion removal and lemmatisation. These standard pre-
processing steps reduce the size of the vocabulary
and remove tokens / distinctions which are unlikely to
have an effect on classification. We then use python’s
scikit-learn library to construct the TF-IDF repre-
sentation of each post and to realise the LR classifer.
4.2.2 Archictecture 2: General Purpose Word
Embeddings and LSTM
Recurrent neural networks (RNNs) are typically used
to model sequences because the hidden state of an
RNN at any given time depends both on the current
input and the previous state of the network. Typically,
in language modelling, the input to an RNN is an em-
bedding of a word (a high dimensional representation
which captures similarities between words) and the
network is trained to predict the next word in the ob-
served sequence, given the current word and state of
the network (which represents the context). Vanilla
RNNs, however, have been shown to struggle with
long range dependencies between words (Hochreiter
et al., 2001). LSTMs attempt to overcome this prob-
lem by using 4 interacting layers in each repeated neu-
ron: a cell state for long term memory; a forget gate
to forget information; an input gate decides which val-
ues to update and what with; and an output gate that
controls what to output. A classification layer can be
put on top of any RNN, to make a prediction for a
document label based on the hidden state of the net-
work: either after the last token has been read or by
pooling hidden states after each token is read.
We use the pytorch library to realise an LSTM
which takes a sequence of general purpose (pre-
trained) word embeddings as input. Specifically, we
use GloVe (Pennington, 2014) embeddings with a di-
mensionality of 300 and a context window size of 8,
trained on a large, general corpus of English text. The
model has 2 LSTM and 2 linear hidden layers. The fi-
nal classification output is decided using the final lin-
ear layer.
4.2.3 Architecture 3: BERT Pre-trained
Embedding, BERT Fine-tuning and
Training
BERT (Devlin et al., 2018) is a deep neural network
architecture which can be used to generate contextu-
alised word embeddings and carry out classification
tasks. Using BERT typically has two steps. The first
is pre-training on a very large general corpus; the sec-
ond is fine-tuning on the specific task. Pre-training
BERT has a huge computational cost. Fortunately,
a number of pre-trained BERT models have been re-
HEALTHINF 2020 - 13th International Conference on Health Informatics
192

leased as open source by the developers
1
. The mod-
els for English have been pre-trained on the concate-
nation of BooksCorpus (800M words) and English
Wikipedia (2,500M words). There are different ver-
sions for cased and uncased text as well as two dif-
ferent sizes of model: BERT-base and BERT-large.
BERT-base has 12 layers, 768 hidden units, 12 heads
and a total of 110M parameters. BERT-large has 24
layers, 1024 hidden units, 16 heads and a total of
340M parameters.
In our implementation, the BERT-base uncased
pre-trained model is employed. We then directly build
a downstream model by fine-tuning this pre-trained
BERT using our own labelled training data.
The fine-tuning part of BERT for sequence-level
classification tasks is straightforward. To get an em-
bedding of the input sequence, the final hidden state
is taken for the first token in the input by identifying
the special [CLS] word embedding and outputting a
vector as C ∈ R
H
. This vector is the input of a clas-
sification layer W ∈ R
K×H
where K is the number of
classes. The final label probability is computed with a
softmax function. The parameters W are then trained
in order to maximise the probability of the correct la-
bel. The hyper-parameters for fine-tuning are batch
size, learning rate and number of epochs. We use a
training batch size of 24 and a learning rate of 2e − 5.
Convergence was achieved after a single epoch of
training, with no benefit seen from continued train-
ing.
5 EXPERIMENTS
We carried out two sets of experiments. First, we op-
timised the hyper-parameters for data augmentation
(see Section 5.1). Second, we compared the three dif-
ferent machine learning architectures, with and with-
out data augmentation, on the four different categories
of rejection reason (see Section 5.2).
5.1 Data Augmentation
Hyperparameter Tuning
As discussed in Section 4.1, each data augmentation
technique has 2 parameters: α and n. We experi-
ment with these hyperparameters on just the Suicidal
Ideation category of posts. We prepare the training
and testing data in the following way.
• Select all of the Suicidal Ideation posts labelled
“reject” (453 posts).
1
https://github.com/google-research/bert
• Randomly select the same number of posts (453)
from posts not rejected for Suicidal Ideation.
• Merge the posts selected in above 2 steps to make
a new dataset: the Suicidal Ideation dataset.
• Split the dataset into 75% training and 25% test-
ing data.
After testing each data augmentation technique
individually to find the best hyperparameters, all of
the techniques were used together with their best hy-
perparameters to augment the training dataset for the
subsequent experiments.
5.2 Post Classification Experiments
Here, we investigate the effect of data augmentation
on each of the machine learning architectures intro-
duced previously (LR, GloVe + LSTM, BERT) on
each of the categories for possible post rejection (Sui-
cidal Ideation, Offensive, Not Right for MeeTwo and
Unclear). The process of carrying out these experi-
ments is as follows.
• Prepare each the data for each category of rejec-
tion reason. First, select those rejected posts in
that category. Second, randomly select the same
number of other posts (accepted or other rejection
category). Third, merge the above 2 datasets to-
gether to form the original dataset for that cate-
gory, which is split into training (75%) and testing
(25%) sets..
• Augment the training dataset prepared using the
best parameters of data augmentation methods.
• Use the original prepared dataset and augmented
dataset separately to train each model and test on
the same held-out testing data.
• Compare the accuracy of the different models on
the test data.
The results of model comparison are the accuracy
of each model on each of four different categories of
posts. The average accuracy over the four categories
is also considered.
6 RESULTS
In this section, we present our results on each set of
experiments.
6.1 Data Augmentation
Hyperparameter Tuning
We conducted experiments using a range of α
and n values (α ∈ {0, 0.1, 0.2, 0.3, 0.4, 0.5} and n ∈
Improving Mental Health using Machine Learning to Assist Humans in the Moderation of Forum Posts
193
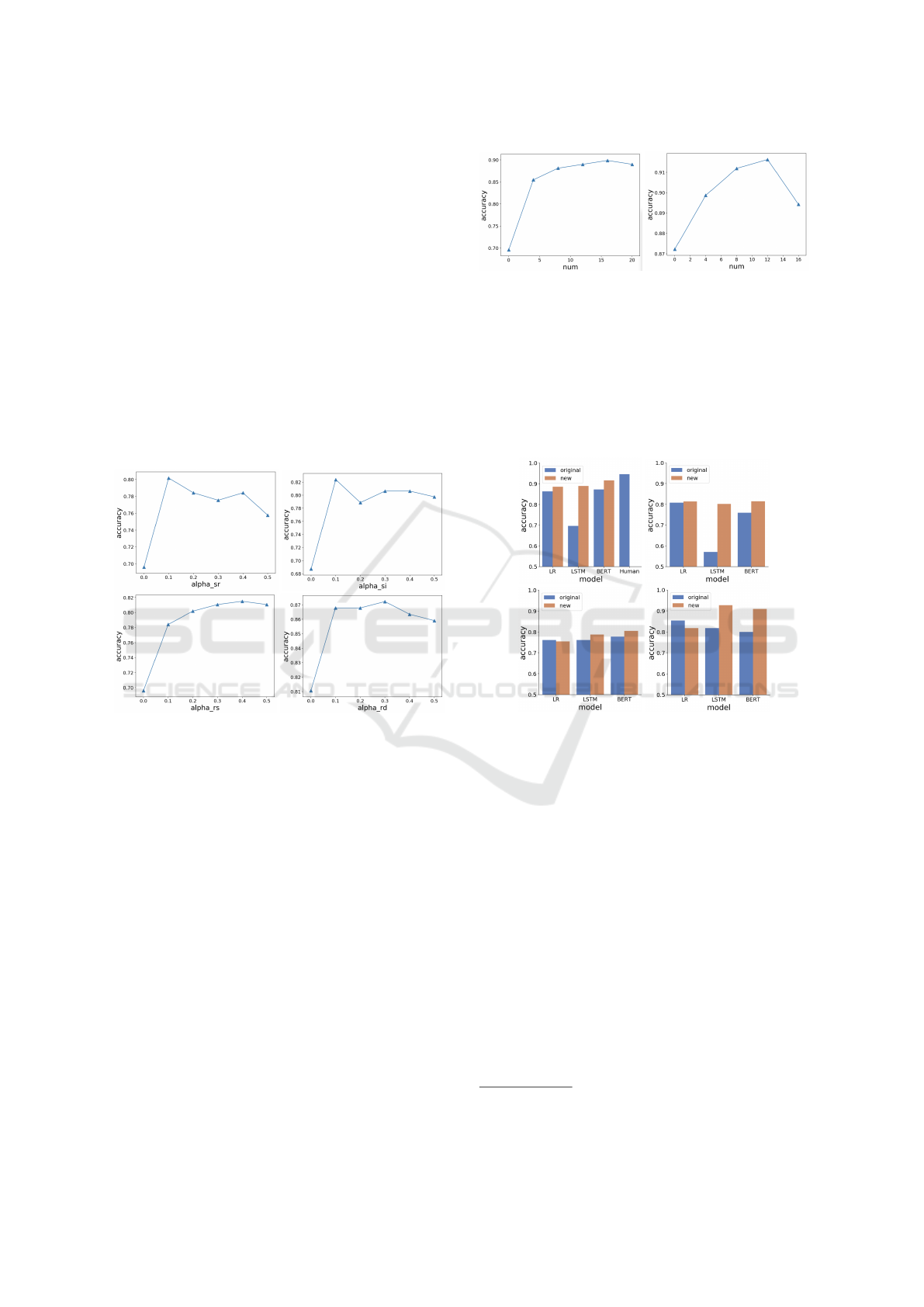
{0, 4, 8, 12, 16, 20}).
When testing on Suicidal Ideation data, all 3 ma-
chine learning architectures make gains in perfor-
mance through the use of the data augmentation tech-
niques. Figure 2 shows the effect of tuning α in data
augmentation methods combined with an LSTM (on
Suicidal Ideation posts). Here n is kept constant (n =
3). We see that optimal performance is achieved with
all of the data augmentation methods with a relatively
low value of α. This means that the best augmented
posts are relatively similar to the original posts (con-
taining, say, 80-90% of the same tokens). In general,
we observed the same patterns for the other classifi-
cation architectures. The only significant difference
being that random swap has no effect on the LR clas-
sifier (since the document representation is based on
a bag-of-words rather than a sequence).
Figure 2: Tuning α for LSTM on Suicidal Ideation posts.
Top left: SR, top right: SI, bottom left: RS, bottom right:
RD.
Figure 3 shows the effect of tuning n in the
data augmentation methods for the LSTM and for
BERT (on Suicidal Ideation posts). Both architec-
tures show substantial improvements with data aug-
mentation (over 20%). We observe that the LSTM re-
quires a greater amount of augmentation (n > 20) to
achieve results in the same ballpark as BERT (n = 4).
The LR classifier, on the other hand, benefited less
from data augmentation, with performance only im-
proving by around 4%. This peak performance oc-
curred at around n = 8.
6.2 Post Classification Experiments
Here, we present the performance of each model on
four categories of posts and the average performance
over the four categories.
Figure 3: Tuning n for LSTM and BERT on Suicidal
Ideation Posts. left: LSTM, right: BERT.
Figure 4 shows our results for the different cate-
gories. The blue bars represent the accuracy of mod-
els which are trained on original training data, while
orange bars represent the accuracy of models which
are trained on data augmented by data augmentation
methods with best parameters.
Figure 4: Testing on different categories. Top left: Suici-
dal Ideation, top right: Not Right for MeeTwo, bottom left:
Unclear, bottom right: Offensive.
From the results we make the following obser-
vations. For the Suicidal Ideation category, the TF-
IDF+LR architecture gains 3 absolute points with
data augmentation; GloVe+LSTM gains 21 absolute
points; BERT gains 5 absolute points and reaches the
highest accuracy among 3 models. The best accuracy
is 0.916 which is close to humans accuracy which is
0.946
2
.
For the Not Right category, TF-IDF+LR increases
1 absolute point; GloVe+LSTM gains 22 absolute
points; BERT gains 3 absolute points and reaches the
highest accuracy among 3 models. The best accuracy
is 0.82 which is much less than the accuracy on Suici-
dal Ideation category. One likely reason for this is
that Suicidal Ideation posts normally contain some
obvious words such as kill, life, sad and so on. Not
2
Human accuracy is using the same test data and testing
by professional posts moderation staff of MeeTwo
HEALTHINF 2020 - 13th International Conference on Health Informatics
194
Right posts are those posts that are not in line with the
MeeTwo rules. These are more difficult to classify.
For the unclear category, TF-IDF+LR decreases 1
absolute point; GloVe+LSTM gains 3 absolute points;
BERT gains 3 absolute points and reaches the highest
accuracy among 3 models. The best accuracy is 0.81
which is quite close to the accuracy on notRight cate-
gory. Unclear posts may include posts that are essen-
tially meaningless. Those kind of posts are also more
difficult for the machine learning models to classify.
LSTM achieves highest accuracy on the Offensive
category of posts. The accuracy is 0.93 which is much
higher than LR. BERT also achieves a good accuracy
which is 0.91. Offensive posts are quite similar with
Suicidal Ideation posts. Both of them have some ob-
vious words, which makes classification easier for all
of the models.
More generally we see that data augmentation is
much more beneficial to the more complex, data hun-
gry architectures such as LSTM and BERT. These
architectures need a large amount of data to achieve
peak performance. The accuracy of 4 different cate-
gories in Table 3 all show that when using augmented
training data, the test accuracy of LSTM and BERT
are greatly improved. For the TF-IDF+LR model, the
increase in data amount does not have the same im-
pact. In fact, in some categories, the accuracy of LR
decreases with the augmented data.
The BERT model achieves highest accuracy on
most of the categories. The highest average accuracy
is the BERT model. The average accuracy of BERT
and LSTM are very close and is around 5 absolute
points higher than LR.
6.3 Error Analysis
The incorrect predictions made by the different mod-
els and the human are not all the same. Table 4 shows
some examples of errors made by each on the Suicidal
Ideation test set. 0 represents an “accepted” decision
for the post while 1 represents a “rejected” decision
for the post. The first post shows that human is correct
while all other models are wrong. The post is quite
short. Some words like break, anymore may lead the
models to a wrong prediction. The second post is the
scenario where the human is wrong while all mod-
els are correct. The third and fourth posts show only
BERT is correct or only BERT is wrong. We note that
the gold standard label was also made by some human
moderator when the posts were uploaded. Therefore,
the gold standard label may not be one hundred per-
cent correct.
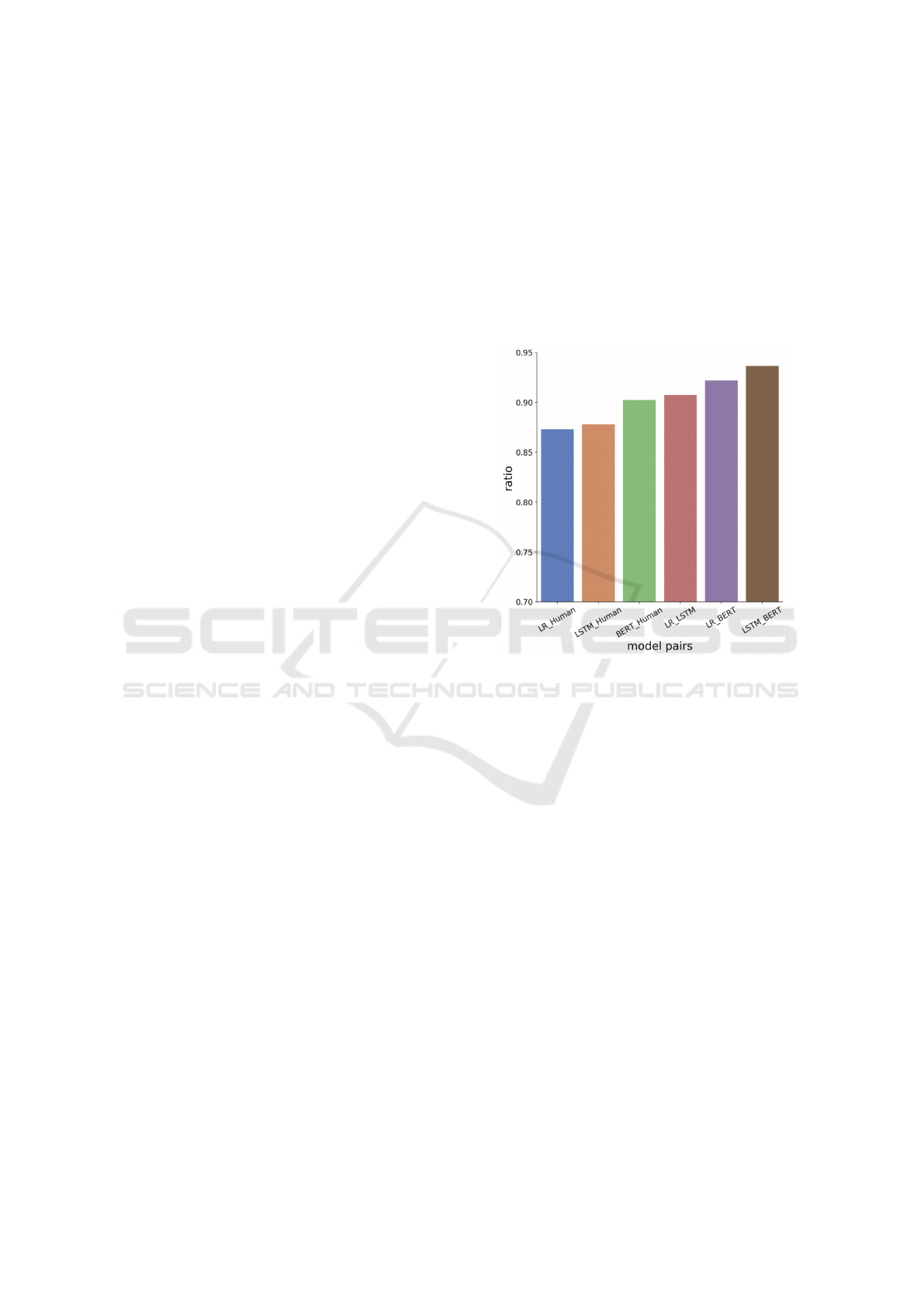
Figure 5 shows the proportion of the same pre-
dictions made by each pair of models on the Suici-
dal Ideation dataset. We note that LSTM and BERT
have the biggest overlap in errors. Therefore, typi-
cally, the mistakes made by these two models are very
similar. We also see that the smallest overlaps in er-
rors are between LSTM and human and between LR
and human. In other words, a greater proportion of
the BERT model’s errors are the same as the human
errors. Consequently, when the results of the LSTM
model and the BERT model differ, the BERT is more
likely to have made a human-like error.
Figure 5: Proportion of predicting the same result for any
pair of models or human.
7 CONCLUSION AND FUTURE
WORK
In this work, we have explored the feasibility of build-
ing a semi-automated moderation model that is able
to reduce the moderation workload and accelerate the
moderation speed in the MeeTwo scenario. We have
demonstrated a practical pipeline which can be used
in this and other small dataset classification scenarios.
We recommend the use of simple data augmentation
methods to build up a much larger training dataset and
then use this dataset to train a data hungry model such
as BERT.
There are in total 38 different possible reasons for
posts being rejected from MeeTwo. Here, we have
focused on the top 4 rejection reasons which account
for more than half of the rejected posts. These are
Suicidal Ideation, Not Right for MeeTwo, Offensive
and Unclear. Using a combination of dataset aug-
mentation and modern machine learning architectures
for classification, we have demonstrated that, despite
Improving Mental Health using Machine Learning to Assist Humans in the Moderation of Forum Posts
195
Table 3: The average performance of 3 models using original data and augmented data.
Model 1(LR) Model 2(LSTM) Model 3(BERT)
Original Data Average Accuracy 0.82 0.70 0.75
Augmented Data Average Accuracy 0.83 0.86 0.87
Table 4: Example errors made by the different architectures on the Suicidal Ideation dataset.
No. Text Real
Label
Human
Label
LR
Label
LSTM
Label
BERT
Label
1 my friend doesn’t want to be with me at break or
lunch anymore
0 0 1 1 1
2 Sometimes I wonder what it’s like to not be alive.
Does anybody else wonder whether death is better
than life? I think about it a little too much I think.
1 0 1 1 1
3 I need to stay happy. I have a bottle of anxiety pills
in the bathroom. One pill a day it says. I could just
swallow them all if I get upset and suicidal. I need
to stay happy.
1 0 0 0 1
4 I’m falling for someone I can’t fall for what do I
do?
0 1 1 1 0
limited and unbalanced training data, it is possible
to build classifiers with near-human accuracy for a
number of different rejection reasons. On the Sui-
cidal Ideation category, we achieve an accuracy of
91.2% on a balanced dataset (compared to human per-
formance of 94.5%). In the Offensive category, we
achieve 92% accuracy. Accuracy is lower (around
80%) on less well-defined categories such as Unclear
and Not Right for MeeTwo. However, in the real-
world scenario, where a much smaller proportion of
posts should actually be rejected than in our testing
scenario, these methods will be very valuable in be-
ing able to identify and flag posts of potential concern,
which a human moderator can then check.
We have demonstrated 4 different augmentation
techniques which can increase the amount of training
data for machine learning by 20 times or more. Our
results show that these methods can massively boost
model performance when we only have small labelled
dataset. We compared three machine learning archi-
tectures (TF-IDF+LR, GloVe+LSTM and BERT) in a
practical text classification task. In general, the per-
formance of BERT was the highest. However, with-
out data augmentation, the performance of the LSTM
is poor and performance of BERT is on a par or worse
than the simple baseline of TF-IDF representations
and a LR classifier. Thus, we conclude, that whilst
some data sparsity issues may be overcome through
the use of a pre-trained BERT model, it is of fur-
ther benefit to augment the training set used for fine-
tuning.
On the Not Right for MeeTwo and the Unclear
categories, the performance of BERT is higher than
LSTM while the performance of LSTM is close to
BERT on the Suicidal Ideation category and even
higher than BERT on the Offensive category. These
latter categories can be more easily defined in terms
of individual words (see Figure 1). This suggests that
the BERT model can work well even when the text has
no obvious words as indicators of a particular class.
There are a number of potential avenues for fur-
ther work. First, the data augmentation techniques
presented herein might be improved upon or ex-
tended. For example, other models or datasets could
be used to train the synonyms generation model. A
different or larger corpus for discovering semanti-
cally similar words might create a more generalize-
able model. Techniques for ensuring that only syn-
onyms (rather than antonyms or other related words)
are inserted or substituted could also be investigated.
Further, part-of-speech tagging or dependency analy-
sis might be used to ensure that the new training ex-
amples are linguistically plausible. Finally, we have
looked at ways in which to transform posts at the word
level. However, we could consider transforming posts
at the sentence or discourse level. For example, it
might be possible to create new sentences or posts
by combining different sentences or parts of sentence
which are in a post with a given label.
The second avenue for future work relates to ma-
chine learning classification model performance and
integrating these models into a live system. The 3
architectures investigated here could be blended (e.g.,
through a use of a simple voting system), which could
HEALTHINF 2020 - 13th International Conference on Health Informatics
196

increase the performance. In a practical system which
values recall over precision, if any of the models pre-
dict that a post should be rejected, then this should
be flagged to the human moderators. There are also a
number of other hyper-parameters and potential fea-
tures which could be explored. For example, we have
noticed that posts made by boys have a higher rejec-
tion rate. Consequently, future work could explore
whether and how to incorporate extra-linguistic fea-
tures of the posts including gender and age of user.
REFERENCES
Cheng, J., Danescu-Niculescu-Mizil, C., and Leskovec, J.
(2015). Antisocial behavior in online discussion com-
munities. In Ninth International AAAI Conference on
Web and Social Media.
Devlin, J., Chang, M., Lee, K., and Toutanova, K. (2018).
BERT: pre-training of deep bidirectional transformers
for language understanding. CoRR, abs/1810.04805.
Duggan, M. (2017). Online harrassment. Technical report,
Pew Research Center.
Fellbaum, C. (1998). WordNet: An Electronic Lexical
Database. Bradford Books.
Gagliardone, I., Gal, D., Alves, T., and Martinez, G. (2015).
Countering online hate speech. Unesco Publishing.
Harris, Z. (1954). Distributional structure. Word,
10(23):146 – 162.
Hochreiter, S., Bengio, Y., Frasconi, P., Schmidhuber, J.,
et al. (2001). Gradient flow in recurrent nets: the dif-
ficulty of learning long-term dependencies.
Howard, J. and Ruder, S. (2018). Universal language model
fine-tuning for text classification. arXiv preprint.
Kobayashi, S. (2018). Contextual augmentation: Data
augmentation by words with paradigmatic relations.
CoRR, abs/1805.06201.
McCarthy, D., Koeling, R., Weeds, J., and Carroll, J.
(2004). Finding predominant word senses in untagged
text. In Proceedings of the 42nd Meeting of the Asso-
ciation for Computational Linguistics (ACL’04), Main
Volume, pages 279–286, Barcelona, Spain.
McManus, S., Bebbington, P., Jenkins, R., and Brugha,
T. (2016). Mental health and wellbeing in england:
Adult psychiatric morbidity survey 2014.
McManus, S., Meltzer, H., Brugha, T. S., Bebbington, P. E.,
and Jenkins, R. (2009). Adult psychiatric morbidity
in england, 2007: results of a household survey.
Mikolov, T., Yih, W. T., and Zweig, G. (2013). Linguis-
tic regularities in continuous space word representa-
tions. In Proceedings of the 2013 Conference of the
North American Chapter of the Association for Com-
putational Linguistics: Human Language Technolo-
gies, pages 746–751.
Park, D. S., Chan, W., Zhang, Y., Chiu, C., Zoph, B., Cubuk,
E. D., and Le, Q. V. (2019). Specaugment: A sim-
ple data augmentation method for automatic speech
recognition. CoRR, abs/1904.08779.
Pavlopoulos, J., Malakasiotis, P., and Androutsopoulos, I.
(2017). Deep learning for user comment moderation.
CoRR, abs/1705.09993.
Pennington, J., S. R. . M. C. (2014). Glove: Global vectors
for word representation. In Proceedings of the 2014
conference on empirical methods in natural language
processing (EMNLP), pages 1532–1543.
Peters, M. E., Neumann, M., Iyyer, M., Gardner, M.,
Clark, C., Lee, K., and Zettlemoyer, L. (2018).
Deep contextualized word representations. CoRR,
abs/1802.05365.
Pieschl, S., Kuhlmann, C., and Porsch, T. (2015). Beware
of publicity! perceived distress of negative cyber in-
cidents and implications for defining cyberbullying.
Journal of School Violence, 14(1):111–132.
Radford, A., Narasimhan, K., Salimans, T., and Sutskever,
I. (2013). Improving language understanding by gen-
erative pre-training.
Saleem, H. M., Dillon, K. P., Benesch, S., and Ruths, D.
(2017). A web of hate: Tackling hateful speech in
online social spaces. CoRR, abs/1709.10159.
Shrivastava, A., Pfister, T., Tuzel, O., Susskind, J., Wang,
W., and Webb, R. (2017). Learning from simulated
and unsupervised images through adversarial training.
In 2017 IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), pages 2242–2251.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez A. N., ., and Polosukhin, I. (2017). Atten-
tion is all you need. In Advances in neural information
processing systems, pages 5998–6008.
Weeds, J., Weir, D., and McCarthy, D. (2004). Character-
ising measures of lexical distributional similarity. In
Proceedings of the International Conference on Com-
putational Linguistics (COLING), pages 1015–1021,
Geneva, Switzerland.
Wei, J. W. and Zou, K. (2019). EDA: easy data augmenta-
tion techniques for boosting performance on text clas-
sification tasks. CoRR, abs/1901.11196.
Wulczyn, E., Thain, N., and Dixon, L. (2017). Ex machina:
Personal attacks seen at scale. International World
Wide Web Conferences Steering Committee., pages
1391–1399.
Yu, A. W., Dohan, D., Luong, M., Zhao, R., Chen, K.,
Norouzi, M., and Le, Q. V. (2018). Qanet: Combining
local convolution with global self-attention for read-
ing comprehension. CoRR, abs/1804.09541.
Improving Mental Health using Machine Learning to Assist Humans in the Moderation of Forum Posts
197
