
Augmented Semantic Explanations for Collaborative Filtering
Recommendations
Mohammed Alshammari
1,2
and Olfa Nasraoui
1
1
Knowledge Discovery and Web Mining Lab, CECS Department, University of Louisville, Louisville,
Kentucky 40292, U.S.A.
2
Northern Border University, Rafha 76313, Saudi Arabia
Keywords:
Recommender Systems, Semantic Web, Collaborative Filtering, Matrix Factorization.
Abstract:
Collaborative Filtering techniques provide the ability to handle big and sparse data to predict the rating for
unseen items with high accuracy. However, they fail to justify their output. The main objective of this paper is
to present a novel approach that employs Semantic Web technologies to generate explanations for the output
of black box recommender systems. The proposed model significantly outperforms state-of-the-art baseline
models in terms of the error rate. Moreover, it produces more explainable items than all baseline approaches.
1 INTRODUCTION
Matrix factorization (MF) Koren et al. (2009) is a
powerful collaborative filtering technique. However,
MF lacks transparency even though it produces accu-
rate recommendations. This means that despite its ef-
ficient handling of big data and high accuracy in pre-
dicting unseen items’ ratings, it fails to justify its out-
put. Thus, it is called a black box recommender sys-
tem. Moreover, users’ explicit preferences may not
be enough for the model to consider some items in
the process of recommending new items. Since users
may not have given new items any preferences, these
items may be discarded. This cold-start problem is
well-known in the recommender systems field.
Extra information can be used to overcome both
the black box and cold-start problems. Information
can be found in semantic KGs built using semantic
web technologies. Linked open data (LOD) Bizer
et al. (2009) is a platform for linked, structured, and
connected data on the web. The goal of LOD is to
make information machine processable and semanti-
cally linked. For example, in the movie domain, in-
formation about movie stars or directors is available
in a linked way. If an actor has starred in two movies,
those two movies are linked. This can help us infer
new facts about movies that eventually lead to the res-
olution of the cold start and transparency problems
mentioned earlier.
Our research question is as follows: can we build
semantic knowledge graphs (KGs) about users, items,
and attributes to generate explanations for a black box
recommender system, while maintaining high predic-
tion accuracy?
This paper’s contribution consists of solving the
problem of a non-transparent MF recommender sys-
tem, in addition to constructing semantic KGs about
users, items, and attributes for the inference and ex-
planation process.
2 RELATED WORK
Explaining black box recommender systems has been
the subject of several studies. RippleNet Wang et al.
(2018) is an approach that used KGs in collaborative
filtering to provide side information for the system in
order to overcome sparsity and the cold-start problem.
This black box system takes advantage of KGs, which
are constructed using Microsoft Satori, to better en-
hance recommendation accuracy and transparency.
The authors simulate the idea of water ripple propaga-
tion in understanding user preferences by iteratively
considering more side information and propagating
the user interests. In the evaluation section, the au-
thors claim that their model is better than state-of-the-
art models. The research of Ai et al. (2018) focuses
on adding explanations to a black box recommender
system by using structured knowledge bases. The
system takes advantage of historical user preferences
to produce accurate recommendations and structured
knowledge bases about users and items for generating
Alshammari, M. and Nasraoui, O.
Augmented Semantic Explanations for Collaborative Filtering Recommendations.
DOI: 10.5220/0008070900830088
In Proceedings of the 11th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2019), pages 83-88
ISBN: 978-989-758-382-7
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
83

justifications. After the model recommends items, a
soft matching algorithm is used, utilizing the knowl-
edge bases to provide personalized explanations for
the recommendations. The authors argue that their
model outperforms other baseline methods. Bellini
et al. (2018) focuses on the issue of explaining the
output of a black box recommender system. In that
work, the SemAuto recommender system is built us-
ing the autoencoder neural network technique, which
is aware of KGs retrieved from the semantic web. The
KGs are adopted for explanation generation. The au-
thors claim that explanations increase the users’ satis-
faction, loyalty, and trust in the system. In their study,
three explanation styles are proposed: popularity-
based, pointwise personalized, and pairwise person-
alized. For evaluation, an A/B test was conducted
to measure the transparency of, trust in, satisfaction
with, persuasiveness of, and effectiveness of the pro-
posed explanations. The pairwise method was pre-
ferred by most users over the pointwise method. Ab-
dollahi and Nasraoui (2017) investigates the possibil-
ity of generating explanations for the output of a black
box system using a neighborhood technique based on
cosine similarity. The results show that Explainable
Matrix Factorization (EMF) performs better than the
baseline approaches in terms of the error rate and the
explainability of the recommended items.
3 PROPOSED METHOD
3.1 Semantic Knowledge Graphs (KGs)
The web is abundant with information that is being
harvested and structured into KGs. KGs are extensive
networks of objects, along with their properties, their
semantic types, and the relationships between objects
representing factual information in a specific domain
Nickel et al. (2016). Examples of KGs are DBpedia
Auer et al. (2007), Freebase Bollacker et al. (2008),
Wikidata Vrande
ˇ
ci
´
c (2012), YAGO Suchanek et al.
(2007), NELL Carlson et al. (2010), and the Google
Knowledge Graph Singhal (2012). In this study, DB-
pedia is used to build the desired KGs about users,
items, and attributes. In contrast with Alshammari
et al. (2018), where only one attribute (actors) was
considered in building the KG and, hence, the model,
more influential attributes (subject(s), actor(s), direc-
tor(s), producer(s), and writer(s)) are included to find
the similarity between items. The LDSD algorithm
Passant (2010) is used to weigh the similarity between
items. Then, Matrix Factorization (MF), Koren et al.
(2009) with the added regularization term in Joint MF
(JMF) Shi et al. (2013), is used for building the model.
3.2 Linked Data Semantic Distance
Matrix Factorization (LDSD-MF)
The loss function of the proposed technique, Linked
Data Semantic Distance Matrix Factorization (LDSD-
MF), is inspired by the work of Koren et al. (2009)
and Shi et al. (2013) as follows:
J =
∑
u,i∈R
(R
u,i
− p
u
q
T
i
)
2
+
γ
2
∑
i, j∈S
ldsd
(S
ldsd
i, j
− q
i
q
T
j
)
2
+
β
2
(k p
u
k
2
+ k q
i
k
2
). (1)
R
u,i
represents the rating for item i by user u. p
u
and
q
i
represent the low dimensional latent space of users
and items, respectively. S
ldsd
is the semantic KG. q
i
and q
j
indicate two items in S
ldsd
, and γ is a coef-
ficient that weighs the contribution of the new term,
S
ldsd
. Stochastic gradient descent Funk (2006) is em-
ployed to update p and q iteratively until J converges.
The updating rules are given by:
p
(t+1)
u
← p
(t)
u
+ α(2(R
u,i
− p
(t)
u
(q
(t)
i
)
T
)q
(t)
i
− βp
(t)
u
),
(2)
q
(t+1)
i
← q
(t)
i
+ α(2(R
u,i
− p
(t)
u
(q
(t)
i
)
T
)p
(t)
u
+ 2γ(S
ldsd
i, j
− q
(t)
i
(q
(t)
j
)
T
)q
(t)
j
− βq
(t)
i
). (3)
The KG is constructed using an approach following
Alshammari et al. (2018). In addition to the known
rating used to update q
i
, the KG also contributes to
the final predicted rating of item i by user u.
4 EXPERIMENTAL EVALUATION
In this study, the MovieLens 100K benchmark dataset
is used. The total number of users is 943, and that
of movies is 1,862. SPARQL, a semantic web query
language, is used for the mapping process between
MovieLens and DBpedia, and movie titles are used
for the mapping. The results indicate that 1,012
movies intersected in the two datasets. The reasons
for this reduction are either absent movies in DBpe-
dia or different spellings. The mapping also resulted
in a decrease in the total number of ratings to 60K. All
ratings are normalized to 1, and the hyper-parameters
are set to α = 0.01, β = 0.1, and γ = 0.9, after be-
ing tuned using cross-validation. 90% of the ratings
are used for training the model, and 10% are used for
testing the model. Since our method randomly initial-
izes the user and item latent spaces, an average of 10
experiments is reported.
KDIR 2019 - 11th International Conference on Knowledge Discovery and Information Retrieval
84

Table 1: Numeric values of selected attributes in the ex-
periment, with unique IDs in the second column, the total
number of triples for movies in the third column, and the
total number of triples for users in the fourth column.
Attribute Unique ID Triple (movies) Triple (users)
Subject 4996 19983 818784
Actor 4165 6770 332484
Director 1193 1577 92008
Producer 1154 1868 103943
Writer 1491 1944 110692
Five different properties are extracted from the se-
mantic KG DBpedia: subject, actor, director, pro-
ducer, and writer. The total number of unique sub-
jects is shown in the second column of Table 1. The
third column in Table 1 shows the total number of
previously existing triples of movies and attributes in
DBpedia. An example could be ”Mel Gibson is star-
ring in Braveheart.” The fourth column in Table 1 de-
scribes the size of the constructed semantic KG with
the total number of triples in each KG. For example,
”User 581 likes the actor Ben Kingsley to a certain
degree.”
Five baseline methods are used for comparison:
MF Koren et al. (2009), EMF Abdollahi and Nas-
raoui (2016) Abdollahi and Nasraoui (2017) Abdol-
lahi (2017), Probabilistic Matrix Factorization (PMF)
Salakhutdinov and Mnih (2007), Asymmetric Matrix
Factorization (AMF) BenAbdallah et al. (2010), and
Asymmetric Semantic Explainable Matrix Factoriza-
tion (ASEMF UIB) Alshammari et al. (2018).
Several metrics are used to evaluate the recom-
mender system. The first metric is the error rate
in equation (4), while the remaining metrics are the
Mean Explainability Precision (MEP), Mean Explain-
ability Recall (MER), and the harmonic mean of the
precision and recall (xF-score) Abdollahi and Nas-
raoui (2017), in equations (5-7).
RMSE =
s
1
| T |
∑
(u,i)∈T
r
0
ui
− r
ui
2
. (4)
T represents the total number of predictions, r
0
ui
rep-
resents the predicted rating on item i by user u, and
r
ui
is the actual rating on item i by user u.
MEP =
1
|U |
∑
u∈U
|R ∩W |
|R |
. (5)
MER =
1
|U |
∑
u∈U
|R ∩W |
|W |
. (6)
xF −score = 2 ∗
MEP ∗ MER
MEP + MER
. (7)
U represents the set of users, R is the set of rec-
ommended items, and W denotes the set of explain-
able items. MEP computes the ratio of recommended
Table 2: RMSE, varying the number of hidden features, K.
RMSE
K MF EMF PMF AMF ASEMF UIB LDSD-MF
10 0.205 0.205 0.698 0.236 0.205 0.204
20 0.212 0.211 0.698 0.27 0.204 0.204
30 0.214 0.215 0.698 0.309 0.204 0.204
40 0.216 0.217 0.7 0.344 0.203 0.205
50 0.217 0.217 0.7 0.374 0.203 0.206
and explainable items to the total number of recom-
mended items over all users. Similarly, MER cal-
culates the recommended and explainable items over
the total number of explainable items, again, over all
users. The xF-score is the harmonic mean of MEP
and MER.
Our hypothesis for the significance test is that our
model is better than baseline approaches using all
metrics. The null hypothesis that we are trying to re-
ject is that the mean of all metrics for all models are
equal by conducting a t-test experiments. The models
are ran 10 times while randomly initializing the user
and item latent factors, then we calculated all metrics
and did the significance tests which are reported in
this paper.
Table 3: RMSE significance test results in the movie do-
main (K = 10).
Model 1 Model 2 p-value
MF LDSDMF 2.3e-07
EMF LDSDMF 4.8e-08
PMF LDSDMF 4.04e-54
AMF LDSDMF 6.6e-22
ASEMF UIB LDSDMF 1.3e-07
4.1 Discussion
Table 2 shows the error rates of all the methods. The
best values are in bold (the lower the value, the better).
When K = 10, LDSDMF significantly outperforms all
the other methods with a small p-value as shown in
Table 3; however, it competes with ASEMF
UIB
as the
number of hidden features increases.
In Figures 1 and 2, there are six graphs showing
the performance of all models while varying θ
s
and
θ
n
. θ
s
is a threshold for items to be considered se-
mantically explainable or not, and θ
n
is a threshold
for items to be explainable based on the neighbor-
hood technique used in the baseline EMF (Abdollahi
and Nasraoui, 2017). The formula for generating the
neighborhood-based explainability matrix is
W
ui
=
(
|N
0
(u)|
|N
k
(u)|
i f
|N
0
(u)|
|N
k
(u)|
> θ
n
0 otherwise,
(8)
where N
0
(u) denotes the set of neighbors of user u
Augmented Semantic Explanations for Collaborative Filtering Recommendations
85
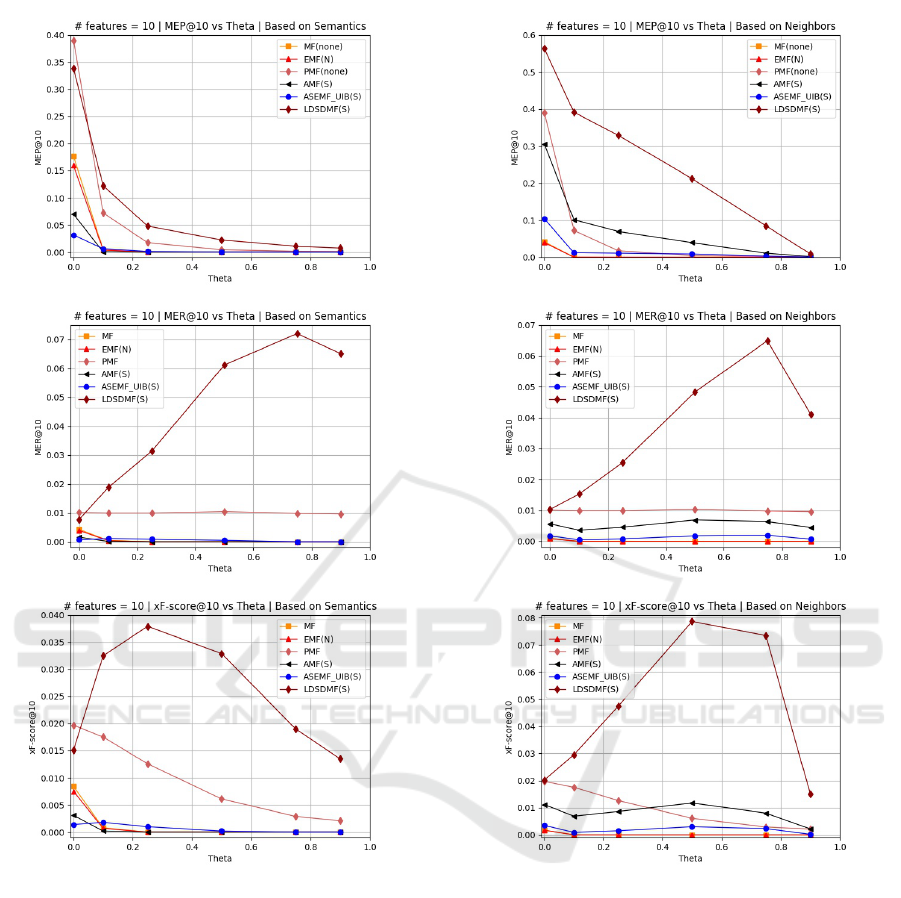
Figure 1: The upper graph shows the results of MEP@10
for all methods, while the middle one shows MER@10 for
all methods, and the lower graph illustrates the results of all
methods using the xF-score metric, which utilizes semantic
KGs against K.
who rated item i, and N
k
(u) depicts the list of the k
nearest neighbors of u.
The three graphs in Figure 1 illustrate that when
θ
s
is set to 0, which means that all items (even those
with a small explainability value) are considered ex-
plainable, the baseline PMF is the winner. However,
when adding more restrictions to items to be consid-
ered semantically explainable, the proposed method,
LDSDMF, significantly outperformed the other meth-
ods for all θ
s
values by all metrics (MEP, MER, and
xF − score). Tables 4, 5, and 6 present the signifi-
cance test results.
Figure 2: The upper graph shows the results of MEP@10
for all methods, while the middle one shows the MER@10
results for all methods, and the lower graph illustrates the
results of all methods using the neighborhood explainability
graph against K.
Graphs in Figure 2 present the models’ perfor-
mance when measuring the explainability of the rec-
ommended items based on the neighborhood tech-
nique. Our model, LDSDMF, significantly exceeded
all baseline methods in all three metrics (see Tables
7, 8, and 9 for significance test results). This obser-
vation shows that our proposed method recommends
more accurate explainable items, based on semantic
KGs and neighborhood based techniques, than all the
baseline methods.
KDIR 2019 - 11th International Conference on Knowledge Discovery and Information Retrieval
86

Table 4: MEP@10 significance test results (K = 10 and
θ
s
= 0.25) using semantic KGs.
Model 1 Model 2 p-value
MF LDSDMF 8.06e-23
EMF LDSDMF 8.1e-23
PMF LDSDMF 3.05e-17
AMF LDSDMF 8.06e-23
ASEMF UIB LDSDMF 2.6e-20
Table 5: MER@10 significance test results (K = 10 and
θ
s
= 0.25) using semantic KGs.
Model 1 Model 2 p-value
MF LDSDMF 6.2e-21
EMF LDSDMF 6.3e-21
PMF LDSDMF 2.1e-15
AMF LDSDMF 6.2e-21
ASEMF UIB LDSDMF 1.3e-19
Table 6: xF-score@10 significance test results (K = 10 and
θ
s
= 0.25) using semantic KGs.
Model 1 Model 2 p-value
MF LDSDMF 1.1e-21
EMF LDSDMF 1.1e-21
PMF LDSDMF 5.1e-16
AMF LDSDMF 1.1e-21
ASEMF UIB LDSDMF 5.6e-20
Table 7: MEP@10 significance test results (K = 10 and
θ
n
= 0.25) using neighborhood technique.
Model 1 Model 2 p-value
MF LDSDMF 1.9e-21
EMF LDSDMF 1.9e-21
PMF LDSDMF 3.9e-17
AMF LDSDMF 1.2e-13
ASEMF UIB LDSDMF 9.9e-19
Table 8: MER@10 significance test results (K = 10 and
θ
n
= 0.25) using neighborhood technique.
Model 1 Model 2 p-value
MF LDSDMF 1.2e-21
EMF LDSDMF 1.2e-21
PMF LDSDMF 1.4e-15
AMF LDSDMF 5.3e-15
ASEMF UIB LDSDMF 5.9e-19
4.2 Case Study
We investigated our dataset and selected a sample
user as an example to show how the model captures
the user’s desire and recommends the next new items
accordingly with an explanation. User 586 in the
MovieLens dataset rated 94 movies, including Twister
(1996) and Tombstone (1993) with 4-star ratings and
Table 9: xF-score@10 significance test results (K = 10 and
θ
n
= 0.25) using neighborhood technique.
Model 1 Model 2 p-value
MF LDSDMF 1.1e-21
EMF LDSDMF 1.1e-21
PMF LDSDMF 9.2e-16
AMF LDSDMF 6.4e-15
ASEMF UIB LDSDMF 5.9e-19
Figure 3: Example of Inferred Fact Style Explanation.
Apollo 13 (1995) with a 3-star rating. All three
movies are starred by Bill Paxton. Titanic (1997) in-
cludes the same actor in the starring actors list, and
the model recommended this movie among the top
10 recommended items. Using the semantic KGs on
users and attributes that were built by the model, our
model succeeds in capturing the user’s attribute pref-
erences and recommends new items accordingly. Fig-
ure 3 depicts a projected example of what an explana-
tion would look like for user 586.
5 CONCLUSIONS
As recommendation systems become an essential
component of big data and artificial intelligence (A.I.)
systems, and as these systems embrace more and
more sectors of society, it is becoming ever more criti-
cal to build trust and transparency into machine learn-
ing algorithms without significant loss of prediction
power. Our research harnesses the power of A.I., such
as KGs and semantic inference, to help build explain-
ability into accurate black box predictive systems in
a way that is modular and extensible to a variety of
prediction tasks within and beyond recommender sys-
tems.
REFERENCES
Abdollahi, B. (2017). Accurate and justifiable : new algo-
rithms for explainable recommendations. PhD thesis.
Augmented Semantic Explanations for Collaborative Filtering Recommendations
87

Abdollahi, B. and Nasraoui, O. (2016). Explainable matrix
factorization for collaborative filtering. In Proceed-
ings of the 25th International Conference Companion
on World Wide Web. ACM Press.
Abdollahi, B. and Nasraoui, O. (2017). Using explainability
for constrained matrix factorization. In Proceedings of
the Eleventh ACM Conference on Recommender Sys-
tems, pages 79–83, Como, Italy. ACM.
Ai, Q., Azizi, V., Chen, X., and Zhang, Y. (2018). Learn-
ing heterogeneous knowledge base embeddings for
explainable recommendation. Algorithms, 11(9).
Alshammari, M., Nasraoui, O., and Abdollahi, B. (2018).
A semantically aware explainable recommender sys-
tem using asymmetric matrix factorization. In Pro-
ceedings of the 10th International Joint Conference
on Knowledge Discovery, Knowledge Engineering
and Knowledge Management. SCITEPRESS - Sci-
ence and Technology Publications.
Auer, S., Bizer, C., Kobilarov, G., Lehmann, J., Cyganiak,
R., and Ives, Z. (2007). DBpedia: A nucleus for a web
of open data. In The Semantic Web, pages 722–735.
Springer Berlin Heidelberg.
Bellini, V., Schiavone, A., Di Noia, T., Ragone, A., and
Di Sciascio, E. (2018). Knowledge-aware autoen-
coders for explainable recommender systems. In Pro-
ceedings of the 3rd Workshop on Deep Learning for
Recommender Systems, DLRS 2018, pages 24–31,
New York, NY, USA. ACM.
BenAbdallah, J., Caicedo, J. C., Gonzalez, F. A., and Nas-
raoui, O. (2010). Multimodal image annotation us-
ing non-negative matrix factorization. In Proceedings
of the 2010 IEEE/WIC/ACM International Conference
on Web Intelligence and Intelligent Agent Technology
- Volume 01, WI-IAT ’10, pages 128–135, Washing-
ton, DC, USA. IEEE Computer Society.
Bizer, C., Heath, T., and Berners-Lee, T. (2009). Linked
data - the story so far. International Journal on Se-
mantic Web and Information Systems, 5(3):1–22.
Bollacker, K., Evans, C., Paritosh, P., Sturge, T., and Tay-
lor, J. (2008). Freebase: a collaboratively created
graph database for structuring human knowledge. In
Proceedings of the 2008 ACM SIGMOD international
conference on Management of data, pages 1247–
1250, Vancouver, Canada. ACM.
Carlson, A., Betteridge, J., Kisiel, B., Settles, B., Hruschka,
Jr., E. R., and Mitchell, T. M. (2010). Toward an ar-
chitecture for never-ending language learning. In Pro-
ceedings of the Twenty-Fourth AAAI Conference on
Artificial Intelligence, AAAI’10, pages 1306–1313.
AAAI Press.
Funk, S. (2006). Netflix update: Try this at home. Technical
report.
Koren, Y., Bell, R., and Volinsky, C. (2009). Matrix factor-
ization techniques for recommender systems. Com-
puter, 42(8):30–37.
Nickel, M., Murphy, K., Tresp, V., and Gabrilovich, E.
(2016). A review of relational machine learning
for knowledge graphs. Proceedings of the IEEE,
104(1):11–33.
Passant, A. (2010). Measuring semantic distance on linking
data and using it for resources recommendations. In
AAAI spring symposium: linked data meets artificial
intelligence, volume 77, page 123.
Salakhutdinov, R. and Mnih, A. (2007). Probabilistic ma-
trix factorization. In Proceedings of the 20th Inter-
national Conference on Neural Information Process-
ing Systems, NIPS’07, pages 1257–1264, USA. Cur-
ran Associates Inc.
Shi, Y., Larson, M., and Hanjalic, A. (2013). Mining con-
textual movie similarity with matrix factorization for
context-aware recommendation. ACM Trans. Intell.
Syst. Technol., 4(1):16:1–16:19.
Singhal, A. (2012). Introducing the knowledge graph:
things, not strings. Technical report, Google.
Suchanek, F. M., Kasneci, G., and Weikum, G. (2007).
Yago: Core of semantic knowledge. In Proceedings
of the 16th international conference on World Wide
Web - WWW '07. ACM Press.
Vrande
ˇ
ci
´
c, D. (2012). Wikidata: a new platform for collab-
orative data collection. In Proceedings of the 21st in-
ternational conference companion on World Wide Web
- WWW '12 Companion. ACM Press.
Wang, H., Zhang, F., Wang, J., Zhao, M., Li, W., Xie,
X., and Guo, M. (2018). Ripplenet: Propagating
user preferences on the knowledge graph for recom-
mender systems. In Proceedings of the 27th ACM
International Conference on Information and Knowl-
edge Management, CIKM ’18, pages 417–426, New
York, NY, USA. ACM.
KDIR 2019 - 11th International Conference on Knowledge Discovery and Information Retrieval
88
