
A Probabilistic Approach based on a Finite Mixture Model of
Multivariate Beta Distributions
Narges Manouchehri and Nizar Bouguila
Concordia Institute for Information System Engineering (CIISE), Concordia University, Montréal, Canada
Keywords:
Mixture Models, Multivariate Beta Distribution, Maximum Likelihood, Clustering.
Abstract:
Model-based approaches specifically finite mixture models are widely applied as an inference engine in ma-
chine learning, data mining and related disciplines. They proved to be an effective and advanced tool in
discovery, extraction and analysis of critical knowledge from data by providing better insight into the nature
of data and uncovering hidden patterns that we are looking for. In recent researches, some distributions such
as Beta distribution have demonstrated more flexibility in modeling asymmetric and non-Gaussian data. In
this paper, we introduce an unsupervised learning algorithm for a finite mixture model based on multivariate
Beta distribution which could be applied in various real-world challenging problems such as texture analysis,
spam detection and software modules defect prediction. Parameter estimation is one of the crucial and critical
challenges when deploying mixture models. To tackle this issue, deterministic and efficient techniques such as
Maximum likelihood (ML), Expectation maximization (EM) and Newton Raphson methods are applied. The
feasibility and effectiveness of the proposed model are assessed by experimental results involving real datasets.
The performance of our framework is compared with the widely used Gaussian Mixture Model (GMM).
1 INTRODUCTION
Over the past couple of decades, machine learning ex-
perienced tremendous growth and advancement. Ac-
curate data analysis, extraction and retrieval of infor-
mation have been largely studied in the various fields
of technology (Han and Pei, 2012). Technological im-
provement led to the generation of huge amount of
complex data of different types (Diaz-Rozo and Lar-
ranaga, 2018). Various statistical approaches have
been suggested in data mining, however data clus-
tering received considerable attention and still is a
challenging and open problem (Giordan, 2015). Fi-
nite mixture models have been proven to be one of
the most strong and flexible tools in data clustering
and have seen a real boost in popularity. Multimodal
and mixed generated data consists of different compo-
nents and categories and mixture models proved to be
an enhanced statistical approach to discover the latent
pattern of data (McCabe, 2015). One of the crucial
challenges of modeling and clustering is applying the
most appropriate distribution. Most of the literatures
on finite mixtures concern Gaussian mixture model
(GMM) (Zhou, 2017), (Guha and Shim, 2001), (Gev-
ers, 1999), (Hastie and Tibshirani, 1996), (Luo et al.,
2017). However, GMM is not a proper tool to express
the latent structure of non-Gaussian data. Recently,
other distributions such as Dirichlet and Beta distri-
butions which are more flexible have been considered
as a powerful alternative (Giordan, 2015), (Olkin and
Trikalinos, 2015), (Fan and Bouguila, 2013), (Cock-
riel and McDonald, 2018), (Elguebaly and Bouguila,
2013), (Fan et al., 2014), (Klauschies et al., 2018),
(Wentao et al., 2013).
In this work, we introduce multivariate Beta mix-
ture model to cluster k dimensional vectors with
features defined between zero and one. For learn-
ing the parameters, we applied the Expectation-
Maximization (EM) algorithm. Our model will be
evaluated on two real world applications. The first
one is software defect detection. Nowadays, complex
software systems are increasingly applied and the rate
of software defects is growing correspondingly. Er-
rors, failures and defects may cause serious and costly
complications in systems and projects by providing
unexpected or unintended results. Hence, prediction
of defective modules by statistical methods has be-
come one of the attention-grabbing subjects of many
studies using machine learning methods to differenti-
ate fault prone or non-fault prone softwares (Malhotra
and Jain, 2012). Spam filtering is our second topic of
interest. Evolutionary automated communication by
Manouchehri, N. and Bouguila, N.
A Probabilistic Approach based on a Finite Mixture Model of Multivariate Beta Distributions.
DOI: 10.5220/0007707003730380
In Proceedings of the 21st International Conference on Enterprise Information Systems (ICEIS 2019), pages 373-380
ISBN: 978-989-758-372-8
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
373

Internet improved the style of everyday communica-
tion. Electronic mail is a dominant medium for dig-
ital communications as it is convenient, economical
and fast. However, unwanted emails take advantage
of the Internet. Spam emails are sent to widely and
economically advertise a specific product or service,
serve online frauds (Malhotra and Jain, 2012) or are
carrying a piece of malicious code that might damage
the end user machines.
The rest of this paper is organized as follows; In
sections 2 and 3, we present our proposed mixture
model and model learning, respectively. Model as-
sessment is performed by devoting section 4 to exper-
imental results and the accuracy of our model is esti-
mated by comparing it with Gaussian mixture models.
Finally, we conclude this paper in section 5.
2 THE MIXTURE MODEL
In this section, we propose a new mixture model
based on a multivariate Beta distribution.
2.1 The Finite Multivariate Beta
Distribution
Bivariate and multivariate Beta distributions have
been introduced by Olkin and Liu (Olkin and Liu,
2003), (Olkin and Trikalinos, 2015). This article is
devoted to our proposed mixture model based on mul-
tivariate Beta distribution. In this section, we will
briefly introduce the bivariate distribution with three
shape parameters and then describe the multivariate
case in detail.
Let us consider two correlated random variables X
and Y defined by Beta distribution and described as
follows:
X =
U
(U +W )
(1)
Y =
V
(V +W )
(2)
U, V and W are three independent random vari-
ables arisen from standard Gamma distribution and
parametrized by their shape parameters a, b and c,
respectively. Both variables X and Y have positive
real values and are less than one. The joint density
function of this bivariate distribution is expressed by
Equation 3.
f (X,Y ) =
X
a−1
Y
b−1
(1 − X)
b+c−1
(1 −Y )
a+c−1
B(a,b, c)(1 −XY )
(a+b+c)
(3)
where
B(a,b, c) =
Γ(a)Γ(b)Γ(c)
Γ(a + b + c)
(4)
The multivariate Beta distribution is constructed
by generalization of above bivariate distributions to k
variate distribution. Let U
1
,....,U
k
and W be indepen-
dent random variables each having a Gamma distri-
bution and variable X is defined by Equation 5 where
i = 1,...k.
X
i
=
U
i
(U
i
+W )
(5)
The joint density function of X
1
,...., X
k
after integra-
tion over W is expressed by:
f (x
1
,..., x
k
) = c
∏
k
i=1
x
a
i
−1
i
∏
k
i=1
(1 −x
i
)
(a
i
+1)
h
1 +
k
∑
i=1
x
i
(1 −x
i
)
i
−a
(6)
where x
i
is between zero and one and:
c = B
−1
(a
1
,..., a
k
) =
Γ(a
1
+ ... + a
k
)
Γ(a
1
)......Γ(a
k
)
=
Γ(a)
∏
k
i=1
Γ(a
i
)
(7)
a
i
is the shape parameter of each variable X
i
and:
a =
k
∑
i=1
a
i
(8)
2.2 Mixture model
Let us consider X = {
~
X
1
,
~
X
2
,...,
~
X
N
} be a set of N
k-dimensional vectors such that each vector
~
X
n
=
(X
n1
,..., X
nk
) is generated from a finite but unknown
multivariate Beta mixture model p
~
X|Θ
. We as-
sume that X is composed of M different finite clusters
and can be approximated by a finite mixture model as
below (Bishop, 2006), (Figueiredo and Jain, 2002),
(McLachlan and Peel, 2000):
p
~
X|Θ
=
M
∑
j=1
p
j
p(
~
X|
~
α
j
) (9)
where
~
α
j
= (a
1
,...., a
k
). The weight of component j
is denoted by p
j
. All of mixing proportions are posi-
tive and sum to one.
M
∑
j=1
p
j
= 1 (10)
The complete model parameters are denoted by
{p
1
,..., p
M
,
~
α
1
,...,
~
α
M
} and Θ = (p
j
,
~
α
j
) represents
the set of weights and shape parameters of component
j.
ICEIS 2019 - 21st International Conference on Enterprise Information Systems
374

3 MODEL LEARNING
In this section, we first estimate the initial values of
the parameters. Then, the optimal parameters are es-
timated by developing maximum likelihood estima-
tion within EM algorithm. The initialization phase
is based on k-means framework and method of mo-
ments.
3.1 Method of Moments for the Finite
Multivariate Beta Distribution
Method of moments (MM) is a statistical technique
to estimate model’s parameter. Considering Equation
11 and Equation 12 as the first two moments, sample
mean and variance, the shape and scale parameters of
Beta distribution can be estimated using the method of
moments by Equation 13 and Equation 14 as follow:
E(X) = ¯x =
1
N
N
∑
i=1
X
i
(11)
Var(X) = ¯v =
1
N − 1
N
∑
i=1
(X
i
− ¯x)
2
(12)
ˆ
α = E(X)
E(X)
Var(X)
1 − E(X)
− 1
(13)
ˆ
β =
1 − E(X)
E(X)
Var(X)
1 − E(X)
− 1
(14)
By the help of the mean and variance of compo-
nents obtained from k-means phase, the initial param-
eters are approximated.
3.2 Maximum Likelihood and EM
Algorithm
As one of the suggested methods to tackle the prob-
lem of finding the parameters of our model, we apply
maximum likelihood estimate (ML) approach (Gane-
salingam, 1989) and expectation maximization (EM)
framework (McCabe, 2015), (McLachlan and Krish-
nan, 2008) on the complete likelihood. In this tech-
nique, the parameters which maximize the probability
density function of data are estimated as follow:
Θ
∗
= argmax
Θ
L (X , Θ) (15)
L (Θ, X ) = log
p(X |Θ)
=
N
∑
n=1
log
M
∑
j=1
p
j
p(
~
X
n
|
~
α
j
)
(16)
Each
~
X
n
is supposed to be arisen from one of the
components. Hence, a set of membership vectors is
introduced as
~
Z
n
= (
~
Z
n1
,. .. ,
~
Z
nM
) where:
z
n j
=
1 if X belongs to a component j
0 otherwise,
(17)
M
∑
j=1
z
n j
= 1 (18)
This gives the following complete log-likelihood:
L (Θ, Z, X ) =
M
∑
j=1
N
∑
n=1
z
n j
log p
j
+ log p(
~
X
n
|
~
α
j
)
(19)
In the EM algorithm, as the first step in Expectation
phase, we assign each vector
~
X
n
to one of the clusters
by its posterior probability given by:
ˆ
Z
n j
= p( j|
~
X
n
,
~
α
j
) =
p
j
p(
~
X
n
|
~
α
j
)
∑
M
j=1
p
j
p(
~
X
n
|
~
α
j
)
(20)
The complete log-likelihood is computed as:
L (Θ, Z, X ) =
M
∑
j=1
N
∑
n=1
ˆ
Z
n j
log p
j
+ log p(
~
X
n
|
~
α
j
)
=
M
∑
j=1
N
∑
n=1
ˆ
Z
n j
log p
j
+ log
∏
k
i=1
X
(a
ji
−1)
ni
∏
k
i=1
(1 − X
ni
)
(a
ji
+1)
×
h
1 +
k
∑
i=1
X
ni
(1 − X
ni
)
i
−a
j
×
Γ(
∑
k
i=1
a
ji
)
∏
k
i=1
Γ(a
ji
)
!
=
M
∑
j=1
N
∑
n=1
ˆ
Z
n j
log p
j
+ log
k
∏
i=1
X
(a
ji
−1)
ni
−log
k
∏
i=1
(1 − X
ni
)
(a
ji
+1)
+ log
Γ(a
j
)
−log
k
∏
i=1
Γ(a
ji
) + log
h
1 +
k
∑
i=1
X
ni
(1 − X
ni
)
i
−a
j
!
=
M
∑
j=1
N
∑
n=1
ˆ
Z
n j
log p
j
+
k
∑
i=1
(a
ji
− 1)
log(X
ni
)
−
k
∑
i=1
(a
ji
+ 1)
log(1 − X
ni
)
+ log
Γ(a
j
)
−
k
∑
i=1
log
Γ(a
ji
)
− a
j
log
h
1 +
k
∑
i=1
X
ni
(1 − X
ni
)
i
!!
(21)
The value of a
j
is computed by Equation 13 for
each component of mixture model.
A Probabilistic Approach based on a Finite Mixture Model of Multivariate Beta Distributions
375

To reach our ultimate goal and in maximization
step, the gradient of the log-likelihood is calculated
with respect to parameters. To solve optimization
problem, we need to find a solution for the following
equation:
∂L(Θ,Z, X )
∂Θ
= 0 (22)
The first derivatives of Equation 21 with respect to
a
ji
where i = 1,..., k are given by:
∂L(Θ,Z, X )
∂a
ji
=
M
∑
j=1
N
∑
n=1
ˆ
Z
n j
log(X
ni
) − log(1 − X
ni
)
+Ψ(a
j
) − Ψ(a
ji
) − log
h
1 +
k
∑
i=1
X
ni
(1 − X
ni
)
i
!
(23)
where Ψ(.) and Ψ
0
(.) are digamma and trigamma
functions respectively defined as follow:
Ψ(X) =
Γ
0
(X)
Γ(X)
(24)
Ψ
0
(X) =
Γ
00
(X)
Γ(X)
−
Γ
0
(X)
2
Γ(X)
2
(25)
As this equation doesn’t have a closed form so-
lution, we use an iterative approach named Newton-
Raphson method expressed as follow:
ˆ
α
j
new
=
ˆ
α
j
old
− H
j
−1
G
j
(26)
where G
j
is the first derivatives vector described in
Equation 23 and H
j
is Hessian matrix.
G
j
=
G
1 j
,..., G
k j
T
(27)
The Hessian matrix is calculated by computing the
second and mixed derivatives of L(Θ,Z,X ).
H
j
=
∂G
j1
∂a
j1
·· ·
∂G
j1
∂a
jk
.
.
.
.
.
.
.
.
.
∂G
jk
∂a
j1
·· ·
∂G
jk
∂a
jk
=
N
∑
i=1
ˆ
Z
n j
× (28)
Ψ
0
(|~a
j
|) − Ψ
0
(a
j1
) ·· · Ψ
0
(|~a
j
|)
.
.
.
.
.
.
.
.
.
Ψ
0
(|~a
j
|) ·· · Ψ
0
(|~a
j
|) − Ψ
0
(a
jk
)
where
|~a
j
| = a
1
+ ... + a
k
(29)
The estimated values of mixing proportions are
expressed by Equation 30 as it has a closed-form so-
lution:
p
j
=
∑
N
n=1
p( j|
~
X
n
,
~
α
j
)
N
(30)
3.3 Estimation Algorithm
The initialization and estimation framework is de-
scribed as follows:
1. INPUT: k-dimensional data
~
X
n
and M.
2. Apply the k-means to obtain initial M clusters.
3. Apply the MOM to obtain
~
α
j
.
4. E- step: Compute
ˆ
Z
n j
using Equation 20.
5. M-step: Update the
~
α
j
using Equation 26 and
p
j
using Equation 30.
6. If p
j
< ε, discard component j and go to 4.
7. If the convergence criterion passes terminate,
else go to 4.
4 EXPERIMENTAL RESULTS
In this section, we estimate the accuracy of our algo-
rithm by testing on two real world applications. As
the first step, we normalize our datasets by Equation
31 as one of the assumptions of our distribution is that
the values of all observations are positive and less than
one.
X
0
=
X −X
min
X
max
− X
min
(31)
To assess the accuracy of the algorithm, the ob-
servations are assigned to different clusters based on
Bayesian decision rule. Afterward, the accuracy is
inferred by confusion matrix. At the next step, multi-
variate Beta mixture and Gaussian mixture model will
be compared.
4.1 Software Defect Prediction
Software quality assurance and detection of a fault or
a defect in a software program have become one of the
topics that have received lots of attention in research
and technology. Any failure in software may result in
high costs for the system (Bertolino, 2007), (Briand
and Hetmanski, 1993), (El Emam and Rai, 2001). The
evaluation of the quality of complex software systems
is costly and complicated. Consequently, prediction
ICEIS 2019 - 21st International Conference on Enterprise Information Systems
376
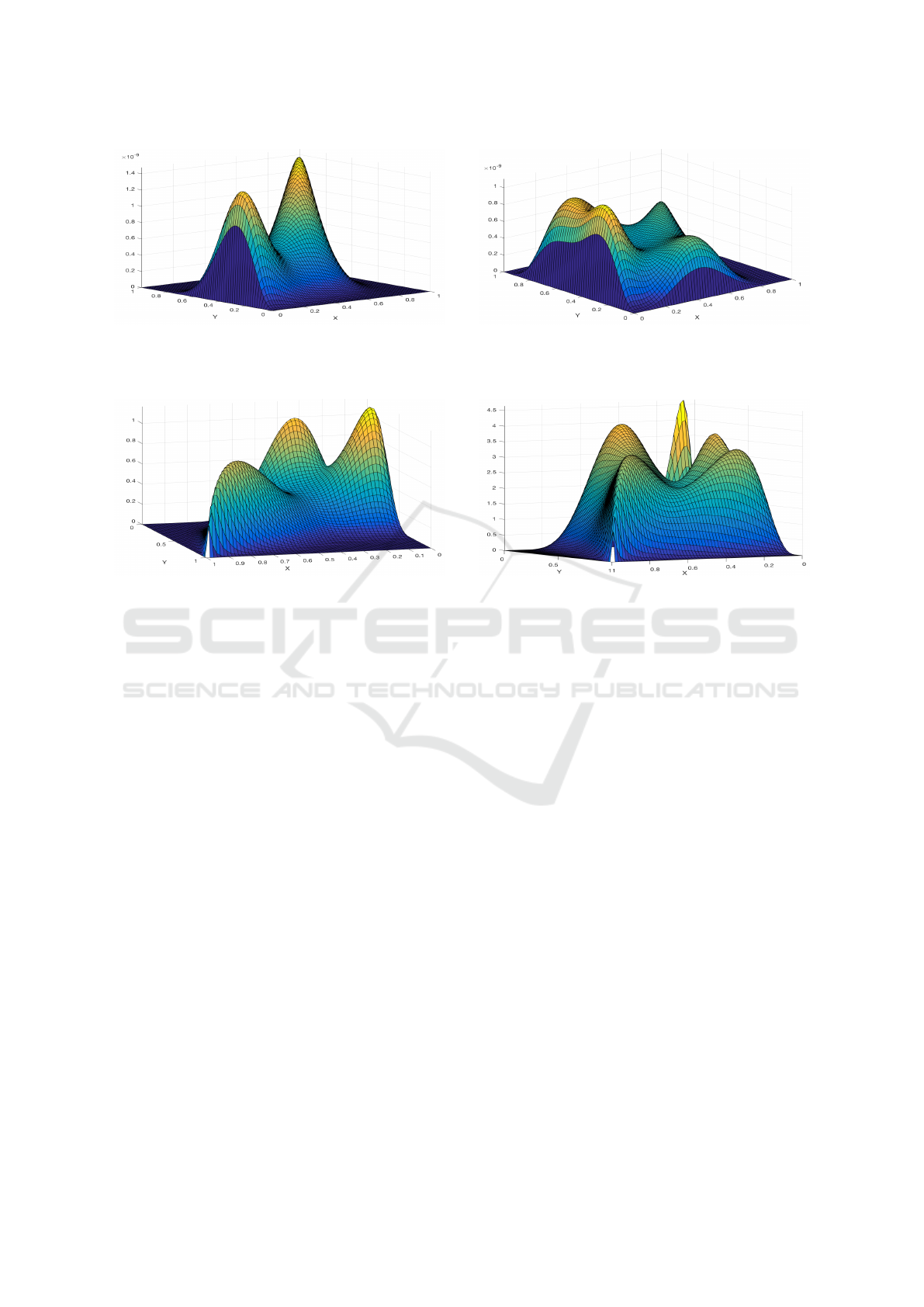
Figure 1: Two-component mixture of bivariate Beta distri-
bution.
Figure 2: Three-component mixture of bivariate Beta distri-
bution.
of software failures and improving reliability is one
of the attractive applications for scientists (Boucher
and Badri, 2017), (Kawashima and Mizuno, 2015),
(Lyu, 1996), (Koru and Liu, 2005). To tackle this
problem, it is critical to define the appropriate met-
rics to express the attributes of the software modules.
There are some metrics (Aleem et al., 2015) for as-
sessing software complexity such as the code size,
McCabes cyclomatic and Halsteads complexity (Mc-
Cabe, 1976). The McCabes metric includes essential,
cyclomatic and design complexity and the number of
lines of code. While the Halsteads metric consists of
base and derived measures and line of code (LOC)
(McCabe, 1976), (Shihab, 2014). Prediction mod-
els are applied to improve and optimize the quality
which is translated to customer satisfaction as a sig-
nificant achievement for the companies. Finite mix-
ture models as flexible statistical solutions and clus-
tering techniques are considered as powerful tools in
this area (Oboh and Bouguila, 2017), (Bouguila and
Hamza, 2010), (Kawashima and Mizuno, 2015). Our
experiment is performed on three datasets from the
PROMISE data repository obtained from NASA soft-
ware projects and its public MDP (Modular toolkit for
Data Processing) which are currently used as bench-
mark datasets in this area of research (NASA, 2004).
Figure 3: Four-component mixture of bivariate Beta distri-
bution.
Figure 4: Five-component mixture of bivariate Beta distri-
bution.
The metrics or features of each dataset are five dif-
ferent lines of code measure, three McCabe metrics,
four base Halstead measures, eight derived Halstead
measures and a branch-count. The datasets are clas-
sified by a binary variable to indicate if the module is
defective or not. CM1 as the first dataset is a NASA
spacecraft instrument software written in "C". KC1
as the second one, is a "C++" dataset raised from sys-
tem implementing storage management for receiving
and processing ground data. The last case, PC1 is
developed using "C" considering functions flight soft-
ware for earth orbiting satellite. To highlight the basic
properties of the datasets, Table 1 is created. As it is
shown in Table 2 and Table 3, multivariate Beta mix-
ture model (MBMM) has better performance in all
three datasets in comparison with Gaussian mixture
model (GMM). For CM1, the accuracy of our model
is 98.79% while this value for GMM is 85.94% . KC1
has a more accurate result (94.12%) with MBMM
than GMM (88.66%). The performance of models for
PC1 is similar by 94.13% and 91.79% of accuracy
for MBMM and GMM, respectively. The precision
and recall follow the same behavior as accuracy. The
multivariate Beta mixture model is capable to reach
97.44% precision and 99.55% of recall for PC1 and
KC1, respectively. While GMM has the best preci-
A Probabilistic Approach based on a Finite Mixture Model of Multivariate Beta Distributions
377

Table 1: Software modules defect properties.
Dataset Language Instances Defects
CM1 C 498 49
KC1 C++ 2109 326
PC1 C 1109 77
Table 2: Software modules defect results inferred from the
confusion matrix of multivariate Beta mixture model.
Dataset Accuracy Precision Recall
CM1 98.79 99.15 99.55
KC1 94.12 94.69 98.31
PC1 94.13 97.44 95.97
sion and recall in PC1 with 96.06% and 95.23%.
4.2 Spam Detection
Spam filtering as our second real application is one
of the major research fields in information systems
security. Spams or unsolicited bulk emails pose se-
rious threats. As it was mentioned is some literature
up to 75–80% of email messages are spam (Blanzieri
and Bryl, 2008) which resulted in heavy financial
losses of 50 and 130 billion dollars in 2005, respec-
tively (Galati, 2018), (Lugaresi, 2004), (Wang et al.,
2018). Considering serious risks and costly conse-
quences, classification and categorization of email
(Ozgur and Gungor, 2012), (Amayri and Bouguila,
2009a), (Amayri and Bouguila, 2009b), (Amayri and
Bouguila, 2012) have received a lot of attention. Ap-
plying machine learning and pattern recognition tech-
niques capability was enhanced compared to hand-
made rules (Amayri and Bouguila, 2010), (Bouguila
and Amayri, 2009), (Fan and Bouguila, 2013), (Cor-
mack and Lynam, 2007), (Chang and Meek, 2008),
(Hershkop and Stolfo, 2005), (Drake, 2004) .
Our experiment was carried out on a challenging
spam data set obtained from UCI machine learning
repository, created by Hewlett-Packard Labs (UCI,
1999). This dataset contains 4601 instances and 58
attributes (57 continuous input attributes and 1 nomi-
nal class label target attribute). 39.4% of email (1813
instances) are spam and 60.6% (2788) are legitimate.
The attributes are extracted from a commonly used
technique called Bag of Words (BoW) as one of the
main information retrieval methods in natural lan-
guage processing. In this method, each email is pre-
sented by its words disregarding grammar. Most of
the attributes in spam base dataset indicate whether a
particular word or character was frequently occurring
in the e-mail. 48 features include the percentage of
words in the e-mail that match the word. 6 attributes
Table 3: Software modules defect results according to the
confusion matrix of Gaussian mixture model.
Dataset Accuracy Precision Recall
CM1 85.94 92.21 90.88
KC1 88.66 93.99 92.69
PC1 91.79 96.06 95.23
Table 4: Spam filtering results to compare the performance
of MBMM and GMM.
Mixture model Accuracy Precision Recall
MBMM 79.92 80.6 82.74
GMM 67.81 78.99 68.29
are extracted from the percentage of characters in the
e-mail that match characters. The rest of the features
are the average length of uninterrupted sequences of
capital letters, the length of the longest uninterrupted
sequence of capital letters and the total number of
capital letters in the e-mail. The dataset class denotes
whether the e-mail was considered spam or not. To
evaluate our framework, first the dataset has been re-
duced to 3626 instances to have a balanced case. Then
it was normalized by Equation 31 as our assumption is
that all observation values are between zero and one.
Table 4 shows the results of our model performance in
comparison with Gaussian mixture model considering
their confusion matrix. As we can realize from table
4, multivariate Beta mixture model is more accurate
(79.92%) and has higher value in terms of precision
and recall, 80.6% and 82.74%, respectively.
5 CONCLUSION
In this paper, we have developed a clustering tech-
nique and a mixture model in order to propose a new
approach to model data and improve clustering accu-
racy. We have mainly proposed our model using a
multivariate Beta distribution which has more flex-
ibility. The work addresses the parameters estima-
tion within a deterministic and efficient method us-
ing maximum likelihood estimation. After the pre-
sentation of our algorithm for parameters estimation,
we evaluated the capability of the proposed statisti-
cal mixture model in two real attractive domains and
applied confusion matrix as a typical evaluation ap-
proach to estimate the accuracy, precision and recall
and effectiveness of our solution. As the first real
world experiment, we considered a popular and crit-
ical application in information security engineering
about predicting defects in software modules in the
ICEIS 2019 - 21st International Conference on Enterprise Information Systems
378

context of three NASA datasets. Our clustering algo-
rithm was developed to discover two groupings based
on some software complexity metrics. The proposed
methodology has been shown to outperform Gaussian
mixture model as a classical approach and our offered
solution achieved better results in terms of data mod-
eling capabilities and clustering accuracy. The second
application was spam detection using the spam base
dataset from the UCI repository. The ultimate goal of
our extensive study is developing a powerful classi-
fier as a devoted filter to accurately distinguish spam
emails from legitimate emails in order to improve the
blocking rate of spam emails and decrease the mis-
classification rate of legitimate emails. Spam filtering
solutions presented in this paper generates acceptable,
accurate results in comparison with Gaussian mixture
model as the results of our algorithm has higher pre-
cision and recall. From the outcomes, we can infer
that the multivariate Beta mixture model could be a
competitive modeling approach for the software de-
fect and spam prediction problems. In other words,
we can say that our model produces enhanced clus-
tering results largely due to its model flexibility.
REFERENCES
Aleem, S., Capretz, L. F., and Ahmed, F. (2015). Bench-
marking machine learning technologies for software
defect detection. 6(3):11–23.
Amayri, O. and Bouguila, N. (2009a). A discrete mixture-
based kernel for svms: Application to spam and im-
age categorization. Artificial Intelligence Review,
34(1):73–108.
Amayri, O. and Bouguila, N. (2009b). Online spam filtering
using support vector machines. IEEE Symposium on
Computers and Communications, pages 337–340.
Amayri, O. and Bouguila, N. (2010). A study of spam fil-
tering using support vector machines. Artificial Intel-
ligence Review, 34(1):173–108.
Amayri, O. and Bouguila, N. (2012). Unsupervised feature
selection for spherical data modeling: Application to
image-based spam filtering. International Conference
on Multimedia Communications, Services and Secu-
rity, pages 13–23.
Bertolino, A. (2007). Software testing research: Achieve-
ments, challenges, dream. Future of Software Engi-
neering, page 85–103.
Bishop, C. (2006). Pattern recognition and machine learn-
ing. Springer, New York.
Blanzieri, E. and Bryl, A. (2008). A survey of learning-
based techniques of email spam filtering. Artificial
Intelligence Review, 29:63–92.
Boucher, A. and Badri, M. (2017). Predicting fault-prone
classes in objectoriented software. page 306–317.
Bouguila, N. and Amayri (2009). A discrete mixturebased
kernel for svms: Application to spam and image cate-
gorization. Information Processing and Management,
45:631–642.
Bouguila, N., W. J. and Hamza, A. (2010). Software mod-
ules categorization through likelihood and bayesian
analysis of finite dirichlet mixtures. Applied Statistics,
37(2):235–252.
Briand, L. C., B. V. and Hetmanski, C. J. (1993). Develop-
ing interpretable models with optimized set reduction
for identifying high-risk software components. vol-
ume 19, page 1028–1044. IEEE Transactions on Soft-
ware Engineering.
Chang, M., Y. W. and Meek, C. (2008). Partitioned logistic
regression for spam filtering. page 97–105. 14th ACM
SIGKDD international conference on knowledge dis-
covery and data mining.
Cockriel, W. M. and McDonald, J. B. (2018). Two multi-
variate generalized beta families, communications in
statistics. Theory and Methods, 47(23):5688–5701.
Cormack, G. and Lynam, T. (2007). Online supervised
spam filter evaluation. ACMTransactions on Informa-
tion Systems, 25(3):1–31.
Diaz-Rozo, J., B. C. and Larranaga, P. (2018). Clustering
of data streams with dynamic gaussian mixture mod-
els: An iot application in industrial processes. IEEE
Internet of Things Journal, 5:3533.
Drake, C., O. J. K. E. (2004). Anatomy of a phishing email.
First conference on email and anti- Spam (CEAS),
25(3):1–31.
El Emam, K. Benlarbi, S. G. N. and Rai, S. N. (2001). Com-
paring casebased reasoning classifiers for predicting
high risk software components. Journal of Systems
and Software, 55(3):301–320.
Elguebaly, T. and Bouguila, N. (2013). Finite asymmetric
generalized gaussian mixture models learning for in-
frared object detection. Computer Vision and Image
Understanding, 117:1659–1671.
Fan, W. and Bouguila, N. (2013). Variational learning of a
dirichlet process of generalized dirichlet distributions
for simultaneous clustering and feature selection. Pat-
tern Recognition, 46:2754–2769.
Fan, W., Bouguila, N., and Ziou, D. (2014). Variational
learning of finite dirichlet mixture models using com-
ponent splitting. Neurocomputing, 129:3–16.
Figueiredo, M. and Jain, A. K. (2002). Unsupervised
learning of finite mixture models. IEEE Transac-
tions on Pattern Analysis and Machine Intelligence,
24(3):381–396.
Galati, L. (2018). The anatomy of a phishing attack. Fair-
field County Business Journal, 54:5.
Ganesalingam, S. (1989). Classification and mixture ap-
proaches to clustering via maximum likelihood. Jour-
nal of the Royal Statistical Society: Series C (Applied
Statistics, 38(3):455–466.
Gevers, T., S. A. (1999). Color-based object recognition.
Journal of the Royal Statistical Society: Series C (Ap-
plied Statistics, 32(3):453–464.
Giordan, M., W. R. (2015). A comparison of compu-
tational approaches for maximum likelihood estima-
tion of the dirichlet parameters on high-dimensional
data. SORT-Statistics and Operations Research Trans-
actions, 39(1):109–126.
A Probabilistic Approach based on a Finite Mixture Model of Multivariate Beta Distributions
379

Guha, S., R. R. and Shim, K. (2001). Cure: an efficient
clustering algorithm for large databases. Information
Systems, 26:35–58.
Han, J., K. M. and Pei, J. (2012). Data mining: concepts
and techniques. Elsevier, Morgan Kaufmann, Amster-
dam; Boston.
Hastie, T. and Tibshirani, R. (1996). Discriminant analysis
by gaussian mixtures. Journal of the Royal Statistical
Society Series B (Methodological), 58(1):155–176.
Hershkop, S. and Stolfo, S. (2005). Combining email mod-
els for false positive reduction. The eleventh ACM
SIGKDD international conference on Knowledge dis-
covery in data mining, pages 98–107.
Kawashima, N. and Mizuno, O. (2015). Predicting fault-
prone modules by word occurrence in identifiers. Soft-
ware Engineering Research, Management and Appli-
cations, page 87–98.
Klauschies, T., Coutinho, R. M., and Gaedke, U. (2018). A
beta distribution-based moment closure enhances the
reliability of trait-based aggregate models for natural
populations and communities. Ecological Modelling,
381:46–77.
Koru, A. G. and Liu, H. (2005). Building effective de-
fect prediction models in practice. IEEE software,
22(6):23–29.
Lugaresi, N. (2004). European union vs. spam: a legal
response. First conference on email and anti-Spam
(CEAS).
Luo, Z., He, W., Liwang, M., Huang, L., Zhao, Y., and
Geng, J. (2017). Real-time detection algorithm of ab-
normal behavior in crowds based on gaussian mixture
model. 12th International Conference on Computer
Science and Education (ICCSE), 20:183.
Lyu, M. R. e. a. (1996). Handbook of software reliabil-
ity engineering. IEEE computer society press CA,
222:183.
Malhotra, R. and Jain, A. (2012). Fault prediction using sta-
tistical and machine learning methods for improving
software quality. Journal of Information Processing
Systems, 8(2):1241–262.
McCabe, T. J. (1976). A complexity measure. IEEE Trans-
actions on software Engineering, 8(4):308–320.
McCabe, T. J. (2015). Mixture Models in Statistics. Elsevier
Ltd.
McLachlan, G. and Krishnan, T. (2008). The EM algorithm
and extensions. Wiley-Interscience.
McLachlan, G. and Peel, D. (2000). Finite Mixture Models.
New York: Wiley.
NASA (2004). PROMISE Software Engineering Repos-
itory data set. http://promise.site.uottawa.ca/
SERepository/datasetspage.html.
Oboh, S. and Bouguila, N. (2017). Unsupervised learning
of finite mixtures using scaled dirichlet distribution
and its application to software modules categorization.
volume 8, page 1085–1090.
Olkin, I. and Liu, R. (2003). A bivariate beta distribution,
statistics and probability letters. volume 62, pages
407–412.
Olkin, I. and Trikalinos, T. A. (2015). Constructions for a
bivariate beta distribution. volume 96, pages 54–60.
Ozgur, L. and Gungor, T. (2012). Optimization of depen-
dency and pruning usage in text classification. vol-
ume 15, pages 45–58.
Shihab, E. (2014). Practical software quality prediction,
in software maintenance and evolution (icsme). page
639–644.
UCI, R. (1999 (accessed 2 August 1999)).
Spambase UCI Repository data set.
https://archive.ics.uci.edu/ml/machine-
learningdatabases/spambase/spambase.data.
Wang, S., Zhang, X., Cheng, Y., Jiang, F., Yu, W., and Peng,
J. (2018). A fast content-based spam filtering algo-
rithm with fuzzy-svm and k-means. pages 301–307.
Wentao, F., Bouguila, N., and Ziou, D. (2013). Unsu-
pervised hybrid feature extraction selection for high-
dimensional non-gaussian data clustering with varia-
tional inference. IEEE Transactions on Knowledge
and Data Engineering, 25(7):1670–1685.
Zhou, J. H., P. C. K. Y. W. (2017). Gaussian mixture model
for new fault categories diagnosis. pages 1–6.
ICEIS 2019 - 21st International Conference on Enterprise Information Systems
380
