
On Mining Conditions using Encoder-decoder Networks
Fernando O. Gallego and Rafael Corchuelo
ETSI Informática, Avda. Reina Mercedes s/n., Sevilla E-41012, Spain
Keywords:
Condition Mining, Natural Language Pr ocessing, Deep Learning, Sequence Labelling.
Abstract:
A condition is a constraint that determines w hen something holds. Mining them is paramount to understanding
many sentences properly. There are a few pattern-based approaches that fall short because the patterns must be
handcrafted and it is not easy to characterise unusual ways to express conditions; there is one machine-learning
approach that requires specific-purpose dictionaries, taxonomies, and heuristics, works on opinion sentences
only, and was evaluated on a small dataset with Japanese sentences on hotels. In this paper, we present an
encoder-decoder model to mine conditions that does not have any of the previous drawbacks and outperforms
the state of the art in terms of effectiveness.
1 INTRODUCTION
A condition describes the circumstances or factors
that must be met for something else to hold. Unfortu-
nately, current state-of-the-art text miner s do not take
them into accoun t, which may easily result in misin-
terpretations.
For instance, entity-relatio n extrac tors (Etzion i
et al., 2011; Mitchell et al., 2015) mine entities and
relations amongst them and return overviews th a t are
useful to make decisions. For instance, they return
("Acme Bank ", "won’t merge", "Trust Bank") from
a sentence like "May the new law be approved
and Acme Bank won’t merge Trust Bank"; neg-
lecting the condition might lead a broker not to
recommend investing on Acme Bank regardless of
the status of the new law. Similarly, opinion m i-
ners (Ravi and Ravi, 2015; Schouten and Frasin car,
2016) analyse the opinions that people express in
social media, which is very useful for co mpanies to
improve their products or to devise m arketing ca m-
paigns. For instance, they return {flash = -0.99,
lens = 0.55} from a sentence like "The flash’s hor-
rible indoors, but the lens is not bad for amateurs";
neglecting the conditions might result in a manufac-
turer not testing the flash appropriately or targeting
a campaign to the wrong customers. Analogou sly,
recommenders (Ravi and Ravi, 2015; Schouten and
Frasincar, 201 6) seek to predict the interest of a
user in an item building on his or her previous se-
arches, pu rchase records, e-mail messages, and the
like. Unfortunately, they typically start recommen-
ding rent-a-car agents and flights to Australia when
they see a sentence like "I’ll rent a good car after
I book my flight to Australia", independently from
whether the user has already booked a flight or not.
The previous examples clearly motivate the need
for mining conditions, which has recently attrac-
ted the attention of some researchers. The nai-
vest approaches search for user-defined patterns that
build on con nectives, verb tenses, and other com-
mon grammatical landmarks (Ma usam et al., 2012;
Chikersal et al., 2015). Such a handcrafted appro-
ach may result in high precision, but falls short
regarding recall because condition connectives have
a long-tail distribution, which implies that there are
common conditions that do not fit common pat-
terns (see the pr evious examples). There is only
one machine-learning approach (Nakayama and Fu-
jii, 2015), but it must be customised with several
specific-purpose dictionaries, taxonomies, and heu-
ristics, m ines conditions regarding opinions only,
and it was evaluated on a small dataset with 3 155
Japanese sentences on hotels.
In this paper, we present an encoder-decoder
approa c h to mine con ditions, which has already
proven to be useful in tasks that involve transfor-
ming a sequence into another, e.g., machine transla-
tion (Cho et al., 2014; Sutskever et al., 2014; Chen
et al., 2017), summarisation (Chopra et al., 2016;
Nallapati et al., 2016; Rush et al., 2015), or se-
quence labelling (Ma and Hovy, 2 016; Zhai et al.,
2017; Zhu and Yu, 2017). Our propo sal consists
in using two recurrent neural networks (Han et al.,
624
Gallego, F. and Corchuelo, R.
On Mining Conditions using Encoder-decoder Networks.
DOI: 10.5220/0007379506240630
In Proceedings of the 11th International Conference on Agents and Artificial Intelligence (ICAART 2019), pages 624-630
ISBN: 978-989-758-350-6
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

2017), namely: the encoder, which enco des the in-
put sentence into a context vector, an d th e dec oder,
which deco des the context vector into a sequen ce
of labels that help identify the words that consti-
tute a condition. This approach does not require
to provide any user-defined patterns, it does not re-
quire any specific-purpose dictionaries, taxonomies,
or heuristics, it c an m ine conditions in both fac-
tual and opinion sentences, and it relies on rea dily-
available components (a stemmer and a word em-
bedder ). We have performed an experimental ana-
lysis on a dataset with 3 790 203 sentenc es on 15
common topics in English and Span ish ; our results
prove that our approach beats the others in terms
of F
1
score.
The rest of the paper is organised as fol-
lows: Section 2 reports on the related work;
Section 3 d escribes our propo sal to mine conditi-
ons; Section 4 repo rts on our experimen ta l analysis;
finally, Section 5 presents our conclusion s.
2 RELATED WORK
(Narayan an et al., 2009) range amongst the first
authors who rea lised the problem with conditions
in the field of opinion minin g. They devised a fe-
ature model that allowed them to mac hine-learn a
regressor th a t computes the polarity of a conditio -
nal sentence, but they did not report on a proposal
to mine the conditions. Recently, (Skeppstedt et al.,
2015) presented a proposal that helps ide ntify con -
ditional sentences.
The naivest approaches to mining conditions
build on searching for user-defined patterns. (Mau-
sam et al., 2012) studied the problem in the field of
entity-relatio n extraction and suggested that con diti-
ons might be identified by locating adverbial clau-
ses whose first word is one of the sixteen one-
word condition connectives in English; unfortuna -
tely, they did not repor t on the effectiveness of
their approach to mining cond itions, o nly on the
overall effectiveness of their proposal for entity-
relation extraction. Their sy stem was updated re-
cently (Mausam, 2016), but their proposal to mine
conditions was not. (Chikersal et al., 2015) propo-
sed a similar, but simpler approach: they searched
for sequence s of words in between connectives “if”,
“unless”, “until”, and “in case” and th e first occur-
rence of “then” or a comma. Unfortunately, the
previous proposals are not goo d enough in p ractice
because ha ndcrafting such p atterns is not trivial and
the results fall short regarding recall.
The only existing machine-learning approach
ŵďĞĚĚŝŶŐƐ
ŶĐŽĚĞƌ
ĞĐŽĚĞƌ
ϕ ϕ
ϕ ϕ ϕ
ϕ ϕ
Figure 1: Encoder-decoder model.
was introduce d by (Nakayama and Fujii, 2015 ),
who worked in the field of opin ion mining. They
devised a model that is based on featu res that are
computed by means of a syntactic parser and a
semantic analyser. The former identifies so-c alled
bunsetus, which are Japanese sy ntactic u nits that
consists of one independent word and one or more
ancillary words, as w e ll as their inter-dependencies;
the latter identifies opinion expressions, which re-
quires to provide some specific-purpose dictiona-
ries, taxonomies, and heuristics. They used Condi-
tional Random Fields and Support Vector Machines
to learn classifiers that make bunsetus that can be
considered conditions apart from the others. Un-
fortun a te ly, their approach was only evaluated on
a small dataset with 3 155 Japanese sentences re-
garding hotels and the be st F
1
score attained was
0.5830. As a co nclusion, this proposal is not gene-
rally a pplicable.
The former approach es confirm that mining con-
ditions is an interesting research problem. Unfortu-
nately, they have many drawbacks that hinder their
general applicability. T his motivated us to work on
a new approach that overcomes their w eaknesses
and outperforms them by means of a sequenc e-
to-sequence model; our proposal only requires a
stemmer and a word embedder, which are readily-
available componen ts.
3 MINING CONDITIONS
In this section, we describe our proposal to mine
conditions, which consists of an encoder-decoder
model that is based on recurrent and bi-directional
recurrent neural networks.
On Mining Conditions using Encoder-decoder Networks
625

Figure 1 sketches its architecture. The input
are sentences that are encode d as vectors of the
form (x
m
, x
m−1
, . . . , x
1
), where e a ch x
i
represents the
correspo nding lowercased, stemmed word (term) in
the sentence (i ∈ [1, m], m ≥ 1); note that m mu st
be set a priori to a large enough length and that
padding must be used when analysing sho rter sen-
tences. The input vectors are first fed into an em-
bedding layer tha t transforms each term into its
correspo nding word embedd ing vector E
i
, which
is assumed to preserve som e similarity amongst
the vectors that correspond to semantically similar
terms (E
i
∈ R
t
, where t denotes the dimensiona-
lity of the word embedding). In order to im prove
efficiency without a significant impact on effective-
ness, we replaced numbers, email addresses, URLs,
and words whose frequency is equal or smaller than
five by class words "NUMBER", "EMAI L", "URL",
and "UNK", respectively. Note that the input vec-
tors encode the reversed in put sentences because
(Sutskever et al., 2014) suggested that this appro-
ach works better with bi-directional recurrent neural
networks and does n ot have a negative impact on
regular recurrent neural networks. Furthermore, in
order to prevent over-fitting, we used drop-out regu-
larisations (Srivastava et al., 2014) and early stop-
ping (Caruana et al., 2000) when the loss did not
improve significatively after 10 epo chs. We used
the Adam method (Kingma and Ba, 2 014) with ba-
tch size 32 as the optimiser.
3.1 The Encoder
We dec ided to implement the encoder using a
single-layer neural network, for which we tried two
alternatives, namely: a recurrent neura l network
(RNN) and a bi-directional recurren t neural net-
work (BiRNN). Th e reason is that th e se networks
are particularly well-suited to d e aling with natural
languag e because of their inherent ability to process
varying-length inputs (even if they must be encoded
using fixed-sized vectors with padding, like in our
problem). The difference is that RNNs cannot take
future elements of the input into account, w hereas
BiRNNs can.
Unfortu nately, such network s suffer f rom the
so-called exploding and vanishing gradient pro-
blems (Bengio et al., 1994; Pascanu et al.,
2013). These problems can be addressed by using
long-short-term-memory units (LSTM) (Hochreiter
and Schmidh uber, 1 997) or gated recurrent units
(GRU) (Han et al., 2017), which basically help con-
trol the data that is passed on to the next tra ining
epoch. Our decision was to use GRU units because
they seem to be more efficient because they do not
have a separate me mory cell like LSTM units.
Hereinafter, we refer to the alternative in which
we use an RNN with GRU units as GRU and to
the alternative in which we use a BiRNN with GRU
units as BiGRU. T he en c oder return s a context vec-
tor C that captures global semantic and syntactic
features of the input sentences. In the case of the
GRU alternative, it is computed as the output of
the last GRU unit, that is, C ∈ R
t
; in the case of
the BiGRU alternative, it is computed fr om the last
left-to-right GRU unit and the last right-to-left GRU
unit, that is, C ∈ R
2t
.
3.2 The Decoder
We decided to imp lement the decoder as a recur-
rent neural network with four layers sin ce ou r pre-
liminary experiments proved that this approach was
better than u sin g a single layer. We implemented
two alternatives, too: one in which we used re-
current neur al networks with gated recurr e nt units
(GRU) and another in whic h we used bi-directional
recurrent neural networks with gated recurrent units
(BiGRU).
The deco der gets a context vecto r as input for
each recurrent unit of the first layer. Then, it com-
putes an output vector D from each recurrent un it of
the last layer. Since the number of recurrent units
for each layer is m, the compone nts of the output
vector D indicate wh ether the cor responding input
term belongs to a cond ition or not using the well-
known IOB classes, namely: I, which indicates that
a term is inside a condition, O, which indicates that
it is outside a condition, and B, which indicates that
it is the beginning of a condition. The ind ividual
components of the output vector are then p assed
onto a collection of perceptrons that comp ute the
output of our sy stem as follows:
ˆ
Y
i
= ϕ(W D
i
+ b) (1)
where ϕ is an activation function, W is a weight
matrix, D
i
is the output of the decoder, and b is
a bias vector.
ˆ
Y
i
represents the probability distribu-
tion of the IOB cla sses as 3-dimensional vectors.
We decided to implement the activation function
using either the Softmax function or the Sigmoid
function, since the preliminary experiments that we
carried out proved tha t other choices resulted in
worse results.
To reconstruct the conditions from this output,
we simp ly take the class with the highest proba-
bility and then r e turn all of th e subsequences of
words in the original sentence that start with a term
ICAART 2019 - 11th International Conference on Agents and Artificial Intelligence
626

with class B that is followed by one, two or mor e
terms with class I.
4 EXPERIMENTAL ANALYSIS
In this section, we first describe our experimen-
tal setup, then comment on our results, and finally
present a statistical analysis.
4.1 Experimental Setup
We implemented our proposal
1
with Python 3.5.4
and the following components: Snowball 1.2.1 to
stemmise words, Gensim 2.3.0 to compute word
embedd ers using a Word2Vec implem entation, and
Keras 2.0. 8 with Theano 1.0.0 for training our neu-
ral networks. We run our experiments on a virtual
computer that was equipped with one Intel Xeon
E5-26 90 core at 2.60 GHz, 2 GiB of RAM, and an
Nvidia Tesla K10 GPU accelerator with 2 GK-104
GPUs at 745 M H z with 3.5 GiB of RAM each;
the operating system on top of which we run our
experiments was CentOS Linux 7.3.
We have not found a single record in the litera-
ture of a dataset with conditions, which motivated
us to crea te one.
2
It consists of 3 790 203 senten-
ces in English and Spanish that were gathered f rom
the Web between April 2017 and May 2017. The
sentences were classified into 15 topic s according
to their sources, n a mely: adults, bab y care, beauty,
books, cameras, compute rs, films, headsets, hotels,
music, ovens, pets, phones, TV sets, and video ga-
mes. We examined roughly 23 000 sentences and
labelled the position where the connectives start, the
position where they end, and the position where the
conditions end.
We evaluated our proposal on our dataset using
4-fold cross-validation. We set the length o f the
input vectors to m = 100 because the analysis of
our dataset revealed that this threshold is enough to
deal with the immense majority of sentences that
we have found on the Web. We measured the stan-
dard performance measures, namely: precision, re-
call, and the F
1
score. We used the proposals by
(Chikersal et al., 2015) and (Mausam e t al., 2012)
as baselines. The proposal by (Nakayama and Fujii,
2015) was not taken into account be c ause we could
not find an implemen ta tion, it is not clear whether
1
The prototype is available at https://github.-
com/FernanOrtega/encoder-decoder.
2
The dataset is available at https://www.-
kaggle.com/fogallego/reviews-with-conditions.
Table 1: Experimental results.
W Z & W Z &
D Ϭ͘ϲϮϳϬ Ϭ͘ϲϭϰϰ Ϭ͘ϲϮϬϲ Ϭ͘ϲϮϳϬ Ϭ͘ϲϭϰϰ Ϭ͘ϲϮϬϲ
Ϭ͘ϳϵϳϵ Ϭ͘ϰϲϰϮ Ϭ͘ϱϴϳϬ Ϭ͘ϳϵϳϵ Ϭ͘ϰϲϰϮ Ϭ͘ϱϴϳϬ
ǀĞƌĂŐĞ Ϭ͘ϳϭϮϱ Ϭ͘ϱϯϵϯ Ϭ͘ϲϬϯϴ Ϭ͘ϳϭϮϱ Ϭ͘ϱϯϵϯ Ϭ͘ϲϬϯϴ
DĂdžŝŵƵŵ Ϭ͘ϳϵϳϵ Ϭ͘ϲϭϰϰ Ϭ͘ϲϮϬϲ Ϭ͘ϳϵϳϵ Ϭ͘ϲϭϰϰ Ϭ͘ϲϮϬϲ
'ZhͲ'Zh Ϭ͘ϲϴϭϲ Ϭ͘ϲϬϵϭ Ϭ͘ϲϰϯϯ Ϭ͘ϲϰϱϱ Ϭ͘ϲϭϴϱ Ϭ͘ϲϯϭϳ
'ZhͲŝ'Zh Ϭ͘ϲϴϬϭ Ϭ͘ϲϭϳϱ Ϭ͘ϲϰϳϯ Ϭ͘ϲϱϮϭ Ϭ͘ϲϯϰϴ Ϭ͘ϲϰϯϯ
ŝ'ZhͲ'Zh Ϭ͘ϲϰϵϵ Ϭ͘ϲϭϴϭ Ϭ͘ϲϯϯϲ Ϭ͘ϲϯϰϱ Ϭ͘ϲϬϵϭ Ϭ͘ϲϮϭϲ
ŝ'ZhͲŝ'Zh Ϭ͘ϲϵϰϳ Ϭ͘ϱϴϵϳ Ϭ͘ϲϯϳϵ Ϭ͘ϲϳϮϮ Ϭ͘ϲϭϴϬ Ϭ͘ϲϰϰϬ
ǀĞƌĂŐĞ Ϭ͘ϲϳϲϲ Ϭ͘ϲϬϴϲ Ϭ͘ϲϰϬϱ Ϭ͘ϲϱϭϭ Ϭ͘ϲϮϬϭ Ϭ͘ϲϯϱϭ
DĂdžŝŵƵŵ Ϭ͘ϲϵϰϳ Ϭ͘ϲϭϴϭ Ϭ͘ϲϯϳϵ Ϭ͘ϲϳϮϮ Ϭ͘ϲϭϴϬ Ϭ͘ϲϰϰϬ
D Ϭ͘ϲϲϵϵ Ϭ͘ϱϮϴϱ Ϭ͘ϱϵϬϵ Ϭ͘ϲϲϵϵ Ϭ͘ϱϮϴϱ Ϭ͘ϱϵϬϵ
Ϭ͘ϳϵϱϯ Ϭ͘ϰϯϵϵ Ϭ͘ϱϲϲϱ Ϭ͘ϳϵϱϯ Ϭ͘ϰϯϵϵ Ϭ͘ϱϲϲϱ
ǀĞƌĂŐĞ Ϭ͘ϳϯϮϲ Ϭ͘ϰϴϰϮ Ϭ͘ϱϳϴϳ Ϭ͘ϳϯϮϲ Ϭ͘ϰϴϰϮ Ϭ͘ϱϳϴϳ
DĂdžŝŵƵŵ Ϭ͘ϳϵϱϯ Ϭ͘ϱϮϴϱ Ϭ͘ϱϵϬϵ Ϭ͘ϳϵϱϯ Ϭ͘ϱϮϴϱ Ϭ͘ϱϵϬϵ
'ZhͲ'Zh Ϭ͘ϲϮϴϴ Ϭ͘ϱϲϴϯ Ϭ͘ϱϵϳϬ Ϭ͘ϲϭϭϳ Ϭ͘ϱϲϰϭ Ϭ͘ϱϴϲϵ
'ZhͲŝ'Zh Ϭ͘ϲϯϵϮ Ϭ͘ϱϳϳϴ Ϭ͘ϲϬϲϵ Ϭ͘ϲϲϲϰ Ϭ͘ϱϳϮϵ Ϭ͘ϲϭϲϭ
ŝ'ZhͲ'Zh Ϭ͘ϲϰϱϱ Ϭ͘ϱϲϮϭ Ϭ͘ϲϬϬϵ Ϭ͘ϱϵϱϳ Ϭ͘ϱϱϲϳ Ϭ͘ϱϳϱϱ
ŝ'ZhͲŝ'Zh Ϭ͘ϲϰϭϭ Ϭ͘ϱϴϯϲ Ϭ͘ϲϭϭϬ Ϭ͘ϲϯϰϵ Ϭ͘ϱϴϳϱ Ϭ͘ϲϭϬϯ
ǀĞƌĂŐĞ Ϭ͘ϲϯϴϲ Ϭ͘ϱϳϮϵ Ϭ͘ϲϬϰϬ Ϭ͘ϲϮϳϮ Ϭ͘ϱϳϬϯ Ϭ͘ϱϵϳϮ
DĂdžŝŵƵŵ Ϭ͘ϲϰϱϱ Ϭ͘ϱϴϯϲ Ϭ͘ϲϭϭϬ Ϭ͘ϲϯϰϵ Ϭ͘ϱϴϳϱ Ϭ͘ϲϭϬϯ
ϕ
с^ŽĨƚŵĂdž
ϕ
с^ŝŐŵŽŝĚ
ĞƐ
>ĂŶŐ
ĞŶ
WƌŽƉŽƐĂů
it can be customised to de a l with lang uages other
than Japanese, and the best F
1
attained was 0.5830.
Regarding our proposal, we evaluated eight al-
ternatives that resu lt from com bining the two al-
ternatives to implement the encoder (GRU or Bi-
GRU), with the two alternatives to implement the
decoder (GRU or BiGRU), and the two alternatives
to implement the activation functions in the last
layer (Softmax and Sigmoid). We used Categorical
Cross-Entropy as the loss function, namely:
L(Y,
ˆ
Y
) = −
1
m
m
∑
i
t
∑
j
Y
i, j
log(
b
Y
i, j
) (2)
where Y is the expe cted output vector for a given
sentence,
b
Y is the outpu t computed by our sy stem,
m is the size of th e input vector, and t is the size
of the word embedding vectors.
4.2 Experimental Results
In Figur e 2, we show th e decay of the loss function
during training. Although it deca ys smoothly for
both functions and achieve low loss value, the Soft-
max activation function seems to decay faster than
the Sigmoid activation function.
Table 1 presents the results of our experiments,
where MB and CB refer to the baselines by (Mau-
sam et al., 2012) and (Chikersal et al., 2 015), re-
spectively. The approaches that beat the best base-
line are hig hlighted in grey.
Although the baselines a re naive approaches to
the problem, they attain relatively good precision;
the proposal by (Mausam et al., 2012) attains a
recall that is similar to its precision, but the propo-
On Mining Conditions using Encoder-decoder Networks
627
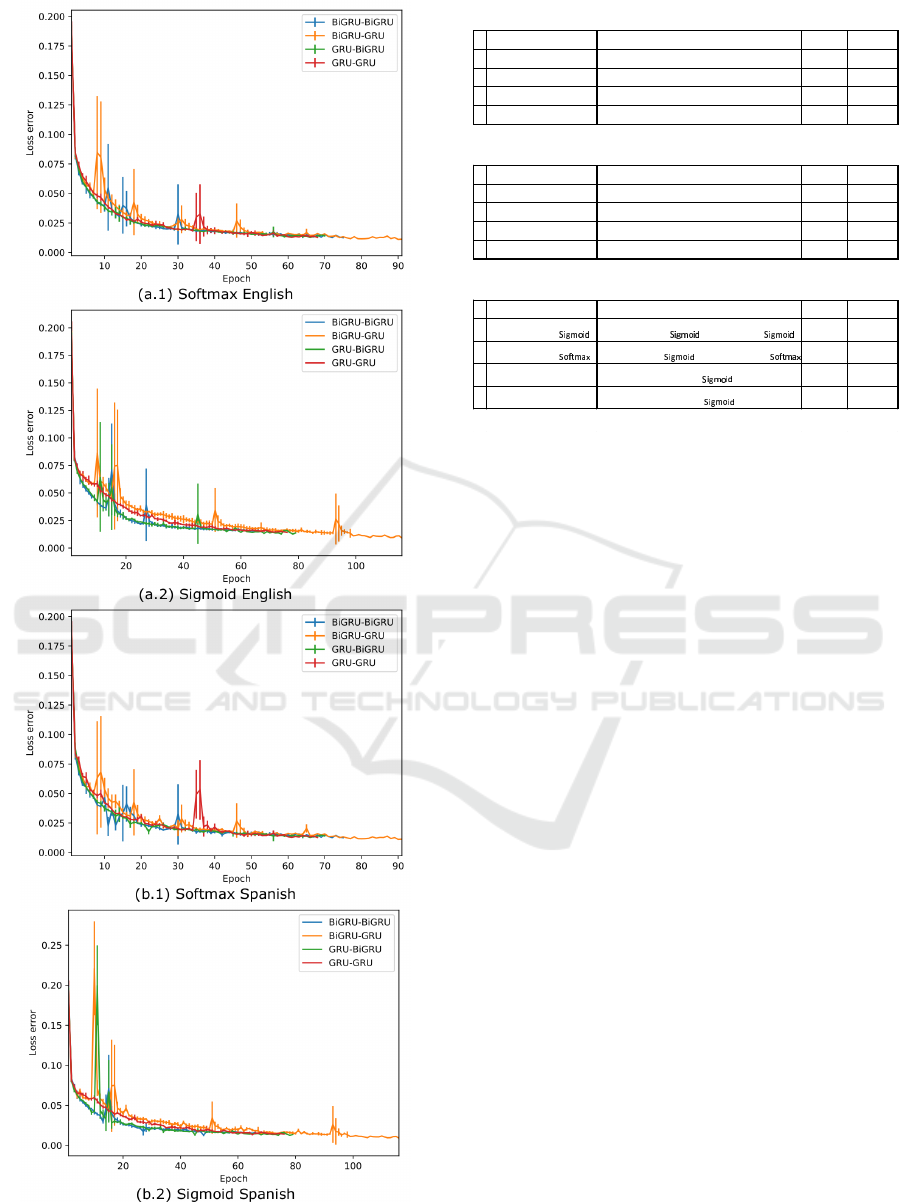
Figure 2: Loss error decay during training epochs.
Table 2: Statistical analysis.
η WƌŽƉŽƐĂů ŽŵƉĂƌŝƐŽŶ nj ƉͲǀĂůƵĞ
ϭ 'ZhͲŝ'Zh 'ZhͲŝ'Zhdž'ZhͲŝ'Zh Ͳ Ͳ
Ϯ ŝ'ZhͲŝ'Zh 'ZhͲŝ'Zhdžŝ'ZhͲŝ'Zh Ϭ͘ϲϲϬϲ Ϭ͘ϱϬϴϵ
ϯ 'ZhͲ'Zh 'ZhͲŝ'Zhdž'ZhͲ'Zh ϭ͘ϯϮϭϮ Ϭ͘ϭϴϲϰ
ϰ ŝ'ZhͲ'Zh 'ZhͲŝ'Zhdžŝ'ZhͲ'Zh ϭ͘ϳϯϰϬ Ϭ͘ϬϴϮϵ
η WƌŽƉŽƐĂů ŽŵƉĂƌŝƐŽŶ nj ƉͲǀĂůƵĞ
ϭ 'ZhͲŝ'Zh 'ZhͲŝ'Zhdž'ZhͲŝ'Zh Ͳ Ͳ
Ϯ ŝ'ZhͲŝ'Zh 'ZhͲŝ'Zhdžŝ'ZhͲŝ'Zh Ϭ͘ϯϯϬϯ Ϭ͘ϳϰϭϮ
ϯ 'ZhͲ'Zh 'ZhͲŝ'Zhdž'ZhͲ'Zh Ϯ͘ϰϳϳϮ Ϭ͘ϬϭϯϮ
ϰ ŝ'ZhͲ'Zh 'ZhͲŝ'Zhdžŝ'ZhͲ'Zh ϯ͘ϯϬϮϵ Ϭ͘ϬϬϭϬ
η WƌŽƉŽƐĂů ŽŵƉĂƌŝƐŽŶ nj ƉͲǀĂůƵĞ
ϭ 'ZhͲŝ'Zh
'ZhͲŝ'Zh dž'ZhͲ'Zh Ͳ Ͳ
Ϯ 'ZhͲŝ'Zh
'ZhͲŝ'Zh dž'ZhͲŝ'Zh Ϭ͘ϬϴϮϲ Ϭ͘ϵϯϰϮ
ϯ D 'ZhͲŝ'Zh
džD Ϯ͘ϮϮϵϱ Ϭ͘ϬϮϱϴ
ϰ 'ZhͲŝ'Zh
dž ϰ͘ϭϮϴϲ Ϭ͘ϬϬϬϬ
;ďͿŽŵƉĂƌŝƐŽŶŽĨŽƵƌ^ŝŐŵŽŝĚͲďĂƐĞĚƉƌŽƉŽƐĂůƐ
;ĂͿŶĂůLJƐŝƐŽĨŽƵƌ^ŽĨƚŵĂdžͲďĂƐĞĚƉƌŽƉŽƐĂůƐ
;ĐͿŽŵƉĂƌŝƐŽŶŽĨŽƵƌǁŝŶŶŝŶŐƉƌŽƉŽƐĂůƚŽƚŚĞďĂƐĞůŝŶĞƐ
sal by (Chikersal e t al., 2015) falls short regarding
recall. None of our ap proaches beat the ba selines
regarding precision, but most of them beat the base-
lines regarding recall since they learn more complex
patterns than ks to the deep learning approach that
projects the input sentences onto a rich com puter-
generated feature space. Note that the improvement
regarding recall is enough for the F
1
score to im-
prove the baselines.
Regarding the activation function, precision is
better for most of our alternatives when the Soft-
max activation function is used, but all of our
alternatives attain similar results regarding recall
indepen dently from the activa tion function. Fi-
nally, the best alterna tives for English are GRU -
BiGRU when using Softmax and BiGRU-BiGRU
when using Sigmoid; the best a lternatives for Spa-
nish are BiGRU-BiGRU when using Softmax and
GRU-BiGRU when using Sigmoid.
4.3 Statistical Analysis
To make a decision regarding which of the alterna-
tives performs the best, we used a stratified strategy
that builds on Hommel’s test.
In Tables 2.a and 2.b, we report on the results
of the statistical analysis regarding our proposal.
They show the rank of each approach, and then the
compariso ns between the best one and the others;
for every compa rison, we show th e value o f the
z statistic and its corresponding adjusted p-value.
In the case of the Softmax activation function, the
experimental results do not provide any evidences
that the best-ranked appro ach is different from the
others since the adjusted p-value is greater than the
ICAART 2019 - 11th International Conference on Agents and Artificial Intelligence
628

standard significance level α = 0.05 in every case.
In the case of the Sigmoid activation function, the
experimental results do not provide any evidences
that the best-ranked appro ach is different from the
second one since the adjusted p-value is greater
than the standard significance level; however, there
is enough evidence to prove that it is different from
the remaining ones since the adjusted p-value is
smaller th an the significance level. So, we selected
the GRU-BiGRU alternative in both ca ses.
Next, we compare d our best alternatives to the
baselines. The results of the comparison a re shown
in Table 2.c, where the subindex d enotes the activa-
tion function used. According to the statistical test,
there is not enough evidence in the experimental
data to make a difference between our proposals,
but there is enough evidence to prove that they
both are significantly better than the baseline s.
5 CONCLUSIONS
We have motivated the need for mining conditi-
ons and we have presented a novel approach to the
problem. It relies on a encoder-decoder model as
a means to overcome the drawbacks that we have
found in o ther proposals, namely: it does not rely
on user-defined patterns, it does not require any
specific-purpose dictionaries, taxo nomies, or heu-
ristics, and it ca n mine conditions in both factual
and opinion sen tences. Furthermor e it only needs
two components that are read ily available, namely:
a stemmer and a word embedder. We have also per-
formed a comprehensive experimental analysis on a
large multi-topic dataset with 3 779 000 sentences in
English and Spanish that we make publicly availa-
ble. Our results confirm that our proposal is similar
to the state-of-the -art proposals in terms of preci-
sion, but it improves recall enough to beat them
in terms of the F
1
score. We have backed up the
previous conclusions using sound statistical tests.
ACKNOWLEDGEMENTS
The work described in this paper was supported
by Opileak.es and the Spa nish R&D programme
(grants TIN2013-40848-R and TIN2013-40848-R).
The computing facilities were provided by the An-
dalusian Scientific Computing Cen tre (CICA).
REFERENCES
Bengio, Y., Simard, P. Y., and Frasconi, P. ( 1994). Le-
arning long-term dependencies with gradient descent
is difficult. IEEE Trans. Neural Networks, 5(2):157–
166.
Caruana, R., Lawrence, S., and Giles, C. L. (2000). Over-
fitting in neural nets: Backpropagation, conjugate
gradient, and early stopping. In NIPS, pages 402–
408.
Chen, H., Huang, S., Chiang, D., and Chen, J. (2017).
Improved neural machine translation with a syntax-
aware encoder and decoder. In ACL, pages 1936–
1945.
Chikersal, P., Poria, S., Cambria, E., Gelbukh, A . F., and
Siong, C. E . (2015). Modelling public sentiment in
Twitter. In CICLing (2), pages 49–65.
Cho, K., van Merrienboer, B., Bahdanau, D. , and Ben-
gio, Y. (2014). On the properties of neural ma-
chine translation: Encoder-decoder approaches. In
EMNLP, pages 103–111.
Chopra, S ., Auli, M., and Rush, A. M. (2016). Ab-
stractive sentence summarization with attentive re-
current neural networks. In NAACL, pages 93–98.
Etzioni, O., Fader, A., Christensen, J. , Soderland, S., and
Mausam (2011). Open information extraction: the
second generation. In IJCAI, pages 3–10.
Han, H. , Zhang, S., and Qiao, J. (2017). An adaptive gro-
wing and pruning algorithm for designing recurrent
neural network. Neurocomputing, 242:51–62.
Hochreiter, S. and Schmidhuber, J. (1997). Long short-
term memory. Neural Comput., 9(8):1735–1780.
Kingma, D. P. and Ba, J. (2014). Adam: A method for
stochastic optimization. CoRR, abs/1412.6980.
Ma, X. and Hovy, E. H. (2016). End-to-end sequence la-
beling via bi-directional LSTM-CNNs-CRF. In ACL,
pages 1–11.
Mausam (2016). Open information extraction systems
and downstream applications. In IJCAI, pages 4074–
4077.
Mausam, Schmitz, M., Soderland, S., Bart, R., and Etzi-
oni, O. (2012). Open language learning for informa-
tion extraction. In EMNLP-CoNLL, pages 523–534.
Mitchell, T. M., Cohen, W. W., Hruschka, E. R. , Ta-
lukdar, P. P., Betteridge, J., Carlson, A., Mishra,
B. D., Gardner, M., Kisiel, B., Krishnamurthy, J.,
Lao, N., Mazaitis, K., Mohamed, T., Nakashole, N.,
Platanios, E. A., Ritter, A., Samadi, M., Settles, B.,
Wang, R. C., Wijaya, D. T., Gupta, A., Chen, X.,
Saparov, A., Greaves, M., and Welling, J. (2015).
Never-ending learning. In AAAI, pages 2302–2310.
Nakayama, Y. and Fujii, A. (2015). Extracti ng condition-
opinion relations toward fine-grained opinion mi-
ning. In EMNLP, pages 622–631.
Nallapati, R., Zhou, B., dos Santos, C. N., Gülçehre, Ç.,
and Xiang, B. (2016). Abstractive text summariza-
tion using sequence-to-sequence rnns and beyond. In
CoNLL, pages 280–290.
On Mining Conditions using Encoder-decoder Networks
629

Narayanan, R., Liu, B., and Choudhary, A. N. (2009).
Sentiment analysis of conditional sentences. In
EMNLP, pages 180–189.
Pascanu, R., Mikolov, T., and Bengio, Y. (2013). On the
difficulty of training recurrent neural networks. In
ICML, pages 1310–1318.
Ravi, K. and Ravi, V. (2015). A survey on opinion
mining and sentiment analysis: tasks, approaches
and applications. Knowl.-Based Syst., 89:14–46.
Rush, A. M., Chopra, S., and Weston, J. (2015). A neural
attention model for abstractive sentence summariza-
tion. In EMNLP, pages 379–389.
Schouten, K. and Frasincar, F. (2016). Survey on aspect-
level sentiment analysis. IEEE Trans. Knowl. Data
Eng., 28(3):813–830.
Skeppstedt, M., Schamp-Bjerede, T., Sahlgren, M., Para-
dis, C., and Kerren, A. (2015). Detecting speculati-
ons, contrasts and conditionals in consumer reviews.
In WASSA@EMNLP, pages 162–168.
Srivastava, N., Hinton, G. E., Krizhevsky, A. , Sutskever,
I., and Salakhutdinov, R. (2014). Dropout: a sim-
ple way to prevent neural networks fr om overfitting.
Journal of Machine Learning Research, 15(1):1929–
1958.
Sutskever, I., Vinyals, O., and Le, Q. V. (2014). Sequence
to sequence learning with neural networks. In NIPS,
pages 3104–3112.
Zhai, F., Potdar, S., Xiang, B., and Zhou, B. (2017). Neu-
ral models for sequence chunking. In AAAI, pages
3365–3371.
Zhu, S. and Yu, K. (2017). Encoder-decoder with focus-
mechanism for sequence labelling based spoken lan-
guage understanding. In ICASSP, pages 5675–5679.
ICAART 2019 - 11th International Conference on Agents and Artificial Intelligence
630
