
One Shot Learning for Generic Instance Segmentation in RGBD Videos
Xiao Lin
1, 2
, Josep R. Casas
2
and Montse Pard
`
as
2
1
Industry and Advanced Manufacturing Department, Vicomtech, San Sebastian, Spain
2
Image Processing Group (GPI), Universitat Polit
´
ecnica de Catalunya, Barcelona, Spain
Keywords:
Instance Segmentation, One Shot Learning, Convolutional Neural Network.
Abstract:
Hand-crafted features employed in classical generic instance segmentation methods have limited discrimina-
tive power to distinguish different objects in the scene, while Convolutional Neural Networks (CNNs) based
semantic segmentation is restricted to predefined semantics and not aware of object instances. In this paper,
we combine the advantages of the two methodologies and apply the combined approach to solve a generic
instance segmentation problem in RGBD video sequences. In practice, a classical generic instance segmen-
tation method is employed to initially detect object instances and build temporal correspondences, whereas
instance models are trained based on the few detected instance samples via CNNs to generate robust features
for instance segmentation. We exploit the idea of one shot learning to deal with the small training sample
size problem when training CNNs. Experiment results illustrate the promising performance of the proposed
approach.
1 INTRODUCTION
The performance of classical generic instance seg-
mentation methods, such as (Lin et al., 2018), is usu-
ally restricted to the discriminative power of the em-
ployed hand-crafted features. Those features are not
representative enough to describe and distinguish dif-
ferent object instances when segmenting interacting
object instances in generic scenes. On the other hand,
Convolutional Neural Networks (CNNs) based se-
mantic segmentation methods introduce a good re-
presentation for the predefined semantics, which are
trained to extract robust features via networks with a
huge number of parameters. Although the success of
applying CNNs to semantic segmentation proves the
strong representation capability of CNNs can be ex-
ploited on dense prediction tasks, it also shows some
drawbacks. One of the major downsides of CNNs ba-
sed approaches is their hunger for training data. In se-
mantic segmentation, training data is prepared as ma-
nually labeled segmentation masks, in which labels in
the mask represent different semantics. Preparing the
training data for semantic segmentation requires large
efforts on manual labeling due to the big necessity of
training data. Besides, the idea of semantic segmenta-
tion restricts to certain types of predefined semantics,
which compromises its application to more generic
scenes. From the perspective of generic segmenta-
tion, training data can hardly be prepared, since no
semantics are predefined.
In video instance segmentation, methods propo-
sed to detect/segment generic object instances, such
as (Endres and Hoiem, 2010) and (Lee et al., 2011),
are usually employed as an object proposal genera-
tor. An offline temporal analysis is exploited, in or-
der to search from a pool of object proposals within
a frame along a video sequence, which, in conse-
quence, restricts them to offline applications. On the
other hand, model based generic instance segmen-
tation methods, such as (Husain et al., 2015; Koo
et al., 2014), usually employ online training techni-
ques, where instance models are trained and updated
along a video sequence. These approaches introduce
a way to train instance models without predefined se-
mantics. However, the models used in these appro-
aches are usually simple, such as Gaussian models
used in (Koo et al., 2014) and quadratic functions in
(Husain et al., 2015), due to the small size of the trai-
ning data.
In this paper, we present a generic instance seg-
mentation method which combines the advantages of
the generic instance segmentation method introduced
in (Lin et al., 2018) and those of CNNs based seman-
tic segmentation. That is the genericity in the generic
instance segmentation method and the strong object
representation power in CNNs, by exploiting the idea
Lin, X., Casas, J. and Pardàs, M.
One Shot Learning for Generic Instance Segmentation in RGBD Videos.
DOI: 10.5220/0007259902330239
In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2019), pages 233-239
ISBN: 978-989-758-354-4
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
233

of one shot learning. We employ the classical gene-
ric instance segmentation method to discover object
instances and build temporal correspondences based
on all low level features. To represent the discovered
object instances, we first train a CNN model offline
for tracking generic object instances. Based on it, we
fine-tune the tracking model online with the few ex-
amples of the discovered object instances, in order to
obtain one CNN for each object instance to extract ro-
bust features. In that case, we can predict more accu-
rately if a pixel belongs to the instance or not, based
on the features extracted from CNNs rather than hand-
crafted features used in (Lin et al., 2018). On the other
hand, the genericity is also kept, since no prior infor-
mation, such as initialization or predefined semantics,
is introduced in the proposed approach. Furthermore,
in the experiments section we also evaluate the results
obtained using the generic tracking CNN model trai-
ned offline, without object specific online fine-tuning.
We observe that even these generic features outper-
form the hand-crafted ones, with a similar run-time
performance.
2 RELATED WORK
The most challenging part of the proposed approach
is how to train the CNNs based system with very limi-
ted annotations. The deep architecture of CNNs pro-
vides a complex function with a large amount of pa-
rameters so that useful representations of high dimen-
sional data can be learned. However, this advantage
of CNNs becomes an obstacle in the training process
when only few annotation is provided. In this case,
the learned model is strongly over-fitted due to the
large number of parameters and limited training data.
To tackle the problem, we employ the idea of one shot
learning. The key insight of one shot learning is that,
rather than learning from scratch, one can take advan-
tage of knowledge coming from a previously learned
model and solve the new learning tasks using only one
or few training samples.
One shot learning is an extreme case of transfer
learning. Transfer learning is widely used for training
CNNs in various tasks. For instance, (Chen et al.,
2016) trains a semantic segmentation network first on
a image classification purpose using the large scale
dataset ImageNet (Deng et al., 2009) as the training
data. Then, they take this pre-trained model as an ini-
tialization for a further training with a smaller set of
training data for the semantic segmentation task. In
(Girshick et al., 2014), the authors also pre-train their
object detection network with ImageNet on an image
classification purpose.
One shot learning methods have also been deve-
loped for various tasks in the state of the art, such
as image recognition (Vinyals et al., 2016; Fei-Fei
et al., 2006) and gesture recognition (Konecn
`
y and
Hagara, 2014). More related to our approach, there
are also one shot learning based approaches for video
object segmentation. In (Caelles et al., 2016), the aut-
hors present one shot object segmentation on video
sequences, based on a fully-convolutional neural net-
work architecture that is able to successively transfer
generic semantic information, learned on ImageNet,
to the task of foreground segmentation, and finally
to learning the appearance of a single annotated ob-
ject and segment the object in the following frames
with the learned object model in the test sequence.
Similarly, MaskTrack (Khoreva et al., 2016) learns to
refine the detected mask of an object, by using the
detections of the previous frame. The authors first
synthesize the movement of an object mask between
consecutive frames by performing affine transforma-
tion and non-rigid deformation to ground truth object
masks in group of datasets. In this manner, the mask
refinement network is generally trained off-line for
generic objects in the group of datasets. Then, they
fine-tune the network online for a specific object in a
test sequence using only the ground truth mask provi-
ded in the first frame. One of the drawbacks of these
approaches is that they require an accurate initializa-
tion for performing one shot learning on an object in-
stance in the scene.
3 CLASSICAL GENERIC
INSTANCE SEGMENTATION
In (Lin et al., 2018), the authors have introduced
a classical generic instance segmentation method F,
which calculates the current segmentation O
t
in frame
t with point cloud Ct obtained from the current
RGBD frame and the previous segmentation O
t−1
,
F (C
t
, O
t−1
) → O
t
. O
t
consists of different object in-
stances o
1
t
, o
2
t
...o
M
o
t
∈ O
t
, where M
o
denotes the num-
ber of objects in the scene. Since the temporal cor-
respondences between object instances are made in
F, we have the observed sequence of object instances
in the history for each object instance o
i
1...t−1
before
the segmentation in frame t is obtained. To segment
the current frame, the point cloud C
t
is first divided
into blobs b
1
t
, b
2
t
...b
M
b
t
by analyzing the point cloud
connectivity built on a super-voxel graph G
t
(v, e), in
which v represents super-voxels set and e represents
the edge set of the adjacency of super-voxels. The
current blobs are then assigned to object labels from
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
234

blob
Frame t
Obj 1
Obj 2
Frame t-1
Tem poral Cor responden ce
Seg. Frame t
Blob Seg.
Obj 1
Obj 2
Figure 1: An example of blob segmentation in frame t con-
sidering the temporally corresponded object instances in
frame t − 1.
the previous frame via an optimization process. Blobs
assigned to more than one object labels need Blob
Segmentation. Fig.1 shows an example of a blob seg-
mentation, in which a blob (the region with green
boundary) in frame t is segmented with respect to the
object instances detected in frame t − 1 (the region
with blue and yellow boundary) and the temporal cor-
respondence built between these two frames.
The segmentation for the first frame is simply
done by first removing the plane-like point sets in the
input point cloud, then searching for connected com-
ponents on the super-voxel graph built on the residual
point cloud. In this manner, isolated point sets are
extracted from the input point cloud, which ideally
corresponds to object instances in the scene.
In (Lin et al., 2018), blob segmentation is achieved
by labeling nodes on the graph of the blob with assig-
ned object labels via a Fully Connected Conditional
Random Field (FC-CRF) model. FC-CRF introduces
an unary energy describing the degree of confidence
that a super-voxel belongs to an object instance and a
pairwise energy representing the degree of confidence
that two super-voxels belong to the same object in-
stance. Optimizing the energy function with the two
energy terms provides the best labeling of the graph,
which implicitly represents the segmentation of the
blob. The unary energy for each node on the graph is
defined based on low level features, such as 3D dis-
tance and color. As in (Lin et al., 2016), we define the
unary energy for labelling node v
i
with object label o
j
as the mean distance between node v
i
in the current
frame and the k-nearest nodes labeled by o
j
in the pre-
vious frame. This mean distance is computed compa-
ring feature vectors which concatenate 3 components:
color feature (color histogram in LAB color space),
shape feature (local surface normal) and 3D position
(3D coordinates of the node centroid). Details can be
found in (Lin et al., 2016). These low level featu-
res are not always discriminative enough for well dis-
tinguishing/segmenting different object instances in a
blob, which produces segmentation errors.
Figure 2: The schema of proposed approach.
4 CNNS BASED UNARY ENERGY
LEARNING
To tackle the above mentioned problem, we propose
to exploit CNNs to extract robust features for defi-
ning the unary energy in the blob segmentation task.
In practice, we train one CNN model N
i
for each ob-
ject instance based only on the few observations of
that object instance in the history. The CNN N
i
ex-
tracts feature maps from the input data and outputs a
2 classes probability map via a softmax layer at the
end of the CNN N
i
. The probability map consists of
probabilities that each pixel belongs to instance i or
not. For a super-voxel v
i
, the probability is compu-
ted as the mean probability of pixels in v
i
. Then, we
simply employ the probabilities of the super-voxels
obtained from the CNN models of different object in-
stances as the unary energy. However, training CNNs
with millions of parameters from scratch usually re-
quires a large number of annotated data, in order to
optimize the parameters for extracting robust repre-
sentation of the input data. In our case, we only have
few object instance observations in the history o
i
1...t−1
in frame t, which can be employed as training data.
With limited number of annotated data, it is difficult
to follow the training-from-scratch process. Thus, we
follow the method proposed in (Khoreva et al., 2016)
to perform one shot learning using the object instance
observations in the history.
Given the segmentation of an object o
i
t−1
in frame
t − 1 and the input color image I
t
in frame t, our aim
is to train a CNN N
i
I
t
, o
i
t−1
→ P
t
i
, where P
t
i
repre-
sents a probability map for object instance o
i
at time
t. P
t
i
(x, y) stands for the output probability that the
pixel (x, y) on the input image I
t
belongs to object
One Shot Learning for Generic Instance Segmentation in RGBD Videos
235

o
i
t
or not (P (x, y) =
h
P
o
i
t
(x, y), P
¯
o
i
t
(x, y)
i
). The CNN
model generates the current object instance segmenta-
tion by refining the object instance segmentation o
i
t−1
in frame t − 1 with respect to the current color image
I
t
. We formulate the CNN based unary energy in Eq. 1
as:
µ
v
j
(i) =
1
M
v
j
∑
∀(x,y)∈v
j
P
i
(x, y) (1)
where M
v
j
stands for the number of pixel contained
in super-voxel v
j
. Note that, in Eq. 1, we omit the
notation t for conciseness.
We employ two steps to achieve the training pro-
cess: the offline training and online training step. In
the offline training step, a base network is first em-
ployed to learn the generic attributes in an image clas-
sification task. Then, we extend the base network to
learn a generic notion of how to segment an object
instance taking a color image and a mask in the previ-
ous frame as the input. In the online training step, we
specify the extended network to a specific object in-
stance by fine-tuning the the generic model obtained
in the previous step, using only the few observations
of the object instance in a sequence. Fig.2 shows the
schema of the proposed approach.
4.1 Offline Training
A VGG network (Simonyan and Zisserman, 2014) is
used as our base network and is pre-trained on Ima-
geNet (Deng et al., 2009) for an image classification
task, which has proven to be a very good initializa-
tion in other tasks (Chen et al., 2016; Girshick et al.,
2014). Although the network is not capable of perfor-
ming image segmentation, it provides generic attribu-
tes in the network, which can be further specified to
tackle other tasks.
The network is then extended to cope with the
segmentation task. We follow Deeplab-ASPP (Chen
et al., 2016), which replaces the fully connected lay-
ers in VGG network with atrous upsampling layers
to achieve dense classification in a semantic segmen-
tation task. Deeplab-ASPP is selected due to its
outstanding performance in semantic segmentation.
Then, we extend the network to allow an extra mask
channel in the input. The extra mask channel is meant
to provide an estimation of the visible area of the ob-
ject in the current frame, its approximate location and
shape. We can then train the extended network to out-
put an accurate segmentation of the object instance,
given as input the current image and a rough estimate
of the object mask. To simulate the noise of the previ-
ous frame output, during offline training, we generate
input masks by deforming the annotations using af-
fine transformation as well as non-rigid deformations
via thin-plate splines(Bookstein, 1989), followed by
a coarsening step (dilation morphological operation)
to remove details of the object contour. We apply
this data generation procedure over a dataset of 10
4
images containing diverse object instances. The af-
fine transformations and non-rigid deformations aim
at modelling the expected motion of an object bet-
ween two frames. The coarsening permits us to gene-
rate training samples that resemble the test time data,
simulating the blobby shape of the output mask gi-
ven from the previous frame by the extended network.
These two ingredients make the estimation more ro-
bust to noisy segmentation estimates while helping to
avoid accumulation of errors from the preceding fra-
mes.
4.2 Online Training
The offline training provides the extended network the
ability to refine a roughly estimated mask of a generic
object instance (e.g. the instance mask in the previous
frame) to a segmentation of the object instance. In the
case of a particular sequence, we fine-tune the exten-
ded network, in order to adapt it to the specific object
instance based on the few observation of this object
instance in the history.
Given the observations of an object instance
o
i
1...t−1
, i ∈
{
1...M
o
}
and the images I
1...t−1
, we
obtain t − 2 training data, each of which contains
D
o
i
j−1
, I
j
, o
i
j
E
, j ∈
{
1...t − 1
}
. Apart from this, we
also perform data augmentation for the t − 1 obser-
vations following the data generation method intro-
duced in Section 4.1, in which we randomly gene-
rate o
i
j−1
for
D
I
j
, o
i
j
E
by applying affine transform and
non-rigid deformation. The extended model is fine-
tuned based on these training data, in order to learn
the appearance of a specific object instance and seg-
ment it in the current frame.
4.3 Training Details
Following the descriptions in previous subsections,
we provide the training details of our network regar-
ding the offline and online training strategies.
4.3.1 Network Architecture
The base network follows the architecture of VGG
network (Simonyan and Zisserman, 2014). VGG net-
work employs 5 groups of convolutional layers with
kernel size 3 ∗ 3 to extract robust features from an in-
put image. Following each group of convolutional
layers, a max pooling layer is provided to downsam-
ple the internal feature maps, so that the features can
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
236
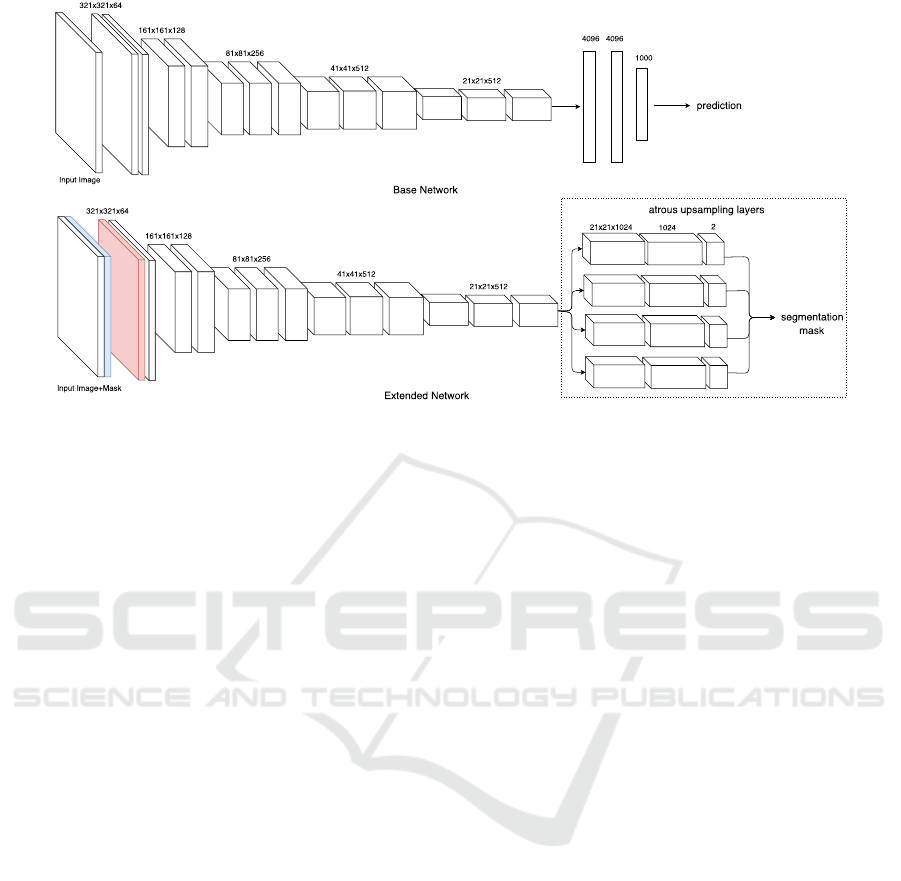
Figure 3: The architectures of the base network and extended network.
be extracted more globally in the following convolu-
tional layers. A Rectified Linear Unit (ReLU) is used
as the activation function for each convolutional layer.
Similarly, the extended network follows the architec-
ture of Deeplab-ASPP which shares the same features
network than VGG network (Simonyan and Zisser-
man, 2014) and substitutes the fully connected layers
in the VGG network with atrous upsampling layers.
These atrous upsampling layers perform Atrous Spa-
tial Pyramid Pooling (ASPP) on the feature maps to
achieve the dense classification task in semantic seg-
mentation. Following (Khoreva et al., 2016), we ex-
tended Deeplab-ASPP to allow an extra mask channel
in an input (denoted blue input channel in the exten-
ded network in Fig.3) by adding another channel in
the filters of the first convolutional layer. Fig.3 shows
an illustration of the architecture of the base network
and extended. Note that the pooling layers are not
shown in the figure for conciseness.
4.3.2 Offline Training
The extended network is initialized from a base net-
work pre-trained on ImageNet for an image classifica-
tion task. For the added channel in filters of the first
convolutional layer (see the red layer in the extended
network in Fig.3) and atrous upsampling layers, we
use Gaussian initialization. The training data used in
the offline training process is generated from serveral
datasets (Cheng et al., 2015; Li et al., 2014; Mova-
hedi and Elder, 2010; Shi et al., 2016) by performing
affine transformation and thin-plate splines (Book-
stein, 1989). That is to say, for each object mask o
on image I, we generate transformed and deformed
masks of o, which forms several offline training sam-
ples. For affine transformation, we consider random
scaling (±5% of object size), translation (±10% shift)
and rotation (±10
◦
). For deformation, we use 5 cont-
rol points and randomly shift them within ±10% mar-
gin of the original object mask. Next, the mask is co-
arsened using dilation operation with 5 pixel radius.
This mask deformation procedure is applied over all
object instances in the training set. For each image
two different masks are generated.
We use Stochastic Gradient Descent (SGD) with
mini-batches of 10 images and a polynomial learning
policy with initial learning rate of 0.001. The mo-
mentum and weight decay are set to 0.9 and 0.0005,
respectively. The network is trained for 20k iterations.
4.3.3 Online Training
For online adaptation, we fine-tune the model previ-
ously trained offline for 200 iterations with training
samples generated from the few observations in the
history. We augment the few observations by image
flipping and rotations as well as by deforming the an-
notated masks for an extra channel via affine and non-
rigid deformations with the same parameters as for
the offline training. This results in an augmented set
of 10
3
training images. The network is trained with
the same learning parameters as for offline training,
fine-tuning all convolutional layers.
5 EXPERIMENTS
In this section, we report the experiment results in
the RGBD video foreground segmentation dataset (Fu
One Shot Learning for Generic Instance Segmentation in RGBD Videos
237

CNN+GISGIS
Figure 4: Examples of qualitative results from CNN+GIS
in the first row and GIS in the second row.
et al., 2017) comparing with the classical generic in-
stance segmentation (GIS) method introduced in (Lin
et al., 2018). The RGBD video foreground segmen-
tation dataset (Fu et al., 2017) contains 12 RGBD se-
quences captured in 7 different types of scenes with
multiple objects. Since blob segmentation is nee-
ded only when objects interact with each other (phy-
sically attached), we perform both the CNN based
generic instance segmentation (CNN+GIS) and the
classical GIS on all the sequences, but evaluation is
only made in frames which involve object interacti-
ons. We keep the evaluation metrics used by (Lin
et al., 2018) in the experiment as mean Intersection
over Union (mIoU). Fig.4 shows some comparison
results, in which results from CNN+GIS are shown
in the first row and results from GIS in the second
row. CNN+GIS obtains clearly improved segmenta-
tion results than GIS due to the better defined unary
energy (see the better object boundaries obtained in
CNN+GIS). A quantitative comparison is also made
on this dataset, shown in Table 1. Apart from GIS and
CNN+GIS, we introduce a comparison to CNN+GIS
without performing online training (CNN+GIS-OT).
CNN+GIS obtains around 6% higher mIoU than GIS,
whereas CNN+GIS-OT also outperforms GIS with
around 2% higher mIoU. To fully exploit the RGBD
data, we have also explored the possibility to in-
corporate the depth map as an extra input channel
in CNN+GIS, however no improvement is observed,
while the complexity is increased.
Table 2 shows average time spent for building
the unary energy in GIS, CNN+GIS and CNN+GIS-
OT in one blob segmentation respectively. Although
CNN+GIS outperforms GIS in mIoU, the computatio-
nal complexity is higher than GIS. With a trade-off in
accuracy, the computation complexity of CNN+GIS
can be decreased by eliminating online training pro-
cess or reducing the online training samples to obtain
the expected run-time performance in the applicati-
ons.
Table 1: Quanitative comparision between GIS, CNN+GIS
and CNN+GIS without performing online training.
mIoU
GIS 67.2
CNN+GIS 73.5
CNN+GIS-OT 69.1
Table 2: Run-time performance of building the unary
energy in GIS, CNN+GIS and CNN+GIS without perfor-
ming online training.
time
GIS 0.07s
CNN+GIS 12s
CNN+GIS-OT 0.09s
6 CONCLUSION
In this paper, we have presented a method which com-
bines the strong object representation power in CNN
based semantic segmentation methods and the gene-
ricity in the generic instance segmentation method in-
troduced in (Lin et al., 2018), and applied the combi-
ned approach to solve an instance segmentation pro-
blem. We verify the feasibility of employing one-
shot learning method to model object instances with
very few examples discovered by the generic object
instance segmentation (GIS) method. The experiment
results illustrate that an improved segmentation per-
formance can be obtained by combining those two
methods. On the other hand, instance independent le-
arned features for tracking obtain a better result than
hand-crafted features based on color, shape and 3D
distance, with just a slight increase of the computati-
onal time. Features fine-tuned to the instance that is
being tracked achieve the best results, but with a much
higher run-time performance.
ACKNOWLEDGEMENT
This work has been developed in the framework of
project TEC2016-75976-R and TEC2013-43935-R,
financed by the Spanish Ministerio de Economia y
Competitividad and the European Regional Develop-
ment Fund (ERDF).
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
238

REFERENCES
Bookstein, F. L. (1989). Principal warps: Thin-plate splines
and the decomposition of deformations. IEEE Tran-
sactions on pattern analysis and machine intelligence,
11(6):567–585.
Caelles, S., Maninis, K.-K., Pont-Tuset, J., Leal-Taix
´
e,
L., Cremers, D., and Van Gool, L. (2016). One-
shot video object segmentation. arXiv preprint
arXiv:1611.05198.
Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K., and
Yuille, A. L. (2016). Deeplab: Semantic image seg-
mentation with deep convolutional nets, atrous con-
volution, and fully connected crfs. arXiv preprint
arXiv:1606.00915.
Cheng, M.-M., Mitra, N. J., Huang, X., Torr, P. H., and
Hu, S.-M. (2015). Global contrast based salient region
detection. IEEE Transactions on Pattern Analysis and
Machine Intelligence, 37(3):569–582.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-
Fei, L. (2009). ImageNet: A Large-Scale Hierarchical
Image Database. In CVPR09.
Endres, I. and Hoiem, D. (2010). Category independent ob-
ject proposals. In European Conference on Computer
Vision, pages 575–588. Springer.
Fei-Fei, L., Fergus, R., and Perona, P. (2006). One-shot
learning of object categories. IEEE transactions on
pattern analysis and machine intelligence, 28(4):594–
611.
Fu, H., Xu, D., and Lin, S. (2017). Object-based multiple
foreground segmentation in rgbd video. IEEE tran-
sactions on image processing: a publication of the
IEEE Signal Processing Society.
Girshick, R., Donahue, J., Darrell, T., and Malik, J. (2014).
Rich feature hierarchies for accurate object detection
and semantic segmentation. In Proceedings of the
IEEE conference on computer vision and pattern re-
cognition, pages 580–587.
Husain, F., Dellen, B., and Torras, C. (2015). Consistent
depth video segmentation using adaptive surface mo-
dels. Cybernetics, IEEE Transactions on, 45(2):266–
278.
Khoreva, A., Perazzi, F., Benenson, R., Schiele, B., and
Sorkine-Hornung, A. (2016). Learning video ob-
ject segmentation from static images. arXiv preprint
arXiv:1612.02646.
Konecn
`
y, J. and Hagara, M. (2014). One-shot-learning ge-
sture recognition using hog-hof. Journal of Machine
Learning Research, 15:2513–2532.
Koo, S., Lee, D., and Kwon, D.-S. (2014). Incremental ob-
ject learning and robust tracking of multiple objects
from rgb-d point set data. Journal of Visual Commu-
nication and Image Representation, 25(1):108–121.
Lee, Y. J., Kim, J., and Grauman, K. (2011). Key-segments
for video object segmentation. In 2011 International
Conference on Computer Vision, pages 1995–2002.
IEEE.
Li, Y., Hou, X., Koch, C., Rehg, J. M., and Yuille, A. L.
(2014). The secrets of salient object segmentation.
In Proceedings of the IEEE Conference on Computer
Vision and Pattern Recognition, pages 280–287.
Lin, X., Casas, J., and Pard
`
as, M. (2016). 3d point cloud
segmentation oriented to the analysis of interactions.
In The 24th European Signal Processing Conference
(EUSIPCO 2016). Eurasip.
Lin, X., Casas, J. R., and Pard
`
as, M. (2018). Temporally
coherent 3d point cloud video segmentation in generic
scenes. IEEE Transactions on Image Processing.
Movahedi, V. and Elder, J. H. (2010). Design and perceptual
validation of performance measures for salient object
segmentation. In Computer Vision and Pattern Re-
cognition Workshops (CVPRW), 2010 IEEE Computer
Society Conference on, pages 49–56. IEEE.
Shi, J., Yan, Q., Xu, L., and Jia, J. (2016). Hierarchical
image saliency detection on extended cssd. IEEE tran-
sactions on pattern analysis and machine intelligence,
38(4):717–729.
Simonyan, K. and Zisserman, A. (2014). Very deep con-
volutional networks for large-scale image recognition.
arXiv preprint arXiv:1409.1556.
Vinyals, O., Blundell, C., Lillicrap, T., Wierstra, D., et al.
(2016). Matching networks for one shot learning. In
Advances in Neural Information Processing Systems,
pages 3630–3638.
One Shot Learning for Generic Instance Segmentation in RGBD Videos
239
