
Picking Process Variability in Small and Medium-Sized Enterprises:
State of the Art and Knowledge Modeling
Daniel Hilpoltsteiner
1
, Stephanie Bäuml
2
and Christian Seel
1
1
Institute for Project Management and Information Modelling, Landshut University of Applied Sciences,
Landshut, Germany
2
Technology Centre for Production and Logistics Systems, Landshut University of Applied Sciences, Landshut, Germany
Keywords: Process Variability Modelling, Order Picking Process, Knowledge Management, Information Modeling,
Adaptive Process Modeling.
Abstract: Information modelling is an established standard for knowledge representation in companies. However, small
and medium-sized companies (SME) often lack the resource to use it for their own purpose. In this paper a
solution to model business process variability in order picking processes is discussed. Therefore we did a
knowledge extraction from different companies using a questionnaire, expert interviews and workshops with
different experts from the field of production logistics in SME has been done. Based on their knowledge
different variants of order picking processes in SME were defined and put together in an adaptive process
model. Using configuration terms to enrich the adaptive process model allows the distinction between these
different variants. Based on different influencing factors a specific process variant can be generated from the
process model using element selection and further process optimizations including introducing new technol-
ogies can be made.
1 INTRODUCTION
Knowledge management is an important component
for the documentation of business processes and at
the same time the starting point for the digitization
strategy in companies besides the reduction of waste
in the processes (Becker et al., 2012). The non-use of
employee knowledge is wasteful and of crucial im-
portance for operational processes. Shared
knowledge is the basis for process improvements,
prevention of knowledge loss (e.g. employee fluctua-
tion, demographic change) and support of learning
and coaching processes.
The analysis of the actual situation and the mod-
elled processes are the basis for the identification of
strengths and weaknesses in the process and for the
elaboration of development potentials. In addition to
the core processes which create value in the company,
there are also so-called support processes (Becker et
al., 2012). One of these support processes in manu-
facturing companies is logistics with order picking as
a sub-process. In this paper we focus on picking pro-
cesses in SME, because they are an important part of
the value chain. The preparatory activities of logistics
staff in this process reduce waste in the value-adding
production process. The production employees do not
have to collect their goods themselves, which short-
ens distances and reduces access times to the neces-
sary goods (Womack et al., 2006).
Information modeling is a well-established stand-
ard for knowledge representation in companies (Seel,
2010). Expert interviews and results from a question-
naire in various SME showed a deficit in workflow
documentation using information modeling tech-
niques. In practice, problems arise when dealing with
model variants. Problems in the management of busi-
ness process variants can be seen in many industries
and application areas for example in logistics or pro-
ject management (Timinger and Seel, 2016).
Creating a separate model for each variant, which
differ only in a few details, will lead to great effort in
model maintenance, expansion and inconsistencies.
Instead we can combine multiple process variants to
an adaptive process model and extract concrete vari-
ants based on defined influence factors. Constructing
an adaptive information model helps to reduce effort
in maintenance and inconsistencies.
The purpose of the paper is to answer the follow-
ing research questions related to knowledge manage-
ment through information models in the field of order
picking processes. Furthermore technologies are pre-
sented which can enhance the order picking process.
120
Hilpoltsteiner, D., Bäuml, S. and Seel, C.
Picking Process Variability in Small and Medium-Sized Enterprises: State of the Art and Knowledge Modeling.
DOI: 10.5220/0006896901200127
In Proceedings of the 10th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2018) - Volume 3: KMIS, pages 120-127
ISBN: 978-989-758-330-8
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

RQ1 How is knowledge management of picking
processes implemented in SME?
RQ2 How can information modeling support
knowledge management in picking pro-
cesses?
The article is divided into the following sections:
At first, the state of research is presented as related
work. Subsequently, the research methodology used
and the structure of the empirical study are discussed.
The next chapter presents the results from the empir-
ical study. Chapter Variability modeling in picking
processes presents the different variants of infor-
mation modeling and explains the resulting adaptive
information model in picking processes. An evalua-
tion of the results completes the contribution.
2 RELATED WORK
According to the VDI (Association of German Engi-
neers), a picking process is defined as (Verband
Deutscher Ingenieure, 1994) "assemble a partial
quantity (assortment) from total quantities of goods
based on requirements (order)".
The picking processes of the participating SME in
the transfer project were analyzed which are con-
ducted according to the "man to goods" picking sys-
tem. The three building blocks defined by GÜNTHNER
(Günthner et al., 2009) are preparation, picking pro-
cess and follow-up were analyzed. In accordance with
VDI guideline 3590, the order picking process is di-
vided into the following sub-tasks: specify transport
information, transport goods to preparation area, pro-
vide goods for picking, specify pick information,
picker move to preparation area, picking goods, de-
liver pick, confirm pick, transport collection unit for
hand over (Figure 1). The main focus of this paper
lies on the picking process itself, because no variants
were found during preparation and post processing of
the picking.
For the examined SME, information is provided
exclusively by means of a picking list. This form of
information provision is the most widespread one
(Günthner et al., 2009). All relevant order data is
listed in the picking list. Among other things, the ar-
ticle, its storage location and quantity is listed. If the
individual items on the picking list are sorted by lo-
cation, it is referred to as a guided picking list. In con-
trast to an unguided picking list, which leads to longer
picking times through not optimized routes.
The prerequisite for process improvements are
described and modeled processes in the form of infor-
mation models (Becker, 2007). Consistently man-
aged, complete information models can also lead to
an improvement in knowledge transfer within the
company. As already mentioned in the introduction,
problems often occur with variants in business pro-
cesses in various industries and applications, such as
logistics, automotive and project management (Tim-
inger and Seel, 2016). If one maintain each of these
variants, which differ only in partial steps, in a sepa-
rate information model, their consistent maintenance
leads to increased effort and an increased risk of in-
consistencies. It makes sense to combine variants of
a process in a single adaptive information model in
order to achieve a reduction in effort. An adaptive or
configurable information model contains different
variants of a process in a single information model.
Variant management is a permanent and ubiqui-
tous problem in information modelling and the state
of current research (La Rosa et al., 2017). The general
goal of variant management is to combine several
variants of the same domain in one model. This can
be adjusted by adding or removing parts of a model.
The existing approaches consider configurable nodes,
element annotation, specialization through various
activities and adapted model fragments. The greatest
scope of research comprises the element annotation,
where predicates are linked to elements of a customi-
zable process model through annotation. (Becker et
al., 2003; Delfmann, 2006).
To annotate the configuration terms on the elements
of the information model, the configuration procedure
"element selection by terms" is used (Becker et al.,
2003). The problem with this method is not the con-
figuration of the models themselves, but rather the
consistent and efficient construction of the infor-
mation models. After executing an element selection,
the result is a meta-model based model projection that
only contains elements whose terms are evaluated to
true (Delfmann, 2006). A similar but simplified ap-
proach to meta-model based model pro jection is the
evaluation of the information models using configu-
ration terms (Seel, 2017). These are annotated to the
elements of the model and ensure the extraction of in-
dividual variants from the adaptive process model.
Figure 1: Reference picking process in BPMN 2.0 based on VDI3590.
Picking Process Variability in Small and Medium-Sized Enterprises: State of the Art and Knowledge Modeling
121

3 RESEARCH METHOLOGY
The paper follows the design science research para-
digm proposed by HEVNER et al. (Hevner and Chat-
terjee, 2010). According to them two complementary
research paradigms have been established in the field
of information science. A distinction is made between
behavioral and construction-oriented research. The
former is based on the formation and verification of
theories about artifacts. This also includes the search
and empirical validation of hypotheses. The aim of
the paradigm is to test the correctness based on the
empirical suitability of theories. Design science, on
the other hand, is based on the engineering approach
and focuses on the construction and evaluation of de-
veloped artifacts. The latter can be implementations,
methods, models and languages.
The first research question (RQ1) is based on an
empirical study and is assigned to behavioral re-
search. A questionnaire was issued to the companies
involved in the technology transfer project. After
evaluation of the questionnaire, a structured interview
guideline was developed and expert interviews were
conducted with four SME using the interview guide-
line. In addition, there is an “intelligent logistic sys-
tems” working group consisting of specialists and
managers from different SME and large companies in
the region. This enables an interactive exchange of
technical and expert knowledge on various problems
in production logistics. The structure of the question-
naire, the structured interview guideline and the
working group is explained in more detail in the fol-
lowing chapter Structure of the empirical study.
The second research question (RQ2) is answered
with the help of the construction oriented paradigm.
This involves modeling the companies picking pro-
cesses in BPMN 2.0 and transferring them into an
adaptive information model. The picking process var-
iants and the adaptive information model represent ar-
tifacts of the design science process. An evaluation is
ensured regarding to the completeness and function-
ality of the adaptive information model in comparison
to the collected picking process variants.
4 STRUCTURE OF THE
EMPIRICAL STUDY
The results of this chapter are based on an empirical
study in form of a quantitative approach using a ques-
tionnaire (Meuser and Nagel, 2009). In the question-
naire various information about the companies were
requested including general company information
such as the number of employees, the type of produc-
tion and the industry they belong to. Further questions
dealt with the self-assessment of companies in certain
areas such as production logistics, applied technolo-
gies and the degree of digitization. In addition, the
characteristics of information modeling and its com-
plexity in the company were queried. More precise,
the consistency of information modeling, the fre-
quency of adaptations to information models, but also
the access possibilities of the employees were ques-
tioned. In addition, they were asked about modeling
languages and tools used in the company as well as
the responsibility for information modeling. The
questionnaire included closed questions, semi-open
and open questions. The last ones were used to obtain
more detailed statements in certain areas. The results
of the questionnaire serve as initial indications and
are incorporated into the structured interview guide-
lines for the expert interviews. The quantitative ap-
proach is supported by a qualitative approach in form
of expert interviews with staff from the four SME par-
ticipating in the EDRF Project and workshops with
specialists and managers from production logistics.
Expert interviews in four companies were used to
determine the picking process variants and the factors
influencing the process. The structured interview
guidelines were discussed with employees and man-
agers. It was divided into the three parts: knowledge
management in the company, consideration of the
picking process including influencing factors and
their impact on process variants. The findings on the
picking processes in the SME serve as a basis for the
developed artifacts, which are presented in the chap-
ter Variability modeling in picking processes. This in-
cludes influencing factors for the picking process and
the resulting variants. After the parts of the empirical
study have been shown, the results are presented in
the following chapter.
5 RESULTS OF EMPIRICAL
STUDY
A questionnaire as described in the previous chapter
was sent to 23 cooperating companies. At the end of
the survey, the response rate was 70 percent. Nearly
all companies are affiliated to the NACE (Nomencla-
ture Générale des Activités Économiques dans les
Communautés Européennes)-Codes for manufactur-
ing industry and the spectrum ranges from very small
companies to global players. Some relevant infor-
mation are shown in Figure 2.
The key findings from the questionnaire on
knowledge management and information models in
KMIS 2018 - 10th International Conference on Knowledge Management and Information Sharing
122

the companies are as follows (RQ1). In general, the
questionnaire shows that information models and
knowledge in the company are insufficiently main-
tained and rarely updated. At the same time, two
thirds of those companies are committed to an estab-
lished continuous improvement process. As a result,
the level of knowledge modeled in the company and
the actual situation of the processes differ. It is very
important to maintain changes to workflows in infor-
mation models in a timely manner, but only about
40 % of the companies provide timely maintenance
for their information models. The majority of those
involved consider the advantages of consistently
maintained information models in the areas of real-
time error detection, congestion management or weak
points in process chains to be important. Problems in
these areas can only be solved if processes in the com-
pany are modeled and correspond to the actual situa-
tion. However, only one company has indicated that
it uses a standardized modeling language to map its
business processes. However, modeled processes are
the starting point for optimizing processes and avoid-
ing errors (Becker et al., 2012). In addition, well-
structured processes can reduce manual workflows
and the resulting media disruptions, thereby creating
greater transparency and leading to a more flexible
reaction to changes.
Another insight of the questionnaire was that em-
ployees have insufficient access to information mod-
els in the company, if they exist. Around half of the
companies surveyed stated that they regularly train
their employees. These shortcomings lead to a higher
probability of errors in the processes. In order to be
able to detect errors in processes, a modeled process
is necessary, but regular process assessments (certifi-
cations) are also useful (Schmelzer and Sesselmann,
2013). According to the results of the questionnaire,
evaluations of the processes never take place or only
take place irregularly, which makes it difficult to
identify deviations between the processes described
and the actual situation in the companies.
Based on the results of the questionnaire, the
structured interview guide as presented in the chapter
Structure of the empirical study was developed. This
served as the basis for the expert interviews in the
companies. The results from the second and the third
part of the structured interview guide are presented in
the chapter Variability modeling in picking processes.
The expert interviews on the subject of knowledge
management in the four SME showed that knowledge
is predominantly documented in text form via work
instructions and made available to employees either
via the intranet or in printed form at the workplace.
Furthermore, structured documentation of the picking
processes was found in two out of four companies. In
one company it was the requirement of the certifica-
tion institution and in the other a necessity to train
new employees. In the latter there are considerations
to realize the knowledge about Wiki-based
knowledge management system. Another result of the
Figure 2: Results from the questionnaire.
0 2 4 6
not at all
a little
intermediate
rather consistent
very consistent
consistent use of information models (n=13)
0 2 4 6 8
not at all
very uncommon
yearly
quarterly
in case of changes
not specified
maintainance of information models (n=17)
0 5 10
not at all
irregular
regular (defined period)
not specified
training on information modeling (n=17)
0 2 4 6
not at all
infrequently
regular (defined period)
commonly
on demand
not specified
frequency of process assessments (n=15)
Picking Process Variability in Small and Medium-Sized Enterprises: State of the Art and Knowledge Modeling
123
questionnaire is that employees generally have a
deeper knowledge of the work processes as docu-
mented in information models. In addition,
knowledge is unevenly distributed across several em-
ployees within the same department. The reasons for
the incomplete preparation of knowledge in the com-
panies are: Added value from knowledge manage-
ment for the company is not recognized, information
modelling is not recognized as a value-adding activ-
ity, expenditure for the survey of complex processes
cannot be mapped with the available resources in
SME. Complex processes result from several influ-
encing factors in the picking process, which means
that there are several different variants of the same
process. In order to enable companies to maintain
their business processes in information models due to
their limited resources, it is proposed to combine the
different variants of one process into a single adaptive
process model.
6 VARIABILITY MODELING IN
PICKING PROCESSES
Using the reference picking process according to
Günthner et al., an actual state analysis of the existing
picking processes in the four SME was conducted.
This chapter deals with the results from the picking
process and information modeling from the expert
interviews.
During the analysis, it became apparent that the
documentation of work processes in the company is
scarce and employees have only limited access to it.
In cases where documentation exists in text form, de-
viations can partly be determined by process changes
between the time of the process documentation and
the actual situation in the company. Various variants
of the picking processes were identified, which differ
only in partial steps. Factors influencing the process
included a sorted and unsorted picking list, order-re-
lated and order-neutral picking, and technology-sup-
ported picking confirmation. The influencing factors
mentioned in Figure 3 in BPMN 2.0 determine the
variants of the picking process (RQ2). These were
collected in cooperation with the technical experts of
the companies. The different variation steps are
marked in red in the information model.
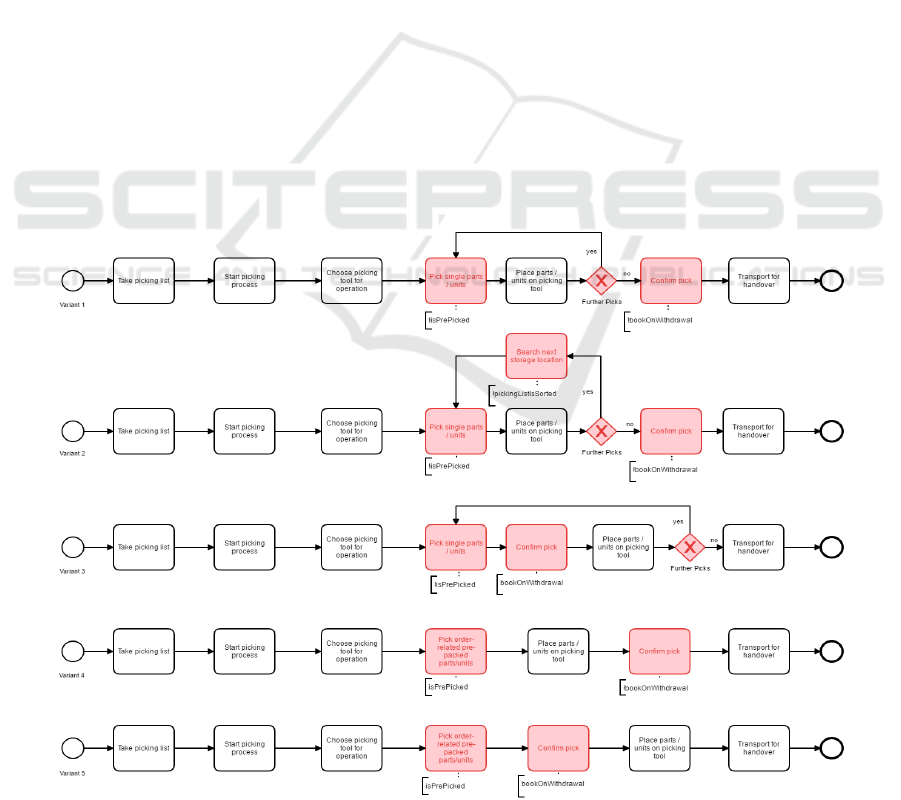
Variant 1 is a classic order-neutral picking
process using a sorted picking list, without any
technological support during goods withdrawal. The
withdrawal is confirmed at the end of the process by
posting all items in the ERP system (Enterprise
Resource Planning). Variant 2 differs from Variant 1
in using an unsorted pick list. Therefore, the
additional process step "Search next storage location"
Figure 3: Overview of the collected picking process variants.
KMIS 2018 - 10th International Conference on Knowledge Management and Information Sharing
124
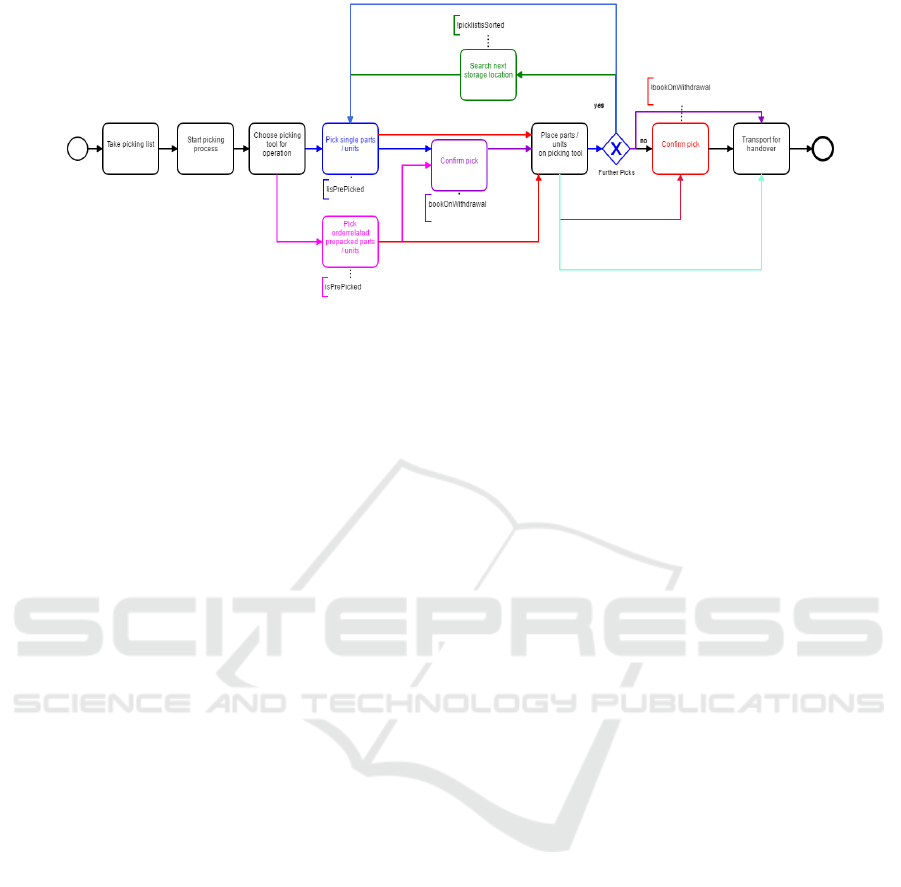
Figure 4: Adaptive Information model, which includes all variants from Figure 2.
is included. Variant 3 describes a process that
provides technological support for the picking
confirmation. Withdrawal is acknowledged in real
time by using technologies pick-by or barcode
scanning technologies. The fourth variant describes
an order-related picking process in which the goods
for an order have already been pre-packed. The fifth
variant describes the order-related picking process,
which, like variant 3, is supported by a technology for
picking confirmation. The variants presented are only
an excerpt of the situation found in the four SME.
Further variants were found when using different
picking aids and in hybrid approaches to order-related
and order-neutral picking lists. The modelling and
description of all further variants would go beyond
the scope of the article and would not show any
further insights for solving the above-mentioned
problem.
It is clear to see that an increased effort is in-
volved in the maintenance of information models if a
company has to maintain all these variants in separate
information models. When process changes occur to
the same parts of the picking process (shown black in
Figure 3), all affected information models must be
modified. Inconsistencies can occur if certain infor-
mation models have been forgotten. If companies are
certified, these inconsistencies can lead to deviations
in the certification assessment and inconsistencies
should therefore be avoided.
To solve this problem, it is proposed to combine
the five variants in an adaptive information model.
Using the configuration terms, which are annotated to
the elements of the model, any original variant can be
generated by an algorithm. This algorithm was imple-
mented in a software tool and can be accessed via an
online repository (Bitbucket, 2018; Hilpoltsteiner et
al., 2018). Figure 4 shows the constructed adaptive
information model, which represents an artifact of the
Design Science process. The adaptive model was en-
riched with configuration terms, which were added to
the individual elements and edges. A configuration
term as used in the model is shown below. The con-
figuration term gets interpreted by the software tool
and returns the result of the expression. Only ele-
ments with the Boolean result true remain in the
model. In the current solution this leads to redun-
dancy regarding to edges.
[pickingListIsSorted] == false &&
[isPrePicked] == false
Altogether three configuration variables were
used in the adaptive information model. They can be
displayed and maintained in a separate overview. Us-
ing an additional function of the software tool, all el-
ements can be colored which have an identical con-
figuration term. As a rule, the variants can already be
identified by this. This approach poses problems,
when several variants dependent on each other. For
example, the process step "Place parts / units on pick-
ing tool" causes problems because it can be achieved
by both incoming process steps with different vari-
ants.
7 EVALUATION
The aim of the design science process is to create ar-
tifacts that solve a practical problem (Hevner and
Chatterjee, 2010). One of the core activities of the De-
sign Science process is the evaluation of the created
artifact to prove and justify its usefulness (Peffers et
al., 2007). To demonstrate the usefulness of the de-
signed artifact it is examined whether all originally
determined variants are present in the adaptive infor-
mation model and can be generated using configura-
tion terms. As a first indicator for the correctness of
the adaptive information model, the number of colors
Picking Process Variability in Small and Medium-Sized Enterprises: State of the Art and Knowledge Modeling
125
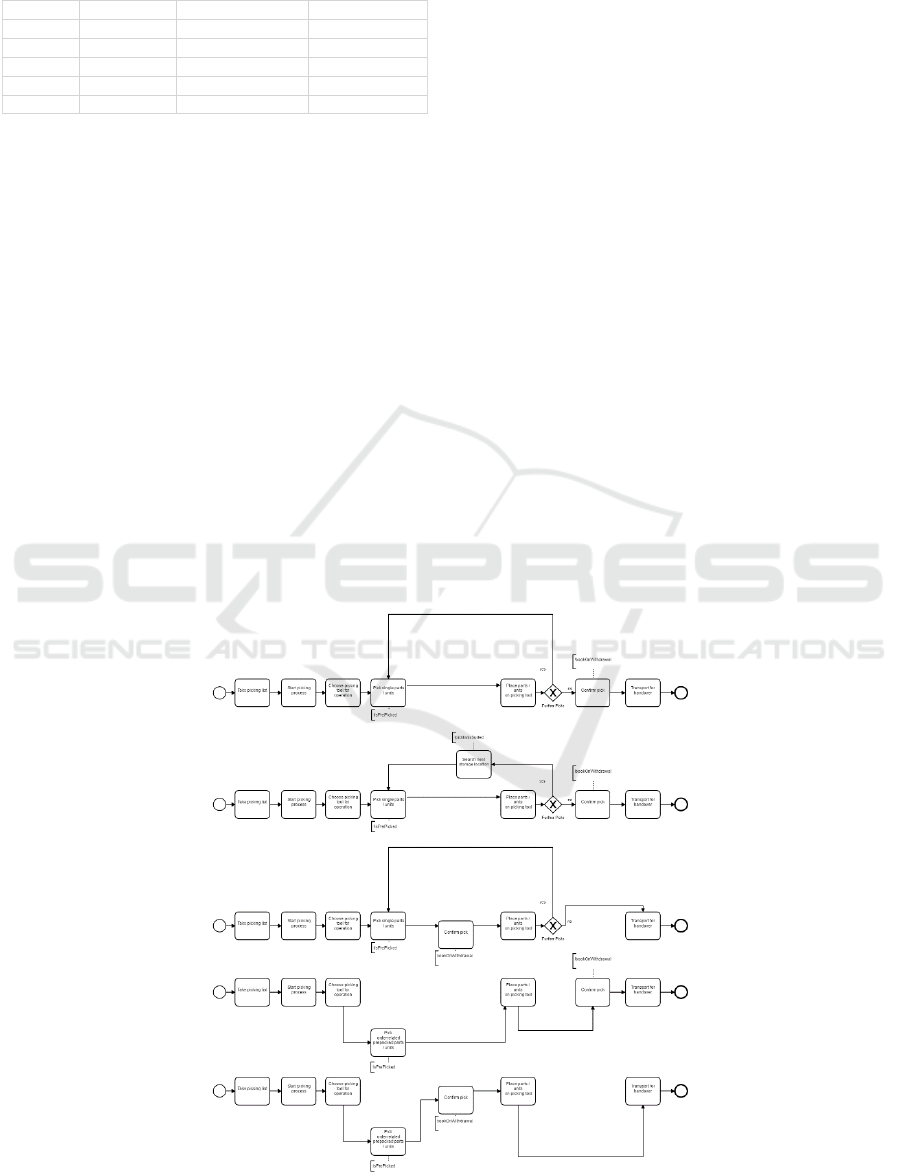
Table 1: Matrix including the used configuration variables
and their relation to the process variants.
can be checked. Elements that occur in all variants are
displayed in black. As already mentioned in the pre-
vious chapter, problems occur when coloring the ele-
ments as soon as the configuration terms differ. The
reason for this problem is that common process steps
can follow two different variants. Therefore, the sub-
sequent configuration term of the process step differs
from both the first and second incoming variants. The
mere check of the correctness of the information
model based on the number of colors can therefore
not be guaranteed in this case. However, the approach
would work well with completely independent pro-
cess variants. On the software side this behavior can
be further optimized. The variable assignments for
the individual variants are defined in Table 1. The in-
dividual variants of the adaptive information model
are written down vertically. By assigning variable
values to variants, one can test whether the individual
information model variants can be generated from the
adaptive information model. The values are inserted
into the evaluation interface of the software tool.
Figure 5 shows the generated information models
from the software tool. On closer inspection, all five
generated variants are technically correct. Only their
optical appearance differs by the positioning of the el-
ements and the edges, because the absolute positions
from the adaptive information model are used. Com-
mercial software already offers possibilities to auto-
matically align elements after changes.
By creating the adaptive information model, the
effort for the administration and maintenance of in-
formation models could be reduced, because only one
information model must be maintained. This will also
reduce the risk of inconsistency after changes to var-
iants. However, it should be noted that the introduc-
tion of configuration terms in the adaptive infor-
mation model leads to a higher complexity of the
model.
8 CONCLUSION
In this paper the two research questions RQ1 and RQ2
have been answered. The first question dealt with the
state of the art of knowledge management in picking
processes in SME (RQ1).
It was found that knowledge management in SME
is insufficiently established in order picking. The rep
Figure 5: All generated variants from the software tool.
isPrePicked bookOnWithdrawal pickingListIsSorted
Variant 1 false false true
Variant 2 false false false
Variant 3 false true true
Variant 4 true false true || false
Variant 5 true true true || false
KMIS 2018 - 10th International Conference on Knowledge Management and Information Sharing
126

resentation of knowledge in information models is
also weak. Furthermore, it was discovered that
knowledge is unequally distributed among employ-
eesin the same department and that access to the in-
formation models is not guaranteed across the depart-
ment. The documentation of knowledge and its acces-
sibility is essential to avoid errors. Also errors in the
processes themselves or potentials for optimizations
can often only be recognized if these have already
been documented in advance. The questionnaire and
the interviews with experts showed that there is po-
tential for development in SME. Among other things,
the modelling of business processes due to variations
was considered complex. Especially the documenta-
tion of these process variants is important to achieve
a holistic representation of the process flows.
As part of the empirical study, expert interviews
were conducted in four SME. Various factors have
been identified that influence the order picking pro-
cess in SME. Together with the companies, these var-
iants of the picking processes were documented. With
the help of adaptive information modeling, an artifact
was created from these process variants as part of the
design science process. Using this artifact, the support
of knowledge management in SME through infor-
mation modeling was demonstrated (RQ2). Specifi-
cally, variants of the picking process were collected
and modelled in four SME. Based on the influencing
factors, the adaptive information model was extended
by configuration terms. Through using element selec-
tion by terms, all process variants found in the com-
panies in Figure 3 can be recreated. The correctness
of the information model and the software tool that
executes the element selection by terms was proven
in the evaluation of this paper.
Overall, adaptive information models can support
SME in documenting their expert knowledge. Espe-
cially in processes with many variation steps, adap-
tive information modeling enables a more compact
option for long-term digitalization of knowledge,
which requires less effort in maintenance and man-
agement. Above all, the possibility of optimizing pro-
cesses on the basis of the documented processes has
great advantages.
ACKNOWLEDGEMENTS
The technology transfer project "Competence Net-
work Intelligent Production Logistics" is funded by
the European Regional Development Fund (ERDF) -
Operational Program "Investment in Growth and Em-
ployment" Bavaria 2014 - 2020.
REFERENCES
Becker, J. (Ed.) (2007). Reference modeling. Heidelberg:
Physica-Verl.
Becker, J., Knackstedt, R., Kuropka, D., & Delfmann, P.
(2003). Konfiguration fachkonzeptioneller Referenz-
model. WI. (2003), 901–920.
Becker, J., Kugeler, M., & Rosemann, M. (Eds.) (2012).
Prozessmanagement: Ein Leitfaden zur prozess-
orientierten Organisationsgestaltung. Berlin,
Heidelberg: Springer Gabler.
Bitbucket. ipimlandshut / ipimmodeler. Retrieved April 26,
2018, from https://bitbucket.org/ipimlandshut/ipim
modeler.
Delfmann, P. (2006). Adaptive Referenzmodellierung:
Methodische Konzepte zur Konstruktion und Anwendung
wiederverwendungsorientierter Informationsmodelle.
Günthner, W. A., Blomeyer, N., Reif, R., & Schedlbauer, M.
(2009). Pick-by-Vision: Augmented Reality unterstützte
Kommissionierung. Garching: Lehrstuhl für
Fördertechnik Materialfluß Logistik (fml) Techn. Univ.
München.
Hevner, A. R., & Chatterjee, S. (2010). Design Research in
Information Systems Theory and Practice. Integrated
Series in Information Systems Volume 22.
Hilpoltsteiner, D., Seel, C., & Dörndorfer, J. (2018).
Konzeption und Implementierung eines Softwarewerk-
zeuges zum Management von BPMN-Prozessvarianten.
In R. Hofmann & W. Alm (Eds.), Wissenstransfer in der
Wirtschaftsinformatik. Fachgespräch im Rahmen der
MKWI 2018 (pp. 15–24). Aschaffenburg: Hochschule
Aschaffenburg, Information Management Institut.
La Rosa, M., van der Aalst, W. M. P., Dumas, M., & Milani,
F. P. (2017). Business Process Variability Modeling: A
Survey. ACM Computing Surveys, 50(1), 1–45.
Meuser, M., & Nagel, U. (2009). Das Experteninterview —
konzeptionelle Grundlagen und methodische Anlage. In
S. Pickel, D. Jahn, H.-J. Lauth, & G. Pickel (Eds.),
Methoden der vergleichenden Politik- und Sozial-
wissenschaft. Neue Entwicklungen und Anwendungen
(1st ed., pp. 465–479). Wiesbaden: VS Verlag für
Sozialwissenschaften / GWV Fachverlage GmbH
Wiesbaden.
Peffers, K., Tuunanen, T., Rothenberger, M. A., & Chatter-
jee, S. (2007). A Design Science Research Methodology
for Information Systems Research, 24(3), 45–77.
Schmelzer, H. J., & Sesselmann, W. (2013). Geschäfts-
prozessmanagement in der Praxis: Kunden zufrieden
stellen ; Produktivität steigern ; Wert erhöhen. München:
Hanser.
Seel, C. (2010). Reverse Method Engineering.
Wirtschaftsinformatik - Theorie und Anwendung.
Seel, C. (2017). Metamodellbasierte Erweiterung der BPMN
zur Modellierung und Generierung von Prozess-
varianten.
Timinger, H., & Seel, C. (2016). Ein Ordnungsrahmen für
adaptives hybrides Projektmanagement. GPM-Magazin
PMaktuell, 2016(4), 55–61.
VDI 3590 (April 1994). Düsseldorf: VDI-Gesellschaft
Fördertechnik Materialfluß Logistik.
Womack, J. P., Jones, D. T., & Roos, D. (2006). The machine
that changed the world. New York, NY:
HarperPerennial.
Picking Process Variability in Small and Medium-Sized Enterprises: State of the Art and Knowledge Modeling
127
