
Ontology-based Information Extraction from Technical Documents
Syed Tahseen Raza Rizvi
1, 2
, Dominique Mercier
2
, Stefan Agne
1
, Steffen Erkel
3
, Andreas Dengel
1
and Sheraz Ahmed
1
1
German Research Center for Artificial Intelligence (DFKI), Kaiserslautern, Germany
2
Kaiserslautern University of Technology, Kaiserslautern, Germany
3
Bosch Thermo-technology, Lollar, Germany
Keywords:
Table Detection, Information Extraction, Ontology, PDF Document, Document Analysis, Table Extraction,
Relevancy.
Abstract:
This paper presents a novel system for extracting user relevant tabular information from documents. The pre-
sented system is generic and can be applied to any documents irrespective of their domain and the information
they contain. In addition to the generic nature of the presented approach, it is robust and can deal with differ-
ent document layouts followed while creating those documents. The presented system has two main modules;
table detection and ontological information extraction. The table detection module extracts all tables from a
given technical document while, the ontological information extraction module extracts only relevant tables
from all of the detected tables. The generalization in this system is achieved by using ontologies, thus enabling
the system to adapt itself, to a new set of documents from any other domain, according to any provided ontol-
ogy. Furthermore, the presented system also provides a confidence score and explanation of the score for each
of the extracted tables in terms of its relevancy. The system was evaluated on 80 real technical documents of
hardware parts containing 2033 tables from 20 different brands of Industrial Boilers domain. The evaluation
results show that the presented system extracted all of the relevant tables and achieves an overall precision,
recall, and F-measure of 0.88, 1 and 0.93 respectively.
1 INTRODUCTION
Tabular data representation is one of the most com-
mon way of presenting a lot of information in com-
pact form. Mostly, the tables are relatively simple
but sometimes a piece of information is shared be-
tween multiple rows or columns in the form of merged
rows or columns. Technical documents usually con-
tain hundreds of pages with dozens or hundreds of
tables. Most of the times, we are interested in only a
few tables among all tables in a document.
A lot of solutions have been proposed so far for
table detection and extraction but they were designed
to work on a specific set of documents with a known
layout. Furthermore, there are a bunch of complicated
cases for merged rows and columns within a table.
Sometimes data needs to be duplicated among merged
rows or columns. While sometimes there could be
possibility for an empty row, column or a cell. Exist-
ing systems can not handle complex table structures
or empty cells, thus spoiling the final output. Also,
previous systems were extracting all tables from a
given document which is a very rare use case. But
most of the time, we are interested only in a few ta-
bles of our concern from a document.
The objective of this work is to extract only rele-
vant tables from given documents in a portable form
which could be conveniently plugged into any system
for direct usage.
2 RELATED WORK
This section provides an overview of different solu-
tions available for information extraction from docu-
ments with table.
(Milosevic et al., 2016) proposed a rule based so-
lution for extracting table data from tables in clini-
cal documents in which the data is firstly decomposed
into cell level structures depending on their complex-
ity and then information is extracted from these cell
structures. (Gatterbauer and Bohunsky, 2006) pro-
posed a solution based on spatial reasoning in which a
visual box is drawn around each of the HTML DOM
Rizvi, S., Mercier, D., Agne, S., Erkel, S., Dengel, A. and Ahmed, S.
Ontology-based Information Extraction from Technical Documents.
DOI: 10.5220/0006596604930500
In Proceedings of the 10th International Conference on Agents and Artificial Intelligence (ICAART 2018) - Volume 2, pages 493-500
ISBN: 978-989-758-275-2
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
493

element. Based on the alignment, certain visual boxes
were merged together to form a hyper box. Eventu-
ally a table is segregated from other HTML DOM el-
ements and information is extracted from this table.
(Ramakrishnan et al., 2012) presented 3 stage pro-
cess for extracting text from layout aware PDF scien-
tific articles. In which firstly, contiguous blocks of
text are detected and then classifying them in differ-
ent categories based on predefined rules. And finally
stitching blocks together in correct order.
(Ruffolo and Oro, 2008) proposed an ontology
based system, known as XONTO, for semantic infor-
mation extraction from PDF documents. This system
makes use of self-describing ontologies which help
in identifying the relevant ontology object from the
text corpus. (Chao and Fan, 2004) proposed a tech-
nique that extract layout and content information from
a PDF document. Logical components of document,
i.e. outline, style attributes and content, are identified
and extracted in XML format.
(Rosenfeld et al., 2002) proposed a system which
makes use of a learning algorithm known as struc-
tural extraction procedure. It extracts different entities
from the text based on their visual characteristics and
relative position in the document layout. (Liu et al.,
2006) also proposed an approach which is used to ex-
tract meta-data, i.e. rown and column number, infor-
mation from digital documents which could further be
used to understand semantics of the textual content.
(Pinto et al., 2003) proposed the use of conditional
random fields (CRFs) for the task of table extraction
from plain-text government statistical reports. CRFs
support the use of many rich and overlapping layout
& language features. Later on tables were located
and classified into 12 table related categories. This
paper also discussed future extension of this work
for segmentation of columns, finding cells and clas-
sifying them as data cells. (Tengli et al., 2004) pro-
posed a technique that exploits format cues in semi-
structured HTML tables. Then it learns lexical vari-
ants from training samples and matches labels using
vector space. This approach was evaluated by apply-
ing it to 157 university websites.
(Peng and McCallum, 2006) proposed an ap-
proach, based on CRFs for constraint co-reference in-
formation. In this approach, several local features,
external lexicon features and global layout features.
(Chang et al., 2006) performed a survey of approaches
for information extraction from web pages. The
comparison between different systems was performed
based on three factors. Firstly, the extent to which a
system failed to handle any web page. Secondly, the
quality of technique used. Thirdly, degree of automa-
tion
(Freitag, 1998) observed the task of information
extraction from the perspective of machine learning.
The proposed approach suggested the implementation
of a relational learner for information extraction task.
Where extensible token oriented feature set, consist-
ing of structural and other information, is provided as
input to the system. Based on the input, system learns
extraction rules for given specific domain. (Rahman
et al., 2001) proposed a solution for automatically
summarizing content from web pages. In this ap-
proach, structural analysis of the document is per-
formed followed by decomposition of the document
based on extracted structure. Then document is fur-
ther divided into sub-documents based on contextual
analysis. Finally the labeling of a each sub-document
is performed.
(Wei et al., 2006) proposed an approach to extract
answers from the tables in a document. In which a
cell document is created where each table cell has its
title or header as metadata. A model was designed
for retrieval which ranks the cells using a given lan-
guage model. This approach was applied to Govern-
ment statistical websites and news articles. (Adelfio
and Samet, 2013) proposed an approach which makes
use of CRFs in combination with logarithmic bin-
ning specially designed for table extraction task. This
approach was proposed for the extraction of a table
along with its structural information in the form of
schema. This solution could work on web tables as
well as tables in spreadsheets. At the end schema
also included its characteristics information like row
grouping etc.
3 PROPOSED APPROACH
Figure 1 shows the workflow overview of proposed
system. The presented system has three major phases
i.e. Preprocessing, Ontological information extrac-
tion and Reliability assessment. Preprocessing phase
involves converting PDF document into HTML doc-
ument. Ontological information extraction involves
table extraction, relevancy assessment, preparing ex-
tracted data in memory and exporting into CSV for-
mat. The system is generic and can be applied to doc-
uments from any domain.
An ontology consists of entities, relationships and
instances. Figure 2 shows an example ontology,
where there are different entities i.e. Document, Rel-
evant Information, Irrelevant Information, Relevant
Terms, Warning Terms, Region and Trade. It can be
observed that there are some child entities and they
have a ”is a relationship” from child to parent entity
.i.e. Region is a Relevant Term. While the entities at
ICAART 2018 - 10th International Conference on Agents and Artificial Intelligence
494
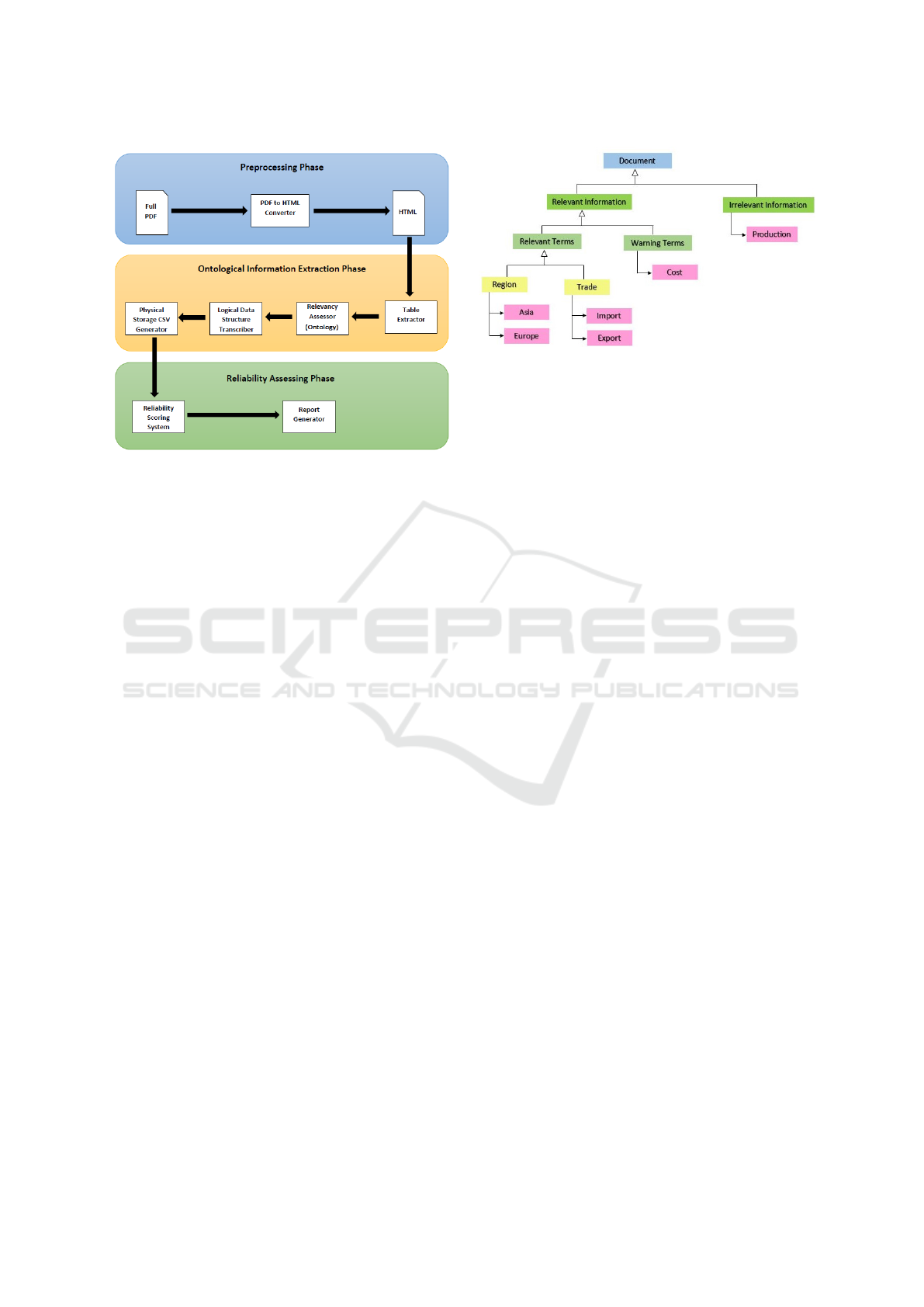
Figure 1: Overview of the workflow of the proposed system.
the bottom have instances like Asia, Europe, Import,
Export, Cost, Production etc.
In the given example, the main entity is Docu-
ment, which includes two different entities Relevant
Information and Irrelevant Information. Irrelevant In-
formation consists of an instance ”Production”. It
means that within a given set of documents, this term
will always give us a hint that the part of the docu-
ment under consideration is irrelevant for us. On the
Other hand, Relevant Information further consists of
Relevant Terms and Warning Terms. Warning terms
have an instance ”Cost”. Which represents that in
some context this term may be relevant while in some
context it might be not. While Relevant Terms have
further two entities Region and Trade. Region has
two instances Asia and Europe. While Trade has two
instances Import and Export. Which represents that
these terms definitely represent the information of our
interest.
After understanding the basic components and
their relationships of the example ontology, now one
needs to understand that what does the ontology in
Figure 2 represents. The given example ontology is
designed to target statistics in a document related to
trade in different regions of the world. There could
be some additional rules based on the use case. i.e.
Coexistence of multiple entities or exclusive presence
of entities define the relevancy of a piece of informa-
tion in complex use cases. For our system, all the
rules provided along with the ontology and ontology
itself were used to define heuristics based on which
we inspected the relevancy of the information under
consideration.
Figure 2: Illustrated example of an ontology.
3.1 Preprocessing Phase
In order to extract information stored in a layout, doc-
ument needs to be converted into some other interme-
diary format which can sustain not only text but also
the layout in which the text is stored. Layout plays a
vital role in building sense about the text stored in the
layout. Information stored in a layout connects differ-
ent bits of information together to form a context.
Conversion of PDF to an intermediary format con-
sists of two crucial steps, Selection of suitable inter-
mediary file format and Conversion from PDF to se-
lected file format.
Selection of suitable intermediary file format is a
quite challenging task. There is a wide range of po-
tential formats which can keep text along with layout
information attached to it.
Most common file formats are XML, Docx,
HTML etc. XML keeps the information stored in a
structured and convenient way. But it can not keep
layout information. Docx is another potential file for-
mat which can keep both textual and layout informa-
tion. There are a bunch of libraries around for Docx
parsing but none of them is reliable libraries to parse
Docx file properly. Specially when it comes to com-
plicated tables, those libraries are not so robust and
reliable. Lastly, HTML is the file format which not
only sustains layout and textual information but is
also relatively simple to generate and parse. Addi-
tional advantage of selecting HTML format is that,
the problems during file format conversion can be
quickly identified by visual inspection of HTML in
a web browser. For this use case using HTML, due to
having most advantages, looks like the most dominant
choice for intermediary file format.
On the other hand, quality of generated HTML
depends on the tool used for conversion of PDF to
HTML. Every tool has its own formatting of resultant
HTML as they put the extracted content from PDF
into their own customized structures and layouts.
Ontology-based Information Extraction from Technical Documents
495

Using a different tool for PDF to HTML conver-
sion, refers to different HTML parser to be used for
extraction of text from HTML. The tool used for PDF
to HTML conversion in this use case is Adobe Acro-
bat. Preliminary experimentation proved that Adobe
Acrobat is the most reliable choice for format conver-
sion task, as Adobe has almost 23 years of experience
in document analysis domain. Also it is very mature
product from Adobe, which evolved over years of ex-
perience and development. Unlike other tools or open
source libraries, Adobe can successfully convert most
of the PDF documents to HTML with almost the same
look and feel as in original PDF document. On the
other hand, other tools and open source libraries either
unable to convert some PDF documents due to encod-
ing incompatibilities or are unable to convert PDF to
HTML in the correct layout i.e. placing table data out
of table layout in resultant HTML file or unexpectedly
merging cell data from two different cells of the table
into one.
It is to be noted that the final output of the system
relies a lot on quality of conversion of PDF to HTML.
If there are any errors or mistakes occurred during this
conversion phase, then it will also be depicted in the
final extracted output. Since the system is designed to
extract data out of the document even if there are un-
expected column merges or missing table data during
conversion process. It will not effect the extraction
process but will badly effect quality of extracted data.
3.2 Ontological Information Extraction
Phase
The HTML file obtained from preprocessing serves
as input to the system. It is to be noted that complete
HTML file is fed to the system instead of feeding se-
lective part of HTML file or a subset of the file. The
objective of the system is to keep users interruption
and effort as less as possible, so that the system is au-
tomatically able to find out relevant content by itself.
3.2.1 Table Extractor
HTML file provided as input is then processed to fil-
ter out all the tables in document along with their tex-
tual contents. In order to extract tables, HTML file
is carefully parsed and filtered all tables from the file.
HTML tags play an important role in identifying ta-
bles in an HTML file. It is to be noted that the tables
extracted at this stage are in a raw form. i.e. the data
from merged rows or columns only exists just once
for all rows or columns sharing that data. The filtered
tables are then pruned to keep only those which are
relevant to users needs.
3.2.2 Relevancy Assessor
Defining relevancy is sometimes a too subjective task
and can vary from one person to another. Thus in
order to find out a relevant table, we need to recog-
nize each column title as an entity which is in ac-
cordance with the provided ontology. Relevance is
decided based on rules and relationships defined, be-
tween different entities, in the ontology. In this stage,
ontology is used to define heuristics upon which the
table filtering is performed. The tables which adhere
to the provided ontology are kept while leaving the
others.
Figure 3: Sample output report of the system.
3.2.3 Logical Data Structure Transcriber
Pruned tables based on defined relevancy are then
stored in logical structures. It is not as simple as it
seems, as tables can have a bunch of cases for merged
rows and/or columns. In tables, merged rows or
columns means that the piece of data is shared among
those merged rows or columns respectively. And
sometimes multiple cases can occur simultaneously
i.e. A table cell can have merged rows and columns
at the same time. In order to overcome all such prob-
lems, data from the shared rows or columns needs to
be duplicated very carefully among the merged rows
or columns respectively.
3.2.4 Physical Storage CSV Extractor
Finally, data from logical structure is stored in some
physical storage i.e. Comma separated values (CSV
file). The data stored in CSV file is stored in a way
that it can be used anywhere, by any text file read-
ing system, without any issue. CSV is quite flexible
file format which can be customized to any system
requirements.
ICAART 2018 - 10th International Conference on Agents and Artificial Intelligence
496

3.3 Reliability Assessing Phase
Once a system generates output, one is curious to find
out that how well the system performed to achieve the
given task. The only way to find out is to validate the
quality of the output by comparing it to the desired re-
sult for a specific input. Depending upon the subjec-
tivity of task and system, there are different measures
which can evaluate output of the system: Confidence
scoring, Precision, Recall, F-Measure & Accuracy.
3.3.1 Reliability Scoring System
The system generates a separate output CSV file for
each table. Thus every output file will be assessed
separately and each will be given a separate score
computed using defined rules.
The quality of the output plays a key role in defin-
ing the rules for confidence scoring of the output. For
that purpose, we defined three lists of terms based
on ontology 1) Relevant Terms 2) Irrelevant Terms 3)
Warning Terms. Relevant terms are those which are
related to our topic of interest. Irrelevant terms, as
their names suggest, are those which are not related
in any manner to our topic of interest. Lastly, Warn-
ing terms are those which might be relevant in some
context while irrelevant in any other context. Every
output table starts with an initial confidence score of
100 at the time of extraction. Later on, the compliance
of those tables is checked by the heuristics defined on
provided ontology. The confidence score decreases if
the titles of the table are not in accordance with rele-
vant terms in our ontology, then the confidence score
decreases. Also, if a warning term is spotted, the con-
fidence score decreases to 0.5. Each table is assessed
by using these rules and remaining final score at the
end represents the extent to which system find that
specific table to be relevant.
3.3.2 Report Generator
After computing confidence score for each table, the
system reports these statistics to the user. In addition
to individual confidence score for each table, system
also reports the reason why the score for a particular
table is less than 100. Report file consists of 4 data
columns i.e. Status, Filename, Confidence Score and
Reason. An example of a sample report file is shown
in Figure 3.
In the above example, ”warning term” refers to
such column titles which have different meanings
based on context. Thus it makes the relevancy a bit
doubtful. The reasoning along with confidence scor-
ing is self explanatory for the user to understand the
reason for that specific score. If the confidence score
is reported as 100.0, then the user can directly use that
specific file without any doubt. In case of low confi-
dence score for a certain file, user will have to look
explicitly into the area of the output file reported in
the reason section of the report.
4 EVALUATION
This section discusses dataset details and the results
obtained from different experiments performed on the
data set. Evaluation of results provide an insight into
the strength and robustness of the system.
4.1 Dataset
The dataset consists of 76 documents from 20 differ-
ent manufactures of industrial boilers. All documents
were full text PDF documents. All the documents
were randomly divided into Train and Test sets.
Complexity Levels
Due to huge variations in the document layout and ta-
ble complexity, all documents were divided into three
different difficulty levels based on complexity of their
table layouts.
Complexity level 1 is the simplest of all levels as
it contains all simple tables, where there is no merged
row or column and they have very clear structure. An
example of document containing such table is shown
in Figure 4a. In training set, 4 documents were desig-
nated as level 1 documents. While in test set, 8 docu-
ments were allocated to Complexity level 1.
Complexity level 2 is a bit more complex level
as compared to Complexity level 1. As it contains
cases for merged rows or columns. More specifically,
documents in level 2 have either one merged row or
column at a time. An example of document contain-
ing merged rows and merged columns is shown in the
Figure 4b. In training set, 3 documents were desig-
nated as level 2 documents. While in test set, 13 doc-
uments were allocated to Complexity level 2.
Complexity level 3 is the most complicated level,
as it contains more complex cases of merged rows and
columns. The documents in this level has either both
merged rows and column cases at a time or multi-
ple cases of merged rows or columns, which makes
it more complicated and tricky as compared to previ-
ous levels. An example of document containing such
table is shown in Figure 4c. In training set, 3 docu-
ments were designated as level 3 documents. While
in test set, 7 documents were alloted to Complexity
level 3.
Ontology-based Information Extraction from Technical Documents
497

(a) Table Complexity Level 1 (b) Table Complexity Level 2 (c) Table Complexity Level 3
Figure 4: Documents with different complexity level tables.
(a) Output from our system (b) Output from Adobe Acrobat Pro (c) Output from Tabula
Figure 5: Comparison with outputs from different tools.
4.1.1 Training Set
Training set consisted of total 10 documents dis-
tributed into 3 complexity levels. Training set along
with ontology was used to define heuristics that rep-
resent the relevance. Table 1 shows training set distri-
bution statistics.
Table 1: Training set Distribution.
Levels Total no. of Tables Relevant Tables
Level 1 195 19
Level 2 164 14
Level 3 97 25
Overall 456 58
4.1.2 Validation Set
Validation set consisted of total 38 documents dis-
tributed into 3 complexity levels. Validation set was
used to evaluate the significance of earlier defined
heuristics. Table 2 shows validation set distribution
statistics.
Table 2: Validation Set Distribution.
Levels Total no. of Tables Relevant Tables
Level 1 301 12
Level 2 364 43
Level 3 42 4
Overall 707 59
ICAART 2018 - 10th International Conference on Agents and Artificial Intelligence
498

4.1.3 Test Set
Testing set consisted of total 28 documents which
were also divided into 3 levels based on their layout
complexity level. Table 3 shows test set distribution
statistics.
Table 3: Test Set Distribution.
Levels Total no. of Tables Relevant Tables
Level 1 310 28
Level 2 444 47
Level 3 116 18
Overall 870 93
4.2 Results
This section not only discusses results from the devel-
oped system but also from a couple of renowned tools
around for solution of the problem stated in our use
case.
In this section we will discuss results from eval-
uation of our developed system. Table 4 shows the
results when test set was fed into our system. In Table
4, it can be observed that there exists no case where
relevant tables are missed by the developed system.
Such measure is represented by False -ve in the given
tables. It depicts robustness of the developed system
against the variation in terminologies used by differ-
ent manufacturers.
It is quite evident from the statistics that as soon as
layout complexity increases from one document level
to the other, number of issues also increases. It is to
be noted that the all results mentioned in this section
are based on documents from 20 different manufac-
turers, with a lot of variation and no generalized lay-
out format or set terminology followed in any of these
documents.
Comparison with Renowned Tools
It is to be noted that existing tools for table extrac-
tion are not directly comparable with the proposed ap-
proach. This is because, they do not provide a feature
of extracting relevant tables. Therefore, in the paper
we provide a comparison with these tools, only on ta-
ble extraction level.
For results comparison, we selected one tool with
top performance in both open source and premium
categories. Output from each system is compared
with output of proposed system while providing same
set of documents to each system.
Tabula is an open source tool freely available on-
line for all types of usage. It specializes in extracting
tables out of PDF documents. It provides two ways
of extracting tables. One by automatic detection and
other by manual selection.
Acrobat Pro is very famous product of Adobe
family. There are several ways which Adobe Acrobat
Pro provide for extracting data from PDF document.
Acrobat extracts tables by exporting complete docu-
ment in the form of an excel sheet. In this way all the
content and tabular data will be exported to an excel
sheet.
Comparison with other Tools
This section discusses the comparison of the system
output with different state-of-the-art tools to witness
the effectiveness of the output generated by our sys-
tem.
Figure 5 shows the sample output from each of
the systems, provided that a sample document con-
taining a table with merged rows was fed to each of
the systems respectively. Figure 5a shows the output
of our system. It can be seen that all row and column
data is extracted with absolute precision where there
are crisp boundaries between all rows and columns.
Additionally, the data in merged rows is duplicated
carefully to the respective row cells. Figure 5b shows
the output from Adobe Acrobat Pro. It can be seen
that merged rows were not been detected correctly.
But also the merged rows were considered as separate
rows thus leaving the cells empty for the later row and
resulting the gaps in the tabular data. Figure 5c shows
the output from Tabula. It can be seen that neither the
merged rows were detected correctly, nor the data in
each row cell was considered as a single block. Each
line was considered as a separate row thus leaving a
lot of table cells empty because of misinterpretation
of rows, columns and their respective cells.
From such performance of state-of-the-art tools, it
can be inferred that it is indeed not so simple task to
extract information from complex merged rows and
columns. The proposed system overcame this prob-
lem and made it possible to extract quality wise reli-
able data from the tables.
5 CONCLUSION
This paper presents ontology based method for infor-
mation extraction from technical documents. It serves
as a tool for relevant table extraction from a PDF doc-
ument. Relevancy is defined in the form of an on-
tology in the system. When this ontology is incor-
Ontology-based Information Extraction from Technical Documents
499

Table 4: Test Set Evaluation Results.
Levels True +ve False +ve True -ve False -ve Precision Recall F-Measure
Level 1 28 0 282 0 1 1 1
Level 2 53 6 385 0 0.89 1 0.94
Level 3 26 8 82 0 0.76 1 0.86
Overall 107 14 749 0 0.88 1 0.93
porated with the system, it enables the system to be
generic enough to use it for documents from any other
domain. The presented system is totally autonomous
and can process the documents without any human
feedback. The presented system is able to produce
output efficiently irrespective of the size of document.
It is also very robust as it can process documents from
a bunch of different brands with no standardization of
terminologies or layouts. Reliability of output is rep-
resented in the report generated along the output files,
where each table has separate confidence score with
reasoning.
The presented system is implemented in such a
way that it does not adhere to any specific use case,
but can also work for any other domain documents
with relevant data tables extraction problem. The pre-
sented system could be tested on any other domain
documents by simply replacing the current ontology
with the desired domain ontology.
REFERENCES
Adelfio, M. D. and Samet, H. (2013). Schema extraction
for tabular data on the web. Proc. VLDB Endow.,
6(6):421–432.
Chang, C.-H., Kayed, M., Girgis, M. R., and Shaalan,
K. F. (2006). A survey of web information extrac-
tion systems. IEEE Trans. on Knowl. and Data Eng.,
18(10):1411–1428.
Chao, H. and Fan, J. (2004). Layout and Content Extraction
for PDF Documents, pages 213–224. Springer Berlin
Heidelberg, Berlin, Heidelberg.
Freitag, D. (1998). Information Extraction from HTML:
Application of a General Machine Learning Ap-
proach. In AAAI/IAAI, pages 517–523.
Gatterbauer, W. and Bohunsky, P. (2006). Table extrac-
tion using spatial reasoning on the css2 visual box
model. In Proceedings of the 21st National Confer-
ence on Artificial Intelligence - Volume 2, AAAI’06,
pages 1313–1318. AAAI Press.
Liu, Y., Mitra, P., Giles, C. L., and Bai, K. (2006). Auto-
matic extraction of table metadata from digital docu-
ments. In Proceedings of the 6th ACM/IEEE-CS Joint
Conference on Digital Libraries, JCDL ’06, pages
339–340, New York, NY, USA. ACM.
Milosevic, N., Gregson, C., Hernandez, R., and Nenadic,
G. (2016). Extracting patient data from tables in clini-
cal literature - case study on extraction of bmi, weight
and number of patients. In Proceedings of the 9th
International Joint Conference on Biomedical Engi-
neering Systems and Technologies (BIOSTEC 2016),
pages 223–228.
Peng, F. and McCallum, A. (2006). Information extraction
from research papers using conditional random fields.
Inf. Process. Manage., 42(4):963–979.
Pinto, D., McCallum, A., Wei, X., and Croft, W. B. (2003).
Table extraction using conditional random fields. In
Proceedings of the 26th Annual International ACM SI-
GIR Conference on Research and Development in In-
formaion Retrieval, SIGIR ’03, pages 235–242, New
York, NY, USA. ACM.
Rahman, A. F. R., Alam, H., and Hartono, R. (2001). Con-
tent extraction from html documents. In Int. Workshop
on Web Document Analysis (WDA), pages 7–10.
Ramakrishnan, C., Patnia, A., Hovy, E., and Burns, G. A.
(2012). Layout-aware text extraction from full-text
pdf of scientific articles. Source Code for Biology and
Medicine, 7(1):7.
Rosenfeld, B., Feldman, R., and Aumann, Y. (2002). Struc-
tural extraction from visual layout of documents. In
Proceedings of the Eleventh International Conference
on Information and Knowledge Management, CIKM
’02, pages 203–210, New York, NY, USA. ACM.
Ruffolo, M. and Oro, E. (2008). Xonto: An ontology-based
system for semantic information extraction from pdf
documents. 2008 20th IEEE International Conference
on Tools with Artificial Intelligence (ICTAI), 01:118–
125.
Tengli, A., Yang, Y., and Ma, N. L. (2004). Learning table
extraction from examples. In Proceedings of the 20th
International Conference on Computational Linguis-
tics, COLING ’04, Stroudsburg, PA, USA. Associa-
tion for Computational Linguistics.
Wei, X., Croft, B., and Mccallum, A. (2006). Table extrac-
tion for answer retrieval. Inf. Retr., 9(5):589–611.
ICAART 2018 - 10th International Conference on Agents and Artificial Intelligence
500
