
A Q-learning-based Scheduler
Technique for LTE and LTE-Advanced Network
Souhir Feki
1
, Faouzi Zarai
1
and Aymen Belghith
2
1
NTS'COM Research Unit, National School of Electronics and Telecommunications of Sfax, Tunisia
2
Saudi Electronic University (SEU), Computer Science Department, Saudi Arabia
Keywords: LTE-Advanced, Scheduling Algorithm, Q-Learning, QoS, Fairness.
Abstract: Long Term Evolution Advanced (LTE-A) is a mobile communication standard used for transmitting data in
cellular networks. It inherits all principal technologies of LTE such as flexible bandwidth, Orthogonal
Frequency Division Multiplexing Access (OFDMA) and provides new functionalities to enhance the
performance and capacity. For some time, LTE-A must co-exist with the 2G and 3G cellular networks, so
resource management, potential interference, interworking necessities, etc. are an important issues. The
Radio Resource Management (RRM) main function is to ensure the efficient use of available radio
resources, making use of the available adaptation techniques, and to serve users depending on their Quality
of Service (QoS) parameters. In this paper, we propose a novel dynamic Q-learning based Scheduling
Algorithm (QLSA) for downlink transmission in LTE and LTE-A cellular network based on the Q-learning
algorithm and adaptable to variations in channel conditions. The main objective of the proposed algorithm is
to make a good trade-off between fairness and throughput and to provide Quality of Service (QoS)
guarantee to Guaranteed Bit Rate (GBR) services. Performances of QLSA are compared with existing
scheduling algorithms and simulation results show that the proposed QLSA provides the best trade-off
fairness/throughput.
1 INTRODUCTION
LTE-Advanced is the evolved version of LTE that
improves network performance and service quality
through efficient deployment of new technologies
and techniques. It uses new functionalities over the
existing LTE cellular systems to offer higher
throughputs and better user experience (Flore,
2015).
For a better management of radio resources in
LTE-A and to guarantee a better level of QoS for
users, Radio Resources Management (RRM) plays a
crucial role in attaining the objective. One of the
RRM functions is the packet scheduling which has a
key role in the network performance as it is
responsible for assigning resources between users
while considering QoS requirements (Alam, 2015).
The main problem with scheduling in LTE-A is
that there is no firm provision included by 3GPP to
manage scheduling process, which make it an open
subject for researchers.
Several scheduling techniques have been
proposed in the literature where the efficient
exploitation of radio resources is fundamental to
reach the system performance targets and to
guarantee the Quality of Service requirements (ITU,
2008).
In this context, we propose a novel scheduling
algorithm for downlink transmission in LTE and
LTE-A cellular network based on the Q-learning
algorithm (Kaelbing, 1996), flexible to system
requirements when different trade-off levels of
fairness and throughput are required, and adaptable
to variations in channel conditions.
The main objective of the proposed algorithm is
to make a good trade-off between fairness and
throughput. The performance of the new scheduler is
evaluated and compared to the Proportional Fair,
Maximum Signal-to-Noise Ratio and Round Robin
schedulers.
This paper is organized as follows. Section II of
the paper describes the LTE-A downlink scheduling
and provides a survey on scheduling algorithms in
LTE and LTE-A. Section III describes the concept
of Q-learning. Section IV describes the proposed
scheduling algorithm. Section V presents the
Feki, S., Zarai, F. and Belghith, A.
A Q-learning-based Scheduler Technique for LTE and LTE-Advanced Network.
DOI: 10.5220/0006425200270035
In Proceedings of the 14th International Joint Conference on e-Business and Telecommunications (ICETE 2017) - Volume 6: WINSYS, pages 27-35
ISBN: 978-989-758-261-5
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
27

simulation results and performance analysis. Finally
section VI concludes this paper.
2 RELATED WORK
The multi-user scheduling is one of the major
features in LTE-A networks since it is in charge of
satisfying QoS of users, generally scheduling
algorithms aim to reach maximum throughput while
maintaining a certain degree of fairness.
In LTE-A, Resource Block (RB) is the smallest
allocated resource unit with a 180 KHZ size in
frequency domain, and divided into two slots in time
domain, the length of each slot is 0.5 ms. Scheduling
decision is made by the eNodeB at each 1ms which
represents the length of Transmission Time Interval
(TTI) (Piro, 2011).
Multi-users diversity is managed in both
frequency and time domains, physical resources are
allocated to users in the frequency/time grid over
time. Subcarriers are not individually allocated due
to signaling restrictions and so they should be
aggregated on a RB-basis.
The Medium Access Control (MAC) layer of the
eNodeB is the module responsible for scheduling the
different users. At every TTI, the eNodeB assigns
RBs based on the channel condition feedback
received from active users in the form of Channel
Quality Indicator (CQI), designating the data rate
supported by the downlink channel.
(Hajjawi, 2016) proposed a novel scheduling
algorithm based on Packet Drop Rate (PDR) and
cooperative game theory mechanisms (Shaply
algorithm) (Niyato, 2006) for LTE-A Networks. A
two level scheduling scheme is proposed, in first
level packets are classified into classes by scheduler
according to the PDR and available resources are
allocated based on this metric. In the second level,
the proposed algorithm forms a combination
between classes using the cooperative game theory;
available resources are allocated to users in each
class based on Shaply algorithm to assure the lowest
requirements for high priority traffic while giving a
chance for low priority traffic to be served. During
the simulation, the algorithm which compared with
Exponential-rule (EXP-rule) and Proportional
Fairness (PF) algorithms outperforms the two
algorithms in terms of throughput, fairness index
and delay.
(Chaudhuri, 2016) proposed a novel Multi
Objective based Carrier Aggregation scheduling
algorithm for LTE-A network. The algorithm’s main
purpose is to achieve optimal user QoS and better
level of fairness by allocating efficiently the required
transmission power to the component carriers
according to user QoS request. To achieve this
purpose, the proposed algorithm defines two
objective functions; maximize cell throughput for all
users every one milli-second and minimize the
power allocation, and tries to solve this optimization
problem using the min-max principle (Gennert,
1988). Simulation results reveal that the proposed
algorithm gives a lowest cell throughput gain of two
times compared with Round Robin (RR), SJS-PF
(Fu, 2013), Cross-CC User Migration (CUM) (Miao,
2014), Efficient Packet Scheduling (EPS) (Chung,
2011), also it achieves best PRB utilization and
scheduling energy efficiency compared to EPS and
RR.
(AbdelHamid, 2015) studied the scheduling
problem in LTE Virtual Networks and proposes a
Virtual Prioritized Slice (VPS) approach to improve
scheduling of resources for Real Time (RT) and Non
Real Time (NRT) traffic in LTE Virtual Networks.
The algorithm target is to facilitate varied traffic in
virtualized LTE networks. It considers two
challenges: the first one is ensuring isolation
between service providers while serving real time
requests as real time traffic is delay sensitive, the
second challenge is time varying channel conditions.
A two level scheduling scheme is proposed, in first
level packets are classified by scheduler according to
the type of traffic by creating a virtual prioritized
slice which is forwarded to the VPS scheduler to
serve all RT requests foremost, then after the RT
traffic is scheduled, the NRT traffic is served using
proportional fairness scheduling. During the
simulation, the algorithm which compared with NVS
(Kokku, 2010) and NetShare (Mahindra, 2013)
reduces the blocking of real time flows and
improves the throughput of non real time flows.
However some limitations can be identified for this
approach; when the number of real time requests
increase, the average throughput of non real time
requests decrease since these requests cannot be
served only after the total real time requests are all
served. In addition allocating a fixed number of RBs
for all real time requests (2 RBs) may be insufficient
for some real time services, i.e., HD voice and
video, and a waste for other services. However,
increasing the number of RBs per real time request
will affect the total throughput and makes starvation
to the non real time flows.
(Bahreyni, 2014) proposed a new scheduling
algorithm for LTE networks that supports channel
fast variations and aimed to increase the system
capacity while keeping the fairness when the number
WINSYS 2017 - 14th International Conference on Wireless Networks and Mobile Systems
28

of active users is greater than the number of existing
RBs. This algorithm improved cell edge users’
performance by according preferences to users who
have less bandwidth. During the simulation, the
algorithm compared with, Round Robin, Best CQI
and Proportional Fair. The results show good level
of fairness with of little decrease in the user's
throughput and in total system throughput, this
indicates that this algorithm is dedicated to assure
good level of fairness among users even if we will
attain the minimum level of QoS.
(Escheikh, 2014) proposed a new channel-aware
scheduling algorithm for downlink LTE system. In
order to offer a good trade-off allowing maximizing
average throughput while keeping fairness between
active users, the algorithm uses a weighting factor in
the scheduling metric, accounting for each active
user the number of assigned RBs in the previous
resource allocations until the instant time (t−1). A
three level scheduling scheme is cited, in first level
the algorithm supposes that each eNodeB receives
the channel feedback information, and then it
calculates for each active user the assigned number
of RBs over a time interval until (t−1). These two
parameters are used to calculate the elements of a
matrix M and calculate each time the maximum
metric between those of the matrix M, and based on
this metric, the algorithm assigns RBs to users. The
algorithm is compared to best CQI, Round Robin
and MY_SCH_Not_Fair (Talevski, 2012)
algorithms, the results show that the algorithm offer
better performance and considerable enhancement
compared with the other scheduling algorithms.
In dynamic environment, such as wireless
network, we cannot predict the system next
situation, it will be more efficient to predict the
appropriate scheduling rule when no such previous
knowledge about users next requirements and
channels conditions is available.
Our Q-learning based algorithm purpose is to
achieve an optimal use of radio resources with a
satisfied level of fairness even in a very dynamic
system, by taking into consideration the state of the
transmission channel and trying to best adapt to the
propagation conditions.
3 Q-LEARNING
Our scheduling algorithm deploys reinforcement
learning by applying the concept of Q-learning
(Kaelbing, 1996) in both users scheduling and
resources allocation phases. In this section, we give
the detailed description of this concept.
3.1 Reinforcement Learning
Reinforcement learning is the problem faced by an
agent that must learn behaviour through trial and
error interactions with a dynamic environment
(Kaelbing, 1996). This type of learning can guide
agents based on a function of reward/penalty. The
agent interacts with its environment by realizing
actions and receives in exchange rewards or
penalties. The reinforcement learning can be
compared to learning by trial and error, in the sense
that it allows the agent to learn by interacting with
its environment, without having prior knowledge of
it, only rewards or penalties will be provided.
3.2 The Concept of Q-Learning
Q-learning is used for dynamic environments. It is
one of the best known algorithms for reinforcement
learning framework. Its main idea is to reinforce
good behaviour and weaken the bad behaviour of an
agent by executing its reinforcement function which
specifies the estimated instantaneous reward as a
function of the actual state and action.
Q-learning is based on the function Q, which
applies to an action in a given state: Q (state, action).
()
t
tttt
asQasQ
δ
α
×+← ),(,
(1)
()()
ttt
a
tt
asQasQr ,,max
11
−+=
++
γ
δ
(2)
Where:
Q (s, a): function of evaluation actions.
δ
t
: temporal difference error.
α: learning rate, 0 ≤ α ≤ 1. It is used to rate the
certitude of values previously estimated.
r
t+1
: immediate reward received from the
environment.
γ: the weight affected to future rewards relative to
immediate rewards, it is between 0 and 1. If γ = 0,
only the immediate reward will be considered.
The Q-learning algorithm is as follows:
• Initialize all couples Q(state, action) to an
initial value.
• Execute the action a for each state e.
• Obtain the corresponding reward/penalty r.
• Refresh the value of Q using the equation of
incremental update defined previously
(equation (1)).
A Q-learning-based Scheduler Technique for LTE and LTE-Advanced Network
29
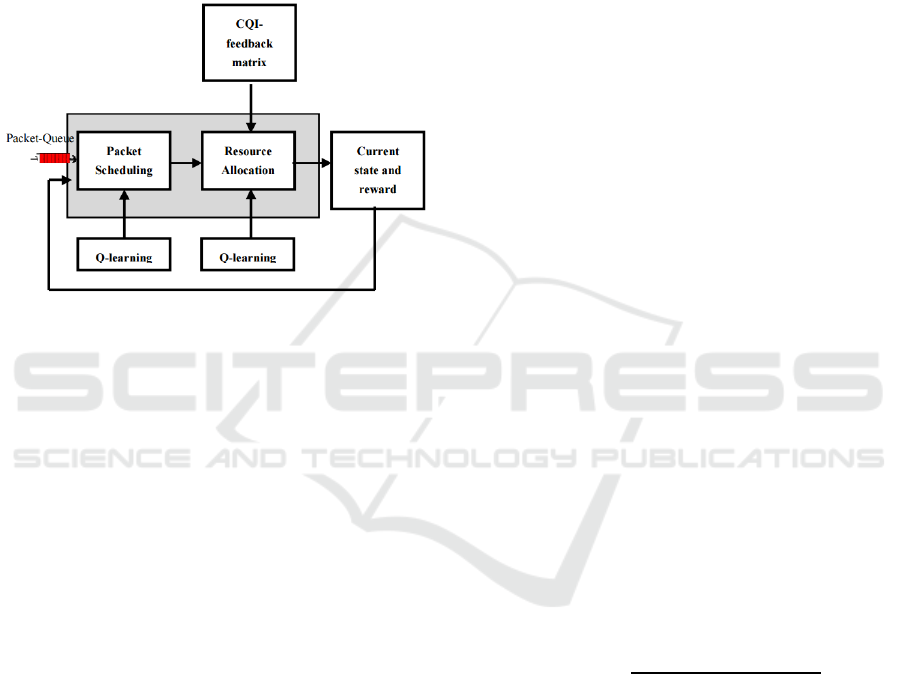
4 THE NOVEL Q-LEARNING-
BASED SCHEDULER
TECHNIQUE ARCHITECTURE
In QLSA our objective is to achieve the best trade-
off for user's throughput and fairness, so we chose to
give priority to users according to both channel
condition and fairness rate.
Figure 1: LTE/LTE-A Packet Scheduler Framework.
The current state returns the result of executing
the previous scheduling rule in the previous TTI.
The immediate reward value gives an objective
evaluation about how successful the previous action.
By using the Q-learning, the present action is
determined based on the last action-state pair, the
current state and immediate reward.
4.1 Packet Scheduling
Our QLSA aims to reach a good relationship
throughput/fairness and to provide QoS guarantee to
Guaranteed Bit Rate (GBR) services while being
suited to the Non Guaranteed Bit Rate (Non-GBR)
services.
The technique gives priority to users who will
have the best trade-off throughput and fairness in the
next TTI. Its principle is to calculate the weighted
value of this trade-off for each active user in the
network using the reinforcement function of Q-
learning.
(
)
=
(
−1
)
+(
(
)
−
(
−1
)
)
(3)
Where:
Q
k
(t): the weighted trade-off of the k
th
user at time
(t).
Q
k
(t-1): the previous weighted trade-off of the k
th
user.
r
k
(t): immediate reward of the environment to the k
th
user at time (t).
α: learning rate, with 0 ≤ α ≤ 1. More α is greater,
more the new reinforcement value will have
influence (the current state of the channel will have
influence).
To guarantee higher QoS for real time
applications, we fortify the current state of the
channel by using α>0.5 for GBR traffic, thus
channel conditions of GBR users at time t will have
more influence, as we consider:
>0.5
<0.5
−
The term γ describing the future reward is
ignored, we consider only the immediate reward
because the reward is mainly determined by the
current state of the environment (for γ = 0).
The immediate reward policy is based on the
definition of a user fairness index (UFI) to evaluate
how close the user’s transmission throughput is from
its throughput requirement (Rodrigo, 2014), and the
normalized user throughput (N_TH) which defines
the fairness criteria. These two metrics are based on
throughput and calculated for each user in the cell.
UFI
k
(t) is the ratio between the real achieved
throughput and the maximum required throughput
for the k
th
user at time (t). The instantaneous UFI is
defined as:
() =
()/
()
(4)
Where T
k
(t) is the real achieved throughput and
(
)
is the throughput requirement of user k at
time (t).
_
() =
()
_
ℎℎ
()
(5)
Where N_TH
k
(t) is the normalized throughput
defined as the ratio between the real achieved
throughput and the fair throughput of the k
th
user at
time (t).
The immediate reward of the environment is
defined as:
(
)
=ŋ∗
(
−1
)
+
(
1−ŋ
)
∗_
(− 1)
(6)
Where η is the weight that allows the setting of a
desired trade-off.
WINSYS 2017 - 14th International Conference on Wireless Networks and Mobile Systems
30

4.2 Resource Allocation
The proposed algorithm assumes that each eNodeB
receives every TTI, a channel feedback information
matrix (CQI-feedback matrix) with two dimensions
(Number Users_Equipement x Resource_Bloc Grid
Size). User's feedback R
k,n
(t) corresponds to the
predicted instantaneous achievable rate for the k
th
user at the n
th
resource block given by:
,
(
)
=
(1 + ) (7)
Where B is the total bandwidth and N is the
number of sub-carriers (Seo, 2004).
For each RB, the algorithm looks for the
maximum value of T
k,n
(t), the k
th
user's average data
rate at the n
th
resource block calculated as (Song,
2010):
,
(
)
=
(
1−
)
,
(
−1
)
+
,
(
)
(8)
We introduce the Q-learning to calculate the
weighted average data rate of active users, which
corresponds to the estimated average data rate of
user at each resource block in the next TTI. Then we
proceed to the incremental update of weighted
average data rate by applying the principle of Q-
learning.
The new predicted value is calculated by
combining the observed average data rate and the
previous values stored as shown in equation (9):
,
(
)
=
,
(
−1
)
+(
,
(
)
−
,
(
−1
)
)
(9)
Where:
Q
k,n
(t): the weighted average data rate of the k
th
user
at the n
th
resource block at time (t).
Q
k,n
(t-1): the previous weighted average data rate of
the k
th
user at the n
th
resource block.
T
k,n
(t): the immediate reward of the environment
showing the user's average data rate at time t at the
n
th
resource block.
α: learning rate, with 0 ≤ α ≤ 1.
For each resource block, the algorithm finds the
maximum value of Q
k,n
(t) and scheduler each user in
the RB where he would experience the highest
value.
This algorithm aims to increase the system's
throughput while maintaining the concept of
fairness, since it does not consider only the
instantaneous throughput and fairness, but it
considers all the previous achieved levels.
5 EVALUATION
In this section, the performance of the proposed
algorithm is evaluated and compared with traditional
scheduling algorithms, Proportional Fair, MaxSNR
and Round Robin (Sravani, 2013). The performance
parameters used for comparison are: average users
throughput, average rate of served packets, fairness,
and average queuing delay.
• Jain's fairness index: is obtained by Jain’s
equation to calculate fairness index among the
users (Jain, 1991), calculated as (equation (10)):
1,2
,…..,
=
∑
=1
2
∑
2
=1
(10)
Where x
k
is the normalized throughput for k
th
user and n is the number of users. To achieve the
highest fairness index, all users must have the same
throughput, and fairness index will be equal to 1.
• Average queuing delay: is the average waiting
time that takes for a user to get RB allocation in
a TTI. It is calculated as (equation (11)):
=
∑
∑
()
(11)
Where:
K: number of users in a network.
T: total simulation time (number of TTIs).
W
k
(t): delay of user k at time t.
5.1 Simulation Model Description
We consider a simulation model composed of a
single cell of the radius equal to 1.5 km, one
eNodeB carrier frequency of 2 GHz, a system
bandwidth of 5MHz (where 25 RBs are allocated),
and a number of users varying between 10 and 100.
The eNodeB is considered to be static, serving
video, Voice over IP (VoIP) and File Transfer
Protocol (FTP) traffic. Users have random positions
and random distribution inside the sector.
We choose a mixed data traffic in order to
simulate real traffic and demonstrate the impact of
the proposed scheduling algorithm on the QoS of
different services.
Power transmission of eNodeB and Bit Error
Rate (BER) for all users is 43 dBm. The simulation
and configuration parameters are presented in
Table 1.
A Q-learning-based Scheduler Technique for LTE and LTE-Advanced Network
31
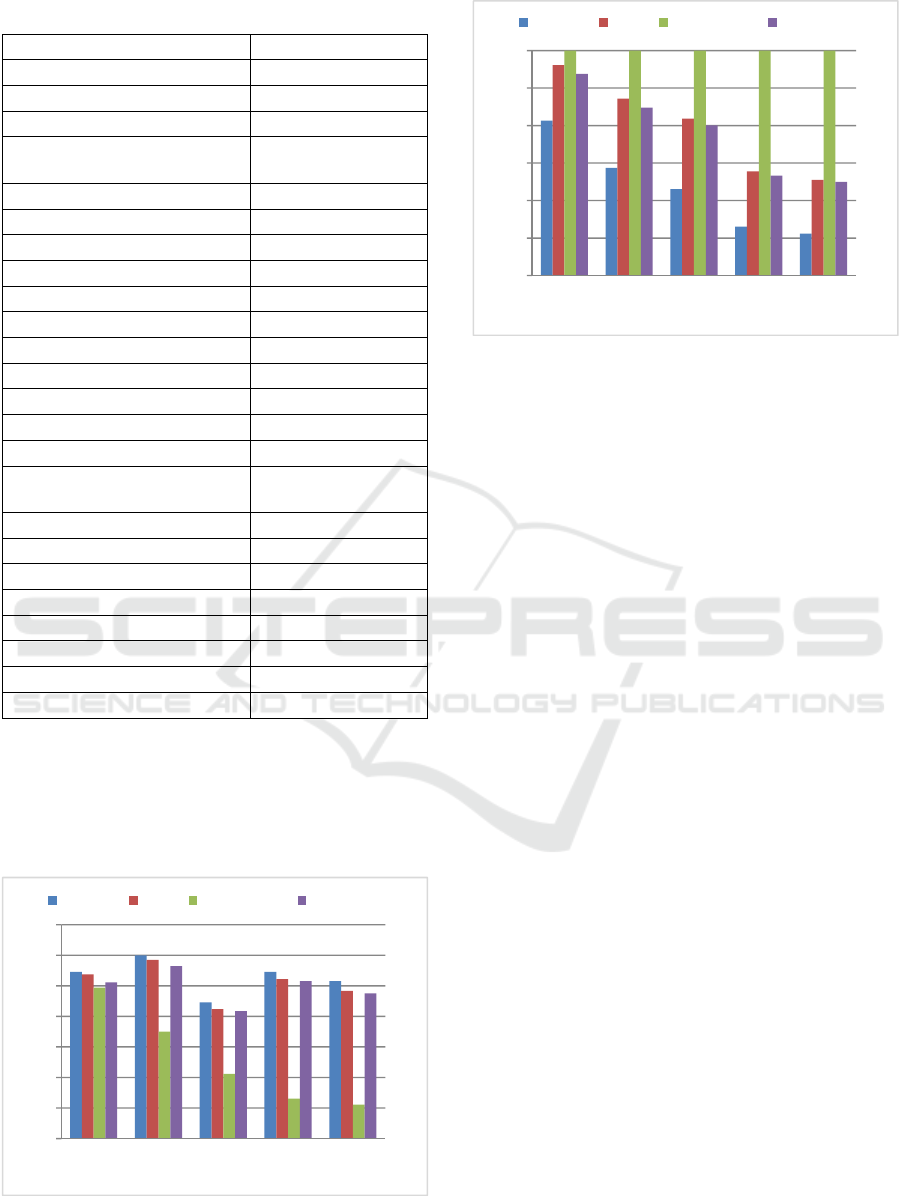
Table 1: Simulation parameters.
Parameter Value
Cell Radius 1.5 km
Cell topology Single cell
Channel type Pedestrian-B
Shadow fading standard
deviation
9 dB
Carrier frequency 2 GHz
System bandwidth 5 MHz
OFDM symbols per slot 7
Number of RBs 25 RBs
Traffic model VoIP, Video, and FTP
VoIP packet generation interval 20 ms
Video packet generation interval 100 ms
FTP packet generation interval 10 ms
VoIP delay threshold 100 ms
Video delay threshold 150 ms
FTP delay threshold 300 ms
UE speeds
between 5 and 50
(km/hr)
Number of eNodeB 1
eNodeB transmission power 43dBm
Number of UEs 10 -100
UE distribution Random
Simulation length 5000 slot
Time-slot length 1 ms
Scheduling/Allocation resource Per slot
ŋ 0.5
5.2 Simulation Results Description
Different network statuses have been chosen in order
to evaluate our new approach performance in
different scenarios.
Figure 2: Average user throughput.
Figure 3: Fairness index.
Figures 2 and 3 show the average user
throughput and the achieved fairness index as
function of the number of users in the cell. As
expected the average throughput of the system with
MaxSNR algorithm is the highest as MaxSNR
selects the users having the maximum reported SNR
value. Therefore, MaxSNR utilizes efficiently the
radio resource since it selects packets of users with
the best channel conditions. However, this algorithm
provides the worst fairness performance, since it
prevents users with low SNR from receiving packets
until the user’s channel conditions will be improved.
Contrary to the MaxSNR algorithm, the RR
algorithm provides the best fairness index and the
worst throughput. To keep balance between
throughput and fairness, the PF algorithm was
proposed. For the proposed algorithm, we show that
QLSA gives the best fairness/throughput trade-off
and outperforms PF in both congested and non-
congested network. In fact, in the QLSA algorithm,
the resources allocation process is triggered
according to the history of the channel state of all
users in the network, thus it does not depend only on
the last state of the channel in order to eliminate
discrimination between users with poor or strong
channel quality, it considers all the variation in the
channel state which brings more fairness. On the
other hand, this algorithm gives priority to users
with the best channel conditions over the time which
improves users' throughput.
0
2
4
6
8
10
12
14
10 30 50 70 100
Average throughput (Mbps)
Number of users
MaxSNR QLSA Round Robin Proportional Fair
0,4
0,5
0,6
0,7
0,8
0,9
1
10 30 50 70 100
Fairness index
Number of users
MaxSNR QLSA Round Robin Proportional Fair
WINSYS 2017 - 14th International Conference on Wireless Networks and Mobile Systems
32
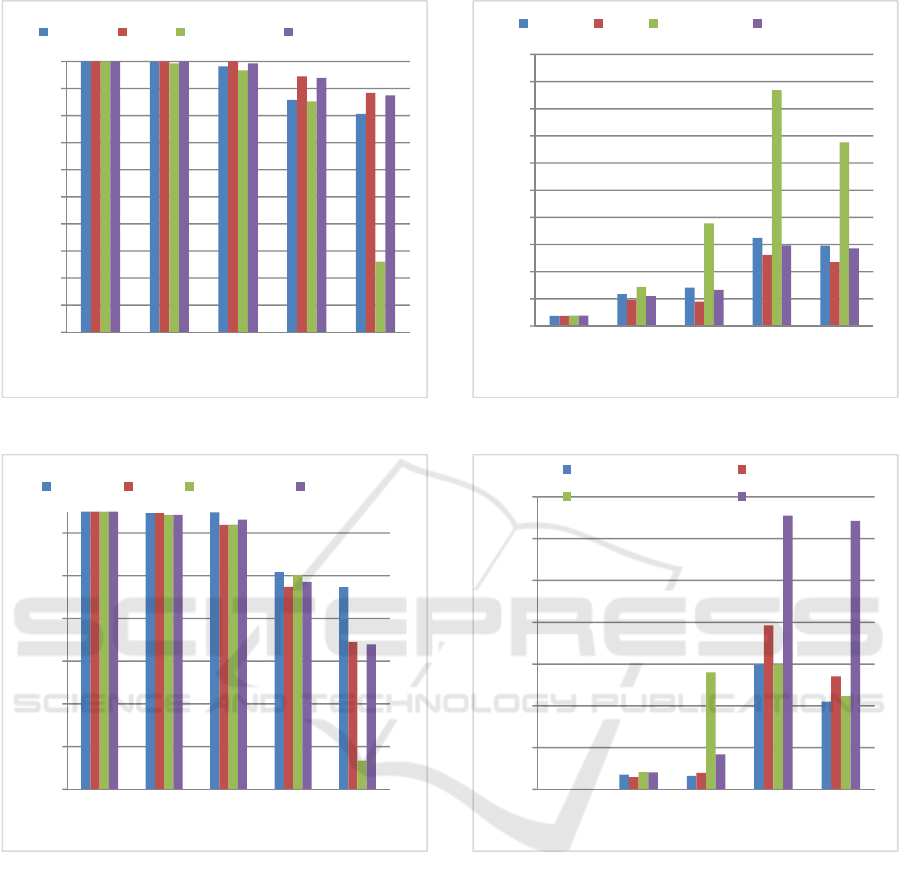
Figure 4: Average rate of served GBR packets.
Figure 5: Average rate of served Non-GBR packets.
Figures 4 and 5 show the average rate of served
GBR and non-GBR packets as a function of the
number of users, respectively. For GBR traffic,
QLSA reached the best rate since this algorithm
distinguishes between GBR and non-GBR traffic.
Recall that in QLSA current channel state has more
influence for the real time traffic, with α>0.5(for the
non-GBR traffic α<0.5). However, Figure 5 shows
that, for the Non-GBR traffic, when the number of
users increase, MaxSNR becomes more efficient and
outperforms all other algorithms, RR has the worst
result while QLSA and PF have comparative results.
Figure 6: Average queuing delay for GBR packets.
Figure 7: Average queuing delay for Non-GBR packets.
Figures 6 and 7 show the average queuing delay
for GBR and Non-GBR as a function of the total
number of users, respectively. For GBR traffic,
QLSA reached the best average delay while RR and
MaxSNR show the worst delay. For non-GBR
traffic, PF shows the highest average delay followed
by QLSA. On the one hand PF does not consider the
delay requirements and QLSA does not give priority
to non real-time services as this kind of traffic is
more QoS requirements-tolerant.
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
10 30 50 70 100
Average served GBR packets
Number of users
MaxSNR QLSA Round Robin Proportional Fair
0,35
0,45
0,55
0,65
0,75
0,85
0,95
10 30 50 70 100
Average served Non-GBR packets
Number of users
MaxSNR QLSA Round Robin Proportional Fair
0
2
4
6
8
10
12
14
16
18
20
10 30 50 70 100
Average queuing delay for GBR packets (ms)
Number of users
MaxSNR QLSA Round Robin Proportional Fair
0
5
10
15
20
25
30
35
10 30 50 70 100
Average queuing delay for Non-GBR packets
(ms)
Number of users
MaxSNR QLSA
Round Robin Proportional Fair
A Q-learning-based Scheduler Technique for LTE and LTE-Advanced Network
33

6 CONCLUSION
Maximizing throughput is a target feature of
scheduling strategies, but there are other important
problems that must be taken into consideration.
Fairness is one of these problems that may resist
throughput maximization. A trade-off between
performance and fairness when implementing
scheduling in wireless networks is found.
In this paper, we proposed a novel resource
scheduling algorithm based on the Q-learning
algorithm for LTE and LTE-A downlink. The
proposed scheduler considers two types of traffic:
Guaranteed Bit Rate and Non Guaranteed Bit Rate.
Simulation results show that the proposed QLSA
provides a good trade-off between fairness and
throughput; it outperforms other packet scheduling
algorithms with a higher rate of served packets and a
better queuing delay for GBR traffic. The use of Q-
learning makes our technique efficient and opens
new perspectives to solve different issues in LTE-A
scheduling, so it is interesting to adapt the Q-
learning neural algorithm in scheduling for the fifth
generation (5G) cellular wireless systems as future
work.
REFERENCES
Flore, D., 2015. Evolution of LTE in Release 13. [Online]
available: http://www.3gpp.org/news-events/3gpp-
news/1628-rel13.
Alam, M., Ma, M., 2015. Radio Resource Management by
Evolutionary Algorithms for 4G LTE-Advanced
Networks. In book: Bio-Inspired Computation in
Telecommunications, pp.141-163. Morgan Kaufmann,
ISBN: 9780128017432.
International Telecommunication Union (ITU), 2008.
Overall network operation, telephone service, service
operation and human factors, ITU-T Recommendation
E.800 Annex B.
Kaelbing, L., Littman, M., Moore, A., 1996.
Reinforcement learning: a survey. In Journal of
Artificial Intelligence Research, vol.4, pp: 237–285.
Piro, G., Grieco, L. A., Boggia, G., Capozzi, F., Camarda,
P., 2011. Simulating LTE cellular systems: an open-
source framework. In IEEE Transactions on Vehicular
Technology, vol. 60, no. 2, pp: 498 - 513.
Hajjawi A., Ismail M., Abdullah, N., Nordin, R., Ertuğ,
O., 2016. A PDR-Based Scheduling Scheme for LTE-
A Networks. In Journal of Communications, vol. 11,
no. 9, pp: 856-861.
Niyato, D., Hossain, E., 2006. A cooperative game
framework for bandwidth allocation in 4G
heterogeneous wireless networks. In IEEE
International Conference on Communications,
Turkey, pp: 4357-4362.
Chaudhuri, S., Baig, I., Das, D., 2016. QoS aware
Downlink Scheduler for a Carrier Aggregation LTE-
Advance Network with Efficient Carrier Power
Control. In IEEE Annual India Conference, India.
Gennert, M. A., Yuille, A. L., 1988. Determining The
Optimal Weights In Multiple Objective Function
Optimization. In Second International Conference on
Computer Vision, USA, pp: 87–89.
Weihong F., Qingliang, K., Yue, Z., Xin, Y., 2013. A
Resource Scheduling Algorithm Based on Carrier
Weight in LTE-advanced System with Carrier
Aggregation. In Wireless and Optical Communication
Conference, China, pp: 1-5.
Miao, W,. Min, G., Jiang, Y., Haozhe W, X., 2014. QoS-
aware resource allocation for LTE-A systems with
carrier aggregation. In Wireless Communications and
Networking Conference, Turkey, pp: 1403-1408.
Chung, Y. L., Jang L. J., Tsai. Z., 2011. An efficient
downlink packet scheduling algorithm in LTE-
Advanced systems with Carrier Aggregation. In
Consumer Communications and Networking
Conference, USA, pp: 632-636.
AbdelHamid, A., Krishnamurthy, P., Tipper, D., 2015.
Resource Scheduling For Heterogeneous Traffic in
LTE Virtual Networks. In IEEE Conference on Mobile
Data Management, Pittsburgh, PA, pp: 173-178.
Kokku, R., Mahindra, R., Zhang, H., Rangarajan S., 2010.
Nvs: a virtualization substrate for wimax networks. In
the sixteenth annual International Conference on
Mobile Computing and Networking, USA, pp: 233–
244.
Mahindra, R., Khojastepour, M. A., Zhang, H.,
Rangarajan, S., 2013. Radio Access Network sharing
in cellular networks. In the IEEE International
Conference on Network Protocols, Germany, pp: 1-10.
Bahreyni, M. S., Naeini, V. S., 2014. Fairness Aware
Downlink Scheduling Algorithm for LTE Networks.
In Journal of Mathematics and Computer Science, vol
11, no. 1, pp: 53-63, pp: 53-63.
Escheikh, M., Jouini, H., Barkaoui, K., 2014. Performance
analysis of a novel downlink scheduling algorithm for
LTE systems. In the international Conference on
Advanced Networking Distributed Systems and
Applications, Algeria, pp: 13-18.
Talevski, D., Gavrilovska, L., 2012. Novel Scheduling
Algorithms for LTE Downlink Transmission. In Telfor
Journal, vol. 4, no. 1, pp: 45-56.
Rodrigo, F., Cavalcanti, P., 2014. Resource Allocation and
MIMO for 4G and Beyond, Springer-Verlag, New
York. 1st edition. ISBN: 978-1-4614-8056-3.
Seo, H., Gi, L. B., 2004. A Proportional Fair Power
Allocation for Fair and Efficient Multiuser OFDM
Systems. In Global Telecommunications Conference,
USA, pp: 3737-3741.
Song, L., Shen, J., 2010. Evolved Cellular Network
Planning And Optimization For UMTS and LTE, CRC
Press. ISBN 9781439806494.
WINSYS 2017 - 14th International Conference on Wireless Networks and Mobile Systems
34

Sravani, S., Jagadeesh, B. K., 2013. Scheduling
Algorithms Implementation for LTE Downlink. In the
international Journal for Research in Applied Science
and Engineering Technology, pp: 74-80, vol. 1, No. 4.
Jain, R., 1991. The art of computer systems performance
analysis: techniques for experimental design,
measurement, simulation and modeling, John Wiley &
Sons, New York. ISBN: 978-0-471-50336-1.
A Q-learning-based Scheduler Technique for LTE and LTE-Advanced Network
35
