Linguistic Modifiers with Unbalanced Term Sets in Multi-valued Logic
Nouha Chaoued
1,2
, Amel Borgi
1
and Anne Laurent
2
1
Université de Tunis El Manar, Faculté des Sciences de Tunis,
LR11ES14 Informatique en Programmation, Algorithmique et Heuristique, 2092 Tunis, Tunisie
2
Univ. Montpellier, LIRMM, UMR 5506, F-34395, Montpellier Cedex 5, France
Keywords:
Imperfect Knowledge, Multi-valued Logic, Unbalanced Terms, Linguistic Modifiers.
Abstract:
Modeling human knowledge by machines should be as faithful as possible to reality. Therefore, it is imper-
ative to take account of inaccuracies and uncertainties in this knowledge. This problem has been dealt with
through different approaches. The most common approaches are fuzzy logic and multi-valued logic. These
two logics propose a linguistic term modeling. Generally, problems modeling qualitative aspect use linguistic
variables assessed in linguistic terms that are uniformly distributed on the scale. However, in many cases,
linguistic information needs to be defined by unbalanced term sets whose terms are not uniformly and/or not
symmetrically distributed. In the literature, it is shown that many researchers have dealt with these term sets
in the context of fuzzy logic. Thereby, in our work, we introduce a new approach to represent and treat such
term sets in the context of multi-valued logic. First, we propose an algorithm that allows representing terms
within an unbalanced set. Then, we describe a second algorithm that permits the use of linguistic modifiers
within unbalanced multi-sets.
1 INTRODUCTION
Knowledge handled by humans is often imperfect.
These imperfections may be due to ambiguity, incom-
pleteness, imprecision, uncertainty, inconsistency,
etc. Several approaches were suggested in the lit-
erature for such knowledge representation and treat-
ment. The most known are fuzzy logic (Zadeh, 1965)
and multi-valued logic (De Glas, 1989; Akdag et al.,
1992).
We notice that humans are able to perform reason-
ing without any exact measurements. They mostly
use abstract terms of natural language (young, old,
mature, etc.) and symbolic data rather than numer-
ical values or qualitative ones. Terms can also be
composed by using adverbs, such as little, more or
less and slightly. Both fuzzy logic and multi-valued
logic propose a linguistic term modeling to allow us-
ing words in reasoning process. They use linguistic
variables that take values in a set of linguistic terms
(Zadeh, 1975). These latter express the various nu-
ances of the processed information using words.
Generally in Knowledge-Based Systems, experts
use linguistic terms that are uniformly and symmetri-
cally distributed on a scale. However, in some cases,
we need to assess qualitative aspects by means of vari-
ables using linguistic term sets which are not uni-
formly distributed. For example, in the evaluation
process, we often consider a single negative term, e.g.
Fail, and many positive terms such as Medium, Good,
Excellent, etc. The gap between these terms is un-
equal.
In this paper, we focus on multi-valued logic. It al-
lows to symbolically represent imprecise knowledge
using ordered adverbial expressions of natural lan-
guage (De Glas, 1989). We have noticed that in the
context of this logic, few studies have treated unbal-
anced linguistic term sets (Abchir, 2013; Chaoued
and Borgi, 2015). The aim of this paper is to establish
a methodology to represent and manage this kind of
data. It is based on our previous work (Chaoued and
Borgi, 2015) that expresses unbalanced terms using a
uniform multi-set. In the present work, we apply our
proposal to an Information Retrieval System (IRS).
The latter aims to retrieve a set of documents that sat-
isfies a user query. This system is composed of three
units (Herrera-Viedma and López-Herrera, 2007):
1. A documentary archive or a database including a
set of documents. They are represented by means
of index terms describing their subject content.
2. A query subsystem presenting user needs by
means of weighted queries. It indicates the top-
ics that he/she is asking for.
50
Chaoued, N., Borgi, A. and Laurent, A..
Linguistic Modifiers with Unbalanced Term Sets in Multi-valued Logic.
In Proceedings of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2015) - Volume 2: KEOD, pages 50-60
ISBN: 978-989-758-158-8
Copyright
c
2015 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
3. An evaluation subsystem allowing the evaluation
of documents according to their relevance com-
pared to the user query.
Usually, users are interested in documents whose
contents are the most relevant to their queries. This
implies the use of more precise labels in the left
(positive) interval than in the right (negative) one
(Herrera-Viedma and López-Herrera, 2007). Thus,
in IRS the use of non-uniformly distributed term
sets is recommended. Indeed, it is more appropriate
to use such a kind of multi-sets to represent the
relevance degrees of the documents or to express the
weights of index terms in the queries. To achieve
this, we will use the unbalanced set S
un
= {None,
Low, Medium, High, Quite High, Very High, Total}
= {N, L, M, H, QH,V H, T } (Herrera-Viedma and
López-Herrera, 2007) (Fig. 1).
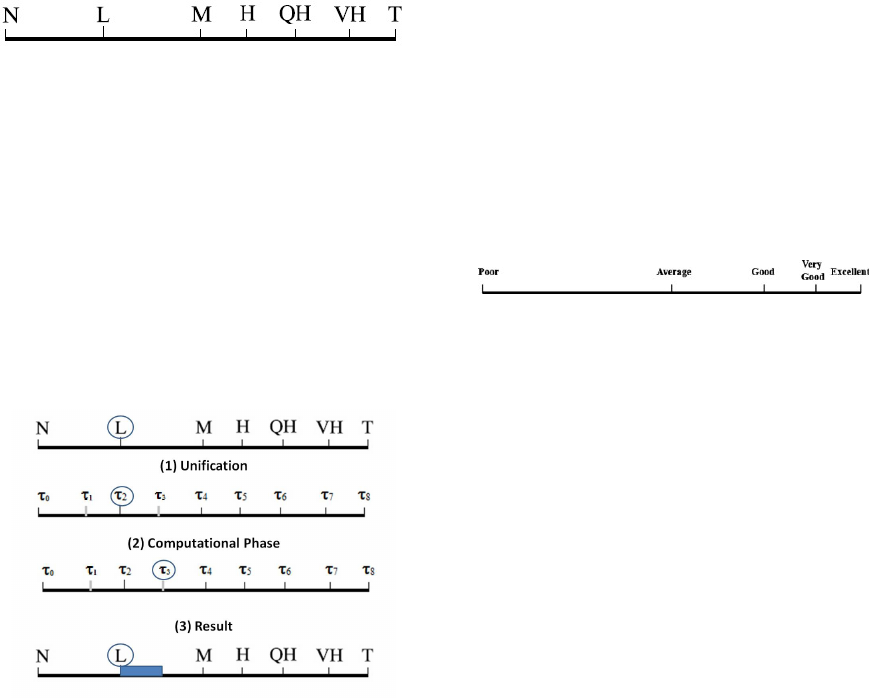
Figure 1: Unbalanced Linguistic Term Set.
Two aspects are discussed in the present work.
The first concerns the representation of terms within
an unbalanced multi-set. The second deals with the
management of such a kind of knowledge. Fig. 2 il-
lustrates the different steps of this process. In the first
one, we apply the single scale algorithm (Chaoued
and Borgi, 2015) to express a term (L in the figure)
using a uniform multi-set (L is represented by τ
2
). Af-
terwards, an existing tool, as aggregation operator or
modifiers, is applied to the obtained term (τ
2
is modi-
fied into τ
3
). The last step aims to express the result of
the computational phase with a term from the initial
multi-set (Approximately L in the figure).
Figure 2: Management of Unbalanced Linguistic Term Set.
This article is organized as follows. We start, in
section 2, with an explanation of what is unbalanced
term sets. In section 3, we introduce the basic con-
cepts of multi-valued logic and of linguistic modifiers.
Existing works that concern the representation of un-
balanced multi-sets are presented in section 4. Then,
section 5 introduces our approach to express terms
within an unbalanced set (Fig. 2 Step 3). Finally, in
section 6, we propose a new way to use Generalized
Symbolic Modifiers (GSM) with unbalanced linguis-
tic terms (Fig. 2 Step 2).
2 PRELIMINARIES
Most Knowledge-Based Systems use linguistic sets
with terms that are uniformly and symmetrically dis-
tributed. However, there are other cases that need to
assess qualitative aspect by means of variables using
linguistic terms which are not uniformly and/or sym-
metrically distributed, named unbalanced linguistic
sets. In many real-life situations, these latter are used
as in project investment, negotiation process, evalua-
tion process, etc. Asymmetric linguistic information
can be a consequence of the nature of the linguistic
variables involved in the problem such as personal
examination or evaluation system (Fig. 3) (Martínez
and Herrera, 2012). Terms are not equidistant, e.g.
the distance between Poor and Average is greater than
between Average and Good. This difference indicates
the expert’s interest in having a more precise defini-
tion of a part of the domain, that leads to the use of
more labels in this interval.
Figure 3: Set of 5 Linguistic Terms not Uniformly Dis-
tributed.
Moreover, in many problems, several decision
makers are involved. In fact, it is more reliable to
obtain a decision based on the opinion of several ex-
perts than on a single one. In a multi-experts decision
making process, each expert may assess his knowl-
edge with a particular scale having a specific granu-
larity (Fig. 4) (Martínez and Herrera, 2012). It indi-
cates their different knowledge backgrounds or judg-
ing abilities. In each used linguistic set, terms are uni-
formly distributed.
Herrera et al. (Francisco Herrera and Martínez,
2008) considered that an unbalanced fuzzy set is a set
with a minimum term, a maximum term and a central
term s
c
called also midpoint. The remaining terms
are neither uniformly distributed nor asymmetrically
on both side of central term :
S = S
L
∪ S
C
∪ S
R
(1)
With :
• S
L
: the subset including terms on the left of the
central term s
c
and #(S
L
) its cardinality;
Linguistic Modifiers with Unbalanced Term Sets in Multi-valued Logic
51

Figure 4: Fuzzy Multi-Granular Scales Used by Experts.
• S
C
: the singleton containing the term s
c
;
• S
R
: the subset including terms on the right of the
central term s
c
and #(S
R
) its cardinality.
Hence, S is described by:
S = {(#(S
L
), density
L
), 1, (#(S
R
), density
R
)} (2)
where 1 is the midpoint. The density corresponds to
a high granularity around the central term or the end
of fuzzy partition. Therefore, the density value can be
middle or extreme.
For example, the set represented by Fig. 3 will
be described by S = {(1, extreme), 1, (3, extreme)}. In
fact, the central term is {Average}. The left subset in-
cludes only the term {Poor} which is the minimum
term. While the right subset includes {Good, Very
Good, Excellent}. These terms are closer to the max-
imum term Excellent. So the density corresponds to
extreme for the two subset.
Xu (Xu, 2009) proposed the unbalanced set as a
set of (2t-1) labels, with t a positive integer, defined
by:
S
(t)
= {s
(t)
β
|β = (1 −t),
2
3
(2 − t),
2
4
(3 − t), ..., 0,
...,
2
4
(t − 3),
2
3
(t − 2), (t − 1)} (3)
Thus, the central term has index 0 and other terms
have positive or negative indices. The main idea of
this definition is that the absolute value of the devia-
tion between the indices of two successive terms in-
crease regularly proceeding from the center term to
the end of the scale. Fig. 5 (Xu, 2009) illustrates an
unbalanced set with t = 4. We notice that the terms
are symmetrically distributed around the central term.
In this work, we propose to define an unbalanced
linguistic term set S
un
as a set of degrees that includes
a minimum degree, False, a maximum degree, True,
and the remaining ones are not necessarily uniformly
Figure 5: A Set of Seven Linguistic Labels S
(4)
.
distributed on the scale: the gaps between adjacent
terms may be unequal. Set granularity, i.e. its cardi-
nality, can be odd or even. Each term is defined by its
position on the scale. They are supplied directly or by
specifying the gap between each successive terms.
To illustrate our proposal, let us use the set repre-
sented in Fig. 3. This set will be described using the
distance between terms :
• Distance Poor - Average: d
1
=
1
2
• Distance Average - Good: d
2
=
1
4
• Distance Good - Very Good: d
3
=
1
8
• Distance Very Good - Excellent: d
4
=
1
8
There are two important subjects to treat when
dealing with imperfect knowledge: (1) their represen-
tation and (2) their management. Many researches
have dealt with these term sets in the fuzzy logic
context (Herrera-Viedma and López-Herrera, 2007;
Martínez and Herrera, 2012; Herrera and Martínez,
2001; Wang et al., 2015; Xu, 2009; Marin et al.,
2014; Bartczuk et al., 2012; Jiang et al., 2015). Re-
searchers have proposed approaches for their repre-
sentation (Martínez and Herrera, 2012; Herrera and
Martínez, 2001; Bartczuk et al., 2012) and their man-
agement, such as operators for unbalanced aggrega-
tion (Marin et al., 2014; Jiang et al., 2015). In the
context of multi-valued logic, only we and Abchir, in
(Chaoued and Borgi, 2015) and (Abchir, 2013) re-
spectively, proposed algorithms to represent unbal-
anced term sets within a uniform set. Our work, de-
veloped in the multi-valued context, has two targets:
the first one is to propose a new way to represent terms
within unbalanced multi-sets; the second intends to
define an approach to use linguistic modifiers with
such knowledge.
3 MULTI-VALUED LOGIC AND
GENERALIZED SYMBOLIC
MODIFIERS
Multi-valued logic is based on De Glas’s multi-set
theory (De Glas, 1989). In this approach, each lin-
guistic term is represented by a multi-set. Knowledge
is expressed thanks to an ordered and finite scale of
M symbols denoted by (De Glas, 1989; Akdag and
KEOD 2015 - 7th International Conference on Knowledge Engineering and Ontology Development
52

Pacholczyk, 1989):
L
M
= {τ
0
, τ
1
, ..., τ
(M−1)
};M ≥ 2 (4)
τ
i
is the membership degree to the multi-set (i ∈ [0,
M-1]).
It should be noted that symbolic degrees are con-
nected only by the total order relation ≤, defined by
(Adkag, 1992)
τ
α
≤ τ
β
⇐⇒ α ≤ β;∀α and β ∈ [0, M − 1] (5)
In most existing works on multi-valued logic,
these degrees are assumed to be uniformly distributed
on the scale. The membership relation in multi-valued
logic is partial:
x ∈
α
A ⇐⇒ x belongs to A at a degree α (6)
To express the imprecision of a predicate, a quali-
fier ϑ
α
is associated with each degree:
x is ϑ
α
A ⇐⇒ (x is ϑ
α
A) is true
⇐⇒ ”x is A” is τ
α
true
The work of Zadeh (Zadeh, 1972), in fuzzy logic, and
more recently those of Akdag et al. (Akdag et al.,
2000; Akdag et al., 2001) and Truck (Truck, 2002),
in multi-valued logic context, consider that any fuzzy
subset or multi-valued symbol can be considered as a
modifier of another fuzzy subset or multi-valued sym-
bol respectively. A modifier allows modeling knowl-
edge and gradual reasoning to build new terms from
the initial ones, or to compare two values by finding
the modifier that allows the transformation from one
to another.
In the multi-valued logic, a membership in a
multi-set is characterized by a symbolic membership
degree τ
i
defined on a scale of ordered degrees L
M
.
Thus, the data modification is a transformation of a
degree and/or the scale of the multi-set. Indeed, some
linguistic modifiers preserve the same multi-set, but
modify the membership degree. Others transform a
multi-set towards another one. Hence, it leads to an
expansion or erosion of the original scale.
Symbolic linguistic modifiers have been proposed
by Akdag et al. (Akdag et al., 2000; Akdag et al.,
2001) and they were generalized and formalized by
Truck (Truck, 2002; Truck et al., 2002). They were
named Generalized Symbolic Modifiers (GSM). Ac-
cording to Truck (Truck, 2002), a GSM (Definition 1)
is a triplet of parameters: radius, nature (i.e. di-
lated, eroded or preserved) and mode (i.e. reinforc-
ing, weakening or central). The radius is denoted by
ρ with ρ ∈ N
∗
. The higher ρ, the more powerful the
modifier.
Definition 1. (Truck, 2002) Let τ
i
be a symbolic de-
gree, such that i ∈ N, in a scale L
M
of M terms
(M ∈ N
∗
\{1}) with i < M. Let m be a GSM with ra-
dius ρ denoted m
ρ
. The modifier m
ρ
is a function that
performs a linear transformation of τ
i
to a new degree
τ
i
0
∈ L
M
0
(where L
M
0
is the linear transformation of
L
M
) according to a radius ρ : m
ρ
(i) = i
0
; m
ρ
(M) = M
0
For each linguistic degree, Akdag et al. (Akdag
et al., 2000) associate a numerical rate, i.e. an in-
tensity level. In fact, an item from the multi-set can
be considered as a precision degree of a proposition.
This latter is the quotient prop(τ
i
) =
p(τ
i
)
M−1
associated
with each τ
i
such that p(τ
i
) is its position in the scale.
Thus, Prop(τ
i
) is the weight of the degree τ
i
relatively
to the linguistic set granularity, i.e. its intensity com-
pared to the truth degree τ
(M−1)
(True).
Symbolic modifiers are classified as: weaken-
ing when the proportion decreases, i.e. prop(τ
i
0
) <
prop(τ
i
) (the four weakening modifiers defined in
(Truck, 2002) are EW
ρ
, DW
ρ
, DW
0
ρ
and CW
ρ
); rein-
forcing when it increases, i.e. prop(τ
i
0
) > prop(τ
i
)
(the four reinforcing modifiers proposed in (Truck,
2002) are ER
ρ
, DR
ρ
, DR
0
ρ
and CR
ρ
) or central if
prop(τ
i
) does not change, such modifiers may act as
a zoom on the base (the four central modifiers pre-
sented in (Truck, 2002) are EC
ρ
, EC
0
ρ
, DC
ρ
and DC
0
ρ
).
Some examples of GSM are presented in Table 1.
4 REPRESENTING
UNBALANCED MULTI-SETS
In the context of multi-valued logic, few works
have treated the non-uniformly distributed knowl-
edge. Abchir proposed in the discussion of his the-
sis (Abchir, 2013) a first approach based on the use
of Generalized Symbolic Modifiers (GSM). We also
proposed in a previous work (Chaoued and Borgi,
2015) a modified version of the Abchir’s algorithm
to represent unbalanced degrees on a single uniform
scale .
4.1 Abchir’s Algorithm
This approach aims to represent numerical input val-
ues v
1
, v
2
, ..., representing the position of terms on
a scale, as symbolic degrees of a uniform multi-set
L
M
. The algorithm starts by calculating a γ coeffi-
cient multiplier to transform input values (v
i
) to in-
teger ones, denoted val
i
, if they are not. Then, each
obtained integer value is transformed into a couple (τ
i
,
1
b.c is the flour function.
Linguistic Modifiers with Unbalanced Term Sets in Multi-valued Logic
53

Table 1: Some Examples of Generalized Symbolic Modifiers (GSM) (Truck, 2002).
Mode Nature Modifier Effect
Weakening
Erosion EW
ρ
m(i) = max (0, i - ρ )
m(M) = max (2, M - ρ )
Dilatation
DW
ρ
m(i) = i
m(M) = M + ρ
DW
0
ρ
m(i) = max (0, i - ρ )
m(M) = M + ρ
Conservation CW
ρ
m(i) = max (0, i - ρ )
m(M) = M
Reinforcing
Erosion
ER
ρ
m(i) = i
m(M) = max (i + 1, M - ρ )
ER
0
ρ
m(i) = min (i + ρ , M - ρ - 1)
m(M) = max (1, M - ρ )
Dilatation DR
ρ
m(i) = i + ρ
m(M) = M - ρ
Conservation CR
ρ
m(i) = min (i + ρ , M - 1)
m(M) = M
Central
Erosion EC
ρ
m(i) = max ( b
i
ρ
c , 1)
1
m(M) = max (b
M
ρ
c + 1, 2)
1
Dilatation DC
ρ
m(i) = i ρ
m(M) = M ρ - ρ + 1
L
M
) according to the following rule:
M = max(2, val
i+1
);τ
i
= τ
val
i
(7)
The procedure is iterative. It stops when all in-
put values have been treated. The author denotes the
first M by M
1
. If the next value to treat cannot be
integrated in this set, i.e., val
2
≥ M
1
, a new value M,
denoted by M
2
, is calculated such that: M
2
= val
2
+1.
Thus, the couple (val
2
, M
2
) leads to (τ
val
2
, L
M
2
).
When M changes, previously calculated couples must
be represented within the new scale L
M
2
. The weak-
ening expanding modifier DW(M
2
− M
1
) (Table 1) is
used to do this.
The process continues for each value, ensuring
that the multiplier coefficient γ always generates in-
teger values. If this is not the case, the multiplier γ
should be changed in a new γ that allows transform-
ing all considered values into integers, and its old
value will be denoted by γ
old
. Then, all previous val-
ues must be recalculated using the central expanding
modifier DC(c) (Table 1). The multiplier c allows to
transform γ
old
into γ. It is obtained as follows:
γ = c ∗ γ
old
(8)
For this algorithm, neither considered values to
treat nor their number is known in advance. Partition-
ing will be done as the value is specified. The final
result remains the same if a change is made in input
terms order. The main criticism made to this approach
is its iterative part for recalculating pairs representing
terms already treated. This is done each time that the
used multi-set or the value of the multiplier γ is mod-
ified.
4.2 Single Scale Algorithm
The difference between Abchir’s algorithm (Abchir,
2013) and the single scale approach (Chaoued and
Borgi, 2015) is in the input data as well as in their
treatment. In this latter, input data can be the po-
sitions of the values to partition or the distances be-
tween them. This last case, not allowed with Abchir’s
approach, offers more flexibility to the users.
The gap between each pair of successive terms re-
flects a difference in their meaning. In this proposal,
inputs are expressed by numerical values which are
supplied directly (d
i
) (Fig. 6-a) or specified by the po-
sition of each term on the scale (v
i
) (Fig. 6-b). In the
latter case, the distance between the terms (more pre-
cisely their positions) v
i+1
and v
i
are calculated as fol-
lows:
d
i
= v
i+1
− v
i
(9)
(a) Distances between terms
(b) Terms position
Figure 6: Algorithm Inputs.
KEOD 2015 - 7th International Conference on Knowledge Engineering and Ontology Development
54
This proposal is based on Espinilla et al.’s work
(Espinilla et al., 2011). The authors proposed a new
definition of linguistic hierarchies: Extended Linguis-
tic Hierarchies (ELH), within fuzzy logic. To build an
ELH, they use a finite number of levels l(t, n(t)) with:
• t: the number indicating the hierarchy level with
t=1,..,m; such m is the number of experts;
• n(t): the granularity of the linguistic term sets cor-
responding to the level t. Each linguistic term has
a triangular membership function, uniformly and
symmetrically distributed on [0,1]. The granular-
ity of each level is always odd.
To express his knowledge, each expert can use a
specific level, i.e. a particular granularity (Espinilla
et al., 2011). Espinilla et al. proposed to add a new
level l(t
∗
, n(t
∗
)) (Definition 2) to the hierarchy with
t
∗
= m + 1. This level retains all the modal points
of all the previous levels. The modal points have a
membership degree that is equal to one.
Definition 2. (Espinilla et al., 2011) Let
{S
n(1)
, ..., S
n(m)
} be the set of linguistic scales
with any odd value of granularity. A new level,
l(t
∗
, n(t
∗
)) with t
∗
= m + 1, that keeps the former
modal points of the previous m levels can have the
following granularity:
n(t
∗
) = 1 + LCM[(n(1) − 1), (n(2) − 1), ...,
(n(m + 1) − 1)]
With m the number of experts
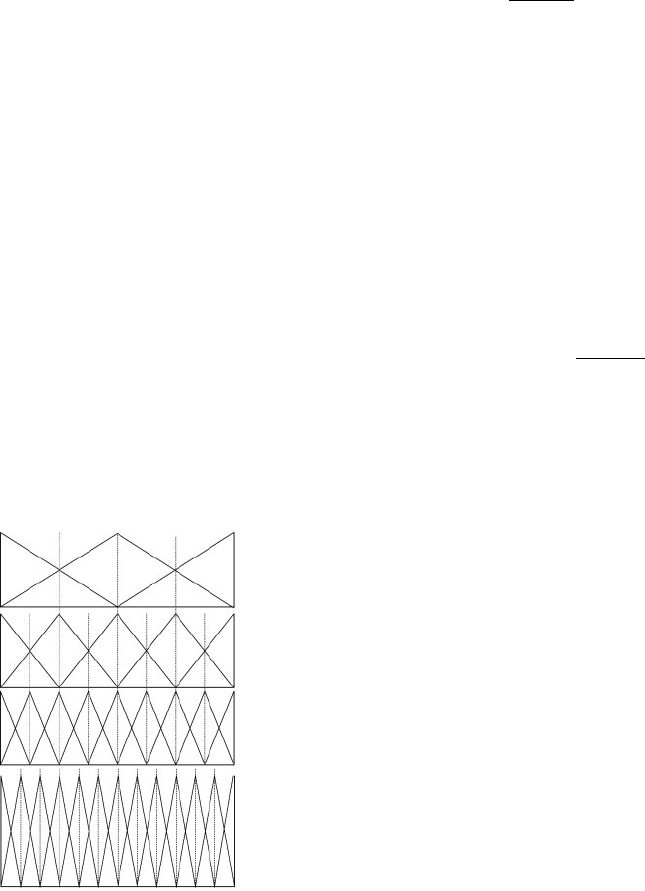
Fig. 7 (Espinilla et al., 2011) shows an ELH with
three levels of 3, 5 and 7 terms. The fourth level (t
∗
)
has as granularity the LCM of the previous ones:
1 + LCM(3 − 1, 5 − 1, 7 − 1) = 13.
Figure 7: Extended Linguistic Hierarchy (ELH) with 3, 5,
7 and 13 Terms.
In a similar way, we proposed to express unbal-
anced terms within a new uniform multi-set (Chaoued
and Borgi, 2015). In fact, the granularity of the uni-
form multi-set equals the LCM of the sets represent-
ing initial terms granularity. The input data are unbal-
anced linguistic terms set S
un
(L
M
, M the number of
terms) and the gap between terms. These are provided
directly or by specifying the position of each term.
First, the granularity M
k
of each uniformly dis-
tributed linguistic set L
M
K
used to represent each input
term v
k
is calculated. In this set, the distance between
each two successive terms is denoted by d
k
.
M
k
=
(1 + d
k
)
d
k
;k = 1, ..., (M − 1) (10)
Once the sets L
M
K
including all the terms of the
initial set are determined, the granularity of the uni-
form set L
M
0
is deduced as:
M
0
= 1 + LCM
M−1
k=1
(M
k
− 1) (11)
Each value will be expressed on the new uniform
scale L
M
0
as a couple (τ
γ
k
, L
M
0
) according to the fol-
lowing rule:
d
k
= γ
k
∗ d
0
;k = 1, ..., (M − 1) (12)
Where d
0
is the distance between any pair of succes-
sive degrees in L
M
0
. For a uniform linguistic set, this
distance is:
d
0
=
1
(M
0
− 1)
(13)
To express the distances d
k
according to the dis-
tance d
0
, the multiplier γ
k
is calculated using the rule
(12).
The minimum term is represented by (τ
0
0
, L
M
0
) and
denoted by s
0
. The process, presented in Algorithm
1, continues for other values. The obtained couples
(τ
0
γ
k
, L
M
0
) are denoted by s
k
. To ensure the succession
of terms, the calculated multiplier γ
k
is added to the
one calculated in the previous iteration named γ
old
.
Thus, the comparison is always done regarding the
first term of the set L
M
0
, i.e., τ
0
0
.
This algorithm allows to bring us back to the uni-
form case which will give us the capacity to use differ-
ent existing tools as linguistic modifiers (Kacem et al.,
2015), aggregation operators, etc.
Considering the complexity, this proposal is less
complex (O(p)) than Abchir’s (O(p
2
)), with p the
number of input terms (Chaoued and Borgi, 2015).
Indeed, in this approach the treatment is done after
introducing all data. Hence, the couples representing
terms are calculated once.
To illustrate this algorithm, let us consider an In-
formation Retrieval System (IRS) and the linguis-
tic term set S
un
= L
7
= {N, L, M, H, QH, VH, T}
Linguistic Modifiers with Unbalanced Term Sets in Multi-valued Logic
55

(Herrera-Viedma and López-Herrera, 2007) (Fig. 1).
This latter is used to express the relevance of docu-
ments in the retrieval process. We aim to represent
each term of L
7
using a term from a uniform linguistic
set. As input, we consider the normalized distances in
L
7
as:
• Distance N - L: d
1
=
1
4
= 0.25
• Distance L - M: d
2
=
1
4
= 0.25
• Distance M - H: d
3
=
1
8
= 0.125
• Distance H - QH: d
4
=
1
8
= 0.125
• Distance QH - VH: d
5
=
1
8
= 0.125
• Distance VH - T: d
6
=
1
8
= 0.125
First, we calculate the values M
k
:
M
1
=
1+d
1
d
1
= 5 = M
2
; M
3
=
1+d
3
d
3
= 9 = M
4
=
M
5
= M
6
Algorithm 1: Single Scale algorithm.
Input:
M unbalanced linguistic terms
Normalized distances d
k
with k=1, ..., (M-1)
begin
Calculate granularities M
k
; M
k
∈ N
∗
\{1}
with k=1, ..., (M-1)
Calculate granularity:
M
0
= 1 + LCM
M−1
k=1
(M
k
− 1)
Deduce distance d
0
=
1
(M
0
−1)
s
0
← (τ
0
0
, L
M
0
)
Calculate γ
k
=
d
k
d
0
with k=1, ..., (M-1)
s
k
← (τ
0
γ
k
, L
M
0
)
Output: S
0
= {(τ
0
0
, L
M
0
),(τ
0
γ
1
, L
M
0
),...,
(τ
0
γ
p−1
, L
M
0
)}
Then, we determine the granularity M
0
of the uni-
form set and the distance between any of its succes-
sive terms d
0
: M
0
= 1 + LCM(5 − 1, 9 − 1) = 9;
d
0
=
1
M
0
−1
= 0.125
We associate the couple (τ
0
0
, L
9
) to the term N, and
we treat the other values:
• For the term L (k = 1)
γ
old
← 0; γ
1
← γ
old
+
d
1
d
0
= 2; L ← (τ
2
, L
9
)
• For the term M (k = 2)
γ
old
← 2; γ
2
← γ
old
+
d
2
d
0
= 4; M ← (τ
4
, L
9
)
• For the term H (k = 3)
γ
old
← 4; γ
3
← γ
old
+
d
3
d
0
= 5; H ← (τ
5
, L
9
)
• For the term QH (k = 4)
γ
old
← 5; γ
4
← γ
old
+
d
4
d
0
= 6; QH ← (τ
6
, L
9
)
• For the term VH (k = 5)
γ
old
← 6; γ
5
← γ
old
+
d
5
d
0
= 7;V H ← (τ
7
, L
9
)
• For the term T (k = 6)
γ
old
← 7; γ
6
← γ
old
+
d
6
d
0
= 8; T ← (τ
8
, L
9
)
The algorithm output is illustrated in Fig. 8.
Figure 8: Result of the Single Scale Algorithm.
5 REPRESENTATION OF TERMS
WITHIN AN UNBALANCED
SET
In the previous section, we have presented our pre-
vious work (Chaoued and Borgi, 2015) to represent
an unbalanced term set S
un
within a uniform term set
L
M
0
. Thereby, existing linguistic modifiers or aggre-
gation operators can be applied to its terms. The ob-
tained values are also expressed using the uniform set
L
M
0
. However, it is more understandable for the user
to represent these results using terms from the initial
set S
un
.
In this section, we focus on the representation of a
term τ
0
i
from the uniform set L
M
0
with a term from S
un
denoted by L
M
. We suppose that the used distances on
both sets are normalized. For more clarity, we denote
the degrees of the uniform set L
M
0
by τ
0
0
, ..., τ
0
i
... and
those of S
un
by τ
0
, ..., τ
i
... (knowing that τ
0
and τ
0
0
cor-
respond to the same position 0 and τ
M
and τ
0
M
0
to 1).
We propose a way to determine the nearest position,
in S
un
, to an initial term τ
0
i
, represented by its position
v
i
in L
M
0
. For that purpose, first, we need to define the
proportion of an unbalanced degree from S
un
.
Definition 3. Let τ
i
be a symbolic degree of an unbal-
anced multi-set S
un
(L
M
). Its proportion is defined as:
Prop(τ
i
) =
i
∑
j=1
d
j
With d
j
the normalized distance between each pair of
successive degrees in the unbalanced multi-set S
un
.
We aim to identify the term τ
pos
in S
un
which dis-
tance between it and the first term (τ
0
0
) of L
0
M
is the
closest to v
i
, the position of τ
0
i
on L
0
M
. Thus, we will
compare v
i
with the sum l
k
of the distances separating
successive terms in L
M
: l
k
=
k
∑
j=1
d
j
.
The process will stop when the value of l
k
is
higher or equal to v
i
. If the values v
i
and l
k
are equal,
KEOD 2015 - 7th International Conference on Knowledge Engineering and Ontology Development
56

the position of τ
0
i
in L
M
0
is that of τ
k−1
. If v
i
< l
k
, we
check the closest term to v
i
between τ
k−1
and τ
k
. In
this case, a proportion error, denoted by α, exists and
its value is the difference between the position of a
term τ
0
i
and that of the closest term, i.e. τ
k−1
or τ
k
. If
these terms are equidistant to τ
0
i
, we choose the term
with the smallest index. This approach is described in
Algorithm 2.
The inputs for this function are the position v
i
of
the term τ
0
i
, the M terms of the unbalanced multi-
set S
un
and the normalized distances d
k
between its
successive terms. As output, we obtain the couple
(τ
pos
, α).
To illustrate our approach, let us continue with the
IRS already described. Let us suppose that a docu-
ment D is described in the database with a set of 5
index t
i
(i ∈ {1, ..., 5}):
D = 0.7/t
1
+ 0.5/t
2
+ 0.9/t
3
+ 0.6/t
4
+ 0.4/t
5
.
In fact, the system indicates for each index term
a numeric value corresponding to its importance in
describing the subject discussed in the document. If
the index term t
i
is not linked to the document subject
content, its value is equal to 0. However, the index
value that is equal to 1 means that t
i
is too important
in the document subject. We aim to represent each
index value, i.e. v
i
, by means of a couple (τ
pos
, α);
such τ
pos
is a membership degree from L
7
(S
un
).
The counter k is initialized to 1 and the distance l
k
to 0. For the first index value v
1
:
• k = 1: l
1
= 0.25 < 0.7 = v
1
• k = 2: l
2
= 0.25 + 0.25 = 0.5 < 0.7
• k = 3: l
3
= 0.5+ 0.125 = 0.625 < 0.7
• k = 4: l
4
=0.625 + 0.125 = 0.75 > 0.7
In this case v
1
is lower than l
4
(= 0.75). We can
say that the index value is between τ
3
, High (H), and
τ
4
, Quite High (QH). So, we check the closest term
between τ
3
and τ
4
by comparing values of (l
4
- v
1
)
and (v
1
- (l
4
- d
4
)): (0.75 - 0.7) < (0.7 - (0.75 - 0.125)).
Hence, τ
4
is closer than τ
3
and the proportion error
is α = -0.05. Thus, v
1
is represented by (QH, -0.05)
(Fig. 9). We can say that the degree τ
4
is weakened
of 0.05. We proceed using the same approach for the
other index values. Thus, we obtain:
D = (QH, -0.05)/t
1
+ (M, 0)/t
2
+ (VH, 0.025)/t
3
+
(H, -0.025)/t
4
+ (M, -0.1)/t
5
.
Figure 9: Representation of the Index v
1
within an Unbal-
anced Set.
Algorithm 2: Representation of terms within unbal-
anced multi-set.
Input:
The position v
i
of the term τ
0
i
, τ
0
i
∈ L
M
0
M linguistic terms of L
M
(S
un
)
Normalized distances d
k
in L
M
; k=1, ..., (M-1)
begin
k = 1
l
1
= 0
while l
k
< v
i
do
l
k
=
k
∑
j=1
d
j
k ← k + 1
if l
k
= v
i
then
pos ← k-1
α ← 0
else
if l
k
- v
i
< v
i
- (l
k
- d
k
) then
pos ← k
α ← - (l
k
- v
i
)
else
pos ← k-1
α ← v
i
- (l
k
- d
k
)
Output: The couple (τ
pos
, α)
6 LINGUISTIC MODIFIERS
WITH UNBALANCED
MULTI-SETS
In multi-valued logic, any symbol can be considered
as a modifier of another one. Thereby, modifiers allow
to represent small variations of imprecise characteri-
zations of a linguistic variable. Symbolic modifiers
may transform simultaneously the membership de-
grees and the scale of the multi-set. We propose in this
section to illustrate how to use linguistic modifiers
with unbalanced imperfect knowledge. We present
an approach to apply Generalized Symbolic Modi-
fiers (Truck, 2002) (Table 1), initially designed for
balanced sets, to unbalanced term sets.
To perform this, first, we express the unbalanced
term to modify with a term from a balanced multi-set.
Afterwards, we apply the GSM modifier on the ob-
tained term within a balanced set. Then, we should
find the closest matching term back in the original
unbalanced multi-set. Our proposal has as input M
linguistic terms of the unbalanced multi-set S
un
(rep-
resented on a scale L
M
), a term τ
i
from this set, the
normalized distances d
k
between its successive terms
and the GSM m to apply. The treatment will be as
follows (Algorithm 3):
Linguistic Modifiers with Unbalanced Term Sets in Multi-valued Logic
57

Algorithm 3: Using GSM with unbalanced multi-set.
Input:
M unbalanced linguistic terms of L
M
(S
un
)
The term τ
i
∈ L
M
Normalized distances d
k
of L
M
; k=1, ..., (M-1)
The GSM m
begin
L
M
0
← Single scale approach (M
unbalanced terms, d
k
) (Algo.1)
Identify the couple (τ
i
0
, L
M
0
) corresponding
to (τ
i
, L
M
) in L
M
0
(τ
i
00
, M
00
) ← m (τ
i
0
, M
0
)
v
i
00
←
i
00
(M
00
−1)
Calculate the closest term τ
pos
to v
00
i
in S
un
and the proportion error α (Algo.2)
Output: The couple (τ
pos
, α)
1. Express the term τ
i
within a uniform multi-set L
M
0
using the single uniform scale approach (Subsec-
tion 4.2). The new term is denoted by τ
0
i
.
2. Apply the GSM m to the term τ
0
i
. Thus, we get
a new uniform linguistic set L
00
M
, such that M
00
=
m(M
0
), and a new term τ
00
i
= m(τ
0
i
).
3. Represent the term τ
00
i
within the initial unbal-
anced linguistic set L
M
(S
un
) using the approxi-
mation function presented in Algorithm 2.
Thus, for this last step, we have to determine the
nearest position to τ
00
i
in S
un
(L
M
). First, we calculate
the position v
00
i
, i.e. the distance between the term τ
00
i
and τ
00
0
. Afterwards, we determine the term τ
pos
by
comparing v
00
i
to the sum l
k
of the distances between
each successive terms in L
M
(d
k
).
To illustrate our approach, we use the same ex-
ample of IRS previously presented. We consider the
unbalanced set L
7
of relevance degrees (Fig. 10). We
apply the reinforcing modifier CR(1) to the relevance
degree Medium, i.e. τ
2
. The process is represented in
Fig. 11.
Figure 10: Unbalanced Set of Relevance Degrees.
As mentioned before, the distances d
k
are:
d
1
= d
2
= 0.25; d
3
= d
4
= d
5
= d
6
= 0.125.
The proportion of the term τ
2
in the unbalanced
term set L
7
(Definition 3) is:
Prop (τ
2
) = d
1
+ d
2
= 0.25 + 0.25 = 0.5
The granularity of the uniform set, previously cal-
culated in Subsection 4.2, is 9 and the term τ
2
from
S
un
is represented by τ
0
4
in L
9
. We notice that the pro-
portion is preserved Prop(τ
0
4
) =
4
8
= 0.5.
For this example, we apply the GSM CR (1) to the
couple (τ
0
4
, L
9
) (Table 1):
i
00
= m(4) = min(4 + 1, 9 − 1) = min(5, 8) = 5;
M
00
= m(9) = 9
The obtained couple is (τ
00
5
, L
9
). We remind that
the modifier CR is a reinforcing one, i.e. the propor-
tion is increased: Prop (τ
00
5
) =
5
8
> Prop(τ
0
4
) =
4
8
.
Finally, we must express the term τ
00
5
within the
initial set L
7
. We first calculate the distance: v
00
5
=
i
00
(M
00
−1)
=
5
8
= 0.625.
The counter k is initialized to 1 and the distance l
1
to 0.
• For k = 1; l
1
← 0.25 < v
00
5
• For k = 2 ; l
2
← 0.25 + 0.25 = 0.5 < v
00
5
• For k = 3 ; l
3
← 0.5 + 0.125 = 0.625 = v
00
5
In this case, the value of l
3
is equal to v
00
5
. Thus,
τ
3
is the correspondent term in the unbalanced set L
7
.
The proportion of this term is Prop (τ
3
) = 0.625. It
corresponds to the proportion of the term τ
00
5
in the
balanced multi-set L
9
.
We can say that the result of applying CR (1) to
the relevance degree Medium corresponds to the rele-
vance degree High.
Figure 11: The Process of Applying CR (1) to Relevance
Degree M.
7 CONCLUSIONS
This work deals with imperfect knowledge manage-
ment in the multi-valued logic context. Specifically,
it deals with the representation and management of
unbalanced multi-sets. In fact, the available literature
KEOD 2015 - 7th International Conference on Knowledge Engineering and Ontology Development
58
that involves unbalanced term sets are only concerned
with the fuzzy logic. They also do not propose a for-
mal definition of unbalanced term sets, which could
be an important improvement in imperfect knowledge
management.
This paper proposes an algorithm that allows to
represent uniformly distributed terms within an unbal-
anced term set. This is performed by an approxima-
tion function that provides the closest term in the un-
balanced multi-set to the desired value. In some cases,
a proportion error may exist. Besides that, based on
our previous work (Chaoued and Borgi, 2015) that al-
lows the representation of terms on a single uniform
scale, we introduce a second algorithm that applies
linguistic modifiers, initially designed for balanced
terms, to unbalanced ones.
As future work, we notice that, in both Abchir’s
and our algorithms, the input terms for the represen-
tation are numerical. It would be interesting to pro-
pose a way to treat symbolic cases where the dis-
tances between terms are defined with words instead
of numbers. It would also be more understandable
by humans to express the proportion error using ad-
verbs like little, more or less, slightly,... Another
aspect in the management of imperfect knowledge
that should be treated is the approximate reasoning
(Zadeh, 1975). It is based on the Generalized Modus
Ponens. Its principle is to deduce a fact similar to the
conclusion rule from an observation approximately
equal to the premise rule. It would be important to
propose a new Generalized Modus Ponens rules deal-
ing with unbalanced multi-sets.
REFERENCES
Abchir, M.-A. (2013). Towards fuzzy semantics for geolo-
cation applications. Phd thesis, University of Paris
VIII Vincennes-Saint Denis.
Adkag, H. (1992). Une approche logique du raisonnement
incertain. Phd thesis, University of Paris 6.
Akdag, H., De Glas, M., and Pacholczyk, D. (1992). A
qualitative theory of uncertainty. Fundamenta Infor-
maticae, 17(4):333–362.
Akdag, H., Mellouli, N., and Borgi, A. (2000). A symbolic
approach of linguistic modifiers. Information Process-
ing and Management of Uncertainty in Knowledge-
Based Systems, Madrid, pages 1713–1719.
Akdag, H. and Pacholczyk, D. (1989). Incertitude et logique
multivalente, première partie : Etude théorique.
BUSEFAL, 38:122–139.
Akdag, H., Truck, I., Borgi, A., and Mellouli, N.
(2001). Linguistic modifiers in a symbolic frame-
work. Int. J. Uncertain. Fuzziness Knowl.-Based Syst.,
9(Supplement):49–61.
Bartczuk, L., Dziwinski, P., Starczewski, J., Rutkowski,
L., Korytkowski, M., Scherer, R., Tadeusiewicz, R.,
Zadeh, L., and Zurada, J. (2012). A new method
for dealing with unbalanced linguistic term set. vol-
ume 1, Czestochowa University of Technology, De-
partment of Computer Engineering, al. Armii Kra-
jowej 36, Czestochowa, 42-200, Poland.
Chaoued, N. and Borgi, A. (2015). Representation of unbal-
anced terms in multi-valued logic. In The 12th IEEE
International Multi-Conference on Systems, Signals &
Devices.
De Glas, M. (1989). Knowledge representation in a fuzzy
setting. Rapport interne, 89:48.
Espinilla, M., Liu, J., and Martínez, L. (2011). An extended
hierarchical linguistic model for decision-making
problems. Computational Intelligence, 27(3):489–
512.
Francisco Herrera, E. H. and Martínez, L. (2008). A fuzzy
linguistic methodology to deal with unbalanced lin-
guistic term sets. IEEE T. Fuzzy Systems, 16(2):354–
370.
Herrera, F. and Martínez, L. (2001). A model based on
linguistic 2-tuples for dealing with multigranular hi-
erarchical linguistic contexts in multi-expert decision-
making. Systems, Man, and Cybernetics, Part B: Cy-
bernetics, IEEE Transactions on, 31(2):227–234.
Herrera-Viedma, E. and López-Herrera, A. G. (2007). A
model of an information retrieval system with unbal-
anced fuzzy linguistic information. Int. J. Intell. Syst.,
22(11):1197–1214.
Jiang, L., Liu, H., and Cai, J. (2015). The power average op-
erator for unbalanced linguistic term sets. Information
Fusion, 22(0):85 – 94.
Kacem, S. B. H., Borgi, A., and Tagina, M. (2015). Ex-
tended symbolic approximate reasoning based on lin-
guistic modifiers. Knowl. Inf. Syst., 42(3):633–661.
Marin, L., Valls, A., Isern, D., Moreno, A., and Merigó,
J. (2014). Induced unbalanced linguistic ordered
weighted average and its application in multiperson
decision making. Scientific World Journal, page
642165.
Martínez, L. and Herrera, F. (2012). An overview on the
2-tuple linguistic model for computing with words in
decision making: Extensions, applications and chal-
lenges. Inf. Sci., 207:1–18.
Truck, I. (2002). Approches symbolique et floue des mod-
ificateurs linguistiques et leur lien avec l’agrégation:
Application: le logiciel flous. Phd thesis, University
of Reims Champagne-Ardenne.
Truck, I., Borgi, A., and Akdag, H. (2002). Generalized
modifiers as an interval scale: Towards adaptive col-
orimetric alterations. In Advances in Artificial Intel-
ligence - IBERAMIA 2002, 8th Ibero-American Con-
ference on AI, Seville, Spain, November 12-15, 2002,
Proceedings, pages 111–120.
Wang, B., Liang, J., Qian, Y., and Dang, C. (2015). A nor-
malized numerical scaling method for the unbalanced
multi-granular linguistic sets. International Journal of
Uncertainty, Fuzziness & Knowledge-Based Systems,
23(2):221 – 243.
Linguistic Modifiers with Unbalanced Term Sets in Multi-valued Logic
59
Xu, Z. (2009). An interactive approach to multiple attribute
group decision making with multigranular uncertain
linguistic information. Group Decision and Negotia-
tion, 18(2):119 – 145.
Zadeh, L. A. (1965). Fuzzy sets. Information and Control,
8(3):338 – 353.
Zadeh, L. A. (1972). A fuzzy-set-theoretic interpretation of
linguistic hedges. Journal of Cybernetics, 2(3):4–34.
Zadeh, L. A. (1975). The concept of a linguistic variable
and its application to approximate reasoning - I. Inf.
Sci., 8(3):199–249.
KEOD 2015 - 7th International Conference on Knowledge Engineering and Ontology Development
60
