
A Comparative Study of Two Egocentric-based User Profiling Algorithms
Experiment in Delicious
Marie Franc¸oise Canut
1
, Manel Mezghani
1,2
, Sirinya On-At
1
, Andr
´
e P
´
eninou
1
and Florence S
`
edes
1
1
Toulouse Institute of Computer Science Research (IRIT), University of Toulouse,
CNRS, INPT, UPS, UT1, UT2J, 31062 Toulouse Cedex 9, France
2
Department of Computer Science, Sfax University, MIRACL Laboratory, Sfax, Tunisia
Keywords:
User’s Profile, User’s Interests, Tags, Social Network Analysis, Egocentric Network, Community.
Abstract:
With the growing amount of social media contents, the user needs more accurate information that reflects
his interests. We focus on deriving user’s profile and especially user’s interests, which are key elements
to improve adaptive mechanisms in information systems (e.g. recommendation, customization). In this
paper, we are interested in studying two approaches of user’s profile derivation from egocentric networks:
individual-based approach and community-based approach. As these approaches have been previously applied
in a co-author network and have shown their efficiency, we are interested in comparing them in the context
of social annotations or tags. The motivation to use tagging information is that tags are proved relevant
by many researches to describe user’s interests. The evaluation in Delicious social databases shows that
the individual-based approach performs well when the semantic weight of user’s interests is taken more in
consideration and the community-based approach performs better in the opposite case. We also take into
consideration the dynamic of social tagging networks. To study the influence of time in the efficiency of the
two user’s profile derivation approaches, we have applied a time-awareness method in our comparative study.
The evaluation in Delicious demonstrates the importance of taking into account the dynamic of social tagging
networks to improve effectiveness of the tag-based user profiling approaches.
1 INTRODUCTION
The introduction of online social networks (e.g.
Facebook, Google+, Twitter, YouTube, Flickr,
Delicious, etc.), also called social media, provides
an explosion of online information resources. Our
work focuses on extracting user’s interests from
this kind of data in order to derive the user’s
profile, which is a key element to improve adaptive
mechanisms (recommendation, customization, etc.).
The better a user’s profile reflects user’s appropriate
characteristics (interests, preferences, etc.), the better
these mechanisms will propose relevant information
to the user.
User profiling aims to detect/derive user’s
interests that are generally extracted from his own
profile (e.g. interests are directly provided by the
user), or from his own activities in the system (e.g.
annotating resources) or his social network (e.g.
friends). However, detecting user’s interests is a
crucial problem. Some issues of detecting user’s
interests could be summarized through two main
points.
The first issue is the cold-start problem. For
new or less-active users that interact less frequently
with the system, their profile can be empty or does
not contain any useful interests for a mechanism of
customization or recommendation. Several works
(Tchuente et al., 2013) (Carmel et al., 2009) (Ding
et al., 2009) propose to use information from user’s
social networks. These works demonstrate the
effectiveness and advantages of using social network
resources to solve the lack of information problem.
Indeed, the researchers have analyzed the social
environment of the user such as his neighbours
(persons connected to the user explicitly or implicitly)
(Tchuente et al., 2013) or his own behaviour in social
network (e.g. the action of tagging resources) (Kim
et al., 2011).
The second issue is related to the evolution of
user’s interests over time. Because the user becomes
more and more an active contributor for producing
social information, he requires updated information
reflecting his current needs and interests in every
period of time. This requirement is not widely
taken into consideration in existing users’ interests
632
Françoise Canut M., Mezghani M., On-At S., Péninou A. and Sèdes F..
A Comparative Study of Two Egocentric-based User Profiling Algorithms - Experiment in Delicious.
DOI: 10.5220/0005377006320639
In Proceedings of the 17th International Conference on Enterprise Information Systems (ICEIS-2015), pages 632-639
ISBN: 978-989-758-097-0
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)

detection approaches.
In this work, we are interested in studying two
social network-based user profiling approaches that
aim to overcome the two above mentioned issues. We
focus particularly on egocentric-based user profiling.
This approach extracts user’s interests by analyzing
the information provided by his egocentric network, a
specific social network that takes into account only
the user’s direct neighbours
1
, by considering that
people directly connected to the user in the social
network are most similar to him. We consider
in this work, the Individual-based approach
(Cabanac, 2011) (Carmel et al., 2009) that considers
egocentric network as a set of similar users and
the Community-based approach (Tchuente et al.,
2013) that considers the existing communities in the
egocentric network. These approaches have been
experimented in a co-author network of scientific
publications. Since the online social networks are
considered heterogeneous in terms of data type and
network characteristics, we are interested in studying
the effectiveness of these two approaches in another
kind of social network.
In this paper, we are interested in social tagging
networks
2
. There are several motivations to use
this kind of social networks. First, social tagging
information has been proved relevant to describe
the user’s interests (Kim et al., 2011). Second,
its popularity makes its broad utility in different
social network applications. Finally, a social tagging
network is considered as an evolving network that
provides temporal information. This characteristic
could provide a good opportunity to study user’s
profile derivation process that takes into consideration
both social and temporal information.
The motivation of this work is two-fold:
1. to compare two egocentric-based users profiling
approaches, that try to overcome the cold-start
problem issue, in a social tagging network. The
aim is to deduce the most efficient approach in the
context of a social tagging network.
2. to study the effectiveness of these approaches
while applying the time constraint. Since the
two studied approaches are time-agnostic, we
further have integrated into these approaches, a
time-awareness method based on the time-weight
strategy, proposed by (Zheng and Li, 2011). Thus,
we evaluate the influence of the time to study
the relevance of user’s interests founded by these
1
In this paper, we consider a neighbour as an individual
in the user’s egocentric network
2
Social tagging networks = social networks based on
tagging information
two approaches and how they could overcome the
user’s interests evolution issue.
This paper is structured as follows. In
the second section, we present related works
about tag-based user profiling approaches, the two
different egocentric-based approaches adopted in our
comparative study and the time-awareness user’s
interests extraction process. In the third section we
present the comparative study. In section four, we
present and comment on the results of the comparison
study. The last section consists in concluding and
presenting our future work.
2 RELATED WORK
User’s shared information and interactions in social
network can represent his behaviours. Some works
have been done to extract his interests to build/derive
his user’s profile in a social dimension.
In this section, we discuss researches done in
order to derive user’s profile from his behaviour
of tagging (tagging information) and also from his
behaviour of making friends (through the information
of the egocentric network).
2.1 Tag-based User Profiling
According to (Kim et al., 2011) (Mezghani et al.,
2014), among a variety of information in available
online social networks, social annotations or tags
are interesting elements for building and enriching a
social user’s profile. The reasons of choosing tags
as information that could be used to detect user’s
interests could be summarized through two main
points:
1. Popularity and Variety: Tags are becoming
more and more popular and widely used in
different social networks (Gupta et al., 2010)
(Laniado and Mika, 2010): in popular tagging
social networks such as Flickr and Delicious, in
social media sharing sites such as YouTube or
Instagram, in microblogging networks such as
Twitter (hash tags), or even in social networking
services such as Facebook, Google+. So,
extracting user’s interests from tag information
would be very useful since it could be reused in a
lot of different kinds of social media applications.
2. Utility: According to (Gupta et al., 2010), tags
are used for many purposes (e.g. contributing
and sharing, giving an opinion, marking a place
for a future search, etc.). They are also a
meaningful tool to mark resources, on one hand
AComparativeStudyofTwoEgocentric-basedUserProfilingAlgorithms-ExperimentinDelicious
633

for guiding other users to get information, on
the other hand, to receive information about a
user from the history of tagging (Gupta et al.,
2010). In addition, tags allow users to categorize
information in a free way without the need of an
intermediary entity (i.e. an administrator to define
some words taxonomy).
Tag-based user’s interests detection may use tags
assigned by the user himself or tags deduced from
his neighbours. The approaches that exploit the
user’s own tags may seem to be powerful to capture
user’s interests. However, they could be less effective
to reflect a comprehensible user’s profile due to
the ambiguity associated to these social tags. The
approaches that exploit the tags of the neighbours
could overcome the previous issue by capturing the
collective knowledge from the network. So, we
will use in this paper, tags from neighbours in order
to detect user’s interests not provided by the user
himself.
Like a great number of online social networks,
social tagging networks are considered as evolving
and providing more and more information over time.
(Ding et al., 2009) analysed tags frequencies across
time and found that changing trends in user’s interests
can be identified and tracked over time. To extract the
relevant information from this kind of data, we have
to take into account this dynamic characteristic (see
section 2.3).
2.2 Egocentric-based User Profiling
According to (Tchuente et al., 2013), we consider that
people directly connected to the user in the social
network are the most similar to him. Thus, we
consider in our work, the notion of user’s egocentric
network as a specific social network that takes into
account only his direct neighbours.
The egocentric-based approaches build/derive a
user’s profile by extracting the information from his
immediate neighbours (called egocentric network).
We describe the egocentric network of a user
as follows: for each user (u) we consider the
undirected graph G(u) = (V,E) where V is the set
of nodes directly connected to u, and E is the set
of relationships between each node pair of V. We
emphasize that u is not included in V. According to
this graph, the user u is called ”ego”. The neighbours
in V are called ”alter”. The user’s interests can be
extracted either by using people selected individually
in G (Cabanac, 2011) (Carmel et al., 2009) or rather
by using communities in G (Tchuente et al., 2013).
This distinction is described in figure 1 and explained
below:
Figure 1: Individual-based algorithm (IBSP) and
Community-based algorithm (CoBSP).
2.2.1 Individual-based Approach (IBSP)
This approach uses people individually selected in
the user’s social network to derive his interests that
could be relevant to him. This kind of social profile
is used in (Carmel et al., 2009) to improve search
engine results and in (Cabanac, 2011) to propose a
social recommender system in a co-author network
that uses a co-author graph and a graph of venue
(in conferences) to recommend relevant authors to a
researcher. In these two works, people are selected
individually according to their topical similarity, their
proximity, their connectivity or the strength of their
tie in their social graph (see figure 1).
In this approach, the weight of an interest is computed
by combining his structural weight and his semantic
weight. The structural weight of an interest i from
an individual v, is the centrality value of v in the
egocentric network. The semantic weight of i is its
weight in the profile of v. The combination weight of
the structural and the semantic weight can be adjusted
with some parameter, as presented in the following
formula (1):
w(i,c) = α ∗ Struct
weight(c)
+
(1 − α) ∗ Semantic
weight(i,c)
(1)
2.2.2 Community-based Approach (CoBSP)
Instead of considering only some individually
selected people in the user’s social network,
(Tchuente et al., 2013) propose a community-based
algorithm to derive user’s interests. This work
considers that the user is better described by
communities of people around him, especially the
people who are in his egocentric network. This work
introduced a user’s social dimension building process
(named CoBSP, Community Based Social Profile),
consisting of four steps (see figure 1):
1. Step 1 consists in extracting communities from
the user’s egocentric network. This phase is
ICEIS2015-17thInternationalConferenceonEnterpriseInformationSystems
634

realized by applying iLCD algorithm (Cazabet
et al., 2010), that performs very well with
overlapping communities and outperforms other
algorithms particularly for egocentric networks.
2. Step 2 consists in computing the profile of each
community found in the first step. The profile
of a community is computed by analysing the
behaviour of all members of this community.
3. Step 3 consists in computing the weight of each
interest in the social dimension of the user’s
profile. The weight of an interest i in the
community c is a combination of structural weight
and semantic weight. The structural weight
of an interest i from a community c, is the
centrality value of c in the egocentric network
compared to others communities extracted from
user’s egocentric network. The semantic weight
of an interest i in a community c, depends on
the weight of this interest in the comminuty. The
weights combination is made by the same way as
in the individual-based approach.
4. Finally, in step 4, we derive the social dimension
by using the weights calculated in the third step.
2.3 Time-awareness User’s Interests
Extraction
As time goes by, user’s behaviours and interests
change. Especially, in online social network, user
behaviours tend to change rapidly. Several works
propose time-awareness approaches to cope with the
dynamic and evolution of the studied information.
Most of these works rely on time-forgetting approach.
In this approach, outdated information is completely
forgotten. For example, (Maloof and Michalski,
2000) use a function of aging all the information
and fix a threshold for the up-to-date one. The ones
that are older for the fixed threshold are forgotten.
However, in some cases, the ignored information
could be eventually valuable. Thus, this could lead
to the lost of useful knowledge. To avoid this
inconvenient, some works propose a time gradual
approach (Koychev, 2009). This approach supposes
that the natural forgetting is a gradual process.
Nevertheless, the recent information should be more
important than the older one. Several works consider
the user’s interests drift in an exponential way (Li
et al., 2013).
In a social tagging context, (Zheng and Li, 2011)
consider that both the latest bookmarks and the old
bookmarks are important. They propose to use a
time-score method to assign a weight (time-score)
to a tag according to its posted date and time. The
more a tag is recent, the more its time-score is high.
This time-score method is presented by the following
formula 2:
time
w
(t) = e
−(ln2∗time(t))/hl(u)
(2)
Where time(t) is a non-negative integer representing
the tagging time of the tags shared by a user u. The
time (t) takes the value of 0 for the most recent tagging
time and time (t) sets to be 1 for the previous one,
and so on. hl(u) represents the half-life of the user
u which adapt to each user life cycle in his social
tagging network (the time duration since he started
tagging).
In this paper, we are interested in adopting this
time-weighted method in our time-awareness
comparative study of the two egocentric
network-based user profiling approaches. The
used method is modified to be able to deal with
the egocentric network user profiling context.
We calculate the parameter time(t) from all the
information of the egocentric network of the user u
(instead of his own information).
2.4 Proposed Work
We have shown the importance of the tags and
the relevance of the egocentric network to find
relevant user’s interests. We propose to study in
this work, the two different approaches for egocentric
network-based user profiling in order to select the
most efficient one in a social tagging context.
The experiments in the individual-based
approach proposed by (Cabanac, 2011) and in
the community-based approach (Tchuente et al.,
2013) have been conducted on co-author network,
namely dblp
3
. In this network nodes represent the
authors. Two authors are connected if they publish
together. The user’s interests are extracted from
the titles of their publications. The performance of
the community-based algorithm has been proved
with empirical results compared to the individual
based approach (Tchuente et al., 2013). In this
work, we are interested in: i) applying the two
existing approaches in the context of a social tagging
network and compare the results to find out the most
performing one in this context. ii) comparing these
same approaches but with a temporal constraint using
a time-awareness method.
3 COMPARATIVE ANALYSIS
In this section, we first present the experimentation
3
Digital Bibliography and Library Project
AComparativeStudyofTwoEgocentric-basedUserProfilingAlgorithms-ExperimentinDelicious
635

setup, which allows us to explain the main steps
of building users’ profiles and also to explain the
evaluation process. Then, we present the results of the
comparison through two main criteria: time-agnostic
(ignoring the time constraint) and time-awareness
(taking into account the time constraint). We
consider in this comparative analysis the notion of
user dimension and social dimension to distinguish
between the user’s explicit interests (user dimension)
and the interests extracted from his egocentric
network (social dimension).
The goal of evaluation is to compare the
effectiveness of the two algorithms mentioned in the
section 2.2, in a social tagging context. We compare
these algorithms on the Delicious
4
social database.
Nodes in the social tagging network graph represent
the users. The links between these users are extracted
from their contacts list.
The evaluation strategy consists in comparing the
results of the two algorithms CoBSP and IBSP with
the user’s real profile (user dimension), and selecting
the one that allows building a social dimension that is
the closest to the user dimension.
3.1 Experimentation Setup
To build the user and social dimension of each
user’s profile, we extract the interests from theirs
tags posted in their Delicious profile. Our data set
contains the tags data posted in different time stamps
between 2003 and 2010 extracted from (Ivan et al.,
2011). We consider the tags indicated in each user’s
profile as his real interests and use them to build
the user dimension. To build the social dimension,
we use the tags from all users’ contacts (user’s
egocentric network). To extract the best performance
of community based approach, the studied user in
our work has to possess a significative number of
neighbours. The user considered relevant to the
experiment of (Tchuente et al., 2013) had at least 50
neighbours (ones who possess less neighbours could
lead us to the misinterpretation in the community
extraction step). Subsequently, we have decided
to take into account, users having more than 45
neighbours in our dataset.
3.1.1 Profile Building Process
In this work, we adopt the same process of
building and evaluating users’ profiles as presented
in (Tchuente et al., 2013), except that we extract
the user’ interests from users’ tags instead of users’
publication titles.
4
www.delicious.com
User Dimension Construction. The user
dimension in this experiment consists in representing
the real interests of the user. This dimension is build
by mining keywords in the list of tags posted by the
user as presented in (Tchuente et al., 2013). The first
step of the user dimension construction consists in
collecting the tags posted in user’s Delicious profile.
As presented in the section 2.1, the social tagging
networks are considered as evolving networks. We
can identify and track the changing trends in user’s
interests over time. Consequently, for each user,
we only consider his recent posted tags in his user
dimension. In the second step, we extract interests
from the collected tags using a tag-mining engine: we
first use dictionaries/thesaurus to merge tags having
the same meaning. Then we apply filters to remove
empty words, in order to retain only consistent
interests. In the third step, we compute interests
weights using a semantic weight. The semantic
weight of each interest is computed by its tf measure
that represents the time frequency of the each interest
in the set of all found interests.
Social Dimension Construction. To build a social
dimension, interests are detected by mining texts
that appear in tags of communities or individuals
according to the algorithm used to derive social
dimension presented in the section 2.2 (CoBSP,
IBSP). The first step of the user dimension
construction consists in collecting the tags from
user’s egocentric network (the tags posted by his
direct neighbours). In the second step, we extract
interests using a tag-mining engine. We use the
same process as defined in the second step of user
dimension construction process. In the third step,
we compute interests weights by using the combined
weight between the structural weight from user’s
egocentric network and the semantic weight using the
formula 1.
3.1.2 Evaluation Process
To evaluate the relevance of each social dimension
(Social Dim.) compared to user dimension (User
Dim.), we use the precision and the recall measures.
The precision assesses the proportion between the
relevant found interests and the total number of found
interests. The precision formula is presented as
follows (3):
Precision =
Nb.Interests(SocialDim. ∩U serDim.)
Nb.InterestsSocialDim.
(3)
The recall assesses the proportion of relevant
founded interests compared to the total number
ICEIS2015-17thInternationalConferenceonEnterpriseInformationSystems
636
of real relevant interests (user dimension). In
our experimentation context, the recall formula is
presented as follows (4):
Recall =
Nb.Interests(SocialDim. ∩UserDim.)
Nb.InterestsUserDim.
(4)
To compute the precision and the recall, we only
consider the most relevant interests. The total number
of interests in the user dimension top N (user’s
interests) + m first interests obtained after building
the social dimension (m=5 in this experiment). For
example, if the user dimension of an author’s profile
contains 10 interests, we will consider the social
dimension as only the top 15 first interests computed
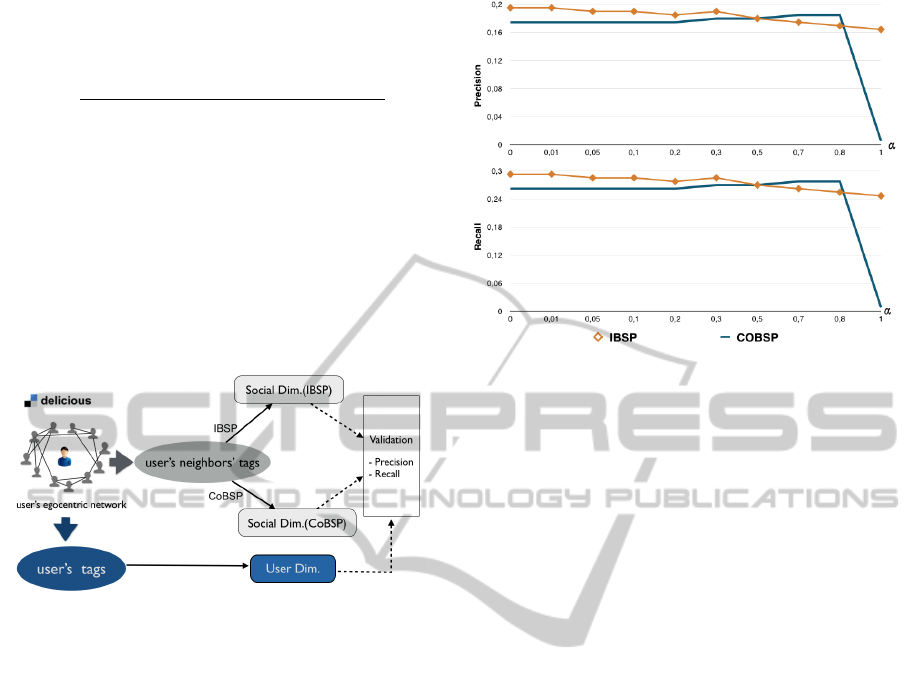
in the social dimension. Figure 2 summaries the
evaluation process.
Figure 2: Evaluation process.
3.2 Results
In this section, we first present the comparison results
of CoBSP and IBSP algorithms without the temporal
constraint. Then, we present the time-weight strategy
used in our time-awareness comparison approach and
the results of this approach.
3.2.1 Time-agnostic Method Results
We present the comparison results of the CoBSP
and IBSP algorithms in the Delicious social tagging
network in figure 3. This figure presents comparative
curves (precision, recall) of these algorithms for
all users’ egocentric networks studied in this work.
The alpha value (α) indicates the weight of
structural weight compared to the semantic weight
as presented in the formula 1. We can see that
the community-based approach (CoBSP) provides
the worst accuracy in terms of precision and recall
compared to the individual approach (IBSP), when
the alpha value is low, that is when we consider more
the semantic weight than the structural one during the
interest weighting step.
The results are conflicting compared to the work
of (Tchuente et al., 2013) where CoBSP outperforms
Figure 3: Comparison of the precision (top) and the recall
(bottom) of calculated social dimensions (Orange: IBSP,
Blue: CoBSP).
IBSP with the experimentation on co-author network,
when the alpha value = 0.1. This can be explained
by the fact that in the scientific publications network,
users’ research field are quite similar, an author tends
to work in the same field than his co-author in
order to publish papers together. Thus, the interests
extracted from this kind of network are in the same
domain. For example, computer scientists tend to
publish in computer science field. The interests
extracted from this kind of network are for the
majority in the computer science domain. So, we
can detect meaningful user’s communities that lead
to an effective social dimension of the user’s profile
(computed by CoBSP).
In case of tagging information, we can find
different domains of interest from the same user (e.g.
sport, art, music, etc.), with different motivations of
tagging. The more the number of users there are, the
more different domains of tags can be provided. As
the community extraction algorithm used in CoBSP
algorithm is only based on the network structure, it
could be possible that the communities extracted from
this process are irrelevant. Thus, this could lead to
a misinterpretation of the results. When the alpha
value is very high (i.e. structural weight is considered
more than the semantic weight during the interests
extraction step) we can see that the CoBSP algorithm
outperforms the IBSP one.
3.2.2 Results with Time-awareness Method
To take into account the evolution of social tagging
network in the user profiling process, we propose
to apply a time-awareness method to evaluate the
relevance of each tag according to his posted time.
To reach this goal, we apply a time-weighted
AComparativeStudyofTwoEgocentric-basedUserProfilingAlgorithms-ExperimentinDelicious
637
method to assign a weight to a tag according to
his posted date. The more a tag is recent, the
more its time-weight is high. We adopted the
time-weight strategy proposed by (Zheng and Li,
2011) in formula (2). We use the similar evaluation
strategy as presented in the section 3.1, except in the
semantic weight computing step of social dimension
construction where we give a weight to each interest
extracted from users’ social tags by multiplying its
time-score with its tf weight. The results of this
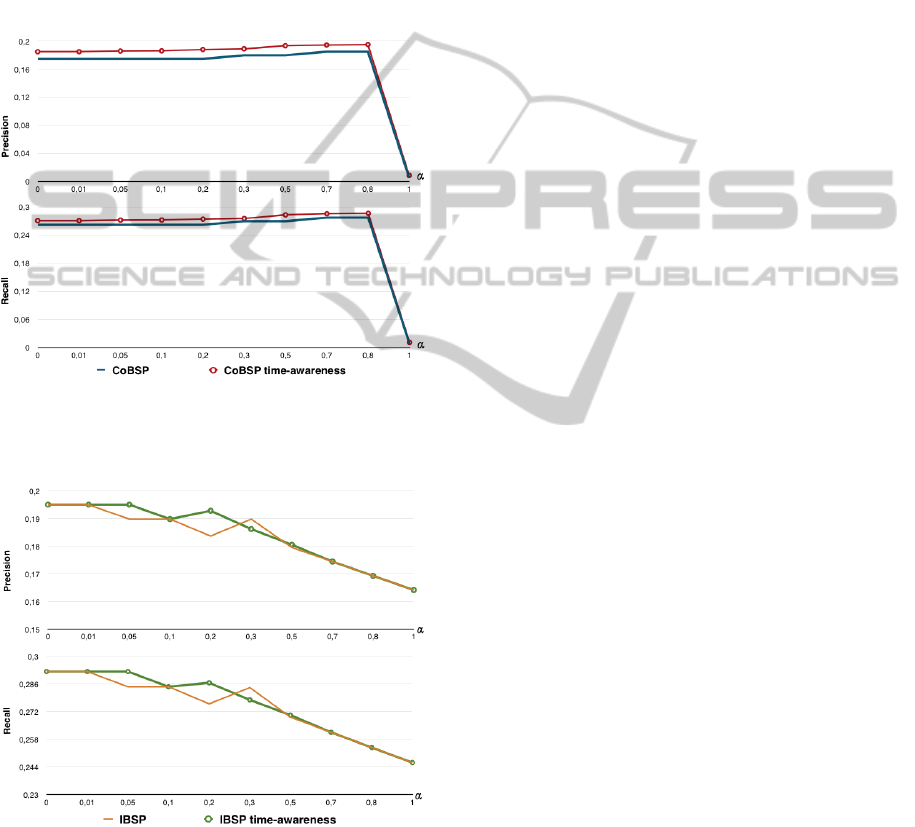
comparison are presented in the figures 4 and 5.
Figure 4: Comparison of the precision (top) and the recall
(bottom) of calculated social dimension of the COBSP
algorithm (Blue: CoBSP time-agnostic, Red: CoBSP
time-awareness.)
Figure 5: Comparison of the precision (top) and the
recall (bottom) of calculated social dimension of the IBSP
algorithm (Orange: IBSP time-agnostic, Green: IBSP
time-awareness).
For the community-based approach, the
time-awareness method (CoBSP time-awareness)
outperforms the time-agnostic one (CoBSP) for all
values of α (figure 4). For the individual-based
approach, the results are improved after applying the
time-weight method when α ∈ [0.01, 0.2] (figure 5).
We have also calculated the average gain of
the time-awareness approach compared to the
time-agnostic one for each algorithm (IBSP and
CoBSP). The average gain is computed according
to the difference between the IBSP time-awareness
curve (respectively CoBSP time-awareness) and the
IBSP time-agnostic curve (respectively CoBSP) for
all α. The results show that:
• for the comparison of the CoBSP vs. CoBSP
time-awareness approach (figure 4): the gain
according to the precision values is 6.0% and the
gain according to the recall values is 3.7%
• for the comparison of the IBSP vs. IBSP
time-awareness approach (figure 5): the gain
according to the precision values is 0.73% and the
gain according to the recall values is 0.47%
The positive average gain values show that
the time-awareness approach can improve the
performance of all algorithm compared to the
time-agnostic one. The results demonstrate the
benefit of taking into account the evolution of
social tagging networks by applying the proposed
time-awareness method to extract the interests
to build a more relevant user social profile.
Nevertheless, the gain rates are still low and require
more studies to improve the effectiveness of this
approach.
4 CONCLUSION AND
PERSPECTIVES
In this work, we are interested in user’s profile
deriving process using user’s social tagging network.
We have compared two egocentric-based user’s
profile derivation approaches: the individual-based
approach and the community-based approach. This
comparative study aims to find out the most effective
approach in a social tagging context. In order to take
into account the dynamic characteristic of tagging
information, we further integrate a time-weight
strategy into the two studied approaches.
Our experiment in Delicious database shows that
the individual-based approach performs well when
the semantic weight of user’s interests is taken more
in consideration and the community-based approach
performs better in the opposite case (more importance
to structural weight).
In the time awareness comparison study, the
results show that the time-awareness user’s profile
is more relevant than the time-agnostic one. These
ICEIS2015-17thInternationalConferenceonEnterpriseInformationSystems
638

results demonstrate the importance of taking into
account the time criteria (temporal information)
in tag-based user’s profile derivation or even in
other kinds of online social network that are
considered evolving. However, the gain rates of
the time-awareness approach studied in this work
are still low and require more studies to enhance
its effectiveness. Our perspective is to improve
the effectiveness of the time-awareness approach by
study of different time-awareness methods to select
ones that fit the best with each adopted social network.
The popularity of online social networks offers
a variety of available data that are heterogeneous
in terms of structure and utility. To build a
relevant user’s profile from each social network
data, it’s necessary to take into account the data
characteristics in the user profiling process. Our
long-term perspective consists in taking into account
this suggestion in order to find out an effective user’s
interests extraction technique for each type of data.
Finally, we expect to propose a platform that extracts
the information and derives a social dimension of
user’s profile according to the type and the specific
characteristics of each studied social network.
ACKNOWLEDGEMENTS
This presentation was subsidized by the Pyrenean
Working Community and the Region Midi-Pyr
´
en
´
ees
(Toulouse, France).
REFERENCES
Cabanac, G. (2011). Accuracy of inter-researcher
similarity measures based on topical and social clues.
Scientometrics, 87(3):597–620.
Carmel, D., Zwerdling, N., Guy, I., Ofek-Koifman, S.,
Har’el, N., Ronen, I., Uziel, E., Yogev, S., and
Chernov, S. (2009). Personalized social search based
on the user’s social network. In Proceedings of the
18th ACM Conference on Information and Knowledge
Management, CIKM ’09, pages 1227–1236. ACM.
Cazabet, R., Amblard, F., and Hanachi, C. (2010).
Detection of overlapping communities in dynamical
social networks. In 2010 IEEE Second International
Conference on Social Computing (SocialCom), pages
309–314.
Ding, Y., Jacob, E. K., Caverlee, J., Fried, M., and Zhang,
Z. (2009). Profiling social networks: A social tagging
perspective. D-Lib Magazine, 15(3).
Gupta, M., Li, R., Yin, Z., and Han, J. (2010). Survey on
social tagging techniques. SIGKDD Explor. Newsl.,
12(1):58–72.
Ivan, C., Peter, B., and Tsvi, K. (2011). HetRec ’11:
Proceedings of the 2Nd International Workshop
on Information Heterogeneity and Fusion in
Recommender Systems. ACM, New York, NY,
USA.
Kim, H.-N., Alkhaldi, A., El Saddik, A., and Jo,
G.-S. (2011). Collaborative user modeling with
user-generated tags for social recommender systems.
Expert Systems with Applications, 38(7):8488–8496.
Koychev, I. (2009). Gradual forgetting for adaptation
to concept drift. In In Proceedings of ECAI
2000 Workshop Current Issues in Spatio-Temporal
Reasoning, pages 101–106.
Laniado, D. and Mika, P. (2010). Making sense of twitter.
In Patel-Schneider, P. F., Pan, Y., Hitzler, P., Mika,
P., Zhang, L., Pan, J. Z., Horrocks, I., and Glimm,
B., editors, The Semantic Web ISWC 2010, number
6496 in Lecture Notes in Computer Science, pages
470–485. Springer Berlin Heidelberg.
Li, D., Cao, P., Guo, Y., and Lei, M. (2013). Time
weight update model based on the memory principle
in collaborative filtering. Journal of Computers, 8(11).
Maloof, M. A. and Michalski, R. S. (2000). Selecting
examples for partial memory learning. Machine
Learning, 41(1):27–52.
Mezghani, M., P
´
eninou, A., Zayani, C. A., Amous, I.,
and Sedes, F. (2014). Analyzing tagged resources
for social interests detection. In ICEIS 2014 -
Proceedings of the 16th International Conference on
Enterprise Information Systems, Volume 1, Lisbon,
Portugal, 27-30 April, 2014, pages 340–345.
Tchuente, D., Canut, M.-F., Jessel, N., Peninou, A., and
Sdes, F. (2013). A community-based algorithm for
deriving users profiles from egocentrics networks:
experiment on facebook and DBLP. Social Network
Analysis and Mining, 3(3):667–683.
Zheng, N. and Li, Q. (2011). A recommender system
based on tag and time information for social
tagging systems. Expert Systems with Applications,
38(4):4575–4587.
AComparativeStudyofTwoEgocentric-basedUserProfilingAlgorithms-ExperimentinDelicious
639
