
Promoting Best Practice Sharing within Organizations
Angelo Di Iorio and Davide Rossi
Department of Computer Science and Engineering, University of Bologna, Bologna, Italy
Keywords:
Web Automation, Semantic Wikis, Organizational Best Practices.
Abstract:
In recent years we are witnessing the wide adoption of Web 2.0’s social software tools (blogs, microblogs,
wiki, forums, shared calendars, etc.) within organizations complementing (or even replacing) existing enter-
prise applications. This trend is justified by the improved immediacy with which information can flow among
the members of the organization and by a better support of agile, emergent cooperation models that re-shape
the practices and the processes within organizations, allowing their continuous refinement and alignment with
the organizations’ missions and evolving know-how. One of the problems that arise in this new scenario is that
as more and more practices and processes include interactions with several tools, often not controlled by the
organization itself, it becomes more difficult to manage the knowledge they embody. In this paper we present
an approach to mitigate this problem that plays nicely with the enhanced participation mechanisms triggered
by social software. Our proposal revolves around the use of semantic wiki technologies as knowledge man-
agement tools; specifically we focus on dealing with practice and process-related knowledge, emerging from
users interactions with Web 2.0 applications, and how this knowledge can effectively be represented, shared
and made persistent.
1 INTRODUCTION
In recent years we are witnessing a trend that sees
Web 2.0-based social software tools complement
(or even replace) enterprise applications within the
IT landscape of several organizations. This phe-
nomenon, often referred to as Enteprise 2.0 (McAfee,
2006), has seen a steady growth and the use of so-
cial software tools is part of the everyday experience
of many not just for personal interest but to carry out
work-related activities as well.
The integration of social software tools within the
enterprise can follow two distinct paths. The first path
leads to installing and managing specific tools within
the organization. For example a wiki and a shared
calendar are installed in the enterprise’s servers and
are accessed as web applications. The second path
leads to the adoption of tools managed by external or-
ganizations using a Software as a Service (Saas) pro-
visioning model. This is the case when, for exam-
ple, Twitter
TM
and Google Calendar
TM
are used rou-
tinely to coordinate the work among members of the
organization. Both solutions present distinct advan-
tages and disadvantages but the Saas-based one opens
new issues to deal with. Among these we can list: se-
curity, privacy, control of information, processes and
practices-related knowledge. In this paper we focus
on this latter issue. The ability to represent, share and
reason on this kind of knowledge is of particular rel-
evance within organizations. As per the knowledge
management (KM) discipline organizations’ knowl-
edge is embodied in persons, practices and processes;
not having control on processes and practices-related
knowledge means ignoring most of the know-how
that supposedly constitutes the main competitive ad-
vantage of an enterprise. This problem pre-dates the
advent of Enterprise 2.0 but is severely amplified by
it: social software is a strong driver for emergent coor-
dination, it improves people participation and pushes
them to re-shape the practices and the processes,
allowing their continuous refinement and alignment
with their missions and evolving know-how. In this
agile environment, mostly when knowledge-workers
are involved, structured processes show their limits
and evolve into less well-defined entities that we call
organizational best practices. If, on top of that, these
practices include interactions with lots of different IT
tools not managed by the organization, it is clear that
capturing this evolving knowledge is not a trivial task.
In this paper we propose a method and a platform
to describe and share organizational best practices and
the knowledge they embody. The method we propose
375
Di Iorio A. and Rossi D..
Promoting Best Practice Sharing within Organizations.
DOI: 10.5220/0004371403750380
In Proceedings of the 9th International Conference on Web Information Systems and Technologies (WEBIST-2013), pages 375-380
ISBN: 978-989-8565-54-9
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

revolves around the use of a classic Enterprise 2.0
tool: wikis; this allows us to use social software to
deal with social software-related knowledge, easing
the integration of our method with the IT landscape
it is meant for. In order to allow a more structured
representation of this knowledge and ease searching
and automated reasoning we decided to use semantic
wikis. Other research works exist that make use of se-
mantic wikis to manage process-related knowledge (a
brief state of the art is presented in section 2) but the
nature of structured processes is quite different from
that of organizational best practices so these works are
not directly applicable to the context we are focusing
on; also: we explicitly limit our method to practices
enacted by using social software tools or, more gener-
ically, Web 2.0 applications. The platform we present,
that can be used to enact our method, is based on Se-
mantic Media Wiki (SMW) (Kr
¨
otzsch et al., 2006)
and on a web browser extension, WikiRecPlay, used
to ease the creation of the process-related knowledge
and to recommend available best practices to the users
depending on their navigation context.
It should be noted that, while the main focus of
the paper is on enterprise environments, most of the
concept we are going to develop are applicable to any
structured organization and, with some distinctions,
to generic communities as well.
This paper is structured as follows: in section 2
we present a survey on how (semantic) wikis are used
to represent enterprise knowledge. In section 3 we in-
troduce our model, how we represent organizational
best practices and how we use semantic wikis to or-
ganize and share the related knowledge. Section 4 is
about the platform we implemented and its two main
components: a semantic wiki and a web browser ex-
tension. Conclusions are sketched out in section 5.
2 ENTERPRISE, WIKIS AND
KNOWLEDGE MANAGEMENT
After their explosion in educational and public set-
tings, wikis are increasingly used to create, refine
and share knowledge within enterprises as well. In
(Majchrzak et al., 2006) authors surveyed 168 cor-
porate wikis, proving that these tools are sustainable
even in long-term projects, a result confirmed also by
the analysis of (Kussmaul and Jack, 2009); in (Voigt
et al., 2011) authors discuss issues and benefits of the
adoption of wikis for small and medium-sized enter-
prises (SME) too.
Nonetheless, the unstructured nature of wikis is
still an obstacle to the full automatic processing of
knowledge. Semantic wikis, such as Semantic Media
Wiki, have been introduced to overcome such limita-
tions: even if not yet widespread within enterprises,
they have great potentialities in this context too.
Basically, a semantic wiki is a wiki system en-
abling users to write collaboratively semantic data
about a given domain. Wiki pages, in fact, map con-
cepts of the domain and usually are composed of both
unstructured text and formal assertions, that can be
exploited by reasoners and semantic query engines.
The interesting point for our discussion is that se-
mantic wikis can be used for enterprise modeling too.
Moki (Ghidini et al., 2009) is one of the most relevant
projects in this area. It is a wiki-based environment
designed to let users with different skills working to-
gether and create a sound enterprise model. Different
MoKi users can access and create content at different
degrees of formality, according to their competencies.
MoKi is based on Semantic MediaWiki. It associates
one wiki page to each (simple or complex) element
of the model. The page contains both an informal
description of the element in natural language and a
formally structured part, with assertions about that el-
ement and relationships with other elements.
KnowWE (Baumeister et al., 2007) is another in-
teresting knowledge engineering tool, designed for
supporting decision-making. Basically, it is a seman-
tic wiki that is further extended to parse additional
markup and to process problem-solving instructions.
The system, in fact, includes interfaces for expressing
rules, decision-trees and fault models and an engine
that parses those instructions and automatically eval-
uates solutions.
An application of semantic wikis particularly rele-
vant for this work is the modelling of (enterprise) pro-
cesses. The most relevant proposals were surveyed in
(Dengler et al., 2011). In (Hussain et al., 2009) au-
thors proposed a wiki-aided process to create business
process specifications. They basically extended the
MediaWiki syntax to allow users (business domain
experts) to describe the requirements of a system in a
semi-structured natural language, that can be exported
into RDF and BPEL.
Wikiing Pro (Dengler and Vrande
ˇ
ci
´
c, 2011) and
BP-MoKi (Francescomarino et al., 2011) integrates
Semantic MediaWiki with Oryx
1
, a graphical editor
that users can exploit to build the model. In particular,
BP-MoKi is a customization of MoKi that also sup-
ports constraints definition and validation (through an
external validator).
1
http://code.google.com/p/oryx-editor/
WEBIST2013-9thInternationalConferenceonWebInformationSystemsandTechnologies
376

3 CAPTURING AND SHARING
ORGANIZATIONAL BEST
PRACTICES
The main goal of the research we present in this pa-
per is to investigate how to support enterprises in col-
lecting, persisting and sharing knowledge about best-
practices and processes that users carry on by inter-
acting with social software tools.
Considering the successful experiences presented
in the previous section, wikis are good candidates for
these tasks but a challenging issue needs to be faced:
how to model and capture such know-how. In fact,
the dynamic and non-predictable flow of information
characterizing organizational best practices makes it
impossible to use structured, prescriptive approaches.
In most cases, in fact, users refine their activities in-
crementally and improve the process at each itera-
tion but the global process is not encoded anywhere.
The visibility of each user is “local” but the interplay
of their activities generates distributed and emergent
processes. Our goal is to capture this kind of interac-
tions as well as their related knowledge.
We are seeking a more flexible approach that, on
the one hand, is able to capture such knowledge and
to make it representable, documented and processable
and, on the other, it is not difficult to be deployed
to the final users. Our solution basically consists in
capturing interaction paths with social software by di-
rectly monitoring browser’s activities and using a se-
mantic wiki as back-end to store, organize, search and
share such know-how. In order to present it, we dis-
cuss separately how to (1) model, (2) share and persist
and (3) search/recommend such know-how.
1 - Processes as Event-based Parametric Synchro-
nizable Interaction Sequences. in order to embrace
a broader definition of process that is also able to cap-
ture organizational best-practices as described so far,
we model them as the interplay of sequences of ac-
tivities carried out by single actors. These activities
take the form of interactions with web applications,
sequences composed by (parametric) interaction steps
and synchronization steps.
Each interaction step is associated to an event oc-
curring on a web page. Clicking on a link, filling
a form, selecting a menu option, copying&pasting a
piece of content, refreshing an iframe are only a few
examples of such events.
The fact that interaction steps can be parametric
is another very important aspect. It is useful, in fact,
not only that sequences are repeatable (so that can be
shared within the enterprise) but also that users can
repeat them with different input values.
Finally, synchronization steps are used in order
to model cooperation and distributed activities. This
means that interaction sequences can be suspended
until a given event occurs, or another step is com-
pleted (even belonging to another process) or a time-
out expires.
Consider, for instance, a wiki page describing the
requirements of a project that, in order to be approved,
need to be checked by three different people in a team.
The approval process can be implemented by using a
page associated to the requirements’ one and by re-
quiring reviewers to publish reviews as distinct sec-
tions of that page. The sequence for the approval pro-
cess includes a step that halts the sequence waiting
for the three reviews to be posted. Each reviewer will
then follow his/her own process to fill the proper sec-
tion in the review page. When all sections will be
filled, the synchronization step will resume and the
main sequence can be resumed.
A detailed discussion of this coordination model
is out of the scope of this paper, but can be found in
(Rossi, 2012). It should be clear, however, how so-
phisticated interplay among activities can be modeled
easily with this approach.
2 - Using Wikis to Share and Persist Sequences. af-
ter making explicit the best practices-related knowl-
edge, we need to persist it and make it promptly
accessible. The easy way in which users can read
and write content, the sophisticated surfing capabil-
ities (backlinks, indexes, recent changes and special
pages) and the versioning/tracking features pointed us
to wikis, supported by the promising results of previ-
ous research in this field. We propose to store each
sequence in a wiki page following syntactical guide-
lines to write information about each step, its associ-
ated event and its execution. From a technical point
of view, this is not an issue.
A relevant feature of our proposal is the possi-
bility of intermixing structured descriptions of se-
quences with text, allowing users to enrich pages with
contextual information that others can exploit to bet-
ter understand and share knowledge. This, however,
opens challenging issues with respect to the coexis-
tence of structured and semi-structured information.
Since wiki pages can be freely edited, in fact, users
could ‘corrupt’ the descriptions of sequences mak-
ing them not in line with their textual counterparts.
Apart from non-technical considerations (i.e. wikis
are meant to be writable and their open editing model
is a strength instead of a risk, leveraging on the com-
munity enthusiasm and skills), researchers have pro-
posed different solutions to mitigate this issue such
as using templates, automatically generating forms
and implementing validation post-processors. For in-
PromotingBestPracticeSharingwithinOrganizations
377

stance, Light-Constraints wiki is a framework to deal
with constraints and validation rules on wiki content,
that does not alter the wiki open editing philosophy
(Di Iorio and Zacchiroli, 2006). It basically consists
of encoding constraints as validator functions that can
be associated to pages and used to check whether the
constraints have been respected, when viewing or sav-
ing those pages. While it would still be possible for
users to de-synchronize the formal representation of a
sequence with its textual (and graphical) description,
the use of validators should prevent this from happen-
ing in most cases.
3 - Searching and Recommending on Semantic
Wikis. Semantic wikis have pushed forward the
potentialities offered by wikis such as text-based
searchers, recent changes lists, backlinks, indexes,
and so on. They enable users to write collaboratively
semantic data about a given domain. Wiki pages, in
fact, intermix unstructured text and formal assertions,
that users can write quite easily by exploiting ad hoc
interfaces and/or natural-language syntaxes. These
assertions can be exploited by reasoners and seman-
tic query engines, and provide a rich knowledge base
to the final users. Our framework relies on a seman-
tic wiki and users are allowed to annotate wiki pages:
by annotating pages associated to sequences, they en-
rich sequences with a network of information that can
used as basis for knowledge representation and diffu-
sion. Semantic descriptions of sequences can be ex-
ploited to search sequences related to the current one,
to search sequences of a given author, to mine data on
sequences and so on. Sophisticated recommendation
tools can be built on top of such information. The list
of semantic properties that can be set on a sequence
is completely open. Users might decide to charac-
terize them by their scope, by their application do-
main, by their reliability, stability and so on. Some of
these properties can also be generated automatically,
derived from the information about versions and page
history (i.e. frequency of modifications, size of modi-
fications, authorship, etc.) and integrated in the over-
all knowledge-base. The interesting point is that the
community of users could agree on a set of proper-
ties useful for characterizing sequences, supported by
the open editing model of wikis, and refine that set
incrementally. Finally, note that semantic data could
also be integrated with other information collected on
wiki pages, in order to build a richer knowledge-base.
Some wiki modules, for instance, allow users to rate
pages (that can be useful to measure the popularity of
sequences), or to manage users’ profiles (that can be
useful to measure the reputation of an author) or to tag
pages (useful to create a folksonomic characterization
of sequences).
4 A PLATFORM TO SUPPORT
ORGANIZATIONAL BEST
PRACTICES
Here we present a software platform able to sup-
port the approach described in the previous section;
this platform includes two main components: a se-
mantic wiki, and a web browser extension. In our
current implementation of the platform we are us-
ing Semantic Media Wiki and WikiRecPlay respec-
tively. SMW provides support for sharing interaction
sequences (each sequence is represented in a separate
wiki page), for making them persistent and for search-
ing them; WikiRecPlay provides support for recom-
mending potentially relevant sequences to the users
from those stored in the wiki, for extracting sequences
from users browsing sessions and for automated re-
play of sequences available in the wiki.
The page describing a sequence contains all the
details needed to acquire the knowledge about how
to replay the sequence and describes each interaction
and synchronization steps that it includes. Specifi-
cally, the wiki page contains both a human-readable
and a machine-processable representation of the se-
quence. The human-readable representation contains
all the details about the elements of the web page
shown to the users that they have to interact with
(form fields to be filled, buttons to be clicked and so
on) and how the browser contents changes in relation
to these interactions. The machine-processable rep-
resentation is used to formally describe all the details
of a sequence; it is included both for semantic dis-
ambiguation purposes as well as a potential input to
automatically replay the sequence.
Consistently producing sequence pages can be
perceived as a daunting task for most users (and prob-
ably it is), this is why WikiRecPlay can be used to
automate it. WikiRecPlay is a web browser extension
(currently available for Firefox) that (among other
things) records the interaction of the users with the
web page they are visiting. At any point in time users
can review their browsing session and decide that a
certain sub-session constitutes a sequence. They can
then mark the first and the last step, the data fields that
have to be considered parametric and insert synchro-
nization steps where needed (these are the steps that
pause the reply of a sequence until a given event oc-
curs). Basic semantic metadata can be specified at this
point; further semantic information can be entered
later by directly editing the corresponding page in the
wiki. It is also possible to mark which step descrip-
tion has to contain a screenshot of the web page that is
shown when the step has to be executed. Once this is
done the sequence can be automatically uploaded to
WEBIST2013-9thInternationalConferenceonWebInformationSystemsandTechnologies
378
the wiki (using wiki APIs), creating a new wiki page
that is structured in the correct way, this page also
contains all the automatically generated screenshots
for all the steps and includes the relevant semantic
meta-data. The wiki page also includes a machine-
processable description of the steps. This description
can be replayed by WikiRecPlay on the behalf of the
user (who is in charge to eventually define the actual
values to be used for parametric fields). The page thus
created is automatically opened in a new tab in the
browser and users can edit it in order to add context,
comments, links and so on. The same applies to other
users that, once created, can make the information on
the page evolve. This can foster collaboration around
sequences and motivate users to use and refine them
in a mutual loop that leverage the circulation of such
enterprise know-how.
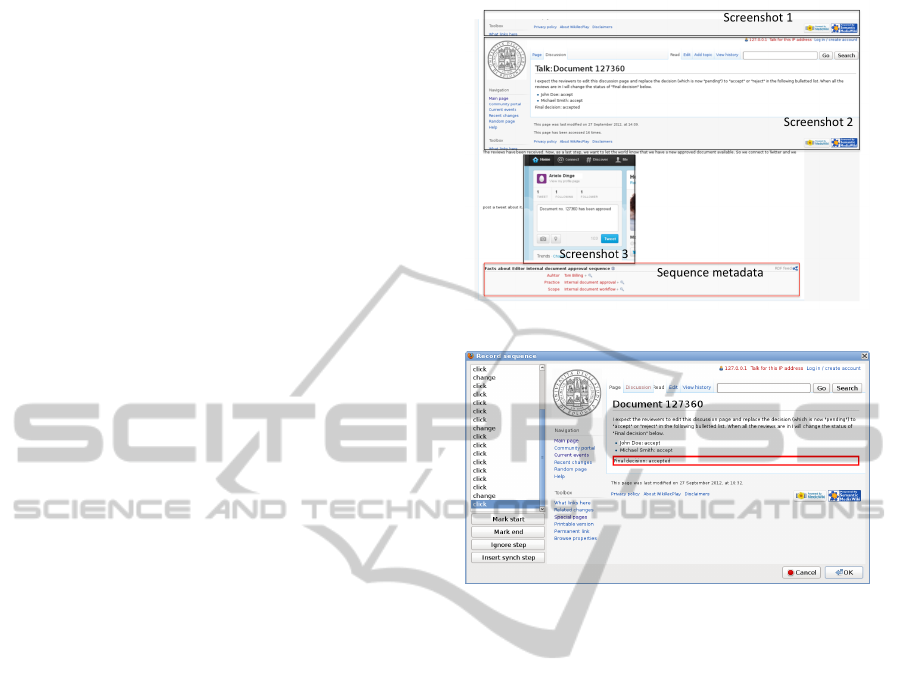
Figure 1 depicts a page of the wiki representing
a sequence. The sequence is part of a practice re-
lated to the approval of a document used for inter-
nal documentation purposes. In this practice a user
assuming the role of editor assigns reviews tasks to
other members of the organization. When the reviews
are completed, if they are positive, the document is
accepted and a tweet is produced on Twitter (which
could trigger other practices related to the manage-
ment of the document). The figure shows the screen-
shot of the wiki page, used to describe the sequence in
both machine-readable and human-readable format.
It shows semantic properties as a factbox in the bot-
tom part and, in the body, contains three screenshots
corresponding to the three main steps of the sequence
(one of which is external, performed on Twitter).
Figure 2 shows a dialog of WikiRecPlay, the web
browser extension used to extract sequences from the
user surfing session. Once the sequence has been de-
fined it is automatically uploaded as a new page into
the wiki. The created page is then opened in a new
browser tab and can be further refined.
Another relevant feature of WikiRecPlay is the in-
tegrated recommender module that, by analyzing the
data stored in the wiki, it is able to suggest available
sequences that can be of interested to the user. We
think that this could easily become the more appar-
ent feature, with respect to the point of view of the
end user, of the whole system. The current imple-
mentation is far from refined and just uses the cur-
rent URL to search for sequences that start from the
same location and present them to the users sorted by
their score. We are planning to leverage the semantic
knowledge and information extracted by mining us-
age data patterns to dramatically improve the existing
recommender module.
The success of the approach we presented (as with
Figure 1: A sequence in the wiki.
Figure 2: Recording a sequence with WikiRecPlay.
most wiki-based environments) depends tightly from
the ability to assure users buy-in. In this specific con-
text this means: how to make users contribute to the
wiki and store sequences into wiki pages? The prob-
lem is complex and still open: working on users’ mo-
tivations, pushing the culture of collaboration, provid-
ing users simplified authoring tools are all pieces of
the solution. In our specific case the relatively com-
plex structure of a page representing a sequence could
be an additional limiting factor. Two of the function-
alities provided by WikiRecPlay are, as a matter of
fact, not mandated by the approach presented in the
previous section but are, rather, dictated by our desire
to solve the user buy-in problem: these are (i) the abil-
ity to automate sequence replaying and (ii) the sup-
port to create sequence pages from actual web surfing
sessions: (i) provides a direct reward to users when
they share a sequence in the wiki in which the se-
quence, once stored in the wiki, becomes playable;
(ii) eases the authoring tasks lowering a classic entry
barrier that usually affect wiki-based solutions.
5 CONCLUSIONS
Other web browser extensions that are able to record
and reply the interactions of a single user with a web
PromotingBestPracticeSharingwithinOrganizations
379

application have been presented in the past, the most
notable one being CoScripter(Leshed et al., 2008).
While also CoScripter makes use of social software
tools to share the interaction sequences, the similari-
ties between the two approaches end there. In our ap-
proach a best practice is not determined by the inter-
action of a single actor with a web application but it is
(possibly) the result of the interplay between several
actors’ interactions. We also have a more refined way
to semantically enrich the information related to the
best practices and we provide a more general knowl-
edge framework of which what we presented is just a
part.
The maturity of the project is another difference
between CoScripter and our work. We have not tested
yet our proof-of-concept implementation with a large
community, while CoScripter has been successfully
adopted by thousands and thousands of users. A full
evaluation of our approach cannot prescind from such
a real-world analysis. Thus, this will be the next step
of our research. We are planning to deploy our solu-
tion in an enterprise context; at the same time we plan
to open the access to the software tools to the broad
public in order to create other feedback channels.
Interesting results could be also obtained by mon-
itoring users’ interactions with the social software
tools and with WikiRecPlay we can collect a signif-
icant amount of data that can be mined in order to ex-
tract further knowledge. These and other interesting
research ideas - such as improving the recommender
system, integrating profiles and sophisticated visual-
izations processes embodied by sequences - can en-
rich the approach we proposed in this paper.
REFERENCES
Baumeister, J., Reutelshoefer, J., and Puppe, F. (2007).
Knowwe: community-based knowledge capture with
knowledge wikis. In Proceedings of the 4th interna-
tional conference on Knowledge capture, K-CAP ’07,
pages 189–190, New York, NY, USA. ACM.
Dengler, F. and Vrande
ˇ
ci
´
c, D. (2011). Wiki-based maturing
of process descriptions. In Proceedings of the 9th in-
ternational conference on Business process manage-
ment, BPM’11, pages 313–328, Berlin, Heidelberg.
Springer-Verlag.
Dengler, F., Vrande
ˇ
ci
ˇ
c, D., and Simperl, E. (2011). Com-
parison of wiki-based process modeling systems. In
Proceedings of the 11th International Conference on
Knowledge Management and Knowledge Technolo-
gies, i-KNOW ’11, pages 30:1–30:4, New York, NY,
USA. ACM.
Di Iorio, A. and Zacchiroli, S. (2006). Constrained wiki:
an oxymoron? In Proceedings of the 2006 interna-
tional symposium on Wikis, WikiSym ’06, pages 89–
98, New York, NY, USA. ACM.
Francescomarino, C. D., Ghidini, C., Rospocher, M., Ser-
afini, L., and Tonella, P. (2011). A framework for the
collaborative specification of semantically annotated
business processes. J. Softw. Maint. Evol., 23(4):261–
295.
Ghidini, C., Kump, B., Lindstaedt, S., Mahbub, N., Pam-
mer, V., Rospocher, M., and Serafini, L. (2009). Moki:
The enterprise modelling wiki. In Proceedings of
the 6th European Semantic Web Conference on The
Semantic Web: Research and Applications, ESWC
2009 Heraklion, pages 831–835, Berlin, Heidelberg.
Springer-Verlag.
Hussain, T., Balakrishnan, R., and Viswanathan, A. (2009).
Semantic wiki aided business process specification. In
Proceedings of the 18th international conference on
World wide web, WWW ’09, pages 1135–1136, New
York, NY, USA. ACM.
Kr
¨
otzsch, M., Vrande
ˇ
ci
´
c, D., and V
¨
olkel, M. (2006). Se-
mantic mediawiki. In Proceedings of the 5th inter-
national conference on The Semantic Web, ISWC’06,
pages 935–942, Berlin, Heidelberg. Springer-Verlag.
Kussmaul, C. and Jack, R. (2009). Wikis for Knowl-
edge Management: Business Cases, Best Practices,
Promises, & Pitfalls. In Lytras, M. D., Dami-
ani, E., and Ord
´
o
˜
nez de Pablos, P., editors, Web 2.0,
chapter 9, pages 1–19. Springer US, Boston, MA.
Leshed, G., Haber, E. M., Matthews, T., and Lau, T. (2008).
Coscripter: automating & sharing how-to knowledge
in the enterprise. In Proceeding of the twenty-sixth
annual SIGCHI conference on Human factors in com-
puting systems, CHI ’08, pages 1719–1728, New
York, NY, USA. ACM.
Majchrzak, A., Wagner, C., and Yates, D. (2006). Corpo-
rate wiki users: results of a survey. In Proceedings of
the 2006 international symposium on Wikis, WikiSym
’06, pages 99–104, New York, NY, USA. ACM.
McAfee, A. P. (2006). Enterprise 2.0: The dawn of emer-
gent collaboration. MIT Sloan Management Review,
47(3):21–28.
Rossi, D. (2012). A social software-based coordination
platform. Coordination Models and Languages, pages
17–28.
Voigt, S., Fuchs-Kittowski, F., H
¨
uttemann, D., Klafft, M.,
and Gohr, A. (2011). Ickewiki: requirements and con-
cepts for an enterprise wiki for smes. In Proceed-
ings of the 7th International Symposium on Wikis and
Open Collaboration, WikiSym ’11, pages 144–153,
New York, NY, USA. ACM.
WEBIST2013-9thInternationalConferenceonWebInformationSystemsandTechnologies
380
