
OPTIMAL COMBINATION OF LOW-LEVEL FEATURES
FOR SURVEILLANCE OBJECT RETRIEVAL
∗
Virginia Fernandez Arguedas, Krishna Chandramouli, Qianni Zhang and Ebroul Izquierdo
Multimedia and Vision Research Group, School of Electronic Engineering and Computer Science
Queen Mary, University of London, Mile End Road, London, E1 4NS, U.K.
Keywords:
Object retrieval, Multi-feature fusion, Particle swarm optimisation, Surveillance videos, MPEG-7 features,
Machine learning.
Abstract:
In this paper, a low-level multi-feature fusion based classifier is presented for studying the performance of
an object retrieval method from surveillance videos. The proposed retrieval framework exploits the recent
developments in evolutionary computation algorithm based on biologically inspired optimisation techniques.
The multi-descriptor space is formed with a combination of four MPEG-7 visual features. The proposed
approach has been evaluated against kernel machines for objects extracted from AVSS 2007 dataset.
1 INTRODUCTION
Recent technological developments coupled together
with people’s concern for safety and security have
caused a wide spread application of Closed Circuit
Television (CCTV) cameras which have been widely
installed for surveillance monitoring. With such an
exponential increase in video footage, there exists
critical need for the development of automatic and in-
telligent retrieval models for objects and events to en-
able efficient media access, navigation and retrieval.
Addressing the challenges related to object indexing,
several approaches has been presented based on prob-
abilistic, statistical and biologically inspired classi-
fiers (Chandramouli and Izquierdo, 2010). Many of
these techniques generate satisfactory results for gen-
eral datasets such as movies, sports and news. How-
ever, the challenge of retrieving surveillance objects
remains a largely an open issue.
Among the approaches presented in the literature,
visual appearance based retrieval has gained much
popularity. The range of visual features used for ob-
ject retrieval from surveillance videos include, colour
histograms from different colour space and Gabor
filters. More recently, MPEG-7 based colour, tex-
ture and shape descriptors have been largely investi-
gated for multimedia indexing and retrieval (Sikora,
2002). In many of these approaches authors con-
∗
The research was partially supported by the European
Commission under contract FP7-216444 PetaMedia.
sider a single low-level descriptor to provide a high-
level degree of distinguishability among objects. In
order to generate robust and complex representation
of objects, a multi-descriptor feature space is con-
structed to represent objects extracted from surveil-
lance videos (Mojsilovic, 2005). The combination of
low-level-features to obtain higher order representa-
tions have been addressed over the years in pattern
recognition. For instance, in (Zhang and Izquierdo,
2007; Soysal and Alatan, 2003) authors proposed ap-
proaches that used combination of multiple low-level
features to index and retrieve media items. However,
to the best of our knowledge, such feature fusion ap-
proaches has not yet been applied for object retrieval
from surveillance video datasets.
In this paper, we present an optimal combination
of low-level feature spaces appropriate for surveil-
lance object retrieval. Besides, in order to study
the performance of the proposed multi-feature space
a comparison against the individual features perfor-
mance along with a linear combination of selected
features is presented. The proposed retrieval frame-
work exploits the recent developments in evolution-
ary computational algorithms based on biologically
inspired optimisation techniques. Recent develop-
ments in optimisation techniques have been inspired
by problem solving abilities of biological organisms
such as bird flocking and fish schooling. One such
technique developed by Eberhart and Kennedy is
called Particle Swarm Optimisation (PSO)(Kennedy
and Eberhart, 2001). The proposed approach has been
187
Fernandez Arguedas V., Chandramouli K., Zhang Q. and Izquierdo E..
OPTIMAL COMBINATION OF LOW-LEVEL FEATURES FOR SURVEILLANCE OBJECT RETRIEVAL.
DOI: 10.5220/0003527101870192
In Proceedings of the International Conference on Signal Processing and Multimedia Applications (SIGMAP-2011), pages 187-192
ISBN: 978-989-8425-72-0
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

evaluated against three kernel machines for objects
extracted surveillance dataset. From the study of eval-
uation results, we note the improved performance of
the proposed approach across all concepts as opposed
to improved performance for a single concept. The
dataset has been specifically designed to be noisy in
order to measure the robustness of the proposed opti-
mal combination of the low-level feature space.
The remainder of the paper is structured as fol-
lows. In Section 2, an overview of the proposed
surveillance object retrieval framework is presented
followed by a brief introduction of Particle Swarm
classifier in Section 3. Section 4 outlines the contribu-
tion of optimally combining low-level visual descrip-
tor space. The experimental results are discussed in
Section 5, followed by conclusion and future work in
Section 6.
2 SURVEILLANCE OBJECT
RETRIEVAL FRAMEWORK
The proposed surveillance object retrieval framework
is presented in Fig.1. The framework integrates a
training phase, a feature extraction component and
object retrieval module. The training phase consists
of the multi-feature fusion algorithm, which is used
to create visual models to enable optimal combina-
tion of multiple low-level features. The multi-feature
fusion algorithm is discussed in detail in Section 4. In
the feature extraction phase, the video is subjected to
motion analysis component to extract the blobs from
the surveillance videos. The motion analysis compo-
nent is based on an adaptive background subtraction
algorithm based on Stauffer and Grimson approach
(Stauffer and Grimson, 2000), followed by a spatial
segmentation based on connected components and a
temporal segmentation performed by a linearly pre-
dictive multi-hypothesis tracker. Finally, the retrieval
phase is based on the particle swarm classifier. The
classifier is based on evolutionary computation mod-
els, simulating the effects of fish schooling and bird
flocks. The classifier is implemented for the multi-
descriptor feature space whose performance is influ-
enced by the weights derived for non-linear optimal
combination of low-level feature space. The outcome
of the classifier is a ranked list of objects retrieved
from the image database, which are further evaluated
against ground truth.
Due to surveillance videos nature, a really time-
consuming analysis processes a huge amount of infor-
mation, where most of it belong to their quasi-static
background proving no useful data. Motion analy-
sis component’s objective is to improve the computa-
Figure 1: Framework overview.
tional efficiency of the system and to provide move-
ment information about the surveillance video ob-
jects. The three-step real-time Motion Analysis Com-
ponent procures individual blobs to the Low-level fea-
ture extraction Component. Despite many advantages
of the use of the Motion Analysis Component, object
detection from surveillance videos is affected by sev-
eral external factors as highlighted in Fig.2.
3 PARTICLE SWARM
CLASSIFIER
In the PSO algorithm (Eberhart and Shi, 2001), the
birds in a flock are symbolically represented as par-
ticles. A particle’s location in the multidimensional
problem space represents one solution for the prob-
lem. When a particle moves to a new location, a dif-
ferent solution to the problem is generated. The par-
ticles at each time step are considered to be moving
towards particle’s personal best (pbest) and swarm’s
global best (gbest). The motion is attributed to the ve-
locity and position of each particle. Acceleration (or
velocity) is weighted with individual parameters gov-
erning the acceleration being generated for c
1
and c
2
.
The equations governing the velocity and position of
each particle are presented in Eq. 1 and 2.
v
it
(t + 1) = v
id
(t) + c
1
(pbest
i
(t) − x
id
(t))
+ c
2
(gbest
d
(t) − x
id
(t)) (1)
x
id
(t + 1) = x
id
(t) + v
id
(t + 1) (2)
where v
id(t)
represents the velocity of particle x
in d− dimension at time t, pbest
i
(t) represents the
personal best solution of particle i at time t, gbest
d
(t)
represents the global best solution for d− dimension
at time t, x
id
(t) represents the position of the particle
SIGMAP 2011 - International Conference on Signal Processing and Multimedia Applications
188

Figure 2: Motion analysis component results. Background
subtraction and spatial segmentation techniques results can
be observed for two different problematic situations as
low quality image (top-left),videos with inaccurate back-
ground substration (top-right), videos with camera move-
ment (bottom-left) and objects merged due to noise and
shadow (bottom-right).
x in d− dimension at time t and c
1
, c
2
are constant
parameters.
The first part of Eq. 1 represents the velocity at
time t, which provides the necessary momentum for
particles to move in the search space. During the ini-
tialisation process, the term is set to ‘0’ to symbolise
that the particles begin the search process from rest.
The second part is known as the “cognitive compo-
nent” and represents the personal memory of the in-
dividual particle. The third term in the equation is the
“social component” of the swarm, which represents
the collaborative effort of the particles in achieving
the globally best solution. The social component al-
ways clusters the particles toward the global best so-
lution determined at time t.
The PSO optimisation has been applied to im-
prove the performance of Self Organising Maps
(SOM), which is based on competetive learning
scheme as discussed by Xu et al in (Xu and II, 2005).
Briefly, the basic SOM training algorithm the input
training vectors are trained with Eq. 3
m
n
(t + 1) = m
n
(t) + g
cn
(t)[x− m
n
(t)], (3)
where m is the weight of the neurons in the SOM
network, g
cn
(t) is the neighbourhood function that is
defined as in Eq. 4,
g
cn
(t) = α(t)exp(
||r
c
− r
i
||
2
2α
2
(t)
), (4)
The PSO optimisation is achieved by evaluating
the L1 norm between the input feature vector and the
feature vector of the winner node. The global best so-
lution obtained after the termination of the PSO algo-
rithm is assigned as the feature vector of the winner
node. The training process is repeated until all the
input training patterns are exhausted. In the testing
phase, the distance between the input feature vector
is compared against the trained nodes of the network.
The label associated with the node is assigned to the
input feature vector.
4 MULTI-OBJECTIVE
OPTIMISATION TECHNIQUE
In this paper, a fusion technique of multiple visual
descriptors called Multi-objective optimisation tech-
nique (MOO) is presented. The objective is to learn
associations between complex combinations of low
level visual descriptors and the semantic concepts un-
der study. As a result, the visual descriptors associa-
tion is expected to complement each other improving
their individual performance and overcoming their in-
dividual flaws. MOO aims to reduce the influence
of noise coming from the background and identify
an optimal mixture of visual descriptors to describe
each semantic concept. In fact, the descriptors are
combined according to a concept-specific metric, ac-
quired during a training/learning stage from a set of
representative blobs.
The challenge in Multiple-objective optimisation
technique (MOO) is to find an optimal metric combin-
ing several low-level features and the suitable weights
for such a combination. The MOO technique is a four-
step process (Zhang and Izquierdo, 2007):
1. Distance Matrix Calculation. Four low-level
features were extracted for each blob provided by
the motion analysis. The provided training dataset is
composed of as many entries as the number of train-
ing blobs, K, and four descriptors per blob. Consider-
ing all the entries of the dataset, composed of multiple
descriptors. Foe each of such descriptor, a centroid is
calculated generating a virtual centroid vector called
¯
V = (¯v
F
1
, ¯v
F
2
, ¯v
F
3
, ¯v
F
4
). Then, every distance between
each blob low-level-feature descriptor and the respec-
tive centroid vector is calculated, obtaining the multi-
feature distance matrix, D, which is the basis to build
the objective functions for optimisation.
2. Objective Functions Formulation. In order
to calculate an appropriated combined metric, a
weighted linear combination of the feature descriptor
distances (also called objective function) is proposed:
D
(k)
(V
(k)
,
¯
V, A) =
L
∑
l=1
α
l
d
(k)
l
( ¯v
l
, v
(k)
l
), (5)
where, d
(k)
1
is the distance between the blob’s low-
level-feature descriptors and the centroids and α
l
the
OPTIMAL COMBINATION OF LOW-LEVEL FEATURES FOR SURVEILLANCE OBJECT RETRIEVAL
189

elements of the set of weighting coefficients to opti-
mise.
3. Multi-objective Optimisation and Pareto Opti-
mum. The challenge consists of optimising the set
of formulated objective functions and therefore, opti-
mising α
l
, in order to represent every semantic object
with a suitable mixture of low-level-feature descrip-
tors. However, two aspects need to be taken into con-
sideration: (i) single optimisation of each object func-
tion may lead to biased results; (ii) the contradictory
nature of low-level-feature descriptors should be con-
sidered in the optimisation process. The existence of
several objective functions ensures better discrimina-
tion power compared to using a single objective func-
tion. Consequently, a set of compromised solutions,
known as Pareto-optimal solutions are generated us-
ing the multi-objective optimisation-strategy that re-
lies on a local search algorithm. Individual Pareto-
optimal solutions cannot be consider better than the
others without further consideration. Therefore, a set
of conditions are allocated to choose the most suit-
able Pareto-optimal solution, (i) to minimise the ob-
ject functions of the negative training samples, (ii) to
maximise the object functions of the positive training
samples and (iii) the sum of the elements of A must
fulfil
∑
K
l=1
α
l
= 1.
Once the requirements have been set, a decision
making step must take place, to find a unique solution
which minimise the ratio between (i) and (ii):
min
∑
K
k=1
D
(k)
+
(V
(k)
,
¯
V, A
s
)
∑
K
k=1
D
(k)
−
(V
(k)
,
¯
V, A
s
)
, s = 1, 2, ..., S (6)
where D
(k)
−
and D
(k)
+
are the distances over positive
and negative training samples respectively, while, A
s
is the s
th
in the set of Pareto-optimal solutions, and S
is the number of available Pareto-optimal solutions.
4. Similarity Matching Function. The optimised
Multi-feature matching function for any blob example
is calculated by:
D
MOO
(V,
¯
V, A) =
L
∑
l=1
α
l
d
l
(v
l
, ¯v
l
), (7)
the resulting values D
MOO
(V,
¯
V, A) represent the
likelihood of a blob to contain a certain concept, in
our case Person or Car (concepts considered positive
while computing Eq. (6)).
Figure 3: Representative set of blobs from the Ground truth,
which resolution is also presented.
5 EXPERIMENTAL EVALUATION
AVSS 2007 dataset
2
was used to evaluate the pre-
sented surveillance video retrieval approach provid-
ing indoor and outdoor videos summing a total of
35000 frames. For evaluation purposes, three outdoor
videos were selected at different levels of difficulty.
A total of 1377 objects were included and manually
annotated in the ground truth, of which 50% of ob-
jects were annotated as “Cars” against 10% annotated
as “Person” and the remaining 40% were annotated as
“Unknown”. Instead of ignoring the blobs labelled as
“Unknown”, our dataset included these blobs to ex-
plicitly study the effect of noise on the performance
of the retrieval models. An overview of the dataset
used for the evaluation of the proposed framework
is presented in Fig. 3. Besides less than 6% of the
ground truth was selected to form the training dataset
which was used to train the Multi-objective optimisa-
tion component.
5.1 MPEG-7 Visual Feature Extraction
In this section, a short description of the set of se-
lected MPEG-7 descriptors, chosen by their robust-
ness, compact representation and significance for hu-
man perception is presented.
Colour Layout Descriptor (CLD) is a very com-
pact and resolution-invariant representation of the
spatial distribution of colour in an arbitrarily-shaped
region (Sikora, 2002).
Colour Structure Descriptor (CSD) describes
spatial distribution of colour in an image, but unlike
colour histograms, CSD also describes local colour
spatial distribution.
Dominant Colour Descriptor (DCD) describes
global as well as local spatial colour distribution in
images for fast search and retrieval. DCD provides a
description on the distribution of the colour within an
analysed image by storing only the a small number of
representative colours or dominant colours.
2
http://www.eecs.qmul.ac.uk/˜andrea/avss2007 d.html
SIGMAP 2011 - International Conference on Signal Processing and Multimedia Applications
190
Edge Histogram Descriptor (EHD) provides a de-
scription for non-homogeneous texture images and
captures the spatial distribution of edges whilst pro-
viding ease of extraction, scale invariance and support
for rotation-sensitive and rotation-invariant matching.
5.2 Experimental Evaluation of Particle
Swarm Optimisation
The PSO model implemented is a combination of
cognitive and social behaviour. The structure of the
PSO is fully connected in which a change in a par-
ticle affects the velocity and position of other par-
ticles in the group as opposed to partial connectiv-
ity, where a change in a particle affects the limited
number of neighbourhood in the group. Each dimen-
sion of the feature set is optimized with 50 particles.
The size of the SOM network is pre-fixed with the
maximum number of training samples to be used in
the network. The stopping criteria threshold is ex-
perimentally determined for different individual fea-
ture space. The value of the threshold indicated the
closeness in solving the optimization problem. In Fig.
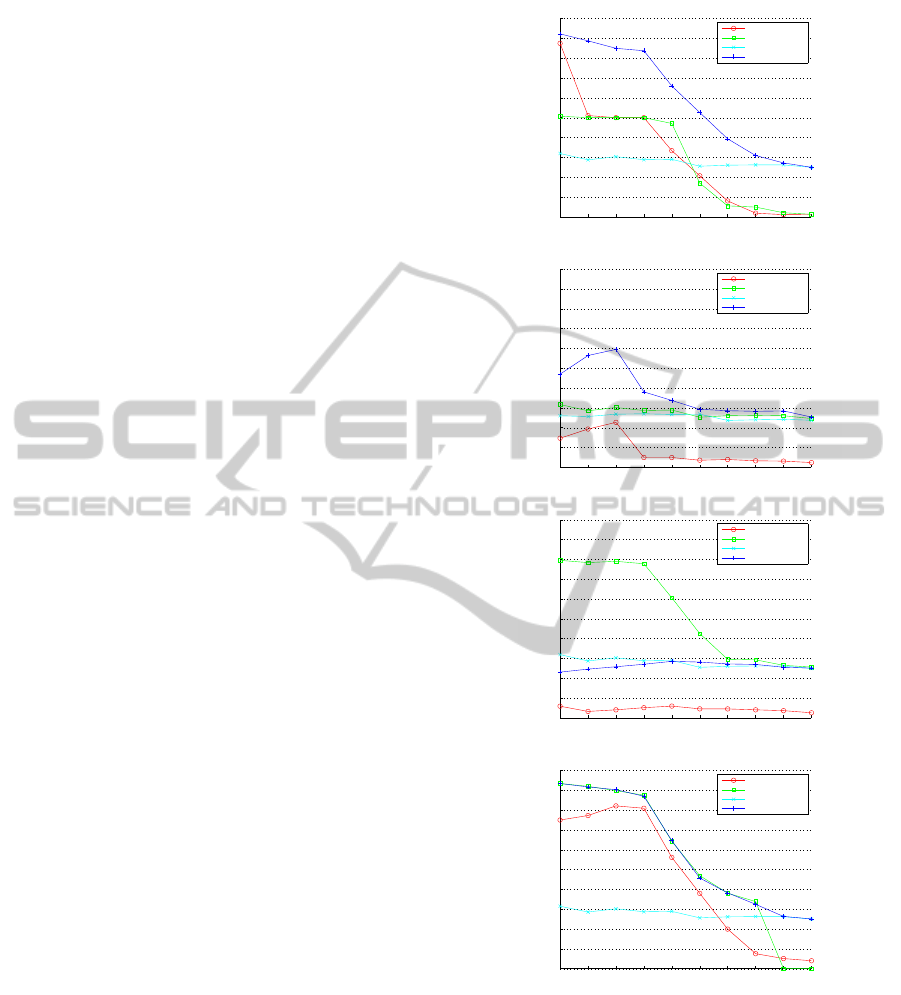
4, performance comparison of PSO based retrieval is
evaluated against different kernels of Support Vector
Machines (SVM). As it is noted from the results, the
performance of the classifier varies according to the
feature space. This could be largely attributed to the
extraction of different features and the matching func-
tions involved in these distinct spaces. From the re-
sults, we can see that CLD space is quite optimal for
retrieving the concept ’Car’, while for concept ’Per-
son’, the retrieval performance drops beyond recall
at 0.5. Similar interpretations could be extrapolated
from CSD feature space where the performance for
retrieving ’Car’ is higher than for concept ’Person’.
5.3 Evaluation of Optimal Combination
of Low-level Feature Space
In Fig. 5, precision-recall curve for the concept ’Car’
is presented with performance comparison of PSO
algorithm with optimal and primitive low-level fea-
ture fusion technique. As it can been, the primitive
combination of the feature vector, drops in retrieval
performance at lower recall, but remains competitive
over mid-range recall values. On the other hand, the
optimal combination achieves improved retrieval per-
formance for lower recall values. However, the re-
trieval performance drops over mid-range recall and
for 0.83 recall both techniques achieve same preci-
sion. Interestingly, from the study of results for the
concept “Person”, it can be easily noted that, the per-
formance of optimal combination of feature vector is
10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
0
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
recall
average precision
Individual Performance for CLD
SVM−polynomial
SVM−radial
SVM−sigmoid
PSO
10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
0
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
recall
average precision
Individual performance for CSD
SVM−polynomial
SVM−radial
SVM−sigmoid
PSO
10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
0
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
recall
average precision
Individual Performance for DCD
SVM−polynomial
SVM−radial
SVM−sigmoid
PSO
10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
0
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
recall
average precision
Indivisual Performance for EHD
SVM−polynomial
SVM−radial
SVM−sigmoid
PSO
Figure 4: Performance of Particle Swarm and Kernal Ma-
chines in Individual Feature Space for Concepts ’Car’ and
’Person’.
much better compared to its primitive counter part,
refer to Fig. 6. The improved performance of the
optimal combination of low-level features could be
attributed to the fact that, the optimisation technique
determines appropriate weights for all concepts in the
multi-descriptor space, achieving a overall balanced
solution. With the aim of obtaining global perfor-
OPTIMAL COMBINATION OF LOW-LEVEL FEATURES FOR SURVEILLANCE OBJECT RETRIEVAL
191
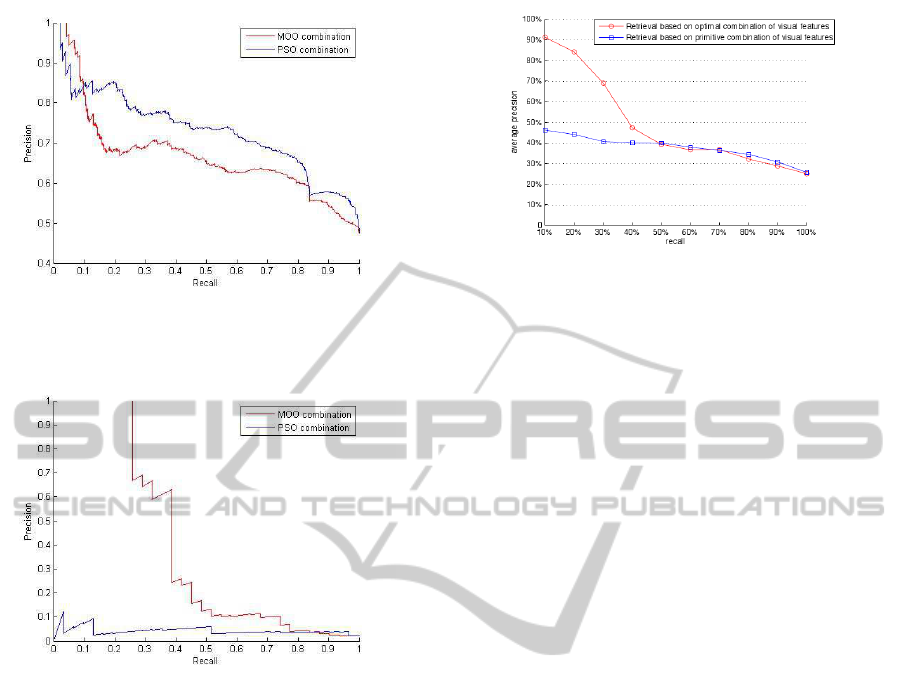
Figure 5: Precision-Recall curve for Surveillance Object
Retrieval using optimal combination and primitive combi-
nation for concept Car.
Figure 6: Precision-Recall curve for Surveillance Object
Retrieval using optimal combination and primitive combi-
nation for concept Person.
mance, we clearly note that the optimal combination
of low-level feature space performs better compared
to the primitive combination as highlighted in FIg. 7.
The average performance obtained over two concepts
for optimal combination is nearly 40% more than the
primitive combination at 0 recall. However, from
50% recall both technique provide similar results with
respect to average precision-recall.
6 CONCLUSIONS & FUTURE
WORK
In this paper, an optimal combination of low-level
descriptor space was presented for surveillance ob-
ject retrieval. The optimal combination of multi-
descriptor space was evaluated against individual de-
scriptor space using Particle Swarm Classifier and
three support vector machines kernels. In addition,
an evaluation of optimally combined feature space
was evaluated against a primitive combination of fea-
Figure 7: Average Precision-Recall curve for Surveillance
Object Retrieval using optimal combination and primitive
combination across both concepts.
ture space. Moreover, a detailed study of the results
was carried out. As noted in the results, the proposed
retrieval framework achieves 40% improvement over
the primitive combination and more importantly con-
sistent performance is obtained across different con-
cepts. For the future work we will extend the study to
include more concepts and novel non-MPEG-7 visual
features. Similarly, a relevance feedback module will
be included for online training of the system.
REFERENCES
Chandramouli, K. and Izquierdo, E. (2010). Image Re-
trieval using Particle Swarm Optimization, pages
297–320. CRC Press.
Eberhart, R. and Shi, Y. (2001). Tracking and optimiz-
ing dynamic systems with particle swarms. Evolu-
tionary Computation, 2001. Proceedings of the 2001
Congress on, 1.
Kennedy, J. and Eberhart, R. C. (2001). Swarm intelligence.
Morgan Kaufmann.
Mojsilovic, A. (2005). A computational model for color
naming and describing color composition of images.
Image Processing, IEEE Trans., 14(5):690–699.
Sikora, T. (2002). The MPEG-7 Visual standard for con-
tent description-an overview. Circuits and Systems for
Video Technology, IEEE Trans., 11(6):696–702.
Soysal, M. and Alatan, A. (2003). Combining MPEG-7
based visual experts for reaching semantics. Visual
Content Processing and Representation, pages 66–75.
Stauffer, C. and Grimson, W. (2000). Learning patterns of
activity using real-time tracking. Pattern Analysis and
Machine Intelligence, IEEE Trans., 22(8):747–757.
Xu, R. and II, D. W. (2005). Survey of clustering algo-
rithms. IEEE Trans. Neural Network, 6(3):645–678.
Zhang, Q. and Izquierdo, E. (2007). Combining low-level
features for semantic inference in image retrieval.
Journal on Advances in Signal Processing.
SIGMAP 2011 - International Conference on Signal Processing and Multimedia Applications
192
