
SEMANTIC INDEXING OF WEB PAGES VIA PROBABILISTIC
METHODS
In Search of Semantics Project
Fabio Clarizia, Francesco Colace, Massimo De Santo and Paolo Napoletano
Department of Information Engineering and Electrical Engineering, University of Salerno
Via Ponte Don Melillo 1, 84084 Fisciano, Italy
Keywords:
Semantic index, Information Retrieval, Web Search Engine, Latent Dirichlet Allocation.
Abstract:
In this paper we address the problem of modeling large collections of data, namely web pages by exploiting
jointly traditional information retrieval techniques with probabilistic ones in order to find semantic descrip-
tions for the collections. This novel technique is embedded in a real Web Search Engine in order to provide
semantics functionalities, as prediction of words related to a single term query. Experiments on different small
domains (web repositories) are presented and discussed.
1 INTRODUCTION
Modern search engines rely on keyword matching and
link structure (cfr. Google and its Page Rank algo-
rithm (Brin, 1998)), but the semantic gap is still not
bridged.
The semantics of a web page is defined by its
content and context, understanding of textual docu-
ments is yet beyond the capability of todays artifi-
cial intelligence techniques, and the many multime-
dia features of a web page make the extraction and
representation of its semantics even more difficult.
As well known any writing process can be thought
as a process of communication where the main actor,
namely the writer, encode his intentions through the
language. Therefore the language can be considered
as a code that conveys what we can call “meaning”
to the reader that performs a process for decoding it.
Unfortunately, due to the accidental imperfections of
human languages, contingent imperfections may oc-
curs then both encoding and decoding processes are
corrupted by “noise”, are ambiguous in practice.
We argue that the meaning is never fully present
in a sign, but it is the limit point of a temporal, sit-
uated process, in which the text acts as a boundary
conditions and in which the user is the protagonist.
Following these claims we argue that semantic dis-
covering and its representation could emerge through
the interaction of facets, texts and users, that we call
light and deep semantics.
In this direction Semantic Web (Berners-Lee et al.,
2001) and Knowledge Engineering communities are
both confronted with the endeavor to design different
tools and languages for describing semantics in or-
der to avoid the ambiguity of the encoding/decoding
process. In the light of this discussions specific lan-
guage has been introduced, RDF (Resource Descrip-
tion Framework), OWL (Ontology Web Language),
etc., to support the creator (writer) of documents in
describing semantic relations between concept/words,
namely the metadata of the documents. During such
a process of creation all the elements of ambiguity
should be avoided because of use of a shared knowl-
edge based on ontology as mean for semantics repre-
sentation.
As a consequence the Web should be entirely re-
written in order to semantically arrange the content of
each web pages, but this process can not be still real-
ized, due to the huge amount of existent data and ab-
sence of definitive tools for managing and manipulat-
ing those languages. In the meantime, waiting for the
semantic web starting, we could design tools for au-
tomatically revealing and managing semantics of the
previous web by using methods and tools that don’t
ground on any web semantic specification.
In this direction, this paper deals with the prob-
lem of modeling large collections of data, namely web
pages by exploiting jointly traditional information re-
trieval techniques with probabilistic ones in order to
find semantic descriptions for the collections. This
novel technique is embedded in a real Web Search
Engine, in order to provide semantics functionalities,
134
Clarizia F., Colace F., De Santo M. and Napoletano P. (2009).
SEMANTIC INDEXING OF WEB PAGES VIA PROBABILISTIC METHODS - In Search of Semantics Project.
In Proceedings of the 11th International Conference on Enterprise Information Systems - Software Agents and Internet Computing, pages 134-140
DOI: 10.5220/0002010401340140
Copyright
c
SciTePress

as prediction of words related to a single term query.
Experiments on different small domains (web reposi-
tories) are presented and discussed.
The paper is organized as follows. In Section 2 we
introduce basic notions about traditional and proba-
bilistic indexing techniques. A probabilistic model,
namely the topic model, is presented in Section 3
where a procedure for single and multi-words predic-
tion is presented. An algorithm for building a seman-
tic indexing is illustrated in Section 4 where illustra-
tive examples of real environment are provided. Fi-
nally, in Section 5 we present some conclusions.
2 FROM TRADITIONAL TO
PROBABILISTIC INDEXING
TECHNIQUES
Several proposal have been made by researchers
for the information retrieval (IR) problem (R. and
Ribeiro-Neto, 1999). The basic methodology pro-
posed by IR researchers for text corpora - a methodol-
ogy successfully deployed in modern Internet search
engines - reduces each document in the corpus to a
vector of real numbers, each of which represents ra-
tios of counts. Following this methodology we ob-
tain the popular term frequencyinverse document fre-
quency (tf-idf ) scheme (Salton and McGill, 1983),
where a basic vocabulary of “words” or “terms” is
chosen, and, for each document in the corpus, a count
is formed of the number of occurrences of each word.
After suitable normalization, suitable comparison be-
tween term frequency count and inverse document
frequency count, we obtain the term-by-document
matrix W whose columns contain the tf-idf values for
each of the documents in the corpus.
Thus the tf-idf schema reduces documents of ar-
bitrary length to fixed-length lists of numbers, and it
also provides a relatively small amount of reduction
in description length and reveals little in the way of
inter- or intradocument statistical structure. The la-
tent semantic indexing(LSI) (Deerwester et al., 1990)
technique has been proposed in order to address these
shortcomings. Such method uses a singular value de-
composition of the W matrix to identify a linear sub-
space in the space of tf-idf features that captures most
of the variance in the collection. This approach can
achieve significant compression in large collections.
Moreover, a significant step forward a full prob-
abilistic approach to dimensionality reduction tech-
niques was made by Hofmann (Hofmann, 1999), who
presented the probabilistic LSI (pLSI) model, also
known as the aspect model, as an alternative to LSI.
The pLSI approach models each word in a document
as a sample from a mixture model, where the mixture
components are multinomial random variables that
can be viewed as representations of “topics”. Thus
each word is generated from a single topic, and differ-
ent words in a document may be generated from dif-
ferent topics. Each document is represented as a list
of mixing proportions for these mixture components
and thereby reduced to a probability distribution on
a fixed set of topics. This distribution is the reduced
description associated with the document.
While Hofmanns work is a useful step toward
probabilistic modeling of text, it is incomplete in that
it provides no probabilistic model at the level of doc-
uments leading to several problems: overfitting and
probability assignment to a document outside of the
training set is unclear. In order to overcome these
problems a new probabilistic method has been in-
troduced, called Latent Dirichlet Allocation (LDA)
(Blei et al., 2003) that we exploit in this paper in or-
der to catch essential statistical relationships between
words contained in web pages’ index. This method is
based on the bag-of-words assumption - that the or-
der of words in a document can be neglected. In the
language of probability theory, this is an assumption
of exchangeability for the words in a document (Al-
dous, 1985), which holds also for documents; the spe-
cific ordering of the documents in a corpus can also
be neglected. A classic representation theorem es-
tablishes that any collection of exchangeable random
variableshas a representation as a mixture distribution
- in general an infinite mixture. Thus, if we wish to
consider exchangeable representations for documents
and words, we need to consider mixture models that
capture the exchangeability of both words and doc-
uments. In this paper we propose an hybrid proposal
where the LDA technique is embedded in a traditional
technique procedure, the tf-idf schema. More details
are discussed next.
3 PROBABILISTIC TOPIC
MODEL: LDA MODEL
As discussed before a variety of probabilistic topic
models have been used to analyze the content of doc-
uments and the meaning of words. These models all
use the same fundamental idea that a document is
a mixture of topics but make slightly different sta-
tistical assumptions. In this paper we use the topic
model, discussed in (T. L. Griffiths, 2007) based on
the LDA algorithm (Blei et al., 2003), where statistic
dependence among words is assumed. By following
this approach, 4 problems have to be solved: word
SEMANTIC INDEXING OF WEB PAGES VIA PROBABILISTIC METHODS - In Search of Semantics Project
135

Figure 1: Graphical Models (T. L. Griffiths, 2007) rely-
ing on Latent Dirichlet allocation (Blei et al., 2003). Such
Graphical Models (GM) don’t allow relations among words
by assuming statistical independence among variables.
patching, prediction, disambiguation and gist extrac-
tion, resulting in the GM reported in Figure 1.
Assume we have seen a sequence of words w =
(w
1
, . . . , w
n
). These n words manifest some latent se-
mantic structure l. We will assume that l consists of
the gist of that sequence of words g and the sense or
meaning of each word, z = (z
1
, . . . , z
n
), so l = (z, g).
We can now formalize the four problems identified in
the previous section:
• Word patching: Compute (w
i
, w
j
) from w.
• Prediction: Predict w
n+1
from w.
• Disambiguation: Infer z from w.
• Gist extraction: Infer g from w.
Each of these problems can be formulated as a sta-
tistical problem. In this model, latent structure gener-
ates an observed sequence of words w = (w
1
, . . . , w
n
).
This relationship is illustrated using graphical model
notation (Bishop, 2006). Graphical models provide
an efficient and intuitive method of illustrating struc-
tured probability distributions. In a graphical model, a
distribution is associated with a graph in which nodes
are random variables and edges indicate dependence.
Unlike artificial neural networks, in which a node
typically indicates a single unidimensional variable,
the variables associated with nodes can be arbitrar-
ily complex. The graphical model shown in Figure
1 is a directed graphical model, with arrows indicat-
ing the direction of the relationship among the vari-
ables. The graphical model shown in the figure indi-
cates that words are generated by first sampling a la-
tent structure, l, from a distribution over latent struc-
tures, P(l), and then sampling a sequence of words,
w, conditioned on that structure from a distribution
P(w|l). The process of choosing each variable from a
distribution conditioned on its parents defines a joint
distribution over observed data and latent structures.
In the generative model shown in Figure 1, this joint
distribution is P(w, l) = P(w|l)P(l). With an appro-
priate choice of l, this joint distribution can be used
to solve the problems of word patching, prediction,
disambiguation, and gist extraction identified above.
In particular, the probability of the latent structure l
given the sequence of words w can be computed by
applying Bayes’s rule:
P(l|w) =
P(w|l)P(l)
P(w)
(1)
where
P(w) =
∑
l
P(w, l)P(l) (2)
This Bayesian inference involves computing a proba-
bility that goes against the direction of the arrows in
the graphical model, inverting the generative process.
Equation 2 provides the foundation for solving
the problems of word patching, prediction, disam-
biguation, and gist extraction.
Summing up:
• Word patching
P(w
i
, w
j
) =
∑
w−(w
i
,w
j
)
∑
l
P(w, l)P(l) (3)
• Prediction
P(w
n+1
, w) =
∑
l
P(w
n+1
|l, w)P(l|w) (4)
• Disambiguation
P(z|w) =
∑
g
P(l|w) (5)
• Gist extraction
P(g|w) =
∑
z
P(l|w) (6)
We will use a generative model introduced by Blei
et al. (Blei et al., 2003) called latent Dirichlet alloca-
tion. In this model, the multinomial distribution rep-
resenting the gist is drawn from a Dirichlet distribu-
tion, a standard probability distribution over multino-
mials, e.g., (Gelman et al., 1995). The results of LDA
algorithm are two matrix:
1. the words-topics matrix Φ: it contains the proba-
bility that word w is assigned to topic j;
2. the topics-documents matrix Θ: contains the
probability that a topic j is assigned to some word
token in document d.
ICEIS 2009 - International Conference on Enterprise Information Systems
136
3.1 Single and Multi-words Prediction
Once we have the LDA computation for the index, we
can compute predictions and semantic relations be-
tween documents.
As reported in (T. L. Griffiths, 2007) we need the
single topic assumption for word prediction, namely
z
i
= z for all i. This single topic assumption makes
the mathematics straightforward and is a reasonable
working assumption for this real application.
This also suggests a natural measure of semantic
association, P(w
i
|w
j
), in practice, given the word w
j
(for a real IR environment it could be a single term
query) we compute the probability to predict the word
w
i
. More in general we have:
P(w
n+1
|w
n
) =
∑
z
P(w
n+1
|z)P(z|w
n
) (7)
Starting from the single word prediction we could
generalize and compute the multi-words prediction,
namely:
P(w
n+m
, ··· , w
n+1
|w
n
) = (8)
∑
z
P(w
n+m
, ··· , w
n+1
|z)P(z|w
n
) (9)
where m represents the number of words to be pre-
dicted. Each IR system performs term query function-
alities that, due the nature of language is ambiguos,
could not satisfy user intentions. A kind of single or
multi-words prediction could be useful in order to aid
the user to better perform his request.
4 SEMANTIC INDEXING FOR A
REAL ENVIRONMENT
We propose a new indexing technique that, exploiting
the topic model, reveals topics and semantic relations
between words for the corpora. The index of this web
search engine is composed of the traditional term-by-
document matrix W whose columns contain the tf-idf
values and the Θ and Φ matrix that are useful to com-
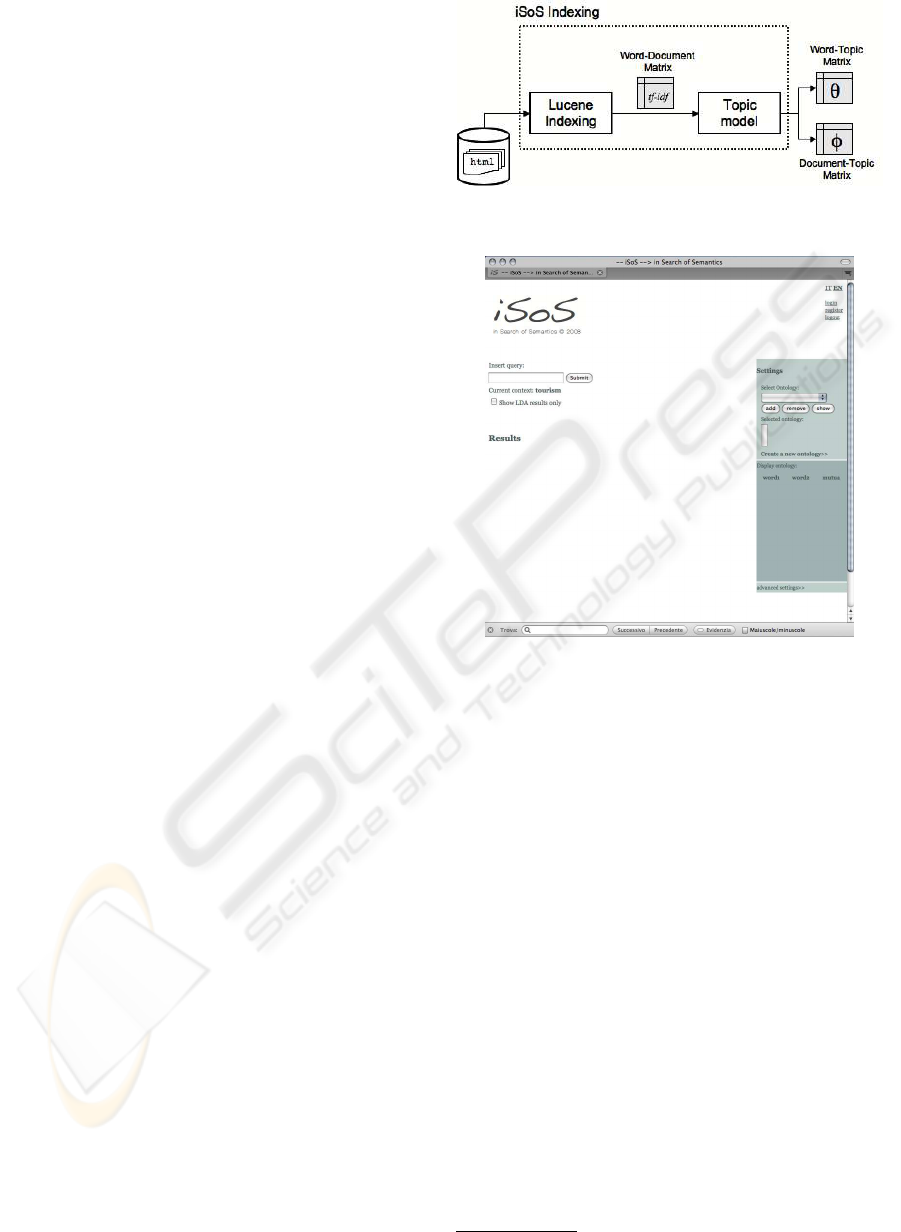
pute word prediction. In Fig. 2 is reported a diagram
for summarize this indexing procedure.
The probabilistic topic model is embedded in
a real web search engine developed at Univer-
sity of Salerno and reachable through the URL
http://193.205.164.64/isos after a registration proce-
dure. Such a web search engine is part of a research
project called in Search of Semantics (iSoS) which
aims to develop a framework for extracting/revealing,
representing and managing semantics of each kind of
documents - text, web pages etc.
Figure 2: in Search of Semantic indexing procedure.
Figure 3: in Search of Semantic web search engine screen-
shot.
The project aims at investigating how light and
deep semantics -and their mutual interaction - can
be modeled through probabilistic models of language
and through probabilistic models of human behaviors
(e.g., while reading and navigating Web pages), re-
spectively, in the common framework of most recent
techniquesfrom machine learning, statistics, informa-
tion retrieval, and computationallinguistics. In Figure
3 is showed a screenshot for the iSoS web search en-
gine and in following we describe its principal func-
tionalities.
4.1 in Search of Semantics:
Functionalities
As discussed above, iSoS is a web search engine with
advanced functionalities. This engine is a web based
application, entirely written in Java programminglan-
guage and Java Script Language embedding some of
the open source search engine Lucene
1
functionali-
ties. As basic functionalities it performs sintax query-
1
http://lucene.apache.org/
SEMANTIC INDEXING OF WEB PAGES VIA PROBABILISTIC METHODS - In Search of Semantics Project
137
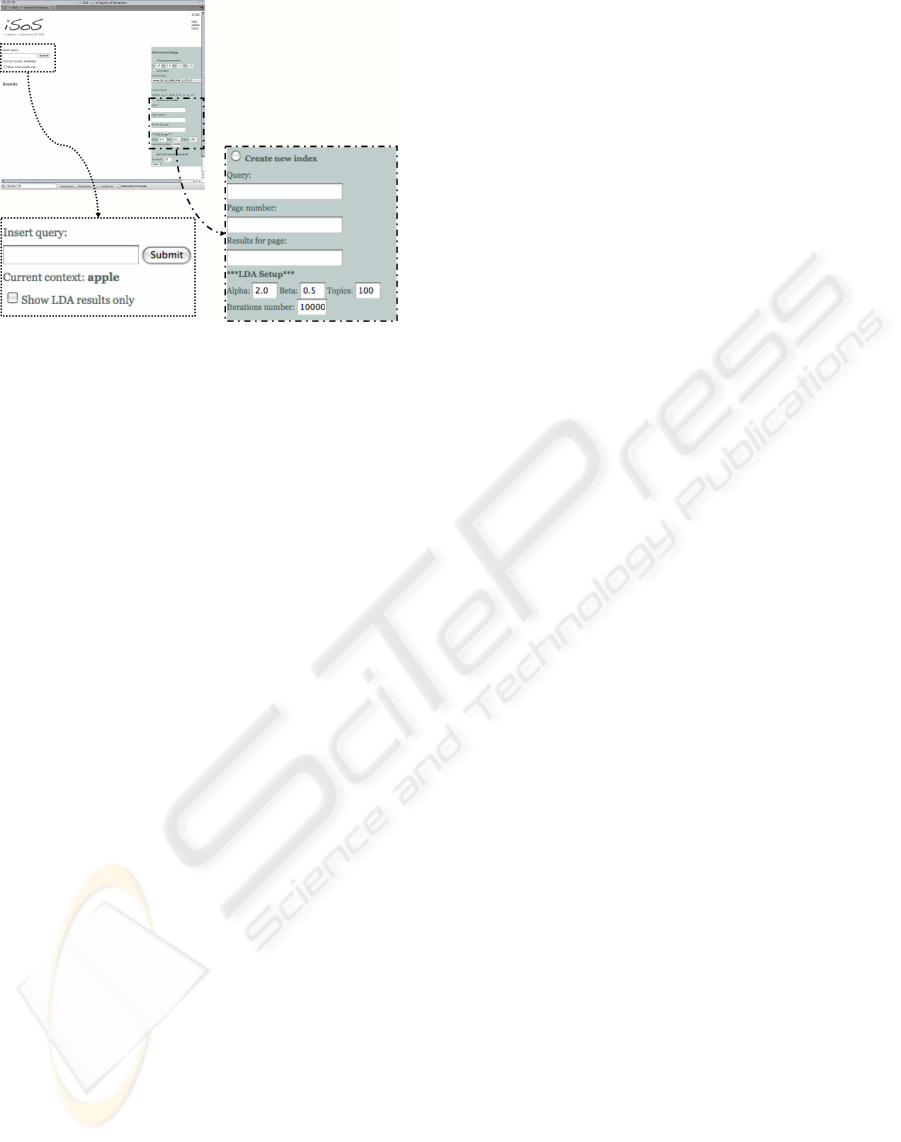
Figure 4: in Search of Semantic web search engine’s func-
tionalities screenshot.
ing, see the left side of Figure 4, and it gives results as
a list of web pages ordered by frequency of the term
query.
The iSoS engine operates, in the following or-
der: 1. Web crawling, 2. Indexing, 3. Searching.
Each web search engines work by storing informa-
tion about web pages, which are retrieved by a Web
crawler, a program which follows every link on the
web. In order to better evaluate the performance of
such web search engine, a small real environment is
created. It performs a simplified crawling stage by
submitting a query to a famous web search engine
Google (www.google.com), and crawling the URL
of the web pages contained in the list of results of
Google. In Fig. 5 we report the code for the crawling
stage.
During the indexing stage each page is indexed by
performing the semantics indexing process discussed
above.
The searching stage is composed of 2 main parts.
The first is a language parsing stage for the query,
where stop words like “as”, “of ” and “in”, are re-
moved and the second is a term searching stage in the
tf-idf schema. During this stage the words related to
the term query are predicted by using the Φ matrix.
4.2 Experimental Results
In order to show how the topic model is able to reveal-
ing semantics, we have indexed several web domain:
apple, bass and piano. For each domain we have cre-
ated a small web pages repository composed of 200
documents obtained by using the crawling procedure
discussed above, namely by referring to Fig. 4 for the
query apple we have:
query=apple, step=2, start=100
In the following we report result for the semantic
indexing and for the multi-word prediction we have
m = 6 for each domain. We used a java implementa-
tion of the LDA algorithm based on Gibbs sampling
and for all the experiments we used 50 topics.
4.2.1 Apple Domain
In Fig. 6 we show some list of words extracted from
the words-topics matrix Φ ordered by probability of
belonging to such topic. The lists are truncated to the
first 10 and then most probable words.
In Fig. 7 we show some multi-word prediction
processes obtained by submitting several query to the
iSoS web search engine: macbook , tree . We note that
for macbook word the semantic index gives really re-
lated words belonging to the Apple Inc. domain. For
what concerns the query tree we have words related
to apple fruit domain.
4.2.2 Bass Domain
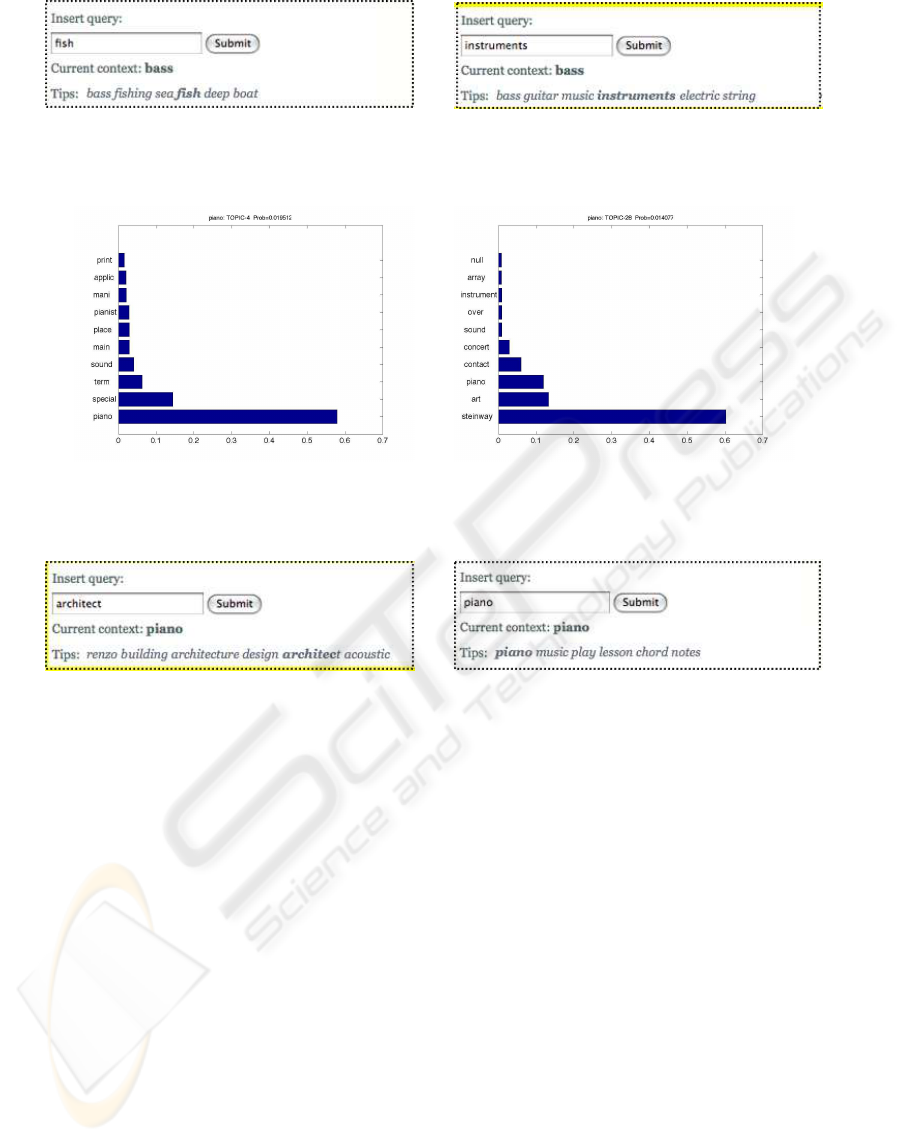
In Fig. 8 we show some list of words extracted from
the words-topics matrix Φ ordered by probability of
belonging to such topic. .
In Fig. 9 we show some multi-word prediction
processes obtained by submitting several query to the
iSoS web search engine: fish , instruments . We note
that for fish word the semantic index gives really re-
lated words belonging to the sea bass domain. For
what concerns the query instruments we have words
related to instruments domain.
4.2.3 Piano Domain
In Fig. 10 we show some list of words extracted from
the words-topics matrix Φ ordered by probability of
belonging to such topic. .
In Fig. 11 we show some multi-word prediction
processes obtained by submitting several query to the
iSoS web search engine: architect , piano . We note
that for architect word the semantic index gives really
related words belonging to the Renzo Piano Architect
domain. For what concerns the query instruments we
have words related to instruments domain.
5 CONCLUSIONS
In this work we presented a noveltechnique for index-
ing web pages based on a combination of traditional
and probabilistic method, the topic model. We have
experimented the proposed method in a real environ-
ment, a web search engine, namely 3 web domain for
both the topics revealing and multi-word prediction
ICEIS 2009 - International Conference on Enterprise Information Systems
138
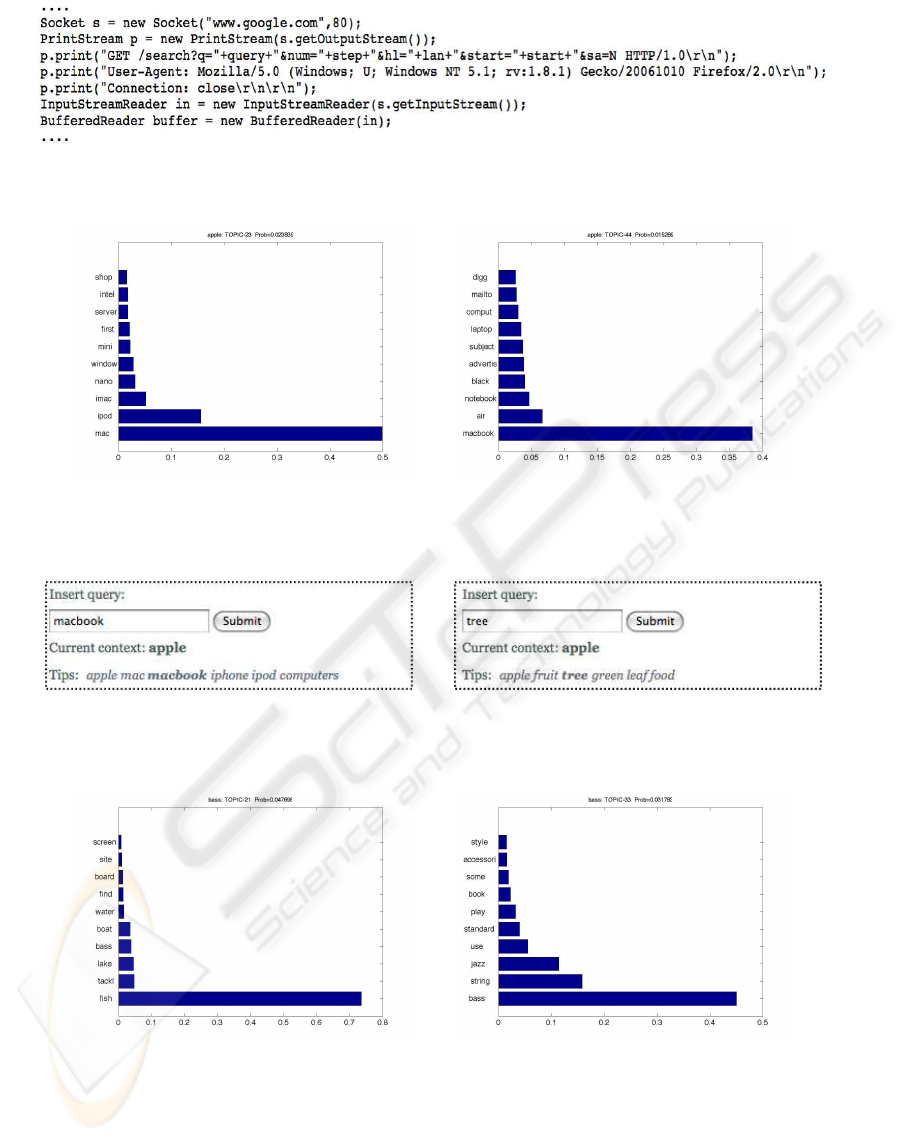
Figure 5: in Search of Semantic web search engine’s crawler.
(a) (b)
Figure 6: Apple domain topics example. 6(a) Computer shop topic.6(b) Apple Inc. topic.
(a) (b)
Figure 7: Apple domain prediction. 7(a) query word macbook.7(b) query word tree.
(a) (b)
Figure 8: Bass domain topics example. 8(a) Sea bass topic.8(b) Bass instrument topic.
tasks. The experiments confirm that such semantic
indexing teachnique reveals semantic relations among
words belonging to the same topic.
ACKNOWLEDGEMENTS
The authors wish to thank Luca Greco because part
of this work is developed during his Master thesis in
SEMANTIC INDEXING OF WEB PAGES VIA PROBABILISTIC METHODS - In Search of Semantics Project
139
(a) (b)
Figure 9: Bass domain prediction. 9(a) query word fish.9(b) query word instruments.
(a) (b)
Figure 10: Piano domain topics example. 10(a) Piano instrument topic.10(b) Concert topic.
(a) (b)
Figure 11: Piano domain prediction. 11(a) query word architect.11(b) query word piano.
Electronic Engineering at University of Salerno, su-
pervised by Prof. Massimo De Santo and Dr. Paolo
Napoletano.
REFERENCES
Aldous, D. (1985). Exchangeability and related topics. In
Springer, B., editor, Ecole d’ete de probabilites de
Saint-Flour XIII— 1983, pages 1–198.
Berners-Lee, T., Hendler, J., and Lassila, O. (2001). The
semantic web. Scientific American, May.
Bishop, C. M. (2006). Pattern Recognition and Machine
Learning. Springer.
Blei, D. M., Ng, A. Y., and Jordan, M. I. (2003). Latent
dirichlet allocation. Journal of Machine Learning Re-
search, 3(993–1022).
Brin, S. (1998). The anatomy of a large-scale hypertextual
web search engine. In Computer Networks and ISDN
Systems, pages 107–117.
Deerwester, S., Dumais, S., Landauer, T., Furnas, G., and
Harshman, R. (1990). Indexing by latent semantic
analysis. Journal of the American Society of Infor-
mation Science, 41(6):391–407.
Gelman, A., Carlin, J. B., Stern, H. S., and Rubin, D. B.
(1995). Bayesian data analysis. New York: Chapman
& Hall.
Hofmann, T. (1999). Probabilistic latent semantic indexing.
In Proceedings of the Twenty-Second Annual Interna-
tional SIGIR Conference.
R., B.-Y. and Ribeiro-Neto, B. (1999). Modern Information
Retrieval. ACM Press, New York.
Salton, G. and McGill, M. J. (1983). Introduction to modern
information retrieval. McGraw-Hill.
T. L. Griffiths, M. Steyvers, J. B. T. (2007). Topics
in semantic representation. Psychological Review,
114(2):211–244.
ICEIS 2009 - International Conference on Enterprise Information Systems
140
