
DELINEATING TOPIC AND DISCUSSANT TRANSITIONS IN
ONLINE COLLABORATIVE ENVIRONMENTS
Noriko Imafuji Yasui
1
, Xavier Llor
`
a
2
, David E. Goldberg
1
1
IllGAL, University of Illinois at Urbana-Champaign
104 S.Mathews Ave., Urbana, IL 61801, USA
2
NCSA, University of Illinois at Urbana-Champaign
1205 W.Clark St., Urbana, IL 61801, USA
Yuichi Washida and Hiroshi Tamura
Research and Development Division, Hakuhodo Inc.
Tokyo 108-8088, Japan
Keywords:
Online collaborative environments, Innovation and Creativity Support, Topic transition, HITS.
Abstract:
In this paper, we propose some methodologies for delineating topic and discussant transitions in online col-
laborative environments, more precisely, focus group discussions for product conceptualization. First, we
propose KEE (Key Elements Extraction) algorithm, an algorithm for simultaneously finding key terms and key
persons in a discussion. Based on KEE algorithm, we propose approaches for analyzing two important factors
of discussions: discussion dynamics and emerging social networks. Examining our approaches using actual
network-based discussion data generated by real focus groups in a marketing environment, we report interest-
ing results that demonstrate how our approaches could effectively discover knowledge in the discussions.
1 INTRODUCTION
In the last decades, mainstream communication has
been shifted to network-based ones. Network-based
communications which enable a great number of di-
verse people to join collaborative discussions are rich
repositories of innovative and creative ideas. The
methodological approaches for modeling, measur-
ing and analyzing the network-based communications
have become key elements to success in the fields of
decision making, problem solving, and total quality
management.
A goal of this paper is to delineate topic and dis-
cussant transitions in online collaborative environ-
ments, more precisely, focus group discussions for
product conceptualization. Toward the goal, first we
propose KEE algorithm for simultaneously finding
key terms and key persons in network-based discus-
sions. A key term is a significant word- or phrase-
indicative of innovative and creative ideas. A key per-
son is a significant participant having innovative and
creative ideas or potential for producing them. We
suppose a network-based discussion is (1) held for
enhancing innovation and creativity toward product
conceptualization, (2) based on participants posting
and replying messages (3) on online message boards
or chat rooms. Those discussions are made several
attempts with different focus groups.
One of the biggest advantages of the KEE algo-
rithm is its high applicability. We propose and exam-
ine approaches based on the KEE algorithm for ana-
lyzing discussions with two important factors: discus-
sion dynamics and social network. Observing topic
transitions and detecting topic segmentations lead to
making sense out of key terms, which helps us figur-
ing out the building block of innovative and creative
ideas (Llor
`
a et al., 2006). Detecting relationship be-
tween participants based on their significances lead to
grasping diffusion of key persons, which helps us fig-
uring out who had the innovative and creative ideas.
Both analyses are essential in planning strategies for
further discussions, including discussion theme set-
ting and re-grouping of participants.
The reminder of this paper is organized as follows.
Section 2 proposes the KEE algorithm, which is a
core algorithm for innovation and creativity oriented
mining from discussions. In Section 3, we propose
two approaches for analyzing discussions: discussion
dynamics and social networks. Section 4 reports the
experimental results with using real data collected in
real focus groups. Finally, this paper concludes in
Section 5 with summarizing and directions for future
work.
14
Imafuji Yasui N., Llorà X., E. Goldberg D., Washida Y. and Tamura H. (2007).
DELINEATING TOPIC AND DISCUSSANT TRANSITIONS IN ONLINE COLLABORATIVE ENVIRONMENTS.
In Proceedings of the Ninth International Conference on Enterprise Information Systems - AIDSS, pages 14-21
DOI: 10.5220/0002381000140021
Copyright
c
SciTePress

2 KEYS EXTRACTION BY KEE
Our goal is to find out key terms and key persons from
network- and text-based discussions. Suppose several
discussions are held with different groups of people.
In this section, we propose KEE (key elements extrac-
tion) algorithm. KEE enables us to find key persons
and key terms simultaneously. We also propose two
metrics used for the term weight: a generality and a
particularity.
2.1 Kee Algorithm
KEE (Key Elements Extraction) is an algorithm for
finding key persons and key terms of a discussion by
scoring participants and terms in the context of their
significance in discussions. Higher scored partici-
pants are key persons having innovative and creative
ideas or potential for producing them. Higher scored
terms are key terms indicating or leading to innovative
and creative ideas.
KEE is based on the idea of mutually reinforcing
relationship between participants and terms: signifi-
cant participants are the participants using many sig-
nificant terms, and conversely, significant terms are
the terms used by many significant participants. KEE
uses HITS (Hyperlink-Induced Topic Search) algo-
rithm (Kleinberg, 1999) in an unintended way. HITS
is an algorithm for ranking web pages in terms of hubs
and authorities. KEE is an algorithm applying HITS
framework to text mining, and obtains scores for rank-
ing participants and terms by an iterative calculation.
A discussion is represented by a weighted directed
bipartite graph G(V, E) where V and E are sets of
nodes and weighted edges, respectively. Let V
P
be
a set of participants of the discussion, and V
T
be a
set of terms used by the participants. V = V
P
∪ V
T
,
V
P
∩V
T
= φ. Let (p
i
,t
j
) and w(p
i
,t
j
) denote an edge
between p
i
∈ V
P
and t
j
∈ V
T
and its weight, respec-
tively. w(p
i
,t
j
)=m, if the participant p
i
used the term
t
j
m times.
Participants and terms are ranked by key scores of
participants (or participant scores for short) and key
scores of terms (or term scores for short). Let s(p
i
)
and s(t
i
) denote the key score of participant p
i
and the
key score of term t
i
, respectively. Similarly to HITS
algorithm (Kleinberg, 1999), the mutually reinforc-
ing relationship in KEE algorithm are as follows: If
the participant p
i
had used many terms with high key
scores, then he/she should receive a high participant
score; and if the term t
i
had been used by many par-
ticipants with high key score, then the term should
receive a high term score.
KEE algorithm obtains participant and term scores
simultaneously by an iterative calculation. Given par-
ticipant score s(p
i
) and term score s(t
j
), s(p
i
) and
s(t
j
) are updated by the following calculations. α(t
j
)
is a weighting factor for the term t
j
, which will be
argued in the next sub section.
s(p
i
) ←
∑
(p
i
,t
j
)∈E
s(t
j
) · w(p
i
,t
j
) · α(t
j
) (1)
s(t
i
) ←
∑
(p
i
,t
j
)∈E
s(p
i
) · w(p
i
,t
j
) · α(t
j
) (2)
KEE algorithm is as follows. A vector of
participant scores and a vector of term scores are
represented by S
P
and S
T
respectively. k in the below
is a natural number.
KEE algorithm:
1. Initialize S
0
P
= 1, 1,...,1, and S
0
T
= 1, 1...,1
2. For i = 1, 2,...,k
(a) S
i
P
is obtained using Equation (1) with S
i−1
T
(b) Normalize S
i
P
so the square sum in S
i
P
to 1
(c) S
i
T
is obtained using Equation (2) with S
i
P
(d) Normalize S
i
T
so the square sum in S
i
T
to 1
3. Return S
k
P
and S
k
T
Kleinberg proved theorems that S
P
and S
T
con-
verge and the limits of S
k
P
and S
k
T
are obtained by the
principal eigenvectors of A
T
A and AA
T
(Kleinberg,
1999). A is an adjacency matrix; (i, j) entry is 1 if
(p
i
,t
j
) ∈ E, and is 0 otherwise. Empirically, S
P
and
S
T
converge very rapidly (k = 6 on the average in our
experiments).
2.2 Term Weight Assignment
In the previous subsection, we described how KEE
algorithm obtains key terms and key persons simul-
taneously. This subsection covers how to assign the
term weight α(t) (see Equation (1) and Equation (2)).
A term weight is a tuning parameter in order to
avoid strong influences by frequent terms. KEE al-
gorithm tends to give high score to frequent terms, if
not using the term weights. However, frequent terms
are not always suitable for key terms. For example, in
case that the discussion theme is cell phone (as of our
experiments described in the next section), the discus-
sion participants tend to frequently use terms, such as
cell, phone, talk, and call. Those terms would not be
significant. Besides, it is only natural that those terms
are detected from the discussion.
Key terms must be not too general in every dis-
cussion, but particular only to a focused discussion.
DELINEATING TOPIC AND DISCUSSANT TRANSITIONS IN ONLINE COLLABORATIVE ENVIRONMENTS
15

We propose an assignment of a term weight based
on a generality and particularity.Agenerality mea-
sures overall importance of a term. If a term was fre-
quently used in all discussions, the generality would
be higher. A particularity measures local importance
of a term. If a term was frequently used only in a
focused discussion, the particularity would be higher.
Let M be a set of messages posted in all discus-
sions, M
G
(t) ⊂ M be a set of messages in all discus-
sions containing the term t, and M
L
(t) ⊂ M be a set
of messages in the focused discussion containing the
term t. Denote a logarithmic generality and a partic-
ularity of the term t by w
g
(t) and w
p
(t), respectively.
The weight or term t is assigned by
α(t)=w
g
(t) · w
p
(t),
where w
g
(t) and w
p
(t) are given by the following
equations.
w
g
(t)=log
|M|
|M
G
(t)|
, (0 ≤ w
g
(t) ≤ 1) (3)
w
p
(t)=
|M
P
(t)|
|M
G
(t)|
, (0 ≤ w
p
(t) ≤ 1)
3 DISCUSSION ANALYSIS BY
KEE
In this section, two approaches for knowledge dis-
covery from network-based discussions are proposed.
These approaches are based on key terms and key per-
sons obtained by KEE algorithm.
3.1 Discussion Dynamics Analysis
This subsection proposes methods for analyzing dis-
cussion dynamics. Suppose that we have a discussion
data stored as a sequence of messages. Our goal is to
observe how key terms and key persons were changed
as the discussion went on.
Key terms/persons transition : Transitions of key
terms and key persons are observed with sliding win-
dows over the discussion. A sliding window is a se-
quence of a certain number of messages. We observe
transition of key terms and key persons obtained in
each sliding window.
In order to detect subtle changes of the keys
clearly, a particularity for window, instead of the par-
ticularity proposed in the previous subsection, is used
for the term weights. A particularity for window is
defined so as to increase term weight proportion to
particularity of a term in a sliding window. Suppose
M
G
(t) be a set of messages containing the term t in the
focused discussion. Let M
PW
i
(t) ⊂ M
G
(t) be a set of
messages containing the term t in ith sliding window.
Denote the particularity for ith sliding window of the
term t by w
pw
i
(t). w
pw
i
(t) is obtained as follows.
w
pw
i
(t)=
|M
PW
i
(t)|
|M
G
(t)|
, (0 ≤ w
pg
i
(t) ≤ 1)
Key terms and persons dynamics over a discus-
sion are observed by the following procedure.
Key-s transition:
1. Collect document and clean with typical text
processing methods including noise filtering and
term stemming.
2. Assign generality to each term.
3. For each window,
(a) Assign particularity for the window to each
term.
(b) Calculate score by KEE algorithm with α(t)=
w
g
(t) · w
pw
i
(t).
4. Chart the score transitions of each term and par-
ticipant.
Discussion dynamics : How topics were changing
over discussions is observed by examining the key-
term transitions, which are, more precisely, similar-
ities between a set of key terms in a sliding window
and in each of sets of key terms in some previous win-
dows.
Let C
i
be a term score vector for ith window
obtained by the procedure Key-s transition. C
i
=
{c
i
(t
1
), c
i
(t
2
),...,c
i
(t
n
)}. Suppose that we examine
the similarity between C
i
and C
j
(i− k < j < i, k is a
natural number). Each entry of C
j
is the score in jth
sliding window of each term t
1
,t
2
,...,t
n
(extracted in
ith window), that is, C
j
= {c
j
(t
1
), c
j
(t
2
),...,c
j
(t
n
)}.
Let Sim(C
i
,C
j
) denote similarity between C
i
and C
j
.
Many similarity measures have been proposed (Lin,
1998; Strehl and Ghosh, 2000). We use one of the
most typical similarity measures, a cosine similarity
(Salton and McGill, 1986) for obtaining Sim(C
i
,C
j
),
which is given by the following equation.
Sim(C
i
,C
j
)=
∑
n
k=1
c
i
(t
k
) · c
j
(t
k
)
∑
n
k=1
c
i
(t
k
)
2
∑
n
k=1
c
j
(t
k
)
2
(4)
How topics of the discussion were converged, or
conversely diverged, are measured by the differences
of each Sim(C
i
,C
j
), i − k < j < i and their average.
Let diff
sim(i) and ave sim(i) be a difference and
an average of Sim(C
i
,C
j
), i− k < j < i, respectively.
They are given by
ICEIS 2007 - International Conference on Enterprise Information Systems
16
dif f sim(i)= max
i−k< j<i
Sim(C
i
,C
j
)
− min
i−k< j<i
Sim(C
i
,C
j
) (5)
avg
sim(i)=
∑
i−1
j=i−k
Sim(C
i
,C
j
)
k
. (6)
If diff sim(i) is small and ave sim(i) is high, the
discussion may have converged into a certain topic
around ith sliding window. If diff
sim(i) is small but
ave
sim(i) is low, the topic may have changed into
completely different topics. The large diff
sim(i) in-
dicates diversity of key terms.
The procedure for observing discussion dynamics
is summarized as followings.
Discussion Dynamics :
1. Obtain term score vector for each window by the
procedure Key-s transition
2. For each term score vector C
i
(a) For each term score vector C
j
(i− k < j < i)
i. Obtain cosine similarity Sim(C
i
,C
j
)
(b) Calculate diff
sim(i) and ave sim(i)
3. Chart the transitions of diff
sim(i) and ave sim(i)
3.2 Social Network Analysis
This subsection proposes a method for generating a
map of social network. The social network is rep-
resented by a weighted directed graph, based on post-
reply relationships between participants. The network
shows that which pair of participants were how signif-
icant throughout the discussion. This social network
gives us an intuitive grasp of how key terms were tran-
siting over the participants.
A social network is represented by a weighted di-
rected graph G(V, E), where V and E are a set of par-
ticipants and a set of weighted edges, respectively.
Let w(u, v) be a weighted edge from a participant u
replying to another participant v. Edge weight w(u, v)
is measured by sum of the scores of common terms in
the messages from u to v, which is given by
w(u, v)=
n
∑
k=1
r
k
(u, v),
where r
k
(u, v) is a post-reply relationship from a
message m
u
by a participants u replying to a message
m
v
by another participants v, and
r
k
(u, v)=
∑
t∈T
c(t) · s, (7)
where T is a set of common terms in the messages
m
u
and m
v
, and c(t) is a term score given by KEE
algorithm. s is a tuning parameter used for presenting
w(u, v) with a larger value. Since c(t) is less than 1,
w(u, v) tends to be quite small.
4 EXPERIMENTS
This section reports experimental results of our ap-
proaches applying to actual discussion data. First,
we show the key terms extracted by our method and
make a comparison with terms by TFIDF (Salton and
Buckley, 1987). Next, as a discussion dynamics anal-
ysis, we report key-term transitions, and discussion
dynamics with examining differences with TFIDF.
Then, for understanding relationships between dis-
cussion participants, the transitions of key persons
and the extracted social network are reported.
The data was collected from a series of focus
groups held on March 2005 together with Hakuhodo
Inc. (the second largest advertising company in
Japan). The goal of the workshop was to identify
future scenarios for cell phone usages and the fea-
tures that will make them popular among consumers.
A several discussions were held during each focus
group. The discussion data consists of a sequence of
messages. A message consists of message id, title,
author name, replying id, and message content.
In the experiments reported in the below, only
words (not phrases) were used as terms, and each
words is stemmed using the Porter algorithm (Porter,
1997). The detail description of Porter algorithm is
beyond the scope of this paper. The proposed ap-
proach and the Porter’s algorithm were implemented
by Perl. Multi feature terms are left out for further
research.
4.1 Key Terms Extraction
This subsection reports key terms extracted from the
seven discussions by different groups and gives a
comparison with the terms obtained by TFIDF, one
of the typical and traditional methods for finding key
terms. In order to have fair comparison, we used IDF
given by the equation (3) in Section 3.1.
Table 1 and 2 show highest ranked ten terms of
each discussion by our method and TFIDF, respec-
tively. Our method extracts terms which are even less
frequent but given by key persons, in addition to high
frequent terms given by key persons. For example,
calendar, AOL, Nextel, keyboard from Dis. 1, dvd,
palm from Dis.3, and blackberry from Dis. 4 are
terms that cannot be detected by TFIDF, but they are
DELINEATING TOPIC AND DISCUSSANT TRANSITIONS IN ONLINE COLLABORATIVE ENVIRONMENTS
17
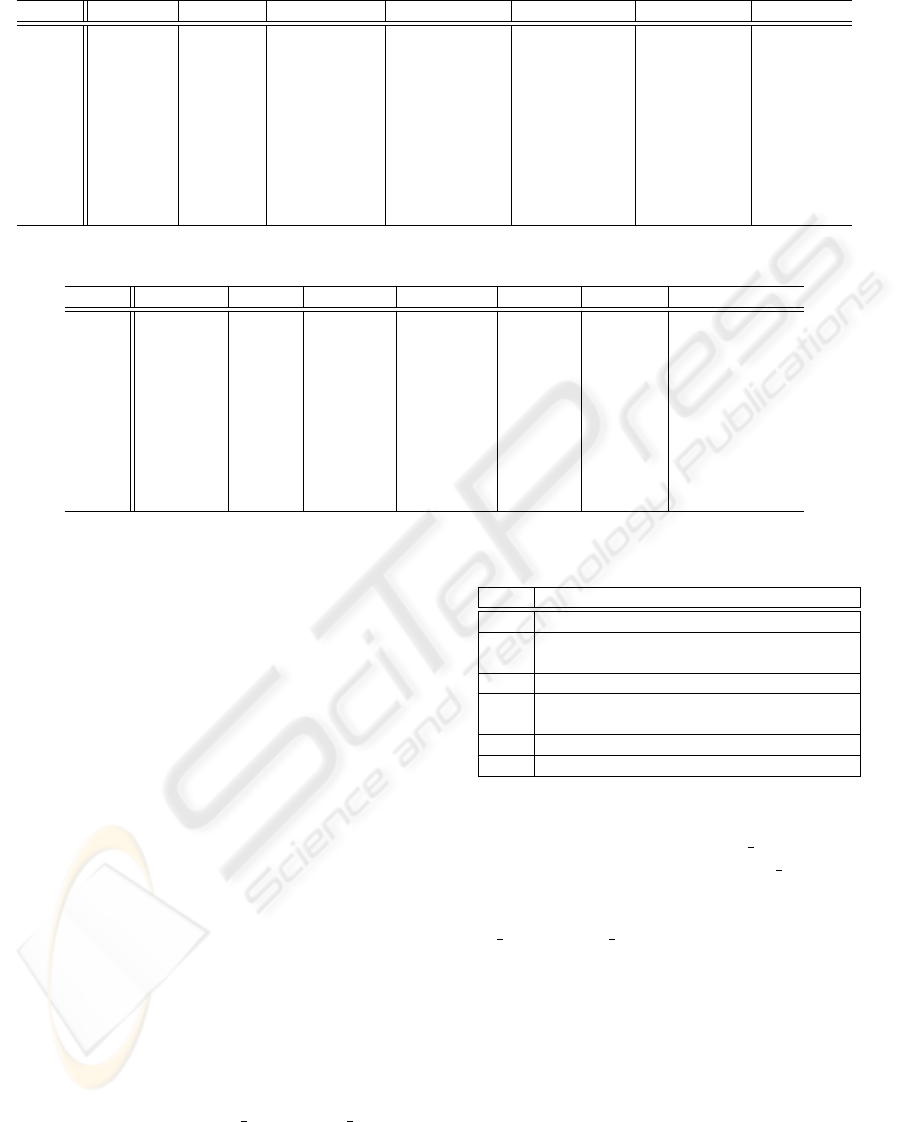
Table 1: KEE algorithm induced key terms for each discussion.
Rank. Dis. 1 Dis. 2 Dis. 3 Dis. 4 Dis. 5 Dis. 6 Dis. 7
1 definitely toy dvd dissatisfaction roam claim 3g
2
gps plane palm louis private radiation bluetooth
3
calendar nap card unhappy telemarketing ofcours unit
4
qwerty compose pilot key unfortunately emit implement
5
aol longrun identification blackberry sign harm fix
6
nextel clearly water stand cellular microwave picture
7
simply society thousand lock junk unable visual
8
keyboard surf dedicated package battery study update
9
interact earlier fraud usage old scientifically landline
10
frequent arent steal design advertisement even ultimately
Table 2: TFIDF. induced key terms for each discussion
Rank. Dis. 1 Dis. 2 Dis. 3 Dis. 4 Dis. 5 Dis. 6 Dis. 7
1 cellphone people cell people battery cell cell
2
cell line computer phone cell people phone
3
device work card tool longer phone bluetooth
4
battery society pay internet phone talk import
5
gps cell phone sometimes roam feel picture
6
people reach video cell people radiation camera
7
computer future connect cellphone cellular right message
8
phone dont camera pay old even software
9
internet land credit user scenario annoy communication
10
number comps cellphone unused sign really 3g
all worth to examine as significant terms by key per-
sons. Of course, TFIDF has high potentiality to de-
tect the discussion topic, although it tends to extract
high frequent but not significant terms, such as cell,
phone, people, etc. Therefore, examining key terms
by the KEE algorithm is essential to grasp what terms
are worth to focus as possible clue of innovative and
creative ideas.
4.2 Discussion Dynamics Analysis
This subsection reports the discussion dynamics for
one of the test discussions. The analysis presents key-
term transition, transition of key term similarity dif-
ferences, and transition of key term similarity aver-
ages. We used the sliding window size set to ten, and
k = 5 for similarity comparisons (see Equation (4)).
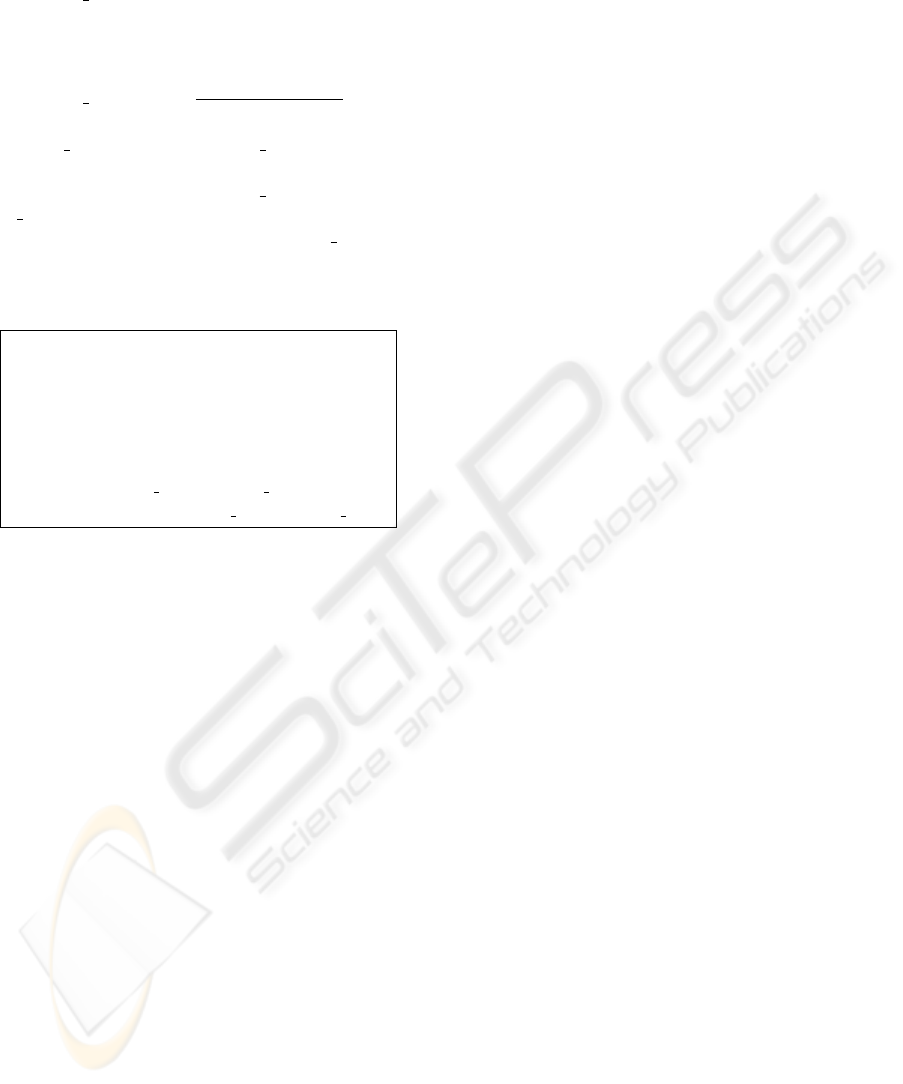
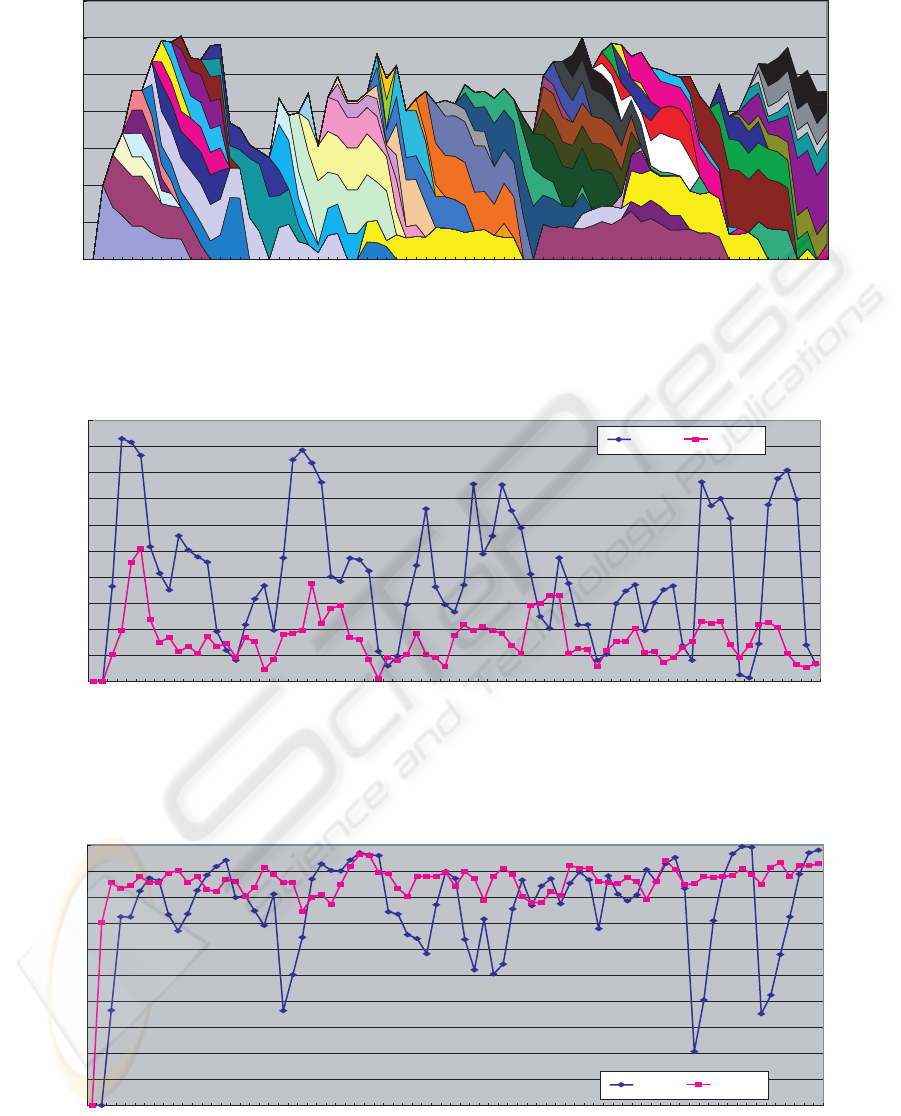
The stacked chart in Figure 1 shows how key
terms were changing over the discussion. X and Y
axes represent i-th sliding window, and the stacked
scores of highest ranked five key terms. Each area
indicates a key-term. Figure 2 and 3 show similarity
differences and averages for key terms extracted by
our method and TFIDF. X axes represent i-th sliding
window. Y axes represent diff
sim and ave sim for
each sliding window given by the equations (5) and
(6).
In the stacked chart, the parts that each term
area is stacked in parallel (roughly, windows be-
Table 3: Key terms of the selected windows.
Wd. Key terms
16th talk, call, vibration, make, answer
32th function, instant, Bluetooth,
internet, phonebook
55th computer, keyboard, screen, small, simply
64th feature, technology, depend,
problem, computer
74th gps, navigation, service, battery, device
78th battery, player, music, mp3, problem
tween 9th-16th, 23rd-32nd, 49th-55th, 67th-74th, and
75th-78th) are identical to high avg
sim appeared in
the chart in Figure 3. Moreover, dif f
sim of those
windows are quite low. These are clear indication
that topics were converged in those windows. Low
dif f
sim and avg sim were observed around 64th
window, which indicates a topic segmentation. Table
3 shows highest ranked five key terms extracted each
listed window. Observing the discussion dynamics,
and key-term transition, we could see that the topics
shifted from general to specific as the discussion went
on. Moreover, key terms of 64th are quite general
compared with others, which indicates that the topic
was segmented at this point.
As seen in the Figure 2 and 3, compared with the
line by KEE, the line chart by TFIDF is quite flat. The
differences of similarities for the key terms by TFIDF
were within the range of 0 to 0.5 and the averages of
ICEIS 2007 - International Conference on Enterprise Information Systems
18
㪇
㪇㪅㪌
㪈
㪈㪅㪌
㪉
㪉㪅㪌
㪊
㪊㪅㪌
㪈
㪊
㪌
㪎
㪐
㪈㪈
㪈㪊
㪈㪌
㪈㪎
㪈㪐
㪉㪈
㪉㪊
㪉㪌
㪉㪎
㪉㪐
㪊㪈
㪊㪊
㪊㪌
㪊㪎
㪊㪐
㪋㪈
㪋㪊
㪋㪌
㪋㪎
㪋㪐
㪌㪈
㪌㪊
㪌㪌
㪌㪎
㪌㪐
㪍㪈
㪍㪊
㪍㪌
㪍㪎
㪍㪐
㪎㪈
㪎㪊
㪎㪌
㪎㪎
i-th sliding window
Stacked Key-term scores
Figure 1: Discussion dynamics by key-term tansition.
㪇
㪇㪅㪈
㪇㪅㪉
㪇㪅㪊
㪇㪅㪋
㪇㪅㪌
㪇㪅㪍
㪇㪅㪎
㪇㪅㪏
㪇㪅㪐
㪈
Diff. of Similarities
㪈
㪊
㪌
㪎
㪐
㪈㪈
㪈㪊
㪈㪌
㪈㪎
㪈㪐
㪉㪈
㪉㪊
㪉㪌
㪉㪎
㪉㪐
㪊㪈
㪊㪊
㪊㪌
㪊㪎
㪊㪐
㪋㪈
㪋㪊
㪋㪌
㪋㪎
㪋㪐
㪌㪈
㪌㪊
㪌㪌
㪌㪎
㪌㪐
㪍㪈
㪍㪊
㪍㪌
㪍㪎
㪍㪐
㪎㪈
㪎㪊
㪎㪌
㪎㪎
KEE
TFIDF
㫀㪄㫋㪿㩷㪪㫃㫀㪻㫀㫅㪾㩷㪮㫀㫅㪻㫆㫎
Figure 2: Discussion dynamics by key termsimilarity differences.
㪇
㪇㪅㪈
㪇㪅㪉
㪇㪅㪊
㪇㪅㪋
㪇㪅㪌
㪇㪅㪍
㪇㪅㪎
㪇㪅㪏
㪇㪅㪐
㪈
㪈
㪊
㪌
㪎
㪐
㪈㪈
㪈㪊
㪈㪌
㪈㪎
㪈㪐
㪉㪈
㪉㪊
㪉㪌
㪉㪎
㪉㪐
㪊㪈
㪊㪊
㪊㪌
㪊㪎
㪊㪐
㪋㪈
㪋㪊
㪋㪌
㪋㪎
㪋㪐
㪌㪈
㪌㪊
㪌㪌
㪌㪎
㪌㪐
㪍㪈
㪍㪊
㪍㪌
㪍㪎
㪍㪐
㪎㪈
㪎㪊
㪎㪌
㪎㪎
Ave. of Similarities
KEE
TFIDF
㫀㪄㫋㪿㩷㪪㫃㫀㪻㫀㫅㪾㩷㪮㫀㫅㪻㫆㫎
Figure 3: Discussion dynamics by key termsimilarity averages.
DELINEATING TOPIC AND DISCUSSANT TRANSITIONS IN ONLINE COLLABORATIVE ENVIRONMENTS
19
㪇
㪇㪅㪈
㪇㪅㪉
㪇㪅㪊
㪇㪅㪋
㪇㪅㪌
㪇㪅㪍
㪇㪅㪎
㪇㪅㪏
㪇㪅㪐
㪈
㪈
㪊
㪌
㪎
㪐
㪈㪈
㪈㪊
㪈㪌
㪈㪎
㪈㪐
㪉㪈
㪉㪊
㪉㪌
㪉㪎
㪉㪐
㪊㪈
㪊㪊
㪊㪌
㪊㪎
㪊㪐
㪋㪈
㪋㪊
㪋㪌
㪋㪎
㪋㪐
㪌㪈
㪌㪊
㪌㪌
㪌㪎
㪌㪐
㪍㪈
㪍㪊
㪍㪌
㪍㪎
㫀㪄㫋㪿㩷㪪㫃㫀㪻㫀㫅㪾㩷㪮㫀㫅㪻㫆㫎
㪢㪼㫐㪄㫇㪼㫉㫊㫆㫅㫊㩷㫊㪺㫆㫉㪼㫊
㪘㫌㫋㪿㪈 㪘㫌㫋㪿㪉 㪘㫌㫋㪿㪊 㪘㫌㫋㪿㪋 㪘㫌㫋㪿㪌 㪘㫌㫋㪿㪍
Figure 4: Key persons transition.
similarities are constantly high. It is very difficult to
identify periods which are worth to examine.
4.3 Social Network Extraction
This subsection reports an observation for one of the
experiment discussions from the view of participants.
Seeing both key persons transition and social network
will promote better understanding the relationship be-
tween participants and their significance.
Auth3
Auth2
Auth5
Auth6
Auth4
Auth1
3.9
2.7
10.2
27.6
13.8
6.3
8.2
15.6
3.7
1.4
2.2
3.3
1.2
1.2
3.2
2.2
3.4
3.5
2.9
Figure 5: Social Network.
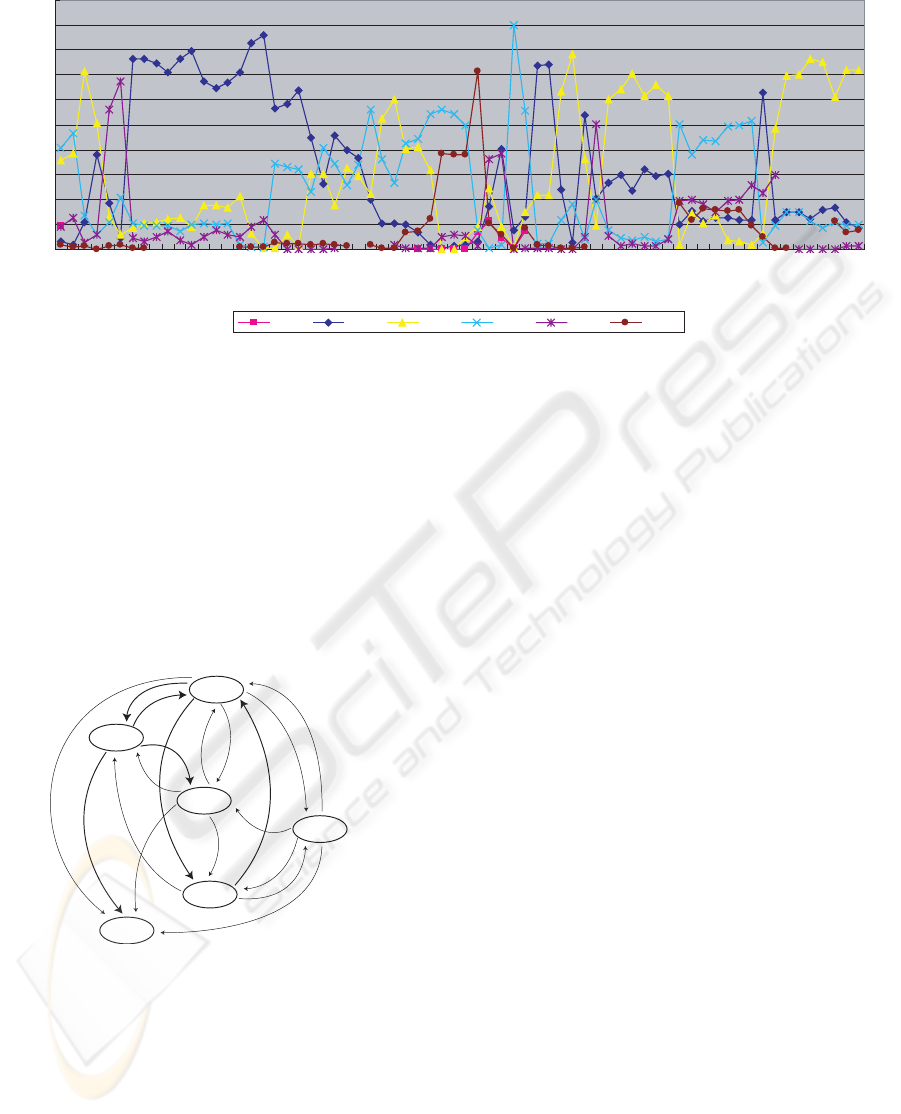
Figure 4 depicts key persons transition. X, Y axes
represent i-th sliding window and key persons scores,
respectively. Sliding window was set to be 10. Figure
5 shows a social network extracted by our method.
Each number beside each edge represents the edge
weight. We used a tuning parameter s = 100 (see the
equation (7).)
As seen in Figure 4, Author2 and Author3 domi-
nated the first and the last part of the discussion, re-
spectively. Seen in Figure 5, the relationship between
Author2 and Author3 is the most significant. How-
ever, each role seemed slightly different. While Au-
thor2 had a large connection only from Author3, Au-
thor2 had large connections to many authors, such as
Author5, Author3, and Author1. This indicates Au-
thor2 would play a role as a replier. Conversely, Au-
thor3 had large connections both from and to other
participants. This indicates that Author3 would play
a role as an opinion generator.
5 CONCLUSIONS
This paper focused on delineating topic and dis-
cussant transitions in online collaborative environ-
ments, more precisely, focus group discussions for
product conceptualization. We proposed KEE algo-
rithm. Based on KEE algorithm, we proposed two
approaches for analyzing discussions: discussion dy-
namics and social network. Our experimental results
using real discussion data showed that key terms ob-
tained by KEE algorithm gave us better understand-
ing of participantsfidea than the terms obtained by a
traditional method TFIDF. Moreover, since the key
terms were from the key persons in the discussion,
those key terms would be potential knowledge, that
we had looked for. Both discussion dynamics anal-
ysis and social network analysis also gave us signifi-
cant knowledge which is essential to decision support.
These experimental results show the effectiveness of
KEE algorithm for network- and text-based commu-
nication analysis.
As future work, we plan to use KEE algorithm
for knowledge discovery in web-logs or web forums.
KEE algorithm effectively works not only on the re-
ICEIS 2007 - International Conference on Enterprise Information Systems
20

lationship between terms and people, but also for any
relationship between terms and possible conceptual
packets of terms, such as, sentences, messages, etc.
Similar idea to key terms/persons extraction can be
applied to these relationship; key terms are included
in many key sentences (or messages), and key sen-
tences (or messages) contain many key terms. We
would like to apply our approaches to various data
source, and lead to innovation and creativity support.
6 RELATED WORKS
The DISCUS project targets on innovation sup-
port through network-based communication (Gold-
berg et al., 2003). In addition to KEE methods, two
chance discovery approaches: KeyGraph (Ohsawa
and Yachida, 1998) and influence diffusion models
(IDM) (Matsumura et al., 2002) are used in the DIS-
CUS. Various methods have been proposed for find-
ing significant terms from text (key phrases (Witten
et al., 1999), topic words (Lawrie et al., 2001)). Many
approaches have been proposed for analyzing text
stream by topic detection, tracking, and segmentation
(Allan et al., 1998; Beeferman et al., 1999). Some
works have focused on finding persons in text-based
communication (Kamimaeda et al., 2005; Reich et al.,
2002). However, there had been no method for find-
ing significant terms and persons simultaneously.
ACKNOWLEDGEMENTS
We would like to thank to Hakuhodo Inc. for their
project collaboration. This work was sponsored by
the Air Force Office of Scientific Research, Air Force
Materiel Command, USAF (AF9550-06-1-0096 and
AF9550-06-1-0370). The US Government is autho-
rized to reproduce and distribute reprints for Govern-
ment purposes notwithstanding any copyright nota-
tion thereon.
REFERENCES
Allan, J., Carbonell, J., Doddington, G., Yamron, J., and
Yang, Y. (1998). Topic detection and tracking pilot
study: Final report.
Beeferman, D., Berger, A., and Lafferty, J. D. (1999). Sta-
tistical models for text segmentation. Machine Learn-
ing, 34(1-3):177–210.
Goldberg, D. E., Welge, M., and Llor
`
a, X. (2003). DISCUS:
Distributed Innovation and Scalable Collaboration In
Uncertain Settings. IlliGAL Report No. 2003017,
University of Illinois at Urbana-Champaign, Illinois
Genetic Algorithms Laboratory, Urbana, IL.
Kamimaeda, N., Izumi, N., and Hasida, K. (2005). Dis-
covery of key persons in knowledge creation based on
semantic authoring. In KMAP 2005.
Kleinberg, J. M. (1999). Authoritative sources in a hyper-
linked environment. Journal of the ACM, 46(5):604–
632.
Lawrie, D., Croft, W. B., and Rosenberg, A. (2001). Finding
topic words for hierarchical summarization. In SIGIR
’01: the 24th ACM SIGIR conference on Research and
development in information retrieval, pages 349–357.
Lin, D. (1998). An information-theoretic definition of sim-
ilarity. In Proc. 15th International Conf. on Machine
Learning, pages 296–304. Morgan Kaufmann, San
Francisco, CA.
Llor
`
a, X., Goldberg, D., Ohsawa, Y., Matsumura, N.,
Washida, Y., Tamura, H., Masataka, Y., Welge, M.,
Auvil, L., Searsmith, D., Ohnishi, K., and Chao, C.-J.
(2006). Innovation and creativity support via chance
discovery, genetic algorithms, and data mining. New
Mathematics and Natural Computation, 2(1):85–100.
Matsumura, N., Ohsawa, Y., and Ishizuka, M. (2002). Influ-
ence diffusion model in text-based communication. In
WWW ’02: Special interest tracks and posters of the
11th international conference on World Wide Web.
Ohsawa, Y.and Benson, N. E. and Yachida, M. (1998). Key-
Graph: Automatic indexing by co-occurencd graph
based on building construction metaphor. In Proceed-
ings of Advances in Digital Libraries, pages 12–18.
Porter, M. F. (1997). An algorithm for suffix stripping.
pages 313–316.
Reich, J. R., Brockhausen, P., Lau, T., and Reimer, U.
(2002). Ontology-based skills management: Goals,
opportunities and challenges. Universal Computer
Science, 8(5):506–515.
Salton, G. and Buckley, C. (1987). Term weighting ap-
proaches in automatic text retrieval. Technical report.
Salton, G. and McGill, M. J. (1986). Introduction to Mod-
ern Information Retrieval. McGraw-Hill, Inc. New
York, NY, USA.
Strehl, A. and Ghosh, J. (2000). Value-based customer
grouping from large retail data-sets. In Proceedings
of the SPIE Conference on Data Mining and Knowl-
edge Discovery: Theory, Tools, and Technology II, 24-
25 April 2000, Orlando, Florida, USA, volume 4057,
pages 33–42. SPIE.
Witten, I. H., Paynter, G. W., Frank, E., Gutwin, C., and
Nevill-Manning, C. G. (1999). Kea: practical auto-
matic keyphrase extraction. In DL ’99: the fourth
ACM conference on Digital libraries, pages 254–255.
DELINEATING TOPIC AND DISCUSSANT TRANSITIONS IN ONLINE COLLABORATIVE ENVIRONMENTS
21
