TOWARDS A HOLISTIC INTEGRATION OF SOFTWARE
LIFECYCLE PROCESSES USING THE SEMANTIC WEB
Roy Oberhauser and Rainer Schmidt
Department of Computer Science, Aalen University, Beethovenstr. 1, 73430 Aalen, Germany
Keywords: Software Lifecycle Proce
sses, Software Engineering, Semantic Web.
Abstract: For comprehensive software lifecycle processes, a trichotomy continues to subsist between the software
development processes, enterprise IT processes, and the software runtime environment. Currently,
integrating software lifecycle processes requires substantial effort, and the information needed for the
execution of (semi-)automated software lifecycle workflows is not readily accessible and is typically
scattered across semantically heterogeneous sources. Consequently, an interrupted flow of information
ensues between the development/maintenance phases and operational phases in the software lifecycle,
resulting in ignorance, inefficiencies, and suboptimal product quality and support levels. Furthermore,
today’s abstract IT (e.g., ITIL) and software processes are often derived into concrete processes and
workflows manually, causing errors, extensive effort, and limiting widespread adoption of best practices.
This paper describes an approach for improving information flow throughout the software lifecycle via the
(semi-)automated realization of abstract software lifecycle processes and workflows in combination with
Semantic Web technologies.
1 INTRODUCTION
For a long time, software development and operation
were regarded as separate disciplines. However,
there is an increasing interest in a holistic view on
the entire software lifecycle. For enterprises,
software lifecycle processes such as the ITIL
(ITSMF, 2004) application management process
provide an abstract view that includes phases of the
software lifecycle as shown in Figure 1. Software
lifecycle processes tend to have a broader view than
most software development processes, which
typically include only the phases from requirements
analysis to roll-out, but often ignore the operation
and the retirement phases of software. Application
development entails the requirements, design, and
build phases. Service management consists of the
deploy, operate, optimize, and retirement phases.
For instance, it is theoretically possible to use
information gathered during one phase to help
optimize another. Operational information could be
used for optimizing the software design.
To realize advantages of software lifecycle
processes ec
onomically and efficiently, it is
necessary to have information flows of semantically-
annotated information with appropriate information
retrievable in a diverse operational infrastructure
across organization boundaries.
Today, however, various barriers impede the
necessary effi
cient information flow capability.
Therefore, this paper will analyze barriers for
realizing the advantages of comprehensive software
lifecycle processes and provide an initial approach to
towards overcoming some of these impediments.
Application Management
Requirements
Optimise
Operate
Deploy
Design
Build
Service Management
Application Development
Retirement
V1
V2
Figure 1: ITIL application management.
137
Oberhauser R. and Schmidt R. (2007).
TOWARDS A HOLISTIC INTEGRATION OF SOFTWARE LIFECYCLE PROCESSES USING THE SEMANTIC WEB.
In Proceedings of the Second International Conference on Software and Data Technologies - Volume ISDM/WsEHST/DC, pages 137-144
DOI: 10.5220/0001343101370144
Copyright
c
SciTePress
2 PROBLEM
While comprehensive software lifecycle processes
offer a number of advantages, in practice these are
rarely fully exploited. Two reasons are plausible:
realizing integrated software lifecycle processes
requires significant effort, and the information
needed for the execution of (semi-)automated
software lifecycle workflows is not readily
accessible and is typically distributed across
semantically heterogeneous sources.
2.1 High Implementation Effort for
Software Lifecycle Processes
The prodigious implementation effort for software
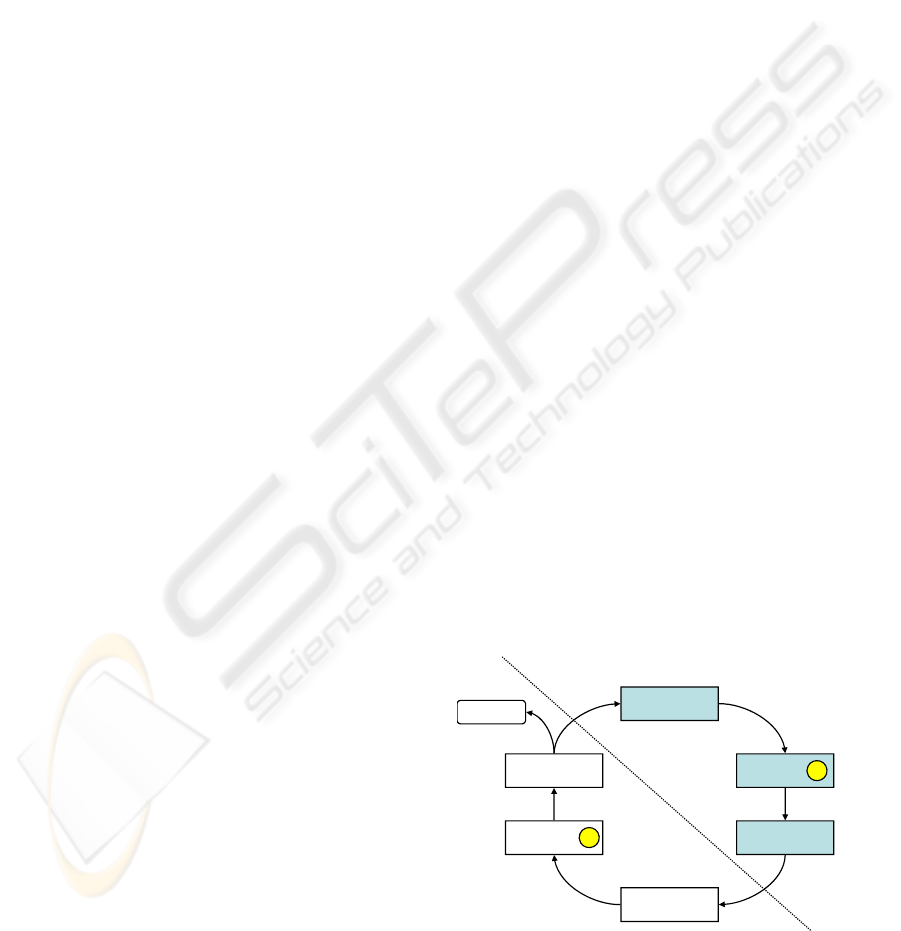
lifecycle processes is due to a large extent because
of the semantic gap between the abstract process
descriptions and the executable process, as shown in
Figure 2. Furthermore, there is no appropriate
representation of best practices. Workflows which
already have been proven as beneficial cannot be
easily reused, because they are not easily accessible
and a common representation is missing. Thus, the
derivation of executable processes from the abstract
process description has to be done manually.
However, the manual derivation causes a number of
subsequent problems: it is an error-prone task.
Second, the degree of reuse is low; the executable
software lifecycle processes reuse only few
elements, leading to a higher error rate because
tested workflows are rarely reused. Third, there is
only a low degree of standardization. This is of
particular consequence when the software lifecycle
process spans multiple interacting organizations.
Figure 2: Semantic gap.
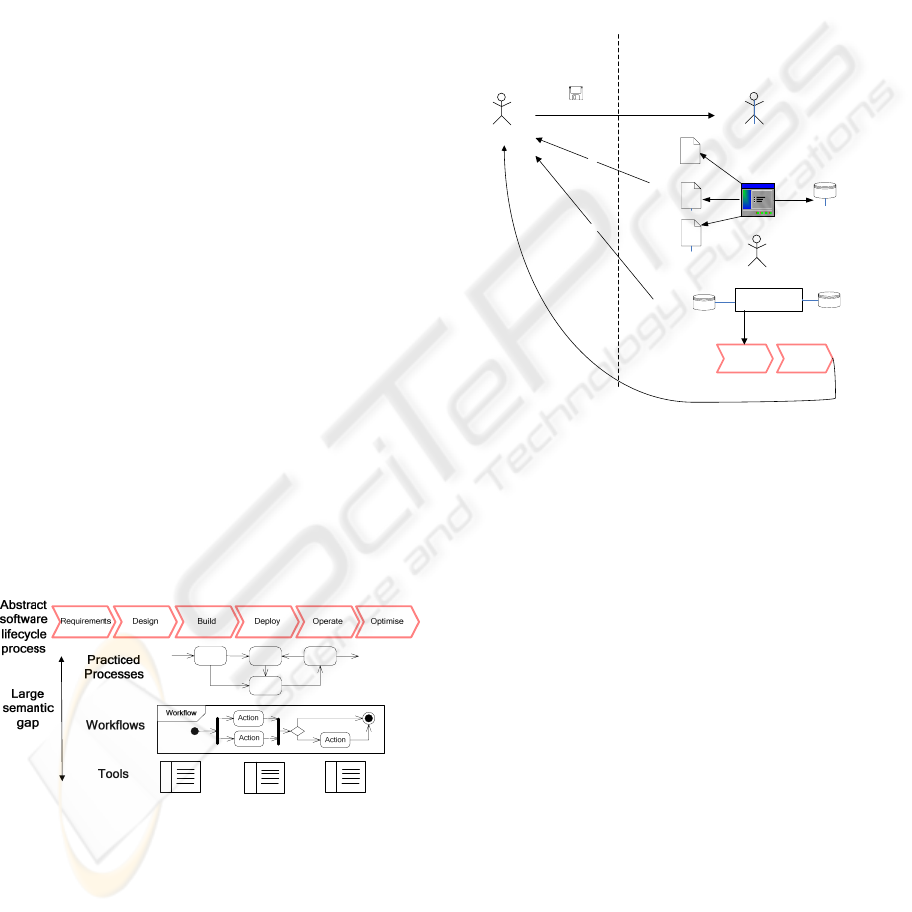
2.2 Breaks in Information Flows
An encumbering problem for the efficient
implementation of software lifecycle processes are
breaks in the information flows between software
operation and software development as shown in
Figure 3.
After transferring the software to the run-time
environment, only few or no information is passed
back to the software developer. This information can
be divided into two sets.
First, there is run-time information which is
machine-observable. That means, this information
can be gathered automatically. Such machine
observable run-time information is, for example, the
application log, the server log, and the system log.
Furthermore, data in the application database may be
important for debugging, etc.
Software Developer
Administrator
Software Development Operation
Software
Run-time
environment
X
Ru
n
-
t
i
m
e
I
n
f
o
r
m
a
t
i
o
n
(
M
a
c
h
i
n
e
o
b
s
e
r
v
a
b
l
e
)
User
Help Desk
Incident
Management
Problem
Management
X
R
u
n
-
t
i
m
e
I
n
f
o
r
m
a
t
i
o
n
(
No
n
m
a
c
h
i
n
e
o
b
s
e
r
v
a
b
l
e
)
Application
Log
Application
Application
Database
System Log
Server Log
X
CMDB Incident DB
Figure 3: Breaks in information flows.
Second, there is run-time information which
cannot be directly gathered by a machine, e.g.,
functional defects in the software: the software
continues its operations but delivers invalid results
or exhibits incorrect behavior. This information is
gathered indirectly by a user or administrator and
usually communicated to a single point of contact,
called a help or service desk. All information
gathered by the help desk is processed by incident
and problem management processes (as defined in
ITIL) and stored in an incident database. The
incident and problem analysis is supported by the
configuration management database which contains
information about the configuration of the run-time
environment, e.g., details such as software versions
used on which systems, hardware, networking, etc.
In practice, an important problem is deciding
which information can be used to diagnose which
type of problem. Figure 4 shows three hypothetical
examples. For performance problems, the server log
and the application database could be analyzed.
Reliability problems can be analyzed using the
server, system and application log in conjunction
with the configuration management database
ICSOFT 2007 - International Conference on Software and Data Technologies
138
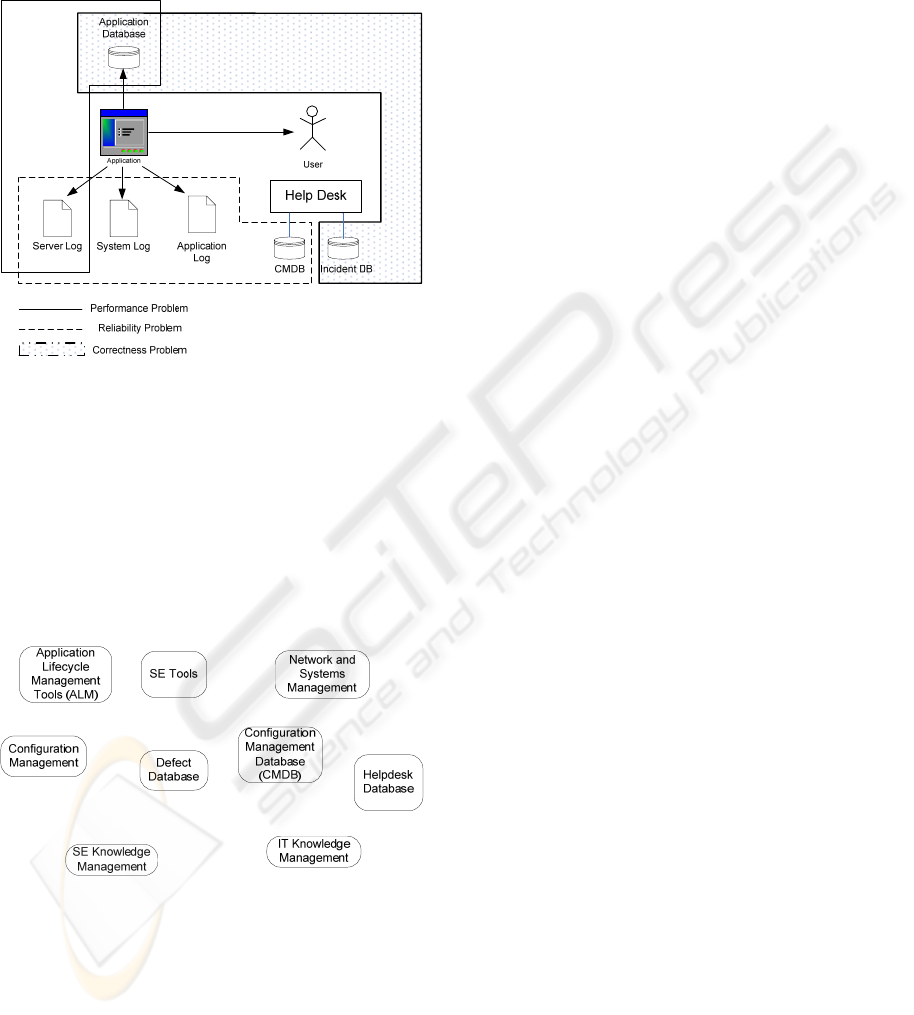
(CMDB). Finally problems in the application logic
(e.g., incorrect behavior) can be analyzed using the
application database and incident database where
observations of incorrect behavior of the application
are stored.
Figure 4: Best practices for problem diagnosis.
It is evident that the selection of the appropriate
information sources non-trivial. But in practice,
there is no means to appropriately store the
information about which kind of problem requires
which information sources. This knowledge is not
theory-based, but comes from observation and
experience and can be seen as a collection of best
practices.
Figure 5: Scattered Information Island Landscape.
While both machine-readable and human-
readable run-time information could provide a
significant benefit to the software developer -
however, differences in syntax and semantics
impede the usage of such information. Furthermore,
important information is not discoverable because of
the dispersion across different sources using
incompatible syntaxes and semantics. Consequently
a landscape of isolated tools, systems, and databases
emerges as shown in Figure 5.
3 SOLUTION APPROACH
Any feasible and concomitantly practical approach
towards a holistic solution needs to address the
previously mentioned problems of section 2 within
realistic constraints. E.g., to further adoption, it
should be platform-independent, vendor-neutral,
utilize standards, and support a high degree of
flexibility and loose-coupling. A possible approach
that this paper presents is SWLIFE: Semantic Web-
based Lifecycle Integration Framework for
Enterprises. Before describing the framework
elements, the underlying principles of the
framework’s architecture will be elucidated.
3.1 Solution Principles
This section describes the key principles of the
solution approach.
I) Holistic need-based integration of human and
machine processes, services, and ontologically
structured data for the operational lifecycle.
The lack of integration between software
engineering processes and customer (e.g.,
enterprise or IT) software operational processes
(e.g., ITIL) causes extensive inefficiencies,
especially in the maintenance phase of a
software product - both in the processes and
access to necessary data. Yet this is typically
the longest, most expensive, and least
predictable phase.
II) Round-trip Process Engineering: prescriptive
while concurrently descriptive abstract
processes. Too often abstract processes are not
transformed or mapped to concrete processes
correctly, thereby losing its prescriptive nature.
Abstract processes hereby are mapped (semi-
)automatically to concrete processes, and
customized current concrete processes are
abstracted to determine if they still conform to
the abstract processes. If not, either they or the
abstract processes are adjusted so that the
abstract processes are also descriptive.
III) Semantic Web accessibility and utilization of
meaningful data. Instead of hidden, obscure
(operational) data in applications and tools
such as log files, this data is discoverable,
accessible, and its meaning described via
Semantic Web Services.
TOWARDS A HOLISTIC INTEGRATION OF SOFTWARE LIFECYCLE PROCESSES USING THE SEMANTIC WEB
139

IV) (Semi-)Automated exchangeability and reuse of
machine-readable best practices in the form of
workflows. Rather than just textual exchange
via documents, which are difficult and arduous
to automate, both abstract and concrete
processes and workflows are described in
standardized Markup Languages, e.g.,
including XMI (e.g., from UML Activity
Diagrams), BPEL4WS, various Grid Workflow
languages, etc. These are stored and exchanged
in enterprise-wide and trusted internet
repositories. Apposite choices or standards for
such Markup Languages are outside the scope
of this paper.
V) Service-Oriented Architecture (SOA). In order
to achieve the level of integration necessary,
SOA principles including loose-coupling,
encapsulation, reusability, composability,
discoverability, etc. are applied, generally in
conjunction with Web Services standards.
VI) Feasible and reasonable automation. Common
operational or maintenance routines are
automated to the degree reasonable and
economical for workflows and the (semi)-
automated composition of services.
VII) Web-based human process documentation and
integrated infrastructure binding. Web-based
process documentation of software engineering
processes (e.g., VM-XT, RUP) and IT
processes (e.g., ITIL) are tailored to the context
and bound to the actual human and machine
workflows used, with the services hyperlinked
within the documentation. Thus a human can
determine the status of a workflow, start an
(automated) workflow, etc., all in the context
of the organization’s processes.
3.2 Solution Description
This section describes the solution approach of
SWLIFE as depicted in the illustration of Figure 6.
The layers used are for grouping purposes and are
not intended to show strict abstraction or
dependency relations. The white rectangles show
examples of possible current processes and tools.
The black rectangles show new areas that SWLIFE
provides or enables. It is not intended to be
exhaustive but rather illustrative of the approach,
additional layers and items are conceivable.
The vertical column Vendor Development
Operations (see Fig. 6) includes the processes and
infrastructure of a product developer, while the
vertical column Enterprise IT Operations includes
those of the product customer who operates the
software product. Black hashed ellipses between
these columns show a new permeation between
these two usually distinct organizational entities at a
given layer.
The Process Layer (see Fig. 6) can include
processes defined at an organizational level, and
depicts abstract process models (e.g., RUP or ITIL)
that are tailored via a Process Mapping Framework
to concrete processes. These processes typically
include workflows performed at various points by
various human roles defined by theses processes,
and can include machine-based workflows to
automate certain recurring tasks. The Process
Mapping Framework includes techniques and
tooling to support the tailoring of abstract processes
and workflows to concrete processes, and for
analyzing concrete processes and workflows,
abstracting them, and comparing them to intended or
previous abstract processes. The Process and
Workflow Repository provides a retrieval, update,
and exchange mechanism for processes and
workflows, such as software engineering-related,
domain-specific (e.g., ecommerce, banks),
enterprise-specific, platform-specific, and vendor-
and application- specific areas. Such a mechanism
could improve quality and reduce investment costs
by enhancing the distribution and interchange of best
practices in these areas. The Integrated Process and
Workflow Transformation and Execution Subsystem
ensures that integrated human and machine
processes and workflows are transformed, including
(semi-)automatic composition, as necessary at run-
time, and ensures and monitors their execution.
The transformations and mappings in the Process
Layer can utilize, where available, a Knowledge
Layer, where Knowledge Management repositories
of the applicable organizations may contain
knowledge in the form of rules for defining process
and workflow transformation.
The Semantic Integration Layer (see Fig. 6)
includes the Semantic Web interfaces for tools and
services, including adapters when not provided, and
any necessary infrastructure. This includes existing
subsystems on the vendor and enterprise side for
ontology loading and reasoning, as well as an
integrated capability for SWLIFE scenarios.
The Infrastructure and Technology Layer in Fig.
6 includes the tools, applications, and technology
utilized in the various organizations.
Governance Management includes the aspects
necessary to govern the integration between
organizations, including the integration of policy
management.
ICSOFT 2007 - International Conference on Software and Data Technologies
140
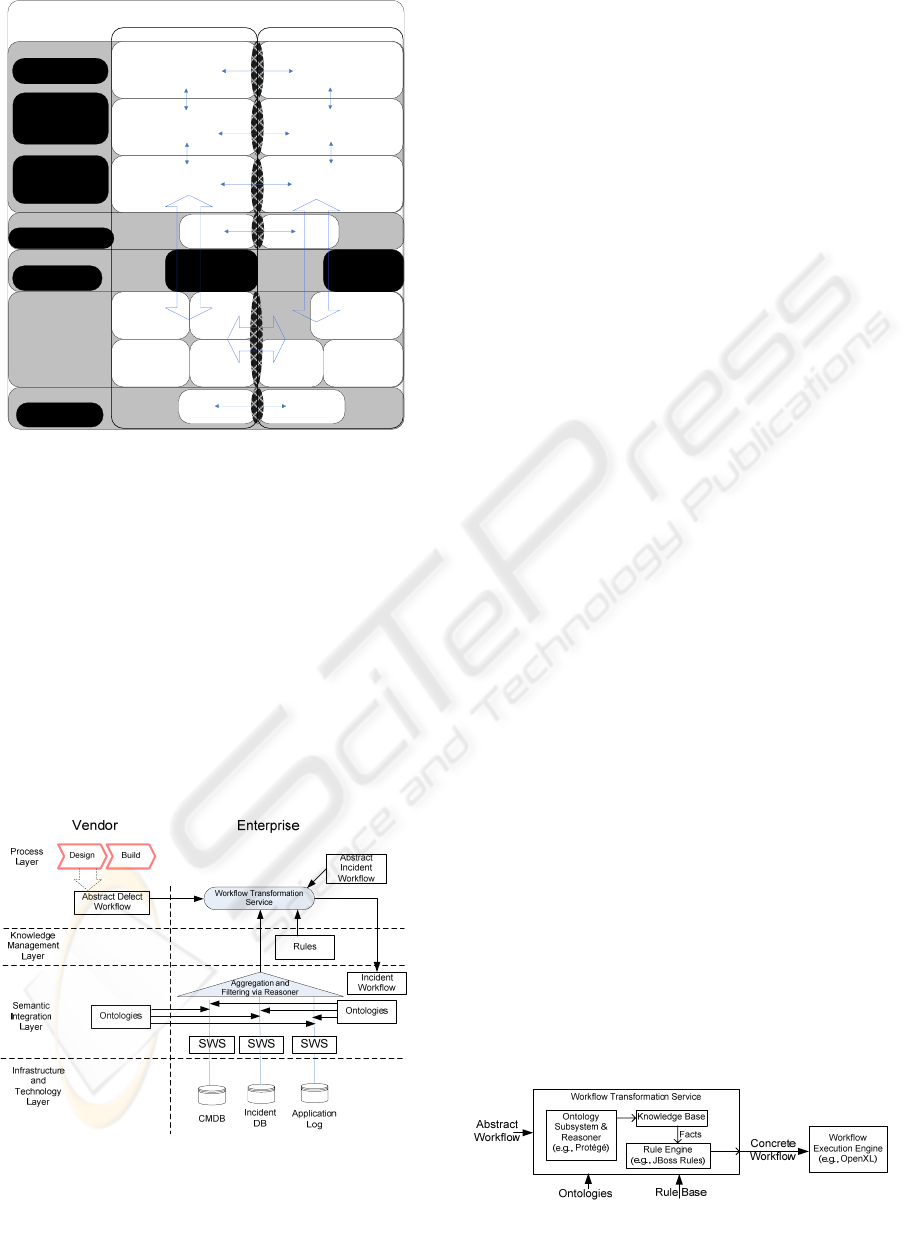
SWLIFE
Semantic Web-based Lifecycle Integration Framework for Enterprises
Infrastructure and
Technology Layer
Process Layer
Abstract IT Processes
(e.g., ITIL)
Concrete IT Processes
Application
Lifecycle
Management
Tools (ALM)
Abstract Software Engineering
(SE) Processes
(e.g, VM-XT, RUP)
Concrete SE Processes
Specific Human and Machine
SE Workflows
Specific Human and Machine
IT Operational Workflows
Configuration
Management
Database
(CMDB)
Process Mapping
Framework
Process and
Workflow
Repository
(Shared and Local)
Incident
Database
Network and
Systems
Management
Defect
Database
SE Tools
Configuration
Management
Integrated Process
and Workflow
Transformation and
Execution
Governance Management
Enterprise Policy
Management
Vendor Policy
Management
Integrated Policy
Management
Knowledge Layer
IT Knowledge
Management
SE Knowledge
Management
Integrated Knowledge
Management
Semantic Integration Layer
Semantic Web
Infrastructure
SE and Application
Ontology
Subsystem
IT and Domain
Ontology
Subsystem
Enterprise IT OperationsVendor Development Operations
Figure 6: SWLIFE.
An example of the interaction of the layers is
shown in Figure 7. The Semantic Integration Layer
encapsulates Semantic Web Services (SWS)
interfaces of information sources such as CMDB,
Incident DB, and Application Logs. In the Semantic
Integration Layer, ontologies both from the vendor
and enterprise are used to classify the SWS and to
clarify their relationships. Aggregation and filtering
is done via a Reasoner to support the workflow
transformation process. Rules provided in the
Knowledge Management Layer assist the Workflow
Transformation Service in order to transform
integrated workflows from the vendor and enterprise
into concrete executable workflows which are
provided and executed as SWS.
Figure 7: Layer interaction.
4 SOLUTION REALIZATION
The implementation of the SWLIFE approach has
focused on the problem of the transformation of
abstract processes to and from concrete processes.
To support an efficient, correct, and reliable
transformation, the support non-trivial workflows
and their (semi-)automatic composition should be
supported on tooling suitable in engineering and IT
settings. Although there is much research in the
automatic composition of OWL-S based services,
various HTN planners mentioned in research were
considered unsuitable, e.g., due to the lack of access,
instability, or lack of usable results in practice. E.g.,
OWLS-XPlan was considered, but lacked branching
capabilities, sufficient documentation, and an
execution engine for its PDDXML workflow format.
E.g., Mindswap Composer also lacked branching
and loop capabilities.
With the current lack of usable planners for
workflow composition, a separate and practical
solution for the Workflow Transformation Service
was developed that combines an Ontology
Subsystem with a Rule Engine, as shown in Figure
8. For the Ontology Subsystem, the Protégé OWL
API 3.2 Beta, was used to read in the ontologies, and
the integrated Protégé Reasoner was used (external
reasoners are an option) to select a set of possible
service matches. For the Rule Engine, JBoss Rules
3.0.5 was chosen. As the abstract workflow is read
in and parsed, any abstract concepts are detected and
the Reasoner returns a set of service instances that
are a possible match. Because the choices may be
highly dependent on a number of factors, this set is
passed to the rule engine as a fact model and
inserted into its working memory. The rule engine
then selects the appropriate service based on the set
of rules in the Rule Base. The use of a rule engine
allows a greater degree of flexibility and change for
enterprises without the encumbrances inherent in
lower-level programming languages, although script
languages are an alternative. If no matching service
was found, an error is issued. If more than one
service matched, then the first one was used,
replacing the abstract concept in the workflow with
a concrete service.
Figure 8: Abstract to Concrete Workflow Transformation.
TOWARDS A HOLISTIC INTEGRATION OF SOFTWARE LIFECYCLE PROCESSES USING THE SEMANTIC WEB
141

Various workflow languages would be suitable
for SWLIFE, however, the domain-specific language
Service Language Layer (SLL) (Kossmann et al,
2005)(Dinger et al, 2006 SLL), was chosen for the
implementation due to its simplicity as a workflow
language at the programming language level and
because of its service-centric nature. SLL can also
be viewed in its XML form and be transformed into
BPEL4WS or another workflow language.
For feasibility test purposes for such a workflow
scenario, Web Service adapters and OWL-S
descriptions for typically non-SOA software
lifecycle applications (e.g., Subversion version
control system, compiler, etc.) were created, along
with an abstract workflow specified in SLL that
specified various abstract tools to automatically
generate a report for an engineer. This abstract SLL
workflow was passed to the Workflow
Transformation Service which then converted it into
a concrete SLL workflow referencing concrete tool
service instances, and the workflow was then
deployed and executed as a service on the OpenXL
platform.
For performance measurements, a Windows XP
SP2 PC with an AMD 2600+ CPU, 1GB RAM, a
1Mb/s Internet connection, Java 5, Apache Tomcat
Version 5.5.20, Apache Axis 1.4, and OpenXL 1.0
was used.
In applying a SWLIFE scenario, it was
determined that a major contributing factor to the
performance of the workflow transformation was the
ontology loading time. Because of the difficulty of
creating local copies, adapting import URLs, and
maintaining these against new version, Internet
retrieval of OWL-S related ontologies is a highly
likely use case. The average across 100 attempts for
inserting an OWL-S based service ontology to the
knowledge base was 5.66 seconds. This would
indicate that it is best to load and initialize the
Workflow Transformation Service once as a long-
running service even in an enterprise setting.
Table 1: Average workflow transformation time.
Number of
possible Services
4 Abstract
concepts (ms)
100 Abstract
concepts (ms)
5 86 111
10 92 120
25 106 123
The actual abstract to concrete workflow
transformation time given a simple rule file was
measured, averaged across 500 attempts as shown in
Table 1, based on the number of available services,
and utilizing 4 or 100 abstract concepts. This shows
that the performance of workflow transformation
from abstract to concrete workflows utilizing a rule
engine is practicable.
5 RELATED WORK
Approaches for a holistic access and integration of
information include collaboration software, ALM
(Application Lifecycle Management) and ECM
(Enterprise Content Management) which allows the
management of an organization’s unstructured
information, wherever it exists as the AIIM
(Association for Information and Image
Management) intends. Yet most of the current
applications in these areas have only partial
solutions, non-standard interfaces, and little to no
integration in the operational IT processes of
customers. Grid technologies, platforms (e.g., the
Globus Toolkit), and related research (e.g., the
Adaptive Services Grid) could well provide an
infrastructural basis for some aspects of SWLIFE, so
while this approach does not preclude it, it does not
require the Grid since the primary focus of SWLIFE
is not the sharing computational resources or
services. The concept of virtual organizations as
used in the Grid could be leveraged for the ad-hoc
integration and access by a vendor to the provided
customer software and/or data.
The SWLIFE approach can leverage and
integrate work on software engineering ontologies,
e.g., (Calero, 2006) includes work on SWEBOK,
software maintenance, software measurement, and
other related ontologies. Work on generic IT and
domain-specific ontologies could be used in
SWLIFE, an example is the Health Information
Technology Ontology Project (HITOP).
The approach presented here also has
relationships to the semantic-based composition of
web services as described in (Sivashanmugam et al.,
2004), (Medjahed et. al., 2003) and (McIllraith et al.,
2000). These approaches show how Web Services
can be integrated using semantic web technologies.
This also applies to the ontology-based description
of business processes as defined in (Koschmider et
al., 2005) and in (Rosemann et al., 2002) and
(Rosemann et al., 2004). Work utilizing the
Semantic Web for automated software engineering
purposes includes (Dinger, 2006 SWS-ASE). A
tighter relationship exists with approaches for the
ontology-based representation of service processes
such as the incident and problem management
processes as defined in (Schmidt et al., 2007). The
semantic alignment of business processes using
ICSOFT 2007 - International Conference on Software and Data Technologies
142

ontologies is described in (Brockmanns et al., 2006).
Ontologies can also be used for supporting the
composition of web services as described in
(Agarwal et al., 2005). A mixed-initiative
framework for Semantic Web service discovery and
composition is presented in (Rao et al., 2006). It
interleaves human decision making and automated
functionality. Thus it can also be applied even if
annotations are incomplete and inconsistent. This
scenario is rather similar to the scenario of SWLIFE,
and therefore this approach will be further
investigated.
6 CONCLUSION
The lack of integration of between the stages in
comprehensive lifecycle processes between product
vendors and enterprise customers continues to
plague the software industry. This manifests itself
perplexed administrators, in extensive, expensive
and difficult defect remediation, long defect duration
times, long service response and patch turn-around
times, etc. As software continues to increase in its
complexity and degree of integration, this situation
will deteriorate without attention.
To address this situation, the SWLIFE approach
bridges these process and information flow breaks
by supporting integrated lifecycle processes, shared
human and machine (semi-)automated workflows,
and enabling better quality and more efficient
semantic integration of infrastructure elements and
artifacts. SWLIFE is influenced by background
trends such as a high degree of networked systems,
increasing integration via Service-Oriented
Architecture (SOA) and Web Services, Semantic
Web, outsourcing, and cross-organizational value
creation, and service providing in the IT area.
Economically, an advantage of the SWLIFE
approach is that each vendor of a product invests in
the Semantic Web interface to its product once, and
all customers can benefit from faster and higher
quality maintenance response, providing an
incentive to customers. Customers can utilize the
Semantic Web interfaces to automate workflows,
integrate workflows into higher-level processes, and
more efficiently gather and analyze quality metrics.
Via a standardized exchange format and repositories
for processes and workflows, the investments can be
incremental and shared. The implementation work
showed that a feasible and practical solution for the
(semi-)automatic composition of workflows using
Semantic Web Service interfaces for the tools and
services involved in SWLIFE scenarios exists.
A future market for packaged processes and
workflows (analogous to the IBM Rational Unified
Process) which are trusted, supported, and
maintained, is thinkable. In addition, Semantic Web
Service adapters can be provided to integrate legacy
or non-conforming products.
Even a partial application of the SWLIFE
approach can yield advantages via increased and
systematic application of best practices in the form
of human and machine-readable processes and
workflows, the holistic needs-based integration of
vendor and customer infrastructure, and the
utilization of machine-processable semantic
infrastructure. This a viable approach to addressing
the skyrocketing complexity and maintenance costs
associated with the use of software products.
Some challenges for the SWLIFE approach
include: the need for highly-trained personnel for
semantic, ontology, process, and workflow creation
and usage; for cross-organizational access trust,
security, authorization, and policy issues need to be
addressed; the lack of (standardized) ontologies in
the various SE and IT areas; and the adoption and
usage of abstract processes and their description in
machine-processable form.
Further work will include exploring additional
application scenarios, for instance, enhanced
response workflows for security intrusions, where
rapid response and high quality incident data play
important roles.
ACKNOWLEDGEMENTS
The authors would like to thank and acknowledge
Thomas Ilzhöfer for his thesis work.
REFERENCES
Agarwal, V.; Koustuv, D.; Karnik, N.; Kumar, A.; Kundu,
A.; Mittal, S,; Srivastava, B.; 2005: A service creation
environment based on end to end composition of Web
services. Proceedings of the 14th International
Conference on World Wide Web, Chiba, Japan p 128
– 137, 2005.
Brockmans, S.; Ehrig, M.; Koschmider, K.; Oberweis, A.;
Studer, R., 2006.: Semantic Alignment of Business
Processes. In: Proceedings of the Eighth International
Conference on Enterprise Information Systems (ICEIS
2006), pp. 191-196. INSTICC Press, Cyprus, 2006.
Calero, C., Ruiz, F., Piattini, M., 2006. Ontologies for
Software Engineering and Software Technology.
Springer-Verlag.
TOWARDS A HOLISTIC INTEGRATION OF SOFTWARE LIFECYCLE PROCESSES USING THE SEMANTIC WEB
143

Dinger, U., Oberhauser, R., Reichel, C., 2006. SWS-ASE:
Leveraging Web Service-based Software Engineering.
In Proceedings of the International Conference on
Software Engineering Applications, 2006.
Dinger, U., Reichel, C., 2006. Service Language Layer
(SLL) Specification Version 1.1.3, Working Draft.
http://www.dbis.ethz.ch/people/reichech/sll_service_la
nguage_layer_specification_version_1.1.3.pdf
ITSMF, Service Management Forum, 2004.: IT Service
Management – An Introduction. Van Haren
Publishing, Amsterdam, 2004.
Koschmider, A.; Oberweis, A., 2005.: Ontology based
Business Process Description. In: Proceedings of the
CAiSE´05 WORKSHOPS, no. 2, pp. 321-333,
Portugal, 2005.
Kossmann, D., Reichel, C., 2005. SLL: Running My Web
Services on Your WS Platforms. Proceedings of ICWS
2005
McIlraith, S.A. Son, T.C. Honglei Zeng, 2000.
Semantic Web sServices 2000. IEEE Intelligent
Systems and Their Applications Volume: 16, Issue: 2,
pages 46- 53
Medjahed, B.; Bouguettaya, A.; and Elmagarmid, A. K.
2003.: Composing Web services on the Semantic
Web. The VLDB Journal The International Journal on
Very Large Data Bases, Volume 12.,
Rao, J.,; Dimitrov, D.;, Hofmann, P.;, Sadeh, N., 2006. ;
"A Mixed Initiative Approach to Semantic Web
Service Discovery and Composition: SAP’s Guided
Procedures Framework," icws , pp. 401-410, 2006.
Rosemann, M.; Green, P., 2002.: Developing a meta
model for the Bunge-Wand-Weber ontological
constructs. In: Information Systems (27), pp. 75-91,
2002.
Rosemann, M.; Indulska, M.; Green, P., 2004.: A
Reference Methodology for Conducting Ontological
Analyses. In: Proceedings of the 23rd International
Conference on Conceptual Modelling (ER 2004). pp.
110-121, Shanghai, 2004.
Schmidt, R.; Bartsch C.:, 2007. Ontology-based Modelling
of Service Processes and Services. In: Proceedings of
the IADIS International Conference, Applied
Computing 2007, pp. 67-74, Salamanca, Spain, 2007.
Sivashanmugam, K.; Miller, J. A.; Sheth, A. P.; Verma K.
2004:. Framework for Semantic Web Process
Composition International Journal of Electronic
Commerce Volume 9, Number 2 / Winter 2004-5,
pages 71 - 106
ICSOFT 2007 - International Conference on Software and Data Technologies
144
