
Effect of Feature Smoothing Methods in Text
Classification Tasks
David Vilar , Hermann Ney , Alfons Juan , and Enrique Vidal
Lehrstuhl f¨ur Informatik VI
Computer Science Department
RWTH Aachen University
D-52056 Aachen (Germany)
Institut Tecnol`ogic d’Inform`atica
Universitat Polit`ecnica de Val`encia
E-46071 Val`encia (Spain)
Abstract. The number of features to be considered in a text classification sys-
tem is given by the size of the vocabulary and this is normally in the range of
the tens or hundreds of thousands even for small tasks. This leads to parameter
estimation problems for statistical based methods and countermeasures have to
be found. One of the most widely used methods consists of reducing the size of
the vocabulary according to a well defined criterion in order to be able to reliably
estimate the set of parameters. In the field of language modeling this problem is
also encountered and several smoothing techniques have been developed. In this
paper we show that using the full vocabulary together with a suitable choice of
the smoothing technique for the text classification task obtains better results than
the standard feature selection techniques.
Key words: Text Classification, Naive Bayes, Multinomial Distribution, Feature Selec-
tion, Smoothing, Length Normalization
1 Introduction
Text classification systems, even for small tasks, have to deal with vocabularies of thou-
sands or tens of thousands of words, which form the effective dimensions of the repre-
sentation space of the documents to classify. This often leads to parameter estimation
problems due to the sparseness of the data, as a high percentage of the words will rarely
be seen and the parameters of the models can not be reliably estimated. As an example,
in the 20 newsgroups data set, more than half of the words are seen two times or less.
To counteract this problem, a frequent solution consists of using only a reduced subset
of the vocabulary, selected according to a well defined criterion, in order to reduce the
number of parameters to be estimated, and thus trying to obtain more accurate values.
Similar problems are also found in the field of language modeling, where the most
widely used models, the
-gram models, are also subjected to this data sparseness prob-
lem. The most frequent solution in this area is to use feature smoothing techniques in
Vilar D., Ney H., Juan A. and Vidal E. (2004).
Effect of Feature Smoothing Methods in Text Classification Tasks.
In Proceedings of the 4th International Workshop on Pattern Recognition in Information Systems, pages 108-117
DOI: 10.5220/0002682001080117
Copyright
c
SciTePress

order to redistribute the original probability mass and so to achieve a good estimate
even for unseen events.
In this paper we have used some of this techniques adapted to the text classifica-
tion task, and for four out of five corpora we obtain better results by using the whole
vocabulary instead of a reduced set.
This paper is organized as follows. Section 2 presents the basic model we will use
for our experiments. Section 3 describes the feature selection technique most widely
applied and Section 4 presents the feature smoothing technique we will use. The results
for the different corpora are shown in Section 5 and lastly some conclusions are drawn
in Section 6.
2 The multinomial model
As representation of the documents we use the well-known bag-of-words representa-
tion, that is, each document is assigned a
-dimensional vector of word counts, where
is the size of the (possibly reduced) vocabulary. We will denote the word variable
as
and the document class variable as . As classification
model we use the naive Bayes text classifier in its multinomial event model instan-
tiation [1]. In this model the assumption is made that the probability of each event
(word occurrence) is independent of the word’s context and position in the document
it appears, and thus the chosen representation is justified. Given the representation of
a document by its counts
the class-conditional probability is given
by the multinomial distribution
(1)
where
is the length of document , and are the parameters of
the distribution, with the restriction
(2)
In order to reduce the number of parameters to estimate, we assume that the distribution
parameters are independent of the length
and thus , and that
the length distribution is independent of the class
, so (1) becomes
(3)
Applying Bayes rule we obtain the classification rule
(4)
To estimate the prior probabilities
of the class and the parameters we
apply the maximum-likelihood method. For a given training set
, where
109
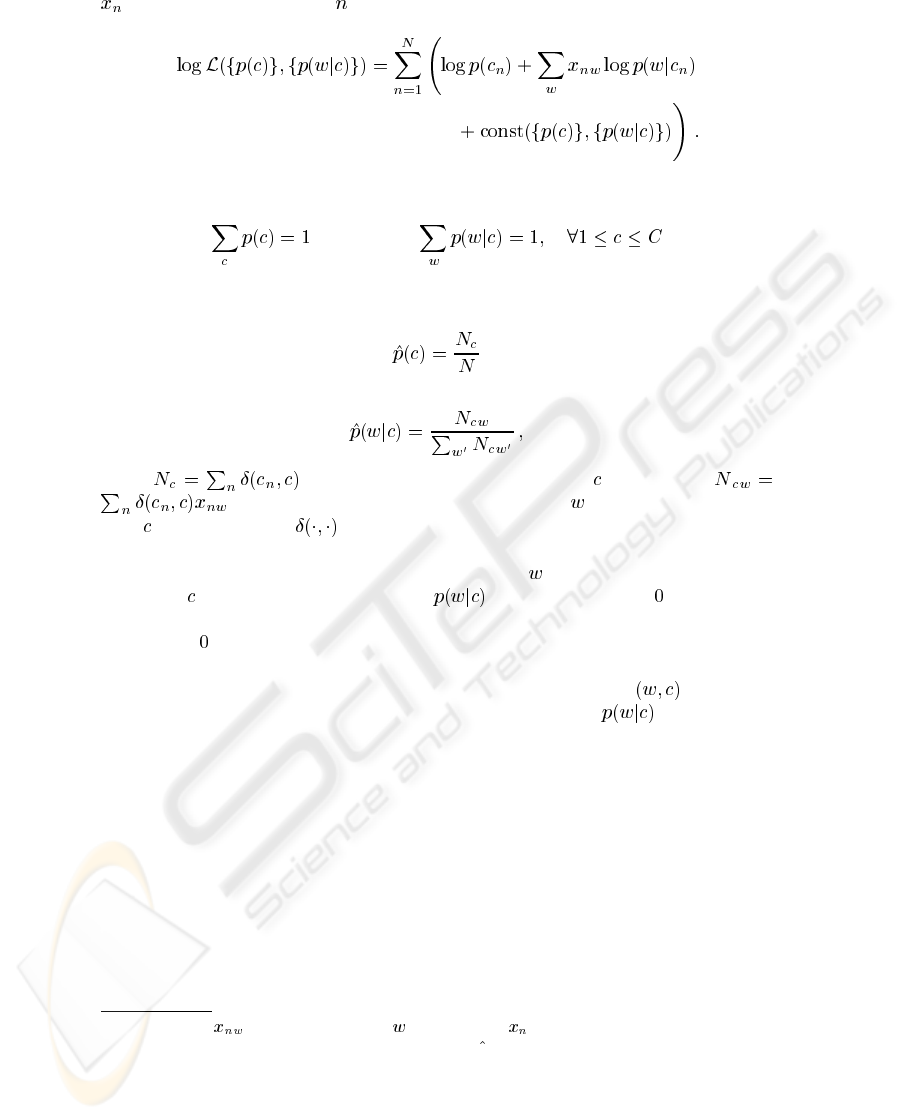
is the representation of the th document
3
, the log-likelihood function is
(5)
Using Lagrange multipliers we maximize this function under the constraints
and (6)
The resulting estimators
4
are the relative frequencies
(7)
and
(8)
where
is the number of documents of class and similarly
is the total number of occurrences of word in all the documents of
class
. In this equations denotes the Kronecker delta function, which is equal to
one if its both arguments are equal and zero otherwise.
From equation (8) it can be observed that if a word
has not been seen in training
for a class
, the corresponding parameter will be estimated as . If in the test
phase a document belonging to this class contains this word, the conditional probability
will also be
(see eq (3)), which will produce a classification error. This problem is
known as data sparseness, and is caused by the fact that the amount of possible features
is much larger than the available data. In our case a feature is a pair
, composed
by a word and a class, (compare with the distribution parameters
) and, as stated
in the example, many of the words will be seen only in a reduced set of classes during
training. Two solutions to this problem will be discussed in the next sections: feature
selection and feature smoothing.
3 Feature Selection
Feature selection techniques aim to reduce the number of features to take into consid-
eration without degrading the performance of the system. The use of such techniques is
mandatory for certain classifiers like neural networks or Bayes belief networks, where
a high dimensionality of the input space implies an intractable number of parameters
to estimate. Nevertheless it is reported that for some corpora and several classification
3
Analogously is the count of word for document .
4
We will denote parameter estimations with the hat ( ) symbol.
110

techniques, reducing the size of the vocabulary effectively improves classification ac-
curacy by considering only those parameters which can be reliably estimated [1–3]. For
the classifier we are considering the efficiency consideration is not crucial except in
some special cases, if strict efficiency requirements must be met.
The most widely used feature selection technique which obtains the best results is
known as information gain [4], based on the mutual information
5
concept of informa-
tion theory [5]. It is a measure of the number of bits of informationobtained for category
prediction by knowing the presence or absence of a term in a document. For a word
,
the information gain is defined as
(9)
where
denotes the absence of word . Having computed this value for each word of
the vocabulary, we use as classification features only those with information gain above
a predefined threshold or, more frequently, the highest scoring
words.
Nevertheless, reducing the amount of features in general can not guarantee a so-
lution for the “zero-frequency” problem. A frequent approach to solve it within this
context is to use the so called Laplace estimator [1], where the effect of including one
document with each word appearing exactly once is simulated for each class. As we
will see in the next section, this is a simple form of smoothing and better results can be
obtained using more refined approaches.
4 Feature Smoothing
Parameter smoothing is required to counteract the effect of statistical variability of the
training data, particularly when the number of parameters to estimate is relatively large
in comparison with the amount of available data. A clear example of this effect are the
multinomial parameters whose value are set to
according to the maximum likelihood
estimation.
One simple case of parameter smoothing, known as Laplace smoothing, consists
simply of adding a pseudo-count to every word-count
(10)
5
It is important to distinguish between the information theoretical concept of mutual infor-
mation and the (related but different) criterion of mutual information for feature selection
(see [4]).
111

The Laplace estimator mentioned in Section 3 is the special case of (10) when .
Also, this special case can be seen as the result of a Bayesian estimation method in
which a Dirichlet prior over word probabilities is used [6]. Although this approach
avoids zero probabilities, we find that it can not achievean effective redistribution of the
probability mass. This problem has been extensively studied in the context of statistical
languagemodeling [7] and the applicationto text classification tasks is presented in [8].
In this paper four different techniques are studied on the well known 20 newsgroups
corpus (see also Section 5). Further experiments on more corpora have shown that the
technique known as unigram interpolation usually achieves the best results and, in order
to focus our exposition, we will only reproduce the derivation of this method here.
The base of this method is known as absolute discounting and it consist of gaining
“free” probabilities mass from the seen events by discounting a small constant
to
every (positive) word count. The idea behind this model is to leave the high counts
virtually unchanged, with the justification that for a corpus of approximately the same
size, the counts will not differ much, and we can consider the “average” value, using a
non-integer discounting. The gained probability mass
6
for each class is
(11)
and is distributed in accordance to a generalized distribution, in our case, the unigram
distribution
(12)
The final estimation thus becomes
(13)
The selection of the discounting parameter
is crucial for the performance of the
classifier. A possible way to estimate it is using the so called leaving-one-outtechnique.
This can be considered as an extension of the cross-validation method [9,10]. The main
idea is to split the
observations (documents) of the training corpus into ob-
servations that serve as training part and only
observation, the so called hold-out part,
that will constitute the simulated training test. This process is repeated
times in such
a way that every observation eventually constitutes the hold-out set. The main advan-
tage of this method is that each observation is used for both the training and the hold-out
part and thus we achieve and efficient exploitation of the given data. For the actual pa-
rameter estimation we again use maximum likelihood. For further details the reader is
referred to [7].
No closed form solution for the estimation of
using leaving-one-out can be given.
Nevertheless, an interval for the value of this parameter can be explicitly calculated as
(14)
6
Normally the numerator of (11) would be . Allowing the generalization
presented in the main text allows us to use discounting parameters greater than
, which will
be specially interesting when we consider document length normalization (see 4.1).
112

where is the number of words that have been seen exactly
times in the training set. Since in general leaving-one-outtends to underestimate the ef-
fect of unseen events we choose to use the upper bound as the leaving-one-out estimate
(15)
Comparing the results with this estimation and with the optimum parameter determined
on the test set for full vocabulary, in which can be considered a “cheating” experiment,
we observed that this estimate performs very well on every corpus, as nearly no classi-
fication accuracy, if any at all, is lost.
4.1 Document length normalization
The multinomial naive Bayes text classifier is biased towards correctly classifying long
documents due to the unrealistic assumption that the class-conditional word posterior
probabilities are independent of the document length. Because of this assumption the
estimate (8) is dominated by the word counts coming from long documents.
One possible solution to this problem is to normalize the word counts of each doc-
ument with respect to its length
(16)
where
can be any arbitrary constant, such as the average document length.
Multinomial distributions with fractional counts are ill-defined. Nevertheless the
derivations made in section 2 are extensible to fractional counts and so the estimate (8)
is still valid. Another point to note is that the classification rule (4) is invariant to length
normalization, so test documents can be classified without prior normalization. The
smoothing techniques presented in 4 can also be directly applied, but the leaving-one-
out estimate can not be easily adapted to this situation.
5 Experiments
For our experiments we used five different corpora: the 20 Newsgroups data set, the
Industry Sector data set, the 7 Sectors data set, the WhizBang! Job Categorization data
set and the 4 Universities data set.
The Industry Sector data set, made available by Market Guide Inc., and the 7 Sec-
tors data set from World Wide Knowledge Base (Web
KB) project of the CMU Text
Learning Group [11], consist both of collections of web pages from different compa-
nies, divided into a hierarchy of classes. In our experiments, however, we have “flat-
tened” this structure, assigning each document a class consisting of the whole path to
the document in the hierarchy tree.
The WhizBang! Job Categorization data set consist of job titles and descriptions,
also organized in a hierarchy of classes. This corpus contains labeled and unlabeled
samples and only the former were used in our experiments.
113

Table 1. Corpus statistics
Corpus #Documents #Classes Vocabulary Avg. doc. length
Industry Sector
7 Sectors
Job Category
20 Newsgroups
4 Universities
The 20 Newsgroups data set is a collection of approximately 20000 newsgroupdoc-
uments, partitioned nearly evenly across 20 different newsgroups. We used the original
version of this data as providedin www.al.mit.edu/
jrennie, in which document headers
are discarded, but the “From:” and “Subject:” header files are retained. The documents
were sorted by their posting date, the first 800 documents of each class were used for
training and the rest for testing.
The 4 Universitiesdata set, also available fromthe CMU Web
KB project, consists
of a set of web pages from the computer science departments of 4 different universities.
There is a total of 7 classes defined, but according to the usual procedure only the four
most populated ones
7
were used in the experiments. It is also usual practice to train with
data of three universities and test with the data of the remaining university. The results
presented here are therefore the average values of the four experiments.
The statistics of each corpus are shown in Table 1. Unless stated otherwise (i.e.
in the 20 newsgroups and 4 Universities data sets) the corpora were randomly split
into a training set consisting of approximately 80% of the samples for training and the
remaining 20% for test.
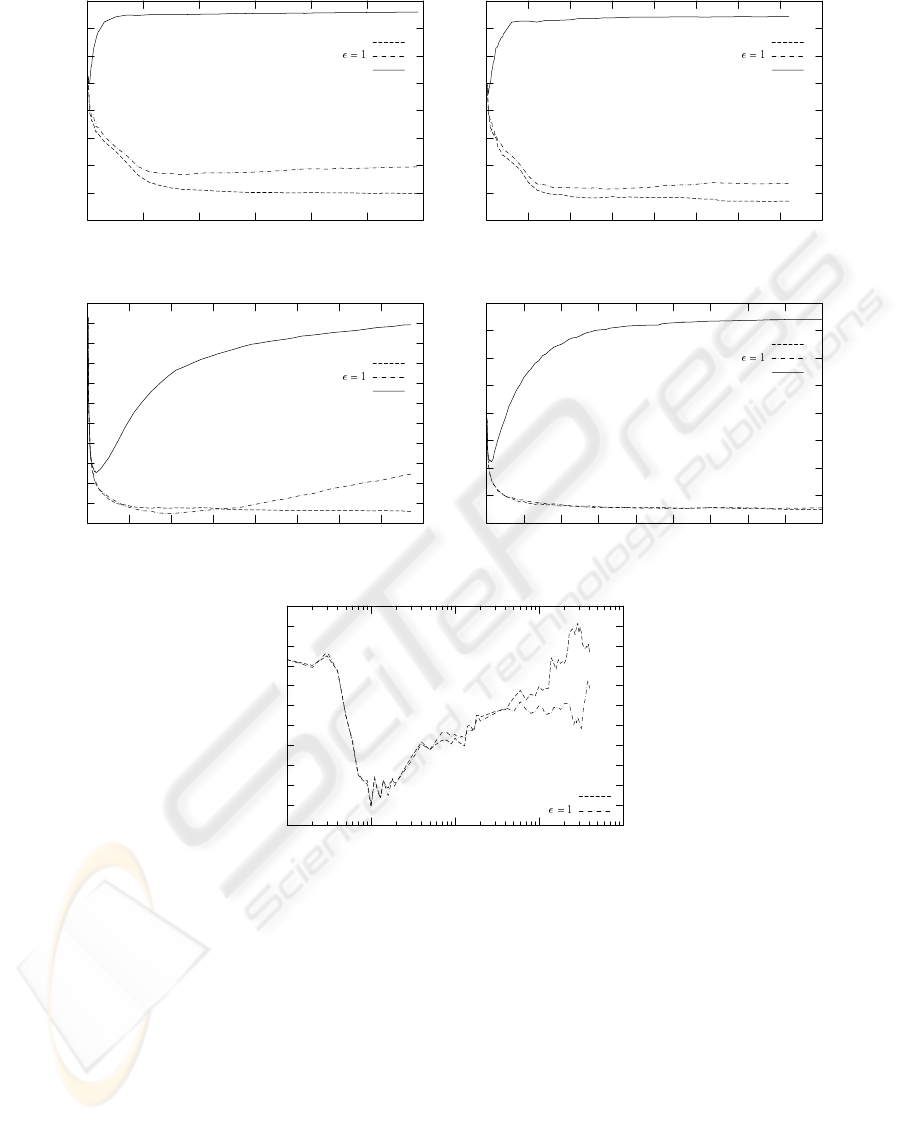
Figure 1 shows the error rate as a function of the vocabulary size for all the corpora.
It can be clearly seen that only for small vocabulary sizes the maximum likelihood
estimator can be directly used. Using the “traditional” Laplace smoothing to avoid zero
probabilities the best results are achieved using a reduced vocabulary set in three of the
five corpora, as claimed in previous works. Using the unigram interpolation smoothing
technique, however, better results are obtained, and in the first four corpora the best
performance is achieved using the whole vocabulary set.
The remaining corpus, the 4 Universities data set, presents an anomalous behavior,
as shown in figure 1(e). The best results are obtained with an extremely reduced vocab-
ulary set (100 words) and the evolution of the error rate is rather irregular and does not
correspond to the expected behavior as observed in the other corpora. In this case we
hardly improve the error rate using any smoothing technique. We feel that no signifi-
cant conclusions can be extrapolated from this corpus. The results are summarized in
Table 2.
We also found out that length normalization increases the accuracy of the classi-
fier, an example can be seen in Figure 2. However in this case we can not make use of
Equation (13) as the “count counts”
are not well defined, and the parameter was
7
Without taking the class “others” into account.
114
10
20
30
40
50
60
70
80
90
0 10000 20000 30000 40000 50000 60000
Error rate (%)
Vocabulary size
Unigram Interpolation using l-1-o
Laplace Smoothing
No Smoothing
(a) Industry Sector Corpus
10
20
30
40
50
60
70
80
90
0 5000 10000 15000 20000 25000 30000 35000 40000
Error rate (%)
Vocabulary size
Unigram Interpolation using l-1-o
Laplace smoothing
No smoothing
(b) 7 Sectors Corpus
30
32
34
36
38
40
42
44
46
48
50
52
0 10000 20000 30000 40000 50000 60000 70000 80000
Error rate (%)
Vocabulary size
Unigram Interpolation using l-1-o
Laplace smoothing
No smoothing
(c) Job Category Corpus
10
20
30
40
50
60
70
80
90
0 10000 20000 30000 40000 50000 60000 70000 80000 90000
Error rate (%)
Vocabulary size
Unigram Interpolation using l-1-o
Laplace smoothing
No Smoothing
(d) 20 Newsgroups Corpus
11
12
13
14
15
16
17
18
19
20
21
22
10 100 1000 10000 100000
Error rate (%)
Vocabulary size (logarithmic scale)
Unigram Interpolation using l-1-o
Laplace smoothing
(e) 4 Universities Corpus
Fig.1. Error rate as a function of the vocabulary size for different corpora
115

10
15
20
25
30
35
40
45
50
55
60
0 5000 10000 15000 20000 25000 30000 35000 40000
Error rate (%)
Vocabulary size
Unigram Interpolation using l-1-o
Laplace smoothing
Length Normalization
Fig.2. Effect of length normalization on the corpus 7 sectors
empirically estimated on the test set, and therefore the results are not directly compa-
rable. Somehow surprisingly in the Job category data set the best results are obtained
using the simpler Laplace smoothing with smoothing parameter
.
Table 2. Summary of classification error rates for the five tasks, using the optinum number of
features.
Smoothing method
Corpus None Laplace Abs. disc.
Industry-Sector 60.1 26.7 19.8
7 Sectors 56.2 21.4 16.9
Job category 35.0 31.2 31.1
20 Newsgroups 32.3 15.3 14.9
4 Universities 12.1 12.0 11.9
6 Concluding remarks
We have shown that for all of the corpora,using absolute discounting smoothing we ob-
tain the best results. For four out of the five tested corpora, the best results are obtained
using the whole vocabulary set. This is a satisfying result and shows that the applied
smoothing techniques effectively redistribute the probability mass among the unseen
events.
We also have shown that using length normalization we usually achieve better re-
sults. However the experiments we have performed were optimized on the test set, in
order to try if this method could achieve better results. The next natural step is to find a
well-defined estimation for the discounting parameter. Another conclusion from these
116

results is that the length independenceassumptions we made in Section 2 are too unreal-
istic and perhaps an explicit length model has to be included in our general formulation.
We feel that better results could be achieved by improving the feature selection
techniques and perhaps including a weighting of the different terms, in a similar way as
it is done in prototype selection for
nearest neighbors classifiers.
References
1. McCallum, A., Nigam, K.: A comparison of event models for naive Bayes text classification.
In: AAAI/ICML-98 Workshop on Learning for Text Categorization, AAAI Press (1998) 41–
48
2. Lafuente, J., Juan, A.: Comparaci´on de Codificaciones de Documentos para Clasificaci´on
con K Vecinos M´as Pr´oximos. In: Proc. of the I Jornadas de Tratamiento y Recuperaci´on de
Informaci´on (JOTRI), Val`encia (Spain) (2002) 37–44 (In spanish).
3. Nigam, K., Lafferty, J., McCallum, A.: Using maximum entropy for text classification (1999)
4. Yang, Y., Pedersen, J.O.: A comparative study on feature selection in text categorization.
In Fisher, D.H., ed.: Proceedings of ICML-97, 14th International Conference on Machine
Learning, Nashville, US, Morgan Kaufmann Publishers, San Francisco, US (1997) 412–420
5. Cover, T.M., Thomas, J.A.: Elements of Information Theory. Wiley Series in Telecommuni-
cations. John Wiley & Sons, New York, NY, USA (1991)
6. Nigam, K., McCallum, A.K., Thrun, S., Mitchell, T.M.: Text classification from labeled and
unlabeled documents using EM. Machine Learning 39 (2000) 103–134
7. Ney, H., Martin, S., Wessel, F.: Satistical Language Modeling Using Leaving-One-Out. In:
Corpus-based Methods in Language and Speech Proceesing. Kluwer Academic Publishers,
Dordrecht, the Netherlands (1997) 174–207
8. Juan, A., Ney, H.: Reversing and Smoothing the Multinomial Naive Bayes Text Classifier.
In: Proc. of the 2nd Int. Workshop on Pattern Recognition in Information Systems (PRIS
2002), Alacant (Spain) (2002) 200–212
9. Duda, R.O., Hart, P.E., Stork, D.G.: Pattern Classification. John Wiley & Sons, New York,
NY, USA (2001)
10. Efron, B., Tibshirani, R.J.: An Introduction to the Bootstrap. Chapman & Hall, New York,
NY, USA (1993)
11. Group, C.T.L.: World wide knowledge base (web
kb) project. (http://www-
2.cs.cmu.edu/afs/cs.cmu.edu/project/theo-11/www/wwkb/)
12. Chen, S.F., Goodman, J.: An empirical study of smoothing techniques for language mod-
eling. In Joshi, A., Palmer, M., eds.: Proceedings of the Thirty-Fourth Annual Meeting of
the Association for Computational Linguistics, San Francisco, Morgan Kaufmann Publishers
(1996) 310–318
117
