
A New Entity-relation Joint Extraction Model using Reinforcement
Learning and Its Application Test
Heping Peng
1
, Zhong Xu
1
, Wenxiong Mo
1
, Yong Wang
1
, Qingdan Huang
1
, Chengzhu Sun
2, *
and Ting He
2
1
Guangzhou Power Supply Bureau of Guangdong Power Grid Co Ltd, Guangzhou, China
2
College of Computer Science and Technology, Huaqiao University, Xiamen, China
Keywords: Joint Extraction, Entity, Relation, Reinforcement Learning.
Abstract: Extractions of entity and relation are the key part of natural language processing and its application. The
current popular entity extraction methods mainly rely on artificially formulated features and domain
knowledge which cannot achieve simultaneous extraction of entities and their relations, and are largely
affected by noise labeling problems. This paper proposes a new entity-relation extraction model based on
reinforcement learning. This model uses the joint extraction tagging strategy in which the sentences are firstly
input into a joint extractor based on the Long Short-term Memory network for prediction and subsequently
the reinforcement learning algorithm is based on the Policy Gradient for the extraction training. The model is
tested on a public application dataset and the experimental results show the validity of the presented joint
extraction algorithm.
1 INTRODUCTION
There are currently two methods that are widely used
to solve the tasks of entity and relationship extraction.
The traditional pipeline method first extracts the
entities and then identifies the relations between the
pair of entities. These two separations make the task
easy to handle and more flexible. But in fact, these
two tasks have a close relationship. The entity
extracts information to further help the relation
extraction. The quality of the entity extraction
module will affect the relation extraction module. If
the extracted entity pair has no relationship, it will
bring unnecessary information. Noise is generated,
which increases the error rate of relation extraction
(Li, 2014, Ji, 2014). Unlike the pipeline approach, the
joint extraction approach aims to extract both entities
and relations using only one model framework. This
method can effectively extract the semantic
relationship between entities from unstructured text,
and can improve the pipeline-based information
extraction method. However, most existing joint
extraction methods are feature-based structured
systems (Ren 2016, Wu 2016, He 2016), which often
require complex feature engineering and, to some
extent, rely on other NLP toolkits to cause errors to
spread. In order to reduce manual work in feature
extraction, Zheng (Zheng, 2017, Wang, 2017, Bao,
2017) proposed a hybrid neural network model to
extract entities and their relations simultaneously
without any manual features. Although the federated
model can represent entities and relations with shared
parameters in a single model, they also extract entities
and relationships, respectively, and generate other
information.
In this paper, the joint extraction of entities and
relations of unstructured texts is studied in detail. The
policy gradient reinforcement learning algorithm
(Williams, 1992) and Long Short-term Memory
(LSTM) (Hochreiter, 1997, Schmidhuber, 1997) are
used to solve the above problems. This paper
proposed the algorithm model combining
reinforcement learning and deep learning to jointly
extract the entities and relations of public corpus by
applying the joint extraction tagging strategy.
Research on deep reinforcement learning methods
has been widely developed and successfully applied
in fields such as text games (Pascual, 2015,
Gurruchaga, 2015, Ginebra, 2015) and dialogue
generation (Narasimhan, 2015, Kulkarni, 2015,
Barzilay, 2015). The LSTM-based end-to-end model
has been successfully applied to the named entity
recognition tag task (Lample, 2016, Ballesteros,
992
Peng, H., Xu, Z., Mo, W., Wang, Y., Huang, Q., Sun, C. and He, T.
A New Entity-relation Joint Extraction Model using Reinforcement Learning and Its Application Test.
DOI: 10.5220/0011361800003440
In Proceedings of the International Conference on Big Data Economy and Digital Management (BDEDM 2022), pages 992-999
ISBN: 978-989-758-593-7
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

2016, Subramanian, 2016). The LSTM neural
network model can solve the problem of long-term
sequence dependence, which is very helpful for
sequence modeling tasks. This paper will firstly
introduce joint tagging strategy for entity and relation
extraction and joint extractor based on Long Short-
term Memory network and trainer based on Policy
Gradient reinforcement learning algorithm. The main
contributions of this paper are as follows:(1) A new
model based on reinforcement learning algorithm is
proposed for joint extraction of entity and relation. (2)
The Policy Gradient reinforcement learning
algorithm is applied to the joint extraction problem,
and it can better predict the entities and their relations.
The model scheme based on this paper has achieved
better results than most existing pipelines, joint
learning methods, and provides new ideas for future
research in this field.
2 RELATED WORK
Extraction of entities and relations are two common
tasks in NLP (Zou, 2014, Huang, 2014, Wang, 2014),
for example in Table 1 they are very beneficial for
many NLP tasks such as social media analysis tasks
(Sang, 2012, Xu, 2012). These two tasks are mainly
based on the pipeline method and the joint extraction
method. The traditional method treats the two
subtasks, Named Entity Recognition (NER) (Nadeau,
2007, Sekine, 2007) and Relation Classification (CR)
(Rink, 2010, Harabagiu, 2010), into separate tasks in
a pipelined manner.
Table 1: Examples for the entities and relations extraction
task.
Sentences Entities Relation
1
Bill Gates and Steve
Ballmer joined
forces at Microsoft
in 1980.
Bill Gates,
Microsoft
Company-
Founder
2
Bill Gates and Paul
Allen founded the
predecessor of
Microsoft.
Bill Gates,
Microsoft
Company-
Founder
3
Bill Gates was the
co-founder and
CEO of Microsoft.
Bill Gates,
Microsoft
Company-
Founder
4
Bill Gates was born
in the US.
Bill Gates,
US
PlaceofBirth
2.1 Pipeline Method
The classical NER model is a linear statistical model,
such as Hidden Markov Model (HMM) (Luo, 2016,
Huang, 2016, Lin, 2016) and Conditional Random
Fields (CRF) (Passos, 2014, Kumar, 2014, Mccallum,
2014), whose performance depends largely on
manual features of NLP tools and external knowledge
resource extraction. Currently, Recurrent Neuron
Network (RNN) exhibits better performance than
many other neural networks in many sequence-to-
sequence tasks. In the neural network architecture,
NER is considered a continuous marking task. Chiu
and Nichols (Chiu, 2015, Nichols, 2015) proposed a
hybrid model by learning the characteristics of
character and word levels. They independently code
each tag on a linear layer and a log-softmax layer.
Miwa and Bansal (Miwa, 2016, Bansal, 2016)
proposed a coded Bi-directional Long Short-term
Memory (Bi-LSTM) and a separate incremental
neural network structure to jointly decode the tags.
The existing relational classification models
mainly include manual feature-based methods, neural
network-based methods and other valuable methods
(Yu, 2014, Gormley, 2014, Dredze, 2014), Mooney
and Bunescu (Bunescu, 2005, Mooney, 2005) used
distant supervision methods for classification, which
is supervised. The method relies heavily on high
quality label data. Rink (Rink, 2010, Harabagiu,
2010) designed to extract 16 features by using a
number of supervised NLP toolkits and resources
(including part-of-speech tagging POS, English
dictionary Word-Net, etc.). However, this approach
requires a lot of work to design and extract features
and is heavily dependent on other NLP tools. In
recent years, neural network models have been
widely used in relational classification including
convolutional neural networks (Chiu, 2015, Nichols,
2015), long short-term memory networks (Ebrahimi,
2015, Dou, 2015), etc., have achieved good results.
There are other valuable methods. Nguyen (Nguyen,
2009, Moschitt, 2009, Riccardi, 2009) studied the use
of innovative kernels based on syntax and semantic
structure. The synthetic model FCM (Yu, 2014,
Gormley, 2014, Dredze, 2014) studied the
representation of a substructure of an infinite word
statement, and FCM can easily handle arbitrary Type
input and global information.
2.2 Joint Extraction Approach
The entities and relationships extracted based on the
pipeline method ignore the relationship between
these two subtasks, and thus propose a joint
A New Entity-relation Joint Extraction Model using Reinforcement Learning and Its Application Test
993
extraction model. Li and Ji (Li, 2014, Ji, 2014)
proposed a joint model that incrementally predicts
entities and relationships using a structural
perceptron with efficient directed search. Dan and
Yih (Dan, 2007, Yih, 2007) studied the global
reasoning of entity and relationship recognition
through linear programming formulas. Feng and
Zhang (Feng, 2017, Zhang, 2017, Hao, 2017)
combined the intensive learning Q-learning algorithm
with the neural network to extract entities and
relationships. Kate and Mooney (Kate, 2010,
Mooney, 2010) proposed a new method for joint
entities and relation extraction using card pyramid
parsing. Yu and Lam (Yu, 2012, Lam, 2012) jointly
identify entities and extract relationships in an
encyclopedia through a graphical model approach.
Although these methods implement joint extraction,
they cannot achieve high accuracy of entity and
relationship extraction and joint extraction at the
same time.
3 THE JOINT EXTRACTION OF
ENTITIES AND RELATIONS
USING REINFORCEMENT
LEARNING
This paper treats the joint entity and relation
extraction task as a Markov Decision Process (MDP)
and divides a complete joint extraction procedure into
two parts-joint extractor and reinforcement learning
for trainer. For every sentence in a bag, a
reinforcement learning episode will extract the
entities and their relation. Briefly, each sentence will
have its corresponding action which predicted by the
joint extractor and then predict that the bag relation
calculated by the proposed reward function will be
compared to the truly correct bag value. Finally, the
trainer which is the agent by getting rewards trains
the LSTMs network until convergence. Figure 1
shows how the proposed method works.
Figure 1: Overall process of this research.
3.1 Joint Extractor
This paper adopted a novel tagging scheme published
in 2017 from the Association for Computational
Linguistics (ACL) conference for joint extraction
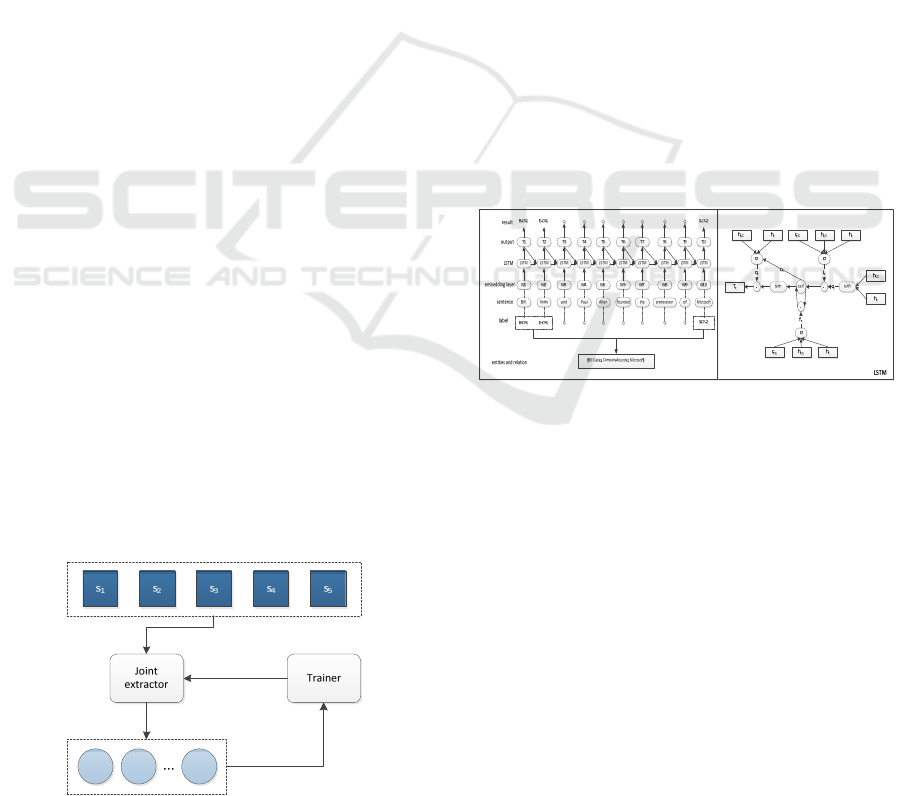
(Zheng, 2017, Wang, 2017, Bao, 2017). Specifically,
tag “O” represents the “Other” bag; the location
information of the word in the entity is marked as
{B(the start of entity), I(the interior of entity), E(the
end of entity), S(single entity)}; the information of
relationship type{1, 2}, Where {1, 2} are respectively
represented as {entity1, entity2}. This strategy
combines the two subtasks in the information
extraction into a sequence labeling problem to further
improve the extraction task. Based on the use of a
joint extraction tagging scheme, this paper only
applies one LSTM network to highlight the role of
reinforcement learning algorithm. The LSTM
network is mainly composed of three gates: forget
gate, input gate and output gate which have the ability
to delete or add information to the cell state. Take the
sentence “Bill Gates and Paul Allen founded the
predecessor of Microsoft” as an example, where
Company-Founder (CF) is the relation of Bill Gates
and Microsoft. Figure 2 displays the novel strategy
combined with LSTM network and LSTM memory
block.
Figure 2: Example for joint extraction tagging scheme and
LSTM block.
The LSTM network is a special extension of
recurrent neural network to avoid long-term
dependency problems. The gate structure is a way to
selectively pass information, usually consisting of a
sigmoid function and a point-by-point product
operation (the output value of the sigmoid layer is 0
to 1, 0 and 1 respectively indicate that the information
has passed and all failed). The detail operation of
LSTM can be defined as follows:
i
t
=δ
(
W
wi
h
t
+W
hi
h
t-1
+W
ci
c
t-1
+b
i
)
(1)
f
t
=δ
(
W
wf
h
t
+W
hf
h
t-1
+W
cf
c
t
-
1
+b
f
)
(2)
z
t
=tanh
(
W
wc
wh
t
+W
hc
h
t-1
+b
c
)
(3)
BDEDM 2022 - The International Conference on Big Data Economy and Digital Management
994

𝑐
=
𝑓
𝑐
+𝑖
𝑧
(4)
o
t
=δ
(
W
wo
h
t
+W
ho
h
t-1
+W
co
c
t
+b
o
)
(5)
ℎ
=𝑜
tanh
(
𝑐
)
(6)
𝑇
=𝑊
ℎ
+𝑏
(7)
Where w is the weight and b is the bias. The final
softmax layer computes the confidence vector 𝑦
:
𝑦
=𝑊
𝑇
+𝑏
(8)
𝑝
(
𝑎
|
𝑠
,𝜓)
exp (𝑦
)
∑
exp (𝑦
)
(9)
Where 𝑎
is the action predicted by the network,
𝑠
is the representation by the joint extractor
predicted and 𝑁
is the total number of tags. In order
to accelerate the training of the model and improve
the accuracy of the model, this paper pre-trained the
neural network and define the objective function of
the joint extractor using RMSprop proposed by
Hinton (Hinton 2012, Srivastava 2012, Swersky
2012) as follows:
𝐽
(
𝜓
)
= 𝑚𝑎𝑥log(𝑝
||
=𝑦
|𝑠
,𝜓)
(10)
Where |𝑆| is the size of dataset, 𝐿
is the length
of sentence 𝑠
, 𝑦
is the label of word t in the
sentence 𝑠
and 𝑝
is the normalized probabilities
of tags which defined in equation (9).
3.2 Reinforcement Learning for
Trainer
This paper represents the MDP as a tuple (S, A, T, R),
where S={s} is the collection of states, A={a} is the
set of all actions, R(s) is the reward function, and
𝑇(𝑠
‘
|𝑠,𝑎) is the transition function. This paper
introduces these definitions as follows:
States. In order to take advantage of the dataset,
this paper splits the training sentences 𝑆=
{𝑠
,𝑠
,…,𝑠
} into N bags. Define the sentence input
under the current bag as state 𝑠
in MDP.
Actions. This paper uses the policy gradient
algorithm based on round update which can directly
output the action value, while method based on value
function can’t output action values, but state-action
values. Therefore, this paper will adopt the output
value predicted by the LSTM network as the action in
the MDP. Then according to the used tagging strategy,
the total number of actions is 𝑁
=2∗4∗|𝑅|,
where |𝑅| is the size of the predefined relation set.
Rewards. The reward function is chosen to
maximize the final extraction accuracy. First, when
predicting the distribution of each sentence, the
predicted "O" tag is ignored. In the remaining
predicted entity relationship tags, the relationship of
the relationship with the largest probability value is
selected as the current sentence, and then the
probability value is selected by the maximum
likelihood estimation. The biggest as the current bag
prediction relationship, compared with the gold bag.
If they are the same, the reward value of +1 for each
label of the data set is given except “O”, and if it is
different, the reward value of -1 is given. The specific
formula of the reward function is expressed as
follows:
𝑅
(
𝑠
|
𝐵
)
= 𝛾
𝑟
=
⎩
⎪
⎨
⎪
⎧
𝛾
𝑟
=1
−𝛾
𝑟
=−1
For example in table 1, the first three statements
can be thought of as a bag. When joint extractor
predicted every word’s label, the label predicted is
“O” like the words “and, joined, in,…” in the first
sentence is ignored. And sampling the probabilities
that the words “Bill”, “Gates”, “Microsoft” are
predicted to “B-CF-1”, “E-PoB-1”, “S-CP-2”
respectively is 0.9, 0.85, 0.7, so the maximum
probability of 0.9 as the relation “Company-Founder”
of the current sentence. Similarly, supposing the
relations of the second sentence and the third is
“Company-Founder”, “PlaceofBirth”. By likelihood
function, the relation of this bag can be calculated as
“Company-Founder”. Due to the gold relation of this
bag is “Company-Founder”, thence the episode
reward will be to set +1.
Transitions. For every episode, a sentence in a bag
will be extracted and immediately next sentence will
be input to joint extractor. One transition includes the
agent being given the state s containing current
information and the future generated. The transition
function 𝑇(𝑠
|𝑠,𝑎) incorporates the reward value
from the agent in state 𝑠 and continue to choose the
next state 𝑠
. The episode stops whenever the model
is convergent.
A New Entity-relation Joint Extraction Model using Reinforcement Learning and Its Application Test
995

Optimization. This paper uses the reinforcement
learning algorithm (Williams 1992) to optimize the
model. For a bag B with n sentences, the expected
total reward will be maximized in the episode. The
reward function of the sentence is 𝑅(𝑠
|𝐵), so the
objective function definition is as follows:
𝐽(𝜃) = 𝐸
,…,
𝑅(𝑠
|𝐵)
(12)
According to the policy gradient algorithm
(Williams 1992), this paper regards 𝑎
as the
predicted label of 𝑠
and update the gradient 𝜃 by
using the likelihood in the following way:
∇𝐽
=∇𝑝
(
𝑎
|
𝑠
,𝜃)𝑅(𝑠
|𝐵)
(13)
Algorithm 1. Presents the details of complete
joint training process based on MDP framework
ALGORITHM 1: Reinforcement learning for entities
and relations extraction
(
Trainin
g
p
hase
)
Initialize the parameters of the LSTM model of joint
extractor with random weights respectively. Pre-train
the LSTM model to predict entities and their relation
given the sentence by joint tagging scheme, where the
parameters are 𝜓.
Input: Episode number L.
𝐁=
{
𝐵
,𝐵
…,𝐵
}
. A LSTM network
model parameterized 𝜓.
Initialize the target network as: 𝜃
=𝜃=𝜓
For episode l=1 to L do
Shuffle B to obtain the bag sequence
𝐁={𝐵
,𝐵
,…,𝐵
}
Foreach 𝐵
∈𝐁 do
Sample the entities and relations for each
sentence in 𝐵
with 𝜃
Compute reward 𝑅
(
𝑠
|
𝐵
)
for current
sentence
𝑅
(
𝑠
|
𝐵
)
=
∑
𝛾
𝑟
end
Update 𝜃 in the model:
∇
𝐽
=∇𝑝
(
𝑎
|
𝑠
,𝜃
)𝑅(𝑠
|𝐵)
End
4 EXPERIMENT
4.1 Data
This paper adopted ACE2005 which previous studies
has reported on to evaluate the model and use three
common metrics: precision(P), recall(R) and F1-
score(F1). ACE2005 includes three parts: English,
Chinese and Arabic. In order to compare with most
previous work, this paper use the same way (Li 2014,
Ji 2014) with the English dataset to split and
preprocess the data. There are 351 training
documents, 80 validation documents and 80 testing
documents. ACE2005 includes three parts: English,
Chinese and Arabic and defines 7 coarse-grained
relation types. Relation types are “PHYS”(Physical),
“GEN-AFF”(Gen-Affiliation), “ART”(Artifact),
“PART-WHOLE”(Part-Whole), “PER-
SOC”(Person-Social), “ONG-AFF”(Org-Affiliation)
and “METONYMY”(Metonymy). In the process of
extraction, entities and relations can be extracted in a
sentence simultaneously.
4.2 Hyperparameters
This paper employed word2vec to train the word
embeddings and set the dimension of word
embeddings as 300, the number of LSTM units is
fixed at 300 and dropout rate is 0.5. The batch size is
fixed to 160 and episode number is 20. This paper
uses Adam to optimize parameters during the training
procedure. The learning rate is 0.002 and set 𝛾=1
because in this task, the order of sentences in bag
should not influence the predicted result (Zeng 2018,
He 2018, Liu 2018).
Table 2: Entity and relationship extraction results.
Method Entity Relation
Score P(%) R(%) F1(%) P(%) R(%
)
F1(%)
Pipeline (Li
2014, Ji 2014)
83.2 73.6 78.1 67.5 39.4 49.8
Joint
w/Global (Li
2014, Ji 2014)
85.2 76.9 80.8 68.9 41.9 52.1
SPTree (Miwa
2016, Bansal
2016)
82.9 83.9 83.4 57.2 54.0 55.6
RL 86.7 82.1 84.3 69.7 43.4 53.5
4.3 Baselines
The baseline used in this paper is the latest method of
the ACE2005 dataset, including a classic pipeline
model (Li 2014, Ji 2014), a joint feature-based model
called joint w/Global (Li 2014, Ji 2014) and an end-
to-end neural network-based model called SPTree
(Miwa 2016, Bansal 2016). The classic pipeline
method (CRF+ME) trains a linear chain conditional
random field for entity extraction and maximum
BDEDM 2022 - The International Conference on Big Data Economy and Digital Management
996
entropy model for relational extraction. SPTree
proposes a new end-to-end relation extraction model
that represents word sequences and dependent tree
structures through LSTM-RNNs of bidirectional
sequences and bidirectional tree structures. Joint
w/Global developed a number of effective global
features to capture the interdependency among entity
mentions and relations.
4.4 Results
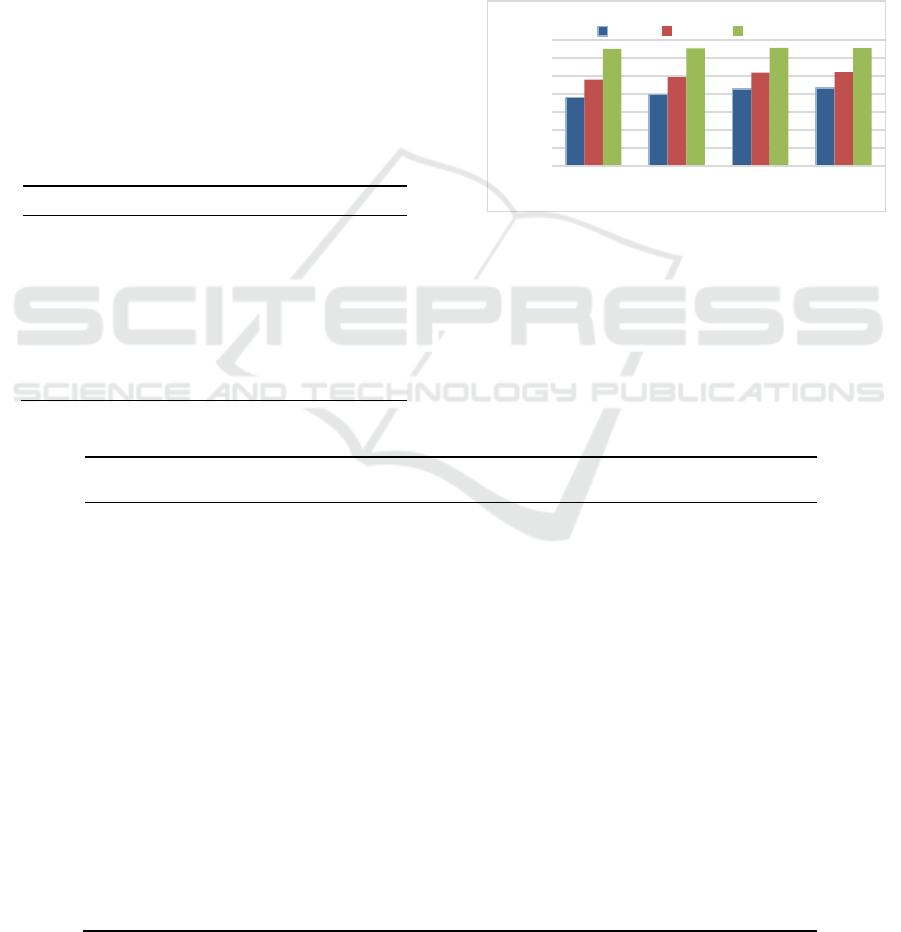
The results of the separate extraction of entities and
relation are shown in Table 2. The combined results
of the joint extraction are shown in Table 3, Where
RL is the method of this paper. The F1 value reached
52.3%, which is the best result compared to the
existing method. It illustrates the effectiveness of the
proposed model in the task of joint extraction of
entities and their relationships.
Table 3: Joint extraction prediction results.
Model P(%) R(%) F1(%)
Pipeline (Li 2014,
Ji 2014)
65.1 38.1 48.1
Joint w/Global (Li
2014, Ji 2014)
65.4 39.8 49.5
SPTree (Miwa
2016, Bansal 2016)
65.8 42.9 51.9
RL 65.6 43.5 52.3
As can be seen from the data in the table 2, SPTree
achieves the highest recall rate for entities and
relations and also is best at the F1 value of the
relations, they are respectively 83.0%, 54.0 and
55.6%. However, the model RL in this paper has the
highest precision in terms of entities and relations and
also is best at the F1 value of the entities, they are
respectively 86.7%, 69.7% and 84.3%. In the joint
extraction of entities and relations from the table 3,
the highest F1 value was also achieved. In order to
facilitate a clear understanding of the indicators
obtained by various models, the histogram 3
characterizes the metrics.
Figure 3: Comparison of histograms of metrics obtained by
each model.
Table 4: Relation of “PlaceofBirth” predicted by the models.
Sentences whose relation type is “PlaceofBirth” RL
PCNN+
Max
PCNN+
ATT
For the two most powerful Americans in Iraq, Gen. George
W. Casey Jr. and Ambassador Zalmay Khalilzad, as for the
Iraqi dignitaries who had gathered here, it was a symbolic
moment: a ceremony on a bluff high above the Tigris River
at which the Americans formally returned the largest of
Saddam Hussein's palace complexes to Iraqi sovereign
control, 31 months after invading troops had seized it for use
as an American base.
PlaceofBirth NA
PlaceofB
irth
It seems inevitable that he's coming back, center fielder
Randy Winn said Wednesday in Los Angeles as the Giants
completed a three-game series with the Dodgers.
PlaceofBirth PlaceofBirth
PlaceofB
irth
The group moved its headquarters to France and then to
Iraq in 1986, when it set up a well-financed military base
under the protection of Saddam Hussein.
PlaceofBirth NA
PlaceofB
irth
Ingrid Rossellini said she was outraged by the conceit, and
by the showing of a widely known scene from the director’s
Rome: Open City in which a German soldier shoots a
character,
p
la
y
ed b
y
Anna Ma
g
nani, in the stomach.
PlaceofBirth PlaceofBirth NA
American commanders have described the violence in Iraq
as being caused variously by a mix of foreign terrorists,
Sunni loyalists to Saddam Hussein, Shiite radicals and
criminals.
PlaceofBirth NA
PlaceofB
irth
/通用格式
/通用格式
/通用格式
/通用格式
/通用格式
/通用格式
/通用格式
/通用格式
Pipeline Joint w/Global SPTree RL
Metrics
Method
R(%) F1(%) P(%)
A New Entity-relation Joint Extraction Model using Reinforcement Learning and Its Application Test
997
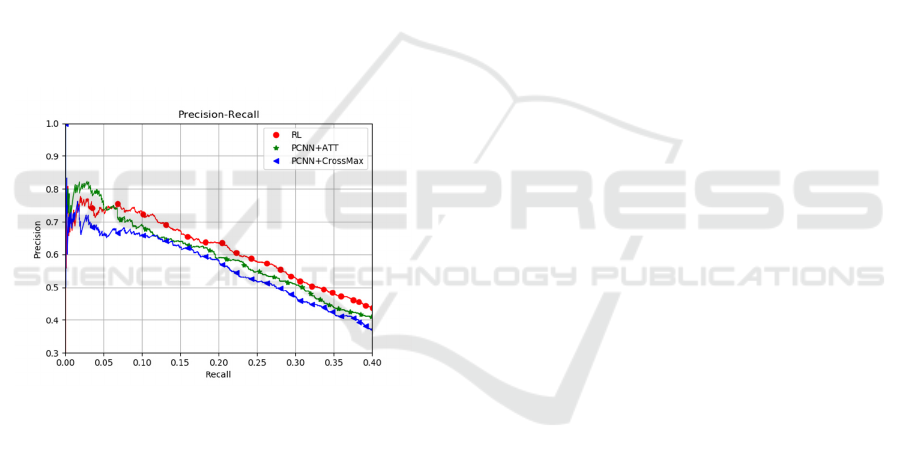
5 DISCUSSION
Entity and relation extractions are always handled in
an unbalanced corpus, where there is no relation
between entities in most statements. Therefore, the
public corpus-New York Time data set is used for
verification. The New York Times corpus is a distant
supervision dataset created by aligning the freebase
knowledge base with the New York Times corpus. In
order to evaluate how accurately the decision of the
Policy Gradient reinforcement learning algorithm
module is carried out, taking the current classical
mainstream comparison research methods
PCNN+CrossMax (Jiang 2016, Wang 2016, Li 2016)
and PCNN+ATT (Lin 2016, Shen 2016, Liu 2016) to
experiment for relation extraction. The
precision/recall curves of those models in Figure 4. It
can be seen from the model presented in this paper
outperforms other two methods. The maximum value
of F1-Score of this paper’s model can reach out
42.19%, although PCNN+CrossMax got the highest
precision.
Figure 4: Comparison between the PCNN+CrossMax and
PCNN+ATT.
By using the distant supervision as the guide of
reinforcement learning so that we can understand that
the model in this paper can better predict the relation
among the sentence. A real case is shown in table 4.
As can be seen from the table, the results predicted by
the model in this paper are correct, while the other
two models have certain errors
6 CONCLUSIONS
In view of the shortcomings of the pipeline method,
this paper proposes a new model using the
reinforcement learning algorithm, which can realize
the joint extraction of entities and relations at the bag
level by using the combination of the joint labeling
strategy and the special reward function. This model
mainly consists of two modules: one is joint extractor
based on the LSTM network with annotation
extraction strategy, and the other is the Policy
Gradient reinforcement learning algorithm for
training. Experiments show that the proposed model
can complete the joint extraction of entities and
relations at the bag level and achieve better results.
FUNDING
Research works in this paper are supported by the
research and application of the key technology of
electromagnetic transient cloud simulation platform
for extremely large urban distribution network
(080037KK52170012/GZJKJXM20170023).
REFERENCES
B. Pascual; M. Gurruchaga; M.P. Ginebra. A Neural
Network Approach to Context-Sensitive Generation of
Conversational Responses. Transactions of the Royal
Society of Tropical Medicine and Hygiene 2015, 51,
502-504, doi: 10.3115/v1/n15-1020.
Bunescu, R. C; Mooney, R. J. Subsequence kernels for
relation extraction. International Conference on Neural
Information Processing Systems. MIT Press 2005, 1,
171-178, doi: 10.1109/cicsyn.2012.13.
Chiu, J. P. C; Nichols. E. Named Entity Recognition with
Bidirectional LSTM-CNNs. Computer Science 2015,
doi: 10.1109/ebbt.2019.8741631.
Dan, R; Yih, W. T. Global Inference for Entity and Relation
Identification via a Linear Programming Formulation.
Introduction to Statistical Relational Learning 2007, 1,
doi: 10.7551/mitpress/7432.003.0022.
Ebrahimi, J; Dou, D. Chain Based RNN for Relation
Classification. Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies 2015, 1,
1244-1249, doi: 10.3115/v1/n15-1133.
Feng, Y; Zhang, H; Hao, W. Joint Extraction of Entities and
Relations Using Reinforcement Learning and Deep
Learning. Comput Intell Neurosci 2017, 2, 1-11, doi:
10.1155/2017/7643065.
Hinton, G; Srivastava, N; Swersky, K. Neural networks for
machine learning lecture 6a overview of mini-batch
gradient descent. Cited on 2012, 14, doi:
10.4135/9781526494924.
Hochreiter, S; Schmidhuber, J. Long short-term memory.
Neural Computation 1997, 9, 1735-1780, doi:
10.4324/9781315174105-4
Jiang, X; Wang, Q; Li, P. Relation extraction with multi-
instance multi-label convolutional neural networks, the
26th International Conference on Computational
BDEDM 2022 - The International Conference on Big Data Economy and Digital Management
998

Linguistics: Technical Papers 2016, 1, 1471-1480, doi:
10.1109/bibm.2018.8621435.
Kate R J, Mooney R J. Joint entity and relation extraction
using card-pyramid parsing. Association for
Computational Linguistics 2010, 1, doi:
10.1109/iccsnt.2011.6182359.
Lample, G; Ballesteros, M; Subramanian, S. Neural
Architectures for Named Entity Recognition. Neural
Architectures for Named Entity Recognition 2016, 1,
260-270, doi: 10.1109/bigcomp.2019.8679233.
Li, Q; Ji, H. Incremental Joint Extraction of Entity
Mentions and Relations. Proceedings of the 52nd
Annual Meeting of the Association for Computational
Linguistics 2014, 1, 402-412, doi: 10.3115/v1/p14-
1038.
Lin, Y; Shen, S; Liu, Z. Neural relation extraction with
selective attention over instances. Proceedings of the
54th Annual Meeting of the Association for
Computational Linguistics 2016, 1, 2124-2133, doi:
10.18653/v1/p16-1200.
Luo, G; Huang, X; Lin, C. Y. Joint Entity Recognition and
Disambiguation. Conference on Empirical Methods in
Natural Language Processing 2016, 1, 879-888, doi:
10.18653/v1/d15-1104.
M, Yu; MR, Gormley; M, Dredze. Factor-based
compositional embedding models. NIPS Workshop on
Learning Semantics 2014, doi 10.18653/v1/d15-1205.
Miwa, M; Bansal, M. End-to-End Relation Extraction using
LSTMs on Sequences and Tree Structures. ACL
2016, 1, 1105-1116, doi: 10.18653/v1/p16-1105.
Nadeau, D; Sekine, S. A survey of named entity recognition
and classification. Lingvisticae Investigationes 2007,
30, 3-26, doi: 10.1075/bct.19.03nad.
Narasimhan, K; Kulkarni, T; Barzilay, R. Language
Understanding for Text-based Games Using Deep
Reinforcement Learning. Computer Science 2015, 40,
1-5, doi: 10.18653/v1/d15-1001.
Nguyen, T. V. T; Moschitti, A; Riccardi, G. Dependency
and Sequential Structures for Relation Extraction.
Conference on Empirical Methods in Natural Language
Processing 2009, 6-7, 1378-1387, doi:
10.3115/1699648.1699684.
Passos, A; Kumar, V; Mccallum, A. Lexicon Infused
Phrase Embeddings for Named Entity Resolution.
Computer Science 2014, doi: 10.3115/v1/w14-1609.
Ren, X; Wu, Z; He, W. CoType: Joint Extraction of Typed
Entities and Relations with Knowledge Bases.
International World Wide Web Conferences Steering
Committee 2016, 1, 1015-1024, doi:
10.1145/3038912.3052708.
Rink, B; Harabagiu, S. UTD: Classifying semantic relations
by combining lexical and semantic resources.
Association for Computational Linguistics 2010, 1,
256-259, doi: 10.1515/9783110920116.xiii.
Sang, J; Xu, C. Right buddy makes the difference:an early
exploration of social relation analysis. ACM
International Conference on Multimedia 2012, 1, 19-
28, doi: 10.1145/2393347.2393358.
Williams, R. J. Simple statistical gradient-following
algorithms for connectionist reinforcement learning.
Machine Learning 1992, 8(3-4), 229-256, doi:
10.1007/978-1-4615-3618-5_2.
Yu, X; Lam, W. Jointly Identifying Entities and Extracting
Relations in Encyclopedia Text via A Graphical Model
Approach. International Conference on Computational
Linguistics DBLP 2012, 1, 1399-1407, doi:
10.1007/978-3-642-40585-3_34.
Zeng, X; He, S; Liu, K. Large scaled relation extraction
with reinforcement learning. Thirty-Second AAAI
Conference on Artificial Intelligence 2018, 1, doi:
10.5220/0006508702330238.
Zheng, S; Wang, F; Bao, H. Joint Extraction of Entities and
Relations Based on a Novel Tagging Scheme.
Proceedings of the Twenty-Seventh International Joint
Conference on Artificial Intelligence 2017, 1, 1227-
1236, doi: 10.24963/ijcai.2018/620.
Zou, L; Huang, R; Wang, H. Natural language question
answering over RDF:a graph data driven approach.
ACM SIGMOD International Conference on
Management of Data 2014, 1, 313-324, doi:
10.1145/2463676.2463725.
A New Entity-relation Joint Extraction Model using Reinforcement Learning and Its Application Test
999
