
Local Personal Data Processing with Third Party Code and Bounded
Leakage
Robin Carpentier
1,2
, Iulian Sandu Popa
1,2
and Nicolas Anciaux
1,2
1
University of Versailles-Saint-Quentin-en-Yvelines, Versailles, France
2
Inria Saclay-
ˆ
Ile-de-France, Palaiseau, France
Keywords:
Personal Data Management Systems, User Defined Functions, Bounded Leakage.
Abstract:
Personal Data Management Systems (PDMSs) provide individuals with appropriate tools to collect, manage
and share their personal data under control. A founding principle of PDMSs is to move the computation code
to the user’s data, not the other way around. This opens up new uses for personal data, wherein the entire
personal database of the individuals is operated within their local environment and never exposed outside,
but only aggregated computed results are externalized. Yet, whenever arbitrary aggregation function code,
provided by a third-party service or application, is evaluated on large datasets, as envisioned for typical PDMS
use-cases, can the potential leakage of the user’s personal information, through the legitimate results of that
function, be bounded and kept small? This paper aims at providing a positive answer to this question, which is
essential to demonstrate the rationale of the PDMS paradigm. We resort to an architecture for PDMSs based
on Trusted Execution Environments to evaluate any classical user-defined aggregate PDMS function. We show
that an upper bound on leakage exists and we sketch remaining research issues.
1 INTRODUCTION
Personal Data Management Systems (PDMSs) are
emerging, providing mechanisms for automatic data
collection and the ability to use data and share com-
puted information with applications. This is giving
rise to new PDMS products such as Cozy Cloud, Per-
sonium.io, Solid/PODS (Sambra et al., 2016) to name
a few, and to large initiatives such as Mydata.org sup-
ported by data protection agencies. Such initiatives
have been made possible by the successive steps taken
in recent years to give individuals new ways to re-
trieve and use their personal data. In particular, the
right to data portability in the European Union allows
individuals to retrieve their personal data from differ-
ent sources (e.g., health, energy, GPS traces, banks).
Context. Traditional solutions to handle compu-
tations involving user’s data usually requires them to
send those data to a third party application or service
that performs the computation. In contrast, a PDMS
can receive a third-party computation code and eval-
uate it locally. This introduces a new paradigm where
only aggregated computed results are externalized,
safeguarding user’s control on their data. The exam-
ple presented below illustrates this new paradigm.
’Green bonus’ Example. Companies want to re-
ward their employees having an ecological conduct,
and thus monthly compute a green bonus (finan-
cial incentive) based on the number of commutes
by bike. To this end, an employee collects her
GPS traces within her PDMS from a reliable service
(e.g., Google Maps). The traces are then processed
locally and the result is delivered to the employer
with compliance proof.
In this example, the PDMS must support ad hoc
code specified by the employer while preventing the
disclosure of personal data. Thus, the PDMS must
offer both extensiveness and security. Several similar
scenarios can be envisioned for service offers based
on statistical analysis of historical personal factual
data related to a user, e.g., health services (medi-
cal and prescription history), energy services (electric
traces), car insurance (GPS traces), financial services
(bank records).
Objective. This position paper aims at analysing
the conflict between extensiveness and security on
PDMSs. Supporting a code created by a third party
run by the PDMS to process large volumes of personal
data (typically an aggregation) calls for extensiveness.
However, the PDMS user (owner of the data and of
the PDMS) does not trust this code and the PDMS
must ensure security of the data during the process-
520
Carpentier, R., Sandu Popa, I. and Anciaux, N.
Local Personal Data Processing with Third Party Code and Bounded Leakage.
DOI: 10.5220/0011321900003269
In Proceedings of the 11th International Conference on Data Science, Technology and Applications (DATA 2022), pages 520-527
ISBN: 978-989-758-583-8; ISSN: 2184-285X
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
ing. More precisely, we search to control potential in-
formation leakage in legitimate query results during
successive executions of such code.
Limitations of Existing Approaches. Traditional
DBMSs ensure extensiveness of computations by
the support of user-defined functions (UDFs). But
UDF security relies on administrators, e.g., check-
ing/auditing UDF code and their semantics. In con-
trast, PDMSs are administered by laymen users. In
addition, the function code is implemented by third-
parties, requires authorized access to large data vol-
umes and externalizes results. Therefore, the use of
traditional UDF solutions is proscribed. Another ap-
proach would be to use anonymization or differential
privacy (Dwork, 2006) to protect the input of the com-
puted function, but this method is not generic thus un-
dermining the extensiveness property and can hardly
preserve result accuracy. Similarly, employing secure
multiparty cryptographic computation techniques can
hurt genericity (e.g., semi-homorphic encryption (El-
Gamal, 1985)) or performance (e.g., fully homomor-
phic encryption (Gentry, 2009)), and cannot solve the
problem of data leakage through legitimate results
computed by untrusted code.
Proposed Approach. We consider split execution
techniques between a set of data tasks within sand-
boxed enclaves running untrusted UDF code on parti-
tions of the input dataset to ensure extensiveness, and
an isolated core enclave running a trusted PDMS en-
gine orchestrating the evaluation to mitigate personal
data leakage and ensure security. In our architecture,
the security relies on hardware properties provided by
Trusted Execution Environments (TEEs), such as In-
tel SGX (Costan and Devadas, 2016) or ARM Trust-
Zone (Pinto and Santos, 2019), and sandboxing tech-
niques within enclaves, like Ryoan (Hunt et al., 2018)
or SGXJail (Weiser et al., 2019).
Contributions. Our contribution is twofold. First, we
formalize the threat and computation models adopted
in the PDMS context. Then, we introduce three secu-
rity building blocks to bound the information leakage
from user-defined computation results on large per-
sonal datasets.
2 BACKGROUND
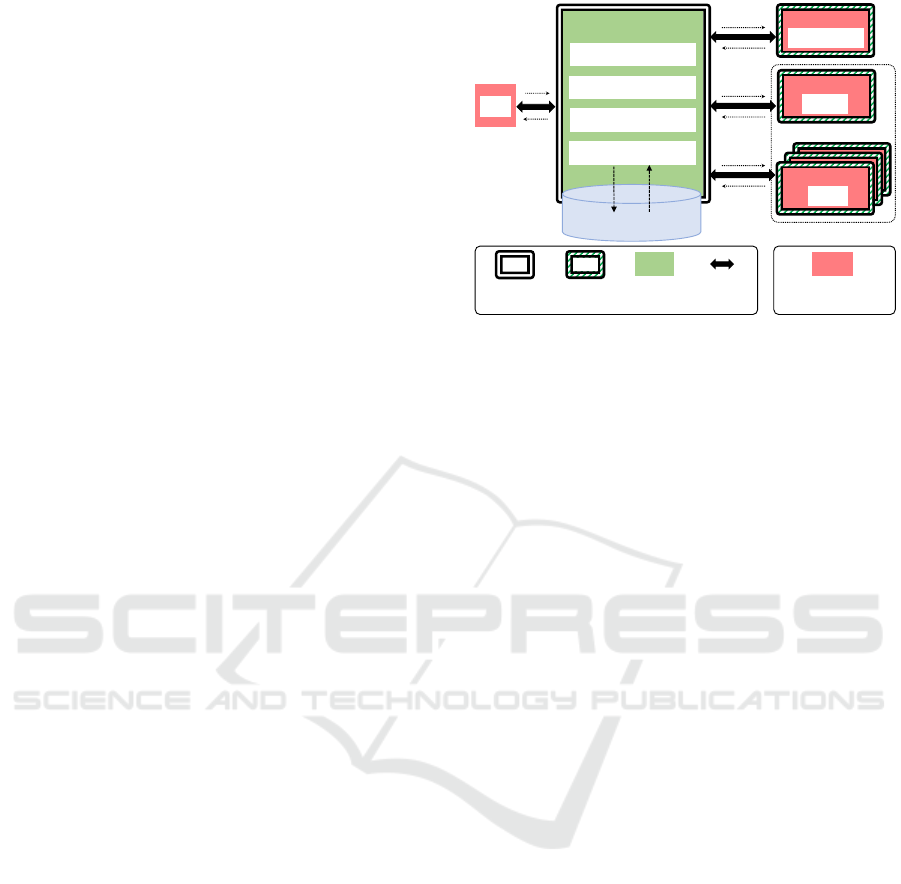
2.1 Architecture Outline
Designing a PDMS architecture that offers both secu-
rity and extensiveness is a significant challenge: secu-
rity requires trusted code and environment to manip-
ulate data, while extensiveness relies on user-defined
potentially untrusted code. We proposed in (Anciaux
σ
{o}
f (O
)
DATA TASK
f=agg∘cmp
Communication
Policy enforcement
Data storage
UDF execution
CORE
sealed user database
O
σ
f (O
)
{cmp(o)}
f (O
)
{o}
{cmp(o)}
DATA TASK
agg
DATA TASK
agg
DATA TASK
agg
DATA TASK
cmp
decomposed execution
secure
channel
enclave
+ sandbox
trusted
code
App
trusted architectural elements
untrusted
code
enclave
untrusted elements
Figure 1: Computation and Threat Models.
et al., 2019) a three-layers logical architecture to han-
dle this tension, where Applications (Apps) on which
no security assumption is made, communicate with a
Secure Core (Core) implementing basic operations on
personal data, extended with Data Tasks (Data tasks)
isolated from the Core and running user-defined code
(see Fig. 1).
Core. The Core is a secure subsystem that is a Trusted
Computing Base (TCB). It constitutes the sole en-
try/exit point to manipulate PDMS data and retrieve
results, and hence provides the basic DBMS opera-
tions required to ensure data confidentiality, integrity,
and resiliency. It therefore implements a data stor-
age module, a policy enforcement module to con-
trol access to PDMS data and a basic query mod-
ule (as needed to evaluate simple selection predicates
on database objects metadata) and a communication
manager for securing data exchanges between the ar-
chitecture layers and with the Apps.
Data Tasks. Data tasks can execute arbitrary,
application-specific data management code, thus
enabling extensiveness (like UDFs in traditional
DBMSs). The idea is to handle UDFs by (1) disso-
ciating them from the Core into one or several Data
tasks evaluated in a sufficiently isolated environment
to maintain control on the data sent to them by the
Core during computations, and (2) scheduling the ex-
ecution of Data tasks by the Core such that security is
globally enforced.
Apps. The complexity of the applications (large
code base) and their execution environment (e.g., web
browser) make them vulnerable. Therefore, no secu-
rity assumption is made: Apps manipulate only au-
thorized data resulting from Data tasks but have no
privilege on raw data.
Local Personal Data Processing with Third Party Code and Bounded Leakage
521

2.2 Security Properties
The specificity of our architecture is to remove from
local or remote Apps any sensitive data-oriented com-
putation, delegating it to Data tasks running UDFs un-
der the control of the Core. App leverages an App
manifest which includes essential information about
the UDFs to be executed by the App, including their
purpose, authorized PDMS objects and size of results
to be transmitted to the App. The manifest should be
validated, e.g., by a regulatory agency or the App mar-
ketplace, and approved by the PDMS user at install
time before the App can call corresponding functions.
Specifically, our system implements the following ar-
chitectural security properties:
P1. Enclaved Core/Data Tasks. The Core and each
Data task run in individual enclaves protecting the
confidentiality of the data manipulated and the in-
tegrity of the code execution from the untrusted exe-
cution environment (application stack, operating sys-
tem). Such properties are provided by TEEs, e.g., In-
tel SGX, which guarantees that (i) enclave code can-
not be influenced by another process; (ii) enclave data
is hidden from any other process (RAM encryption);
(iii) enclave can prove that its results were produced
by its genuine code (Costan and Devadas, 2016). Be-
sides, the code of each Data task is sandboxed (Hunt
et al., 2018) within its enclave to preclude any vol-
untary data leakage outside the enclave by a mali-
cious Data task function code. Such Data task con-
tainment can be obtained using existing software such
as Ryoan(Hunt et al., 2018) or SGXJail(Weiser et al.,
2019) which provide means to restrict enclave opera-
tions (bounded address space and filtered syscalls).
P2. Secure Communications. All the communica-
tions between Core, Data tasks and Apps are clas-
sically secured using TLS to ensure authenticity, in-
tegrity and confidentiality. Because the inter-enclave
communication channels are secure and attested, the
Core can guarantee to Apps the integrity of the UDFs
being called.
P3. End-to-end Access Control. The input/output
of the Data tasks are regulated by the Core which
enforces access control rules for each UDF required
by an App. Also, the Core can apply basic selection
predicates to select the subset of database objects for
a given UDF call. For instance, in our ’Green bonus’
example, a Data task running a UDF computing the
number of bike commutes during a certain time inter-
val will only be supplied by the Core with the nec-
essary GPS traces (i.e., covering the given time inter-
val). If several Data tasks are involved in the evalua-
tion of a UDF, the Core guarantees the transmission of
intermediate results between them. Finally, the App
only receives final computation results from the Core
(e.g., number of bike commutes) without being able
to access any other data.
The above properties enforce the PDMS security
and, in particular, the data confidentiality, precluding
any data leakage, except through the legitimate results
delivered to the Apps.
3 RELATED WORKS
Personal Data Management Systems. PDMSs (also
called Personal Clouds or PIMS) are hardware and/or
software platforms enabling users to retrieve and
exploit their personal data (e.g., banking, health,
energy consumption, IoT). The user is considered
the sole administrator of their PDMS, whether it is
hosted remotely within a personal cloud (Cozy Cloud,
BitsaboutMe, Personium, Mydex), or locally on a per-
sonal device (Cozy Cloud, (de Montjoye et al., 2014;
Chaudhry et al., 2015)).
Existing solutions include support for advanced
data processing (e.g., statistical processing or ma-
chine learning on time series or images) by means of
applications installed on the user’s PDMS platform
(Cozy Cloud, (de Montjoye et al., 2014)). Data secu-
rity and privacy are essentially based on code open-
ness and community audit (expert PDMS users) to
minimize the risk of data leakage. Automatic network
control mechanisms may also help identifying suspi-
cious data transfers (Novak et al., 2020). However, no
guarantee exists regarding the amount of PDMS data
that may be leaked to external parties through seem-
ingly legitimate results.
DBMSs Secured with TEEs. Many recent works
(Priebe et al., 2018; Zhou et al., 2021; Han and
Hu, 2021), EdgelessDB or Azure SQL adapt exist-
ing DBMSs to the constraints of TEEs, to enclose
the DBMS engine and thus benefit from TEE security
properties. For example, EnclaveDB (Priebe et al.,
2018) and EdgelessDB embed a –minimalist– DBMS
engine within an enclave and ensure data and query
confidentiality, integrity and freshness, while VeriDB
(Zhou et al., 2021) provides verifiability of database
queries.
These proposals consider the DBMS code running
in the enclaves to be trusted by the DBMS owner –or
administrator–. Support for untrusted UDF/UDAF-
like functions is not explicitly mentioned, but would
imply the same trust assumption for the UDF code.
Our work, on the contrary, makes an assumption
of untrusted third-party UDF code for the database
owner.
Other proposals (Hunt et al., 2018; Goltzsche
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
522

et al., 2019) combine sandboxing and TEEs to secure
data-oriented processing. For example, Ryoan(Hunt
et al., 2018) protects, on the one hand, the confiden-
tiality of the source code (intellectual property) of dif-
ferent modules running on multiple sites, and on the
other hand, users’ data processed by composition of
the modules. Despite similarities in the architectural
approach, the focus of these works is not on control-
ling personal data leakage through successive execu-
tions and results transmitted to a third party.
Secure UDFs in DBMSs. DBMSs support the eval-
uation of third-party code via UDFs. Products such
as Snowflake or Google BigQuery consider the case
of secure or authorized UDFs, where users with UDF
execution privilege do not have access rights to the in-
put data. This context is different from ours because
the UDF code is trusted and verified by the adminis-
trators.
Information Flow Analysis. Several works
(Sabelfeld and Myers, 2003; Sun et al., 2016; Myers,
1999) deal with information flow analysis to detect in-
formation leakage, but these are essentially based on
insuring the non-interference property, which guaran-
tees that if the inputs to a function f are sensitive,
no public output of that function can depend on those
sensitive inputs. This is not applicable in our context,
since it is legitimate –and an intrinsic goal of running
f – for App to compute outputs of f that depend on
sensitive inputs. Our goal is therefore to quantify,
control and limit the potential leakage, without resort-
ing to function semantics.
4 COMPUTING AND THREAT
MODELS
4.1 Computing Model
We seek to propose a computation model for UDFs
(defined by any external App) that satisfies the canon-
ical use of PDMS computations (including the use-
cases discussed above). The model should not im-
pact the application usages, while allowing to ad-
dress the legitimate privacy concerns of the PDMS
users. Hence, we exclude from the outset UDFs
which are permitted by construction to extract large
sets of raw database objects (like SQL select-project-
join queries). Instead, we consider UDFs (i.e., a func-
tion f ) as follows: (1) f has legitimate access to large
sets of user objects and (2) f is authorized to produce
various results of fixed and small size.
The above conditions are valid, for instance, for
any aggregate UDF applied to sets of PDMS objects.
As our running example illustrates, such functions are
natural in PDMS context, e.g., leveraging user GPS
traces for statistics of physical activities, the trav-
eled distance or the used modes of transportation over
given time periods.
Aggregates in a PDMS are generally applied on
complex objects (e.g., time series, GPS traces, docu-
ments, images), which require adapted and advanced
UDFs at the object level. Specifically, to evaluate an
aggregate function agg, a first function cmp computes
each object o of the input. For instance, cmp can com-
pute the integral of a time series indicating the elec-
tricity consumption or the length of a GPS trace stored
in o, while agg can be a typical aggregate function ap-
plied subsequently on the set of cmp results. Besides,
we consider that the result of cmp over any object o
has a fixed size in bits of ||cmp|| with ||cmp|| << ||o||
(e.g., in the examples above about time series and
GPS traces, cmp returns a single value –of small size–
computed from the data series –of much larger size–
stored in o). For simplicity and without lack of gener-
ality, we focus in the rest of the paper on a single App
a and computation function f .
Computing Model. An App a is granted execution
privilege on an aggregate UDF f = agg ◦ cmp with
read access to (any subset of) a set O of database
objects according to a predefined App manifest {<
a, f ,O >} accepted by the PDMS user at App install
time. a can freely invoke f on any O
σ
⊆ O, where
σ is a selection predicate on objects metadata (e.g.,
a time interval) chosen at query time by a. Function
f computes agg({cmp(o)}
o∈O
σ
), with cmp an arbi-
trarily complex preprocessing applied on each object
o ∈ O
σ
and agg an aggregate function. We consider
that agg and cmp are deterministic functions and pro-
duce fixed-size results.
4.2 Threat Model
We consider that the attacker cannot influence the
consent of the PDMS user, required to install UDFs.
However, neither the UDF code nor the results pro-
duced can be guaranteed to meet the user’s consented
purpose. To cover the most problematic cases for the
PDMS user, we consider an active attacker fully con-
trolling the App a with execution granted on the UDF
f . Thus, the attacker can authenticate to the Core on
behalf of a, trigger successively the evaluation of f ,
set the predicate σ defining O
σ
∈ O, the input set, and
access all the results produced by f . Furthermore,
since a also provides the PDMS user with the code
of f = agg ◦ cmp, we consider that the attacker can
instrument the code of agg and cmp such that instead
of being deterministic and producing the expected re-
sults, the execution of f produces some information
Local Personal Data Processing with Third Party Code and Bounded Leakage
523

coveted by the attacker, in order to reconstruct sub-
sets of raw database objects used as input.
On the contrary, we assume that security proper-
ties P1 to P3 (see Section 2.2) are enforced. In par-
ticular, we assume that the PDMS Core code is fully
trusted as well as the security provided by the TEE
(e.g., Intel SGX) and the in-enclave sandboxing tech-
nique used to enforce P1 to P3. Fig. 1 illustrates
the computation model considered for the UDFs and
the trust assumptions on each of the architectural ele-
ments of the PDMS involved in the evaluation.
Note that to foster usage, we impose no restric-
tions on the σ predicate and on the App query budget
(see Section 6). In addition, we do not consider any
semantic analysis or auditing of the code of f since
this is not realistic in our context (the layman PDMS
user cannot handle such tasks) and also mostly com-
plementary to our work as discussed in Section 3.
4.3 Problem Formulation
Our objective is to address the following question: Is
there an upper bound on the potential leakage of per-
sonal information that can be guaranteed to the PDMS
user, when evaluating a user-defined function f suc-
cessively on large sensitive data sets, under the con-
sidered PDMS architecture, computation and threat
models?
Answering this question is critical to bolster the
PDMS paradigm. A positive conclusion is necessary
to justify a founding principle for the PDMS, inso-
far as bringing the computational function to the data,
would indeed provide a quantifiable privacy benefit to
PDMS users.
Let us consider a simple attack example:
Attack Example. The code for f , instead of the ex-
pected purpose which users consent to (e.g., com-
puting bike commutes for the ’Green Bonus’), im-
plements a function f
leak
that produces a result
called leak of size || f || bits (|| f || is the number of
bits allowed for legitimate results of f ), as follows:
(i) f sorts its input object set O, (ii) it encodes on
|| f || bits the information contained in O next to the
previously leaked information and considers them
as the –new– leak; (iii) it sends –new– leak as the
result.
In a basic approach where the code of f is succes-
sively evaluated by a single Data Task DT
f
receiving
a same set O of database objects as input, the attacker
obtains after each execution a new chunk of informa-
tion about O encoded on || f || bits. The attacker could
thus reconstruct O by assembling the received leak af-
ter at most n =
||O||
|| f ||
successive executions, with ||O||
the size in bits needed to encode the information of O.
To address the formulated problem, we introduce
metrics inspired by traditional information flow meth-
ods (see e.g., (Sabelfeld and Myers, 2003)). We de-
note by ||x|| the amount of information in x, measured
by the number of bits needed to encode it. For sim-
plicity, we consider this value as the size in bits of the
result if x is a function and as its footprint in bits if x is
a database object or set of objects. We define the leak-
age L
f
(O) resulting from successive executions of a
function f on objects in O allowed to f , as follows:
Definition 1. Data Set Leakage. The successive ex-
ecutions of f , taking as input successive subsets O
σ
of a set O of database objects, can leak up to the sum
of the leaks generated by the non identical executions
of f . Two executions are considered identical if they
produce the same result on the same input (as the case
for functions assumed deterministic). Successive exe-
cutions producing n non-identical results generate up
to a Data set leakage of size L
f
n
(O) = || f || × n (i.e.,
each execution of f provides up to || f || new bits of
information about O).
To quantify the number of executions required to
leak given amounts of information, we introduce the
leakage rate as the ratio of the leakage on a number n
of executions, i.e., L
f
n
=
1
n
· L
f
n
(O).
The above leakage metrics express the ’quantita-
tive’ aspect of the attack. However, attackers could
also focus their attack on a (small) subset of objects
in O that they consider more interesting and leak those
objects first, and hence optimize the use of the possi-
ble amount of information leakage. To capture ’quali-
tative’ aspect of an attack, we introduce a second leak-
age metric:
Definition 2. Object Leakage. For a given object o,
the Object leakage denoted L
f
n
(o) is the total amount
of bits of information about o that can be obtained af-
ter executing n times the function f on sets of objects
containing o.
5 COUNTERMEASURE
BUILDING BLOCKS
We introduce security building blocks to control data
leakage in the case of multiple executions of a UDF
f = agg ◦cmp and show that bounded leakage can be
guaranteed.
5.1 Definitions
Since attackers control the code of f , an important
lever that they can exploit is data persistency. For in-
stance, in the Attack example (Section 4.3), f main-
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
524

tains a variable leak to avoid leaking the same data
twice. A first building block is hence to rely on state-
less Data Tasks.
Definition 3. Stateless Data Task. A stateless Data
Task is instantiated for the sole purpose of answering
a specific function call, after which it is terminated
and its memory wiped.
In the particular case of executions dealing with
identical inputs, an attacker could exploit randomness
provided by its environment to leak different data. To
further reduce leakage, we enforce a second building
block: determinism.
Definition 4. Deterministic Data Task. A determin-
istic Data Task necessarily produces the exact same
result for the same function code executed on the
same input, which precludes increasing Data set leak-
age in the case of identical executions (enforcing Def.
1).
Regardless if Data Tasks are stateless and deter-
ministic, attackers can leak new data with each ex-
ecution of f by changing the selection predicate σ.
Attackers can also focus their leakage on a specific
object o, by executing f on different input sets each
containing o. To mitigate such attacks, we introduce
a third building block by decomposing the execution
of f = agg ◦ cmp into a set of Data Tasks: one Data
Task DT
agg
executes the code of agg and a set of
Data Tasks {DT
cmp
i
}
i>0
executes cmp on a partition
of the set of authorised objects O, each part P
i
being
of maximum cardinality k. The partitioning of O has
to be static (independent of the input O
σ
of f ), so that
any object is always processed in its same partition P
i
across executions.
Definition 5. Decomposed Data Tasks. Let P(O) =
{P
i
} be a static partition of the set of objects O, au-
thorized to function f = agg ◦cmp, such that any part
P
i
is of maximum cardinality k > 0 (k being fixed
at install time). A decomposed Data Tasks execu-
tion of f over O
σ
⊆ O involves a set of Data Tasks
{DT
cmp
i
,P
i
∩ O
σ
6=
/
0}, with each DT
cmp
i
executing
cmp on a given part P
i
containing at least one object of
O
σ
. Each DT
cmp
i
is provided P
i
as input by the Core
and produces a result set res
cmp
i
= {cmp(o),o ∈ P
i
}
to the Core. The Core discards all results correspond-
ing to objects o /∈ O
σ
, i.e., not part of the compu-
tation. One last Data Task DT
agg
is used to aggre-
gate the union of the results of the computation, i.e.,
∪
i
{res
cmp
i
= {cmp(o),o ∈ P
i
∩O
σ
}} and produce the
final result.
5.2 Enforcement
On SGX, statelessness (Def 3) can be achieved by
destroying the Data Task’s enclave. It also requires
to extend containment (security property P1) by pre-
venting variable persistency between executions or di-
rect calls to stable storage (e.g., SGX protected file
system library).
To enforce determinism (Def 4), Data Task con-
tainment (security property P1) can be leveraged by
preventing access to any source of randomness, e.g.,
system calls to random APIs or timer/date. Virtual
random APIs can easily be provided to preserve le-
gitimate uses (e.g., the need for sampling) as long as
they are ”reproducible”, i.e., the random numbers are
forged by the Core using a seed based on the function
code f and its input set O, e.g., seed = hash( f ||O).
The same inputs (i.e., same sets of objects) must also
be made identical between successive Data Task ex-
ecution by the Core (e.g., sorted before being passed
to Data Tasks). Clearly, to enforce determinism, the
Data Task must be stateless, as maintaining a state be-
tween executions provides a source of randomness.
Finally, to enforce decomposition (Def 5), it is
sufficient to add code to the Core that implements an
execution strategy consistent with this definition.
5.3 Leakage Analysis
Stateless Only. A corrupted computation code run-
ning as a Stateless Data Task may leverage random-
ness to maximize the leakage rate. In the Attack ex-
ample, at each execution, f
leak
would select a random
fragment of O to produce a leak –even if the same
query is run twice on the same input–. Considering
a uniform leakage function, the probability of pro-
ducing a new leakage decreases with the remaining
amount of data –not yet disclosed– present in the data
task input O.
With Determinism. With deterministic (and state-
less) Data Tasks, the remaining source of randomness
in-between computations is the Data Task input (i.e.,
O
σ
⊆ O). The attacker has to provide a different selec-
tion predicate σ at each computation in hope of max-
imizing the leakage rate. Hence, the average leak-
age rate of deterministic Data Tasks is upper bounded
by that of stateless ones. In theory, as the number
of different inputs of f is high (up to 2
|O|
, the num-
ber of subsets of O), an attacker can achieve a similar
Data set leakage with deterministic Data Tasks as with
stateless ones, but with lower leakage rate.
With Decomposition. Any computation involves one
or several partitions P
i
of O. Information about ob-
jects in any P
i
can only leak into up to the k results
produced by DT
cmp
i
. The parameter k is called leak-
age factor. Leveraging stateless deterministic Data
Tasks, the result set {cmp(o)}
o∈P
i
is guaranteed to
be unique for any o. Hence, the data set leakage for
Local Personal Data Processing with Third Party Code and Bounded Leakage
525

each partition P
i
is bounded by ||cmp|| · |P
i
|, ∀P
i
re-
gardless of the number of the computations involv-
ing o ∈ P
i
. Consequently, the Data set leakage over
large numbers n of computations is also bounded:
L
f
n→+∞
(O) ≤
∑
i
||cmp|| · |P
i
| = ||cmp|| · |O|. Regard-
ing Object leakage, for any P
i
, the attacker has the
liberty to choose the distribution of the |P
i
| leak frag-
ments among the objects in P
i
. At the extreme, all |P
i
|
fragments can concern a single object in P
i
. For any
object o ∈ P
i
, the Object leakage is thus bounded by
L
f
n→+∞
(o) ≤ min(||cmp|| · k,||o||).
Minimal Leakage. From above formulas, a decom-
posed Data Task execution of f = agg ◦ cmp is op-
timal in terms of limiting the potential data leakage
with both minimum Data set and Object leakages,
when a maximum degree of decomposition is chosen,
i.e., a partition at the object level fixing k = 1 as leak-
age factor.
’Green bonus’ Leakage Analysis. Let us assume
that ||cmp|| = 1 (i.e., 1 bit to indicate if a GPS trace
is a bike commute or not), ||agg|| = 6 (i.e., 6 bits to
count the number of monthly bike commutes with a
maximum admitted value of 60) and ||o|| = 600 (i.e.,
each GPS trace is encoded with 600 bits of informa-
tion). Without any countermeasure on f , an attacker
needs 100 queries to obtain an object o. With a state-
less f , the number of queries to obtain o is (much)
higher due to random leakage and o has to be con-
tained in the input of each query. With a stateless de-
terministic f , the number of queries to obtain o is at
least the same as with a stateless f but each query has
to have a different input while containing o. Finally,
with a fully decomposed execution of f (i.e., k = 1),
only ||cmp|| = 1 bit of o can be leaked regardless of
the number of queries.
6 RESEARCH CHALLENGES
The introduced building blocks allow an evaluation
of f with low and bounded leakage. However,
their straightforward implementation may lead to pro-
hibitive execution cost with large data sets, mainly be-
cause (i) too many Data Tasks must be allocated at
execution (up to one per object o ∈ O
σ
to reach the
minimal leakage) and (ii) many unnecessary compu-
tations are needed (objects o
0
/∈ O
σ
must be processed
given the ’static’ partitioning if they belong to any part
containing an object o ∈ O
σ
). Hence, a first major re-
search challenge is to devise evaluation strategies hav-
ing reasonable cost, while achieving low data leakage.
The security guarantees of our strategies are based
on the hypothesis that the Core is able to evaluate
the σ selection predicates of the App. This is a rea-
sonable assumption if basic predicates are considered
over some objects metadata (e.g., temporal, object
type or size, tags). However, because of the Core min-
imality, it is not reasonable to assume the support for
more complex selections within the Core (e.g., spa-
tial search, content-based image search). Advanced
selection would require specific data indexing and
should be implemented as Data Tasks, which calls for
revisiting the threat model and related solutions.
Another issue is that our study considers a single
cmp function for a given App. For Apps requiring
several computations, our leakage analysis still ap-
plies for each cmp, but the total leak can be accumu-
lated across the set of functions. Also, the considered
cmp does not allow parameters from the App (e.g.,
cmp is a similarity functions for time series or images
having also an input parameter sent by the app). Pa-
rameters may introduce an additional attack channel
allowing the attacker to increase the data leakage.
This study does not discuss data updates. Personal
historical data (mails, photos, energy consumption,
trips) is append-only (with deletes) and is rarely mod-
ified. Since an object update can be seen as the dele-
tion and reinsertion of the modified object, at each
reinsertion, the object is exposed to some leakage.
Hence, with frequently updated and queried objects,
new security building blocks may be required.
To reduce the potential data leakage, complemen-
tary security mechanisms can be employed for some
Apps, e.g., imposing a query budget or limiting the
σ predicates. Defining such restrictions and incor-
porating them into App manifests would definitely
make sense as future work. Also, aggregate compu-
tations are generally basic and could be computed by
the Core. The computation of agg by the Core intro-
duces an additional trust assumption which could help
to further reduce the potential data leakages.
REFERENCES
Anciaux, N., Bonnet, P., Bouganim, L., Nguyen, B.,
Pucheral, P., Popa, I. S., and Scerri, G. (2019). Per-
sonal data management systems: The security and
functionality standpoint. Information Systems, 80:13–
35.
Chaudhry, A., Crowcroft, J., Howard, H., Madhavapeddy,
A., Mortier, R., Haddadi, H., and McAuley, D. (2015).
Personal Data: Thinking Inside the Box. Aarhus Se-
ries on Human Centered Com.
Costan, V. and Devadas, S. (2016). Intel SGX explained.
IACR Cryptol. ePrint Arch., 2016:86.
de Montjoye, Y.-A., Shmueli, E., Wang, S. S., and Pent-
land, A. S. (2014). openPDS: Protecting the Privacy
of Metadata through SafeAnswers. PLoS one, 9.
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
526

Dwork, C. (2006). Differential privacy. In ICALP (2),
volume 4052 of Lecture Notes in Computer Science.
Springer.
ElGamal, T. (1985). A public key cryptosystem and a signa-
ture scheme based on discrete logarithms. IEEE trans-
actions on Information Theory, 31(4):469–472.
Gentry, C. (2009). A Fully Homomorphic Encryption
Scheme. PhD thesis.
Goltzsche, D., Nieke, M., Knauth, T., and Kapitza, R.
(2019). AccTEE: A WebAssembly-Based Two-Way
Sandbox for Trusted Resource Accounting. Middle-
ware ’19.
Han, Z. and Hu, H. (2021). ProDB: A memory-secure
database using hardware enclave and practical oblivi-
ous RAM. Information Systems, 96:101681.
Hunt, T., Zhu, Z., Xu, Y., Peter, S., and Witchel, E. (2018).
Ryoan: A distributed sandbox for untrusted computa-
tion on secret data. ACM TOCS, 35(4).
Myers, A. C. (1999). Jflow: Practical mostly-static infor-
mation flow control. POPL ’99. ACM.
Novak, E., Aung, P. T., and Do, T. (2020). VPN+ Towards
Detection and Remediation of Information Leakage
on Smartphones. MDM ’20.
Pinto, S. and Santos, N. (2019). Demystifying arm trust-
zone: A comprehensive survey. ACM CSUR, 51(6).
Priebe, C., Vaswani, K., and Costa, M. (2018). EnclaveDB:
A Secure Database Using SGX. In IEEE S&P.
Sabelfeld, A. and Myers, A. (2003). Language-based
information-flow security. IEEE Journal on Selected
Areas in Communications, 21(1):5–19.
Sambra, A., Mansour, E., Hawke, S., Zereba, M., Greco,
N., Ghanem, A., Zagidulin, D., Aboulnaga, A., and
Berners-Lee, T. (2016). Solid: A platform for decen-
tralized social applications based on linked data.
Sun, M., Wei, T., and Lui, J. C. (2016). TaintART: A Prac-
tical Multi-Level Information-Flow Tracking System
for Android RunTime. CCS.
Weiser, S., Mayr, L., Schwarz, M., and Gruss, D. (2019).
SGXJail: defeating enclave malware via confinement.
RAID.
Zhou, W., Cai, Y., Peng, Y., Wang, S., Ma, K., and Li, F.
(2021). VeriDB: An SGX-Based Verifiable Database.
SIGMOD.
Local Personal Data Processing with Third Party Code and Bounded Leakage
527
