
A Formal Model to Support Discourse Semantic Landscape Analysis
Isabelle Linden
a
, Bruno Dumas
b
and Anne Wallemacq
c
Namur Digital Institute (NADI), University of Namur, Belgium
Keywords:
Discourse Analysis, Semantic Landscape, Text Formal Model.
Abstract:
Discourse Analysis is a broadly spread methodology in human and social sciences. The Evoq Software (Clar-
inval et al., 2018) has been developed to offer advanced support for a deep semantic analysis of discourse by
providing intermediary transposition tools that allow the exploration of the semantic landscape underlying a
discourse from multiple angles. This paper presents the formal knowledge model to support these functionali-
ties development and ensure a strong coherence between multiple visualisations seen as so many intermediary
transpositions of the same object.
1 INTRODUCTION
Discourse analysis is an essential practice at the heart
of the activities of many researchers in the humani-
ties and social sciences. Unfortunately, few software
packages offer advanced features for qualitative anal-
ysis. Most of the tools available to humanities re-
searchers are limited to quantitative functions. The
qualitative approach is often neglected or limited to
text manipulation, analysis and dictionary functions
(Lejeune, 2010; Lejeune, 2021).
The EFFaTA-MeM (Evocative Framework for
Text-Analysis - Mediality Model) research project
and the Evoq software have the essential ambition of
offering advanced support for a deep semantic anal-
ysis of discourse by providing intermediary transpo-
sition tools that allow the exploration of the semantic
landscape underlying a discourse from multiple an-
gles (Linden et al., 2020).
To ensure the strong coherence of the intermedi-
ary transposition, a key question is addressed in this
paper: How to formalise the semantical elements of a
discourse to support the extraction, the visualisation
and the analysis of its semantic landscape?
To answer this research question, the paper pro-
ceeds as follows. Section 1 presents the theorical
background used to support our text analysis ap-
proach, namely the structural analysis and introduces
the notion of semantic landscape. Then, Section 3
proposes a basic formal model integrating the key ele-
a
https://orcid.org/0000-0001-8034-1857
b
https://orcid.org/0000-0001-5302-4303
c
https://orcid.org/0000-0001-9822-4966
ment of this theory. This model is extended in Section
4 so as to integrate the elements useful for intermedi-
ary transposition. Finally, Section 5 present the trans-
position integrated in the Evoq Software and explains
how they are supported by the formal model.
A short analysis example drawn on text presenting
the Transition Network (Transition Network, 2021)
serves as running example all along the paper.
2 STRUCTURAL ANALYSIS AND
SEMANTIC LANDSCAPE
One of the essential goal of the EFFaTA-MeM project
is to conceive ways of interacting and visualising texts
that foster new insights in their analysis. This means
that we investigate (i) the mediality of texts and of
graphical and pictorial representations (Kucher and
Kerren, 2015; Gibson et al., 2013), (ii) the intermedial
transposition from the textual semiotic system to a
pictorial semiotic (Rajewsky, 2002; Rajewsky, 2005;
Wolf, 1999; Ellestr
¨
om, 2010; Ellestr
¨
om, 2014), and
(iii) the meaning enrichment opportunities offered by
this transposition.
The theoretical background used to develop the
mediality studied in this research is based on a
deep reformulation of the post-structuralist principles.
From a mediality point of view, post-structuralism is
interesting because it fundamentally questions and re-
frames the linearity of the text. Post-structuralism
opens a very interesting conception of language of
which we present here some essential features for our
work.
118
Linden, I., Dumas, B. and Wallemacq, A.
A Formal Model to Support Discourse Semantic Landscape Analysis.
DOI: 10.5220/0011298300003269
In Proceedings of the 11th International Conference on Data Science, Technology and Applications (DATA 2022), pages 118-126
ISBN: 978-989-758-583-8; ISSN: 2184-285X
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

2.1 A Synchronous View on the Text
While the text is commonly considered as a linear
continuous deployment from a beginning to an end,
post-structuralism considers it as a field of forces
given synchronously. It means that the beginning and
the end of the text are considered in the same way and
with the same status, just as everything inbetween.
2.2 A Relational Semantics
In this global view on the text, rather than phrases or
words, basic units are couples of words in opposition,
such as White/Black.
Moreover, each word in the opposition is wrapped
up in a set of associative relations or simple evoca-
tions which may be explicitly formulated in the text
or implicitly supposed by the culture or the context.
So for example, in the White/Black opposition White
is associated pure and good while Black brings with
it implicitly dirty and bad. The meaning of words is
therefore larger than the simple denotation. White is
far more than a simple colour. Opposed to black it
conveys the semantic universe of purity, angel, par-
adise, untouched.
Let’s now consider another text in which white ap-
pears in tension with red. Red introduces associations
with life, warmth,... to love or anger. In tension with
this red, white then becomes the bearer of death, cold,
impassive,... radically different from its meaning
in the previously considered opposition white/black.
These considerations highlight the deeply relational
nature of word semantics in the structuralist perspec-
tive, which is no longer intrinsic to the word under
consideration but depends on its interweaving in the
network of words in the text
2.3 The Semantic Fields
The concept of semantic field has been proposed to
cover this system of oppositions and associations. Se-
mantic fields are not always explicitly revealed by the
words in the text, they are commonly assumed, re-
sulting from the culture or the specific context. In the
structuralist approach, this distinction is referred to as
the distinction between the level of language and the
level of discourse. It implies that an author (writer or
speaker) never has a complete mastery of the mean-
ing of her words. Indeed, her discourse is received by
the audience integrating these semantic fields that are
collectively produced and taken for granted. The se-
mantic field has thus to be considered as the semantic
surrounding the text.
Going even further, Derrida (Derrida, 1967) sug-
gests that these semantic fields are not a quiet equi-
librium but always in power tension according to the
idea that there are dominant relationships between
competing semantic fields.
2.4 Structural Analysis
By studying the semantic fields which are underlying
the explicit and conscious discourse, structural analy-
sis aims to reveal the balance of power in defining the
dominant worldview underlying a text.
3 BASIC CONCEPTUAL MODEL
In the post-structuralist approach as presented in the
previous section 2, a text becomes much more than a
linear sequence of words. It involves a domain knowl-
edge, implicit representations and tensions which are
captured by relations. This section presents the basic
formal model developed to capture this approach and
formalise a notion of Analysis project which extends
the notion of text according to the principles of struc-
tural analysis.
This formal model plays two key roles in the over-
all framework of the research:
• first, it is itself a transposition on which artificial
intelligence techniques can be applied.
• then, it can be used to ensure the coherence be-
tween the multiple proposed intermedial transpo-
sitions,
After the introduction of the underlying Intuitions
subsection 3.1, subsection 3.2 introduces the notation
of the basic model and subsection 3.3 formalises the
model transformations reflecting the steps of an anal-
ysis process.
3.1 Intuitions
The synchronous nature of the approach adopted al-
lows the consideration of the analysis as a single ob-
ject without any temporal aspect. As the main focus is
on relationships, a key element of our model consists
of a set of relationships between objects that, for sake
of simplicity we call words. Actually, there are three
different types of words depending of the object of in-
terest for the analyst. The first ones are single literal
expression (as e.g. a brand name or ”Transition” in
the context of our illustration). The second ones are
equivalence classes on the natural language dictionary
for which a root represent itself and all its derivative.
A Formal Model to Support Discourse Semantic Landscape Analysis
119

And, the last ones are concepts represented by expres-
sion involving several words (as e.g. ”collective intel-
ligence”). In our model, we denote by Word the set
of all these possible values.
Relations between these words can be of two
different natures: associations denoting a proximity
(whatever its nature), and oppositions that materialise
the tensions of the semantic field. The description of
the approach does not suggest any orientation of the
relations, consequently they are modelled by symmet-
rical relations.
3.2 Notations
The basic elements of our model are build from three
sets: Text which denotes the texts that can be anal-
ysed, Word introduced above, and BasicRel the set
of relations, formalised as (Word ×Word ×Boolean).
With these notations, the basic model of an analysis is
a triple
(t, wl, rl) ∈ Text ×P(Word) × P(BasicRel)
where
• t is the analysed text,
• wl is the set of the words of interest,
• rl is the set of the relations,
• all the word appearing in rl are in wl
1
• (w
1
, w
2
, b) ∈ rl iff (w
2
, w
1
, b) ∈ rl.
Note that this model integrates associations and
oppositions in one single set. They can be retrieved
as {(w
1
, w
2
) : (w
1
, w
2
, b)} with b = 0, 1 respectively.
3.3 Operations
With this notation, drawing an analysis consists in be-
ginning with (t,
/
0,
/
0) and integrating information step
by step by either integrating a new word w or a new
relation r = (w
1
, w
2
, b) in the analysis (t, wl, rl). The
addition of a word is formalised by the following op-
eration.
addWord : ((t, wl, rl), w) → (t, wl ∪ {w}, rl)
The addition of a relation is a partial function only
defined provided none of (w
1
, w
2
, 0) or (w
1
, w
2
, 1) is
in rl:
addRel : ((t, wl, rl), (w
1
, w
2
, b))
* (t, wl ∪ {w
1
, w
2
}, rl ∪ {(w
1
, w
2
, b), (w
2
, w
1
, b)}
1
but not mandatory in t
The operations set involves also possibility for
correction in an analysis, namely, removing a term or
a relation.
removeWord : ((t, wl, rl), w)
→ (t, wl \ {w}, rl \ {(w
1
, w
2
, b) : w
1
= w ∨ w
2
= w}
removeRel : ((t, wl, rl), (w
1
, w
2
, b))
→ (t, wl, rl \ {(w
1
, w
2
, b), (w
2
, w
1
, b)})
Note that to preserve the constraints on the inclu-
sion of words appearing in the relations in the set of
words, removing a term implies the withdrawal of all
the relations in which it is involved.
4 INTERMEDIAL CONCEPTUAL
MODEL
In an unpublished study of the first paragraph of
a description of the Transition (Transition Network,
2021), the Words dictionary made of 21 words (Head,
Heart, Hands, find, best information, evidence avail-
able, collective intelligence, compassion, value, pay-
ing attention, emotional, psychological, relational, so-
cial aspect, tangible reality, practical projects, build,
new healthy economy, good intentions, charity, old
economy) and 26 symetrical relations between them.
Intermediate transposition aims to present the
same information in different media in a way that fa-
cilitates its appropriation by the analyst while stim-
ulating reflection. In section 5, we explore several
visual transpositions. Preliminary, this section de-
scribes the enrichment of the conceptual model to
take into account visual aspects of the transposition
regardless the specific visual format.
After the introduction of the Analysis Project
model in subsection 4.1, subsection 4.2 enhances the
enriched views on the project which can be derived
from the model. Then, section 4.3 formalises the
model transformations and their use in the process of
drawing an analysis.
4.1 The Knowledge Model
Integrating the elements useful for conducting a struc-
tural analysis as described in the section 2, the text-
enriched model, which we call Analysis Project (or
AP) consists of a Text, FieldWords, FieldRelations,
and mappings to a representation domains defined by
functions of DomMap. Let’s first introduce these sets.
Notation 1. Let
• FieldWord = Word × Colour denote the set of
pairs of words associated with a colour,
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
120

• FieldRelation = Word ×Word × Boolean denote
the set of pairs of words associated with a boolean
denoting if the relation is a association or an op-
position
• DomMap = FieldWord * Coordinate denote the
set of the partial functions defined on (a sub-
set of) Fieldword into a visualisation domain
Coordinate.
Definition 1. Formally, the minimal definition
of a analysis project can be given by a tu-
ple (t, wd, rd, ml) in AnalysisProject = Text ×
P(FieldWord) × P(FieldRelation) × P(DomMap)
where
• t ∈ Text, is the text object of the analysis,
• wd ∈ P(FieldWord) is the set of purposeful words
2
associated with colours. wd is also called the
Words dictionary,
• rd ∈ P(FieldRelation) is a list of pairs of Words
appearing in wd with a boolean denoting if the re-
lation reflects an evocation or an opposition (also
called association and dissociation). rd is also
called the Relations dictionary
• ml ∈ P(DomMap) is a list of partial function de-
fined on (a subset of) the words in wl into (possi-
bly different) visualisation domains.
A few notations are associated with this model.
Notation 2. Given a words dictionary wd, and a spe-
cific FieldWord w, we denote by
• wd
i
, the i
th
element of the list,
• w.word, the word item of the FieldWord pair.
• w.colour, the colour item of the FieldWord pair.
Similarly, given a relations dictionary rd, and a spe-
cific FieldRelation r we denote by
• rd
i
, the i
th
element of the list,
• r.w1, the first word item of r,
• r.w2, the second word item of r,
• r.rel, the boolean denoting the type (association
or opposition) of r.
Beside the project analysis itself, the analysis
drawing process, as well as its presentation integrates
knowledge (k ∈ Knowledge) which basically consists
in structured knowledge as dictionaries, lemmatisers,
synonyms dictionaries, antonyms dictionary and for-
malised domain knowledge as well as explicit and im-
plicit expert knowledge.
2
For sake of simplicity, we call here ”word” the the ba-
sic unit used in the analysis. In a linguistic perspective, it
could be more properly called ”lexical item”. Indeed, ac-
cording to the analyst’s object of interest it can be either a
specific word, a lemma or a fixed set of words
4.2 Enriched Views of an Analysis
Project
Based on the minimal representation introduced in the
previous section, enriched concepts are built that in-
tegrate various element of the Analysis Project Field
tuple. A few notations are introduce to support their
formal definition.
Definition 2. Given a word w, exploiting the linguis-
tic knowledge formalised by a dictionary in k, we call
deriv(w) the set including all its lexical derivation if
w is a lemma, the singleton involving only w if w is a
derived word or a compound expression.
In the following, we extend the seminal notation
∑
n
i=1
to the Append function on list
Notation 3. We denote by
Append
n
i=1
description(...i...)
the list composed of the n elements obtained by in-
stantiating i from 1 to n in the description.
Definition 3. For a given AnalysisProject p =
(t, wd, rd, gl), one defines the following objects.
• Enriched Text: Crossing the text t and wd, the en-
riched text proposed a version of the text in which
the words that appear in wd (or whose lemma ap-
pears) are tagged and associated with the same
colour as in wd. Formally,
Enriched Text :
Text × P(FieldWord) → TaggedText
Enriched Text(t, wd)
= Append
lengt(t)
i=1
coloured(t
i
)
where
coloured(t
i
)
= t
i
< wd
j
.colour >
if t
i
∈ deriv(wd
j
.word)for any j,
t
i
otherwise
• Field Dictionary: enriching the world dictionary
wd with knowledge extracted from the text t, the
field term dictionary is the list of purposeful words
associated with their colour and a natural number
denoting the number of occurrences of the word
in the text (or the number of its declination if the
word is a lemma). This is formalised as follows.
Field dictionary :
Text × P(FieldWord)
→ P(FieldWord ×Colours × R)
A Formal Model to Support Discourse Semantic Landscape Analysis
121

Field dictionary(t, wd)
= Append
length(wd)
i=1
(w
i
.word, w
i
.colour,
#{w ∈ t : w ∈ deriv(wd
i
.word)})
• Field Relation Dictionary: the relation dictionary,
rd, where each word is augmented with the colour
of the word in wd and a Boolean denoting the
presence/absence of the word (or one of its deriva-
tive) in the text. Formally
Field Relation Dictionary :
Text × P(FieldRelation)
→ P(FieldWord × Boolean × FieldWord
×Boolean)
Field dictionary(t, rd)
= Append
length(rd)
i=1
(r
i
.w1, (∃w ∈ t : w ∈ deriv(r
i
.w1)),
r
i
.w2, (∃w ∈ t : w ∈ deriv(r
i
.w2)))
• Field Relation Matrix: the symmetric matrix M of
dimensions |wd|×|wd| where each element m
i, j
is
a colour that indicates the existence and the type
a relation (wd
i
, wd
j
) ∈ rd. The possibles values
are red for an opposition, green for an association
and grey if no relation. Formally, denoting Col the
set {Red, Green, Grey},
Field Relation Matrix :
P(FieldWord) × P(FieldRelation) → M (Col)
Field dictionary(wd, rd)
= {m
i, j
= Red iff (wd
i
, wd
j
, 0) ∈ rd,
Green iff (wd
i
, wd
j
, 1) ∈ rd,
Grey otherwise}
• Visualisation which is a graphical representation
of a DomMap ∈ gl enriched with information in-
volved in p as the colours associated with words,
their occurrence in the text and the relations be-
tween the words.
3
Direct access to these enriched objects provides to
the human scientist an enriched perception of the text,
and guides him into the interpretation process.
3
At this stage, for the sake of genericity, the model al-
lows any kind of domain for visualisation. In the follow-
ing we describe more precisely some of the mapping imple-
mented in Evoq.
4.3 Project Transformations and
Analysis Project Construction
The model presented above formalises a post-
structuralist enhanced model of a text, as the result
of an analysis, and the enriched views on the infor-
mation. We describe in section 5 how it efficiently
serves the intermedial transposition. At the formalisa-
tion level, a question remains to address: how to build
such a model from a fresh text? Expressed in our
formalism: how to transform an original (t,
/
0,
/
0,
/
0, k)
into an analysis (t, wd, rd, ml, k) and its associated en-
riched objects?
Let us remind that we do not aim to offer a tool
that will fully automate the analysis but a tool that
will, on the one hand, stimulate the analyst and, on
the other hand, facilitate some tasks of encoding or
research. That is to say that only a part of the knowl-
edge k requested to lead the analysis can be fully for-
malised and implemented, an important part of it re-
mains in the analyst’s brain.
With this in mind, the analysis process can
be formalised as a sequence of transformation that
will, step-by-step, transform a analysis project field
(t, wd, rd, ml, k), and
• extract words from the text and/or the knowledge
using the text and/or the (integrated or human)
knowledge, and
• add these words, with their associated colour, to
wd,
• identify relations among the words, from the text
and/or the knowledge, and
• add these relations, with their associate boolean,
to rd.
• create or adapt spatial manifestations of the
words and the relations to express semantic fields
and their tension.
Whether the operations are performed by a human an-
alyst or proposed by an AI agent, our aim here is to
show that they can be supported by the proposed for-
mal model.
The current version of the Evoq platform offers
a basic function allowing the extraction of the most
frequent words from the text, with or without the ex-
clusion of stopwords. The version including all words
can be modelled by
FrequentWords(t, wd, rd, ml, k) : AP → P(FieldWord)
t → {(w, black) : #{i : t
i
∈ deriv(t
i
)} ≥ m}
where t
i
denotes the ith word of the text t, m denotes
the arbitrary minimal number of occurences k in-
volves the capability to retrieve derivatives of a word.
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
122

And the one removing stopwords by
FrequentKeyWords(t, k) : Text → P(FieldWord)
t → {(w, black) : #{i : t
i
∈ deriv(t
i
)\Stopwords} ≥ m}
with the same conventions, and Stopwords being a
list of stop words involved in k.
The addition of a (colored) word (w,col) is de-
fined only if w is not already a member of wd
addWord : ((t, wd, rd, ml, k), (w, col))
* (t, wd ∪ {(w, col)}, rd, ml, k)
The addition of relation is the direct adaptaion of
the one on the basic model and similarly defined only
if one of (w
1
, w
2
, 0) or (w
1
, w
2
, 1) is in rl:
addRel : ((t, wd, rd, ml, k), (w
1
, w
2
, b))
→ (t, wd ∪ {(w
1
, w
2
}, rd{(w
1
, w
2
, b), (w
2
, w
1
, b), ml, k)}
The operations for correction in an analysis,
namely, remove a term or a relation follow also di-
rectly from these on the basic model.
removeWord : ((t, wd, rd, ml, k), w)
→ (t, wd \ {(w, col) : col ∈ Colours},
rl \ {(w
1
, w
2
, b) : w
1
= w ∨ w
2
= w}, ml, k)
removeRel : ((t, wd, rd, ml, k), (w
1
, w
2
, b))
→ (t, wd, rd \ {(w
1
, w
2
, b), (w
2
, w
1
, b)}, ml, k)
A last operation consists in modifying the colour
of a word already present in the word dictionnary, this
is formalised by the partial function
changeColour : ((t, wd, rd, ml, k), (w,col))
* (t, (wd \ {(w, c) : c ∈ Colours}) ∪ {(w, col)},
rd, ml, k)
5 SEMANTIC LANDSCAPE:
INTERMEDIAL
TRANSPOSITION
In this section we highlight how our formalisation of-
fers a unifying model and supports the intermediary
transposition between different visualisations associ-
ated with an Analysis Project which constitute its se-
mantic landscape.
This section is illustrated with the analysis of
the text available on (Transition Network, 2021) that
presents the principles and value guiding the move-
ment called Transition Network. As mentioned above
the basic element of this analysis are the text t, the set
of 21 words wl, and a list of 52 relations rl.
In the intermedial model, words are associated
with colours in the word dictionary wd, the relation
dictionary rd = rl. The list of mapping ml and ele-
ments of the knowledge k that complete the Analysis
Project AP = (t, wd, rd, ml, k) are described below.
After a literature review of text-related visualisa-
tion, (Clarinval et al., 2018) proposed a selection of
visuals and studied their respective suitability to sup-
port the structural analysis.
This section present in turn, enriched text, words
and relation dictionaries, chord diagram, adjacency
matrix and node-link diagram.
5.1 Enriched Text
The text presentation built into Evoq provides a di-
rect transposition of the Enriched text defined by the
Enriched Text function in the subsection 4.2. To
provide this visualisation, the domain mapping con-
structs the enriched text and then calls a function that
transforms each tagged word into the html expression
that applies the required formatting.
Figure 1 illustrates the visualisation of the begin-
ning of the text of our running example
4
.
Figure 1: Enriched text visualisation.
5.2 Dictionaries
Dictionaries can be seen as simple lists and presented
as such. However, as they are not isolated objects but
elements of a complete analysis project AP, the Evoq
software propose enriched view of the dictionary.
Namely, the word dictionary wd is completed with
the number of occurrences of each of its words in the
text t using the Field dictionary function and the re-
lation dictionary rd is completed with information re-
lated to the words using the Fied relation dictionary
function.
Here again, the mappings consist in computing the
enriched elements and then turning the results into
4
The text is an extract from (Transition Network, 2021)
used to build our running example
A Formal Model to Support Discourse Semantic Landscape Analysis
123

Figure 2: First items of Word Dictionary Visualisation.
Figure 3: First Items of Relation Dictionary Visualisation.
HTML code that construct the tables. Figures 2 and 3
respectively present the first items of the word dictio-
nary and relation dictionary of our running example.
Note that, in figure 2 the absence of a word in the text
is revealed both by the null number of occurrences
and the parenthesis surrounding the word. Similarly,
in figure 3, the words are presented with the colour
defined in wd and are also surrounded by parenthesis
if they are absent from the text t.
5.3 Adjacency Matrix
Relations being at the heart of the structural analy-
sis, several visuals are proposed from the relation dic-
tionary. The adjacency matrix proposes an enriched
vision from the Field Relation Matrix function de-
fined in subsection 4.2. After computing the Field
Dictionnary and Field Relation Matrix, the mapping
create an html tabular having the coloured words as
columns and lines headers and each cells receiving
the coloured (red/green/grey) defined by the Field Re-
lation Matrix corresponding cell, but for the diagonal
elements which are dark grey coloured.
Figure 4: Top-left corner of the adjacency matrix.
5.4 Node Link Diagram
A last visual associated with the set of relationships
is to present the relation dictionary as a node-link di-
agram. For this visual the mapping consists of
• projecting each word in the dictionary into a two-
dimensional space
• writing the words in the corresponding colour and
surrounding them with brackets if necessary, ac-
cording to the convention explained above
• draw the arcs corresponding to the relations, in red
for oppositions, in green for associations.
After the computation of the Field Relation Dictio-
nary, the last two aspects do not pose any critical
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
124
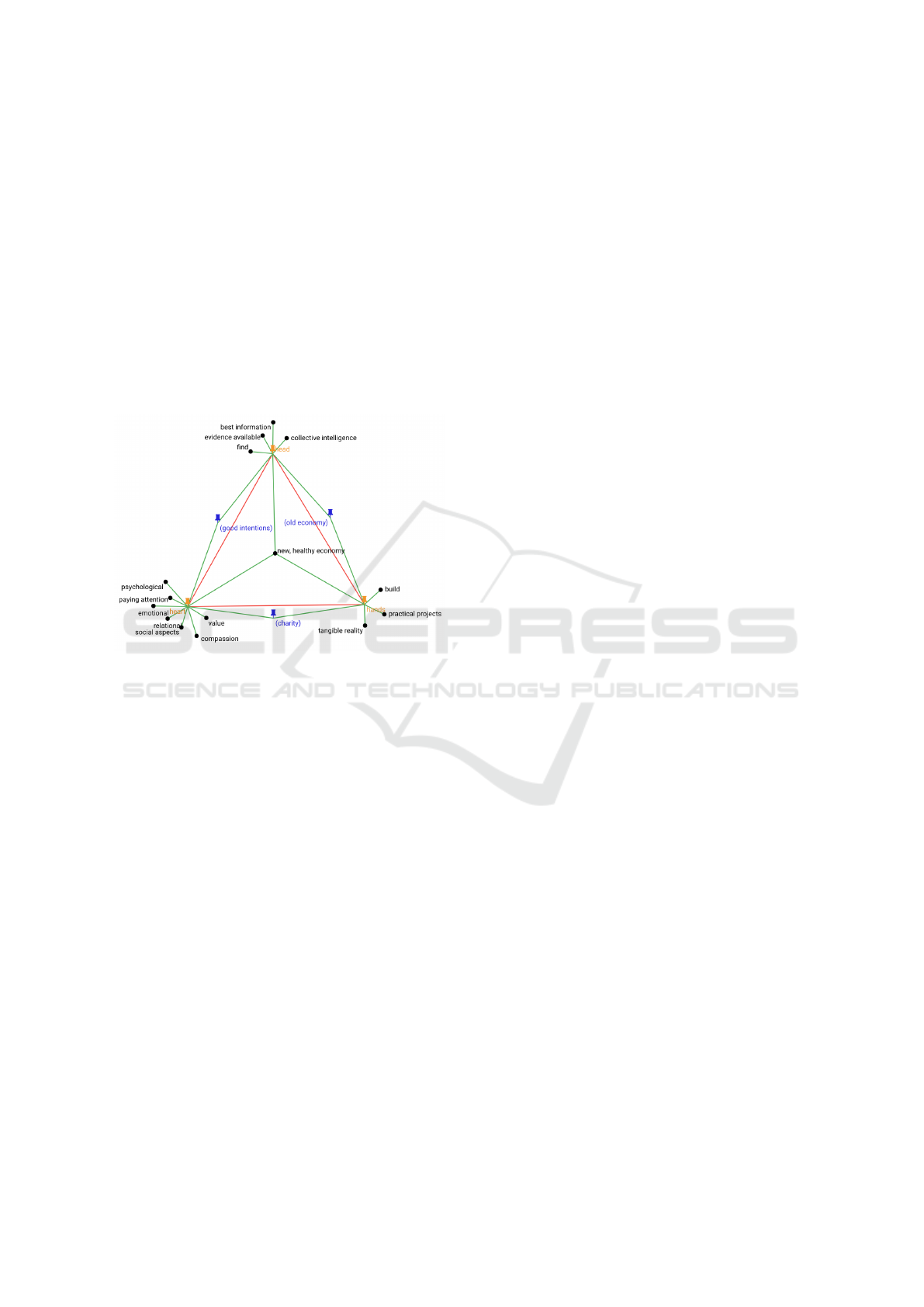
problems. The question of the placement of points
in space is much more delicate. A large literature
deals with the question of the placement of the points
of a graph in particular with the objective of limit-
ing the crossings of the arcs. The dictionaries of re-
lations integrating two types of relations, these so-
lutions proved to be unsatisfactory in terms of inter-
pretability of the produced diagram. The Shock Wave
algorithm (Cauz et al., 2021) has been specifically de-
veloped to visualise relation dictionaries. It places the
nodes to highlight the structural axes represented by
the opposition relations.
Figure 5 presents the node-link diagram created
for the Transition example.
Figure 5: Node-Link diagram.
Each of the visualisations integrates its own inter-
action mechanisms which give access to the functions
described in the section 4.3 : add, delete or modify
a word, add or delete a relation (for more details see
(Clarinval et al., 2018)). The node-link diagram also
offers the specific possibility of modifying the map-
ping function by changing the position of a node with
a simple drag and drop.
6 CONCLUSION
The qualitative analysis of unstructured texts is an es-
sential task for human science researchers. It remains
largely unexplored by the IT world, which offers these
researchers essentially support tools for the manipula-
tion of texts and elements of analysis that do little to
enrich the analyst’s reflection or focus on quantitative
approaches (Lejeune, 2010).
Through the contribution presented in this work,
we develop an innovative perspective which aims to
propose a formal modelling of the analyst’s approach
in order to offer him a variety of visual supports that
multiply the views on the analysis in progress while
preserving their coherence.
To achieve this ambition, the formal modelling of
the analysis integrates in its structure the theory of
language mobilised for the analysis: structural analy-
sis. This paper proposes a formal model of knowledge
that incorporates this theory. It also illustrates how
this model allows for intermediary transposition and
ensures the overall consistency of the semantic land-
scape. The transpositions that make up the semantic
landscape provide rich tools both for communicating
analyses and for stimulating the creativity of the re-
searcher.
This work served as the basis for the development
of the Evoq tool (Clarinval et al., 2018; Linden et al.,
2020) available on https://evoq.info.unamur.be/login.
REFERENCES
Cauz, M., Albert, J., Wallemacq, A., Linden, I., and Dumas,
B. (2021). Shock wave: a graph layout algorithm for
text analyzing. In Patrick Healy, M. B. and Bonnic,
A., editors, Proceedings of the 21st ACM Symposium
on Document Engineering. ACM Press.
Clarinval, A., Linden, I., Wallemacq, A., and Dumas, B.
(2018). Evoq: a visualization tool to support structural
analysis of text documents. In Proceedings of the 2018
ACM Symposium on Document Engineering, United
States. ACM Press.
Derrida, J. (1967). L’
´
ecriture et la diff
´
erence. Editions du
Seuil, Paris.
Ellestr
¨
om, L., editor (2010). Media Borders, Multimodality
and Intermediality. Palgrave Macmillan, London.
Ellestr
¨
om, L. (2014). Media transformation. The Trans-
fer of Media Characteristics among Media. Palgrave
Macmillan, London.
Gibson, H., Faith, J., and Vickers, P. (2013). A survey
of two-dimensional graph layout techniques for infor-
mation visualisation. Information Visualization, 12(3-
4):324–357.
Kucher, K. and Kerren, A. (2015). Text visualization tech-
niques: Taxonomy, visual survey, and community in-
sights. In Proceedings of IEEE Pacific Visualization
Symposium (PacificVis), pages 117–121. IEEE.
Lejeune, C. (2010). Montrer, calculer, explorer, analyser. ce
que l’informatique fait (faire)
`
a l’analyse qualitative.
Recherches Qualitatives, 9:15–32.
Lejeune, C. (2021). http://www.squash.ulg.ac.be/lejeune/.
web page dedicated to Qualitative Data Analysis Soft-
wares, accessed:2022-03-29.
Linden, I., Wallemacq, A., Dumas, B., Deville, G., Clarin-
val, A., and Cauz, M. (2020). Text as semantic fields:
Integration of an enriched language conception in the
text analysis tool evoq
R
. In Fabiano Dalpiaz, J. Z.
and Loucopoulos, P., editors, Research Challenges
in Information Science - 14th International Confer-
ence, RCIS 2020, Proceedings, volume 385 of Lec-
A Formal Model to Support Discourse Semantic Landscape Analysis
125

ture Notes in Business Information Processing, pages
543–548.
Rajewsky, I. (2002). Intermedialit
¨
at. A.Franke UTB,
Stuttgart.
Rajewsky, I. (2005). Intermediality, intertextuality, and re-
mediation: A literary perspective on intermediality.
Interm
´
edialit
´
es / Intermediality, (6):43–64.
Transition Network (2021). https://transitionnetwork.
org/about-the-movement/what-is-transition/
principles-2/. accessed:2022-03-30.
Wolf, W. (1999). The Musicalization of Fiction. A Study in
the Theory and History of Inter mediality. Amsterdam
; Atlanta, GA : Rodopi.
DATA 2022 - 11th International Conference on Data Science, Technology and Applications
126
