
A Grey Literature Review on the Impacts of Covid-19 in Software
Development
Everton Quadros
a
, Rafael Prikladnicki
b
and Regis Lahm
c
PPGCC, Polytechnic School, PUCRS University, Av. Ipiranga, 6681, Porto Alegre, Brazil
Keywords:
Remote Work, Distributed Software Development, Software Engineering, Covid-19, Pandemics.
Abstract:
The workplace has been changed by Covid-19. But what is the meaning of the “work from home” phenomenon
in software development? This paper aims to investigate the “work from home” pandemic phenomenon in
software development. Between October 2019 and December 2021, the Grey Literature review was carried out
to investigate 25,251 records, collected through a scraper written in python language. Descriptive analysis was
performed using data science and artificial intelligence techniques. We developed a methodology to optimize
the collection and extraction of insights from the Grey Literature and reveal perceptions or cognitive distances
from the social representation of the impacts of Covid-19 in software development. The main contributions
of this paper are to show how Grey Literature may contribute to anticipate findings, reveal changes in the
discourse regarding the effects of the pandemic on the work model, and show that in early 2021 the desire for
flexibility pressed for a hybrid model. This type of literature review can assist in strategies to deal with events
such as Covid-19.
1 INTRODUCTION
The Covid-19 pandemic was made official on March
11, 2020 by the World Health Organization (WHO)
(Bogoch et al., 2020). Since then, studies that analyze
the impacts of the pandemic in the area of Software
Engineering (SE) have begun (Ralph et al., 2020;
Oliveira et al., 2020). This paper aims to character-
ize the state-of-the-art about impacts of the pandemic
on the working model of SE through a Grey Literature
(GL) review (Garousi et al., 2019; Kamei et al., 2021).
We also proposed the development of a methodology
that optimizes the collection and extraction of insights
from GL to answer the following research questions:
• RQ1: How to automate the collection of evidences
from the grey literature to investigate the impacts
of Covid-19 in software development?
• RQ2: What are the cognitive distances in the so-
cial representation of the impacts of Covid-19 in
software development?
To answer these questions we resorted to the sci-
entific method of Systematic Literature and Grey
a
https://orcid.org/0000-0003-4137-9937
b
https://orcid.org/0000-0003-3351-4916
c
https://orcid.org/0000-0002-1102-5655
Literature (GL) reviews (Kitchenham and Charters,
2007; Garousi et al., 2019). Using a Python scraper
algorithm we collected from Google Search Engine
(GSE) the GL records for the period between October
2019 and December 2021. This process generated a
corpus with 25,251 records. After the screening (Page
et al., 2021) -procedures for selecting a study by
relevance (Kitchenham and Charters, 2007; Garousi
et al., 2019) and data extraction -procedures for an-
swer research questions (Kitchenham and Charters,
2007; Garousi et al., 2019), data science and artifi-
cial intelligence were applied to create data synthesis
-procedures for synthesizing evidence with qualitative
analysis (narrative) or quantitative analysis (Kitchen-
ham and Charters, 2007; Garousi et al., 2019), speed-
ing up the synthesis of results. The choice to use
GL resulted from the urgency of the research and the
scarcity of data on the impact of pandemics in soft-
ware development in the Academic or Traditional Lit-
erature, according to the guidelines for GL (Garousi
et al., 2019).
The objective of RQ1 was to develop a method-
ological proposal that automates the process of data
collection and data synthesis in GL. RQ2 aimed to re-
veal perceptions or cognitive distances -distance be-
tween different perceptions about an object or phe-
nomenon (Nooteboom et al., 2007) from the social
Quadros, E., Prikladnicki, R. and Lahm, R.
A Grey Literature Review on the Impacts of Covid-19 in Software Development.
DOI: 10.5220/0011116100003179
In Proceedings of the 24th International Conference on Enterprise Information Systems (ICEIS 2022) - Volume 2, pages 199-206
ISBN: 978-989-758-569-2; ISSN: 2184-4992
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
199

representation (Moscovici, 2007; Jodelet, 2001) of
the impacts of Covid-19 in software development.
This RQ2 is important to understand how Covid-19
(as an extreme event) can impact different aspects of
software development, for example: disrupting the
software development working model through “new
normals”.
This paper is organized as follows: Section 2
presents the background. Section 3 describes the
methodology used. Section 4 reports the results. Sec-
tion 5 presents the discussion and Section 6 presents
the conclusions and final considerations.
2 BACKGROUND
Until recently, there were two main work models, first
“work from home” and then “back to the office” (Mi-
crosoft, 2021a) (Meira, 2021). However, the effects of
the pandemic were far from being binary. Now a third
way has been emerging since early 2021. However, it
is common knowledge that the discussion about a fu-
ture of remote work is not new.
Domenico de Masi wrote back in 1993 her book
called “Il telelavoro (Telework)”, where the author an-
alyzed 10 years of case studies about the challenges
and benefits of telework. In 1999, in the book “The
future of work”, he named Chapter 17 ‘Working Any-
where” (de Masi, 2021). This title alone makes clear
the author’s vision, already at that time, that the “fu-
ture of work” would be distributed or remote.
A brief review of the software engineering litera-
ture also reveals that distributed or remote is nothing
new and the present authors are part of a study group
that has been investigating the development of dis-
tributed software since the mid-2000s (Prikladnicki,
2003). If distributed software development, based on
the very concept of remote work, has not been new
for more than 20 years, how has Covid-19 really im-
pacted SE?
Answers are coming from social representations
or perceptions (Moscovici, 2007; Jodelet, 2001) of
professionals in the SE value chain about the impacts
of Covid-19 on the work model. Analyzing their per-
ceptions, verifying if there are cognitive distances and
what they would be, in order to arrive at a social rep-
resentation of the phenomenon itself is the challenge
of this paper.
Primary studies have addressed the impact of
Covid19 on the productivity of software engineers,
highlighting here one at the national in Brazil level
(Oliveira et al., 2020) and another at the international
level (Ralph et al., 2020). These were conducted
through a survey online. The studies showed diver-
gent social representations about how Covid-19 im-
pacted the productivity of software engineers. The
international study reported a loss of productivity (re-
sulting from the lack of an adequate structure for
forced remote work) and the Brazilian study reported
an impact of increased productivity (resulting from
fewer interruptions throughout the day). We iden-
tify in this case that there are different representations
of the same phenomenon that is the very impact of
Covid-19 in SE.
For Serge Moscovici and Denise Jodelet, social
representations are considered a phenomenon capa-
ble of materializing the world of ideas, mobilizing the
subject from the unknown to the familiar, therefore,
from the abstract to the concrete (Moscovici, 2007;
Jodelet, 2001). For Jodelet, social representation is
related to the basic needs of apprehension and com-
munication of/in the world, stating that we create rep-
resentations out of the need to be informed about the
world around us, emphasizing that they help us name
and define the most different aspects of daily life, in
order to interpret, make decisions and position our-
selves in relation to them.
Social Representations explain how and why peo-
ple give different names and concepts to the same
phenomenon. For example, Domenico de Masi’s tele-
work was cited as “Flexible Working Arrangements”
by the Human Resources team of UN (UN, 2019).
According to The Federation of International Civil
Servants Associations (FISCA) “The Future of the
UN System Workforce, or the UN Future of Work, is
a Task Force launched by the High-Level Committee
for Management (HLCM) during its 38th Session, 15-
16 October 2019”. In it, flexible work arrangements
(FWA) represent the modern workplace (UN, 2019).
From this point of view, the data in this GL are so-
cial representations or reported perceptions about how
they understand the impacts of Covid-19 on SE. Car-
rying out this analysis means identifying what are the
similarities, what are the trends evidenced by the re-
ports, therefore, if there are cognitive distances or dif-
ferent views on the phenomenon and what they would
be. What are the views on how Covid-19 impacts the
SE work model? The main objective here is to an-
swer this question. We will now describe the methods
used.
3 METHOD
The Grey Literature review (GL) was performed by
means of GL guidelines (Garousi et al., 2019; Kamei
et al., 2020). Herewith, we defined the Search pro-
cess (Section 3.1), Source selection (Section 3.2),
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
200

Study quality assessment (Section 3.3), Data extrac-
tion (Section 3.4) and Data Synthesis and Classifica-
tion (Section 3.5).
3.1 Search Process
Following Kitchenham and Charters (Kitchenham
and Charters, 2007) the search strings of the system-
atic mapping were organized in terms of population,
intervention, and expected results. The comparison
was omitted here because it is not relevant to the
present goal. Stabilization tests were performed un-
til the final adjustment of the search strings. The final
format used was:
• Population (software engineers or software devel-
opment or disaster informatics);
• Intervention (productivity or work from home or
remote working);
• Result (covid impact or disaster or resilience).
As proposed by (Kitchenham and Charters, 2007),
table 1 presents a summary of the search strategy
adopted, the inclusion criteria (IC) and, exclusion cri-
teria (EC) - which are described in depth in subsection
3.2.
Table 1: Data source and Search strategy.
Database CI/CE Search
title
Google Search ”Criteria” summary
Engine for selecting key words
(GSE) a study” date
The challenge in searching GL is choosing the
data source. There are many alternatives. Some au-
thors use project versioning platforms like GitHub.
Others use social networks for technical support to
developers such as Medium or StackOverflow. There
is also the possibility to focus on newspaper news.
Any choice impacts the result. To facilitate a broad
spectrum search, it was chosen to use Google search
results, as it can give an overview of the topic (Souza
et al., 2021; de Oliveira et al., 2021).
3.2 Source Selection
For each record collected, a set of inclusion and ex-
clusion criteria were applied. To be included, each
study must meet all inclusion criteria. The Table 2
describes the inclusion criteria. Exclusion criteria, on
the other hand, are described in Table 3. We excluded
any study that met at least one exclusion criterion.
The study quality assessment is described below.
Table 2: Inclusion criteria list.
Code Description
IC1 Record written in English
IC2 Record presenting empirical data, theoreti-
cal data, experience reports, or opinions;
IC3 Record published between 10/2019 and
12/2021, inclusive.
IC4 Record is available in its entirety and free
of charge.
IC5 Record of blogs, tweets, annual reports,
news article, presentation, videos, Q/A
sites such as StackOverflow, Wiki Arti-
cles, books, magazines, government re-
ports, white papers (Garousi et al., 2019).
Table 3: Exclusion criteria list.
Code Description
EC1 Duplicate records.
EC2 Records not focused on Software Engi-
neering.
EC3 Records unrelated to the Covid-19 pan-
demic.
EC4 Non-English language records.
EC5 Records not responding to RQ’s (RQ1 and
RQ2).
EC6 Records that do not explicitly address in
their reports the impacts of the pandemic
on SE, according to Computing Curricula
2020 - CC2020.
EC7 Records that clearly is only propaganda
of professionals/companies/governments
with the intention of taking advantage of
the pandemic for marketing and selling a
certain product or service.
3.3 Study Quality Assessment
The quality of the records of a GL is measured
through the Tiers or “shades of Grey” (Garousi et al.,
2019; Kamei et al., 2020). These authors state that in
GL reviews it is important to minimally assess the GL
quality. Tiers indicate the quality of the GL in direct
relation to the font type of each record. Its analysis
provides a sort of hierarchy of the possible quality of
the records. The Tiers(Kamei et al., 2020) are:
• Tier-1: books/chapters, white papers, thesis, mag-
azines and government reports;
• Tier-2: annual reports, newspaper articles, Q&A,
company websites;
• Tier-3: blog, social media articles (e.g. tweets).
A Grey Literature Review on the Impacts of Covid-19 in Software Development
201
3.4 Data Extraction
The data extraction and mapping was performed
from a Python scraper algorithm that collected from
Google Search Engine (GSE) the GL records for the
period between October 2019 and December 2021.
The algorithm performs a search on GSE using the
search strings within a window every 24h and not lim-
iting itself to just the first search page that displays
only the first 10 page rank records, as is usually of-
fered by private web scraping API’s since most free
resources are limited to delivering only the first 10
search records. This process generated a corpus with
25,251 records.
3.5 Data Synthesis and Classification
The data collected by the scraper was stored in a
*.CSV table. The variables created by the scraper are:
Table 4: Classification scheme.
Variable Description
date date of records
header title of records
summary abstract of records by GSE
RQ2 Does que paper answer RQ2?
For the qualitative classification, a classification
scheme was proposed by “a priori” categories for each
record included in this study, namely: “Analysis of
the adopted work model”, “Work model issues” and
“Ideal working model”, based on the model adopted
by the United Nations (UN, 2019). A template is
available in the Appendix Section. A template is
available in Appendix Section.
4 RESULTS
From an initial set of 25,251 records collected through
the search process, we selected 51 records. The re-
sults are presented below.
4.1 RQ1: How to Automate the
Collection of Evidence from the
Gray Literature to Investigate the
Impacts of Covid-19 in Software
Development?
Automation was performed using a scraper to collect
data from the GL using the Python programming lan-
guage. The scraper made it possible to systematize
data collection (Souza et al., 2021; de Oliveira et al.,
2021). The challenge in automating data collection
is that each site has a unique pattern. As it was not
feasible to create a scraper for each WWW site the
choice was to use the Google Search Engine (GSE).
The script is free and available as an appendix.
4.1.1 Data Extraction Results
The Preferred Reporting Items for Systematic Re-
views and Meta-Analyses (PRISMA) methodology
was used for reporting the systematic review result
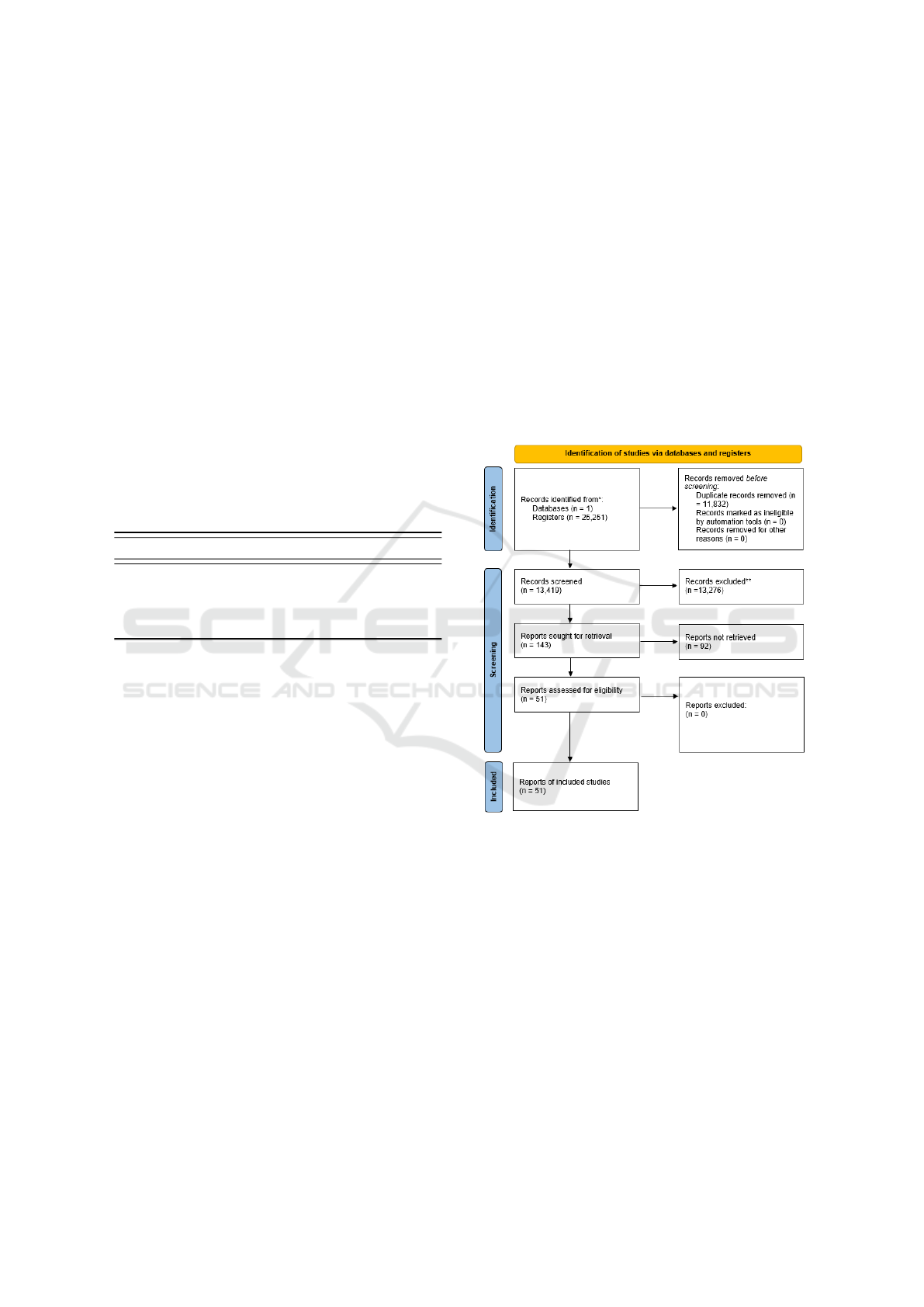
and meta-analyses (Page et al., 2021), as shown in
figure 1. In this diagram flow the screening step was
done in 5 successive statuses (0 to 4) verifying the
relevance of the records to the domain of this study.
Figure 1: Flow diagram, by PRISMA (Page et al., 2021).
In Status1, 11,832 duplicate records were ex-
cluded based on the analysis of the columns “header”,
“summary” and “date”. In Status2, the inclusion (CI)
and exclusion (EC) criteria, cited in table 1, were ap-
plied, resulting in 143 articles considered valid in this
stage. In Status3, the titles, abstracts, and keywords
were read to verify if the record in fact met the study
domain, resulting in 51 selected articles. Finally, in
Status4 these were categorized. Next, we present the
results that help to answer RQ1.
4.1.2 Data Synthesis Results
In addition to the variables planned and mentioned
in Section 3.5, using data science and natural lan-
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
202

guage processing frameworks, it was possible to col-
lect 81 variables in all, the main ones mentioned here:
“domain name”, “ipaddress”, “latitude”, “longitude
”, “city”, “quarter”, “pdf fullText”, “qtd strings”,
“topic dominant”, and “sentiment dominante”.
The data synthesis step was carried out based on a
short protocol was that summarizes the steps and anal-
ysis techniques used in increasing order of complex-
ity. It begins with a temporal visualization by page
rank and day of collection and ends with the applica-
tion of advanced NLP resources, as presented below.
Table 5: Data science, Machine learning and Dataviz Pro-
tocol.
dataviz and machine learning steps
1 Page rank by day of collect data
2 Word cloud
3 Frequency by date
4 Frequency by source
5 Graph analysis of registers
6 Geospatial distribution of the source
7 Sentiment analysis of the total period
8 Sentiment analysis by monthly period
9 Similarity index
10 Q/A with Bert
It is good practice in GL to save eligible records
to “*.pdf” (Garousi et al., 2019; Kamei et al., 2021).
In addition to allowing records to be preserved, we
use python to extract their full text to use as a cor-
pus in the NLP steps of this protocol, for example,
to count the occurrence of keywords and to create a
Word cloud (Sharp et al., 2017; Russell and Norvig,
2009).
Figure 2: Word cloud - Fulltext of records.
This signal cloud was extracted from the full text
of the 51 analyzed records. Next, we present the re-
sults of RQ2.
4.2 RQ2: What Are the Cognitive
Distances in the Social
Representation of the Impacts of
Covid-19 in Software Development?
Cognitive distances resulting from different social
representations or reported perceptions were identi-
fied when analyzing the impact cited in the analyzed
text. For that, we use as reference 3 “a priori” classes:
People, Projects and Organizations. In summary, the
main conclusions about the impacts reported in these
classes are:
• 37 registries reported that Covid-19 had a positive
impact in SE, 25 reported negative impacts and
21 registries reported both positive and negative
impacts.
• Positive impacts on the social representation of
the authors of the records benefit people with 25
records. Organizations were cited in 25 registries
and projects in 15. Some registries cited impacts
in all 3 categories.
• Negative impacts would affect people with 25
records. Organizations with 25 registries and
projects in 15.
The topic modeling analysis revealed that the Peo-
ple, Projects and Organizations classes also emerged
among the 30 Most Relevant Terms for Topic 1
(40.6% of tokens). This unsupervised classification
analysis was generated through Latent Dirichlet Al-
location (LDA) and the Sklearn framework (Python)
using the full text of the records. The 4 main topic
clusters are shown in the following figure.
Figure 3: Topic modeling - LDA.
In the GL Frequency by date analysis, it was found
that there was a higher concentration of records in the
first quarter of 2021 and the second quarter of 2020,
respectively.
It was in the third quarter of 2020 that the first
mention of the “work from home” phenomenon was
A Grey Literature Review on the Impacts of Covid-19 in Software Development
203

Temporal distribution by quarter
Figure 4.
related to the hybrid trend, as shown by the following
evidence:
• knowledgehut.com (Knowledgehut, 2022), Ev-
idence: “Following the pandemic, working from
home more frequently (perhaps 2-3 days per
week) may become an accepted norm for many
companies, as this could realize cost efficiencies
and prove that an agile, remote working model is
productive.” Date: 2020-07-24.
This process was intensified in the first quarter of
2021. In addition, other sub-questions helped to an-
swer RQ2, facilitating the analysis of social represen-
tations reported through the following previous ques-
tions, as shown in Appendix.
The questions about the adopted work model
and the ideal work model were classified (Microsoft,
2021b). Figure 5 shows the summary of the results.’
Figure 5: Social representation - RQ2.
The remaining questions were categorized be-
tween “Yes” and “No”. When a record did not ad-
dress the question, this record was categorized as NA.
The main results are presented below.
4.2.1 Work Model Adopted
Because of the current pandemic situation, the first
question, “Check the option that best represents the
work model adopted by the company” was catego-
rized in all 51 records as ”fully remot”. This was the
only option identified in the reports during this study.
4.2.2 Work Model Issues
A couple of questions were proposed that could in-
dicate the status of the current and future scenario of
Covid-19 impacts on the SE. One of the questions was
to see if there are any reports of negative impacts.
Figure 6: The pandemic had a negative impact on the
change in the work model.
The reported social representations indicate that
38 records (or 74.50%) do not consider that Covid-19
has negatively impacted the work model. Followed
by 18 records (or 35.29%) who affirm that there is
some negative impact. Only 1 record did not report
this issue.
When analyzing the impacts of engagement of the
teams with the company, according to figure 7, it was
found that 12 records (or 23.52%) believe that there
are negative impacts of Covid-19. Only 5 records (or
0.98%) affirm that there are no negative impacts, and
34 records did not report this topic.
Figure 7: The work model adopted has a negative impact on
the team’s engagement with the company.
Another relevant question was to verify if ”The
current working model is different from the dis-
tributed software development (DDS) model”, ac-
cording to 8. In this sense, it was verified that 15
records (or 29.41%) indicate that there are differences
between the current remote working model and the
model traditionally known as DDS. Followed by 12
Figure 8: The current working model is different from the
distributed software development (DDS) model.
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
204

records (or 23.52%) do not consider there are differ-
ences between the current model and DDS. And 24
records did not mention this topic.
4.2.3 Ideal Work Model
Another aspect worth mentioning is “Check the op-
tion that best represents the ideal work model”, ac-
cording to 9. In this sense, we verified that 22 records
(or 43.13%) already indicated the hybrid model with
flexibility as ideal. Followed by 10 records (or
19.60%) indicating the totally remote model. Only 1
record reported the hybrid without flexibility as ideal
and 18 records did not report this topic.
Figure 9: Check the option that best represents the ideal
work model.
These were the main results achieved in RQ2. Fol-
lowing are the discussions.
5 DISCUSSION
This research was an important opportunity to tran-
sit through interdisciplinarity, necessary and desired
in the analysis of any complex problem. Here con-
cepts from Software Engineering, Social Representa-
tion, and Sociology were brought together to contex-
tualize the very notion of what “work” is.
The common thread that made it possible to link
all these different fields of knowledge was the system-
atic review of the Grey Literature. The results of this
union generated as a benefit a methodological pro-
posal for the automation of the Grey Literature data
collection. Moreover, to guide the analytical process,
a small protocol was proposed that contains the main
steps and techniques often used in text data synthesis,
especially when adopting natural language processing
(NLP) resources.
The distributions of social representations identi-
fied in the observed reports indicate that there is con-
siderable cognitive distance as to the ways in which
the Covid-19 pandemic has impacted the SE work-
ing model. At some points, there appears to be
agreement, but not without distinct points of view.
Still, when analyzing the trend of impact on the work
model, one point stood out: the ”hybrid model,” be-
ing reported in 23 records (or 45.09%), considering
the possibility of a ”hybrid model” of work with or
without flexibility.
This finding reinforces what researchers in Soci-
ology such as Domenico de Masi and in Computing
such as Silvio Meira have been saying for some time
(de Masi, 2021; Meira, 2021). First, more than 40
years ago Domenico de Masi asserted the possibil-
ity of remote work. Second, Silvio Meira states that
the future is neither totally face-to-face nor totally re-
mote. The author suggests that the future is Phygital,
an acronym resulting from 3 dimensions that are the
Physical, Digital, and Social dimensions, according
to Silvio Meira.
Invariably, whatever the shape of this future of
work in software engineering, something new seems
to have awakened. This apparent newness is summed
up in the desire for flexibility. Everything indicates
that it is the notion of this concept and the evolution of
this flexibility in the mindset of developers and com-
panies in the software industry that may bring new
perspectives and possibilities that will shape the true
future of software engineers’ work.
6 CONCLUSIONS
The results revealed that at GL there are distant views
on the impacts of Covid-19 on software development.
The pandemic triggered secondary phenomena that
were called, for example, “remote work”, “work from
home” and flexible work”.
These terms are the result of different social repre-
sentations of the same macro-event, which is the very
impact of Covid-19 on the work model. As future
work, further research is suggested on the most recent
of these secondary phenomena: the “hybrid” model.
Questions such as: What is being a hybrid and
what does it imply in the practice of higher education?
What would be the guidelines or best practices for a
hybrid model to work? These are just a few questions
that can help professionals and companies create new
disaster risk reduction protocols aimed at building re-
silience and adaptation in combating the impacts of
Covid-19 or future disasters that may impact software
development.
ACKNOWLEDGEMENTS
Rafael Prikladnicki is partially funded by Fapergs and
CNPQ.
A Grey Literature Review on the Impacts of Covid-19 in Software Development
205

REFERENCES
Bogoch, I., Watts, A., Thomas-Bachli, A., Huber, C., Krae-
mer, M., and Khan, K. (2020). Pneumonia of un-
known etiology in wuhan, china: Potential for inter-
national spread via commercial air travel. Journal of
travel medicine, 27.
de Masi, D. (2021). Jota – domenico de masi: “voc
ˆ
es,
brasileiros, podem ser um modelo para o mundo”.
de Oliveira, P. A. M., de Alc
ˆ
antara dos Santos Neto, P.,
de Andrade e Silva Silva, G., Ibiapina, I., Lira, W.,
and de Castro Andrade, R. M. (2021). Software de-
velopment during COVID-19 pandemic: an analysis
of stack overflow and github. CoRR, abs/2103.05494.
Garousi, V., Felderer, M., and M
¨
antyl
¨
a, M. V. (2019).
Guidelines for including grey literature and conduct-
ing multivocal literature reviews in software engineer-
ing. Information and Software Technology, 106:101–
121.
Jodelet, D. (2001). As representac¸
˜
oes sociais. EdUERJ, Rio
de Janeiro, Brazil.
Kamei, F., Wiese, I., Lima, C., Polato, I., Nepomuceno, V.,
Ferreira, W., Ribeiro, M., Pena, C., Cartaxo, B., Pinto,
G., and Soares, S. (2021). Grey literature in software
engineering: A critical review. Information and Soft-
ware Technology, 138:106609.
Kamei, F., Wiese, I., Pinto, G., Ribeiro, M., and Soares, S.
(2020). On the use of grey literature: A survey with
the brazilian software engineering research commu-
nity. In Proceedings of the 34th Brazilian Symposium
on Software Engineering, SBES ’20, page 183–192,
New York, NY, USA. Association for Computing Ma-
chinery.
Kitchenham, B. and Charters, S. (2007). Guidelines for per-
forming systematic literature reviews in software en-
gineering.
Knowledgehut (2022). Key insights from the 2020 state of
agile report.
Meira, S. (2021). Desnudando o telerabalho: transformac¸o
digital, o teletrabalho e as perspectivas para o futuro.
Microsoft (2021a). New future of work.
Microsoft (2021b). The new future of work:research from
microsoft into the pandemic’s impact on work prac-
tices.
Moscovici, S. (2007). Representac¸
˜
oes sociais:
investigac¸
˜
oes em psicologia social, 5ª ed. Vozes,
Petr
´
opolis, Brazil.
Nooteboom, B., Van Haverbeke, W., Duysters, G., Gils-
ing, V., and van den Oord, A. (2007). Optimal cogni-
tive distance and absorptive capacity. Research Policy,
36(7):1016–1034.
Oliveira, E., Leal, G., Valente, M. T., Morandini, M., Prik-
ladnicki, R., Pompermaier, L., Chanin, R., Caldeira,
C., Machado, L., and de Souza, C. (2020). Surveying
the impacts of covid-19 on the perceived productivity
of brazilian software developers. In Proceedings of
the 34th Brazilian Symposium on Software Engineer-
ing, SBES ’20, page 586–595, New York, NY, USA.
Association for Computing Machinery.
Page, M. J., Moher, D., Bossuyt, P. M., Boutron, I., Hoff-
mann, T. C., Mulrow, C. D., Shamseer, L., Tetzlaff,
J. M., Akl, E. A., Brennan, S. E., Chou, R., Glanville,
J., Grimshaw, J. M., Hr
´
objartsson, A., Lalu, M. M.,
Li, T., Loder, E. W., Mayo-Wilson, E., McDonald,
S., McGuinness, L. A., Stewart, L. A., Thomas, J.,
Tricco, A. C., Welch, V. A., Whiting, P., and McKen-
zie, J. E. (2021). Prisma 2020 explanation and elabo-
ration: updated guidance and exemplars for reporting
systematic reviews. BMJ, 372.
Prikladnicki, R. (2003). Munddos : um modelo de re-
fer
ˆ
encia para desenvolvimento distribu
´
ıdo de soft-
ware. Master’s thesis, Escola Polit
´
ecnica, Programa
de P
´
os-Graduac¸
˜
ao em Ci
ˆ
encia da Computac¸
˜
ao.
Ralph, P., Baltes, S., Adisaputri, G., Torkar, R., Kovalenko,
V., Kalinowski, M., Novielli, N., Yoo, S., Devroey, X.,
Tan, X., Turhan, B., Hoda, R., Hata, H., Robles, G.,
Milani Fard, A., and Alkadhi, R. (2020). Pandemic
programming: How covid-19 affects software devel-
opers and how their organizations can help. Empirical
software engineering, 25:1–35.
Russell, S. J. and Norvig, P. (2009). Artificial Intelligence:
a modern approach. Pearson, 3 edition.
Sharp, B., Sedes, F., and Lubaszewski, W. (2017). Cogni-
tive Approach to Natural Language Processing. ISTE
Press - Elsevier, London/Oxford, GBR, 1st edition.
Souza, W. M., Filho, W., and Santos, W. (2021). Ferramenta
de web-scraping: Impactos da covid-19 na ind
´
ustria
de software. In Anais Estendidos do XVII Simp
´
osio
Brasileiro de Sistemas de Informac¸
˜
ao, pages 49–52,
Porto Alegre, RS, Brasil. SBC.
UN (’2019’). Flexible working arrangements
(st/sgb/2019/3).
APPENDIX
Here is a link to access the graphs and tables of the
data analyzed in this study: https://bit.ly/34k2t3m
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
206
