
An ML Agent using the Policy Gradient Method to win a SoccerTwos
Game
Victor Ulisses Pugliese
a
Federal University of S
˜
ao Paulo, Avenida Cesare Mansueto Giulio Lattes, 1201, S
˜
ao Jos
´
e dos Campos, Brazil
Keywords:
Reinforcement Learning, Proximal Policy Optimization, Curriculum Learning, Video Games.
Abstract:
We conducted an investigative study of Policy Gradient methods using Curriculum Learning applied in Video
Games, as professors at the Federal University of Goi
´
as created a customized SoccerTwos environment to
evaluate the Machine Learning agents of students in a Reinforcement Learning course. We employed the
PPO and SAC as state-of-arts in on-policy and off-policy contexts, respectively. Also, the Curriculum could
improve the performance based on it is easier to teach people in a complex gradual order than randomly. So,
combining them, we propose our agents win more matches than their adversaries. We measured the results by
minimum, maximum, mean rewards, and the mean length per episode in checkpoints. Finally, PPO achieved
the best result with Curriculum Learning, modifying players’ (position and rotation) and ball’s (speed and
position) settings in time intervals. Also, It used fewer training hours than other experiments.
1 INTRODUCTION
Artificial Intelligence (AI) plays an essential role in
video games to generate responsive, adaptive, or in-
telligent behavior, mainly in non-player characters
(NPCs), similar to human intelligence (Ranjitha et al.,
2020). Thus, it keeps players engaged even when
playing offline or when no players are available on-
line.
Furthermore, several games provide interesting
and complex problems for Machine Learning (ML)
agents to solve, and gaming environments are secure,
controllable, and offer unlimited valuable data for the
algorithms. These characteristics make video games
a perfect domain for AI research (Shao et al., 2019).
Therefore, the Artificial Intelligence Center of Ex-
cellence (Centro de Excel
ˆ
encia de Intelig
ˆ
encia Artifi-
cial - CEIA) professors at the Federal University of
Goi
´
as (Universidade Federal de Goias - UFG) did a
customized version of the SoccerTwos game and em-
ployed two ML baseline agents. The baseline agents
were used to evaluate the students’ agents in a Rein-
forcement Learning (RL) course.
The game simulates two soccer teams playing
each other and counts who mark more goals in a spec-
ified time. Our goal was to identify which approach
was the best recommendation to win the matches.
a
https://orcid.org/0000-0001-8033-6679
Thus, we proposed two Policy Gradient meth-
ods, Proximal Policy Optimization (PPO) and Soft
Actor-Critic (SAC), because they are state-of-art in
on-policy and off-policy ways, respectively. We also
employed them with Curriculum Learning (CL). CL
is a provocative learning strategy on how humans and
animals learn better in a complex gradual order than
randomly (Bengio et al., 2009).
To contextualize our work, we surveyed related
works. Then, we performed an evaluation com-
paring the methods with the baseline agents of the
CEIA/UFG. Finally, we present the main findings and
conclude the paper.
2 BACKGROUND
2.1 Reinforcement Learning
Reinforcement learning (RL) is a subfield of machine
learning (ML) that addresses the problem of the auto-
matic learning of optimal decisions over time. It uses
well-established supervised learning methods, such
as deep neural networks for function approximation,
stochastic gradient descent, and backpropagation, and
applies it differently (Lapan, 2018) because there is
no supervisor, only a reward signal, and feedback is
delayed, not instantaneous. Therefore, an ML agent
628
Pugliese, V.
An ML Agent using the Policy Gradient Method to win a SoccerTwos Game.
DOI: 10.5220/0011108400003179
In Proceedings of the 24th International Conference on Enterprise Information Systems (ICEIS 2022) - Volume 1, pages 628-633
ISBN: 978-989-758-569-2; ISSN: 2184-4992
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
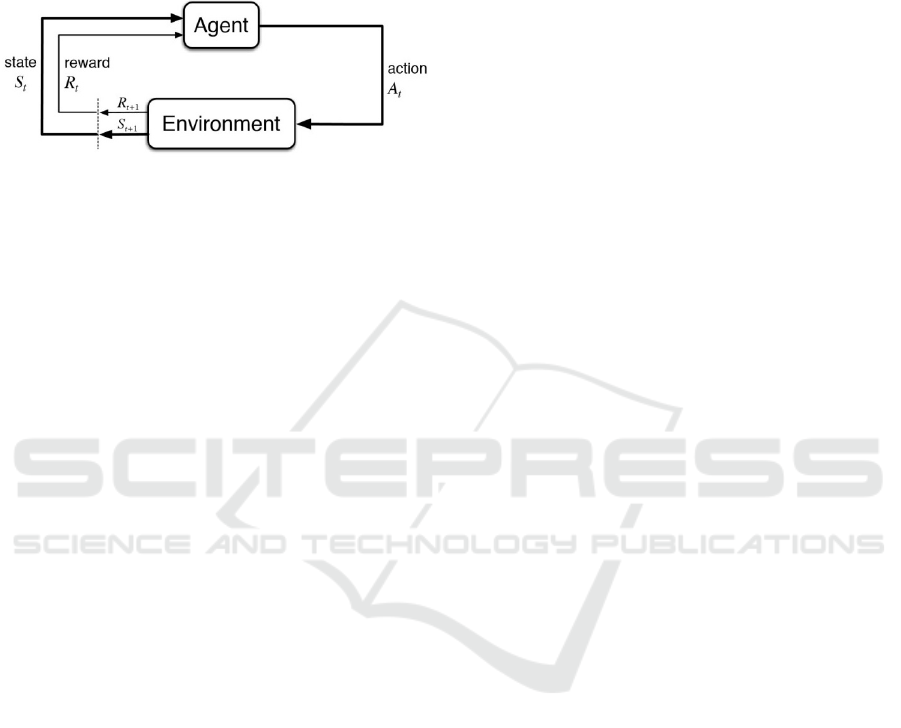
using these methods faces problems, learning its be-
havior through trial-and-error interactions with a dy-
namic environment (Kaelbling et al., 1996), commu-
nicate them through actions and states. Sutton and
Barto (Sutton and Barto, 2018) model the reinforce-
ment learning cycle as shown in Figure 1.
Figure 1: The agent–environment interaction in reinforce-
ment learning (Sutton and Barto, 2018).
2.2 Policy Gradient Method
Policy Gradient methods are a reinforcement learning
technique that optimizes parameterized policies con-
cerning the expected return (long-term cumulative re-
ward) per descending gradient (Huang et al., 2020).
We selected two methods to work, and they are Proxi-
mal Policy Optimization (PPO) and Soft Actor-Critic
(SAC)
2.2.1 PPO
Proximal Policy Optimization trains stochastic policy
in an on-policy way, which means that it explores by
sampling actions according to the latest version of its
stochastic approach. We can implement this in ei-
ther discrete or continuous action spaces (S
´
aenz Im-
bacu
´
an, 2021) and (Achiam, 2018).
Furthermore, the method utilizes the actor-critic,
which maps an observation to action, while the critic
rewards that. So, It collects a set of trajectories for
each epoch by sampling from the latest version of the
stochastic policy. Then, It computes the rewards-to-
go, and the advantage estimates to update the policy
and fit the value function. The approach is updated
via a stochastic gradient ascent optimizer, while the
value function is via some gradient descent algorithm
(Keras, 2022).
The amount of randomness in selecting actions
depends on the initial conditions and the training pro-
cedure. The policy typically becomes progressively
less random throughout training, as the updated rule
encourages it to explore rewards it has already found
(S
´
aenz Imbacu
´
an, 2021).
2.2.2 SAC
Soft Actor-Critic optimizes stochastic policy in an off-
policy way, forming a bridge between stochastic pol-
icy optimization and DDPG-style approaches. Ini-
tially, It was for environments with continuous action
spaces, but there is already an alternative version for
discrete ones (Achiam, 2018).
The method is based on the maximum entropy
RL framework. Thus, The actor aims to maxi-
mize the expected reward while also maximizing en-
tropy. In other words, It succeeds in the task by act-
ing as randomly as possible. We can connect It to
the exploration-exploitation trade-off: increasing en-
tropy results in more exploration, accelerating learn-
ing later. (Achiam, 2018) and (Haarnoja et al., 2018).
Different from previous deep RL methods based
on this framework formulated as Q-learning meth-
ods. SAC works like TD3, incorporating the clipped
double-Q trick, but due to the inherent stochasticity of
the policy in SAC, it also benefits from something like
target policy smoothing. Therefore, It outperforms
prior on-policy and off-policy methods in a continu-
ous control benchmark (Achiam, 2018) and (Haarnoja
et al., 2018).
2.3 Curriculum Learning
We implement those methods with a training strategy,
such as Curriculum Learning. It is based on how hu-
mans and animals learn better in a complex gradual
order than randomly (Bengio et al., 2009).
An easy way to demonstrate this strategy is to
think about how math students learn arithmetic, al-
gebra, and calculus in the education system. Teachers
usually taught arithmetic before algebra, and algebra
before calculus. The skills and knowledge learned in
previous disciplines provide support for later lessons.
We can also apply this principle in machine learning,
where training the ML agents on the most straightfor-
ward tasks provides scaffolding for future challenging
tasks (Camargo and S
´
aenz, 2021).
3 RELATED WORKS
We searched for the term ’SoccerTwos’ on Google
Scholar and found eight academic papers related to it.
However, only six papers are about ML agents using
Reinforcement Learning.
S
´
aenz wrote a master thesis about the impact of
Curriculum Learning on the training process for an
in- intelligent agent in a video game as the SoccerT-
wos case study, using the SAC and PPO algorithms.
An ML Agent using the Policy Gradient Method to win a SoccerTwos Game
629
To measure the performance, he used the mean cumu-
lative reward. In some cases, this approach shortened
the training process by 40% percent and achieved bet-
ter measures than just algorithms. However, it was
sometimes worse or did not affect other cases. PPO
showed better results than SAC (S
´
aenz Imbacu
´
an,
2021). S
´
aenz and Camargo published a paper in 2021
(Camargo and S
´
aenz, 2021), reporting a part of this
thesis using PPO.
Majumder also realized a significant improvement
in training when Curriculum Learning applied along
with a Policy Gradient variant such as PPO. The in-
cremental steps allow the agent to learn quickly in a
new dynamic environment. Therefore, The authors
recommended It in a competitive or collaborative con-
text as SoccerTwos (Majumder, 2021).
Juliani et al. implemented a solution in a ran-
domly generated multiagent using the PPO method
in the’ Soccer Twos’ environment. They trained
the agents in a two-versus-two self-play mode. The
agents learned to reposition themselves defensively or
offensively and work cooperatively to score an oppo-
nent without conceding a goal (Juliani et al., 2018).
Osipov and Petrosian applied a modern multi-
agent reinforcement learning algorithm using the Ten-
sorFlow library, explicitly created for SoccerTwos.
They investigated different modeling tools and did
computational experiments to find their best train-
ing hyperparameters. Furthermore, They applied
this with the COMA gradient policy algorithm and
showed Its effectiveness (Osipov and Petrosian, ).
Unfortunately, the authors wrote it in Russian, and we
could not translate it.
Albuainain and Gatzoulis proposed an ML Agent,
using reinforcement learning to adapt to dynamic
physics-based environments in a 2D version of a ve-
hicular football game. Thus, they perform behaviors
such as defending their goal and attacking the ball us-
ing reward functions. They concluded that a reward
function considering different state-space parameters
could produce better-performing agents than those
with less defined reward function and state-space (Al-
buainain and Gatzoulis, 2020).
4 EVALUATION OF THE
METHODS USING ML AGENTS
We implemented our ML agents to play the SoccerT-
wos game customized by CEIA/UFG. The game is
available at this GitHub
4.1 Explaining the Environment
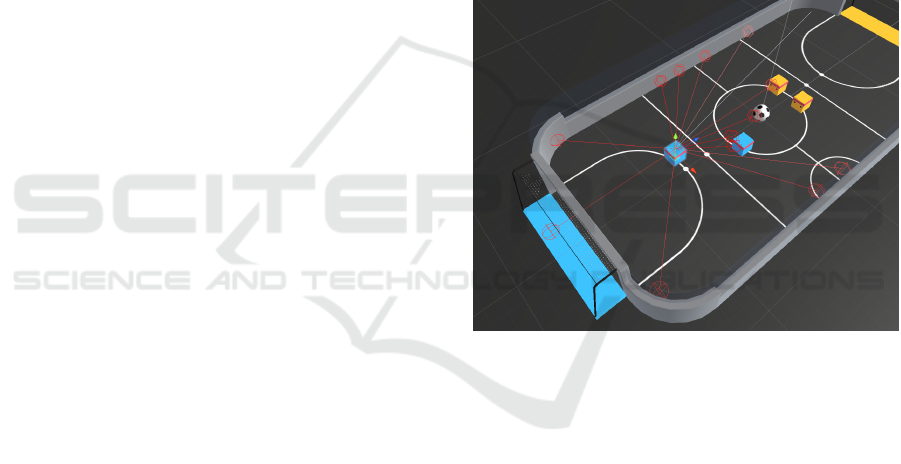
The original SoccerTwos environment contains four
players competing in a two vs. two toy soccer game,
aiming to get the ball into the opponent’s goal while
preventing it from entering its own goal. The players
have the same behavior parameters. The observation
space consists of 336 corresponding to 11 ray-casts
forward distributed over 120 degrees and 3 ray-casts
backward distributed over 90 degrees each 6 possi-
ble object types, along with the object’s distance. The
forward ray-casts contribute 264 state dimensions and
backward 72 state dimensions. The action space con-
sists of 3 discrete branched actions (MultiDiscrete)
corresponding to forward, backward, sideways move-
ment, as well as rotation (27 discrete actions) (Tyagi,
2021).
Figure 2: Observation and action states of SoccerTwos
Game.
The customized game has one time of 2 minutes,
two ML agents that play each other (representing two
teams), and a ball. Each team has two players as left
and right. Both start within a pre-defined position,
close to the field’s middle as seen in Figure 3. Its re-
ward function consists of two items (Oliveira, 2021):
• +1 - accumulated time penalty: when a ball en-
ters the opponent’s goal. With each fixed update,
the accrued time penalty is incremented by (1 /
MaxSteps). It reset to 0 at the beginning of an
episode. In this build, MaxSteps is equal to 5000.
• -1: when ball enters team’s goal.
4.2 The ML Agents Available by CEIA
In addition, the professors provided two baseline
agents (CEIA DQN and CEIA PPO) to evaluate and
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
630

Figure 3: SoccerTwos Game by CEIA/UFG.
test the performance of student’s experiments. Both
agents do not use Curriculum Learning.
CEIA DQN is an ML agent that uses the Deep Q-
Network method, which combines the neural network
within a classical reinforcement learning method
called Q-Network using the experience replay tech-
nique. They set optimized hyperparameters like 0.999
as eps decay, 336x512x27 as Q-Network, and 5000 as
max steps.
CEIA PPO is an ML agent that uses the PPO
method with these optimized hyperparameters like
256x256 as hidden layers and 5000 as rollout frag-
ment length in a multiagent setting. The code is avail-
able at this GitHub. The ML agent is available at link.
4.3 Design of Experiments
Using Ray tools (v1.10.0) with Pytorch as a frame-
work, we employed Policy Gradient methods with
Curriculum Learning. Ray aims to provide a sim-
ple universal API for distributed computing, support-
ing multiple libraries to solve problems in machine
learning, such as scalable hyperparameter tuning and
industrial-grade reinforcement learning (Moritz et al.,
2018).
Saenz recommended hyperparameter sets like
[0.00001; 0.001] for learning rate, [128; 512] for
batch size, [32;512] for hidden units and others for
use in PPO and SAC methods (S
´
aenz Imbacu
´
an,
2021). Also, there is an example of Ray example of
Ray - link - applied in SoccerTwos, which uses 0.0003
for learning rate, 0.95 for lambda, 0.99 for gamma,
256 for sgd minibatch size, 4000 for train batch size,
0.2 for clip param, 20 for num sgd iter, two neural
network layers to 512 units for PPO, and others.
We employed the experiments listed below:
• The first experiment only employs the policy
method for 24 hours without the opponent’s
movement or Curriculum Learning. The method
uses the recommended hyperparameters.
• The second experiment employs the policy meth-
ods with Curriculum A. It divides the 24 hours of
training into 16 without the opponent’s movement
and 8 of a random opponent. The spontaneous ac-
tivity happens in the middle of 16, making it three
intervals of 8 hours. We also set new hyperparam-
eters values.
• The last experiment employs the policy methods
with Curriculum B. Thus, it sets different levels as
Very Easy, Easy, Medium, and Hard, modifying
players’ (position and rotation) and ball’s (speed
and position) settings.
4.4 Evaluation Measures
To measure the performance of the Policy Gradient
methods employed in this study, we use the metrics:
mean length per episode; mean, maximum, and mini-
mum reward.
• Mean length per episode refers to how many it-
erations the ML agent takes to complete a game
move at a checkpoint.
• Mean is the average of cumulative reward values
by checkpoints.
• Maximum and minimum are the biggest and low-
est reward values by checkpoints.
5 RESULTS WITH THE ML
AGENTS
This section presents the results of the Policy Gradient
methods using Curriculum Learning for the SoccerT-
wos game.
We employed the ’PPO self-play’ and ’PPO
+ Curriculum A’. The ’self-play’ utilizes the
Ray example hyperparameters, while we mod-
ified these settings for ’PPO + Curriculum A’,
removing the train batch size, num sgd iter,
rollout fragment length, no done at end, evalua-
tion interval, and evaluation num episodes, and we
also updated the two neural network layers to 256
units. The Figure 4 shown the results comparing
them performance.
As seen in Figure 4, both experiments learned to
score, and their values are similar. However, if we ob-
serve the details, than the ’PPO + Curriculum A’ (rep-
resented by orange, red, and blue colors) converges
first. Also, It ended with a better mean reward than
PPO self-play.
We also evaluate ’PPO + Curriculum A’ versus the
’CEIA PPO’, running the gaming 200 times. Our ex-
An ML Agent using the Policy Gradient Method to win a SoccerTwos Game
631
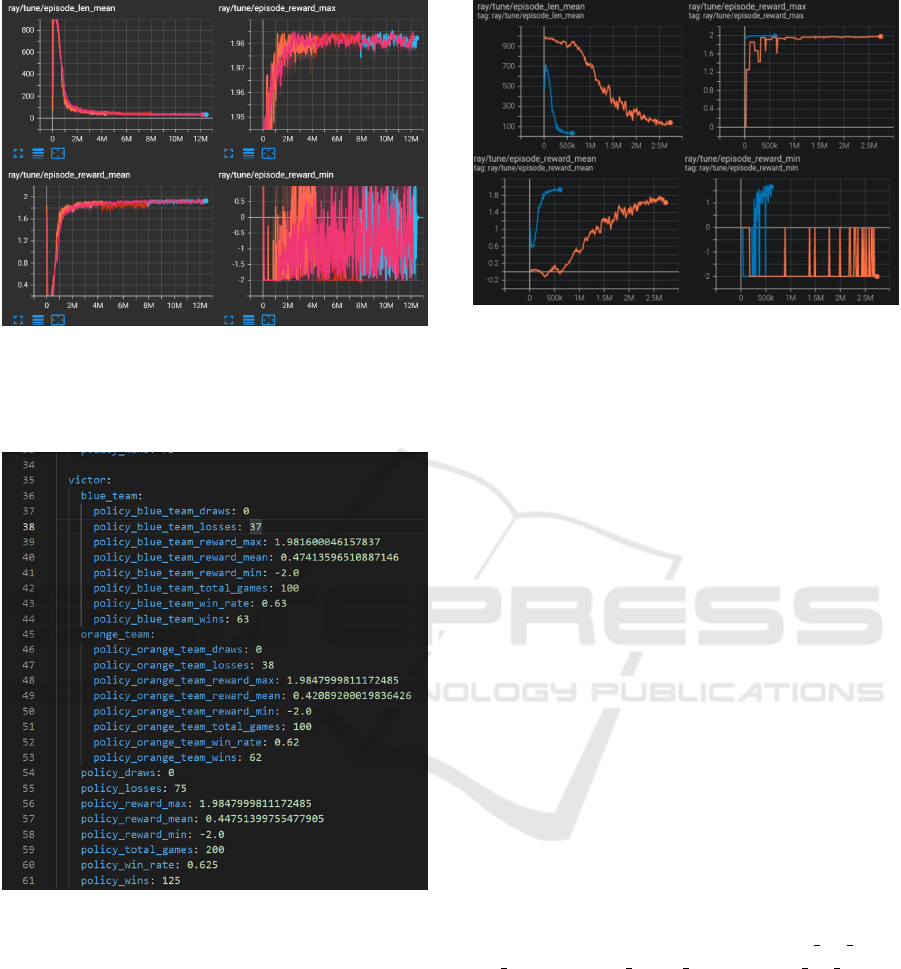
Figure 4: Results of PPO self-play (pink color) and PPO +
Curriculum A (orange, red and blue colors).
periment had won 125 matches, which means 62.5%,
of victories, as seen in Figure 5.
Figure 5: Using CEIA PPO to evaluate the performance of
PPO + Curriculum A.
We employed the ’PPO + Curriculum B’ experi-
ment, modifying players’ (position and rotation) and
ball’s (speed and position) settings. We compare this
one with ’PPO self-play’, as seen in Figure 6.
As shown in Figure 6, the ’PPO + Curriculum B’
convergence (blue color) is faster than PPO self-play
(orange color). Thus, It achieved more than 1.8 by
the mean reward of an episode in just 250k iterations,
which did not happen with ’self-play’. Furthermore,
the other measures are also better for it.
Figure 6: Comparing the performance of PPO + Curriculum
B versus PPO self-play.
6 MAIN CONCLUDES
This study investigated Policy Gradient methods us-
ing the Curriculum Learning strategy, applied in a
SoccerTwos game customized by CEIA/UFG. We
employ PPO and SAC methods in this environment.
Procedures were measured using minimum, maxi-
mum, average reward, and average episode duration
metrics.
We had to deal with different challenges, such as
the ML agent learning to move towards the ball, kick
towards the opponent’s goal to score a positive re-
ward, defend our goal from the opponent, and others.
Therefore, we recommend that an ML agent learns in
a gradual order.
We obtained the best results in this game using the
’PPO + Curriculum B’, executing its training in just 2
hours. We also found a better recommendation set of
hyperparameters than Ray’s example.
Unfortunately, despite the hyperparameters rec-
ommended by Saenz (S
´
aenz Imbacu
´
an, 2021) for
these methods, we did not achieve convergence for
SAC experiments, as Ray’s API returned an error
message for some parameters like buffer init steps,
init entcoef, save replay buffer, steps per update.
So, we did not show SAC results in this paper.
Next time, we will reproduce the Saenz
(S
´
aenz Imbacu
´
an, 2021) research using our hy-
perparameters recommendations as to future work.
We also want to discover the recommended settings
for SAC with Ray API for this game and continue
evolving the Curriculum B strategy.
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
632

ACKNOWLEDGEMENTS
We would like to thank the CEIA/UFG professors for
providing the game environment and support in the
Reinforcement Learning course.
REFERENCES
Achiam, J. (2018). Openai spinning up. GitHub, GitHub
repository.
Albuainain, A. R. and Gatzoulis, C. (2020). Reinforcement
learning for physics-based competitive games. In
2020 International Conference on Innovation and In-
telligence for Informatics, Computing and Technolo-
gies (3ICT), pages 1–6. IEEE.
Bengio, Y., Louradour, J., Collobert, R., and Weston, J.
(2009). Curriculum learning. In Proceedings of
the 26th annual international conference on machine
learning, pages 41–48.
Camargo, J. E. and S
´
aenz, R. (2021). Evaluating the impact
of curriculum learning on the training process for an
intelligent agent in a video game. Inteligencia Artifi-
cial, 24(68):1–20.
Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. (2018).
Soft actor-critic: Off-policy maximum entropy deep
reinforcement learning with a stochastic actor. In
International conference on machine learning, pages
1861–1870. PMLR.
Huang, R., Yu, T., Ding, Z., and Zhang, S. (2020). Policy
gradient. In Deep reinforcement learning, pages 161–
212. Springer.
Juliani, A., Berges, V.-P., Teng, E., Cohen, A., Harper, J.,
Elion, C., Goy, C., Gao, Y., Henry, H., Mattar, M.,
et al. (2018). Unity: A general platform for intelligent
agents. arXiv preprint arXiv:1809.02627.
Kaelbling, L. P., Littman, M. L., and Moore, A. W. (1996).
Reinforcement learning: A survey. Journal of artifi-
cial intelligence research, 4:237–285.
Keras, F. (2022). PPO proximal policy optimization.
Lapan, M. (2018). Deep Reinforcement Learning Hands-
On: Apply modern RL methods, with deep Q-
networks, value iteration, policy gradients, TRPO, Al-
phaGo Zero and more. Packt Publishing Ltd.
Majumder, A. (2021). Competitive networks for ai agents.
In Deep Reinforcement Learning in Unity, pages 449–
511. Springer.
Moritz, P., Nishihara, R., Wang, S., Tumanov, A., Liaw, R.,
Liang, E., Elibol, M., Yang, Z., Paul, W., Jordan, M. I.,
et al. (2018). Ray: A distributed framework for emerg-
ing {AI} applications. In 13th USENIX Symposium on
Operating Systems Design and Implementation (OSDI
18), pages 561–577.
Oliveira, B. (2021). A pre-compiled soccer-twos reinforce-
ment learning environment with multi-agent gym-
compatible wrappers and human-friendly visualizers.
https://github.com/bryanoliveira/soccer-twos-env.
Osipov, A. and Petrosian, O. Application of the contract-
structured gradient group learning algorithm for mod-
eling conflict-controlled multi-agent systems.
Ranjitha, M., Nathan, K., and Joseph, L. (2020). Arti-
ficial intelligence algorithms and techniques in the
computation of player-adaptive games. In Journal
of Physics: Conference Series, volume 1427, page
012006. IOP Publishing.
S
´
aenz Imbacu
´
an, R. (2021). Evaluating the impact of cur-
riculum learning on the training process for an intelli-
gent agent in a video game.
Shao, K., Tang, Z., Zhu, Y., Li, N., and Zhao, D. (2019). A
survey of deep reinforcement learning in video games.
arXiv preprint arXiv:1912.10944.
Sutton, R. S. and Barto, A. G. (2018). Reinforcement learn-
ing: An introduction. MIT press.
Tyagi, D. (2021). Reinforcement-learning: Implemen-
tations of deep reinforcement learning algorithms
and benchmarking with pytorch. https://github.com/
deepanshut041/reinforcement-learning.
An ML Agent using the Policy Gradient Method to win a SoccerTwos Game
633
