
Multi-cloud Load Distribution for Three-tier Applications
Adekunbi A. Adewojo
a
and Julian M. Bass
b
University of Salford, The Crescent, Salford, Manchester, U.K.
Keywords:
Cloud Computing, Multi-cloud, Load Balancing, Algorithm, Three-tier Applications.
Abstract:
Web-based business applications commonly experience user request spikes called flash crowds. Flash crowds
in web applications might result in resource failure and/or performance degradation. To alleviate these chal-
lenges, this class of applications would benefit from a targeted load balancer and deployment architecture of
a multi-cloud environment. We propose a decentralised system that effectively distributes the workload of
three-tier web-based business applications using geographical dynamic load balancing to minimise perfor-
mance degradation and improve response time. Our approach improves a dynamic load distribution algorithm
that utilises five carefully selected server metrics to determine the capacity of a server before distributing
requests. Our first experiments compared our algorithm with multi-cloud benchmarks. Secondly, we exper-
imentally evaluated our solution on a multi-cloud test-bed that comprises one private cloud, and two public
clouds. Our experimental evaluation imitated flash crowds by sending varying requests using a standard ex-
ponential benchmark. It simulated resource failure by shutting down virtual machines in some of our chosen
data centres. Then, we carefully measured response times of these various scenarios. Our experimental re-
sults showed that our solution improved application performance by 6.7% during resource failure periods,
4.08% and 20.05% during flash crowd situations when compared to Admission Control and Request Queuing
benchmarks.
1 INTRODUCTION
One of the attractive features of the cloud is its abil-
ity to dynamically expand or shrink the amount of
resources using auto-scaling services. Despite the
ability of cloud to rapidly detect workload changes
and auto-scale, it requires a considerable amount of
time. Experimental research on Virtual Machine
(VM) startup shows that it takes between 50 and 900
seconds to boot up a VM depending on the size,
model, cost and operating systems (Qu et al., 2017).
This delay in start-up often result into performance
degradation and may even result in temporary system
unavailability if it is not well managed.
Web applications commonly suffer from rapid
surges in user requests. The terminology for this com-
mon scenario is flash crowds (Qu et al., 2017); and it
can occur with little or no warning. This sudden burst
of legitimate network activity are usually responsive
to traffic control, and are web traffic type. This is un-
like distributed denial of service attack(DDOS) which
is usually unresponsive to traffic control, and occurs
a
https://orcid.org/0000-0003-1482-3158
b
https://orcid.org/0000-0002-0570-7086
as any traffic type (Wang et al., 2011). In addi-
tion, sudden resource failure can lead to overload or
complete downtime of cloud deployed web applica-
tions. Cloud providers usually mitigate flash crowds
cases by using an auto-scaler to dynamically provi-
sion enough resources. However, because these sit-
uations occur rapidly, the auto-scaler cannot timely
provision enough resources to extenuate this problem.
Therefore, solely relying on auto-scaling services is
not enough to ensure consistent, and exemplary per-
formance of our class of applications. More so, com-
pletely relying on auto-scaling services allows for un-
necessary over-provisioning in preparation for events
such as flash crowds, which is not but at a high cost to
the clients.
Multi-cloud, the use of multiple cloud (Grozev
and Buyya, 2014) avoids over-provisioning of re-
sources, vendor lock-in, availability, and customisa-
tion issues. Multi-cloud deployment has become in-
creasingly popular mainly because of these stated ad-
vantages (Grozev and Buyya, 2014). If properly im-
plemented, the multi-cloud deployment model makes
it a good fit for overcoming flash crowds and re-
source failure. Therefore, multi-cloud load balanc-
ing is recommended to help avoid overload or per-
296
Adewojo, A. and Bass, J.
Multi-cloud Load Distribution for Three-tier Applications.
DOI: 10.5220/0011092100003200
In Proceedings of the 12th International Conference on Cloud Computing and Services Science (CLOSER 2022), pages 296-304
ISBN: 978-989-758-570-8; ISSN: 2184-5042
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

formance degradation caused by resource failure or
flash crowd. The key factor in using multi-cloud de-
ployment model to achieve this goal solely relies on
the configuration and implementation of this solution,
which is the main reason for this research work.
An approach to implement multi-cloud load bal-
ancing is to use a centralised load balancer to dis-
tribute workload among data centres, such as found
in this research (Grozev and Buyya, 2014). Though
this approach allows fine-grained control over traf-
fic, it introduces extra latencies to all requests, which
reduces the benefit of deploying applications across
multi-cloud. However, this approach is suitable when
there is a need for legislative control and specific ge-
ographic routing of requests.
In this paper, we present a solution that comple-
ments and improves the role of auto-scalers for three-
tier web-based applications deployed across multi-
cloud. We follow the monitor-analyse-plan-execute
loop architecture often used by cloud based systems
in our proposed solution (Qu et al., 2017). Our pro-
posed solution implements a decentralised approach
to multi-cloud geographical load balancing. This
ensures consistent high performing web application
while maintaining a predefined service level agree-
ment (SLA).
Furthermore, our solution employs a peer-to-peer
client-server communication protocol to avoid the
overhead incurred by the broadcast protocol used in
similar research (Qu et al., 2017). This proposed so-
lution was implemented and evaluated across our ex-
perimental test-bed – a heterogeneous combination of
one private and two public clouds. We used mainly
response times as our determinant metric for evaluat-
ing performance.
The key contributions of this research are :
1. a decentralised multi-cloud load balancing archi-
tecture that properly distribute the workload of
our chosen class of application across multiple
clouds;
2. an improved communication protocol of multi-
cloud load balancing system; and
3. an implementation and an experimental evalua-
tion of our proposed system using a heteroge-
neous experimental environment.
The rest of this paper is organised as follows. Sec-
tion 2 discusses similar research works and how our
approach differs to already existing research. Section
3 describes what motivated this research work. We
described the multi-cloud deployment model and ap-
plication requirements in Section 4.1. We introduce
and explain our proposed system and its implementa-
tion in Section 4. We evaluate our proposed system
in Section 5 and presents results in Section 6. Finally,
we conclude the paper in Section 7.
2 RELATED WORK
Workload distribution across multi-cloud requires the
use of proven and reliable load distribution tech-
niques. There have been various research aimed
at distributing workload ranging from popular cloud
services to bespoke research services: cloud ser-
vices such as Amazon Web Service (AWS) Route
53 (Amazon, 2021a), and AWS Elastic Load Bal-
ancer (ELB) (Amazon, 2021b); Azure load balancer
(Azure, 2021b) and Azure autoscale; overload man-
agement (Qu et al., 2017); and geographical load bal-
ancing (Grozev and Buyya, 2014).
Cloud services such as ELB load balancer (Ama-
zon, 2021b) can distribute requests to servers in single
or multiple data centres using standard load balancing
techniques and a set threshold. However, this service
can only distribute incoming requests to AWS regions
and not third party data centres. Likewise, Azure
load balancer (Azure, 2021b) and autoscale (Azure,
2021a) can distribute incoming user requests among
servers and data centres owned by Azure alone. These
approaches focus on predicting future workloads and
provisioning enough resources in advance to accom-
modate increased workload. The downside of these
approaches is that they eventually over provision re-
sources in most cases (Qu et al., 2016; Qu et al.,
2017).
Research approaches such as found in (Gandhi
et al., 2014; de Paula Junior et al., 2015) reactively
provision resources after they detect increased incom-
ing requests or when a set threshold has been met.
Furthermore, a similar approach (Qu et al., 2016) pro-
posed the use of spot instances and over-provision of
application instances to combat terminations of spot
instances and improve workload distribution. How-
ever, because resource failures and flash crowds are
often unpredictable, it takes the auto-scaler consid-
erable time to provision new resources. Also, it is
even more difficult to consistently and evenly dis-
tribute load irrespective of an overload or resource
failure. Therefore, we argue that it is beneficial to
support and improve an auto-scaler to be able to han-
dle situations such as overload and resource failure
more effectively.
Researchers (Niu et al., 2015; Javadi et al., 2012)
have also used the concept of cloudburst (Ali-Eldin
et al., 2014); “the ability to dynamically provi-
sion cloud resources to accelerate execution or han-
dle flash crowds when a local facility is saturated,”
Multi-cloud Load Distribution for Three-tier Applications
297

to combat overload and manage increasing user re-
quests.
Grozev (Grozev and Buyya, 2014) proposed an
adaptive, geographical, dynamic and reactive re-
source provisioning and load distribution algorithms
to improve response delays without violating legisla-
tive and regulatory requirements. This approach dis-
patches users to cloud data centres using the concept
of an entry point of an application framework and a
centralised solution.
Qu and Calherios (Qu et al., 2017) adopted a
decentralised architecture composed of individual
load balancing agents to handle overloads that occur
within a data centre by distributing excess incoming
requests to cloud data centres with unused capaci-
ties. Their approach is composed of individual load
balancing agents that communicates using the broad-
cast protocol to balance extra load. They aimed to
complement the role of an auto-scaler, reduce over-
provisioning in data centres, and detect short-term
overload situations caused by flash crowds and re-
source failure through the use of geographical load
balancing and admission control, so that performance
degradation is minimized.
Our approach is different from the above-
mentioned approaches. Even though we adopt a de-
centralised architecture as implemented by (Qu et al.,
2017), we do not use load balancing agents, because
we want to limit the amount of network broadcast.
Furthermore, we argue that we do not need to wait
for an overload before distributing requests and, so
we aim to consistently distribute workload of cloud
deployed web-based three-tier applications instead of
combating overloads only. Our framework exempli-
fies a high availability cloud deployment architecture
with peer-to-peer client server communication pro-
tocol on an experimental test-bed which comprises
three heterogeneous cloud data centres.
3 MOTIVATION AND USE CASE
SCENARIOS
The use of multi-cloud can reduce cost and improve
resource usage without affecting quality of service
(QoS) rendered. In addition, it is common to be
able to estimate and plan for traffic spikes, but when
the unplanned traffic spikes occur, we need a mecha-
nism to efficiently handle them. Our proposed system
improves existing research by (Grozev and Buyya,
2014) and (Qu et al., 2017). It uses the concept of
geographical load balancing, dynamic load balanc-
ing technique and an improved communication proto-
col to evenly distribute workload of web application
across multi-cloud.
Our solution will be useful for the following sce-
narios that commonly affect our chosen class of ap-
plications:
• Flash Crowds: Flash crowds are unexpected,
rapid request surges that commonly occur in web
applications (Le et al., 2007; Wang et al., 2011;
Ari et al., 2003). They are difficult to manage by
only auto-scalers due to their bursty nature. Com-
mercial techniques for handling this scenario is
to provision resources after the detection of ap-
plication overload. Our proposed solution com-
plements auto-scalers by re-distributing requests
to available data centres to reduce the occurrence
of provisioning new resources and waiting times
during resource provisioning when it is necessary
to do so.
• Resource Failure : Cloud resource failure is a sit-
uation where any of the components in any cloud
computing environment experience drastic fail-
ure. The three most common resource failures
in any cloud environment are hardware, virtual
machines, and application failures (Priyadarsini
and Arockiam, 2013; Prathiba and Sowvarnica,
2017). Resource failures can happen any time,
and can cause performance degradation during re-
source provisioning if the resource loss is beyond
the locally unused resource capacity. Our solu-
tion implements a periodic health check to detect
all types of failures. Our load balancing service
recalculates weights of VM and checks available
capacity on a regular basis and if a failure happens
before the check, a recalculation is done immedi-
ately to properly distribute requests both within
the data centre and across all data centres to avoid
performance degradation.
4 METHODOLOGY
4.1 Deployment Model and Application
Requirements
Our target applications are three-tier web-based busi-
ness applications across multi-cloud. In addition, to
support request forwarding, the application instance
in each data centre should be able to communicate
with instances deployed in other data centres. We
adopt an approach that requires session continuity and
data locality to support processing of requests by ap-
plication replicas deployed across multiple cloud.
Session continuity ensures uninterrupted service
experience to the user, regardless of changes to the
CLOSER 2022 - 12th International Conference on Cloud Computing and Services Science
298

server or equipment’s IP address. Stateless applica-
tions, such as search engines and applications that
utilises web services to achieve statelessness, does not
save client data generated in one session for use in the
next session with that client. This and other properties
of stateless applications implicitly satisfy the require-
ment of session continuity.
Data locality ensures that data resides close to the
system it supports. In the context of our research,
data locality means data should be replicated across
multi-cloud, since requests can only be forwarded to
data centres with available data. To corroborate this
concept for our proposed system, (Grozev and Buyya,
2014) supports data replication for multi-cloud appli-
cations because it is a key to good performance (Ja-
cob et al., 2008; Henderson et al., 2015), and thus,
improves applicability of our approach.
4.2 Deployment Architecture
We present our decentralised architectural design in
Figure 1. This decentralised architectural design fea-
tures a dynamic load balancing algorithm and tech-
nique proposed by (Adewojo and Bass, 2022) and
forms part of our multi-cloud load balancing service.
We deploy our load balancing service (LBS) as an ex-
tra layer of component that augments the three-tier
architecture. Each LBS is deployed alongside our ap-
plication in the same data centre; this helps to reduce
latency in detecting workload requests. The services
are connected to each other through a virtual private
network to ensure communication. Each LBS consist
of monitoring, controller, and communication mod-
ules. The monitoring module constantly monitors in-
coming requests and the status of available resources
to detect resource failures, increased workload, appli-
cation, or server workload. The controller module is
used to modify the weight of each VM to accommo-
date request workload. The communication module
communicates the capacity and status of each data
centre.
4.3 Load Distribution Algorithm
To detect and overcome overload, and resource fail-
ures, we use key server metrics of an applica-
tion server to determine the state of our application
servers. The original algorithm by (Adewojo and
Bass, 2022) implements a unique weighting tech-
nique that combines five carefully selected server
metrics utilisation (CPU, Memory, Bandwidth, Net-
work Buffer and thread count) to compute the weight
of a VM. Our solution improves the algorithm by in-
cluding the calculated weight of each data centre that
will be used in load distribution and the network la-
tencies between data centres.
To calculate the weight of each data centre, we use
the definition of a real-time load Lr(X
k
) as described
by (Adewojo and Bass, 2022) to calculate the weight
of each data centre, as shown in equation (1).
W (DC
i
) =
∑
1
Lr(X
k
)
n
(1)
We abstract our novel multi-cloud load balancing
algorithm in Algorithm 1. The first step in the al-
gorithm is to receive and set an overall threshold for
the input parameters. The values for these thresholds
and how they were calculated can be found in (Ade-
wojo and Bass, 2022). The algorithm loops through
a list of VMs and compares each utilisation values
against the set threshold. The weight of each VM is
then computed and assigned to VMs as described in
(Adewojo and Bass, 2022). The algorithm in line 5
further loops through all remote data centres and cal-
culate the weight of each data centre using equation
(1). Line 7 assigns the weight of each data centre. If
a VM or data centre cannot accommodate any more
requests, it sets the weight to zero. The requests are
then assigned to servers and data centres based on the
assigned weights, as shown in Line 9.
We use the network latency between data centres
to determine the nearest data centre to route requests,
as shown in line 9 in the algorithm.
The input parameters of the algorithm are:
• T h
c
—CPU threshold;
• T h
r
—RAM threshold;
• T h
bw
—Bandwidth threshold;
• T h
tc
—Thread count threshold;
• V M
as
—list of currently deployed application
server VMs;
• V M
dc
—list of currently deployed application
server VMs per remote data centre;
• clouds—list of participating remote data centres;
• L
i
—Latency to the ith data centre from the for-
warding data centre
4.4 Communication Protocol
We deployed our load balancing solution on each par-
ticipating data centre. They communicate with each
other using a peer-to-peer client-server communica-
tion protocol, as depicted in Figure 1. Each solution
relays its system state to another solution in a differ-
ent data centre at a regular predefined time interval
Multi-cloud Load Distribution for Three-tier Applications
299
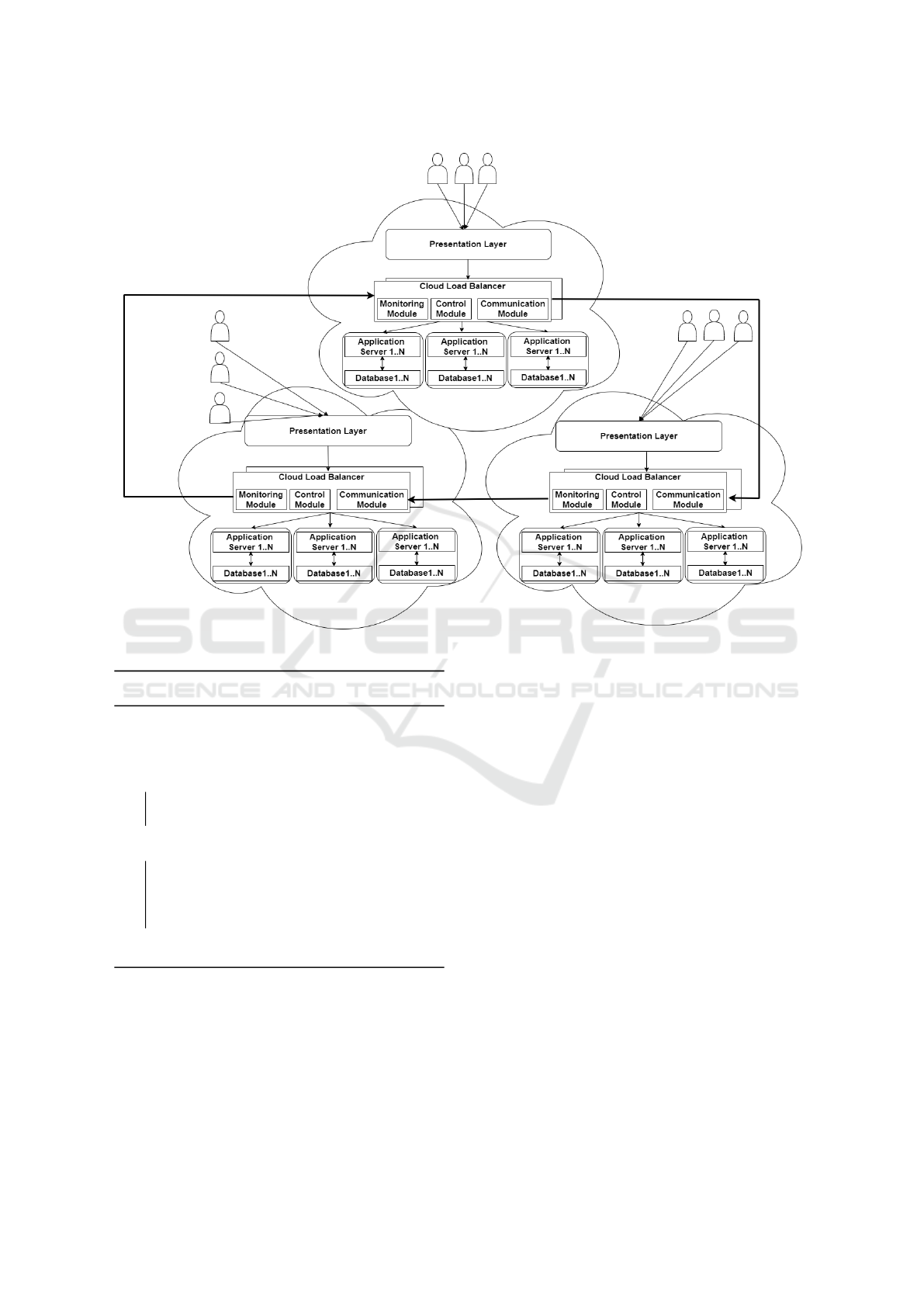
Figure 1: Load Balancing Deployment Architecture.
Algorithm 1: Multi-Cloud Request Handling Algo-
rithm.
Input: s
i
, T hc, Thr, T hbw, T h
t
r, V M
as
, V M
dc
,
L
i
1 RetrieveAllocateToInputAllThresholdValues
();
2 for each VM, vm
i
∈ V M
as
do
3 assignweighttoVM (vm
i
, W(X
k
)) according
to (Adewojo and Bass, 2022);
4 end
5 for each cloud, vm
j
∈ V M
dc
do
6 W (DC
k
) ←
CalculateWeightofDataCentre (Lr
k
,VM
dc
, vm
j
);
7 assignweighttoDC (vm
dc
, W(DC
k
));
8 end
9 HAProxyAssignRequest (s
i
, VM ∈ clouds, L
i
)
of two seconds and every time the load balancer dis-
tributes workload. Each communicated system’s state
always comprises the originated state and the states of
the peered system. This chosen mode of communica-
tion protocol help to reduce network overhead asso-
ciated with node communication by only broadcast-
ing to the peered node. It provides significantly better
spatial reuse characteristics, irrespective of the num-
ber of nodes. As the number of nodes increase sig-
nificantly, there might be slight degradation in perfor-
mance, but the advantages definitely outweighs this
drawback.
4.5 Algorithm Implementation and
Deployment
We implemented our algorithm as a separate pro-
gram that ties into a state-of-the-art load balancer,
HAProxy 2.4.2-1. We created a separate program be-
cause HAProxy does not support complex configura-
tions featured in our algorithm. We colocated our pro-
gram with the HAProxy load balancer to reduce net-
work latency. We used HAProxy’s health monitor to
monitor the performance indicators and VM’s health
every 2000ms.
Our program’s monitoring module periodi-
cally fetches required monitored information using
HAProxy’s stats application programming interface
(API). Then it extracts and manipulates performance
values and health statuses of attached VM, and passes
them to our control module. The control module
activates our algorithm to determine the weight of
CLOSER 2022 - 12th International Conference on Cloud Computing and Services Science
300
each VM and data centre. The control module passes
the weights to the load balancer and also updates the
communication module.
We implement request distribution and admission
control by dynamically changing HAProxy’s config-
uration. When required, the control module dynam-
ically creates a new configuration file for HAProxy
during runtime. This process automatically reloads
the new configuration to the running HAProxy load
balancer, then the load balancer distributes requests
among the data centre.
To activate request forwarding, each new con-
figuration file contains the IP addresses of the load
balancers located in other participating data centres
and represents them as normal servers with individual
weights. Our program assigns weight to each server.
The assigned weight will determine the amount of
requests that can be distributed across data centres
and VMs in each data centre. HAProxy then uses
the weighted round-robin algorithm to distribute re-
quests.
We implement admission control using the Access
Control List (ACL) mechanism of HAProxy. We use
HAProxy’s customised default page to inform users
of delay when there is a surge in user requests that
consequently affect response times.
5 PERFORMANCE EVALUATION
5.1 Case Study Application
Our case study application is a three-tier stateless E-
commerce application that was built using Orchard
core framework. We used Elastic search to imple-
ment its search engine, the main focus of our exper-
iment. The application consist of a data layer that
runs MySQL database loaded with similar products
that can be found on eBay; a domain layer that im-
plements buying and selling of products, and a web
interface where users can search for products.
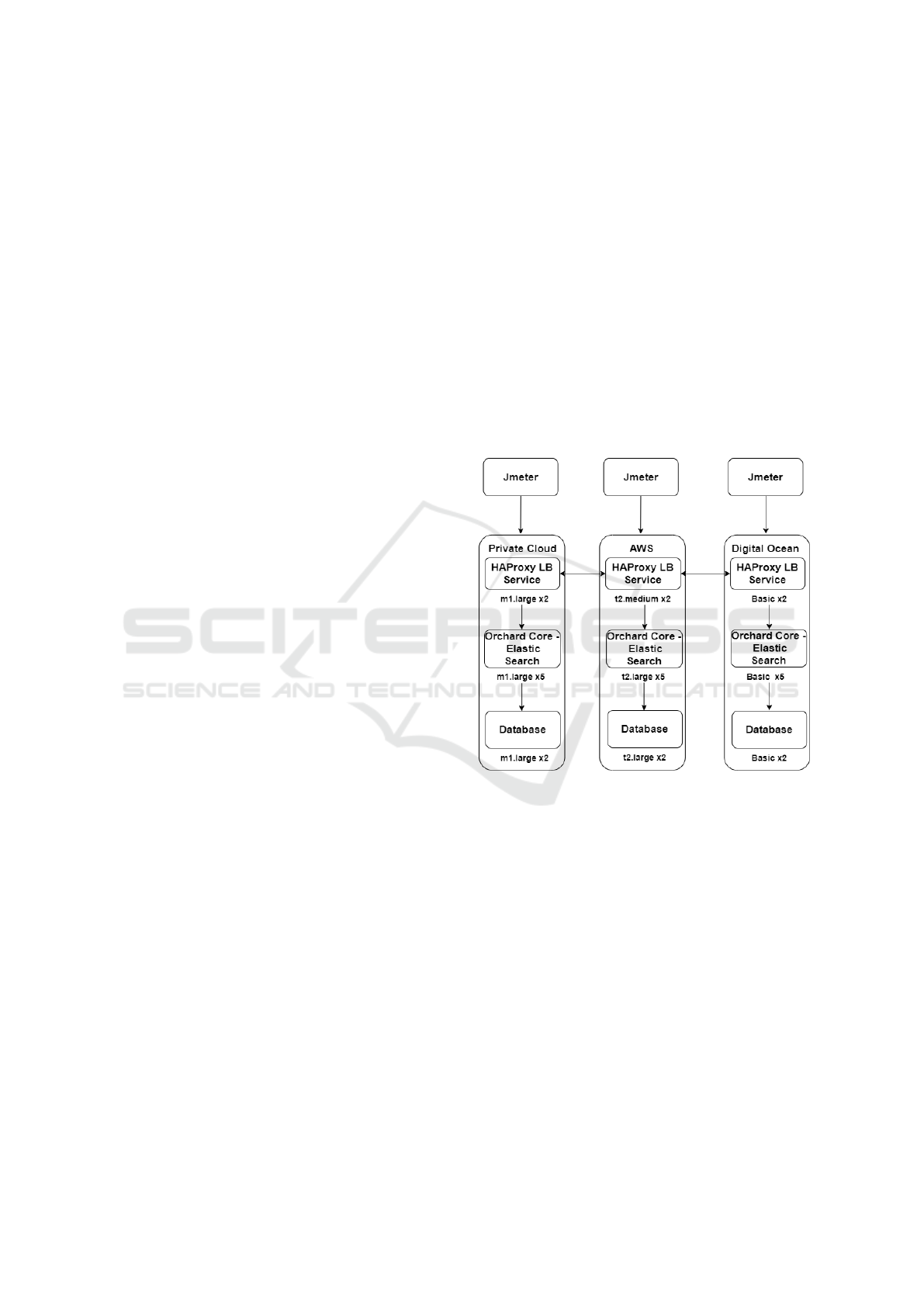
5.2 Experimental Test-bed
Our experimental results are the average of 5 repeated
experiments over a 24-hour period. Our experimental
test-bed consists of 3 heterogeneous data centres; a
private cloud running OpenStack, located in London,
Amazon Web Service located in Tokyo: ap-northeast-
1a, and DigitalOcean located in New York. It is il-
lustrated in Figure 2. Each data centre consists of
nine heterogeneous VMs. The private cloud had VMs
with 4 and 8 VCPUs, 4GB and 8GB RAM, 40GB and
80GB disk size. AWS had VMs with 2 VCPUs, 4GB
and 8GB RAM, and 20GB disk size. DigitalOCean
had VMs with 2 VCPUs, 4GB RAM and 80GB disk
size. We measured and recorded the Round-trip Time
(RTT) latencies between the data centres using ping.
The RTT are: London-Tokyo-London : 1.68ms and
London-New York-London: 240.53ms.
In each data centre, we deployed HAProxy server
along with our load balancing algorithm on two VMs;
one VM acts as a standby, depicting a high availabil-
ity architecture. We deployed our application servers
on five VMs and database servers on two VMs. Fur-
thermore, we deploy a standard auto-scaler on each
data centre. In order to simulate real user request and
location, we deployed Apache Jmeter (our workload
simulator) on an external standalone machine with 4-
core, Intel Core i7, 2.8GHz CPU and 8Gigabit Ether-
net NIC.
Figure 2: Experimental Test-bed.
5.3 Workload
To implement our profiling test, we sent e-commerce
search requests using Jmeter to our cloud deployed
applications. Firstly, we stipulated that 90% of re-
quests should be replied within 1 second. Secondly,
we performed tests to determine the average requests
that each class of our application servers can handle
without violating the SLA. We created workloads us-
ing the proposed workload model by (Bahga et al.,
2011).
Based on this workload model, we created three
workloads for the three data centres using parameters
stated in Table 1. The average of the largest amount
of requests that can be handled by the application
servers are 80 (private cloud), 65 (DigitalOcean) and
45 (AWS) requests/s.
Multi-cloud Load Distribution for Three-tier Applications
301
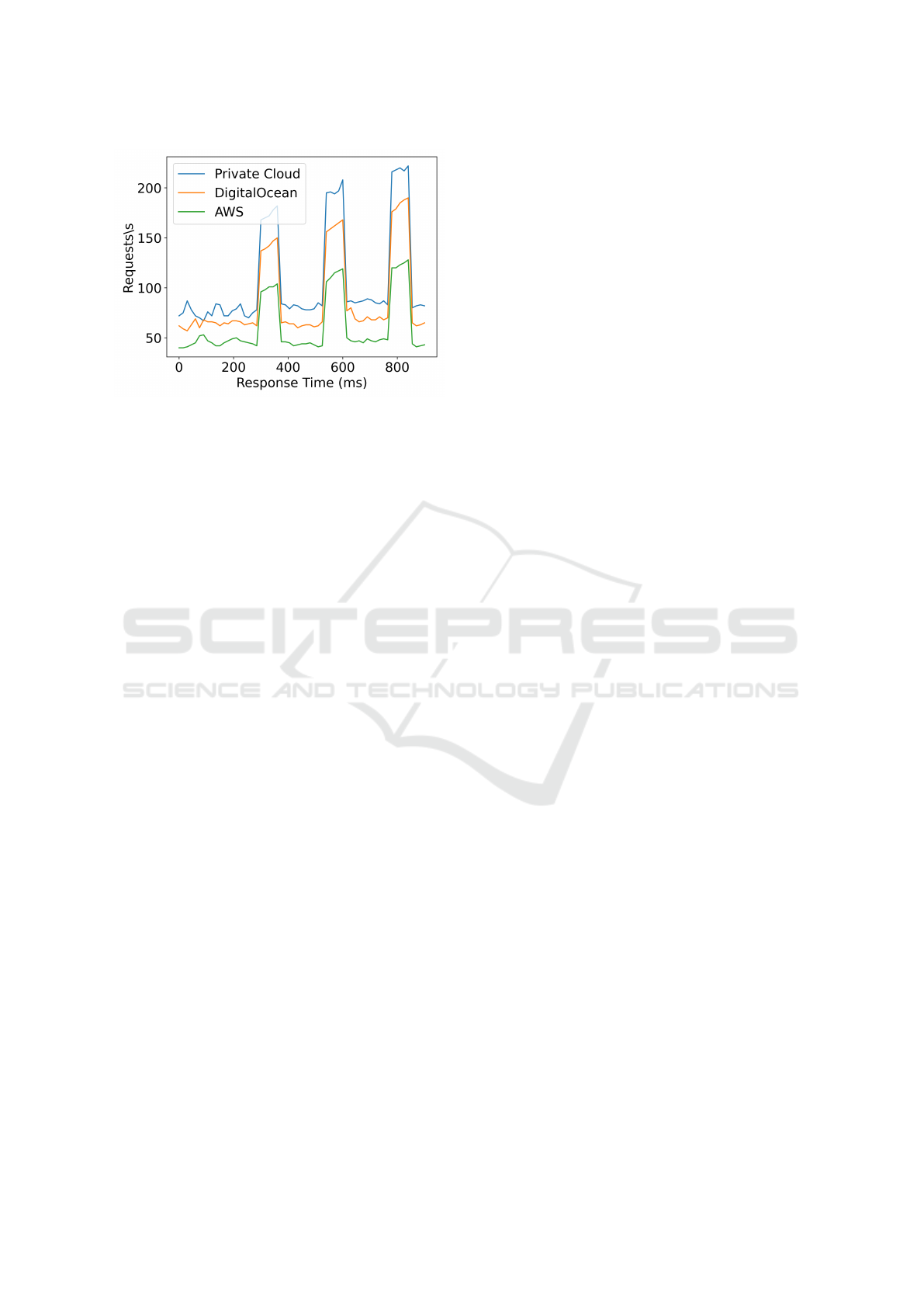
Figure 3: Experimental Workloads with flash crowds rang-
ing from 110% to 190% of the normal load.
To simulate flash crowd, we created two extra
workloads with increased requests, as shown in Fig-
ure 3. Each workload experiences a total of three sec-
onds flash crowds within a period of 1 minute. The
peak of the flash crowd range from 110% to 190%
of the normal workload. The experiment experiences
flash crowds starting from 300ms time point in any
time frame.
To test our approach when there is resource fail-
ure, we ramped up average incoming requests to 240
requests/s, representing the highest bound of our nor-
mal workload. Starting from 300ms, we simulate re-
source failure that lasts for 300ms, this also experi-
ences a total of three seconds resource failure within
1 minute interval.
5.4 Benchmarks
To validate and compare the performance of our solu-
tion, we benchmark our results with the following:
• Request Queuing: This benchmark process
queues up all requests in the local servers, im-
poses no admission control, does no geographi-
cal balancing, and uses just the round-robin al-
gorithm. This imitates the situation that an auto-
scaler is booting a new VM within a data centre.
• Admission control: This benchmark process di-
rectly imposes admission control when distribut-
ing requests. It lets the load balancer redirect re-
quests at first and if there is no capacity to accept
the redirected requests, it sends a message to users
to tell them they are in a queue.
6 RESULTS
6.1 Resource Failures
To test resource failures, we removed some VMs from
the load balancer pool at 300ms time point and added
them back to the pool after 5 seconds to imitate re-
covery from failure. We repeated this experiment for
each of the data centres such that we simulated re-
source failure for each data centre. We also conducted
more experiments where resource failures occurred in
combinations of the data centres.
Figure 4 showed performance of the system dur-
ing one server failure. It showed that without our ap-
proach, all data centres would not maintain the de-
fined SLA. Furthermore, the other approaches exhib-
ited higher response times, which indicated perfor-
mance degradation. This same characteristics were
exhibited in two server failures scenarios; we per-
formed the test on a combination of all participating
clouds. They all could not attend to 90% of requests
at a lesser response times compared to our approach.
Figure 5 shows the performance of our algorithm
and the benchmarks when there were three VM fail-
ures. This approach made the data centres become
unresponsive, unlike our novel approach that was still
able to maintain defined SLA even though the re-
sponse time was high. In summation, our approach
outperformed the response times of both admission
control and request queuing benchmark by 6.7%.
This means our approach can handle more workload
with an acceptable response time during server failure
scenarios.
6.2 Flash Crowds
We tested our approach by simulating flash crowds
in each of the data centres. Figure 6 shows how
our approach and benchmarks performed under flash
crowds. Our experiments showed that our approach
outperformed our benchmarks at every instance of
flash crowds. We recorded an improvement in the per-
centage of requests handled. Our approach improved
response times by 4.08% and 20.05% relatively to ad-
mission control and request queuing benchmarks, re-
spectively. This confirms that our solution can con-
sistently distribute the request of our class of applica-
tions even during flash crowds. We note that the size
of the VM also determines the performance, we be-
lieve a better optimised VM for web applications will
offer a lesser response times if it is coupled with our
solution.
CLOSER 2022 - 12th International Conference on Cloud Computing and Services Science
302

Table 1: Workload Parameter.
Mean Min Max Deviation
ThinkTime 4000 100 20000 2
Intersession Interval 3000 100 15000 2
Session Length 10 5 50 2
(a) 1 Server Failure in Private Cloud. (b) 1 Server Failure in DigitalOcean. (c) 1 Server Failure in AWS.
Figure 4: Cumulative Distribution Values of One Server Failure.
Figure 5: Three Server Failures.
7 CONCLUSIONS AND FUTURE
WORK
Cloud deployed web-based applications commonly
experience flash crowds that might result in resource
failure and/or performance degradation. To resolve
this problem, we proposed a multi-cloud decen-
tralised load balancing system.This system effectively
distributes the workload of this class of applications
using geographical dynamic load balancing to min-
imise performance degradation and improve response
time. Our approach deployed our load balancing solu-
tion in each data centre for quick sensing of overload
and resource failure occurrence. Our load balancing
solution comprises HAProxy and an improved novel
load balancing algorithm (that utilises five carefully
selected server metrics to determine the real-time load
of VMs) to include multi-cloud weighting and request
distribution.
We implemented and evaluated our algorithm
across a private cloud located in London running
OpenStack, AWS located in Asia data centre and Dig-
italOcean in US data centre. We validated our al-
gorithm by comparing it to two benchmarks; request
queuing and standard admission control methods. To
test the applicability of our solution, we simulated
flash crowds and resource failures using our experi-
mental tools to send requests spikes and remove VMs,
respectively. We carefully measured response times
of our experiments and obtained results showed that
our approach maintained accepted SLA of requests
during flash crowds and resource failure. Further-
more, it improved response times performance by
6.7% during resource contention periods and 4.08%
and 20.05% during flash crowd scenarios when com-
pared with admission control and request queuing, re-
spectively. This validates that our proposed approach
improves the performance of multi-cloud deployed
web-based three-tier application and effectively dis-
tributes the workload of these applications.
In future, we hope to tackle some limitations of
this research. We will consider using domain spe-
cific languages such as Cloud Application Modelling
and Execution Language (CAMEL) to describe our
deployment approach. We also will compare our ap-
proaches with some popular approaches such as the
use of serverless technologies.
Multi-cloud Load Distribution for Three-tier Applications
303

(a) 140 req/s flash crowd. (b) 190 req/s flash crowd. (c) 240 req/s flash crowd.
Figure 6: Cumulative Distribution Values of Flash Crowds using Different Approaches.
REFERENCES
Adewojo, A, A. and Bass, M, J. (2022). A novel weight-
assignment load balancing algorithm for cloud appli-
cations. In 12th International Conference on Cloud
Computing and Services Science, page TBD. IEEE.
Ali-Eldin, A., Seleznjev, O., Sj
¨
ostedt-de Luna, S., Tordsson,
J., and Elmroth, E. (2014). Measuring cloud workload
burstiness. In 2014 IEEE/ACM 7th International Con-
ference on Utility and Cloud Computing, pages 566–
572. IEEE.
Amazon (2021a). Amazon route 53.
Amazon (2021b). Elastic load balancing.
Ari, I., Hong, B., Miller, E. L., Brandt, S. A., and Long,
D. D. (2003). Managing flash crowds on the internet.
In 11th IEEE/ACM International Symposium on Mod-
eling, Analysis and Simulation of Computer Telecom-
munications Systems, 2003. MASCOTS 2003., pages
246–249. IEEE.
Azure, M. (2021a). Azure autoscale — microsoft azure.
Azure, M. (2021b). Load balancer documentation.
Bahga, A., Madisetti, V. K., et al. (2011). Synthetic
workload generation for cloud computing applica-
tions. Journal of Software Engineering and Applica-
tions, 4(07):396.
de Paula Junior, U., Drummond, L. M., de Oliveira, D.,
Frota, Y., and Barbosa, V. C. (2015). Handling flash-
crowd events to improve the performance of web ap-
plications. In Proceedings of the 30th Annual ACM
Symposium on Applied Computing, pages 769–774.
Gandhi, A., Dube, P., Karve, A., Kochut, A., and Zhang, L.
(2014). Adaptive, model-driven autoscaling for cloud
applications. In 11th International Conference on Au-
tonomic Computing ({ICAC} 14), pages 57–64.
Grozev, N. and Buyya, R. (2014). Multi-cloud provisioning
and load distribution for three-tier applications. ACM
Trans. Auton. Adapt. Syst., 9(3):13:1–13:21.
Henderson, T., Michalakes, J., Gokhale, I., and Jha, A.
(2015). Chapter 2 - numerical weather prediction op-
timization. In Reinders, J. and Jeffers, J., editors, High
Performance Parallelism Pearls, pages 7–23. Morgan
Kaufmann, Boston.
Jacob, B., Ng, S. W., and Wang, D. T. (2008). Chapter 3
- management of cache contents. In Jacob, B., Ng,
S. W., and Wang, D. T., editors, Memory Systems,
pages 117–216. Morgan Kaufmann, San Francisco.
Javadi, B., Abawajy, J., and Buyya, R. (2012). Failure-
aware resource provisioning for hybrid cloud infras-
tructure. Journal of parallel and distributed comput-
ing, 72(10):1318–1331.
Le, Q., Zhanikeev, M., and Tanaka, Y. (2007). Methods
of distinguishing flash crowds from spoofed dos at-
tacks. In 2007 Next Generation Internet Networks,
pages 167–173. IEEE.
Niu, Y., Luo, B., Liu, F., Liu, J., and Li, B. (2015).
When hybrid cloud meets flash crowd: Towards cost-
effective service provisioning. In 2015 IEEE Con-
ference on Computer Communications (INFOCOM),
pages 1044–1052. IEEE.
Prathiba, S. and Sowvarnica, S. (2017). Survey of failures
and fault tolerance in cloud. In 2017 2nd International
Conference on Computing and Communications Tech-
nologies (ICCCT), pages 169–172. IEEE.
Priyadarsini, R. J. and Arockiam, L. (2013). Failure man-
agement in cloud: An overview. International Journal
of Advanced Research in Computer and Communica-
tion Engineering, 2(10):2278–1021.
Qu, C., Calheiros, R. N., and Buyya, R. (2016). A reliable
and cost-efficient auto-scaling system for web appli-
cations using heterogeneous spot instances. Journal
of Network and Computer Applications, 65:167–180.
Qu, C., Calheiros, R. N., and Buyya, R. (2017). Mitigating
impact of short-term overload on multi-cloud web ap-
plications through geographical load balancing. con-
currency and computation: practice and experience,
29(12):e4126.
Wang, J., Phan, R. C.-W., Whitley, J. N., and Parish, D. J.
(2011). Ddos attacks traffic and flash crowds traffic
simulation with a hardware test center platform. In
2011 World Congress on Internet Security (WorldCIS-
2011), pages 15–20. IEEE.
CLOSER 2022 - 12th International Conference on Cloud Computing and Services Science
304
