
Data Mining Techniques for Analysing Data Extracted from Serious
Games: A Systematic Literature Review
María-Inés Acosta-Urigüen
1a
, Marcos Orellana
1b
and Priscila Cedillo
1,2 c
1
Laboratorio de Investigación y Desarrollo en Informática - LIDI, Universidad del Azuay, Azuay, Ecuador
2
Universidad de Cuenca, Azuay, Ecuador
Keywords: Data Mining, Serious Games, Systematic Review.
Abstract: Serious games are applications that pursue, on the one hand, the users' entertainment and, on the other hand,
look to promote their learning, cognitive stimulation, among reaching other objectives. Moreover, data
generated from those games (e.g., demographic information, gaming precision, user efficiency) provide
insights helpful in improving certain aspects such as the attention and memory of the gamers. Therefore,
applying data mining techniques over those data allows obtaining multiple patterns to improve the game
interface, identify preferences, discover, predict, train, and stimulate the users' cognitive situation, among
other aspects, to reach the games' objectives. Unfortunately, although several solutions have been addressed
about this topic, no secondary studies have been found to condensate research that uses data mining to extract
patterns from serious games. Thus, this paper presents a Systematic Literature Review (SLR) to extract such
evidence from studies reported between 2001 and 2021. Besides, this SLR aims to answer research questions
involving serious games solutions that train the cognitive functions of their users and data mining techniques
associated with data gathered from those games.
1 INTRODUCTION
Serious games are defined as software applications
developed for an explicit educational purpose
(Hernández et al., 2017). Moreover, the objective of
these games is not primarily intended for fun but is
focused on government or corporate training,
education, health, public policy, and strategic
communication purpose (Hernández et al., 2017).
Moreover, serious games are developed to include
interactive and engaging features. These features can
be collected, extracted, measured, analyzed, and
reported. Gathered data can consider users’ attributes
and behavior, the learning progress, and other
outcomes (Chen et al., 2020; Shoukry et al., 2014).
To process the collected data, the Data Science
field can be applied; here, data mining is the branch
that uses a computer-based methodology that helps to
discover knowledge (Mendoza et al., 2019). Different
techniques are performed in the data mining field,
including classification, regression, clustering,
a
https://orcid.org/0000-0003-4865-2983
b
https://orcid.org/0000-0002-3671-9362
c
https://orcid.org/0000-0002-6787-0655
summarization, association, and anomaly detection
(Petrov et al., 2019).
Here, the classification automatically assigns a
pre-defined category to each variable based on its
attributes (Petrov et al., 2019; Zanasi & Ruini, 2018).
While clustering automatically creates clusters of
variables that share similar characteristics (Petrov et
al., 2019; Zanasi & Ruini, 2018).
Some of these techniques have been implemented
in the area of serious games. For example, Ruiz-Rube
et al. (2013) present two serious games: i) a memory
game that seeks to match photos with audio and text;
ii) a hidden room where the player must situate
objects in their place. Their research aims to apply the
k-means algorithm to detect behavior and preferences
according to the user profile. Clustering techniques
are used, and the results identify errors in the lexicon
with different degrees (low, medium, good). Another
example is a serious game called Enzyme-Linked
Immunosorbent Assay (ELISA), developed by
Simani et al. (2018), whose main contribution is the
220
Acosta-Urigüen, M., Orellana, M. and Cedillo, P.
Data Mining Techniques for Analysing Data Extracted from Serious Games: A Systematic Literature Review.
DOI: 10.5220/0011042900003188
In Proceedings of the 8th International Conference on Information and Communication Technologies for Ageing Well and e-Health (ICT4AWE 2022), pages 220-227
ISBN: 978-989-758-566-1; ISSN: 2184-4984
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

detection of Human Immunodeficiency Viruses
(HIV) through an analysis of peptides, proteins,
antibodies, and hormones. Besides, Benmarkelouf et
al. (2015) implemented a regression and clustering
model to explore the relationships between the
characteristics of the players and their performance
(scores and duration of the game). Features such as
personalization, the existence of groups of players,
and the identification of their characteristics to extract
players’ profiles, were available.
From the previous studies, it can be seen that there
are different data mining techniques implemented in
many areas of knowledge. Thus, several primary
studies have been reported. However, those
contributions are scattered in many scientific sources.
Therefore, it is necessary to search for them when
new research starts and state of the art must be
established. Consequently, this paper presents a
review that summarizes the most used and
implemented data mining techniques, the domain area
where the serious game is developed, and the
collected users’ demographic information is needed.
This study follows the methodology proposed by
Kitchenham et al. (2010) for systematic literature
reviews. A systematic literature review (SLR) is a
document that presents a summary of the most
relevant studies referred to a particular research
question (Kitchenham et al., 2010). Several steps are
proposed in this methodology, making the process
repeatable and auditable.
The obtained results aim to answer “How
research on data science solutions applied to serious
games is taking place,” the research emphasizes data
mining techniques. Following the suggested
methodology, 60 studies were selected and analyzed.
Finally, results provide insights helpful to find gaps
and support researchers in this area.
This paper is organized as follows: Section 2
presents an analysis of the related systematic reviews
in serious games and data mining. Then, Section 3
shows the research method implemented in this
review. Section 4 presents the discussion about the
reviewed literature, while Section 5 includes threats
to validity and their mitigation. Finally, Section 6
concludes the paper and offers the guidelines for
future work.
2 RELATED WORKS
For this review, the main research question focuses
on how data science solutions are applied to data
extracted from serious games. Four reviews related to
this topic were found, but none thoroughly addressed
our research question.
Thus, Alonso-Fernández et al. (2019) presented a
systematic literature review that includes data science
applications to perform game and learning analytics
with data collected from serious games. However, the
original search string did not explicitly have “serious
games”; besides, the authors used three different
search strings. Their study concluded with a summary
of the purpose of data analysis application of the
studies and the data science techniques used in the
selected articles. They also presented a table with the
algorithms and procedures generally, only
mentioning the concepts but not a specific number of
studies implemented.
Massa & Küh (2018) present a review based on
the methodology proposed by Kitchenham (2010).
Their study is oriented to data analytics in serious
games. It aims to identify the solutions on learning
analytics, the type of serious game (commercial or
non-commercial), and the methodologies and tools
for implementing learning analytics. However, their
main research question was related to learning
analytics, fun, and implementations. Although the
review was based on serious games, it did not include
any topic related to data science, such as:
methodologies, algorithms, or techniques. Besides, it
only addresses the benefits of integrating “big data”
into the solution, but the authors do not emphasize the
process. Then, in a systematic review, Ravyse et al.
(2017) analyzed the success factors that enhance
learning when applying serious games. The authors
focused on presenting the practical guidelines that
serious game producers could incorporate to
guarantee successful learning with fun. Among those
are the plot, the narrative of the game, the audio-
visual techniques, and graphics. In addition, the work
presented which artificial intelligence techniques are
used to improve fun and learning experiences and
convert player information into personalized
responses but did not include an explanation of the
types of methods used.
Finally, Wang & Huang (2021) developed a
systematic review of the design of serious games for
collaborative learning. The design aspect is the most
relevant topic analyzed. They indicated that few
studies had implemented a data mining method on
game logs, but they did not present details about it.
Although there are some similarities between the
previously described contributions and this
systematic literature review, the main difference is
that this study is mainly focused on how serious
games are addressed in data science, considering the
methodology, algorithms, game mode, and data
Data Mining Techniques for Analysing Data Extracted from Serious Games: A Systematic Literature Review
221

storage. Besides, this review includes demographic
users’ information, such as age, score, and
interaction. Another significant difference relies on
the libraries and indexers selected to extract scientific
articles and the search strategy.
3 RESEARCH METHOD
According to Kitchenham (2010), an SLR consists of
collecting, organizing, evaluating, and interpreting
the information related to a specific Research
Question (RQ) about an area or phenomenon of
interest. Then, Kitchenham proposes a methodology
based on three steps: 1) Planning the SLR, 2)
Conducting the SLR, 3) Reporting the results.
3.1 Planning the SLR
The planning stage consists of establishing the
research questions and sub-questions, the search
strategy, the selection of primary and secondary
studies, and its extraction criteria. Also, it includes a
quality assessment procedure to validate the review.
3.1.1 Research Questions
Research questions are the most relevant part of the
SLR. They allow finding relevant data and
transforming the systematic literature review into a
contribution to the research (Kitchenham et al.,
2010). Here, two main aspects have been considered:
serious games and data science.
The terms “learning analytics”, “data mining” and
“big data” were also included. Learning analytics and
educational data mining sometimes are used
interchangeably (Alonso-Fernández et al., 2019),
while “big data” refers to data sets whose size and/or
complexity can be effectively exploited by using data
science techniques (Zanasi & Ruini, 2018).
The main question is “how research on data
science solutions applied to serious games is taking
place”. The four research sub-questions are: RQ1:
What kind of information is required to analyze
serious games? RQ2: How are serious games
approached in data science? RQ3:
In which
development area are serious games applied?
RQ4 How is
the investigation and its scope?
3.1.2 Search Process
It is necessary to select the sources to obtain the
articles to be considered for this review. Therefore,
international conferences about serious games, digital
libraries, and indexed electronic databases were
considered. Those are ACM-Digital Library, IEEE
Xplore, Springer Link, Science Direct, EBSCO,
Taylor & Francis, Hinari (OARE), Web of Science,
and SCOPUS. Likewise, three international
conferences were included: International Conference
on Serious Games and Game-Based Learning,
International Conference on Serious Games and
Applications for Health, and International
Conference on Gamification & Serious Game.
The search string was developed using four
groups of keywords according to the research scope.
Groups of keywords were defined as “data science”,
“big data”, “data mining” and “serious games.” The
final string used in the search engines was (“Data
mining OR “Big data” OR “Data Science”) AND
(“serious games”). The considered period of the
publications was from the first peer-reviewed
academic journal dedicated to computer game
studies, published in 2001 (Wilkinson, 2016).
3.1.3 Exclusion and Inclusion Criteria
A process of selection was applied to the obtained
articles. It included a preliminary reading of the title,
keywords, and the abstract of each piece to evaluate
if they respond to the established RQs.
With this new group of papers, the following
inclusion criteria were considered: i) papers
describing the application of data science in serious
games; ii) papers describing data mining techniques
to serious games; iii) articles describing methods for
data science oriented to serious games. An article
must to be related to both of the research topics
“serious games” and “data mining”.
The exclusion criteria are: i) duplicate articles
from the same study in different sources; ii)
introductory documents for special issues, books, and
workshops; iii) articles that are not written in the
English language; iv) articles that are only available
as presentations, abstracts, v) incomplete articles
without research design such as workshops, surveys
or without well-defined research questions, vi)
publications that have not undergone a formal review
process or technical reports; and, vii) short articles
with less than five pages.
3.1.4 Quality Assessment
To evaluate the found articles, a group of questions
were proposed. These questions allowed the
classification of their quality, by assigned points
based on the answer to said questions. The questions
formulated along with their proposed answers are
represented in Table 1.
ICT4AWE 2022 - 8th International Conference on Information and Communication Technologies for Ageing Well and e-Health
222

Table 1: Quality assessment.
# Question Answer and score
QA1
Does the study
present topics
about data science
in serious
g
ames?
Agree (+1)
Partially (0)
Disagree (-1)
QA2
Has the study
been published in
a relevant journal
or conference
(Scimago Journal
& Country
Ran
k
)
?
Very relevant (+1)
Relevant (0)
Not relevant (-1)
QA3
Has the study
been cited by
other authors?
Yes, more than 5 (+1)
Partially, from 1 to 5 (0)
No, it has not (-1)
The quality assessment has to be applied to each
article, so that its quality and scientific relevance can
be identified. Also, the Fleiss’ Kappa measure was
calculated. It obtains the agreement among raters,
assigning a coefficient evaluated through a matrix of
ranges and equivalences (McHugh, 2012).
3.2 Conducting the Systematic
Literature Review
All metadata of each article were extracted. Then, a
matrix to organize the information was created with
the research questions and sub-questions that
represent the main features to be considered in this
SRL. From the repository, Table two shows the
number of articles that respond to each extraction
criterion, the percentage in relation to the total of
selected articles and one or more references. For
example, the EC1 looks for the deployment location,
where a console, an app, a website, or other location
is considered. 52 articles answer this EC, but they can
mention more than one answer, for examine the game
can be deployed in an app and over the web.
In the next step, a full paper lecture of each article
is performed to complete the matrix above. For
achieving, a binary qualifier (1,0) was used to
indicate the presence or absence of that feature. This
matrix is used to analyze the contents and measure the
articles’ quality assessment.
3.3 Reporting the Results
This subsection presents the results of the SLR. It is
divided into two phases.
3.3.1 Search Results
The articles were retrieved from the sources
mentioned in 3.1.2; each article was read to evaluate
if it satisfies the inclusion and exclusion criteria
described in section 3.1.3. A total of 591 articles were
retrieved, 57 articles were published in more than one
database, so they were excluded.
The title, abstract, and keywords of the remaining
534 articles were reviewed; the number of citations
and the article’s publication date were also
considered. Each RQ was evaluated, and if the article
answered at least one criterion (EC), information was
extracted and registered into the matrix; otherwise,
the article was rejected. A total of 60 articles was
selected for a complete reading and extraction of
RQs. Figure 1 presents the entire process. Figures,
tables and appendixes are stored in a repository
available at https://bit.ly/3oQpQZy.
3.3.2 Assessing the Quality
For the quality of each article, three questions were
evaluated per article, and the statistical measure
Fleiss’ Kappa was calculated.
Three different research team members read each
article, applied the inclusion and exclusion criteria,
read and answered the RQs. The reading for at least
three members is mandatory since it is the minimum
to construct the Fleiss’ Kappa measure.
The Fleiss' Kappa indicator measures the level of
agreement between 3 or more reviewers of the
articles. To calculate it, 5 articles of the 60 were
selected; a value of 0.61 was obtained. According to
the table of ranges (Nichols et al., 2010), a moderate
level of agreement is evidenced.
Table 3 presents the questions and the percentage
obtained. Again, it is remarkable that the averages for
the topic and the journal’s relevance are over the
mean.
4 DISCUSSION
This section focuses on presenting the main findings
obtained from the extraction matrix. Aspects of data
mining, their techniques, and algorithms have been
considered. Appendix 1 shows the list of selected
articles, and Appendix 2 presents the number of
articles that answer each RQ and their percentage.
RQ1 has eight extraction criteria. In EC1, it can
be seen that APP is the most common deployment
location (50%), followed by the Web (28.85%), only
21.15% of serious games are implemented by
consoles. EC2 presents the results for deployment
platforms, where computers are the most used devices
with 62,50%, while telephones and tablets show
lower percentages of 21,43% and 16,07%,
Data Mining Techniques for Analysing Data Extracted from Serious Games: A Systematic Literature Review
223

respectively. These scores show the need to develop
serious games compatible with various deployment
locations and different devices. EC3 presents the
study area where Education (64,91%), a field where
most serious games are developed. Health is another
area that catches the attention of an influential
audience (22,81%). Business and other areas
represent less than 13%. Age is analyzed in EC4,
where most games are aimed at adults (63.41%) and
a small percentage for children (36.59%). There are
no articles that show that data science techniques
have been applied in serious games aimed at older
adults. There are no articles that show that data
science techniques have been applied in serious
games aimed at older adults. Recollecting and
analysing data from this age group applying data
science is considered an untapped area at the moment.
EC5 presents programs as the most used development
tool (62.50%). 37.51% of articles present
methodologies, and only one article presents a
framework (1.79%). EC6 features single-player
games with the highest percentage (50%), followed
by multiplayer games (21.05%). If the game presents
scores, it is analyzed in EC7. Most do not, with
55.32%, 44.68% shows a positive answer. Scores,
ages, and other options are used to classify users in
EC8. Scores represent the most common manner with
80%.
RQ2 presents different data science techniques
applied to serious games. EC9 Present Sampling as
the most used data preprocessing technique with
91%. Decision trees (35%) and Bayesian networks
(30%) are the most used classification techniques in
EC10. SVM represents 13%, KNN and ANN are the
remaining 4%. Clustering techniques are analyzed in
EC11. K-means has the highest percentage (81.25%),
hierarchical message passing represents 12.50%, and
density-based only 6.25%. Few articles include the
data storage technique in EC12; 2 uses JSON; and 3,
SQL. This fact of not including the data storage
procedure limits the possibility of identifying the best
way to apply data science.
In RQ3, EC13 identifies academia as where most
serious games are developed (64.91%). 21.05%
covers the Medicine area. This fact shows that serious
games are a current line of research in academia.
EC14 presents the evaluation of the serious game.
Analysis (40.60%) and tests (31.3%) are the most
developed evaluations; only 28.1% focus on
implementation, but none on design.
RQ4 presents the topics related to research. The
validation is analyzed in EC15. Controlled
experiments are the most frequent manner of
validation (57%), followed by proof of concepts
(25%) and case studies (19%). The most
representative area of development is the academy,
with 85.45%. The industry registers 14.55% in EC16.
Finally, EC17 presents the study continuity, where
55.36% are new researches, and44.64% are
continuations.
The most relevant findings for this SLR are
related to demographic variables of age and
application area analyzed according to preprocessing,
classification, and clustering.
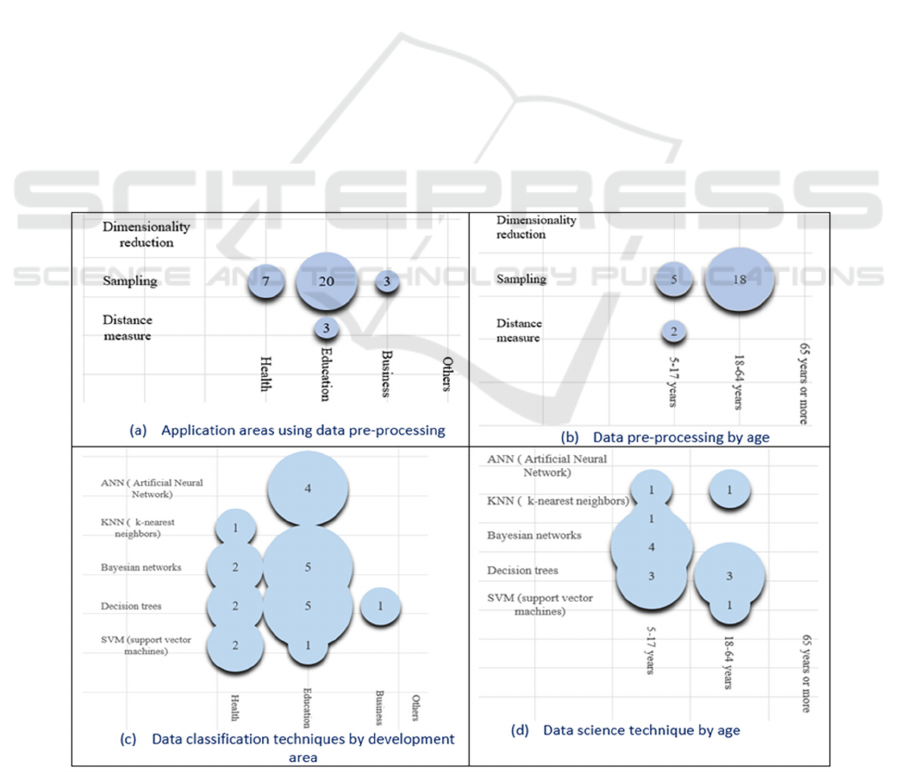
Figure 2(a) shows different areas where data
preprocessing techniques have been applied. Again,
sampling is the most used technique.
For example, the author of A003 performed a
preprocessing on data from students to test its
effectiveness in learning in students (Wang & Huang,
2021).
Figure 2(b) shows the types of users of serious
games, according to ages ranges and the different
preprocessing techniques used. It can be observed
that there is a more significant number of studies that
used data sampling in the category of users between
18 and 64 years. However, none specifies an age
range more significant than 64 years.
Some studies are addressed to a specific range of
age. For example, the Storyboard Interpretation
Technology prototype was designed for an
educational context to support students. Its main
contribution is to provide an environment to
understand the deeper meaning of a problem, working
with students aged 11 to 13 years (Schuldt et al.,
2018). PEGASO is a serious game that promotes a
healthy lifestyle for teenagers. This game provides
tailored interventions to motivate them using their
smartphones (Carrino et al., 2014).
The information about data classification
algorithms used in different development areas is
shown in Figure 2(c). The relevant information is
found in the area of education. To perform the
classification, the Decision Trees and Bayesian
networks are mainly applied.
The objective of some of these studies is to detect
the behavior of students and discover those students
who have some type of problem or unusual behavior
(e.g., wrong actions, low motivation, misuse,
cheating, abandonment, academic failure) (Suhirman
et al., 2014). Several data mining techniques,
classification and grouping has been widely used to
reveal this type of students, and provide them with
adequate help. In addition to these classification
techniques, the authors used traditional statistical
techniques such as factor analysis and model fit
analysis, with the purpose of examining the data, and
the structure of the model. Finally, the authors
ICT4AWE 2022 - 8th International Conference on Information and Communication Technologies for Ageing Well and e-Health
224
developed a computational model of the cognitive
process, using an Artificial Neural Network (ANN),
which allowed to review the underlying mechanisms
of cognition.
Figure 2(d) presents the data mining techniques
applied according to the age. Bayesian network along
with Decision Trees were applied more frequently.
Yahuna et. al. (2017) analyzed the behavior of
the participants when using a mathematical game.
This is a serious game was developed to evaluate the
mathematical ability of special-needs children. This
game uses the Indonesian Math curriculum, for
elementary school students. The game is presented
with a 4-options questionnaire. So, children perform
a classification and prediction that can be used to
determine the content of learning, evaluation
questions, and early warning. Clustering algorithms
according to the development area are shown in
Figure 2(e). The educational field shows the highest
score where the K-means clustering algorithm was
implemented.
Benmakrelouf et at. (2015) applied the K-Means
data mining methods to discuss the analysis of
learning through serious games. Then, an analysis of
the player’s experience was provided, using data
collected from the educational game. This study
revealed that there are three forms of player
participation: beginner, intermediate and advanced,
which are allocated according to their experience.
5 THREATS TO VALIDITY
Although the SLR was performed applying the
methodology proposed by Kitchehman (2010), some
threats to validity were mitigated during this research
process.
SLR included the most remarkable databases, but
it did not eliminate the fact that a small group of
studies could be excluded. To mitigate this problem,
a search was performed, applying different criteria in
the search string in order to obtain the most
significant number of studies. The reading of each
article (title, abstract, and the application of exclusion
and inclusion criteria) was performed by three
different members of the research team; this avoided
the exclusion of relevant articles. The papers selected
were those approved by 2 or 3 members.
Another problem in obtaining articles was the
selection of international congresses or conferences
and their relevance. To mitigate this problem, the
impact of each congress was evaluated, including the
periodicity, sponsors, and indexation sites.
Figure 2: Bubble Plots of the Review Results.
Data Mining Techniques for Analysing Data Extracted from Serious Games: A Systematic Literature Review
225

The agreement between reviewers when
assigning values to different RQs was considered. To
mitigate this situation, the Fleiss' Kappa indicator was
calculated, which gave a level of agreement among
reviewers.
6 CONCLUSIONS
The systematic literature review was carried out using
the methodology proposed by Barbara Kitchenham.
This process consists of several phases that have been
done successfully, obtaining answers to the different
research questions. For each research question,
articles that respond to these have been identified, and
their quality has also been validated.
From the review, it is evident that although there
are other systematic reviews in serious games, none
of these focuses on data mining techniques. Instead,
this review focuses on the classification of game
analytics, in collaborative learning, enhancing
learning but does not analyze data science techniques
such as data pre-processing, classification, clustering,
or data storage in a straightforward way.
Regarding the most relevant findings, the area of
education is exploited to develop serious games.
Many authors emphasize in the importance of
improving student learning. Another area of study in
serious games is health, where the lifestyle,
intellectual or cognitive abilities of people are trained.
Studies show that the data sampling technique and
data classification algorithms are the most widely
used in data science. The Bayesian Networks and
Decision Trees are the most implemented. In
clustering techniques, the k-means algorithm is the
most used.
This review shows that data science techniques
have not been applied to analyze data collected for
serious games. There is evidence of different types of
serious games for different age ranges, but none of
them focuses on the user's performance analysis or
results, and the information that can be extracted from
them. Finally, future work will focus on extracting
data from serious games aimed at the elderly age
group in the field of attention and cognitive memory
to apply the most relevant techniques obtained in this
review.
ACKNOWLEDGEMENTS
The authors wish to thank the Vice-Rector for
Research of the University of Azuay for the financial
and academic support and all the staff of the
Laboratory for Research and Development in
Informatics (LIDI), and the Department of Computer
Science of Universidad de Cuenca.
REFERENCES
Alonso-Fernández, C., Calvo-Morata, A., Freire,
M., Martínez-Ortiz, I., & Fernández-Manjón, B.
(2019). Applications of data science to game learning
analytics data: A systematic literature review.
Computers and Education, 141(April), 103612.
https://doi.org/10.1016/j.compedu.2019.103612
Benmakrelouf, S., Mezghani, N., & Kara, N. (2015).
Towards the identification of players’ profiles using
game’s data analysis based on regression model and
clustering. Proceedings of the 2015 IEEE/ACM
International Conference on Advances in Social
Networks Analysis and Mining, ASONAM 2015, 1403–
1410. https://doi.org/10.1145/2808797.2809429
Bente, G., & Breuer, J. (2010). Why so serious? On the
Relation of Serious Games and Learning. Eludamos -
Journal for Computer Game Culture, 4(1), 7–24.
Carrino, S., Caon, M., Angelini, L., Mugellini, E., Abou
Khaled, O., Orte, S., Vargiu, E., Coulson, N., Serrano,
J. C. E., Tabozzi, S., Lafortuna, C., & Rizzo, G. (2014).
PEGASO: A personalised and motivational ICT system
to empower adolescents towards healthy lifestyles.
Studies in Health Technology and Informatics, 207,
350–359. https://doi.org/10.3233/978-1-61499-474-9-
350
Chen, F., Cui, Y., & Chu, M. W. (2020). Utilizing Game
Analytics to Inform and Validate Digital Game-based
Assessment with Evidence-centered Game Design: A
Case Study. International Journal of Artificial
Intelligence in Education, 30(3), 481–503.
https://doi.org/10.1007/s40593-020-00202-6
Hernández, J. A. C., Duarte, M. P., & Dodero, J. M. (2017).
An architecture for skill assessment in serious games
based on Event Sequence Analysis. ACM International
Conference Proceeding Series, Part F1322.
https://doi.org/10.1145/3144826.3145400
Hou, H. T. (2015). Integrating cluster and sequential
analysis to explore learners’ flow and behavioral
patterns in a simulation game with situated-learning
context for science courses: A video-based process
exploration. Computers in Human Behavior, 48, 424–
435. https://doi.org/10.1016/j.chb.2015.02.010
Kitchenham, B., Pretorius, R., Budgen, D., Brereton, O. P.,
Turner, M., Niazi, M., & Linkman, S. (2010).
Systematic literature reviews in software engineering-
A tertiary study. Information and Software Technology,
52(8), 792–805. https://doi.org/10.1016/j.infsof.
2010.03.006
Loh, C. S., Sheng, Y., & Ifenthaler, D. (n.d.). (Advances in
Game-Based Learning) Christian Sebastian Loh,
Yanyan Sheng, Dirk Ifenthaler (eds.)-Serious Games
Analytics_ Methodologies for Performance
ICT4AWE 2022 - 8th International Conference on Information and Communication Technologies for Ageing Well and e-Health
226

Measurement, Assessment, and Improvement-
Spring.pdf.
Loh, C. S., Sheng, Y., & Ifenthaler, D. (2015). Serious
games analytics: Methodologies for performance
measurement, assessment, and improvement. In
Serious Games Analytics: Methodologies for
Performance Measurement, Assessment, and
Improvement. https://doi.org/10.1007/978-3-319-
05834-4
Massa, S. M., & Kühn, F. D. (2018). Learning Analytics in
Serious Games: a systematic review of literature;
Learning Analytics in Serious Games: a systematic
review of literature.
McHugh, M. L. (2012). Lessons in biostatistics interrater
reliability : the kappa statistic. Biochemica Medica,
22(3), 276–282. https://hrcak.srce.hr/89395
Mendoza, F. T., Paucar, H. R., & Condori, K. V. (2019).
Academic results meanings with data mining mediated
by the use of serious video game matelogic. Journal of
Advanced Research in Dynamical and Control Systems,
11(11 Special Issue), 509–518. https://doi.org/10.5373/
JARDCS/V11SP11/20193061
Nichols, T. R., Wisner, P. M., Cripe, G., & Gulabchand, L.
(2010). Putting the kappa statistic to use. Quality
Assurance Journal, 13(3–4), 57–61.
https://doi.org/10.1002/qaj.481
Petrov, E. V., Mustafina, J., Alloghani, M., Galiullin, L., &
Tan, S. Y. (2019). Learning analytics and serious
games: Analysis of interrelation. Proceedings -
International Conference on Developments in ESystems
Engineering, DeSE, 2018-Septe, 153–156.
https://doi.org/10.1109/DeSE.2018.00037
Ravyse, W. S., Seugnet Blignaut, A., Leendertz, V., &
Woolner, A. (2017). Success factors for serious games
to enhance learning: a systematic review. Virtual
Reality, 21(1), 31–58. https://doi.org/10.1007/s10055-
016-0298-4
Ruiz-Rube, I., Dodero, J. M., Palomo-Duarte, M., Ruiz, M.,
& Gawn, D. (2013). Uses and applications of Software
& Systems Process Engineering Meta-Model process
models. A systematic mapping study. Journal of
Software: Evolution and Process, 25(9), 999–1025.
Schuldt, J., Sachse, S., Friedemann, S., & Breitbarth, K.
(2018). Storyboard interpretation technology used for
value-based STEM education in digital game-based
learning contexts. CSEDU 2018 - Proceedings of the
10th International Conference on Computer Supported
Education, 2(Csedu 2018), 78–88. https://doi.org/
10.5220/0006670700780088
Shoukry, L., Göbel, S., & Steinmetz, R. (2014). Learning
Analytics and Serious Games. 21–26.
https://doi.org/10.1145/2656719.2656729
Slimani, A., Elouaai, F., Elaachak, L., Yedri, O. B., &
Bouhorma, M. (2018). Learning analytics through
serious games: Data mining algorithms for performance
measurement and improvement purposes.
International
Journal of Emerging Technologies in Learning, 13(1),
46–64. https://doi.org/10.3991/ijet.v13i01.7518
Suhirman, X. X., Zain, J. M., & Herawan, T. (2014). Data
mining for education decision support: A review.
International Journal of Emerging Technologies in
Learning, 9(6), 4–19. https://doi.org/10.3991/ij
et.v9i6.3950
Wang, C., & Huang, L. (2021). A Systematic Review of
Serious Games for Collaborative Learning: Theoretical
Framework, Game Mechanic and Efficiency
Assessment. International Journal of Emerging
Technologies in Learning, 16(6), 88–105.
https://doi.org/10.3991/ijet.v16i06.18495
Wilkinson, P. (2016). Brief history of serious games.
Lecture Notes in Computer Science (Including
Subseries Lecture Notes in Artificial Intelligence and
Lecture Notes in Bioinformatics), 9970 LNCS, 17–41.
https://doi.org/10.1007/978-3-319-46152-6_2
Wohlin, C., Runeson, P., Höst, M., Ohlsson, M. C.,
Regnell, B., & Wesslén, A. (2012). Experimentation in
software engineering. Experimentation in Software
Engineering, 9783642290, 1–236.
https://doi.org/10.1007/978-3-642-29044-2
Yuhana, U. L., Mangowal, R. G., Rochimah, S., Yuniarno,
E. M., & Purnomo, M. H. (2017, June 5). Predicting
Math performance of children with special needs based
on serious game. 2017 IEEE 5th International
Conference on Serious Games and Applications for
Health, SeGAH 2017. https://doi.org/10.1109/
SeGAH.2017.7939276
Zanasi, A., & Ruini, F. (2018). It-Induced Cognitive Biases
in Intelligence Analysis: Big Data Analytics and
Serious Games. International Journal of Safety and
Security Engineering, 8(3), 438–450.
https://doi.org/10.2495/SAFE-V8-N3-438-450
Zhang, J., & Lu, J. (2014). Using Mobile Serious Games for
Learning Programming. … 2014, The Fourth
International Conference on …, c, 24–29.
Data Mining Techniques for Analysing Data Extracted from Serious Games: A Systematic Literature Review
227
