
An Evolutionary Algorithm for Task Scheduling in Crowdsourced
Software Development
Razieh Saremi
1 a
, Hardik Yardik
1
, Julian Togelius
2 b
, Ye Yang
1
and Guenther Ruhe
3
1
School of Systems and Enterprises, Stevens Institute of Technology, Hoboken, NJ, U.S.A.
2
Tandon School of Engineering, New York University, NYC, NY, U.S.A.
3
University of Calgary, Calgary, Alberta, Canada
Keywords:
Crowdsourcing, Task Scheduling, Task Failure, Task Similarity, Evolutionary Algorithm, Genetic Algorithm.
Abstract:
The complexity of software tasks and the uncertainty of crowd developer behaviors make it challenging to plan
crowdsourced software development (CSD) projects. In a competitive crowdsourcing marketplace, competi-
tion for shared worker resources from multiple simultaneously open tasks adds another layer of uncertainty
to potential outcomes of software crowdsourcing. These factors lead to the need for supporting CSD man-
agers with automated scheduling to improve the visibility and predictability of crowdsourcing processes and
outcomes. To that end, this paper proposes an evolutionary algorithm-based task scheduling method for crowd-
sourced software development. The proposed evolutionary scheduling method uses a multiobjective genetic
algorithm to recommend optimal task start date. The method uses three fitness functions, based on project
duration, task similarity, and task failure prediction, respectively. The task failure fitness function uses a neu-
ral network to predict the probability of task failure with respect to a specific task start date. The proposed
method then recommends the best tasks’ start dates for the project as a whole and each individual task so as
to achieve the lowest project failure ratio. Experimental results on 4 projects demonstrate that the proposed
method has the potential to reduce project duration by a factor of 33-78%.
1 INTRODUCTION
Crowdsourced Software Development (CSD) has
been increasingly adopted in modern software de-
velopment practices as a way of leveraging the wis-
dom of the crowd to complete software mini-tasks
faster and cheaper (Stol and Fitzgerald, 2014)(Saremi
et al., 2017). In order for a CSD platform to func-
tion efficiently, it must address both the needs of task
providers as demands and crowd workers as suppli-
ers. Mismatches between these needs might lead to
task failure in the CSD platform. In general, plan-
ning for CSD tasks is challenging (Stol and Fitzger-
ald, 2014), because software tasks are complex, inde-
pendent, and require potential task-takers with spe-
cialized skill-sets. The challenges stem from three
factors: 1) task requesters typically need to simulta-
neously monitor and control a large number of mini-
tasks decomposed suitable for crowdsourcing; 2) task
requesters generally have little to no control over how
many and how dedicated workers will engage in their
a
https://orcid.org/0000-0002-7607-6453
b
https://orcid.org/0000-0003-3128-4598
tasks, and 3) task requesters are competing for shared
worker resources with other open tasks in the market.
To address these challenges, existing research has
explored various methods and techniques to bridge
the information gap between demand and supply in
crowdsourcing-based software development. Such
research includes studies towards developing a bet-
ter understanding of worker motivation and pref-
erences in CSD (Faradani et al., 2011)(Difallah
et al., 2016)(Yang and Saremi, 2015), studies fo-
cusing on predicting task failure (Khanfor et al.,
2017)(Khazankin et al., 2011); studies employing
modeling and simulation techniques to optimize CSD
task execution processes(Saremi, 2018)(Saremi et al.,
2019)(Saremi et al., 2021); and studies for recom-
mending the most suitable workers for tasks (Yang
et al., 2016) and developing methods to create crowd-
sourced teams(Wang et al., 2018) (Yue et al., 2015).
The existing work lacks effective supports for ana-
lyzing the impact of task similarity and task arrival
date on task failure. In this study, we approach these
gaps by proposing a task scheduling method leverag-
ing the combination of evolutionary algorithms and
120
Saremi, R., Yardik, H., Togelius, J., Yang, Y. and Ruhe, G.
An Evolutionary Algorithm for Task Scheduling in Crowdsourced Software Development.
DOI: 10.5220/0011000500003179
In Proceedings of the 24th International Conference on Enterprise Information Systems (ICEIS 2022) - Volume 1, pages 120-128
ISBN: 978-989-758-569-2; ISSN: 2184-4992
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

Figure 1: Overview of motivating example.
neural networks.
The objective of this work is to propose a task
scheduling recommendation framework to support
CSD managers to explore options to improve the suc-
cess and efficiency of crowdsourced software devel-
opment. To this end, we first present a motivating
example to highlight the practical needs for software
crowdsourcing task scheduling. Then we propose a
task scheduling architecture based on an evolutionary
algorithm. This algorithm seeks to reduce predicted
task failure while at the same time shortening project
duration and managing the level of task similarity in
the platform. The system takes as input a list of tasks,
their durations, and their interdependencies. It then
finds a plan for the overall project, meaning an as-
signment of each task to a specific day after the start
of the project. Also, the system checks the similarity
among parallel open tasks to make sure the task will
attract the most suitable available worker to perform
it upon arrival. The evolutionary task scheduler then
recommends a task schedule plan with the lowest task
failure probability per task to arrive in the platform.
We applied the proposed scheduling framework to 4
CSD projects in our database. The result confirmed
that the proposed method has the potential of reduc-
ing the project duration between 33-78%.
The proposed system represents a task schedul-
ing method for competitive crowdsourcing platforms
based on the workflow of TopCoder
1
, one of the pri-
mary software crowdsourcing platforms. The recom-
mended schedule provides improved duration while
decreasing task failure probability and number of
open similar tasks upon task arrival in the platform.
The remainder of this paper is structured as fol-
lows. Section 2 introduces a motivating example that
inspires this study. Section 3 outlines our research
design and methodology. Section 4 presents the case
study and model evaluation.Section 5 presents a re-
view of related works, and Section 6 presents the con-
clusion and outlines a number of directions for future
work.
1
https://www.topcoder.com/
2 MOTIVATING EXAMPLE
The motivating example illustrates a real-world
crowdsourcing software development (CSD) project
on the TopCoder platform. It consists of 19 tasks with
a project duration of 110 days. The project experi-
enced a 57% task failure ratio, meaning 11 of the 19
tasks failed. More specifically, Task 14 and 15 failed
due to client request, and Task 3 failed due to unclear
requirements. The remaining eight tasks (i.e. Task
1, 2, 4, 5, 8, 11, 13, and 17) failed due to zero sub-
missions. An in-depth analysis revealed that the eight
failed tasks due to zero submissions were basically
three tasks (i.e. tasks 2, 4, and 8) that were re-posted
after each failure to be successfully completed as the
new task.
As illustrated in Figure 1, Task 2 was cancelled
and re-posted as Tasks 5 and 7. It was completed as
Task 7 with changes in the monetary prize and task
type. Task 4 was cancelled and re-posted as Task 6
which was completed with no modification. Task 8
also failed and re-posted six times as Tasks 11, 13,
14, 15, 17, and 18. Each re-posting modified Task 8
in terms of the monetary prize, task type, and required
technology. Finally, the task was completed as Task
18. Studying task 18 revealed that it arrived with 5
similar tasks with similarity degree of 60% in the plat-
form. Also task failure probability on the arrival day
for task 18 was 17%.
This observation motivated us to develop the
scheduling method presented in this paper. This
method can reduce the probability of task failure in
the platform, while simultaneously controlling the
level of task similarity on task arrival day per project.
3 RESEARCH METHODOLOGY
To solve the scheduling problem, we use a genetic
algorithm to schedule tasks based on the minimum
probability of task failure and degree of similarity
among list of parallel tasks in the project. We adapted
An Evolutionary Algorithm for Task Scheduling in Crowdsourced Software Development
121

Figure 2: Overview of Evolutionary Scheduling Architecture.
dominant CSD project attributes from existing studies
(Saremi et al., 2017)(Yang and Saremi, 2015)(Saremi
and Yang, 2015) (Mejorado et al., 2020)(Lotfalian-
Saremi et al., 2020) and defined metrics used in the
scheduling framework. Then we added the neural net-
work model from (Urbaczek et al., 2021) to predict
the probability of task failure per day. In the method
presented here, task arrival date is suggested based
on the degree of task similarity among parallel tasks
in the project and the probability of task failure in
the platform based on available tasks and reliability
of available workers to make a valid submission in
the platform. Figure 2 presents the overview of the
task scheduling architecture. List of tasks of a crowd-
sourced project is uploaded in the evolutionary task
scheduler. The task dependency orders tasks based
on the project dependency and tasks duration. In par-
allel, task similarity calculates the similarity among
tasks to make sure batch of arrival tasks follow the
optimum similarity level. Then, the task failure pre-
dictor analyzes the probability of failure of an arriv-
ing task in the platform based on the number of simi-
lar tasks available on arriving day, average similarity,
task duration, and associated monetary prize. In next
step, the parent selection selects the most suitable set
of parents to use for reproduction, i.e. the generation
of new chromosomes. In every generation, all chro-
mosomes are evaluated by the fitness functions. The
result of task performance in the platform is to be col-
lected and reported to the client along with the input
used to recommend the posting date.
3.1 Metrics and Task Prediction
We pose crowdsourced task scheduling as a multi-
objective optimization problem with dynamic charac-
teristics that requires agility in tracking the changes
of task similarity and probability of task failure over
time. Therefore, we presume that the objectives ex-
hibit partial conflict (this was also borne out by ob-
servation) so that it will be unlikely to find a single
solution that satisfies all objectives. In other words,
a successful optimization finds a Pareto front of non-
dominated solutions. To that end, we propose a novel
evolutionary task scheduling method which combines
multiple objectives. The presented method integrates
artificial neural network with the non-dominated sort-
ing genetic algorithm (NSGA-II) (Deb et al., 2002),
which is a well-known method for finding sets of so-
lutions for multi-objective problems.
3.1.1 Task Dependency
A crowdsourced project (CP
K
) is a sequence of time
dependent tasks that needs to be completed during
specific period of time. In this study, each task can
start only after all prerequisite tasks are successfully
finished. The set of task dependencies is referred to
as T D
i
. Task (n), T
n
, is parallel (Pl
i
) with task (n-
1), T
n−1
, if it starts before the submission deadline of
T
n−1
. And T
n
is a sequential task (Sl
i
) for T
n−1
if it
starts after the submission deadline of T
n
. The project
duration (CPD
K
) is defined as the total duration be-
tween the first task’s registration start date (T R
1
) and
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
122

last task’s submission end date(T S
n
).
CP
k
= ({T
i
},{T D
i
},CPD
k
) (1)
where
T D
i
=
(
1 Pl
i
= 1
0 Sl
i
= 1
i= 1, 2, 3, . . . , n
(
CPD
k
= T S
n
−T R
1
k = 1, 2, 3, . . . , m
3.1.2 Task Similarity
Task similarity is defined as the degree of similarity
between a set of simultaneously open tasks. We cal-
culate the tasks’ local distance from each other to cal-
culate a task similarity factor, based on different task
features such as detailed task requirements, task mon-
etary prize, task type, task registration and submis-
sions date, required technology and platform.
Def.1: Task local distance (Dis
i
) is a tuple of
tasks’ attributes in the data set. Task local distance
is:
Dis
i
= (Prize
i
,T R
i
,T S
i
,Type
i
,Techs
i
,PLTs
i
,Req
i
)
(2)
Def.2: Task Similarity (Sim
i, j
) between two tasks
T
i
and T
j
is defined as the is the dot product and mag-
nitude of the local distance of two tasks:
Sim
i, j
=
∑
n
i, j=0
Dis
(i, j)
∑
n
i=0
√
Dis
i
∗
∑
n
j=0
p
Dis
j
(3)
3.1.3 Task Failure Predictor
To predict probability of task failure, a fully con-
nected feed forward neural network was trained (Ur-
baczek et al., 2021). It is reported that task mon-
etary prize and task duration (Yang and Saremi,
2015)(Faradani et al., 2011) are the most important
factors in raising competition level for a task. In this
research, we are adding the variables considered in
our observations (for example number of open tasks
and average task similarity in the platform) to the re-
ported list of important factors as input features to
train the neural network model. See table 1 for the
list of features. The network is configured with five
layers of size 32, 16, 8, 4, 2, and 1. We applied a K-
fold (K=10) cross-validation method on the train/test
group to train the prediction of task failure probabil-
ity in the neural network model. Also, We used early
stopping to avoid over-fitting. The trained model pro-
vided a loss of 0.04 with standard deviation of 0.002.
Interestingly, neural network performed better than
moving average, linear regression and support vec-
tor regression on failure prediction(Urbaczek et al.,
2021).
To help in understanding of the qualities of the
task failure predictor model, the main input variables
are defined below, as well as the reward function to
train the neural network model.
Def.3: Number of Open Tasks per day (NOT
d
) is
the Number of tasks (T
j
) that are open for registration
when a new task (T
i
) arrives on the platform.
NOT
d
=
n
∑
j=0
T
j
(4)
where : T RE
j
>= T R
i
Def.4: Average Task Similarity per day (ATS
d
) is
the average similarity score (Sim
i, j
) between the new
arriving task (T
i
) and currently open tasks (T
j
) on the
platform.
AT S
d
=
∑
n
i, j=0
Sim
i, j
NOT
d
(5)
where : T RE
j
>= T R
i
Def.5: Probability of task failure per day
(p(T F
d
)), is the probability that a new arriving task
(T
i
) does not receive a valid submission and fails given
its arrival date.
p(T F
d
) = 1 −
∑
n
i=0
V S
i
NOT
i
(6)
where : T RE
j
>= T R
i
To determine the optimal arrival date, we run the
neural network model and evaluate the probability
of task failure for three days (i.e two days surplus)
from task arrival, arrival day: (p(T F
d
)), one day af-
ter:(p(T F
d+1
)), and two days after: (p(TF
d+2
)). To
predict the probability of task failure in future days,
there is a need to determine the number of expected
arriving tasks and associated task similarity scores
compared to the open tasks in that day.
Def.6: Considering that the registration duration
(difference between opening and closing dates) for
each task is known at any given point in time, the rate
of task arrival per day (TA
d
) is defined as the ratio of
the number of open tasks per day NOT
d
over the total
duration of open tasks per day.
TA
d
=
NOT
d
∑
n
j=0
D
j
(7)
By knowing the rate of task arrival per day, the
number of open tasks for future days can be deter-
mined.
Def.7: Number of Open Tasks in the future OT
f ut
is the number of tasks that are still open given a future
An Evolutionary Algorithm for Task Scheduling in Crowdsourced Software Development
123

date NOT
f ut
, in addition to the rate of task arrival per
day TA
d
multiplied by the number of days into the
future ∆days.
OT
d+i
= NOT
d+i
+ TA
d
∗∆days (8)
Also there is a need to know the average task sim-
ilarity in future days.
Def.8: Average Task Similarity in the future
AT S
f ut
, is defined as the number of tasks that are still
open given a future date NOT
f ut
multiplied by the av-
erage task similarity of this group of tasks AT S
f ut
, the
average task similarity of the current day ATS
d
mul-
tiplied by the rate of task arrival per day TA
d
and the
the number of days into the future ∆days.
AT S
f ut
= NOT
f ut
∗AT S
f ut
+ AT S
d
∗TA
d
∗∆day (9)
3.2 Evolutionary Task Scheduling
Below, we describe the evolutionary method imple-
mented to schedule tasks based on the metrics and
failure predictor described above.
3.2.1 Chromosome Representation and Initial
Population
The chromosome is represented as a sequence of in-
tegers where each value indicates the arrival day for
the respective task. One chromosome represents the
schedule for the given project. The integer values are
bounded between 0 and the maximum allowed dura-
tion for the project.
3.2.2 Reproduction and Variation
Chromosomes are reproduced either through copying
followed by mutation or through crossover. We em-
ploy standard two-point crossover: two indices are se-
lected at random and sequences between those two
points are exchanged between two parent chromo-
somes to create two new offspring. The probabil-
ity of reproduction through crossover is 0.9. With
0.1% probability, reproduction is through copying a
single parent and mutating the copy. For mutation,
we use shuffling. For each value in the sequence,
an index is chosen randomly for shuffling. Proba-
bility for each index to get selected for shuffling is
1/(lengthO f Sequence). These parameters were de-
cided through initial experimentation using this sys-
tem as well as previous experience with similar prob-
lems.
During initialization of chromosomes, as well as
during reproduction, we ensure that every chromo-
some adheres to the task dependency constraint. The
task dependency constraint is that tasks in the crowd
project follow their required dependencies.
T R
j
=
(
T R
i
Sl
i, j
= 0
T S
i
+ 1 Sl
i, j
= 1
(10)
3.2.3 Fitness Functions
We use three fitness functions that seek to, respec-
tively, minimize project duration, minimize probabil-
ity of task failure in the platform, and manage task
similarity in the project. Each fitness function is de-
scribed below:
• Project duration: The first fitness function mea-
sures the complete duration of the project for sug-
gested schedule.
• Task Similarity: Tasks with cosine similarity of
60% lead to the highest level of competition with
lower level of task failure (Saremi et al., 2020).
The similarity fitness function assures that parallel
tasks that are not 60% similar do not arrive at the
same time.
Pl
i, j
= 1 T R
j
=
(
T R
i
Sim
i, j
= 0.6
T RE
i
Sim
i, j
6=0.6
Pl
i, j
= 0 T R
j
= T S
i
+ 1
(11)
When two task in the project are arriving parallel
that are not following 60% rule, task (j),T
j
, with
longer registration duration, will be postponed to
arrive after task (i), T
i
registration end date.
T R
j
= T RE
i
(12)
where :
(
Pl
i, j
= 1
T RE
i
<= T RE
j
• Task Failure Probability: Tasks following the de-
pendency requirement function and meeting the
task similarity are entering the task failure prob-
ability function to be assigned to the task regis-
tration start date with lowest failure probability
based on the result of the neural network.
T R
i
= min(p(T F
d
),p(T F
d+1
),p(T F
d+2
)) (13)
3.2.4 Selection Operator
For parent selection operation we use a crowding-
distance based tournament strategy. A crowding-
distance is a measure of how close a chromosome is
to its neighbors. For selecting individuals for the next
generation from the pool of current population and
offspring we use the standard selection method from
NSGA-II (Deb et al., 2002).
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
124
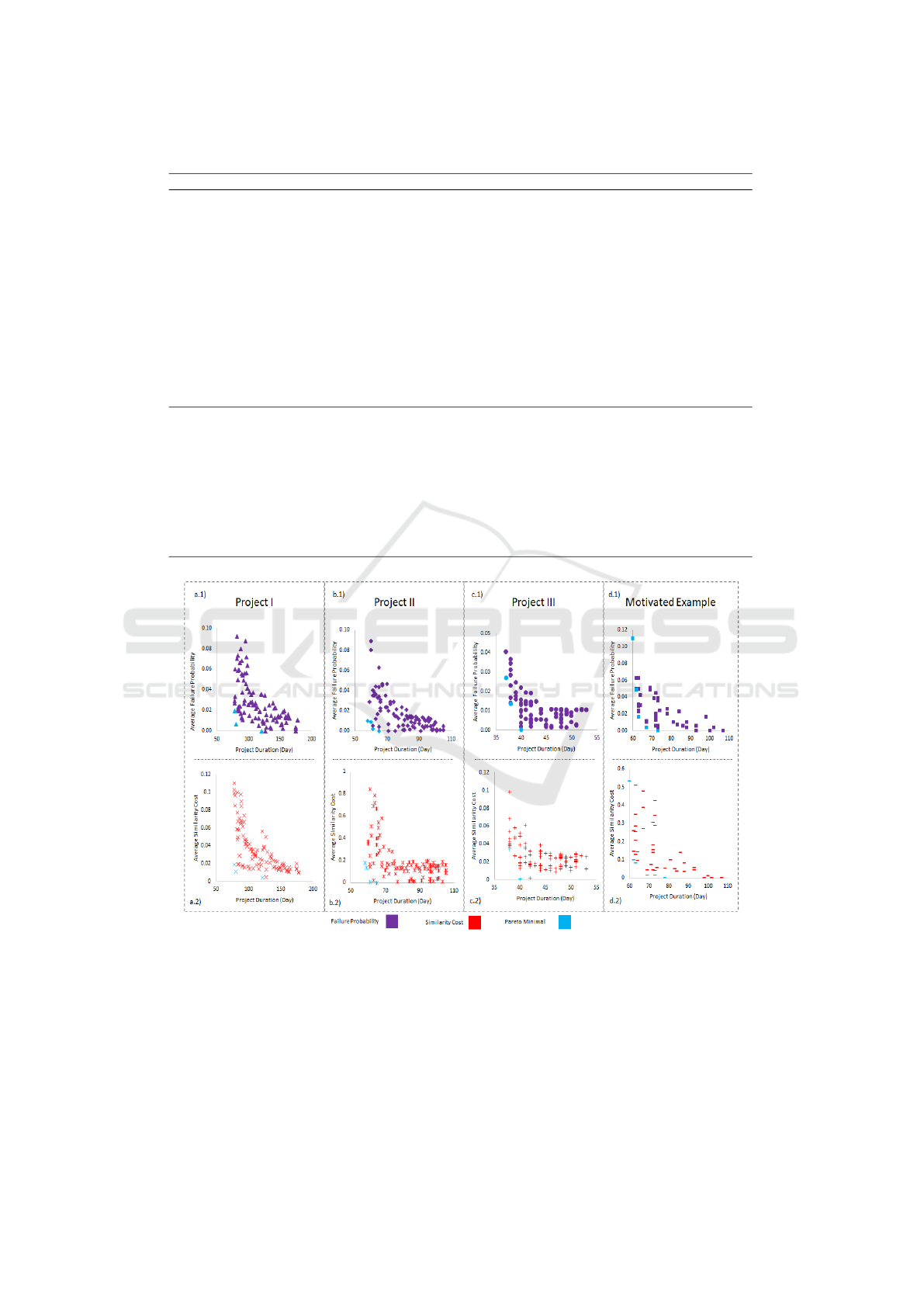
Table 1: Summary of Task Features in the Data Set.
Type Metrics Definition
Task registration start date
(TR)
The first day of task arrival in the platform and when workers can start regis-
tering for it. (mm/dd/yyyy)
Task submission end date (TS) Deadline by which all workers who registered for task have to submit their
final results. (mm/dd/yyyy)
Task registration end date
(TRE)
The last day that a task is available to be registered for. (mm/dd/yyyy)
Tasks Attributes
Task Duration (D
i
) total available days from task (i) registration start date (T R
i
) to submissions
end date (T S
i
)
Monetary Prize (MP) Monetary prize (USD) offered for completing the task and is found in task
description. Range: (0, ∞)
Technology (Tech) Required programming language to perform the task. Range: (0, # Tech)
Platforms (PLT) Number of platforms used in task. Range: (0, ∞).
Task Status Completed or failed tasks
# Registrants (R) Number of registrants that sign up to compete in completing a task before
registration deadline. Range: (0, ∞).
Tasks Performance
# Submissions (S) Number of submissions that a task receives before submission deadline.
Range: (0, # registrants].
# Valid Submissions (VS) Number of submissions that a task receives by its submission deadline that
have passed the peer review. Range: (0, # registrants].
Figure 3: Average Task failure Probability (a.1, b.1, c.1, d.1) and Task Similarity Cost(a.2, b.2, c.2, d.2) of Recommended
Schedules per project.
3.2.5 Population and Termination Criterion
The presented algorithm used a population of 200,
and the run length was experimentally determined
to be 200 generations, after which no more non-
dominated solutions generally emerged. Task exe-
cution follows the project schedule provided for a
project in our data set and the initial chromosome fol-
lows the original task dependencies with 0 days delay
(i.e the earliest project schedule).
An Evolutionary Algorithm for Task Scheduling in Crowdsourced Software Development
125

4 EXPERIMENT DESIGN
To evaluate the evolutionary task scheduling method
this section presents the experiment design and eval-
uation base line for this study.
4.1 Research Questions
To investigate the impact of probability of task fail-
ure in platform and task similarity level with in the
project, the following research questions were formu-
lated and studied:
RQ1 (Overall Performance): How does the evolu-
tionary task scheduling method help to reduce project
duration and task failure potential?
RQ2 (Task Similarity): What is the effect of intro-
ducing a task similarity objective on the algorithm’s
ability to find short and robust schedules?
4.2 Data Set
The gathered data set contains 403 individual projects
including 4,908 component development tasks and
8,108 workers from Jan 2014 to Feb 2015, extracted
from TopCoder website. Tasks are uploaded as com-
petitions in the platform and crowd software work-
ers register and complete the challenges. On average,
most of the tasks have a life cycle of 14 days from the
first day of registration to the submission’s deadline.
Table 1 summarizes the features available in the data
set and used in fitness functions.
5 RESULTS
This section presents the evaluation results of apply-
ing the proposed scheduling framework to 4 CSD
projects. Table 2 summarize the projects overall view.
As figure 3-a represents, the framework recommends
a schedule with duration of 121 days with 0.0% prob-
ability of task failure and 0.4% similarity cost for
project I. This provides almost 70% schedule accel-
eration. The result of scheduling for project II, figure
3-b, is a project duration with Pareto minimum of 65
days, and 0% failure probability and task similarity
cost.
The recommended schedule results in 78% accel-
eration. Applying the presented framework to the
project III, 3-c. lead to 55% shorter schedule accel-
eration. the project duration shortens to 40 days, with
probability of task failure as low as 0.02% and task
similarity cost of 0.04%. Finally, scheduling the mo-
tivating example with the presented system recom-
Table 2: Summary of Scheduled Projects.
Project ID #
Tasks
Original
(day)
Final
(day)
Recom
(day)
Schedule
Accel-
eration
Project I 25 70 393 121 70%
Project II 24 58 203 65 78%
Project III 23 31 88 40 55%
Motivating 11 37 110 73 33%
mended a schedule with 73 days duration, 0.07% av-
erage probability of task failure and 1.3% average task
similarity cost. This means a 33% schedule accelera-
tion.
In order to answer the research questions in part
4.1 and have a better understanding of how the pre-
sented framework part 3.2 is working, we explain
scheduling of motivating example using the evolu-
tionary scheduling introduced in details in parts 5.1,
5.2 and 5.3.
5.1 Project Schedule Acceleration
To answer RQ1 we eliminate the second fitness func-
tion (task similarity) and scheduled the project focus-
ing on minimizing task failure probability. Figure 4-
a illustrates the scheduling result. As it is shown in
figure 4-a, project duration has decreased from 110
days to 60 days.The probability of task failure has
dropped to 10%. While the scheduling method pro-
viding 23 days delay in compare with the shortest pos-
sible project plan (37 days), the recommended sched-
ule finishes 50 days earlier than the original project
duration with 47% higher chance of success. Ac-
cording to the recommended project timeline, project
faced the maximum task failure probability of 33% on
task 7 and the minimum failure probability of 0.0 on
tasks 2,5,6,8,9 and 10.
5.2 Task Similarity
To answer RQ2 we have added task similarity fitness
function to the evolutionary scheduling. In this part
we analyze the recommended schedule with 0 simi-
larity cost form the solution space. As it is presented
in figure 4-b, evolutionary scheduling recommends a
plan with duration of 79 days and average probabil-
ity of task failure of 5%. Compare with the sched-
ule from RQ1, evolutionary scheduling provides 19
days longer project plan, while it provides 5% lower
task failure probability. Also, evolutionary schedul-
ing takes similarity among the project tasks in to ac-
count.This creates easier competition for attracting re-
sources. Also, the method recommended to postpone
the start date of the project for 47 day, in order to have
0 days overlap due to task similarity.
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
126
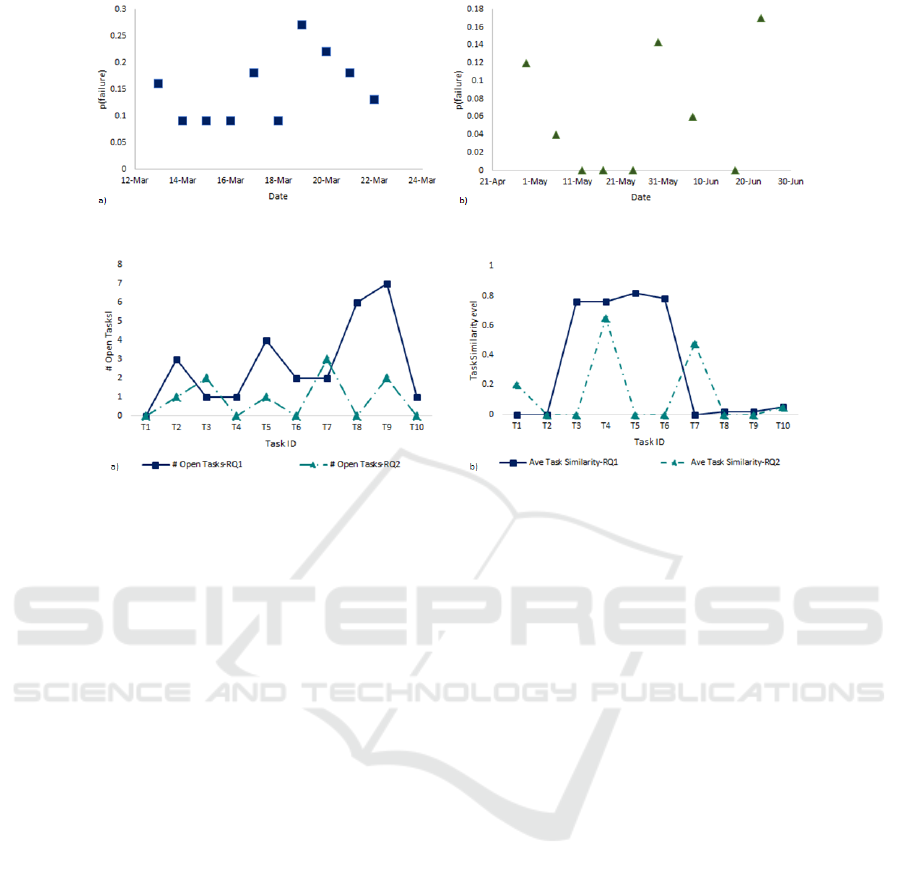
Figure 4: A) Overall Performance of scheduling framework, b) Schedule Acceleration with Task Similarity.
Figure 5: A) Number of Open Tasks on Task Arrival Day, b) Average Task Similarity on Task Arrival Day.
5.3 Comparison between Scheduling
with and without Task Similarity
To have a a better understanding of the impact of the
proposed evolutionary scheduling we investigate the
number of open tasks, number of open tasks and aver-
age task similarity level on the recommended sched-
ule.
Figure 5-a presents the number of open task per
arrival task based on different scheduling plan in RQ1
and RQ2. Scheduling under RQ1 conditions lead to
competition level with on average 3 other tasks per
day. The least competition to attract the resources
happened for T
1
with 0 open tasks in the arrival date
and T
9
faced the hardest competition with 7 other
tasks available in the platform. Clearly, taking task
similarity into account creates less competition. As it
is shown scheduling under RQ2 provides task arriving
with average one open task per arrival date, with min-
imum 0 open task for T
1
,T
4
,T
6
,T
8
,T
10
, and maximum
3 open tasks when T
7
arrived.
Another measure to investigate is average task
similarity on the recommended task arrival date. As
it is shown in figure 5-b, in RQ1 tasks are arriving
to the platform with on average 32% task similarity.
T
3
,T
4
,T
5
, andT
6
are competing with tasks with more
than 75% similarity. While adding task similarity fit-
ness function in RQ2 provides task arrival with on av-
erage 14% task similarity in the platform.T
4
faced the
highest task similarity level of 65%.
5.4 Discussion and Findings
Our evolutionary scheduling method generated plans
with average probability of task failure of 5%. This
result not only is 53% lower than the original plans,
but it is also lower than reported failure ratio in the
platform (i.e 15.7%) (Mejorado et al., 2020)(Yang
et al., 2016). Figure 3-d-1. shows the average prob-
ability of task failure per recommended schedule by
evolutionary scheduler. According to the figure 3-d-1
longer project duration provides lower probability of
task failure. The goal is to reduce schedule duration
while reducing task failure, so the optimum solutions
have duration of around 73 days (33% schedule ac-
celeration) which provides task failure probability of
0.07%.
Investigating the number of open tasks and the av-
erage task similarity on recommended arriving day
per task support that the evolutionary task scheduling
method assures lower competition over shared sup-
plier resources per arrival task(i.e 1 and 14% respec-
tively).
Task similarity cost is the ratio of duration added
to the recommended task schedule due to considering
task similarity fitness function. As shown in figure 3-
d-2 the lowest similarity cost is when project duration
is between 70 to 80 days or more than 95 days. The
main objective is project duration, so the optimum so-
lution 70-80 days (Pareto minimum shown in blue).
An Evolutionary Algorithm for Task Scheduling in Crowdsourced Software Development
127

6 CONCLUSION AND FUTURE
WORK
CSD provides software organizations access to an
infinite, online worker resource supply. Assigning
tasks to a pool of unknown workers from all over
the globe is challenging. A traditional approach to
solving this challenge is task scheduling. Improper
task scheduling in CSD may cause Task failure due
to uncertain worker behavior. The proposed approach
recommends task scheduling plans based on a set of
task dependencies in a crowdsourced project, similar-
ities among tasks, and task failure probabilities based
on recommended arrival date. The proposed evo-
lutionary scheduling method utilizes a genetic algo-
rithm to optimize and recommend the task schedule.
The method uses three fitness functions, respectively
based project duration, task similarity, and task fail-
ure prediction. The task failure fitness uses a neu-
ral network to predict probability of task failure on
arrival date. The proposed method empowers crowd-
sourcing managers to explore potential outcomes with
respect to different task arrival strategies. This in-
cludes the probability of task failure, number of open
similar task in terms of context, prize, duration and
type on the arrival day, and different schedule ac-
celeration. The experimental results on 4 different
projects demonstrate that the proposed method re-
duced project duration on average 59%
REFERENCES
Deb, K., Pratap, A., Agarwal, S., and Meyarivan, T. (2002).
A fast and elitist multiobjective genetic algorithm:
Nsga-ii. IEEE Transactions on Evolutionary Compu-
tation.
Difallah, D. E., Demartini, G., and Cudr
´
e-Mauroux, P.
(2016). Scheduling human intelligence tasks in multi-
tenant crowd-powered systems. In International Con-
ference on World Wide Web.
Faradani, S., Hartmann, B., and Ipeirotis, P. G. (2011).
What’s the right price? pricing tasks for finishing on
time. In Workshops at the Twenty-Fifth AAAI Confer-
ence on Artificial Intelligence.
Khanfor, A., Yang, Y., Vesonder, G., Ruhe, G., and
Messinger, D. (2017). Failure prediction in crowd-
sourced software development. In 2017 24th Asia-
Pacific Software Engineering Conference (APSEC).
Khazankin, R., Psaier, H., Schall, D., and Dustdar, S.
(2011). Qos-based task scheduling in crowdsourc-
ing environments. In International Conference on
Service-Oriented Computing.
Lotfalian-Saremi, M., Saremi, R., and Martinez-Mejorado,
D. (2020). How much should i pay? an empirical
analysis on monetary prize in topcoder. In HCI.
Mejorado, D. M., Saremi, R., Yang, Y., and Ramirez-
Marquez, J. E. (2020). Study on patterns and effect of
task diversity in software crowdsourcing. In Interna-
tional Symposium on Empirical Software Engineering
and Measurement, pages 1–10.
Saremi, R. (2018). A hybrid simulation model for crowd-
sourced software development. In International Work-
shop on Crowd Sourcing in Software Engineering.
Saremi, R., Lotfalian Saremi, M., Desai, P., and Anzalone,
R. (2020). Is this the right time to post my task? an
empirical analysis on a task similarity arrival in top-
coder. In HCII.
Saremi, R., Yang, Y., and Khanfor, A. (2019). Ant
colony optimization to reduce schedule acceleration
in crowdsourcing software development. In Interna-
tional Conference on Human-Computer Interaction.
Saremi, R., Yang, Y., Vesonder, G., Ruhe, G., and Zhang,
H. (2021). Crowdsim: A hybrid simulation model for
failure prediction in crowdsourced software develop-
ment. arXiv preprint arXiv:2103.09856.
Saremi, R. L. and Yang, Y. (2015). Empirical analysis on
parallel tasks in crowdsourcing software development.
In 2015 30th IEEE/ACM International Conference on
Automated Software Engineering Workshop (ASEW).
Saremi, R. L., Yang, Y., Ruhe, G., and Messinger, D.
(2017). Leveraging crowdsourcing for team elasticity:
an empirical evaluation at topcoder. In International
Conference on Software Engineering.
Stol, K.-J. and Fitzgerald, B. (2014). Two’s company,
three’s a crowd: a case study of crowdsourcing soft-
ware development. In International Conference on
Software Engineering.
Urbaczek, J., Saremi, R., Saremi, M. L., and Togelius, J.
(2021). Greedy scheduling: A neural network method
to reduce task failure in software crowdsourcing. In
International Conference on Enterprise Information
Systems.
Wang, H., Ren, Z., Li, X., and Jiang, H. (2018). Solving
team making problem for crowdsourcing with evolu-
tionary strategy. In 2018 5th International Conference
on Dependable Systems and Their Applications.
Yang, Y., Karim, M. R., Saremi, R., and Ruhe, G. (2016).
Who should take this task? dynamic decision support
for crowd workers. In International Symposium on
Empirical Software Engineering and Measurement.
Yang, Y. and Saremi, R. (2015). Award vs. worker be-
haviors in competitive crowdsourcing tasks. In 2015
ACM/IEEE International Symposium on Empirical
Software Engineering and Measurement (ESEM).
Yue, T., Ali, S., and Wang, S. (2015). An evolutionary and
automated virtual team making approach for crowd-
sourcing platforms. In Crowdsourcing.
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
128
