
On the Statistical Independence of Parametric Representations in
Biometric Cryptosystems: Evaluation and Improvement
Riccardo Musto, Emanuele Maiorana, Ridvan Salih Kuzu, Gabriel Emile Hine and Patrizio Campisi
Roma Tre University, Rome, Italy
Keywords:
Biometric Recognition, Template Protection, Biometric Cryptosystems, Statistical Independence, Finger Vein.
Abstract:
Biometric recognition is nowadays employed in several real-world applications to automatically authenticate
legitimate users. Nonetheless, using biometric traits as personal identifiers raises many privacy and security
issues, not affecting traditional approaches performing automatic people recognition. In order to cope with
such concerns, and to guarantee the required level of security to the employed biometric templates, several
protection schemes have been designed and proposed. The robustness against possible attacks brought to
such approaches has been typically investigated under the assumption that the employed biometric represen-
tations comprise mutually independent coefficients. Unfortunately, the parametric representations adopted in
most biometric recognition systems commonly consist of strongly correlated features, which may be there-
fore unsuitable to be used in biometric cryptosystems since they would lower the achievable security. In this
paper we propose a framework for evaluating the statistical independence of features employed in biometric
recognition systems. Furthermore, we investigate the feasibility of improving the mutual independence of rep-
resentations defined through deep learning approaches by resorting to architectures involving autoencoders,
and evaluate the characteristics of the novel templates through the introduced metrics. Tests performed using
templates derived from finger-vein patterns are performed to evaluate the introduced framework for statistical
independence and the proposed template generation strategies.
1 INTRODUCTION
Biometric recognition systems rely on personal char-
acteristics to define unique identifiers, through which
a user can be automatically recognized and granted
physical or logical access to specific goods or services
(Jain et al., 2011). Thanks to the improved comfort
and security this technology offers, with respect to
traditional recognition techniques using passwords or
tokens, biometric applications are frequently encoun-
tered in our daily lives, from using fingerprint or face
to unlock a mobile device, to employing iris patterns
to enter restricted areas in airports.
Nevertheless, it has to be remarked that, along
with several advantages, the use of biometric traits for
recognition purposes also brings many potential secu-
rity and privacy issues. Actually, in case a biometric
trait is compromised, as it may happen if covertly ac-
quired or stolen by an attacker, it cannot be revoked
or reissued, being it an intrinsic and permanent char-
acteristic of its owner. If the compromised trait is em-
ployed in different applications, all of them are not
secure anymore. Since the number of biometric traits
a subject can exploit is limited, losing the possibility
of relying on one of them is a serious limitation. As
far as privacy is concerned, biometric traits could re-
veal sensitive information about their owners, which
could be exploited for purposes not related to recog-
nition and potentially discriminatory. Exploiting the
uniqueness of biometric traits, it could be also pos-
sible to track the activities of a subject across multi-
ple applications. Actually, the EU General Data Pro-
tection Regulation (GDPR) states that biometric traits
are sensitive and personal data, and should be there-
fore processed ensuring adequate levels of security.
For all the aforementioned reasons, it is therefore
extremely important to design and implement biomet-
ric template protection (BTP) schemes, with the aim
of preserving the identifiers stored in every databases,
guaranteeing the desired properties of renewability,
security, and performance (Nandakumar and Jain,
2015). BTP approaches have been typically cate-
gorized into two major classes: cancelable biomet-
rics (Patel et al., 2015) and biometric cryptosystems
(Rathgeb and Uhl, 2011). The former methods typi-
cally employ non-invertible functions, whose defining
parameters may be made publicly available or not, to
480
Musto, R., Maiorana, E., Kuzu, R., Hine, G. and Campisi, P.
On the Statistical Independence of Parametric Representations in Biometric Cryptosystems: Evaluation and Improvement.
DOI: 10.5220/0010988300003122
In Proceedings of the 11th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2022), pages 480-487
ISBN: 978-989-758-549-4; ISSN: 2184-4313
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

transform the original representations into protected
ones. The latter ones either directly extract binary
keys from the considered biometric traits, or adopt
key-binding approaches, exploiting hashing protocols
to bind biometric templates with binary cryptographic
keys. Biometric cryptosystems typically rely on some
public information, known as helper data, during the
recognition process.
It is worth mentioning that BTP methods rely-
ing on cancelable biometrics are commonly analyzed,
in terms of robustness against attacks trying to re-
cover the original information from the transformed
one, in quite superficial modalities, due to the diffi-
culty in quantitatively evaluating the achievable non-
invertibility, and to the heterogeneity of the proposed
methods, which makes it arduous to define general
metrics upon which quantifying the provided security.
Conversely, rigorous evaluations of biometric cryp-
tosystems security have been often provided in litera-
ture (Simoens et al., 2009), with in-depth information
theoretic studies specifically dedicated to key-binding
approaches, trying to evaluate the amount of informa-
tion leaked by the stored helper data about the original
secret sources (Ignatenko and Willems, 2015).
It has yet to be observed that all the theoretical
evaluations so far carried out to evaluate the security
of biometric cryptosystems have assumed ideal char-
acteristics for the biometric templates to be protected.
Specifically, it is typically assumed that the biomet-
ric representations employed in key-binding schemes
consist of mutually-independent features, an hypoth-
esis allowing to derive conclusions regarding a sin-
gle coefficient and automatically extending them to
the whole set of available features. Unfortunately,
real-world data are not characterized by such an ideal
property, and the loss in security of a biometric cryp-
tosystem is greater the further the available data are
from the ideal condition. It is therefore required to
perform proper investigations to evaluate the extent of
the differences between ideal and real qualities of the
employed biometric representations, having in mind
their exploitation in biometric cryptosystems. Fur-
thermore, it would be desirable to design strategies
for generating biometric representations having prop-
erties as close as possible to the ideal ones, while pre-
serving their discriminative capabilities.
Within the context of biometric cryptosystems, the
present paper addresses the aforementioned aspects,
performing an analysis regarding the statistical inde-
pendence of the features comprised within biometric
templates. Specifically, a novel framework, through
which it is possible to derive quantitative evaluations
on the independence of the considered representa-
tions, is proposed in Section 2, and applied to ana-
lyze templates obtained applying deep learning strate-
gies to biometric data. In more detail, finger-vein pat-
ters are considered as biometric traits in this study.
Furthermore, approaches relying on autoencoders are
employed with the aim of improving the non-ideal
characteristics of the considered templates, as de-
scribed in Section 3. The usability of the generated
templates within a biometric cryptosystem is eval-
uated considering a recently-introduced key-binding
scheme with zero-leakage capabilities (Hine et al.,
2017), summarized in Section 4. The statistical inde-
pendence of the considered representations is tested
through the proposed metrics in Section 5, where
their effectiveness in terms of security and recogni-
tion rates is also evaluated. Conclusions are eventu-
ally drawn in Section 6.
2 FRAMEWORK FOR THE
ANALYSIS OF STATISTICAL
INDEPENDENCE
The proposed framework for the evaluation of statisti-
cal independence in biometric templates relies on the
Hilbert-Schmidt Independence Criterion (HSIC) sta-
tistical test (Gretton et al., 2007), described in Section
2.1. The information gained running HSIC tests are
then processed by methods derived from graph the-
ory (Bondy and Murty, 2008), as detailed in Section
2.2, to provide quantitative metrics about the inde-
pendence of the considered coefficients. In the fol-
lowing discussion, it is assumed that a dataset D of
biometric templates, collected from u subjects for a
total of n samples, each expressed as a feature vector
with length m, is available for the conducted statisti-
cal analysis. The considered data are arranged as an
n × m matrix, with each row being a biometric tem-
plate.
2.1 HSIC Statistical Test
Given two random variables X and Y , the HSIC
test estimates the squared Hilbert-Schmidt norm of
the population of interest, that is, HSIC(P
xy
,F ,G),
where P
xy
is the joint distribution of Z = (X , Y ), and
F and G are two reproducing kernel Hilbert spaces
(RKHS). The null and research hypotheses of the
HSIC test are defined as:
J (Z) : (X × Y )
n
7→ 0,1, (1)
H
0
: P
xy
= P
x
P
y
H
1
: P
xy
6= P
x
P
y
,
(2)
that is, the null hypothesis correspond to independent
X and Y variables.
On the Statistical Independence of Parametric Representations in Biometric Cryptosystems: Evaluation and Improvement
481
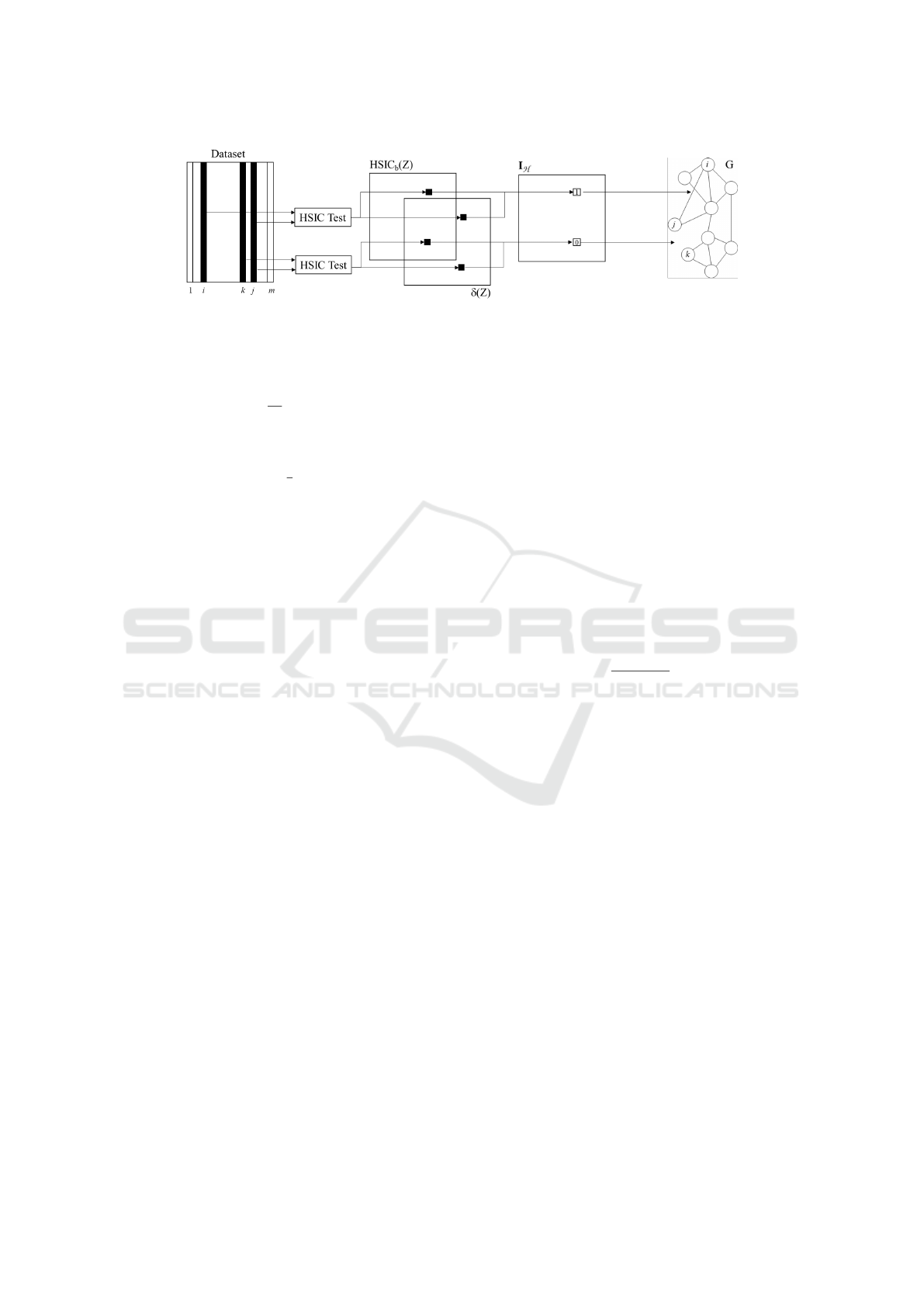
Figure 1: Visual depiction of the proposed framework for statistical independence evaluation.
The desired statistics can be estimated from an ob-
served sample Z = (X,Y ) in a biased version as:
HSIC
b
(Z) =
1
n
2
trace(KHLH),
(3)
that is, computing the sum of elements on the main
diagonal of a square matrix obtained as the product of
the n × n matrices H = I −
1
n
11
>
, K, and L, with the
latter two having as elements:
K(i, j)
:
= exp(−σ
−2
x
||x
i
− x
j
||
2
)
L(i, j)
:
= exp(−σ
−2
y
||y
i
− y
j
||
2
),(i, j) = 1,.. .,n.
(4)
Having set the desired value of the significance
level α for the upper bound of the type I error,
the asymptotic distribution of the empirical estimate
HSIC
b
(Z) is derived under H
0
, and the quantile 1−α
of this distribution, indicated δ(Z), can be used as a
threshold to determine the test outcome. Specifically,
in case HSIC
b
(Z) < δ(Z), it is not possible to reject
the null hypothesis H
0
, thus the two random variables
are assumed as independent.
In our framework the HSIC test is performed for
every possible pairs of features in the considered
m-dimensional biometric representation. An m × m
square and symmetrical independence matrix I
H
∈
Z
m×m
can be thus obtained as:
I
H
[i, j] =
(
1 if HSIC
b
(F
i
,F
j
) < δ(F
i
,F
j
)
0 otherwise,
(5)
where F
i
and F
j
represent any two features in the set
of the m available ones, with samples lying in a R
n
space.
2.2 Graph Theory
Concepts stemming from graph theory are employed
to derive quantitative metrics expressing the degree
of independence of the coefficients in the considered
biometric representation. The computed binary inde-
pendence matrix I
H
can be in fact interpreted as an
adjacency matrix A
G
, thus defining an independence
undirected graph G, with edges connecting nodes as-
sociated to independent coefficients. The overall pro-
cess performed to derive the desired independence
graphs is visually depicted in Figure 1.
In the present paper we consider three different
metrics which can be computed from any undirected
graph G = (V,E,ψ) having nodes N, edges E, and in-
cidence function ψ, namely normalized edge count,
normalized maximum clique size, and normalized de-
gree centrality.
2.2.1 Normalized Edge Count
This metric simply computes the number of edges in
the considered graph G, normalized with respect to
the maximum number of edges in a complete graph
with the same number m of nodes as G, being there-
fore
NEC
m
=
1
m(m − 1)
∑
i, j
I
H
[i, j]. (6)
The obtained value can be interpreted as a per-
centage of independent coefficients. Yet, despite its
simplicity, this metric is weak and not very exhaus-
tive. As a matter of fact, for example, a value of
NEC
m
= 0.9 does not mean that 90% of the features
are mutually statistically independent, but only that
that the independence matrix I
H
contains 90% of uni-
tary entries.
2.2.2 Normalized Maximum Clique Size
A clique of G is defined as a complete subgraph G
0
of G, such that every two distinct nodes in the clique
are adjacent. The clique is said to be maximal if it
is not a subset of another clique, and maximum if it
has the largest number of nodes. In the context here
considered, the size S of the maximum clique of G
is employed as a metric for biometric feature inde-
pendence, once normalized with respect to the largest
possible value, thus obtaining the value NMCS
m
=
S/m.
Since a clique represents a complete subgraph,
this metric gives an effective measure of indepen-
dence: the features in the maximum clique will be
ICPRAM 2022 - 11th International Conference on Pattern Recognition Applications and Methods
482

actually mutually independent. However, this met-
ric presents some criticalities. First, the number of
elements of the maximum clique may not be large,
especially as the number of features increases, return-
ing extremely low independence values that are not
suitable for comparison. Moreover, in the event that
independence is extremely high, the search for this
clique may require a long processing time. Finally,
for a given graph there may be multiple maximum
cliques with the same number of elements, making it
difficult to understand which of them is the best one.
2.2.3 Normalized Degree Centrality
Degree centrality (Freeman, 1978) is a metric which
can be associated to each node i in a graph G, by
computing as d
G
(i) the number of edges incident to
the node itself, that is, its number of connections,
thus quantifying its importance within the graph. The
more important a node is, the more easily it will be
crossed by the information flow. A normalized value
of degree centrality can be computed dividing it by
the maximum feasible degree of the graph, thus ob-
taining
NDC
m
(i) =
d
G
(i)
m − 1
. (7)
In the ideal case of having all the m available
features mutually independent, the maximum clique
would correspond to the graph G itself, and every
node would have a value of normalized degree cen-
trality equal to 1. In the following, when reporting
this metric for the experimental tests described in Sec-
tion 5, the values computed for each node are orga-
nized in a descending order to form a curve, thus bet-
ter representing the deviation from the ideal scenario
of the features under examination. In more detail, the
more the curve of the nodes centrality deviates from
the ideal one with values only at 1, the less the fea-
tures are independent. Such representation also al-
lows to give an indication regarding the number of
more important nodes, that is, the features indepen-
dent of most other coefficients.
3 BIOMETRIC
REPRESENTATIONS
The proposed framework for statistical independence
evaluation has been tested on biometric representa-
tions obtained applying deep learning strategies to
finger-vein patterns. In more detail, the baseline sys-
tem here exploited is the one described in (Kuzu et al.,
2020a), where finger-vein images have been pro-
cessed through a convolutional neural network (CNN)
derived from DenseNet-161 (Huang et al., 2018), with
the addition of a custom set of final layers. In order to
generate representations suitable for verification tasks
in open-set conditions, the loss function employed for
training relies on a cross-entropy function with ad-
ditive angular margin penalty (AAMP) (Deng et al.,
2019). An additional configuration has been here
taken into account as baseline, exploiting ResNext-
101 (Xie et al., 2017) instead of DenseNet-161, while
keeping the same custom set of final layers, and the
same size for the generated representations, compris-
ing 1024 coefficients.
In order to verify whether it is possible to im-
prove the independence of the features generated by
the aforementioned baseline approaches, we have also
evaluated the effectiveness of adding autoencoders
in cascade to the employed networks. An analo-
gous approach has been already proposed in (Kuzu
et al., 2020b), yet the purpose there was improving the
achievable recognition performance, while here the
intended goal would be generating biometric repre-
sentations with more independent features. The ratio-
nale behind the proposed approach resides in the fact
that autoencoders are typically employed to automat-
ically learn efficient encodings of the processed data,
with the aim of reducing the dimensionality of the
input representation while keeping all its informative
content. While pursuing this target, it is also possible
to force the learned representations to assume useful
properties, such as sparseness for example. Within the
context of the present research, the objective would be
therefore to design an autoencoder able to increase the
inner independence of the treated representations.
As autoencoder, we have considered the same
densely-connected convolutional autoencoder (DC-
CAE) proposed in (Kuzu et al., 2020b), consisting
of a total of 55 layers, with an input layer receiving
representations with 1024 coefficients and an inner
encoding producing 256 features, and trained it with
different loss functions. In more detail, the employed
DCCAE has been trained with the aim of minimizing
a loss defined as
L = L
R
+ β · L
S
, (8)
where L
R
represents the reconstruction loss, com-
puted through the cosine dissimilarity
L
R
=
1
B
B
∑
i=1
[1 − cos(f
i
,
ˆ
f
i
)], (9)
being f
i
the i-th feature representation generated by
the baseline CNN,
ˆ
f
i
its counterpart reconstructed by
the autoencoder, and B the employed batch size.
In order to evaluate whether distinct approaches
may have different effectiveness for the sought tar-
get of improving independence, three different loss
On the Statistical Independence of Parametric Representations in Biometric Cryptosystems: Evaluation and Improvement
483

functions have been here considered for the compo-
nent L
S
, namely Kullback-Leibler divergence (KLD),
spectral restricted isometry property (SRIP) (Bansal
et al., 2018), and DeCov (Cogswell et al., 2016).
The L
S
term based on KLD is defined as:
L
KLD
S
=
∑
h∈L
N
(h)
∑
j=1
D
KL
ρk
ˆ
ρ
(h)
j
,
ˆ
ρ
(h)
j
=
1
B
B
∑
i=1
h
a
(h)
j
(f
i
)
i
,
(10)
where a
(h)
j
is the j-th activation output of the h-th hid-
den layer of the DCCAE when f
i
is fed as input to the
DCCAE, with j = 1,...,N
(h)
, being N
(h)
the num-
ber of activation units in the h-th hidden layer, and
ρ ∈ [0, 1] is the sparsity parameter. The set L repre-
sents the layers of the DCCAE dedicated to the inner
encoder and decoder, with L = {26 −29} for the DC-
CAE described in (Kuzu et al., 2020b).
The SRIP regularization forces the weights of the
network to be near-orthogonal, and it is computed on
the weights of each convolutional layer of the pro-
posed DCCAE:
L
SRIP
S
=
55
∑
h=1
σ(W
(h)
)
W
(h)>
W
(h)
− I
, (11)
where W
(h)>
is a matrix with the weights of the h-
th layer, I is the identity matrix and σ is the spectral
norm, defined as the largest singular value of W
(h)
.
The DeCov loss pushes the network to learn non-
redundant representations by minimizing the cross-
covariance of hidden activations through a regulariza-
tion operation. Considering the h-th layer of the em-
ployed DCCAE generating the inner encodings, and
its activations a
(h)
j
, the desired cross-covariance C is
obtained computing, for all the possible pairs of acti-
vations j and k,
C[ j,k] =
1
B
B
∑
i=1
a
(h)
j
(f
i
) − µ
j
a
(h)
k
(f
i
) − µ
k
, (12)
being µ
j
the sample mean of activation j over the
batch, that is,
µ
j
=
1
B
B
∑
i=1
a
(h)
j
(f
i
). (13)
The DeCov loss is then computed as:
L
DeCov
S
=
1
2
(||C||
2
F
− ||diag(C)||
2
2
), (14)
where || · ||
F
is the Frobenius norm.
4 CONSIDERED BIOMETRIC
CRYPTOSYSTEM
In order to verify whether representations generated
as described in Section 3 could be actually em-
Figure 2: Considered zero-leakage biometric cryptosystem
from (Hine et al., 2017).
ployed in a biometric cryptosystems while guarantee-
ing proper recognition and security performance, tests
have been conducted considering the zero-leakage
BTP scheme presented in (Hine et al., 2017), that is, a
code-offset approach inspired by the digital modula-
tion paradigm. As a reference, this method is graphi-
cally depicted in Figure 2.
In brief, it is assumed that a secret binary key
and a biometric representation f ∈ R
m
are available
during enrolment. A point-wise function t(·) is ap-
plied to each coefficient of f in order to derive, from
each of them, a variable with a probability density
function following a raised cosine distribution, de-
scribed by a roll-off parameter γ ∈ [0, 1]. As shown
in (Hine et al., 2017), such transformation guarantees
that the stored helper data cannot reveal any infor-
mation about the employed cryptographic key, thus
implementing a zero-leakage protection scheme. The
roll-off γ of the employed raised cosine distribution
determines the privacy achievable by the proposed
scheme, that is, the minimum reconstruction error an
attacker can commit when trying to estimate the in-
put biometric sample, given the stored helper data.
Specifically, the privacy of the proposed scheme in-
creases with the use of larger values of γ. On the other
hand, as shown in (Hine et al., 2017), large γ values
reduce the capacity of the considered BTP scheme,
that is, the maximum size of the cryptographic key
which can be bind with the employed biometric tem-
plate, thus setting the security of the whole system.
The stored helper data is generated from the input
key and biometric template adopting a quantization
index modulation (QIM) approach, as z = [t(f) − q]
2π
,
where q ∈ {0, 2π/P,...,(P − 1)2π/P}
m
, with P ∈ N
+
,
is a set of symbols belonging to a phase-shift keying
(PSK) constellation of size P, obtained encoding the
input binary key with an error correcting code.
The reverse process is performed during recogni-
tion, with an inverse QIM applied to the combination
of the stored helper data z and the newly acquired bio-
metric representation
ˆ
f, after which a soft decoding
process with decisions based on log-likelihood ratio
(LLR) criteria is performed with the purpose of re-
covering the originally employed cryptographic key.
In case f and
ˆ
f are similar, the hash of the recovered
ICPRAM 2022 - 11th International Conference on Pattern Recognition Applications and Methods
484

Table 1: Comparative analysis of statistical independence
of biometric representations obtained using DenseNet-161
as baseline network. Best results reported in bold.
Metric Baseline ICA
DCCAE
KLD SRIP DeCov
NEC
m
0.152 0.410 0.254 0.250 0.690
NMCS
m
6 9 7 8 19
key corresponds to that of the secret one, and the sub-
ject can be this recognized as a legitimate user.
5 EXPERIMENTAL TESTS
Tests have been performed on finger-vein biometric
traits from the SDUMLA database (Yin et al., 2011),
comprising data from 106 subjects, with three sam-
ples taken from each of three fingers of both hands.
The available data have been divided into two disjoint
datasets of equal size, one used to train the consid-
ered deep learning architectures and the other one to
perform the required evaluations. The employed net-
works have been trained using stochastic gradient de-
scent with momentum (SGDM) and a batch size of
128. The hyperparameters of the DCCAE have been
set, for each considered loss L
S
, with the aim of guar-
anteeing the best achievable performance in terms of
independence of the generated representations.
The independence metrics proposed in Section
2 have been computed performing HSIC tests with
significance level α = 2.5%. A comparative analy-
sis has been conducted in order to evaluate the ef-
fectiveness of the methods in Section 3 to generate
representations with improved independence, which
could be properly used in biometric cryptosystems.
In more detail, in addition to comparing the repre-
sentations generated through the proposed DCCAEs
against those obtained using only the considered base-
line CNNs, we have also taken into account transfor-
mations of the original coefficients obtained through
independent component analysis (ICA) (Hyvarinen
and Oja, 2000). The considered FastICA approach
applies an orthogonal rotation to prewhitened data
in order to maximize a measure of non-Gaussianity,
used as a proxy for statistical independence.
The computed NEC
m
and NMCS
m
independence
metrics are reported in Tables 1 and 2, respectively
for biometric representations obtained when using the
DenseNet-161 and ResNext-101 baseline networks.
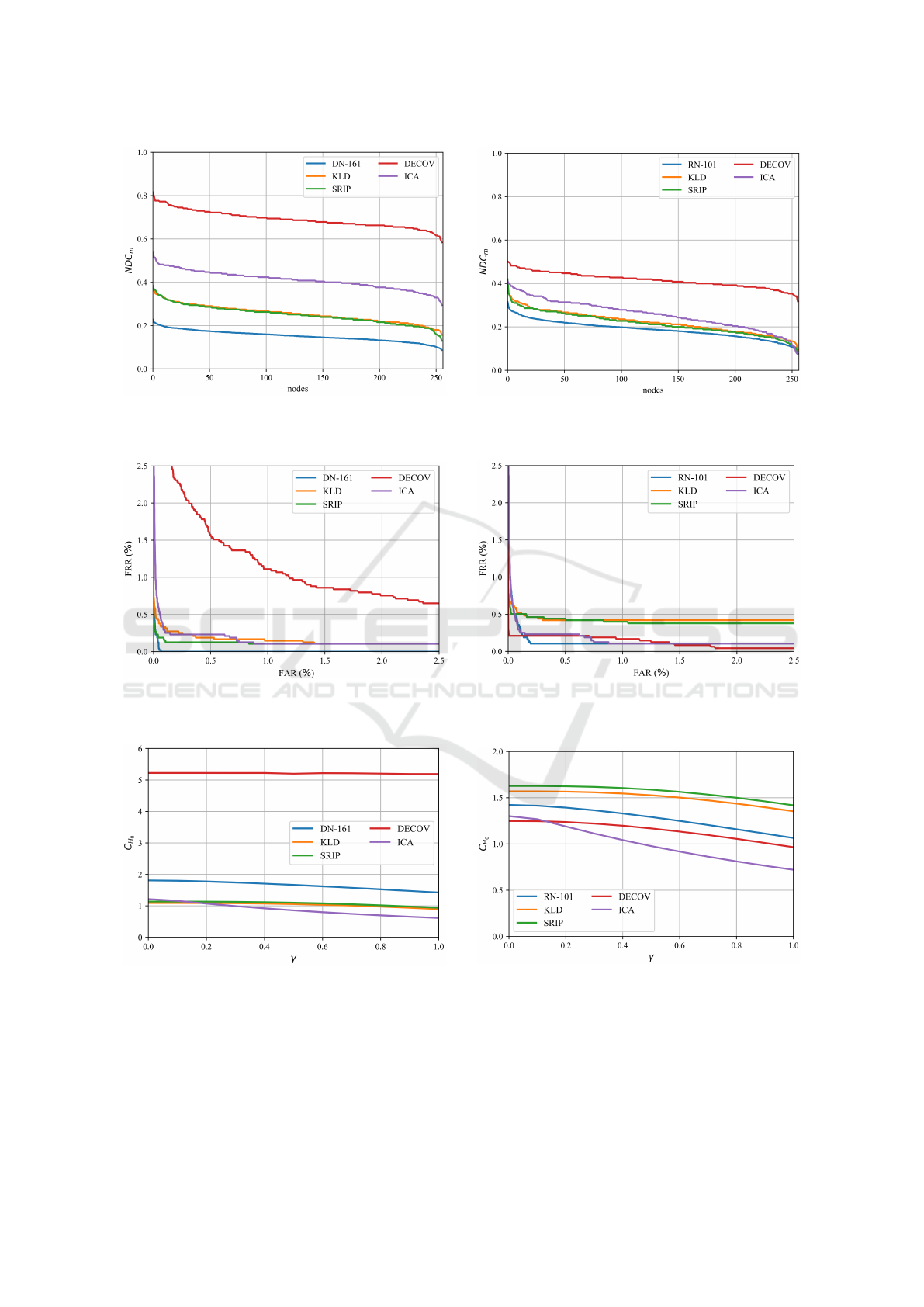
The metrics NDC
m
are instead reported in Figure 3,
which shows the behaviors obtained for all the con-
sidered nodes (coefficients), in order to better illus-
trate the deviation from the ideal conditions with all
values set at 1. It is possible to observe that the pro-
posed approaches relying on KLD and SRIP are able
Table 2: Comparative analysis of statistical independence
of biometric representations obtained using ResNext-101 as
baseline network. Best results reported in bold.
Metric Baseline ICA
DCCAE
KLD SRIP DeCov
NEC
m
0.187 0.256 0.221 0.214 0.415
NMCS
m
8 8 7 7 10
to provide an improvement in terms of NEC
m
and
NDC
m
with respect to the use of representations ob-
tained through the baseline networks. The NMCS
m
is improved when using DenseNet-161 as baseline.
Yet, an ICA transformation guarantee an even fur-
ther independence improvement. Training a DCCAE
with DeCov loss represents the best approach to en-
hance the independence of the considered representa-
tion, with notable improvements in terms of NEC
m
,
NMCS
m
, and NDC
m
for templates obtained through
both DenseNet-161 and ResNext-101. The gains are
especially significant for templates generated with the
DenseNet-161 network, with notable increase of inde-
pendence with respect to ICA too.
In addition to the analysis of the proposed ap-
proaches in terms of independence, other aspects rele-
vant to design biometric cryptosystems are also eval-
uated. The obtained recognition results, in terms of
false rejection rate (FRR) and false acceptance rate
(FAR), are shown by the detection error tradeoffs
(DET) curves of Figure 4, and summarized in terms
of equal error rate (EER) in Table 3. It is impor-
tant to mention that, in this work, the DCCAEs have
been trained to maximize feature independence, dif-
ferently from (Kuzu et al., 2020b) where the networks
have been trained to maximize the achievable recog-
nition performance. Therefore, the DCCAEs here
employed cannot improve the recognition capabilities
offered by the baseline CNN networks as in (Kuzu
et al., 2020b). Actually, the use of SRIP and KLD
losses guarantee results similar to those of baseline
networks, while exploiting the DeCov loss worsen the
recognition performance achievable with DenseNet-
161. As commonly observed in biometric cryptosys-
tem, an improvement in terms of security (here ex-
pressed through the achieved independence) can be
achieved at the cost of a worsening in terms of recog-
nition performance, with security and recognition in-
volved in a trade-off relationship.
The achievable security is also evaluated by com-
Table 3: EERs (in %) obtained with the considered biomet-
ric representations.
Network Baseline ICA
DCCAE
KLD SRIP DeCov
DenseNet-161 0.044 0.586 0.252 0.126 1.072
ResNext-101 0.168 0.230 0.419 0.439 0.209
On the Statistical Independence of Parametric Representations in Biometric Cryptosystems: Evaluation and Improvement
485
(a) (b)
Figure 3: Normalized degree centrality (NDC
m
) computed for the considered representations. (a): DenseNet-161 used as
baseline; (b): ResNext-101 used as baseline.
(a) (b)
Figure 4: DET curves reporting the recognition performance achievable with the considered representations. (a): DenseNet-
161 used as baseline; (b): ResNext-101 used as baseline.
(a) (b)
Figure 5: Average embedding capacity achievable with the considered representations. (a): DenseNet-161 used as baseline;
(b): ResNext-101 used as baseline.
puting the capacities of the employed representations,
reported in Figure 5 in terms of the average number
of bits of a cryptographic key that can be embedded
within the coefficients of the employed representa-
tion. As detailed in (Hine et al., 2017) and mentioned
in Section 4, the achievable capacity depends on the
roll-off parameter γ of the raised cosine distribution
employed in the considered biometric cryptosystem.
ICPRAM 2022 - 11th International Conference on Pattern Recognition Applications and Methods
486

The DeCov loss significantly improves the embedding
capacity with respect to the baseline system relying
on DenseNet-161. It is also worth noting that using an
ICA transformation worsens the capacity achievable
with representations derived with both DenseNet-161
and ResNext-101. The KLD and SRIP loss functions
lead to similar results in terms of channel capacity,
with limited improvements with respect to a baseline
system only for ResNext-101.
6 CONCLUSIONS
In this paper we have proposed a framework to quan-
titatively evaluate the statistical independence of fea-
tures employed within biometric cryptosystems, and
used it to analyze the effectiveness of using cascade
networks including DCCAEs to produce discrimina-
tive and independent biometric representations. Since
each of the proposed metric has its own criticalities, it
is recommended to evaluate a given biometric repre-
sentation considering all of them, rather than drawing
conclusions based on only one. Further developments
could be studied in order to design other metrics with
more informative content. For instance, it would be
possible to define a new centrality measure, possibly
taking into account the difference between the statis-
tics and the thresholds computed by an HSIC test,
and associating greater relevance to pair of features
with greater differences. This way, evaluations could
be performed taking into account the significance of
each test, and not only its binary output. Such met-
ric could be also employed to define effective feature
selection strategies based on statistical independence.
Furthermore, it would be highly desirable to design
novel approaches to automatically learn how to gen-
erate biometric representations with both discrimina-
tive and independence characteristics. To this aim, the
proposed metrics could be integrated within the loss
functions employed during the learning process.
REFERENCES
Bansal, N., Chen, X., and Wang, Z. (2018). Can we gain
more from orthogonality regularizations in training
deep cnns? In Proceedings of the 32nd Interna-
tional Conference on Neural Information Processing
Systems, NIPS’18, page 4266–4276, Red Hook, NY,
USA. Curran Associates Inc.
Bondy, J. and Murty, U. (2008). Graph Theory. Springer
Publishing Company, Incorporated, 1st edition.
Cogswell, M., Ahmed, F., Girshick, R., Zitnick, L., and Ba-
tra, D. (2016). Reducing overfitting in deep networks
by decorrelating representations.
Deng, J., Guo, J., Xue, N., and Zafeiriou, S. (2019). Ar-
cface: Additive angular margin loss for deep face
recognition.
Freeman, L. C. (1978). Centrality in social networks con-
ceptual clarification. Social Networks, 1(3):215–239.
Gretton, A., Fukumizu, K., Teo, C. H., Song, L., Schölkopf,
B., and Smola, A. (2007). A kernel statistical test of
independence. In Proceedings of the 2007 Conference
on Advances in Neural Information Processing Sys-
tems.
Hine, G., Maiorana, E., and Campisi, P. (2017). A zero-
leakage fuzzy embedder from the theoretical formula-
tion to real data. IEEE Transactions on Information
Forensics and Security, 12(7):1724–1734.
Huang, G., Liu, Z., van der Maaten, L., and Weinberger,
K. Q. (2018). Densely connected convolutional net-
works.
Hyvarinen, A. and Oja, E. (2000). Independent component
analysis: Algorithms and applications. Neural Net-
works, 13(4-5):411–430.
Ignatenko, T. and Willems, F. (2015). Fundamental lim-
its for privacy-preserving biometric identification sys-
tems that support authentication. IEEE Trans. on In-
formation Theory, 61(10):5583–5594.
Jain, A., Ross, A., and Nandakumar, K. (2011). Introduc-
tions to biometrics. SPRINGER.
Kuzu, R., Maiorana, E., and Campisi, P. (2020a). Loss func-
tions for cnn-based biometric vein recognition. In Eu-
ropean Signal Processing Conference (EUSIPCO).
Kuzu, R. S., Maiorana, E., and Campisi, P. (2020b). Vein-
based biometric verification using densely-connected
convolutional autoencoder. IEEE Signal Processing
Letters, 27:1869–1873.
Nandakumar, K. and Jain, A. K. (2015). Biometric tem-
plate protection: Bridging the performance gap be-
tween theory and practice. IEEE Signal Processing
Magazine, 32(5):88–100.
Patel, V. M., Ratha, N. K., and Chellappa, R. (2015). Cance-
lable biometrics: A review. IEEE Signal Processing
Magazine: Special Issue on Biometric Security and
Privacy, 32(5):54–65.
Rathgeb, C. and Uhl, A. (2011). A survey on biometric
cryptosystems and cancelable biometrics. EURASIP
Journal on Information Security, 3:1–25.
Simoens, K., Tuyls, P., and Preneel, B. (2009). Privacy
weaknesses in biometric sketches. In 2009 30th IEEE
Symposium on Security and Privacy, pages 188–203.
Xie, S., Girshick, R., Dollár, P., Tu, Z., and He, K. (2017).
Aggregated residual transformations for deep neural
networks.
Yin, Y., Liu, L., and Sun, X. (2011). Sdumla-hmt: A mul-
timodal biometric database. In Sun, Z., Lai, J., Chen,
X., and Tan, T., editors, Biometric Recognition, pages
260–268, Berlin, Heidelberg. Springer Berlin Heidel-
berg.
On the Statistical Independence of Parametric Representations in Biometric Cryptosystems: Evaluation and Improvement
487
