
Keep It Up: In-session Dropout Prediction to Support Blended
Classroom Scenarios
Nathalie Rzepka
1
, Katharina Simbeck
1
, Hans-Georg Müller
2
and Niels Pinkwart
3
1
University of Applied Sciences Berlin, Treskowallee 8, 10318 Berlin, Germany
2
Department of German Studies, University of Potsdam, Am neuen Palais 10, 14469 Potsdam, Germany
3
Department of Computer Science, Humboldt University of Berlin, Unter den Linden 6, 10099 Berlin, Germany
Keywords: Dropout Prediction, VLE, Blended Classroom.
Abstract: Dropout prediction models for Massive Open Online Courses (MOOCs) have shown high accuracy rates in
the past and make personalized interventions possible. While MOOCs have traditionally high dropout rates,
school homework and assignments are supposed to be completed by all learners. In the pandemic, online
learning platforms were used to support school teaching. In this setting, dropout predictions have to be de-
signed differently as a simple dropout from the (mandatory) class is not possible. The aim of our work is to
transfer traditional temporal dropout prediction models to in-session dropout prediction for school-supporting
learning platforms. For this purpose, we used data from more than 164,000 sessions by 52,000 users of the
online language learning platform orthografietrainer.net. We calculated time-progressive machine learning
models that predict dropout after each step (completed sentence) in the assignment using learning process
data. The multilayer perceptron is outperforming the baseline algorithms with up to 87% accuracy. By ex-
tending the binary prediction with dropout probabilities, we were able to design a personalized intervention
strategy that distinguishes between motivational and subject-specific interventions.
1 INTRODUCTION
With the onset of the COVID-19 pandemic, many
schools in Germany had to close on short notice and
teachers were forced to switch to online formats. Af-
ter more than a year of the pandemic, school closures
continued for weeks at a time, resulting in distance
formats becoming established in many schools. This
may have been the starting point for the use of digital
teaching methods, persisting even after the pandemic.
The use of digital instructional offerings can reduce
teacher workload and support internal differentiation
(Gerick et al. 2016, Kepser 2018).
In online learning platforms, dropout prediction
models are often used to provide early interventions
for at-risk users. Many studies are particularly con-
cerned with MOOCs, as dropout rates of up to 90%
are found (Kloft et al. 2014, Xing and Du 2019).
However, dropout prediction models in MOOCs have
quite different requirements to dropout prediction in
online learning platforms that support school teach-
ing:
(1) Voluntariness: most people in MOOCs partici-
pate voluntarily, while completing homework in
school is usually mandatory.
(2) Time Frame: MOOCs provide over several
weeks with a defined end. It is up to the users
how quickly they complete the course. The use
of a learning platform that accompanies school
lessons, on the other hand, depends primarily on
how the curriculum is defined as a whole.
(3) Drop Out: In the German school system you
cannot fail a single subject, but only a entire class
level. Thus, the definition of dropping out as it is
defined in MOOCs cannot be applied to school
settings.
(4) Integration: In school the subject matter is not
taught exclusively via an online course. Rather,
lessons are taught in the classroom, and accom-
panying exercises and homework take place on
the online platform.
Dropout prediction for a school assignment plat-
form is therefore in many respects different from
MOOC dropout prediction. The goal of this paper is
to translate existing research on dropout prediction to
Rzepka, N., Simbeck, K., Müller, H. and Pinkwart, N.
Keep It Up: In-session Dropout Prediction to Support Blended Classroom Scenarios.
DOI: 10.5220/0010969000003182
In Proceedings of the 14th International Conference on Computer Supported Education (CSEDU 2022) - Volume 2, pages 131-138
ISBN: 978-989-758-562-3; ISSN: 2184-5026
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
131

the reality of blended learning scenarios.We therefore
consider the early termination of a single session in-
stead of the dropout of the entire course. We define a
session as a limited time interval during which the
user is working on the completion of an assignment
consisting of several exercises. Leaving a session
early should be avoided, as the exercises of the as-
signments didactically build on each other. Predicting
this dropout provides the opportunity for interven-
tions in adaptive learning environments. These inter-
ventions can, for example, adjust task difficulty, dis-
play orthographic rules, or display motivational gam-
ified texts. This increases the motivation of the user
and leads to higher learning success. Therefore, the
research questions are as follows:
RQ1: How effective are machine learning models in
predicting dropout within a session?
RQ2: How can the predicted dropout probabilities be
used for in-session intervention to prevent early exit?
To this end, we first summarize the current re-
search on dropout prediction and learning analytics
intervention. Then we describe the underlying dataset
and the feature engineering of our study and the used
orthografietrainer.net platform. Next, the results of
the different models are compared using different
metrics for evaluation. Finally, the results are inter-
preted and discussed
2 RELATED WORK
2.1 Dropout Prediction in Online
Learning Environments
There are numerous studies on dropout prediction in
online learning environments. Many of these studies
examine dropouts in MOOCs (Dalipi et al. 2018,
Kloft et al. 2014, Xing and Du 2019). MOOCs do of-
fer many advantages, however, they have dropout
rates of up to 90% (Kloft et al. 2014, Xing and Du
2019). Dalipi et al. (2018) present several factors re-
sponsible for the high dropout rate. These include per-
son-related factors, such as a lack of motivation and
time, and course-related factors, such as poor course
design, too little interaction, and hidden costs. Drop-
out prediction models therefore show great potential
to define at-risk students and prevent dropout through
appropriate intervention measures (Xing and Du
2019).
Research on session dropout prediction, on the
other hand, is found less frequently. Lee et al. (2020)
investigated a session dropout prediction in an online
learning environment and proposed the Deep Atten-
tive Study Session Dropout Prediction (DAS) as a
new Transformer based encoder-decoder model. In
their work, Lee et al. (2021) combined knowledge
tracing with session dropout prediction and were able
to improve the area and receiving operator curve by
3.62% using Lee’s DAS model.
Xing and Du (2019) define three different investi-
gation paths that are often followed in prediction
models: fixed-term dropout prediction, temporal
dropout prediction, and dropout prediction model per-
formance optimization. Fixed-term dropout predic-
tion uses data from a defined period of time to per-
form the predictions. This comes with the disad-
vantage that interventions often cannot be applied
early enough. Other studies only use data from the
first week of the course to identify early dropouts.
This makes it impossible to distinguish in which of
the next weeks a person drops out. As a result, many
students are classified at-risk, and no accurate inter-
vention or personalized feedback is possible. Tem-
poral Dropout Prediction models use data from all the
previous weeks and are supposed to predict which
user will drop out in the next week. This leads to a
much smaller number of at-risk users, which makes it
possible to focus on those users. To be able to plan
personalized interventions, it would be appropriate to
calculate the dropout probability. Dropout prediction
model optimization deals with possibilities to im-
prove the model performances, for example with ap-
proaches using sentiment features in comments or us-
ing deep learning algorithms (Xing and Du 2019).
For prediction, most studies mainly use click-
stream data, which are calculated from log data in
online platforms (Sun et al. 2019, Xing and Du 2019).
They include all interactions a user has with the
course and in temporal dropout prediction models,
these must be considered individually for each week
(Hagedoorn and Spanakis 2017). Since this is a binary
classification problem, most models use supervised
learning algorithms to build the models for dropout
prediction (Liang et al. 2016). In a review by Dalipi
et al. (2018), logistic regression was the most used
machine learning model, followed by support vector
machines (SVM) and decision trees. Hidden Markov
models or survival analysis are used less frequently.
Other studies use deep neural networks or recurrent
neural networks (RNNs) which can outperform clas-
sical ML model (Sun et al. 2019, Dalipi et al. 2018,
Xing and Du 2019). Deep learning models use neural
network architecture with multiple hidden layers and
CSEDU 2022 - 14th International Conference on Computer Supported Education
132

gain great results without the need for time consum-
ing feature engineering processes before (Hernández-
Blanco et al. 2019). In their review of deep learning
in educational data mining, Hernández-Blanco et al.
(2019) found that in 67% of the reviewed articles, the
deep learning model outperformed traditional ma-
chine learning approaches.
Research on dropout prediction is therefore well
advanced and has already been examined from vari-
ous sides. However, the study of courses in MOOCs
or universities, which are designed for longer periods
of time, plays a particularly important role. In-session
dropout prediction is less studied and especially
online environments that support and supplement
classroom learning have not been explored in studies
to date. Yet the use of these environments has in-
creased dramatically, partly due to the pandemic.
With this work, we hope to make a valuable contribu-
tion to in-session dropout prediction in blended learn-
ing scenarios.
2.2 Learning Analytics Intervention
Insights and predictions in the learning analytics field
allow strong conclusions to be drawn about student
learning behavior. However, to have a real impact, the
insights gained must also be meaningfully integrated
within learning analytics interventions. The goal is to
prevent academic failure at an early stage by monitor-
ing progress data and providing personalized and ap-
propriate support (Wong and Li 2020). Interventions
are considered as the “biggest challenge in learning
analytics” (Wong and Li 2018). Wise (2014) defines
learning analytics interventions as "the surrounding
frame of activity through which analytic tools, data,
and reports are taken up and used. It is a soft technol-
ogy in that it involves the orchestration of human pro-
cesses, and this does not necessarily require the crea-
tion of a material artifact.". The design of learning an-
alytics interventions thus plays a significant role in
how helpful the use of information obtained through
learning analytics is (Na and Tasir 2017).
Learning analytics interventions comes with dif-
ferent purposes: they can improve students’ success
and course performance, as well as retention, motiva-
tion, or participation (Na and Tasir 2017). Wong and
Li (2018) categorized learning analytics interventions
into four types: direct message, actionable feedback,
categorization of students, and course redesign. In
their review, most of the interventions used the
method of direct messages, which includes telephone
calls, emails or private messages to both, students at-
risk and their tutors. These messages contain, for ex-
ample, information about additional help or counsel-
ing (Dawson et al. 2017, Milne 2017), encouraging
messages to use online resources (Blumenstein 2017,
Smith et al. 2012), or information to notify the tutor
about students at-risk (Herodotou et al. 2017). The
method of actionable feedback provides the students
with their own performance data, for example via a
dashboard that describes their learning behavior
(Wong and Li 2018). Less common than direct mes-
sage and actionable feedback are the intervention
methods “categorization of students” and “course re-
design”. Categorization of students was done in vari-
ous degrees to indicate risk levels. Interventions were
then performed per category. Course redesign oc-
curred very infrequently in the review and involved
adjusting the course based on the information ob-
tained. Information on dropout rates and at-risk stu-
dents can also be used to evaluate instructors and
course design.
In our article, we propose the prediction of stu-
dents’ early termination to gain valuable insights that
will enable these interventions to be designed and ap-
plied in a personalized way.
3 METHODOLOGY
3.1 Orthografietrainer.net
The online platform orthografietrainer.net is a learn-
ing platform to acquire German spelling skills. It con-
tains exercise sets on various aspects of the German
language, such as capitalization, comma formation,
separated and combined spelling, and sounds and let-
ters. Furthermore, exercises on German grammar are
available. The platform is mainly used in blended
classroom scenarios. The teacher registers the entire
class on the platform and then assigns tasks as home-
work from the spelling area that was discussed in
class. This is the most common form of use of the
platform. During the COVID-19 pandemic, the ac-
cess rates have risen sharply as many new teachers
started using the platform. The platform addresses
mainly school classes from fifth grade to graduating
classes. The data set consists of 181,792 assignments,
164,580 sessions and 3,224,014 answered sentences.
These were completed by 52,032 users in the period
03-01-2020 to 04-31-2020. There are different terms
to be defined before explaining the didactic structure
of the platform:
(1) Exercise Set: A set of sentences, consisting of 10
sentences. Further sentences are added automati-
cally if a sentence is not solved correctly.
Keep It Up: In-session Dropout Prediction to Support Blended Classroom Scenarios
133
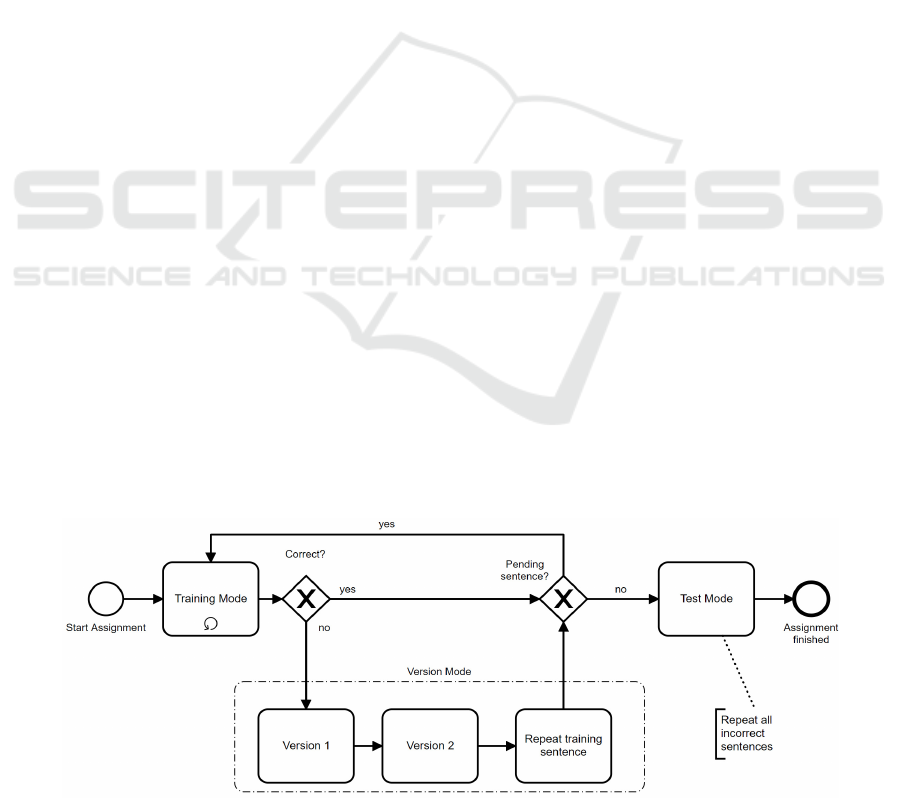
(2) Sentence: One sentence containing one or sev-
eral gaps to be filled in by the user.
(3) Assignment: Assigned exercise set which is dis-
played to the user as pending; generally as home-
work.
(4) Session: Period of time a user is working on the
exercise set.
(5) Dropout: Termination of the session without
completing the exercise set; after dropout, the as-
signment is still pending.
A peculiarity of the platform is the didactic struc-
ture of the exercise sets. The platform focusses less
on learning German spelling rules and more on re-
peated practice. The typical exercise process is there-
fore as follows: the teacher teaches a sub-area of Ger-
man spelling in traditional lessons and assigns exer-
cise sets on the online platform to students as home-
work. The homework is displayed to the students as
pending assignments. Each exercise contains ten dif-
ferent sentences. Each training sentence is available
in at least three versions representing the same ortho-
graphical spelling problem in different verbal con-
texts and words. The program starts in the training
mode (1) which shows sentence 1 of the exercise set.
If sentence 1 is solved correctly, sentence 2 is dis-
played, then sentence 3 is displayed as well. The ex-
ercise set is successfully finished after 10 sentences if
the user makes no mistakes.
If the learner has made a mistake, the program
switches to version mode (2). Here the previously in-
correct sentence is displayed again until the user an-
swers it correctly. The solution is displayed and the
previous incorrect sentence is tested again immedi-
ately after. If it has now been answered correctly, the
other two versions of the sentence are displayed. If
the versions have been answered correctly, the incor-
rect sentence from the beginning is displayed again
and - if the sentence is now answered correctly - the
version mode is terminated. The program then
switches back to training mode.
At the end of the training mode the test mode fol-
lows (3), in which all sentences that were once an-
swered incorrectly are displayed again. As a result,
the assignment takes longer the more mistakes are
made by a user. Figure 1 shows the process of an as-
signment at orthografietrainer.net.
The students have the possibility to leave the ses-
sion at any time and continue working on the assign-
ment at another time. After 45 minutes of inactivity,
a user is automatically logged out. As described be-
fore, the task process is automatically extended if a
user makes mistakes: before moving on with the next
sentence, versions of the mistaken sentence are dis-
played, as well as the wrong sentence is tested again.
A session is thus considered terminated if it is left
without completing the exercise set. This can either
be the case when the required 10 sentences have not
been answered, or if there are more than 45 minutes
between two sentences. If the latter is the case it is
possible that the assignment is resumed later and fin-
ished successfully. In our data set, this is then defined
as one assignment which is worked on in two ses-
sions. The first session is considered dropped out, the
second is considered as finished successfully.
3.2 Feature Selection & Engineering
Our analysis is intended to predict whether a user will
interrupt the session before completing the exercise
set on the basis of the learning process data. Although
these are text tasks, no text analysis is carried out. The
tasks are either correct or incorrect, no further analy-
sis (e.g. of the type of error) is done. The information
as to whether the user terminates the exercise prema-
turely has not yet been stored in the database and is
therefore calculated separately. In addition to the fea-
tures of the learning process shown in table 1, features
of the assignment and session are calculated (table 2).
Figure 1: Task Process at orthografietrainer.net.
CSEDU 2022 - 14th International Conference on Computer Supported Education
134

Table 1: User Features.
Name Description
Field Field of grammar
Class level Class level of the user
Gender Gender of the user
Test position Mode in which the sentence is
displayed
User Attribute Group of users
First Reading
Describes, if the sentence is dis-
played for the first time to the
user
Distracted
Describes, if the user submitted
a task while missing a field
Success Describes, if the answer is cor-
rect
Difficulty Difficulty of the sentence
Years regis-
tered
Count of years the user is regis-
tered at the platform
Pending Count of pending tasks
School
Describes whether the sentence
was processed in school time
Multiple false Describes, if the same sentence
was answered incorrectly sev-
eral times
Datetime
Date and time when the sen-
tence was processed
Table 2: Session Features.
Name Description
Break Describes, if an assignment has
more than one session
Session No.
Session number of the assign-
ment
Order No. Order number of the sentence
Previous
Break
Describes, if this assignment was
interrupted earlier
Steps Describes the difference be-
tween the next possibility to fin-
ish an assignment and the current
sentence number
The "Break" feature describes an exercise that has
been interrupted. The exercise is then divided into
two sessions, which are defined by the "Session No."
feature. Each session contains N records of answered
sentences, which are ordered by time by the "Order
No." feature. The feature "Previous Break" shows if
and how often the assignment has been interrupted.
Table 2 shows the session features.
The structure of the exercise process results in
many exercises being completed at sentence numbers
10, 14, 18, or
22 sentences. A sum of 10 sentences
occurs when the user does not make a single mistake.
A sum of 14 sentences occurs when the user makes
one mistake: Thus, each error adds 4 extra sentences
that must be answered. While this is true for many
assignments, it is not true for all. For example, if a
user makes a second error in version mode, the loop
becomes one level deeper. To explain this specific
task structure in the model as well, the feature “Steps”
is added. This feature describes the difference be-
tween the next possibility to finish an assignment and
the current sentence number.
After preprocessing and feature engineering, the
features were one-hot encoded. This led to a number
of 24 input variables. As the successfully completed
assignments outweighed the unsuccessful ones, the
ratio of successfully / unsuccessfully completed as-
signments was balanced.
3.3 Matrices & Machine Learning
Models
The goal of this research is to predict the dropout
probability within a session. MOOC dropout predic-
tions are usually estimated after several weeks of part
icipation. In this case however, we re-estimate drop-
out prediction after every single sentence. Every time
a user submits a sentence, the prediction model is up-
dated using all sentences answered so far. Thus, the
matrix used by the prediction model grows over the
course of the session. The sentence position can take
values from 1 (beginning of exercise) to 300 (if many
mistakes were made). Since few sessions span more
than 60 sentences, up to 60 matrices are created for
every user. A matrix is defined by:
𝐴
:
1, … , 𝑚
×
1, … , 𝑛
→𝐾,
𝑖,
𝑗
⟼ 𝑎
,
(1)
𝑖=1,…,𝑚𝑎𝑛𝑑
𝑗
=1,…𝑛
(2)
The variables m and n define the number of lines
and columns of the matrix. Here, i describes the lines
of the matrix which represents one session. Further, j
is defined as the columns of the matrix where each
column is representing one feature. Each entry a
ij
is
thus representing a feature j in session i. Each matrix
represents a sentence position and contains the an-
swered sentence of the respective sentence position
and all previous ones. Matrix 1 thus contains all the
first sentences of the sessions, and matrix 2 contains
the first two sentences.
Keep It Up: In-session Dropout Prediction to Support Blended Classroom Scenarios
135
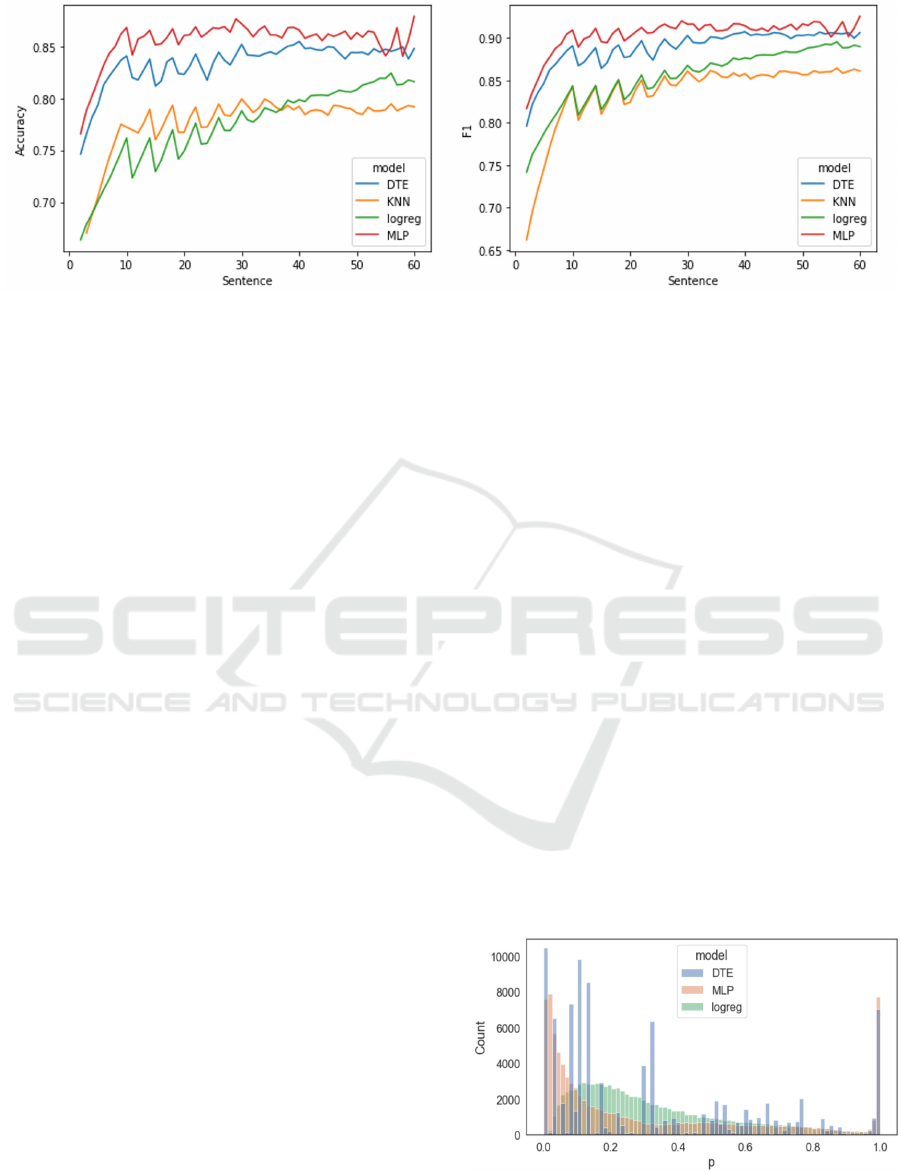
Figure 2: Accuracy and F1-Score per Sentence and Model (DTE=Decision Tree Classifier, KNN=k-Nearest Neighbor,
logreg=Logistic Regression, MLP= multilayer perceptron).
In this study, three popular machine learning mod-
els were implemented as baseline algorithms to com-
pare to the multilayer perceptron (MLP): logistic re-
gression (logreg), decision tree classifier (DTE) and
k-nearest-neighbor (KNN). We follow the selection
of models by Xing and Du (2019) and the most fre-
quent models found in the review by Dalipi et al.
(2018). In our decision tree model (DTE), we use en-
tropy as a criterion to measure the quality of a split
and define the maximum depths of the tree as 5. The
multilayer perceptron (MLP)
consists of an input
layer with 24 input variables. The three fully con-
nected hidden layers (48, 24, and 12 nodes), as well
as the input layer, apply the rectified linear unit func-
tion (ReLu). As we are facing a binary classification
problem, the output layer applied the sigmoid func-
tion and as a loss function, we use binary cross-en-
tropy. To reduce bias, we additionally apply 5-fold
cross-validation.
The models described above are designed to pre-
dict whether a user will terminate the session prema-
turely. Most of the models are not only capable of
making a binary statement, but also of estimating the
probability of termination. Accordingly, we calculate
the probability of early exit for each session in order
to take appropriate interventions with this infor-
mation. This way, interventions can be personalized:
the higher the probability of termination, the stronger
the interventions will be.
4 RESULTS
Figure 2 shows the performance of the different ma-
chine learning algorithms. Specifically, all models
show an increasing accuracy over time. While the
curve initially rises sharply up to sentence 10, it flat-
tens out in the further course and approaches a peak
value. The MLP has the highest overall accuracy, up
to 87%. The decision tree classifier is also very good,
but is still slightly worse than the MLP at almost all
points in time and reaches a maximum value of about
85%. The other models are closer together and reach
up to 80% accuracy. The KNN model performs worst,
remaining below 80%.
We furthermore calculated the importance of the
features on the logistic regression model. Here we see
that especially success and task difficulty have an in-
fluence. Other important features are previous break,
i.e. whether the assignment has already been worked
on in a previous session, the class level, the assign-
ment type, capitalization and the user attribute. The
most important feature in the Decision Tree Classifier
is count wrong, i.e. the total number of errors. In the
KNN model, it is as well count wrong, additionally to
first reading, success and the three features indicating
the testposition.
In addition to the binary statements as to whether
a session is terminated prematurely or not, many
models also calculate a termination probability. This
does not apply to the KNN model and it is therefore
not included in the further discussion. Figure 3 shows
Figure 3: Probability distribution per model (DTE=Deci-
sion Tree Classifier, logreg=Logistic Regression, MLP=
multilayer perceptron).
CSEDU 2022 - 14th International Conference on Computer Supported Education
136

the distribution of the probabilities per model. Here
we can see that the distributions vary between the
models. The distribution of the logistic regression
model is denser and spreads mainly between 0.05 and
0.5. Few very low and few very high probabilities are
predicted. The MLP model on the other hand predicts
many low probabilities up to 0.1 and many high ones
up to 1.0, but few in the middle of the distribution.
The DTE model shows single high values and no
smooth distribution.
5 DISCUSSION
Following our two research questions, we have
shown that dropout prediction models can be applied
not only in the context of MOOCs over multiple
weeks, but also in the context of learning platforms
that accompany classroom teaching. Instead of pre-
dicting over a period of several weeks, we were able
to build models for local prediction, predicting early
termination within a session and providing the oppor-
tunity to offer in-session interventions.
Previous studies on dropout prediction in MOOCs
showed that the MPL outperformed the other
models.
This was also the case when transferring the research
to our blended learning scenario. The accuracy of the
in-session models was worse than that of the MOOC
prediction models. Xing and Du (2019), for example,
achieved an accuracy of 96% while our model could
only reach up to 87%. This can be explained by the
different data basis: in MOOCs, all clickstream data
is used over several weeks, whereas in our models
much less interaction takes place (namely only within
one session). Our analysis also calculated feature im-
portance and showed that the most important features
for in-session dropout prediction are success, task dif-
ficulty, and count of wrong tasks.
In our study, we have also gone one step further
and extended the mere prediction of early termination
with specific termination probabilities to design per-
sonalized learning analytics interventions. The drop-
out probability allows us to better differentiate be-
tween different interventions, which vary depending
on the level of dropout probability.
5.1 Outlook & Limitations
In this paper, we have shown that dropout prediction
models can be applied to classroom supporting online
learning. Using didactic and data-driven thresholds,
we are now able to propose interventions for several
probability domains that better match user needs.
Moreover, session dropout prediction can be used not
only to provide adequate interventions to learners but
also to improve learning paths in the learning envi-
ronment and to inform course creators about frequent
obstacles to exercise completion. Learning analytics
interventions can be designed on different bases (de-
scribed in related work). However, the actual inter-
ventions are then highly dependent on the specific
learning platform. In the case of the ortho-
grafietrainer.net learning platform, which is used to
acquire spelling and grammar skills, different inter-
ventions make sense based on the subject-specific
tasks and the structure of the assignments:
• To increase motivation, basic motivational mes-
sages or a display of the number of sentences still
pending can be implemented
• If users have problems with a certain sentence, they
sometimes cannot get out of the loop of versions.
In this case, it makes sense to release the user from
the loop and continue with the next sentence once
a certain probability has been reached.
• The difficulty of the sentences can be adjusted so
that the user has a higher probability of solving the
sentences correctly and thus completing the exer-
cise.
Basically, interventions can be divided into moti-
vational and subject-specific interventions. Motiva-
tional interventions only serve to further encourage
users and to keep them engaged by means of displays
or gamification elements. Subject-specific interven-
tions, on the other hand, adapt the tasks, for example,
the sentence sequencing or the difficulty. They thus
have an impact on what is learned and therefore offer
a stronger intervention method. The distinction be-
tween intervention types can be used to apply differ-
ent interventions starting at different thresholds de-
pending on dropout probabilities. Future research
should implement and evaluate these very interven-
tions in blended classroom scenarios to validate the
effectiveness of this approach.
An important limitation in our study is the fact
that the students do the homework at home and are
confronted with other confounding factors there.
Therefore, it can never be ruled out whether a drop-
out from the session is actually related to the learning
experience or has resulted from the surrounding cir-
cumstances. Furthermore, we have no information
about the way in which the platform is integrated into
the school lessons. For example, it can make an enor-
mous difference whether homework is graded or not.
This information could be included in the future by,
as an example, a survey for teachers using the plat-
form.
Keep It Up: In-session Dropout Prediction to Support Blended Classroom Scenarios
137

ACKNOWLEDGEMENTS
This research was funded by the Federal Ministry of
Education and Research of Germany in the frame-
work “Digitalisierung im Bildungsbereich” (project
number 01JD1812A).
REFERENCES
Blumenstein, M. (2017). The Student Relationship Engage-
ment System (SRES). In Building an Evidence Base
For Teaching and Learning Design Using Learning An-
alytics, 31.
Sun, D.; Mao, Y.; Du, Y.; Xu, P.; Zheng, Q.; and Sun, H.
(2019). Deep Learning for Dropout Prediction in
MOOCs. In 2019 Eighth International Conference on
Educational Innovation through Technology (EITT),
87–90.
Dalipi, F.; Imran, A. S.; and Kastrati, Z. (2018). MOOC
Dropout Prediction Using Machine Learning Tech-
niques: Review and Research Challenges. In 2018
IEEE Global Engineering Education Conference
(EDUCON), 1007-1014. IEEE 2018.
Dawson, S.; Jovanovic, J.; Gašević, D.; and Pardo, A.
(2017). From prediction to impact: Evaluation of a
learning analytics retention program. In Proceedings of
the Seventh International Learning Analytics &
Knowledge Conference. ACM, 474–478.
DOI=10.1145/3027385.3027405.
Gerick, J.; Eickelmann, B.; and Bos, W. (2016). Zum
Stellenwert neuer Technologien für die individuelle
Förderung im Deutschunterricht in der Grundschule. In
Individualisierung im Grundschulunterricht. Anspruch,
Realisierung und Risiken, 131–136.
Hagedoorn, T. R.; and Spanakis, G. (2017). Massive Open
Online Courses Temporal Profiling for Dropout Predic-
tion. In 2017 IEEE 29th International Conference on
Tools with Artificial Intelligence (ICTAI), 231–238.
Hernández-Blanco, A.; Herrera-Flores, B.; Tomás, D.; and
Navarro-Colorado, B. (2019). A Systematic Review of
Deep Learning Approaches to Educational Data Min-
ing. In Complexity 2019, 1–22.
Herodotou, C.; Heiser, S.; and Rienties, B. (2017). Imple-
menting randomised control trials in open and distance
learning: a feasibility study. In Open Learning: The
Journal of Open, Distance and e-Learning 32, 2, 147–
162.
Liang, J.; Yang, J.; Wu, Y.; Li, C.; and Zheng, L. (2016).
Big Data Application in Education: Dropout Prediction
in Edx MOOCs. In 2016 IEEE Second International
Conference on Multimedia Big Data (BigMM), 440–
443.
Milne, J. (2017). Early alerts to encourage students to use
Moodle. In Building an evidence base for teaching and
learning design using learning analytics, 24–30.
Kepser, M. (2018). Digitalisierung im Deutschunterricht
der Sekundarstufen. Ein Blick zurück und Einblicke in
die Zukunft. In Mitteilungen des Deutschen
Germanistenverbandes 65, 3, 247–268.
Lee, S.; Kim, K. S.; Shin, J.; and Park, J. (2021). Tracing
Knowledge for Tracing Dropouts: Multi-Task Training
for Study Session Dropout Prediction. In Educational
Data Mining Conference 2021.
Lee, Y.; Shin, D.; Loh, H.; Lee, J.; Chae, P.; Cho, J.; Park,
S.; Lee, J.; Baek, J.; Kim, B.; and Choi, Y. (2020).
Deep Attentive Study Session Dropout Prediction in
Mobile Learning Environment. arXiv preprint
arXiv:2002.11624.
Kloft, M.; Stiehler, F.; Zheng, Z.; and Pinkwart, N. (2014).
Predicting MOOC Dropout over Weeks Using Machine
Learning Methods. In Proceedings of the 2014 Confer-
ence on Empirical Methods in Natural Language Pro-
cessing (EMNLP), 60–65.
Na, K. S.; and Tasir, Z. (2017). A Systematic Review of
Learning Analytics Intervention Contributing to Stu-
dent Success in Online Learning. In Fifth International
Conference on Learning and Teaching in Computing
and Engineering - LaTiCE 2017. 62–68.
DOI=10.1109/LaTiCE.2017.18.
Smith, V. C.; Lange, A.; and Huston, D. R. (2012). Predic-
tive Modeling to Forecast Student Outcomes and Drive
Effective Interventions in Online Community College
Courses. In Journal of Asynchronous Learning Net-
works 16, 3, 51–61.
Wise, A. F. (2014). Designing pedagogical interventions to
support student use of learning analytics. In Proceed-
ings of the Fourth International Conference on Learn-
ing Analytics And Knowledge - LAK '14. 203–211.
DOI=10.1145/2567574.2567588.
Wong, B. T.; and Li, K. C. (2018). Learning Analytics In-
tervention: A Review of Case Studies. In 2018 Interna-
tional Symposium on Educational Technology (ISET).
178–182. DOI=10.1109/ISET.2018.00047.
Wong, B. T.; and Li, K. C. (2020). A review of learning
analytics intervention in higher education (2011–2018).
Journal of Computers in Education 7, 1, 7–28.
Xing, W.; and Du, D. (2019). Dropout Prediction in
MOOCs: Using Deep Learning for Personalized Inter-
vention. Journal of Educational Computing Research
57, 3, 547–570.
CSEDU 2022 - 14th International Conference on Computer Supported Education
138
