
Toward Crowdsourced Knowledge Graph Construction: Interleaving
Collection and Verification of Triples
Helun Bu
1 a
and Kazuhiro Kuwabara
2 b
1
Graduate School of Information Science and Engineering, Ritsumeikan University,
1-1-1 Noji Higashi, Kusatsu, Shiga 525-8577, Japan
2
College of Information Science and Engineering, Ritsumeikan University,
1-1-1 Noji Higashi, Kusatsu, Shiga 525-8577, Japan
Keywords:
Knowledge Graph Construction, Crowdsourcing, Knowledge Collection, Knowledge Verification.
Abstract:
This paper presents a method for building a knowledge graph using crowdsourcing. The collection and ver-
ification of pieces of knowledge are essential components of building a high-quality knowledge graph. We
introduce fill-in-the-blank-type of quizzes to collect knowledge as triples and true-or-false-type quizzes to ver-
ify the collected triples. We also present score functions to evaluate and select a quiz for efficient knowledge
graph construction based on the workers’ past inputs. The collection and verification processes are dynami-
cally interleaved using weights in the score function. Simulation results show that the proposed approach can
collect and verify distributed knowledge among casual workers.
1 INTRODUCTION
Information on the Web has become more di-
verse, with more online content containing machine-
readable metadata. With the development of machine
learning technologies, knowledge can be extracted
from the data available on the Internet. Knowledge
graphs is a promising technique for storing and com-
municating real-world knowledge with nodes repre-
senting entities and edges representing relationships
between entities (Hogan et al., 2021). Knowledge
graph have been utilized in various applications, such
as query answering (Yang et al., 2014).
Building a high-quality knowledge graph requires
knowledge collection and verification, which often
involves human intervention. Crowdsourcing is a
promising method for building a knowledge graph
from the knowledge of many casual users (Cao et al.,
2021).
When we apply crowdsourcing to knowledge
graph construction, the amount and quality of knowl-
edge are major issues. For the former (the amount
of knowledge), it is important to collect the pieces of
knowledge each user has and merge them into a larger
knowledge graph. However, as pieces of knowledge
collected from a user may not be correct, we need to
a
https://orcid.org/0000-0001-9537-0757
b
https://orcid.org/0000-0003-3493-1076
verify them to attain a high-quality knowledge graph.
In this sense, there are two different tasks for knowl-
edge graph construction: collection and verification.
It is necessary to balance these properly. For example,
we may prioritize collection tasks and conduct verifi-
cation tasks only after a threshold amount of knowl-
edge pieces are obtained. Alternatively, we may ver-
ify a piece of knowledge when it is obtained. With
crowdsourcing, the tasks assigned to users need to be
carefully selected.
Here, we examine a case in which a task is repre-
sented as a game-like quiz. For example, a fill-in-the-
blank quiz is used for knowledge collection (Bu and
Kuwabara, 2021a), and a true-or-false quiz is used for
knowledge verification (Bu and Kuwabara, 2021b).
In such a crowd sourced knowledge graph construc-
tion process, task assignment to users–in other words,
what kind of quiz should be presented to each user–
is important to efficiently extract knowledge from a
large number of users who potentially have different
partial knowledge.
In this paper, we present a method of dynamically
interleaving the knowledge collection and verification
processes by introducing a score function for each
task (quiz). We conduct simulation experiments to
examine how the different score functions affect the
efficiency of the overall knowledge construction pro-
cess.
Bu, H. and Kuwabara, K.
Toward Crowdsourced Knowledge Graph Construction: Interleaving Collection and Verification of Triples.
DOI: 10.5220/0010902700003116
In Proceedings of the 14th International Conference on Agents and Artificial Intelligence (ICAART 2022) - Volume 1, pages 375-382
ISBN: 978-989-758-547-0; ISSN: 2184-433X
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
375

The remainder of the paper is organized as fol-
lows. Section 2 describes the related work. Section 3
presents our proposed approach to knowledge graph
construction. Section 4 examines the characteristics
of the proposed approach using the experimental re-
sults. Section 5 concludes the paper and discusses
future work.
2 RELATED WORK
One of the main advantages of structuring human
knowledge in large scale graphs is the flexibility of
the schema. In particular, the inference of knowl-
edge graphs can be represented by labels with de-
scriptions of the relationships between entities in stan-
dard representation formats such as RDF, RDFS and
OWL (Tiddi and Schlobach, 2021). In this context,
several approaches to dynamically creating knowl-
edge bases using RDF data have been proposed. For
example, there is a system for users to dynamically in-
corporate web services that describe facts about an en-
tity or topic in a paradigm called “Active Knowledge”
into a dynamic RDF knowledge base (Preda et al.,
2010). RDF models have also been created in the field
of clinical pharmacogenetics to use semantic knowl-
edge bases to manage and solve quality-related prob-
lems with complex and large amounts of data used in
drug selection and dosing (Samwald et al., 2013).
One effective approach to building a knowledge
base is crowdsourcing, where casual users collabo-
rate without the need for experts. For example, a
knowledge base of urban emergencies was built from
social media data using a crowdsourcing framework
that considered performance and effectiveness (Xu
et al., 2016). There has also been a crowdsourcing ap-
proach proposed using mobile applications to collect
human subjective knowledge to support human deci-
sion making (Hosio et al., 2016). However, quality
of knowledge can be a significant issue when deal-
ing with subjective human knowledge. Crowdsourc-
ing has been utilized to check the validity of fake news
and alternative facts (Sethi, 2017).
In addition, to solve the motivation problem of
crowdsourcing, it is important to provide workers
with appropriate task choices that take into account
the worker’s performance. One study suggested cre-
ating a list of tasks using the worker’s past task prefer-
ences and performance and presenting this list to the
worker at the task selection stage (Yuen et al., 2011).
In this study, we propose a process that oversees
tasks to collect pieces of knowledge to build a knowl-
edge graph and tasks to verify this knowledge. In
the proposed process, user performance is predicted
Quiz to
verify
knowledge
Quiz to
collect
knowledge
fib_predicate_object
fib_subject_object
fib_object
fib_tfquiz
Figure 1: Image of the proposed quiz.
based on their knowledge areas and past input history.
3 PROPOSED APPROACH
We regard a knowledge graph as composed of RDF
triples: subject, predicate and object. The knowledge
collection process corresponds to collecting triples,
and the knowledge verification process corresponds to
verifying the collected triples. In the triple collection
process, when knowledge is distributed among many
users, a prediction algorithm is introduced to select
a task (quiz) to efficiently collect knowledge from a
specific user.
The user is presented with different types of
quizzes in the form of fill-in-the-blank tasks. To in-
crease the reliability of the collected knowledge con-
tent, the collected triples are first stored in the tem-
porary knowledge base. A true-or-false quiz is intro-
duced to verify the collected triples, and only verified
triples are moved into the formal knowledge base.
The knowledge collection and verification pro-
cesses are essentially independent. The verification
process may start after all potential triples are accu-
mulated in the temporary knowledge base. However,
by interleaving knowledge collection and verification,
efficiency can be improved.
To achieve this, it is necessary not only to care-
fully select a quiz for a user so that users with different
partial knowledge can provide a piece of knowledge
but also to decide when the system is in knowledge
collection mode and when it is in knowledge verifi-
cation mode. In this sense, we aim to clarify a way
to interleave the collection and verification processes
when selecting a task (quiz) for each user.
3.1 Game Design
The proposed system introduces three types of
quizzes for knowledge collection, and one type of
quiz for knowledge verification. As shown in Fig-
ure 1, the quizzes for collecting knowledge are vari-
ants of fill-in-the-blank (fib) quizzes. These quizzes
are generally presented to the user with a question text
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
376
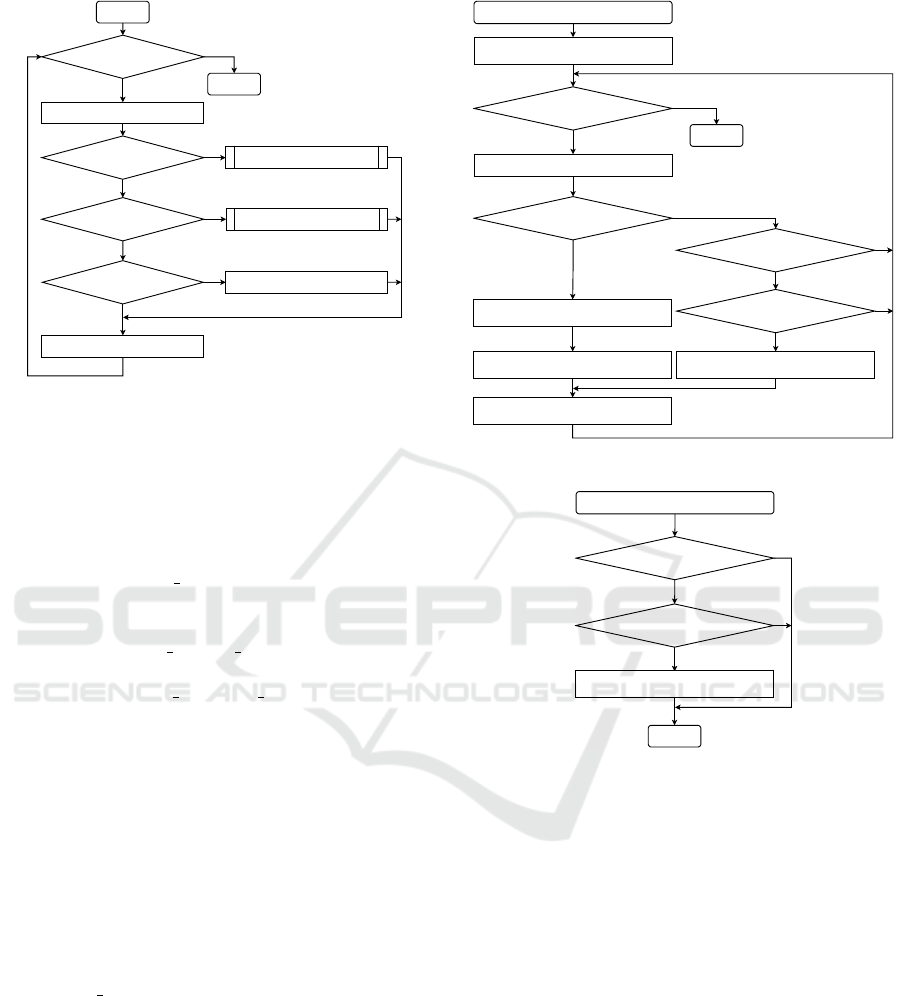
Get user input
Is there a quiz
to be asked next?
Verification process
YES
END?
ANSWER? Collection process
TRUE/FALSE? Record users' votes
Determine the next quiz
YES
NO
YES
YES
NO
NO
START
END
NO
Figure 2: Proposed system main processing flow.
containing a triple with one or two items missing. By
answering the quiz questions, parts of the knowledge
are collected by the system as triples.
For example, the system checks whether all object
items are present for any subject and predicate pair
in the temporary knowledge base. If an object item
does not exist, a f ib ob ject quiz is used to request
an object item that corresponds to the pair of subject
and predicate. Alternatively, to add a new word as
a subject item, a f ib sub ject ob ject quiz is selected,
and the user is asked to answer the pair of subject and
object. Finally, a f ib predicate ob ject quiz asks the
user to answer a pair of a predicate and an object to
add a new predicate item.
When the game starts, choices of ANSWER, SKIP
and END are displayed along with a blank field(s).
When the user enters the answer to the quiz and send
it to the server by selecting ANSWER, the system
stores the user’s response and presents the next quiz.
If the user does not know the answer to the quiz, they
can select SKIP to jump to the next quiz. If the user
selects END, the game session ends. In this process,
the collected triples are first placed in the temporary
knowledge base.
The f ib t f quiz is for verifying triples. For this
type of quiz, the user is presented with a quiz contain-
ing a triple, and the user has to choose between two
options: YES or NO.
3.2 System Flow
The main flow of the proposed approach is shown in
Figure 2. After the user starts the game, a quiz con-
taining either knowledge collection or verification is
presented to the user.
Verification process
Count all votes for triples
in this session
All triples processed?
NO
YES
YES
YES
YES
NO
NO
Select a triple
YES votes are greater
than threshold α?
Insert the triple into the
formal knowledge base
Give bonus to users who voted
TRUE or ANSWER
Remove the triple from the
temporary knowledge base
Give bonus to users who voted FALSE
YES votes are less than
threshold β?
All users answered?
RETURN
NO
Figure 3: Verification process flow.
NO
NO
YES
YES
Collection process
Is it in the formal
knowledge base?
Is it an already
deleted triple?
Store it in the temporary
knowledge base
RETURN
Figure 4: Collection process flow.
If the user selects END, the game session termi-
nates. When the game session is finished, the verifica-
tion process starts. The verification process takes the
form of a majority vote to check whether the triples
that the user has answered in this session have re-
ceived a sufficient number of votes, according to a
threshold α (Figure 3). If the triple has accumulated
more than or equal to α votes, it is treated as true,
moved into the formal knowledge base and then re-
moved from the temporary knowledge base.
Conversely, after all users have voted, if the triple
still has fewer than or equal to β votes, the triple
is treated as false and removed from the temporary
knowledge base.
When the user answers a knowledge collection
quiz (by selecting ANSWER with the answers), the
knowledge collection process stores the triple if it is
not already in the formal knowledge base and has not
been previously deleted from the temporary knowl-
Toward Crowdsourced Knowledge Graph Construction: Interleaving Collection and Verification of Triples
377

edge base (Figure 4).
For the knowledge verification quiz, we record the
number of votes for triples that the user has verified
with TRUE or FALSE.
3.3 Score Function
To facilitate selecting the next quiz to present, we
define the score for each quiz type as follows. Let
S
i
be a subject of triples in the knowledge base, P
j
be a predicate, and O
l
be an object. Let Q
i, j
repre-
sent a knowledge collection (fib object) quiz about
S
i
and P
j
, and let Q
j
represent a fib subject object
quiz regarding predicate P
j
. Further, let Q
i
represent
a fib predicate object quiz regarding subject S
i
, and
Q
i, j,l
represent a knowledge verification quiz about a
triple of (S
i
, P
j
, O
l
). In addition, let b
i
be the num-
ber of missing object items for a given subject item
S
i
, and b
j
be the number of missing object items for
a given predicate item P
j
. The answer history of the
knowledge collection quiz for user u
k
is represented
by c
i, j,k
and is updated as follows:
c
i, j,k
←
c
i, j,k
+ 1
when u
k
responds with AN-
SWER for the quiz Q
i
, Q
j
, or
Q
i, j
c
i, j,k
− 1
when u
k
responds with SKIP
for the quiz Q
i
, Q
j
, or Q
i, j
That is, c
i, j,k
represents how many S
i
and P
j
pairs the
user u
k
may know based on u
k
’s answer history to the
knowledge collection quizzes.
For the knowledge verification quiz, the an-
swer histories of both the collection and verification
quizzes are considered. The score of the verification
quiz Q
i, j,l,k
for a triple of subject S
i
, predicate P
j
and
object O
l
and user u
k
is calculated as the sum of all
previous responses by user u
k
as follows:
t
i, j,l,k
←
t
i, j,l,k
+ 1
when u
k
responds with AN-
SWER for Q
i, j
, Q
i
, or Q
j
or
when u
k
responds with TRUE
or FALSE for Q
i, j,l
t
i, j,l,k
when u
k
responds with SKIP
for the quiz but already re-
sponded ANSWER for the
corresponding item in Q
i
, Q
j
,
Q
i, j
or Q
i, j,l
t
i, j,l,k
− 1
when u
k
responds with SKIP
for the quiz and there is no
ANSWER for the correspond-
ing item in Q
i
, Q
j
, Q
i, j
and
Q
i, j,l
For each type of quiz, score functions SC
type
are de-
fined as follows:
SC
ob j
(Q
i, j
, u
k
) =
∑
s∈S
c
s, j,k
+
∑
p∈P
c
i, p,k
+ b
i
SC
sub ob j
(Q
j
, u
k
) =
∑
s∈S
c
s, j,k
+ max
j
b
j
− b
j
SC
pred ob j
(Q
i
, u
k
) =
∑
p∈P
c
i, p,k
+ max
i
b
i
− b
i
SC
t f quiz
(Q
i, j,l
, u
k
) = (
∑
p∈P,o∈O
t
i, p,o,k
+
∑
s∈S,o∈O
t
s, j,o,k
+
∑
s∈S, p∈P
t
s, p,l,k
) ∗ w
Here, w specifies how much priority the verification
quiz should be given compared to the collection quiz.
Each time we select the next quiz to present to the
user, the quiz with the highest score is chosen. If there
are multiple quizzes with the same highest score, one
of them is selected randomly.
4 EXPERIMENTS
Since it is difficult to experiment under different con-
ditions with many human users, we conducted sim-
ulation experiments, in which BOT programs corre-
sponding to virtual users were run on the simulation
system. We assume N virtual users and M distinct
triples (excluding duplicates), with triples distributed
among virtual users. We also assume that there may
be more than one object for each pair of subject and
predicate in the triples held by the virtual user. The
server in the simulation system is assumed to initially
have only one subject and predicate, and no corre-
sponding object.
The BOT program that implements a virtual user
has triples assigned to the corresponding virtual user.
It receives a quiz sent from the server, looks for
triples related to the quizzes, and sends them to the
server in the form of entering “answers” or select-
ing “true/false” to the “questions” in the quizzes. The
rules for operating a BOT program for a virtual user
are as follows:
1. For a knowledge collection quiz, if a virtual user
has knowledge about the triple associated with the
quiz, they will always reply with ANSWER.
2. For knowledge verification quizzes, if a virtual
user has the same triples as the triple in the quiz,
they will always vote TRUE. If the virtual user’s
triples differ from the triples in the quiz, the vir-
tual user will vote FALSE.
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
378

3. For all quiz types, if the virtual user does not have
the relevant knowledge, they will always reply
with SKIP and ask for the next quiz.
4. If the virtual user sends all of their triples to the
server, they will not send ANSWER for the knowl-
edge collection quiz, even if they have knowledge
of the relevant triples, but will instead send SKIP.
5. In one game session, the virtual user has to answer
Q quizzes given by the server. At the end of one
game session, the virtual user sends END. Here,
we set Q to 5.
The rules for the server side to send quizzes to
BOTs (virtual users) are as follows:
1. If there are no quizzes to be presented to the user,
the simulation ends.
2. If triples have been collected from all users into
the temporary knowledge base, and all triples in
the temporary knowledge base have been verified,
and the maximum score of the candidates for the
next quiz is less than or equal to zero, the simula-
tion ends.
3. The same quiz will not be presented to the same
user twice if the user has answered with SKIP.
4. A triple collected by a knowledge collection quiz
is treated the same as one vote of TRUE in the
knowledge verification quiz. Thus, the collected
triple will not be submitted as the knowledge ver-
ification quiz.
5. The server initially has one subject item and one
predicate item among the M pre-populated triples,
but the server does not have the object item for this
subject and predicate.
6. The only triples stored in the temporary knowl-
edge base are the triples collected from the knowl-
edge collection quiz. Triples collected from other
sources are not considered. Therefore, the triples
in the quiz to be verified will always correspond
to the ones that were answered with ANSWER in
the collection quiz.
To investigate the characteristics of the proposed
approach, we conducted two experiments, as de-
scribed in the following subsections.
4.1 Collection and Verification
The purpose of this experiment was to demonstrate
how interleaving the collection and verification of
knowledge is possible by changing the value of w in
the proposed approach while obtaining triples that are
distributed among many virtual users.
Table 1: The triples user (u
1
) has.
genre p2 p3 p4
s1 g1 o2 o3 o4
s2 g1 o5 o6 o7
s3 g1 o8 o9 o10
4.1.1 Simulation Parameters
In this experiment, we prepared 60 triples (M = 60)
and 100 virtual users (N = 100). In terms of triples,
we set the number of subject items to 15, and the
number of predicate items to 4, comprising 60 triples.
The virtual users were divided into 5 groups, each of
which had 20 virtual users. Virtual users in the same
group were assumed to have the same triples. Each
virtual user was assumed to have 12 triples with 3
subject items and 4 predicate items. Table 1 shows
the triples of an example virtual user. We regard the
predicate genre contains genre or a knowledge area
of the triple. The triples a virtual user has have the
same object value for predicate genre, meaning that
the virtual user has knowledge about a certain genre
(knowledge area).
The threshold α was set to 16, and the threshold
β was set to 4. That is, a triple needs to obtain 16 or
more votes from the virtual users (in this particular ex-
periment, from the same group) to be considered true
and moved to the formal knowledge base. Further, if
only 4 or fewer votes are obtained, the corresponding
triple is treated as false and removed from the tempo-
rary knowledge base.
The objectives of this experiment is to verify that
M = 60 triples can be acquired in the temporary
knowledge base by running the quiz game with N =
100 virtual users, and that M = 60 exact triples can be
verified and moved into the formal knowledge base.
We also varied the weight (w = 1, 10, 100) that con-
trols how much the verification quiz is prioritized to
examine the effect of the weight on the knowledge
collection and verification processes.
4.1.2 Simulation Results and Discussions
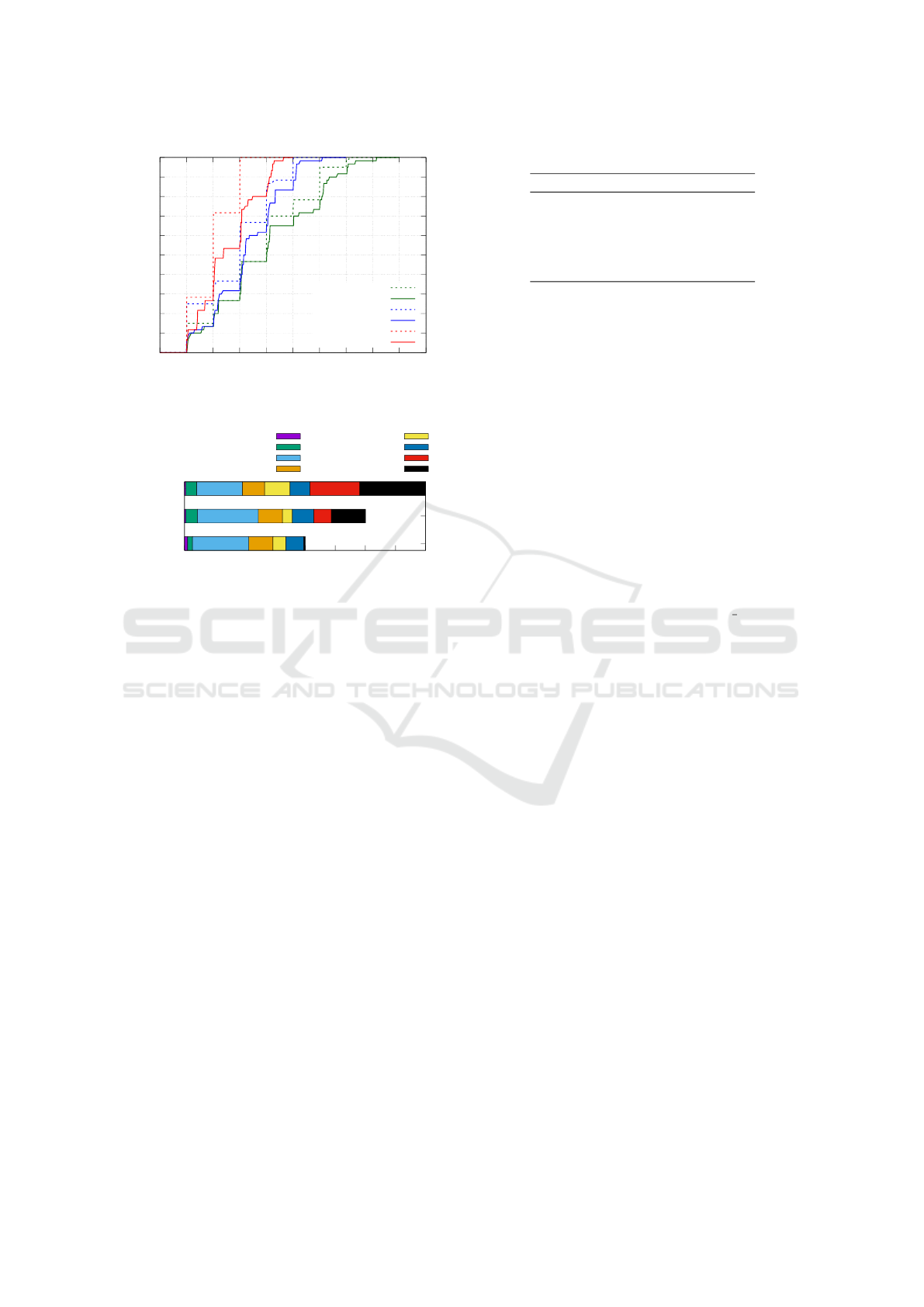
Figure 5 shows how many triples were collected and
verified for different weight values. The horizontal
axis represents the number of game sessions, and the
vertical axis represents the number of triples. The
solid line represents the changes in the number of ver-
ified triples in the formal knowledge base, and the
dotted line represents the changes in the number of
collected triples in the temporary knowledge base.
As can be seen in the graph, for all values of w, all
triples were collected from the virtual user and veri-
fied. However, there were differences in the speed of
Toward Crowdsourced Knowledge Graph Construction: Interleaving Collection and Verification of Triples
379
0
6
12
18
24
30
36
42
48
54
60
0 100 200 300 400 500 600 700 800 900 1000
Number of Triples
Number of Game Sessions
w=100 collected
w=100 verified
w=10 collected
w=10 verified
w=1 collected
w=1 verified
Figure 5: Collected and verified triples.
weight1
weight10
weight100
0 500 1000 1500 2000 2500 3000 3500 4000
Number of Quizzes Sent
fib_obj(ANSWER)
fib_obj(SKIP)
fib_sub_obj(ANSWER)
fib_sub_obj(SKIP)
fib_pred_obj(ANSWER)
fib_pred_obj(SKIP)
fib_tfquiz(TRUE)
fib_tfquiz(SKIP)
Figure 6: Breakdown of users’ answers.
collection and verification. Since both the number of
collected triples and the number of verified triples in-
creased as the game session proceeds, collection and
verification were performed in parallel. More specifi-
cally, as the number of collected triples increases, the
score for the verification quiz increases, resulting in a
higher priority for verification.
The breakdown of the users’ answers to each
type of quiz is shown in Figure 6. From the figure,
the weight w can control the ratio the ratio between
the collection quizzes and the verification quizzes;
smaller w values result in fewer verification quizzes.
The reason the number of verification quizzes in the
case of w = 1 is less than that of w = 100 can be ex-
plained as follows: With a lower w value, the number
of verification quizzes presented to the user is reduced
and the collection quizzes effectively verify the triples
by receiving the same triples as the responses to the
collection quizzes.
In addition, for the w = 100 case, the number of
verification quizzes answered with SKIP is larger than
the cases with a lower w value. As SKIP answers
to quizzes are a cause of inefficiency, decreasing the
number of SKIP responses is a future challenge.
Table 2: The triples user (u
1
) has (2nd experiment).
p1 p2 p3 p4 p5
s1 o
10
o
10
o
10
o
10
o
10
o
8
o
8
o
8
o
8
o
6
o
6
o
6
o
4
o
4
o
2
4.2 Thresholds in Verification
In the second experiment, we checked if the thresh-
old of verifying triples reflects the number of users
that have the target triple. We assume that triples are
distributed among virtual users, and the triples that
many users have are treated as true, and put into the
formal knowledge base. The triples that only a few
users have are treated as false and removed from the
temporary knowledge base. Other triples remain in
the temporary knowledge base. Here, the threshold is
used to determine the truth of a collected triple based
on the number of votes.
4.2.1 Simulation Parameters
We assumed that the triples were collected by a
knowledge collection quiz such as a f ib ob ject type
quiz. In this experiment, the number of triples, M,
was set to 25. The number of subject items was set to
1, and the number of predicate items was set to 5. We
prepared five different values of object for each sub-
ject and predicate pair. The total number of distinct
triples used in the experiment was 25.
The number of virtual users, N, was set to 20. For
each 5 distinct object values (o
10
, o
8
, o
6
, o
4
, and o
2
),
100%, 80%, 60%, 40%, and 20% of users were re-
spectively assumed to have the same triple that con-
tains a certain object value. For example, all 20 vir-
tual users have a triple of (s1, p1, o
10
), 16 users have
a triple of (s1, p1, o
8
), and so on. Table 2 shows the
triples a virtual user has. We distributed triples to vir-
tual users so that each user had the same number of
triples.
The value of threshold α was set to 16. As the
number of virtual users was N = 20, triples that 80%
or more of the virtual users have would be considered
true. The value of threshold β was set to 4, meaning
that triples that 20% or less of the virtual users have
would be considered false. The value of w, which
determines the priority of verification quizzes, was set
to 1,10, and 100, as in the first experiment.
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
380

0
2.5
5
7.5
10
12.5
15
17.5
20
22.5
25
0 25 50 75 100 125 150 175 200 225 250
Number of Triples
Number of Game Sessions
w=100 collected
w=100 verified
w=100 deleted
w=10 collected
w=10 verified
w=10 deleted
w=1 collected
w=1 verified
w=1 deleted
Figure 7: Collected and verified triples (2nd experiment).
weight1
weight10
weight100
0 200 400 600 800 1000 1200
Number of Quizzes Sent
fib_obj(ANSWER)
fib_obj(SKIP)
fib_sub_obj(ANSWER)
fib_sub_obj(SKIP)
fib_pred_obj(ANSWER)
fib_pred_obj(SKIP)
fib_tfquiz(TRUE)
fib_tfquiz(FALSE)
Figure 8: Breakdown of users’ answers (2nd experiment).
4.2.2 Simulation Results and Discussion
As shown in Figure 7 and 8, the results of the experi-
ment with 20 virtual users show that out of 25 triples,
all 10 triples that 80% and 100% of the users have in
common were moved into the formal knowledge base.
By contrast, all 5 triples that only 20% of users had
were considered false and removed from the tempo-
rary knowledge base, while the other triples remained
in the temporary knowledge base. Note that users’ re-
sponses of FALSE for true-or-false quizzes were ob-
served for all the cases (Figure 8). In this way, only
the triples possessed by more users than the threshold
α were verified, and triples possessed by fewer users
than the threshold β were eventually removed from
the temporary knowledge base.
We also found that the system effectively inter-
leaved the collection and verification of knowledge
even when multiple object items existed for a pair of
subject and predicate.
5 CONCLUSION
In this paper, we presented an approach to perform in-
terleaved collection and verification of triples to build
a knowledge graph using crowdsourcing. In this ap-
proach, quizzes were introduced to collect and verify
triples that constitute a knowledge graph: fill-in-the-
blank quizzes for knowledge collection and a true-or-
false quiz for knowledge verification.
Score functions based on the user’s history were
adopted to improve knowledge graph building effi-
ciency. To interleave the collection and verification
processes, we also introduced a weight in score func-
tion calculations. The simulation results show how
weight can influence the performance of the collec-
tion and verification of knowledge. In addition, the
verification threshold works reasonably when a ma-
jority rule is adopted.
Since currently only triples collected in the knowl-
edge collecting quizzes are considered for the verifi-
cation task, we plan to incorporate triples collected
from a variety of other sources into the target of
the verification task in future work. Furthermore, it
would be beneficial to expand the gamification ele-
ments to motivate users. We plan to examine how
different ways of giving rewards to users affect the
collection and verification of triples. For example, we
are considering offering multiple tasks with different
rewards to the user and letting the user choose one of
them for task execution.
ACKNOWLEDGEMENTS
This work was partially supported by JSPS
KAKENHI Grant Number 18K11451.
REFERENCES
Bu, H. and Kuwabara, K. (2021a). Task selection based
on worker performance prediction in gamified crowd-
sourcing. In Jezic, G., Chen-Burger, J., Kusek, M.,
Sperka, R., Howlett, R. J., and Jain, L. C., editors,
Agents and Multi-Agent Systems: Technologies and
Applications 2021, pages 65–75, Singapore. Springer
Singapore.
Bu, H. and Kuwabara, K. (2021b). Validating knowledge
contents with blockchain-assisted gamified crowd-
sourcing. Vietnam Journal of Computer Science,
pages 1–21.
Cao, M., Zhang, J., Xu, S., and Ying, Z. (2021). Knowledge
graphs meet crowdsourcing: A brief survey. In Qi,
L., Khosravi, M. R., Xu, X., Zhang, Y., and Menon,
V. G., editors, Cloud Computing, pages 3–17, Cham.
Springer International Publishing.
Hogan, A., Blomqvist, E., Cochez, M., D’amato, C., Melo,
G. D., Gutierrez, C., Kirrane, S., Gayo, J. E. L., Nav-
igli, R., Neumaier, S., Ngomo, A.-C. N., Polleres, A.,
Rashid, S. M., Rula, A., Schmelzeisen, L., Sequeda,
Toward Crowdsourced Knowledge Graph Construction: Interleaving Collection and Verification of Triples
381

J., Staab, S., and Zimmermann, A. (2021). Knowl-
edge graphs. ACM Comput. Surv., 54(4).
Hosio, S., Goncalves, J., van Berkel, N., and Klakegg, S.
(2016). Crowdsourcing situated & subjective knowl-
edge for decision support. In Proceedings of the 2016
ACM International Joint Conference on Pervasive and
Ubiquitous Computing: Adjunct, UbiComp ’16, pages
1478–1483, New York, NY, USA. Association for
Computing Machinery.
Preda, N., Kasneci, G., Suchanek, F. M., Neumann, T.,
Yuan, W., and Weikum, G. (2010). Active knowl-
edge: Dynamically enriching RDF knowledge bases
by web services. In Proceedings of the 2010 ACM
SIGMOD International Conference on Management
of Data, SIGMOD ’10, pages 399–410, New York,
NY, USA. Association for Computing Machinery.
Samwald, M., Freimuth, R., Luciano, J. S., Lin, S., Powers,
R. L., Marshall, M. S., Adlassnig, K.-P., Dumontier,
M., and Boyce, R. D. (2013). An RDF/OWL knowl-
edge base for query answering and decision support in
clinical pharmacogenetics. Studies in health technol-
ogy and informatics, 192:539–542.
Sethi, R. J. (2017). Crowdsourcing the verification of fake
news and alternative facts. In Proceedings of the 28th
ACM Conference on Hypertext and Social Media, HT
’17, pages 315–316, New York, NY, USA. Associa-
tion for Computing Machinery.
Tiddi, I. and Schlobach, S. (2021). Knowledge graphs as
tools for explainable machine learning: a survey. Ar-
tificial Intelligence, 103627.
Xu, Z., Zhang, H., Hu, C., Mei, L., Xuan, J., Choo, K.-
K. R., Sugumaran, V., and Zhu, Y. (2016). Build-
ing knowledge base of urban emergency events based
on crowdsourcing of social media. Concurrency and
Computation: Practice and Experience, 28(15):4038–
4052.
Yang, M., Ding, B., Chaudhuri, S., and Chakrabarti, K.
(2014). Finding patterns in a knowledge base using
keywords to compose table answers. Proc. VLDB En-
dow., 7(14):1809–1820.
Yuen, M.-C., King, I., and Leung, K.-S. (2011). Task
matching in crowdsourcing. In 2011 International
Conference on Internet of Things and 4th Interna-
tional Conference on Cyber, Physical and Social
Computing, pages 409–412.
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
382
