
Feature Selection for Sentiment Classification of COVID-19 Tweets:
H-TFIDF Featuring BERT
Mehtab Alam Syed
1 a
, Elena Arsevska
3 b
, Mathieu Roche
1 c
and Maguelonne Teisseire
2 d
1
CIRAD, UMR TETIS, Montpellier, France
2
INRAE, UMR TETIS, Montpellier, France
3
CIRAD, UMR ASTRE, Montpellier, France
Keywords:
Text Mining, Sentiment Analysis, Feature Selection, Twitter.
Abstract:
In the first quarter of 2020, the World Health Organization (WHO) declared COVID-19 a public health emer-
gency around the globe. Different users from all over the world shared their opinions about COVID-19 on
social media platforms such as Twitter and Facebook. At the beginning of the pandemic, it became rele-
vant to assess public opinions regarding COVID-19 using data available on social media. We used a recently
proposed hierarchy-based measure for tweet analysis (H-TFIDF) for feature extraction over sentiment clas-
sification of tweets. We assessed how H-TFIDF and concatenation of H-TFIDF with bidirectional encoder
representations from transformers (BH-TFIDF) perform over state-of-the-art bag-of-words (BOW) and term
frequency-inverse document frequency (TF-IDF) features for sentiment classification of COVID-19 tweets. A
uniform experimental setup of the training-test (90% and 10%) split scheme was used to train the classifier.
Moreover, evaluation was performed with the gold standard expert labeled dataset to measure precision for
each binary classified class.
1 INTRODUCTION
In the beginning of March 2020, the World Health
Organization announced the COVID-19 outbreak as
a global pandemic (Dubey, 2020). The lockdown at
the beginning of the pandemic affected the social ac-
tivities of millions of people around the world. Dur-
ing this lockdown, people used social networks, espe-
cially Twitter, to express their feelings and thoughts
about COVID-19. These tweets resulted in differ-
ent trends of global coronavirus (Fernandes et al.,
2020). These trends were helpful for health officials
and other stakeholders by realizing the health crisis
and its impact over different regions (WHO, 2020;
Organization et al., 2020). Due to the massive num-
ber of tweets regarding the COVID-19 pandemic, it is
difficult to analyze the information. Decoupes et al.
(Decoupes et al., 2021) proposed a hierarchy-based
measure for tweet analysis (H-TFIDF) features from
COVID-19 tweets by considering spatial and tempo-
a
https://orcid.org/0000-0003-3696-0030
b
https://orcid.org/0000-0002-6693-2316
c
https://orcid.org/0000-0003-3272-8568
d
https://orcid.org/0000-0001-9313-6414
ral dimensions. H-TFIDF captures important features
that reflect local concerns by taking into account spa-
tiotemporal aspects (Decoupes et al., 2021). These
features illustrate various ways of exploring tweets
in the health context of the coronavirus COVID-19
pandemic. By using an adaptive interest of these
features, global insight of the evolution of features
over space and time is obtained. Furthermore, H-
TFIDF features greater semantic information rich-
ness, which can be helpful for sentiment classification
of COVID-19 tweets. Moreover, bidirectional en-
coder representations from transformers (BERT) (De-
vlin et al., 2018) have pretrained language models that
can be helpful for extracting contextual features in the
context of COVID-19 tweets (Hoang et al., 2019).
The main objective of our work is to perform sen-
timent classification of COVID-19 tweets by taking
into account both spatial and semantic aspects with
H-TFIDF and concatenation of BERT and H-TFIDF
(BH-TFIDF) features. The objective is achieved by
using a supervised learning approach. Moreover, ma-
chine learning models, i.e., linear and nonlinear, are
chosen to perform the sentiment classification task.
These machine learning models are trained using a
publicly labeled dataset (KazAnova, 2016). More-
648
Syed, M., Arsevska, E., Roche, M. and Teisseire, M.
Feature Selection for Sentiment Classification of COVID-19 Tweets: H-TFIDF Featuring BERT.
DOI: 10.5220/0010887800003123
In Proceedings of the 15th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2022) - Volume 5: HEALTHINF, pages 648-656
ISBN: 978-989-758-552-4; ISSN: 2184-4305
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

over, the best model is chosen among them for senti-
ment classification. The model predicts results using
different sets of features, i.e., Bag-of-words (BOW),
TF-IDF, H-TFIDF, BH-TFIDF, and BOW+BERT. Fi-
nally, the purpose of the proposed work is to evalu-
ate how H-TFIDF features and BH-TFIDF perform
over BOW features and TF-IDF features for senti-
ment classification of COVID-19 tweet data. This pa-
per is structured as follows: Section 2 describes the
state-of-the-art literature related to sentiment analy-
sis of COVID-19 tweet data of January 2020. Sec-
tion 3 presents the proposed methodology. Section
4 presents the results of the experiments and a dis-
cussion of the results. In Section 5, we discuss the
advantages and limitations of the proposed work and
propose some future perspectives.
2 STATE-OF-THE-ART
Social media, especially Twitter, provides trends on
different topics by different users around the world
(Ferrara, 2020; Shen et al., 2019). These trends of
topics on the recent COVID-19 pandemic are help-
ful to see the impact of different stakeholders on the
health crisis, current situation, and economic influ-
ences (Allain-Dupr
´
e et al., 2020). (Schouten et al.,
2017) proposed both supervised learning techniques
and unsupervised learning techniques for perform-
ing sentiment analysis on different aspects of Twit-
ter data. (Gulati, 2021) presented a comparative anal-
ysis of common machine learning-based classifiers,
i.e., Linear Support Vector Classifier SVC, Percep-
tron, Passive Aggressive Classifier and Logistic Re-
gression found Logistic Regression, and Linear SVC
(the best for all sentiment classes). Another study
(Sharma and Ghose, 2021) proposed a lexicon-based
approach for sentiment classification of tweet data.
However, it has severe accuracy issues over machine
learning techniques. Further research (Mansoor et al.,
2020) proposed long short-term memory (LSTM) and
artificial neural networks (ANNs) for sentiment clas-
sification of COVID-19 tweets to see the impact of
coronavirus on people’s lives, especially work from
home (WFH) and online learning. Another study
(Wisesty et al., 2021) performed a comparative anal-
ysis of sentiment classification that was performed
with word embedding (word2vec and GloVe) with
LSTM and BERT (bidirectional encoder representa-
tions from transformers). In these experiments, BERT
performed better than other word embedding tech-
niques for sentiment classification. Feature selection
is the most important perspective apart from select-
ing the best models or techniques to solve the senti-
ment classification (Kou et al., 2020). In sentiment
classification, feature selection is a crucial process in
both supervised learning and unsupervised learning.
Improper large feature selection may degrade classi-
fier performance and increase the computational cost
(Kumar, 2014). Feature selection techniques can be
used to select an optimal subset of features, reducing
the computational cost of training a classifier and po-
tentially improving classification performance (Prusa
et al., 2015). (Madasu and Elango, 2020) proposed
the term frequency inverse document frequency (TF-
IDF) as a feature extraction technique to obtain re-
sults with different subsets of features. (Wang and
Lin, 2020) proposed a new method when selecting a
suitable number of features by using the chi-square
feature selection algorithm to employ feature selec-
tion using a preset score threshold. Another study
(Ansari et al., 2019) proposed recursive feature elim-
ination to select the optimal feature set and an evolu-
tionary method based on binary particle swarm opti-
mization of the final feature subset. These approaches
were validated for sentiment analysis in five different
domain balanced datasets including movie reviews
and Amazon product reviews. Further work (Rus-
tam et al., 2021) proposed a comparison of sentiment
classification using different features, i.e., Bag-of-
words (BOW), TF-IDF, and concatenation of BOW
and TF-IDF to boost the performance. In this paper,
the concatenation of BOW and TF-IDF outperformed
other features in sentiment classification of COVID-
19 tweets. However, the issues with features were
the computational cost of model learning and overfit-
ting of the model. To address this research gap, (De-
coupes et al., 2021) proposed a set of features that are
extracted from a COVID-19 tweet dataset by consid-
ering the spatial and temporal aspects of COVID-19
data. In this work, the main focus was on the hierar-
chical characteristics of spatial and temporal dimen-
sions for extracting a more relevant set of features in
the context. These important features, i.e., hierarchi-
cal term frequency inverse document frequency (H-
TFIDF) in the tweets for different regions and time,
help determine the local situation, crisis management,
and opinions of inhabitants. Moreover, these reduced
sets of features (H-TFIDF) may be important for sen-
timent classification of COVID-19 tweets. There-
fore, it is important to analyze how well these H-
TFIDF features perform in the sentiment classifica-
tion of COVID-19 tweets. In the proposed work, we
compare H-TFIDF features and BH-TFIDF features,
and we show how these features outperform state-of-
the-art BOW and TF-IDF features for sentiment clas-
sification of COVID-19 tweets.
Feature Selection for Sentiment Classification of COVID-19 Tweets: H-TFIDF Featuring BERT
649

3 PROPOSED METHODOLOGY
In this work, we performed sentiment analysis of
COVID-19 tweets for sentiment classification using
different features, i.e., H-TFIDF, BH-TFIDF, BOW,
and TF-IDF. The flow of our experiments (training
and prediction steps) is shown in Figure 1. . There are
two major types of learning techniques: supervised
learning and unsupervised learning. In supervised
learning, the models are trained and tested with la-
beled data. However, unsupervised learning learns us-
ing features and predicts unlabeled data. The dataset
for sentiment analysis of COVID-19 tweets is unla-
beled and needs to be classified. For sentiment classi-
fication, prediction of sentiment of these tweets is per-
formed using machine-learning-trained models. The
process of our proposed work has two phases:
3.1 Training Phase
In the training phase, we considered three machine
learning models (linear and nonlinear) for perform-
ing the task: LR, SVM with a linear kernel, and RF.
These models are mainly used for classification tasks,
as already explained in Section 2. The next step is to
choose the dataset for training these models. This is
discussed in Section 3.1.1.
3.1.1 Training Dataset
The training dataset is the well-known kaggle
Sentiment140 dataset for sentiment analysis of
tweets in English only. The dataset is available
at https://www.kaggle.com/kazanova/sentiment140
(KazAnova, 2016). It has labeled data for supervised
learning for the classification of tweets. The dataset
contains 1.6 million tweets. Tweets are annotated as
(0 = negative) and (4 = positive). Later, the trained
model will be used to detect sentiments for COVID-
19 tweet data. The training dataset for learning
models will be used for the binary classification of
tweets.
3.1.2 Data Preprocessing
We next preprocessed and cleaned texts by remov-
ing unwanted words, removing stop words, spe-
cial characters, etc., using the Python library tweet-
preprocessor (
¨
Ozcan, 2016), which was specifically
used for cleaning the text by removing URLs, hash-
tags, reserved keywords, etc. Punctuation in the text
was removed using regular expressions. Text stan-
dardization was applied by converting text into low-
ercase text, which was later used to train the model.
Table 1: Document-term matrix.
virus causes mental stress deaths
D1 1 1 1 1 0
D2 1 1 0 0 1
3.1.3 Feature Extraction
The third step in the training phase is feature se-
lection. We used a state-of-the-art feature selection
model, i.e., BOW, for the learning machine model.
The BOW model is very simple and flexible for ex-
tracting features from the model. A bag of words rep-
resents the following:
1. Vocabulary of known words in the corpus.
2. Measures of the presence of each vocabulary word
in each document of the corpus.
This is represented in document-term matrix form.
The document-term matrix is explained with an ex-
ample below.
A corpus having two documents is
D1: virus causes mental stress.
D2: virus causes deaths.
The document-term matrix of the above corpus is
shown in Table 1.
3.1.4 Training Models
For the experiments, we used linear and nonlin-
ear models for sentiment classification of COVID-19
tweets. These models are logistic regression (LR),
support vector machine (SVM), and random forest
(RF). These models were trained using BOW fea-
tures. Moreover, we applied cross-validation to eval-
uate the performance of models.
3.1.5 Model Selection
It is better to evaluate the performance of each model
by calculating train-test chunks of data with a cross-
validation strategy (Raschka, 2018). Cross-validation
is a data resampling method to assess the generaliza-
tion ability of predictive models and to prevent over-
fitting (Berrar, 2019). For the experimental setup, a
train-test validation scheme of 90% and 10% is used
with 10-fold cross validation. The dataset of 1.6 mil-
lion is divided into 10 splits such that the first split
has test data and the remaining nine splits are used for
training in the first iteration. Similarly, in the second
iteration, the first and last eight are used for training,
the second iteration has test data, and a similar pat-
tern is shown in Figure 2. The performance of each
model is calculated after each iteration. The average
performance of each model is shown in Table 2.
HEALTHINF 2022 - 15th International Conference on Health Informatics
650
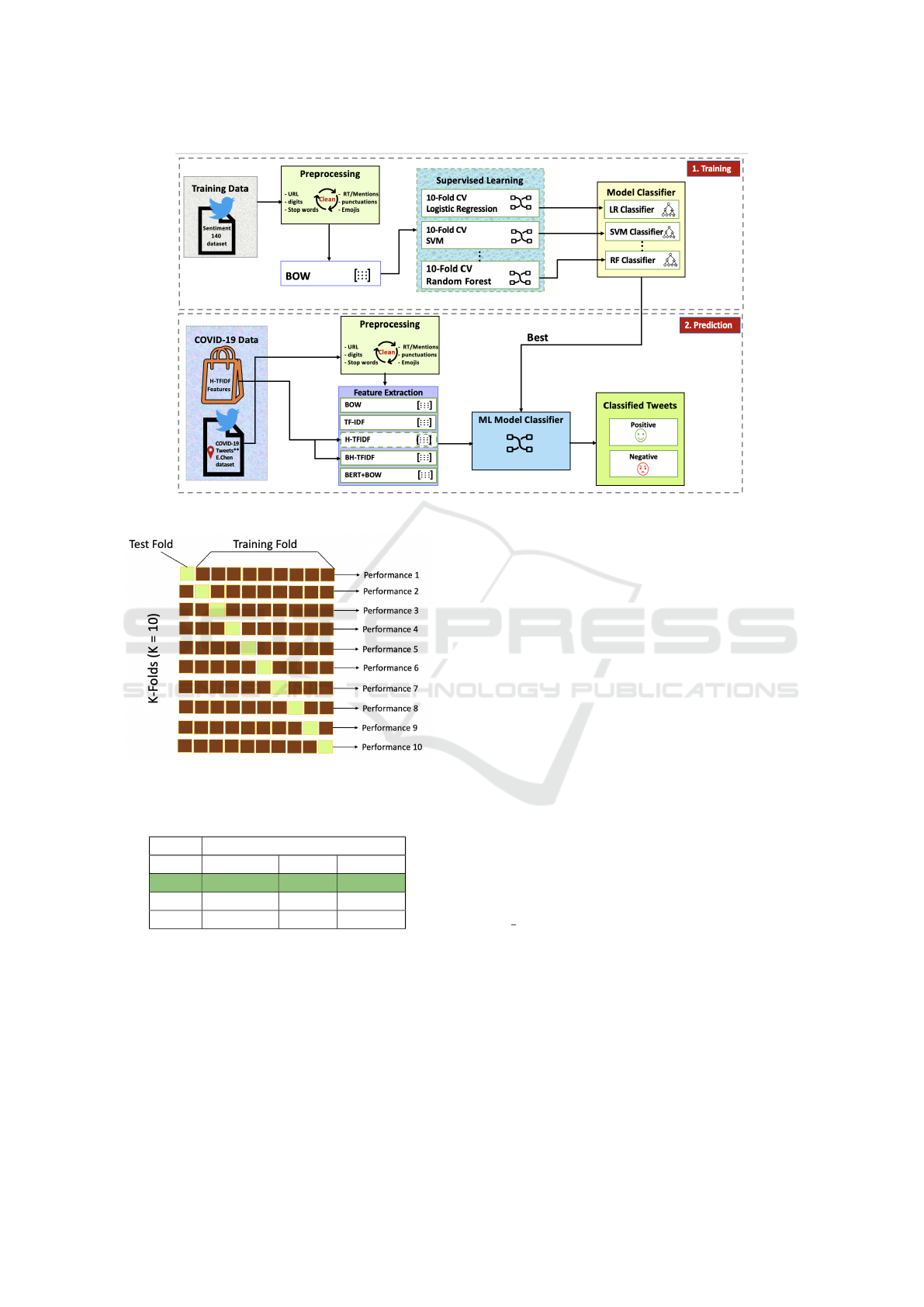
Figure 1: Process pipeline.
Figure 2: Cross-Validation.
Table 2: Machine learning models performance with 10-
fold cross validation.
BOW
Precision Recall F-Score
LR 80 79 79
SVM 71 70 70
RF 61 63 61
The average performance score of the three mod-
els with 10-fold cross validation (cv), i.e., 1) LR, 2)
SVM, and 3) RF, are 79%, 70%, and 63%, respec-
tively, for the test dataset. It is clearly shown in Table
2 that LR is the best model with 10-cv for sentiment
classification over other machine learning models.
3.2 Prediction Phase
In the second phase, which is the prediction phase,
sentiment classification of the COVID-19 tweets is
performed using the best model with different fea-
tures, i.e., BOW, TF-IDF, H-TFIDF, BH-TFIDF, and
BOW+BERT. As mentioned previously, we predict
the sentiment classification on the tweets from Jan-
uary 2020, which are discussed in Section 3.2.1.
3.2.1 COVID-19 Dataset
In the second phase, we first selected the dataset of
COVID-19 tweets that were extracted from E. Chen
dataset (Chen et al., 2020). For the experiments,
we extracted the COVID-19 tweets for the month of
January 2020. The tweet IDs of COVID-19 were
extracted using the Twitter Streaming API by using
COVID-related keywords. The analysis dataset con-
tains 165,537 tweets. Each tweet contains the infor-
mation ID, UserID, text, location, country, and its cre-
ation date. Furthermore, data preprocessing was per-
formed with the same strategy as discussed in section
3.1.2. Finally, sentiment analysis was performed us-
ing different sets of features, i.e., BOW, TF-IDF, H-
TFIDF, and BH-TFIDF. These features are discussed
in Section 3.3.1.
3.3 Data-preprocessing
Similar to the training phase, the tweets were prepro-
cessed through the Python library tweet-preprocessor
Feature Selection for Sentiment Classification of COVID-19 Tweets: H-TFIDF Featuring BERT
651

(
¨
Ozcan, 2016). Some examples of preprocessed
tweets are as follows:
<Tweet1>:"@pearlylondon Don’t worry, if
she does contract a fatal dose of coronavirus
at least she will have a dignified burial
\n#Blackadder https://t.co/8KdpMIItki".
<Tweet2>:"5 confirmed cases of #coronavirus
in Brighton. In the meantime, local news...
#Brighton https://t.co/KTXkQCOApg"
<Preprocessed Tweet1>:"do not worry,if she
does contract a fatal dose of coronavirus
at least she will have a dignified burial"
<Preprocessed Tweet2>:"confirmed cases of
in brighton in the meantime, local news"
3.3.1 Feature Extraction
The results are calculated using BOW, TF-IDF, H-
TFIDF, and BH-TFIDF. These features are discussed
below.
1. BOW: In the first experiment, sentiment analy-
sis is performed on the COVID-19 dataset using
BOW features with the best model for classifica-
tion (i.e., LR). These features were discussed in
Section 3.1.3.
2. TF-IDF: The second experiment was performed
using term frequency-inverse document frequency
(TF-IDF) features using the LR model. TF-IDF
is defined as in two parts. The term frequency
(TF) indicates the frequency of each of the words
present in the document or dataset. The second
part is inverse document frequency (IDF), which
actually tells us how important the word is to the
document (Qaiser and Ali, 2018; Yahav et al.,
2018). The basic purpose of this is to enable us to
determine how each word is relevant in the docu-
ment and the corpus (see equations below):
t f − id f (t, d) = t f (t, d) ∗ id f (t) (1)
t f (t) = f
t
.
f
tot
(2)
id f (t) = log(N
.
d f
t
) (3)
3. H-TFIDF: In the third experiment, a hierarchy-
based measure for tweet analysis known as H-
TDIDF features is used to perform sentiment anal-
ysis of the COVID-19 dataset. H-TFIDF features
are the discriminative features extracted by con-
sidering spatial and temporal windows from the
early beginning of the outbreak (Decoupes et al.,
2021). H-TFIDF are defined in Equation (4) (De-
coupes et al., 2021):
H − T FIDF(t, d
(s
i
,t
j
)
, D
(level
i
,t
j
)
) =
T F(t, d
(s
i
,t
j
)
) ∗ IDF(t, D
(level
i
,t
j
)
)
(4)
4. BH-TFIDF: In the fourth experiment, we used
a combination of bidirectional encoder represen-
tations from transformers (BERT) (Devlin et al.,
2018) and H-TFIDF features to perform sentiment
analysis of COVID-19 tweets. The main purpose
of integrating BERT features is to enhance H-
TFIDF features in terms of enhancing the contex-
tual vocabulary. Moreover, due to semantic rich-
ness, it would also be helpful to improve the sen-
timent classification of COVID-19 tweets.
5. BOW+BERT: In the fifth experiment, we used
a combination of bidirectional encoder represen-
tations from transformers (BERT) (Devlin et al.,
2018) and state-of-the-art BOW features to per-
form sentiment analysis of COVID-19 tweets.
This combination is used to improve sentiment
classification of COVID-19 tweets.
Predicted results using these features are represented
by Equations (5) and (6).
Let B be the BOW set
Let T be the TF-IDF set
Let H be the H-TFIDF set and
Let BH be the BH-TFIDF set
Only(B) = B − (B ∩H) − (B ∩ T )
Only(H) = H −(H ∩ B) − (H ∩ T )
Only(T ) = T − (T ∩ B) − (T ∩ H)
Only(B ∩ T ) = (B ∩ T ) − (B ∩ T ∩ H)
Only(B ∩ H) = (B ∩ H) − (B ∩ T ∩ H)
Only(T ∩ H) = (T ∩ H) − (T ∩ H ∩BH)
COMMON
B,H,T
= B ∩ H ∩ T
(5)
Only(B) = B − (B ∩ H) − (B ∩ BH)
Only(H) = H −(H ∩ B) − (H ∩ BH)
Only(BH) = BH −(BH ∩ B) − (BH ∩ H)
Only(BH ∩B) = (BH ∩B) − ((BH ∩ B) ∩ T )
Only(BH ∩H) = (BH ∩ H) − (BH ∩ H ∩ T )
Only(H ∩B) = (H ∩B) − (H ∩ B ∩ BH)
COMMON
B,H,BH
= B ∩ H ∩ BH
(6)
4 RESULTS & DISCUSSION
Binary classification of positive and negative was pre-
dicted with 4 different experiments. In each exper-
iment, classification was performed using different
sets of features, i.e., BOW, TF-IDF, H-TFIDF, and
BH-TFIDF, using the LR machine learning model.
The results have the final binary classification with
HEALTHINF 2022 - 15th International Conference on Health Informatics
652
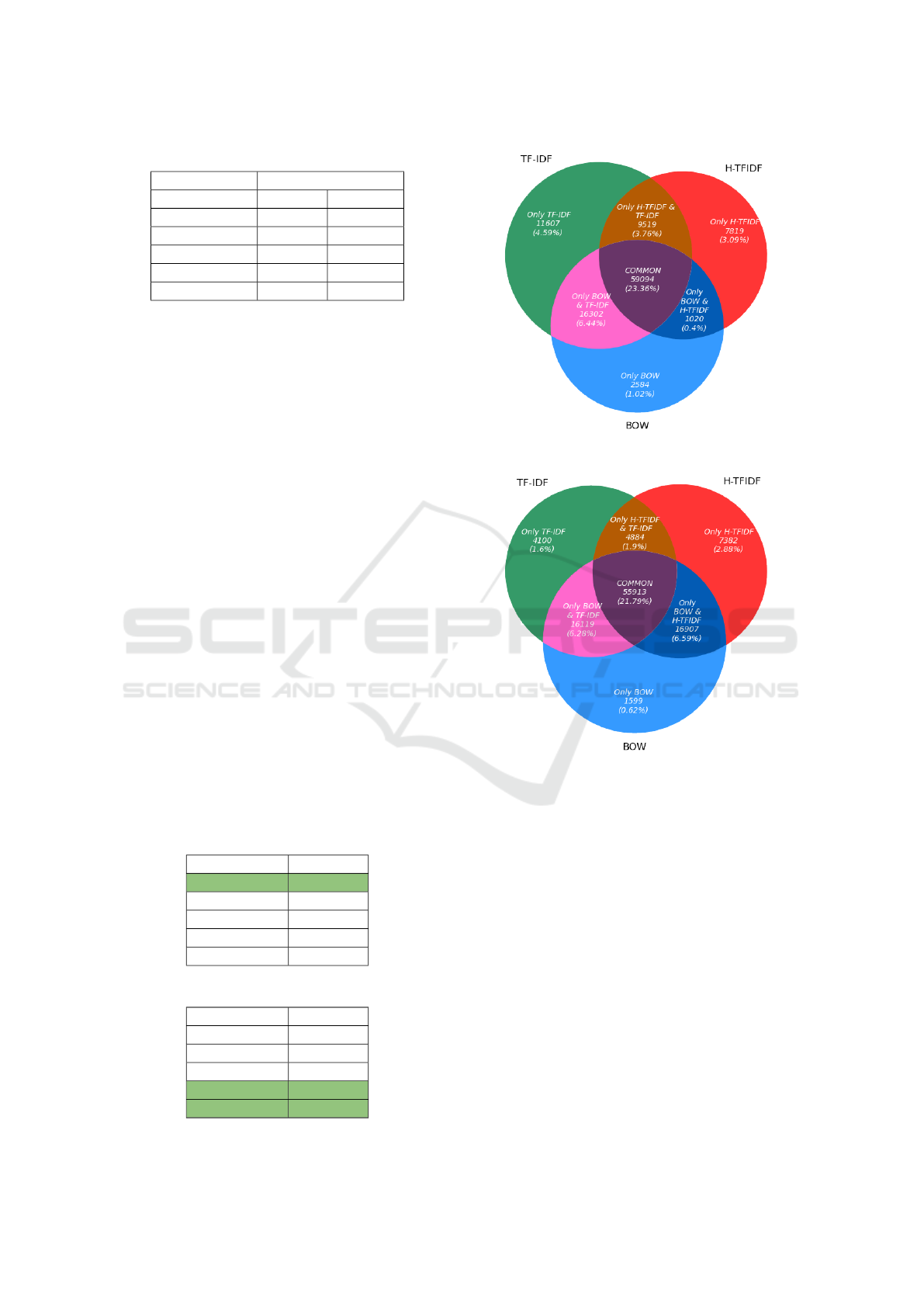
Table 3: Overall sentiment classification count.
Classification
Positive Negative
BOW 79000 90538
TF-IDF 96522 73016
H-TFIDF 77452 92086
BH-TFIDF 97536 72002
BOW+BERT 80007 89531
positive and negative opinions. Overall classified pos-
itive tweets and negative tweets using different fea-
tures are listed in Table 3. To compare different
features, tweets with similar opinions for different
features are further analyzed by the expert to find
the correct classification label. The expert manually
labeled 500 tweets as positive and negative, which
was considered the gold standard . Furthermore, the
state-of-the-art evaluation of the performance of a
classification task was measured for each feature re-
sult, i.e., BOW, TF-IDF, H-TFIDF, BH-TFIDF, and
BOW+BERT, with gold standards for classes “posi-
tive” and “negative,” respectively. The classification
matrix results in “true positives,” “false positives,”
which results in precision for each binary class re-
sult. The precision for the “Positive” predicted class
with different features is shown in Table 4. Similarly,
precision for the “negative” predicted class with dif-
ferent features is shown in Table 5. The best fea-
ture for classifying the positive class for tweets was
BH-TFIDF with a precision of 0.84. The best fea-
tures for classifying negative tweets are BOW and
BOW+BERT with precisions of 0.796 and 0.792, re-
spectively. One perspective of the discussion is
how discrete the extended features are over the state-
of-the-art features. Another perspective is how dis-
crete the extended features performed sentiment clas-
sification over the state-of-the-art features. These per-
Table 4: Positive Tweets: Precision, Recall, and F-Score.
Features Precision
BH-TFIDF 0.840
H-TFIDF 0.340
TF-IDF 0.808
BOW 0.414
BOW+BERT 0.436
Table 5: Negative Tweets: Precision, Recall, and F-Score.
Features Precision
BH-TFIDF 0.352
H-TFIDF 0.583
TF-IDF 0.354
BOW 0.796
BOW+BERT 0.792
(a) Positive tweets using BOW, TF-IDF, and H-TFIDF.
(b) Negative tweets using BOW, TF-IDF, and H-TFIDF.
Figure 3: Positive tweet comparison by features.
spectives were analyzed in two ways: 1) top ranked
features and 2) sentiment level comparison. To com-
pare specific and common features/tweets, we ap-
plied a visualization technique called a Venn dia-
gram (Ho and Tan, 2021) (see Figures 5a, 5b, 3a,
3b, 4a, and 4b). Table 6 shows the top 10 feature
terms in the corpus of COVID-19 tweets. In this ta-
ble, features such as ‘coronavirus’ and ‘China’ are
the most impacting features across different feature
models. However, ‘death’ impacts H-TFIDF and BH-
TFIDF features more than BOW features. Similarly,
‘kill,’ ‘fault,’ and ‘impact’ are less important features
for state-of-the-art BOW and TF-IDF feature mod-
els. Similarly, in the table, these features overlap in
each feature model but with differences in their rank-
ings. Next, insight into the large set of features of all
feature models was visualized using a Venn diagram.
Feature Selection for Sentiment Classification of COVID-19 Tweets: H-TFIDF Featuring BERT
653
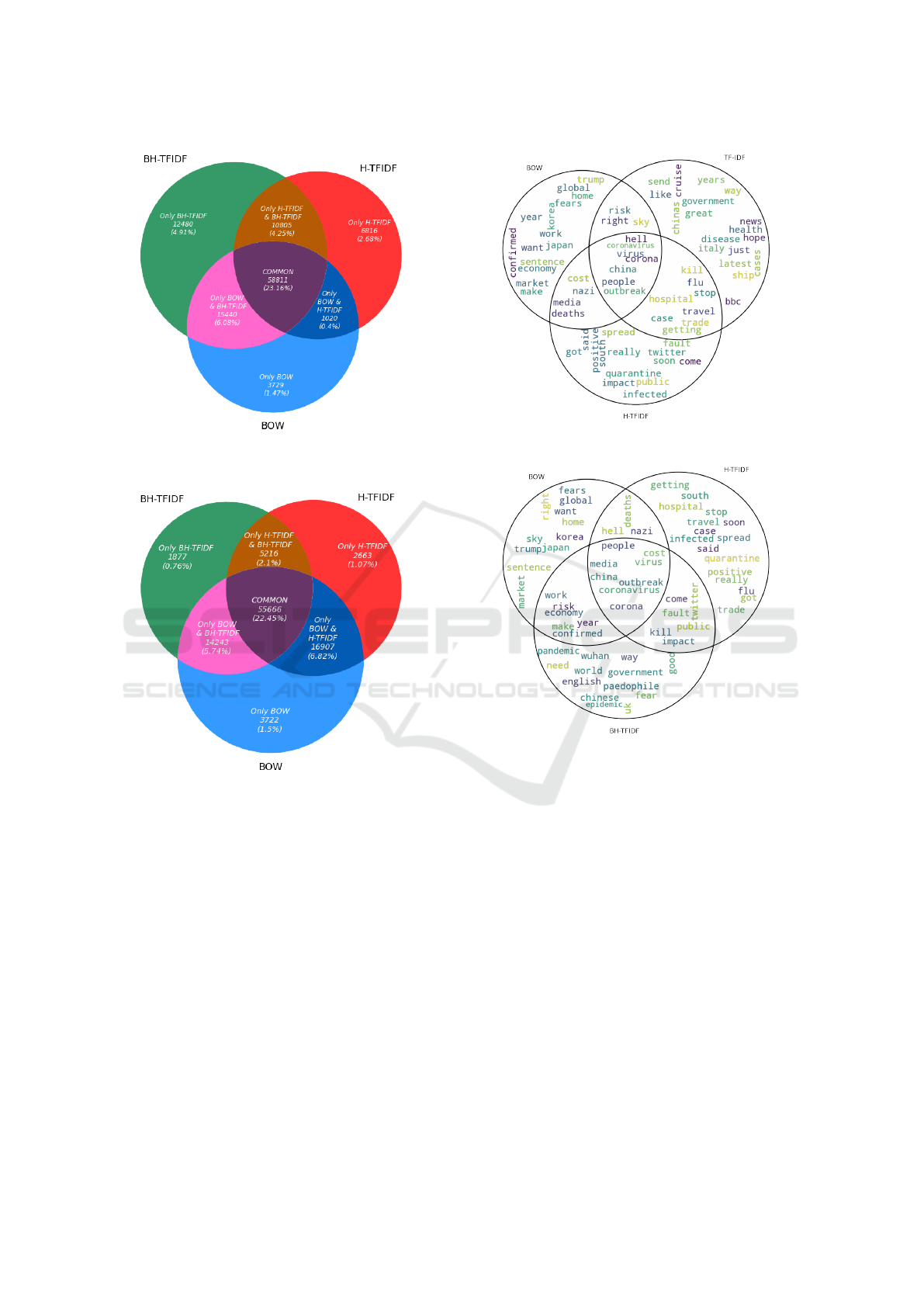
(a) Positive tweets using BOW, H-TFIDF, and BH-
TFIDF.
(b) Negative tweets using BOW, H-TFIDF, and BH-
TFIDF.
Figure 4: Negative tweet comparison by features.
Figure 5a shows BOW, TF-IDF, and H-TFIDF fea-
tures. It can be clearly visualized that the most influ-
ential features, e.g., ‘coronavirus,’ ‘outbreak,’ ‘hell,’
and ‘China,’ between them are visible in overlapping
areas. However, in contrast, there are some discrete
features, e.g., ‘quarantine,’ ‘infected,’ ‘positive,’ and
‘fault,’ in the H-TFIDF feature set that impact sen-
timent classification. Another comparison in Fig-
ure 5b shows BOW, H-TFIDF, and BH-TFIDF fea-
tures. If we gain insight into the overlap between
these features, then we clearly find some supreme
features, e.g., ‘coronavirus,’ ‘outbreak,’ ‘media,’ and
‘China.’ However, there are some distinct influen-
tial features in H-TFIDF, e.g., ‘quarantine,’ ‘infected,’
‘stop,’ ‘trade,’ and BH-TFIDF, e.g., ‘pandemic,’ ‘epi-
(a) Top BOW, TF-IDF, and H-TFIDF features.
(b) Top BOW, H-TFIDF, and BH-TFIDF features.
Figure 5: Top-ranked features.
demic,’ ‘paedophile,’ and ‘fear.’ Conclusively, TF-
IDF and H-TFIDF have more prevalent features than
BOW. In addition, there are more similarities in the
BOW and BH-TFIDF features, as shown in Figure 5a.
It is interesting that visualization shows a compari-
son of predicted results with different feature mod-
els. The first comparison provides a comparison of
positively classified tweets. Figure 3a shows the re-
sults of positive tweets for the features of BOW, TF-
IDF, and H-TFIDF. The exclusively predicted positive
tweets using TF-IDF features are 4.59%, while those
using H-TFIDF features are 3.09%, and those using
BOW are 1.02%. There are 23.06% common posi-
tive tweets among them. This analysis concludes that
TF-IDF results predict more positive tweets than H-
TFIDF and BOW. Figure 3b shows the results of neg-
ative tweets for the features of BOW, TF-IDF, and H-
HEALTHINF 2022 - 15th International Conference on Health Informatics
654

TFIDF. The comparison by percentages of each solely
negative tweet is H-TFIDF with 2.88%, BOW 0.62%,
and TF-IDF 1.62%. Moreover, the common negative
tweet percentage among all is 21.79%. In conclusion,
the features that predicted more negative tweets are
H-TFIDF over BOW and TF-IDF. Another interest-
ing result is the classification of tweets of BOW and
H-TFIDF with BH-TFIDF features. Figure 4a shows
the results of positive tweets of features, i.e., BOW,
H-TFIDF and BH-TFIDF. BH-TFIDF predicts more
exclusive positive tweets, with a percentage of 4.91%,
over BOW, with 1.47%, and H-TFIDF, with 2.68%.
The common positive tweet percentage is 23.16%
between them. Convincingly, BH-TFIDF results in
more positive tweets than H-TFIDF and BOW. Figure
4b shows the results of negative tweets using features,
i.e., . BOW, H-TFIDF and BH-TFIDF (BH-TFIDF).
BOW predicts more exclusive negative tweets with a
percentage of 1.5% than H-TFIDF with a percentage
of 1.07% and BH-TFIDF with 0.76%. The preva-
lent negative tweet percentage between these features
is 22.45%. The conclusion represented in Figure
4b clearly shows that BOW predicted more nega-
tive tweets than H-TFIDF and BH-TFIDF. The trends
of the sentiment classification using different feature
models are analyzed for both COVID-19 tweets and
gold standard labeled tweets. These trends for the
positive classification and negative classification are
the same in both datasets. This clearly shows that
BH-TFIDF features are more enriched toward posi-
tive classification of tweet data. On the other hand,
BOW and BOW+BERT are more tilted toward nega-
tive classification of tweet data.
5 CONCLUSION
This paper proposed new feature selection measures
for the sentiment classification of COVID-19 tweets.
H-TFIDF features and BH-TFIDF features (both were
enriched with contextual information) with other
state-of-the-art features were used in the classifica-
tion of tweets. These features carried out different
COVID-19 aspects such as public opinions to pro-
vide insight into the local situation and government
health concerns. In this work, we showed that BH-
TFIDF features outperform H-TFIDF features and
other state-of-the-art features, i.e., BOW and TF-IDF
for classification of positive tweets. Moreover, state-
of-the-art BOW features and BOW+BERT features
performed better than TF-IDF, H-TFIDF, and BH-
TFIDF for the negative classification of tweets.
In future work, we will focus on terminology extrac-
tion approaches for the classification of COVID-19
Table 6: Top Features of BOW, TF-IDF, H-TFIDF, and BH-
TFIDF.
BOW TF-IDF H-TFIDF BH-TFIDF
coronavirus coronavirus coronavirus coronavirus
china china china china
health death death death
spread health health health
cases news chinese spread
deaths pandemic public world
travel want kill wuhan
disease right impact fault
trade travel fault kill
economy hospital travel impact
tweets. The benefit of these approaches is that they
are weakly supervised and unsupervised. The focus
will be on term extraction of both single-word terms
and multiword terms to further generate typed dic-
tionaries of terminologies. The ultimate goal is to
study the improvements in results in comparison with
other classification methods. The proposed research
focused on sentiment analysis of COVID-19 tweets
during the beginning of the pandemic, as it may be
useful to know about the public opinion during this
period . We selected best machine learning model
i.e., LR, among other models, i.e., SVM and RF, by
applying cross-validation to evaluate model perfor-
mance. Furthermore, experiments were performed
with LR using different features (BOW, TF-IDF, H-
TFIDF, and BH-TFIDF) to predict the sentiments of
the tweets. Furthermore, the analysis of the results
showed that BOW features performed better for pre-
dicting negative tweets. However, BH-TFIDF fea-
tures were useful in predicting positive tweets in the
COVID-19 dataset.
ACKNOWLEDGEMENTS
This study was partially funded by EU grant 874850
MOOD and is catalogued as MOOD031. The con-
tents of this publication are the sole responsibility of
the authors and do not necessarily reflect the views of
the European Commission.
REFERENCES
Allain-Dupr
´
e, D., Chatry, I., Michalun, V., and Moisio, A.
(2020). The territorial impact of covid-19: Managing
the crisis across levels of government. OECD.
Ansari, G., Ahmad, T., and Doja, M. N. (2019). Hybrid
filter–wrapper feature selection method for sentiment
classification. Arabian Journal for Science and Engi-
neering, 44(11):9191–9208.
Feature Selection for Sentiment Classification of COVID-19 Tweets: H-TFIDF Featuring BERT
655

Berrar, D. (2019). Cross-validation. In Ranganathan, S.,
Gribskov, M., Nakai, K., and Sch
¨
onbach, C., editors,
Encyclopedia of Bioinformatics and Computational
Biology - Volume 1, pages 542–545. Elsevier.
Chen, E., Lerman, K., and Ferrara, E. (2020). Tracking
social media discourse about the covid-19 pandemic:
Development of a public coronavirus twitter data set.
JMIR Public Health and Surveillance, 6(2):e19273.
Decoupes, R., Kafando, R., Roche, M., and Teisseire, M.
(2021). H-tfidf: What makes areas specific over time
in the massive flow of tweets related to the covid pan-
demic? AGILE: GIScience Series, 2:1–8.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K.
(2018). Bert: Pre-training of deep bidirectional trans-
formers for language understanding. arXiv preprint
arXiv:1810.04805.
Dubey, A. D. (2020). Twitter sentiment analysis during
covid-19 outbreak. Available at SSRN 3572023.
Fernandes, B., Biswas, U. N., Mansukhani, R. T., Casar
´
ın,
A. V., and Essau, C. A. (2020). The impact of covid-
19 lockdown on internet use and escapism in adoles-
cents. Revista de psicolog
´
ıa cl
´
ınica con ni
˜
nos y ado-
lescentes, 7(3):59–65.
Ferrara, E. (2020). # covid-19 on twitter: Bots, conspira-
cies, and social media activism. arXiv preprint arXiv:
2004.09531.
Gulati, K. (2021). Comparative analysis of machine
learning-based classification models using sentiment
classification of tweets related to covid-19 pandemic.
Materials Today: Proceedings.
Ho, S. Y. and Tan (2021). What can venn diagrams teach us
about doing data science better? International Journal
of Data Science and Analytics, 11(1):1–10.
Hoang, M., Bihorac, O. A., and Rouces, J. (2019). Aspect-
based sentiment analysis using BERT. In Proceedings
of the 22nd Nordic Conference on Computational Lin-
guistics, pages 187–196, Turku, Finland. Link
¨
oping
University Electronic Press.
KazAnova (2016). Sentiment140 dataset.
https://www.kaggle.com/kazanova/sentiment140.
Kou, G., Yang, P., Peng, Y., Xiao, F., Chen, Y., and Alsaadi,
F. E. (2020). Evaluation of feature selection methods
for text classification with small datasets using mul-
tiple criteria decision-making methods. Applied Soft
Computing, 86:105836.
Kumar, S. V. K. R. (2014). Analysis of feature selection
algorithms on classification: a survey.
Madasu, A. and Elango, S. (2020). Efficient feature se-
lection techniques for sentiment analysis. Multimedia
Tools and Applications, 79(9):6313–6335.
Mansoor, M., Gurumurthy, K., Prasad, V., et al. (2020).
Global sentiment analysis of covid-19 tweets over
time. arXiv preprint arXiv:2010.14234.
Organization, W. H. et al. (2020). Aparttogether survey:
preliminary overview of refugees and migrants self-
reported impact of covid-19.
Prusa, J. D., Khoshgoftaar, T. M., and Dittman, D. J. (2015).
Impact of feature selection techniques for tweet sen-
timent classification. In The Twenty-eighth interna-
tional flairs conference.
Qaiser, S. and Ali, R. (2018). Text mining: use of
tf-idf to examine the relevance of words to docu-
ments. International Journal of Computer Applica-
tions, 181(1):25–29.
Raschka, S. (2018). Model evaluation, model selection,
and algorithm selection in machine learning. arXiv
preprint arXiv:1811.12808.
Rustam, F., Khalid, M., Aslam, W., Rupapara, V.,
Mehmood, A., and Choi, G. S. (2021). A performance
comparison of supervised machine learning models
for covid-19 tweets sentiment analysis. Plos one,
16(2):e0245909.
Schouten, K., Van Der Weijde, O., Frasincar, F., and
Dekker, R. (2017). Supervised and unsupervised as-
pect category detection for sentiment analysis with co-
occurrence data. IEEE transactions on cybernetics,
48(4):1263–1275.
Sharma, A. and Ghose, U. (2021). Lexicon a linguistic
approach for sentiment classification. In 2021 11th
International Conference on Cloud Computing, Data
Science & Engineering (Confluence), pages 887–893.
IEEE.
Shen, C.-w., Chen, M., and Wang, C.-c. (2019). Analyz-
ing the trend of o2o commerce by bilingual text min-
ing on social media. Computers in Human Behavior,
101:474–483.
Wang, Z. and Lin, Z. (2020). Optimal feature selection for
learning-based algorithms for sentiment classification.
Cognitive Computation, 12(1):238–248.
WHO (2020). Who announces covid-19 outbreak a pan-
demic.
Wisesty, U. N., Rismala, R., Munggana, W., and Purwari-
anti, A. (2021). Comparative study of covid-19 tweets
sentiment classification methods. In 2021 9th Inter-
national Conference on Information and Communica-
tion Technology (ICoICT), pages 588–593. IEEE.
Yahav, I., Shehory, O., and Schwartz, D. (2018). Comments
mining with tf-idf: the inherent bias and its removal.
IEEE Transactions on Knowledge and Data Engineer-
ing, 31(3):437–450.
¨
Ozcan, S. (2016). tweet-preprocessor: Elegant tweet pre-
processing. https://github.com/s/preprocessor.
HEALTHINF 2022 - 15th International Conference on Health Informatics
656
