
Jason Agents for Knowledge-aware Information Retrieval Filters
Dima El Zein
a
and C
´
elia da Costa Pereira
b
Laboratoire i3s, Universit
´
e C
ˆ
ote d’Azur, CNRS, UMR 7271, Sophia Antipolis, France
Keywords:
Agent Based Framework, Knowledge Aware Filter, User Knowledge, Information Retrieval, BDI Agents.
Abstract:
This paper proposes a novel use of Belief-Desire-Intention agents in Information Retrieval. We present a
cognitive agent that builds its beliefs about the user’s knowledge during his/her interaction with the search
system. The agent reasons about those beliefs and derives new ones using contextual rules. Those beliefs
serve to personalise the search results accordingly. The framework is developed using an extended version
of the Jason agent programming language; the choice of Jason’s extension to model the agents is justified by
some of its advantageous features, in particular, the possibility to represent gradual beliefs. A running example
will illustrate the presented work and highlight its added value.
1 INTRODUCTION,
MOTIVATION AND RELATED
WORK
It is increasingly common for search and recommen-
dation systems to personalise the items proposed ac-
cording to the user’s preferences, location, profile,
etc. However, most of these systems build the user’s
profile based on his/her search history and do not con-
sider the evolution of the user’s information needs
from a “cognitive point of view” (Culpepper et al.,
2018). For example, some existing contributions in
personalisation applied content-based techniques by
using the content of the documents read by the user to
construct the user’s profile (Ricci et al., 2011; Garcin
et al., 2012). The related user profiles are often
static or not frequently updated, hence they cannot
help represent the user’s knowledge, which is con-
stantly evolving. The constant evolution of the user’s
knowledge is an important aspect to be considered
when proposing information that is supposed to be
novel and/or helpful for the user to achieve a goal.
In our opinion, this gap should be essentially filled:
search results must be adapted to the users’ beliefs,
the knowledge they acquire, or even the goals they
want to achieve. The difficulty of extracting, rep-
resenting, and measuring the cognitive aspects may
explain this gap. Indeed, to the best of our knowl-
edge, there are only a few implemented work in In-
a
https://orcid.org/0000-0003-4156-1237
b
https://orcid.org/0000-0001-6278-7740
formation Retrieval (IR) systems that considers “un-
derstanding” the user’s mental attitudes (belief and
knowledge changes, goals, . . . ) and personalising the
results accordingly. We believe that to be promis-
ing, an approach should consider users as cognitive
agents (da Costa M
´
ora et al., 1998; Rao and Georgeff,
2001) with their own beliefs and knowledge of the
world.
The first contributions using an agent-based archi-
tecture in IR have been proposed twenty years ago;
the main goal was to track the user’s activities to
personalise Web search (Guttman and Maes, 1998;
Bakos, 1997). Then, in order to better understand the
user’s behaviour during the search, some user-related
characteristics, such as location and type of device,
were considered (Carrillo-Ramos et al., 2005; Kuru-
matani, 2004). In (Yu et al., 2021), the authors ex-
plored the correlation between the content of a doc-
ument read and the search behaviour from the one
hand, and a user’s knowledge state and knowledge
gain from the other hand. The results showed that
the knowledge gain can be predicted from the users’
search behaviour and from the content features of the
documents they read (e.g., number of money words,
number of religion words, number of words in each
page, etc.).
A theoretical proposal for an IR framework con-
sidering the user’s knowledge to personalise the
search result was recently proposed in (El Zein
and da Costa Pereira, 2020a). The scope of the
framework was textual document retrieval where the
user’s knowledge was assumed to be the informa-
466
El Zein, D. and Pereira, C.
Jason Agents for Knowledge-aware Information Retrieval Filters.
DOI: 10.5220/0010884900003116
In Proceedings of the 14th International Conference on Agents and Artificial Intelligence (ICAART 2022) - Volume 2, pages 466-476
ISBN: 978-989-758-547-0; ISSN: 2184-433X
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

tion contained in the document(s) he/she was read-
ing. The framework considered an agent, designed in
a Belief-Desire-Intention (BDI) architecture (Rao and
Georgeff, 2001), and was made “aware” of the user’s
knowledge. The agent’s beliefs represent the user’s
knowledge that is extracted from the documents the
user has read. Beliefs are considered to be gradual
and are associated to some degrees that define the ex-
tent to which a piece of knowledge is “entrenched”.
These degrees represent the preferences between be-
liefs, and are used in case of divergence or contradic-
tion between new and old beliefs. In particular, they
help deciding which belief to maintain and which to
discard in case of contradiction. The agent also has
some contextual rules (or knowledge rules) that are
used to derive new beliefs. The main task is to “filter”
the search results returned by an IR system to fit the
user’s knowledge.
In (El Zein and da Costa Pereira, 2020b) the au-
thors extended the Jason platform (Bordini et al.,
2007) in order to account for the concept of graded
beliefs, implement belief reasoning and belief chang-
ing capabilities. The resulting approach allows agents
to reason about the degree of certainty of beliefs, track
the dependency between them and revise the belief set
accordingly.
In this paper, we propose an Information Fil-
ter agent which puts together the advantages of
the theoretical framework proposed in (El Zein and
da Costa Pereira, 2020a) with the extended Jason
platform proposed in (El Zein and da Costa Pereira,
2020b). We will develop and describe the implemen-
tation of such a framework, and discuss the advan-
tages and challenges associated with it.
For example, if the user reads a document about
human evolution, the agent will be aware of the user’s
knowledge of that subject. Then, suppose the user
submits the query “Charles Darwin”, the search sys-
tem returns a list of documents on several topics about
Darwin, such as his bibliography, his theory of natural
selection and social Darwinism. Since the agent be-
lieves that its user already has knowledge about natu-
ral selection, it should decide which, among the docu-
ments relevant to the user’s query, to return and which
not to. For example, if the agent’s purpose is to re-
turn new information, then documents dealing with
the subject of natural selection will be discarded.
The language required to develop our filtering
agent must allow the following: (1) representing the
user’s knowledge in the form of agent beliefs (2) asso-
ciating beliefs to a degree of entrenchment (3) revis-
ing the beliefs in case of contradiction (4) updating
the degree of a belief if it already exists (5) deriving
new beliefs by reasoning with the knowledge rules.
All the mentioned conditions are satisfied in the ex-
tended version of Jason (El Zein and da Costa Pereira,
2020b).
The paper is organised as follows. Section 2 dis-
cusses the preliminaries to understand the features of
the framework. Section 3 describes Jason, its current
limitations, and the features of its extended version.
Section 4 discusses the cognitive IR framework. Sec-
tion 5 describes the proposed implemented prototype
as a proof-of-concept in the news articles (BBC) do-
main and, finally, some conclusions and perspectives
of future work are presented in Section 6.
2 PRELIMINARIES
2.1 Rule-based Agents
A Rule-based agent (Jensen and Villadsen, 2015) has
a belief base consisting of facts (ground literals) and
rules (Horn clauses). The facts can originate from
communication with other agents, observations of
the environment, downloaded information from web
sources or other ressources. Facts might change over
time as a result of the inference process or of the
addition and deletion of other facts from the agent’s
belief base. A literal α is a predicate symbol that
is possibly preceded by a negation symbol ¬. We
consider a finite set R of rules, which have of the
form α
1
&α
2
...&α
n
→ β where α
1
,α
2
,...,α
n
(n ≥
1) and β are literals. β is called the derived belief,
and each α
i
is a premise of the rule. The & represents
the logical and operator. We consider the agent’s be-
liefs when the agent’s rules have run to quiescence,
i.e., after all the agent’s rules have been applied to all
the literals in the agent’s memory. Note that this set is
finite if the original set of rules and ground literals is
finite.
2.2 Belief Revision and Partial
Entrenchment Ranking
Belief revision is, by definition, the process of modi-
fying the belief base to maintain its consistency when-
ever new information becomes available. The AGM
belief revision theory (Alchourr
´
on et al., 1985) de-
fines postulates that a rational agent should satisfy
when performing belief revision. In such a theory,
a belief base is closed under logical consequence. We
consider a belief base K and a new piece of informa-
tion α. K is inconsistent, when both α and ¬α are
in Cn(K), or Cn(K) = ⊥, or both α and ¬α are log-
ical consequences of K. Three operators are consid-
ered: Revision K ∗ α : adds a belief α as long as it
Jason Agents for Knowledge-aware Information Retrieval Filters
467

does not cause a contradiction in K. If the addition
will cause inconsistencies in K, the revision opera-
tion starts by minimal changes in K to make it con-
sistent with α, then adds α. Expansion K + α: adds
a new belief α that does not contradict with the ex-
isting beliefs. Contraction K ÷ α: removes a belief
α and all other beliefs that logically imply/entail it.
The sentences in a belief set may not be considered
equally important as it is assumed in the AGM pos-
tulates: belief is gradual and an agent might have be-
liefs more entrenched/accepted than others. Williams
(Williams, 1995) have proposed a quantitative ap-
proach for the AGM framework, by developing finite
partial entrenchment rankings to represent epistemic
entrenchment – a piece of information is labelled by
a degree of confidence denoting how strongly we be-
lieve it. The epistemic entrenchment (G
¨
ardenfors and
Makinson, 1988) captures the notions of significance,
firmness, or defeasibility of beliefs.
Intuitively, epistemic entrenchment relations in-
duce preference orderings of beliefs according to their
importance in the face of change. If inconsistency
arises during belief revision, the least significant be-
liefs (i.e., beliefs with the lowest entrenchment de-
gree) are given up until consistency is restored. The
belief revision operator(s) must then take into con-
sideration the degree i of the belief to be added and
decide whether to add it or not. We discuss later in
Section 5.1 the belief revision algorithm K ∗ (α, i) we
followed.
2.3 Alechina’s Belief Revision and
Tracking
Alechina et al. (Alechina et al., 2005) proposed be-
lief revision and contraction algorithms for resource-
bounded agents. They consider a finite state and a
finite program having a fixed number of rules used to
derive new beliefs from the agent’s existing beliefs.
The approach associated a preference order (similar
to Williams’ approach (Williams, 1995) ) for each be-
lief and tracked dependencies between them.
For every fired rule instance, a Justification J will
record: (i) the derived belief and (ii) a support list,
s, which contains the premises of the rules. The de-
pendency information of a belief had the form of two
lists: dependencies and justifications. A dependen-
cies list records the justifications of a belief, and a
justifications list contains all the Justifications where
the belief is a member of support. The approach rep-
resents the agent’s belief base as a directed graph with
two types of nodes: Beliefs and Justifications. A Jus-
tification has one outgoing edge to the belief it is a
justification for, and an incoming edge from each be-
lief in its support list.
Preference on Beliefs and Quality of justifications
As beliefs are associated with preferences, justifica-
tions are associated with qualities. A quality of a
justification is represented by non-negative integers in
the range [0, . . . , m], where m is the maximum size of
working memory. The lower the value, the least the
quality.
Definition 1. The preference value of a belief α,
p(α), is equal to that of its highest quality justifica-
tion.
p(α) = max{qual(J
0
),...,qual(J
n
)} (1)
Definition 2. The quality of justification J, qual(J),
is equal to the preference of the least preferred belief
in its support list.
qual(J) = min{p(α) : α ∈ support of J} (2)
Independent beliefs have at least one justification
with an empty support list (non-inferential justifica-
tion). They are usually those in the initial belief base
or those perceived from the environment. It was as-
sumed that non-inferential justification is associated
with an a priori quality.
3 JASON: PROPERTIES,
LIMITATIONS & EXTENSION
This section presents an overview of the Jason lan-
guage’s architecture (Bordini et al., 2007) and its fea-
tures (v.2.4) (Jas, 2021). We also discuss the features
and the motivation of the extended version proposed
in (El Zein and da Costa Pereira, 2020b) that we will
use later in our framework.
3.1 Architecture
A Jason agent, similarly to other agents modeled in
BDI, is defined by sets of beliefs, plans, and goals or
intentions. Jason’s beliefs are represented by predi-
cates. Their existence in the agent’s belief base means
the agent currently believes that to be true. The ∼ op-
erator refers to the negation, explicitly representing
that the agent believes a literal to be false. Annota-
tions distinguish the Jason syntax: an annotation is a
list of terms placed after a belief, enclosed in square
brackets, revealing details about it.
A plan is composed of three parts: the triggering
event, the context, and the body. It is expressed as
follows:
+triggering event : context ← body. (3)
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
468

Table 1: Comparison between Jason and its extension’s fea-
tures.
Feature Original Extended
Beliefs
Dependencies Not tracked Tracked
Inconsistency Accepted
Not
accepted
Graded No
Yes
(degOfCert)
Preference
1
No
preference
High Low
New Old
Plans
Knowledge-rule with
n conditions
n plans 1 plan
Order of conditions Dep—endent Independent
(with +tei)
Execution of applica-
ble plans with same
triggering event
One plan
only
All plans
triggering event represents one condition that might
initiate the plan’s execution; it can be the addition (+)
or deletion (-) of a belief or a goal. context is a con-
junction of literals that need to be satisfied to make the
plan applicable – and possibly executed. A plan is ap-
plicable if: (i) first, its triggering event occurred, and
(ii) its context (one or several conditions) is a logical
consequence of the agent’s current beliefs. The body
is a sequence of actions or goals to be achieved upon
the plan execution. Together the triggering event and
the context constitute the plan’s head.
3.2 Extension of Jason: Graded Belief
Revision
The subject Jason extension (El Zein and
da Costa Pereira, 2020b) models knowledge-rule
agents that are capable of reasoning with uncertain
beliefs, tracking the dependency between beliefs
as done in (Alechina et al., 2005) and explained in
Section 2.3 and revising the belief set accordingly.
In the following, we highlight the limitations of the
original version and how the extension overcame
them. Table 1 compares the features of the two
versions.
3.2.1 Representation and Execution of
Knowledge Rules
To represent a rule having n conditions in the form of
α
1
&α
2
...&α
n
→ β using Jason plans, the premises
of rules are supposed to be in the plan’s head. That
1
refers to “more preferred”.
means that one of the conditions of the premises must
be the triggering event and the others in the context
(for example, +α
1
: α
2
&...α
n
→ β ). However,
the plan execution in the original Jason version is re-
liant on the occurrence of the triggering event: a plan
is executed only if the context conditions were sat-
isfied before the triggering event takes place. The
order of the triggering event and the context condi-
tions matters for the execution of a plan. If the con-
dition a
1
was satisfied before the others, the plan will
not be executed. One alternative could be to write n
plans. The extended version of Jason allows the ex-
pression of knowledge-rules by the so-called Trigger-
Independent plans. Those plans will be executed
whenever the combination of several conditions is sat-
isfied, no matter which condition was satisfied first. In
other terms, they do not wait for one specific trigger
condition to occur to execute the plan. The syntax of
Trigger-Independent plans should have the reserved
word “+tei” that stands for trigger event independent
in the trigger part and all the other conditions in the
context. The plan’s new syntax to represent knowl-
edge rules is proposed:
+tei : context
0
← body. (4)
context
0
has all the premises α
1
& α
2
&...&α
n
and
the body contains β the derived belief.
Using the original Jason in the case where two or
more plans had the same trigger and all had a satisfy-
ing context field, would return only one plan for exe-
cution. The returned plan would be by default the first
plan according to the order in which plans were writ-
ten in the code. Contrarily, using the extension in the
same case would return/execute all the plans having
satisfying conditions.
3.2.2 Degree of Certainty
The notion of “believing” in Jason is Boolean: An
agent either believes something is true or false or is ig-
norant about it. The extension allowed the representa-
tion of gradual beliefs by expressing “degOfCert(X)”
in the annotation part of a belief - X represents the
belief certainty defined as follows: We define the cer-
tainty of a belief α as representing the degree to which
the agent believes the belief is true.
The degree of certainty associated with initial be-
liefs, beliefs communicated by other agents and be-
liefs perceived by the agent must be explicitly defined
by the source. As for derived beliefs their related de-
gree will be discussed in 3.2.3.
3.2.3 Deriving and Tracking Beliefs
Derived beliefs are dependent on the premises that
derived them; therefore to calculate their related de-
Jason Agents for Knowledge-aware Information Retrieval Filters
469
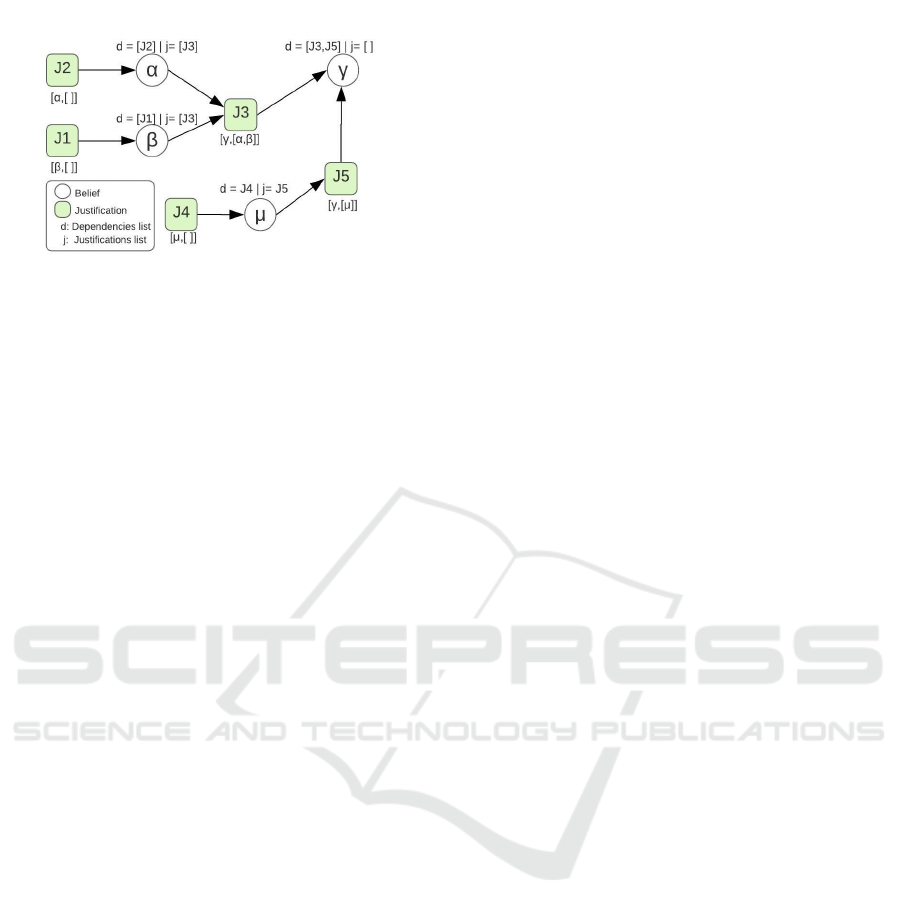
Figure 1: Graph over the beliefs and justifications.
gOfCert, the dependency between beliefs must be
tracked. The extension tracked the beliefs following
the approach discussed in 2.3: a justification is repre-
sented by a derived belief, a support list, and a qual-
ity; a belief is represented by a dependencies list, a
justifications list and a degree of certainty. Whenever
a knowledge-rule, named trigger-independent plan, is
fired and a new belief is added, a justification node is
created. This node links the rule’s premises with the
derived belief. The degree of a derived belief is au-
tomatically calculated by the interpreter using Equa-
tion 1. When any of the beliefs is contracted, the re-
lated justifications are removed as well. Justifications
with an empty support lists are created upon the addi-
tion of initial, communicated, and perceived beliefs.
Unlike in (Alechina et al., 2005), no a priori quali-
ties are assigned for the justification of independent
beliefs, as the degrees are explicitly stated.
Example 3.1. Figure 1 illustrates the belief tracking,
considering four beliefs α, β, γ, and µ, and a rule α
& β → γ. The rule means that if the agent believes in
α and β, it believes in γ. For example, Justification
J
3
is denoted as (γ,[α,β]); γ is the derived belief and
[α,β] is the support list. J
3
is in the dependencies list
of γ and in the justifications list both α and β. If γ
were also derived from µ, i.e. µ → γ, then its depen-
dencies list would also include another justification
J
5
denoted as (γ,[µ]). If the belief α was the result of
an observation, its dependencies list would include a
justification J
2
= (α,[]) having an empty support list.
3.2.4 Belief Revision
Contradictory beliefs were accepted in the Jason’s be-
lief base and no belief revision was performed; no
preference on beliefs neither. The agent could believe
in α and its opposite ∼ α at the same time. The ex-
tended version integrated the notion of belief’s cer-
tainty into the belief revision decisions and did not al-
low belief inconsistency. In case of contradiction, the
preference is given for the belief with the higher de-
gree: belief with the smaller certainty degree in the in-
consistency pair will be contracted/discarded, and the
other belief will be added/kept. In the case of equal
certainties, the new belief is given the preference.
A contraction algorithm was proposed: A belief α
is not contracted unless a more preferred belief ∼ α
was added. When contracting a belief α, there is no
need to contract beliefs that derived it: when the rule
deriving α will attempt to add it again, the addition
will be discarded because it will be faced by ∼ α that
is more preferred. In other terms, the belief in ques-
tion is contracted with its related justifications without
contracting neither the rule’s premises nor the rule it-
self. Beliefs with no justifications will also be con-
tracted.
4 THE KNOWLEDGE-AWARE IR
FRAMEWORK
The IR framework proposed in (El Zein and
da Costa Pereira, 2020a) consists of a search agent
that personalises results to the user’s knowledge. The
framework considers a client-side agent that uses the
content of the documents read by the user to under-
stand his/her knowledge. For every submitted query,
the flow is as follows: (i) the agent sends the query to
the search system and receives a list of candidate doc-
uments (ii) the agent examines the content of the doc-
uments in the list and measures the similarity of each
document with the set of beliefs (iii) the agent returns
a filtered list of documents according to the similar-
ity results (iv) the user reads a document (v) the agent
considers the content of the document is an acquired
knowledge by the user. The keywords representing
the examined documents are added as agent beliefs
(vi) a reasoning cycle is performed to run the applica-
ble rules and revise the beliefs whenever needed.
The IR agent is modeled as a Rule-based entity.
When the IR agent has α in its belief base, it believes
that the user knows that α is true. If the belief base
contains ¬α, then the agent believes the user knows
that α is not true. When neither α nor ¬α is in the
belief base, the agent believes neither the user knows
α is true nor the user knows that α is false. The agent
also has some knowledge rules that will help it reason
and derive news beliefs. During an agent’s reasoning
cycle, the validity of the rules is checked. A rule is
considered valid if all the conditions in the premises
are satisfied (the premise exists in the belief base), the
rule is fired and the belief in the body is added as a
belief. The rules were considered static, and their ex-
traction/origin was not discussed.
The agent acquires its beliefs about the user’s
knowledge from the documents the user has read.
When the user reads a document d, the agent extracts
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
470

the document’s content and considers it an acquired
knowledge by the user. The authors in (El Zein
and da Costa Pereira, 2020a) applied the Rapid Auto-
matic Keyword Extraction RAKE (Rose et al., 2010)
as an easy and understandable method, to extract the
set of keywords representing the document and cal-
culate their related score. The agent’s beliefs will be
then represented by the set of keywords extracted with
RAKE, called extracted beliefs.
Knowledge is gradual: an agent might have be-
liefs more entrenched than others. The “degree” mea-
suring this entrenchment is defined as below:
Definition 3. The degree of a belief α is the degree
to which the agent believes the user is knowledgeable
about α. It is represented by a decimal [0; 1], where 0
means the lowest degree –the agent believes the user
has absolutely no knowledge about α, and 1 means
the highest degree –the agent believes the user has
the maximum knowledge about α.
A document d = {(k
1
;s
1
),...,(k
n
;s
n
)} is a set of
tuples where k
i
is the keyword extracted by RAKE and
s
i
is its related score. k
i
is associated with an ex-
tracted belief b
v
whose degree is calculated as fol-
lows:
degree(b
v
) = λ ·
s
i
max(s
j
)
k
j
∈d
(5)
In Equation 5 the RAKE score of an extracted key-
word is normalized then multiplied by an adjustment
factor λ ∈ [0,1] that weakens the scores’ magnitude.
The factor’s value may vary based on different factors
like the source of the document, for example.
This equation allows the calculation of the degree
for extracted beliefs only. As for derived beliefs, their
degrees will depend on the degree of premises that de-
rived them. For that reason, the beliefs’ dependency
is tracked using Justifications and nodes as discussed
in Section 2.3.
The filtering process is based on the similarity
Sim(B,d) between the agent’s set of beliefs B =
{(b
1
;degree(b
1
)),...,(b
m
;degree(b
m
))} and the con-
tent of a document d = {(k
1
;s
1
),...,(k
n
;s
n
)} to be
proposed to the user. A similarity measure was pro-
posed considering the degrees of the intersected be-
liefs and the document knowledge.
Sim(B,d) =
(
max{
∑
n
k
i
∈d
[e(B,k
i
))−e(B,¬k
i
)],0}
|S|
if |S| 6= 0
0 otherwise.
(6)
The formula is inspired by the similarity function
proposed by Lau et al. in (Lau et al., 2004). S is the
set of keywords appearing both in d and in B, defined
by S = {k
i
∈ d : e(B,k
i
) > 0 ∨ e(B,¬k
i
) > 0}.
The extent e(B,k
i
) = degree(k
i
) if k
i
∈ B; and 0
otherwise. In simple terms, the similarity formula
calculates the average belief degree of the intersected
keywords between the document and the beliefs. The
result is a value between 0 and 1; where 1 means that
all the intersected keywords are strong entrenched be-
liefs. A similarity 0 means either that the document
has no keywords in common with the beliefs or that it
contains more contradictory information than similar
ones when compared to the beliefs.
The similarity formula “rewards” the documents
containing common keywords with the set B and pe-
nalizes those containing keywords whose correspond-
ing negated beliefs are in B.
Finally, a cutoff value γ is set for Sim(B, d) that
allows deciding whether the knowledge inside a doc-
ument is similar to a set of beliefs or not. We can cite
at least two main applications for this framework: (1)
Reinforcing the user’s knowledge: returning the doc-
uments that are “close” to the agent’s beliefs (those
having a similarity score higher than the cutoff) will
be returned. (2) Novelty: returning documents with
new content with respect to what the user already
knows, the documents having similarity below the
cutoff will be returned.
5 PROPOSED INFORMATION
FILTER AGENT
5.1 System Design
The primary concern of this paper is the development
of a proof of concept of an agent-based system in
the cognitive IR domain. We develop the IR filter
discussed in Section 4 using the extended version of
Jason discussed in Section 3.2. The work presented
here is, to our knowledge, the first implemented work
of information filter agents that considers the user’s
knowledge. We justify the choice of the extended Ja-
son language to model agents by its ability to model
rule-based agents.
Jason’s extension considers beliefs as facts, as-
signs entrenchment degree to them represented by de-
gOfCert and deals with belief inconsistency. It also
allows the representation of knowledge-rules that will
derive new beliefs thanks to the trigger-independent
plans. In addition, Jason implements the dependency
approach proposed by Alechina et al. in (Alechina
et al., 2005), and used in (Alechina et al., 2006), to
track the dependencies between beliefs by associat-
ing dependency and justifications lists for each be-
lief. Another particular advantage of Jason is that it
is an open-source interpreter written in Java, which
makes the development easy and customisable. A fur-
Jason Agents for Knowledge-aware Information Retrieval Filters
471

ther advantage of choosing the Jason extension pro-
posed in (El Zein and da Costa Pereira, 2020b) to im-
plement the IR framework proposed in (El Zein and
da Costa Pereira, 2020a) is that both, the framework
and the extension, track the beliefs by following the
method discussed in Section 2.3.
To perform the proposed integration, we associate
the notions of the IR framework to the Jason’s lan-
guage as follows:
• Jason’s beliefs are the agent’s beliefs about the
user’s knowledge.
• The entrenchment degree of a belief will be rep-
resented by the degOfCert in Jason’s belief anno-
tation. It will represent the agent’s estimation of
the user’s knowledge regarding a concept.
• Initial beliefs: are beliefs that represent initial in-
formation about the user. Their degrees are ex-
plicitly expressed in the beliefs’ annotation. Dur-
ing the first reasoning cycle, for every initial be-
lief, one justification with an empty support list is
created.
• Extracted beliefs: are keywords extracted from
the content of the documents. They will be con-
sidered as perceived beliefs and their belief degree
will be calculated as per Equation 5.
• Derived beliefs: are beliefs that result from firing
the applicable rules and from the reasoning pro-
cess. Their degree is calculated as per Equation 1.
• Contextual rules: are considered static and cannot
be revised.
The facts represent information that the agent has
currently obtained about its user’s knowledge. The
user’s knowledge is represented as Jason beliefs, their
related degree is expressed as degOfCert tracked in
the belief annotation. Those beliefs might change
over time as a result of the addition/deletion of other
beliefs due to: (i) reading new documents that might
contain new information, contradictory information,
or redundant information with different degrees, and
to (ii) the rule’s reasoning process itself, that will de-
rive new beliefs from the agent existing beliefs or
delete beliefs in case of inconsistency. To repre-
sent a rule α
1
&α
2
→ β in Jason, the syntax is +tei :
α
1
& α
2
← β.
To maintain the belief base consistency, the en-
trenchment degree of beliefs must be raised or low-
ered via a belief revision operation K ∗ (α,i) where α
is a new belief and i is its new entrenchment degree.
We propose the following to revise belief:
K ∗ (α, i) =
If α /∈ K : K + (α,i)
If α ∈ K :
K + (α,i), if i > j
Nothing, if i < j
If ¬α ∈ K :
K ÷ (¬α, j) then K + (α,i), if i > j
Nothing, if i < j
(7)
The revision operator checks first if α already exists in
the belief base. If it is not in the belief base, it is added
with the degree i. If α already exists, the two degrees i
and j are compared. When the new degree i is smaller
than the existing degree j, the degree of α in the belief
base is not changed. When i is higher than the existing
degree j, an expansion operation K + (α,i) will be
initiated and will increase the degree of α from j to i.
The revision operator finally checks if ¬α is already
in the belief base. If it already exists with a degree
j, the preference will be given to the belief with the
higher degree. When i is higher than j, α will have
the preference to stay, ¬α must be first contracted (or
assigned the lowest entrenchment degree equal to zero
for example). Then, α is added with degree i. Finally,
when i is smaller than j, the addition of α is discarded.
5.2 Use Case: Application for Novelty
We built the information system framework discussed
in Section 4 in Java and modeled the filter agent us-
ing the extended version of Jason discussed in Sec-
tion 3.2. We present in this section a use case of
an interaction between a user and the proposed sys-
tem. The system will be employed to return novel
documents with respect to the user’s knowledge. We
examine the returned results in response to the sub-
mitted queries, investigate the knowledge extraction
process and discuss the filtering decision.
The IR part is built on top of the open-source li-
brary Apache Lucene (luc, 2020) configured with the
standard analyser for indexing and for searching. It is
set to return 10 documents ranked by relevance to the
query. We use a public dataset of short BBC articles
(Greene and Cunningham, 2006), select the 400 doc-
uments of the technology topic and remove duplicate
documents. We rename the text files to include the
article’s title and finally build the search index.
We choose to set the adjustment factor λ of Equa-
tion 5 to be equal to 0.9. The advantage of this fac-
tor is that it prevents having the entrenchment degree
of the most representative keyword of a document d
to be equal to 1. The mentioned keyword is the one
having the maximum RAKE score: k
i
where k
i
∈
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
472

Figure 2: Initial state of Jason filtering agent.
Figure 3: The list of documents returned by Lucene for q
1
.
d and s
i
= max(s
j
)
k
j
∈d
; when its related entrench-
ment degree is calculated it is “normalised” by divid-
ing it by itself which results to 1. That would mean
if the user has read a document having “Vaccine effi-
ciency” as the most representative keyword, the agent
would consider the user already reached the maxi-
mum knowledge about vaccine’s efficiency, which is
not realistic. We set the similarity’s cutoff value, in-
troduced in Section 4 to γ = 0.25. This value is the
threshold to the similarity Sim(B, d) between the be-
lief set and the candidate document d. In a novelty
context, only documents having a similarity smaller
than γ are returned. The closer the cutoff value is to
0 the more conservative the approach and the more
novel documents are returned.
We assume at time zero, i.e. before the user-
system interaction starts, the agent has no informa-
tion about the user: the belief set B is empty. The
agent has a plan representing a contextual rule that
derives the user knows about the Sony corporation if
he/she knows about both the Gizmondo store and the
PlayStation portable psp. This plan could originate
for example from mining contextual knowledge from
textual corpus, like the information flow discussed
(Lau et al., 2004). The initial state of the agent is
expressed in Figure 2.
The interaction starts by submitting a query
q
1
“Gaming device”. The agent relays the query to
Lucene and receives a ranked list of 10 documents re-
sponding to the query -displayed in Figure 3. Since
the agent has no beliefs about the user’s knowledge
yet, there is nothing to compare with the content of
the documents. In this case, any document’s content
will be considered novel to the user’s knowledge. In
consequence, the agent proposes to the user the list of
10 documents without any filter applied.
Table 2: Sample of the keywords extracted from d
363
.
Belief
RAKE
Score
Belief
Degree
the gizmondo combined media player 28.1 0.65
multi player gaming 9.3 0.21
gaming gadget 6.3 0.14
gizmondo store 5.7 0.13
the psp 5.3 0.12
ds handheld 4.7 0.1
Knowledge Extraction and Belief Representation.
The user selects for reading the document d
359
en-
titled “Gizmondo gadget hits the shelves”. The in-
formation inside it will be acquired by the user as
new knowledge. To represent this knowledge, the
agent uses RAKE to extract the keywords represent-
ing the document and associates to each of them an
entrenched degree. 39 keywords are extracted from
the document, some of which are illustrated in Table
2. We have replaced the spaces between words with
underscores in order to respect the syntax of Jason’s
belief. The table shows the RAKE score of some key-
words as well as their associated entrenchment degree
calculated using Equation 5.
In d
359
, the keyword “the british-backed gadget
faces stiff competition” has the highest RAKE score
max
s
j
∈d
(s
j
) = 38.6 . To normalize the scores of other
keywords, their RAKE score will be divided by 38.6
then multiplied by the adjustment factor λ. If we con-
sider for example the belief “gaming gadget” having
a rake score of 6.3, its entrenchment degree is cal-
culated as follows deg(gaming gadget) = 0.9 ·(6.3 ÷
38.6) = 0.14. This means that the agent believes the
user has some knowledge about gaming gadget with
the degree 0.14 on a scale of 0 to 1. In total, 39 expan-
sion operations B + (α,Belie f Degree) are performed
to add the new beliefs.
Reasoning and Deriving Beliefs. Once the knowl-
edge is extracted and the beliefs were added, a
reasoning cycle is run to fire applicable rules and
derive new beliefs if needed. After reading the docu-
ment d
359
, the agent plan becomes applicable since its
premises conditions are satisfied: the gizmondo store
and the psp beliefs are in the belief base. Therefore,
the plan is fired and its body gets executed: the belief
sony is added. To calculate the entrenchment degree
of the derived belief, a Justification J
1
gets cre-
ated with a quality degree equal to qual(J
1
) =
min{deg(gizmondo store),deg(the psp)} =
min{0.13;0.12} = 0.12. The belief sony is then
added with degree(sony) = max{qual(J
1
)} = 0.12.
B + (sony, 0.12) is performed.
Filtering the Results. The user submits another
query q
2
“PSP”, Lucene returns to the agent 10 can-
didate documents displayed in Figure 4. Now that the
Jason Agents for Knowledge-aware Information Retrieval Filters
473

agent is aware about the user’s knowledge, it is capa-
ble of filtering the documents according to what the
user knows. The similarity Sim(B,d) between the set
of beliefs and the content of each of the 10 documents
will be measured.
We take for example d
025
and d
363
, calculate their
similarity with the belief set and examine the re-
lated filtering decision. The document d
025
enti-
tled “Sony PSP console hits US in March” is rep-
resented by 19 keywords, out of which 1 is com-
mon with the belief set. The set of keywords ap-
pearing both in d and in B is S = {ds handheld}.
Sim(B,d
025
) = max{degree(ds handheld, 0} ÷ 1 =
max{0.1,0} ÷ 1 = 0.1. On the other side, d
363
entitled “sony psp handheld console hits us” has
4 out of 41 common keywords with the belief
set. S = {the gizmondo combined media player,
gaming gadget, the psp, multi player gaming} , the
Sim(B,d
363
) = max{0.65 + 0.21 + 0.14 + 0.12,0} ÷
4 = 0.28. By interpreting these similarities, we con-
clude that d
363
is more similar to the belief set (rep-
resenting the user’s knowledge) than d
025
. In other
terms, if the user reads d
025
, he/she will acquire less
novel information compared to d
363
.
Knowing that the similarity cutoff value is 0.25,
8 documents are returned to the user including d
025
and excluding d
363
. The list of returned documents
is displayed in Figure 4. Recalling that the aim of
this example is to return the documents having novel
content: documents having a similar content with the
agent’s beliefs should be excluded. Notice that d
359
was returned by Lucene in response to query q
2
but
filtered out by the agent because it was already read
by the user. The similarity with the belief set is 1.
Belief Expansion. In response to q
2
the user se-
lects to read d
025
. The 19 keywords representing
the document are then added as the user’s knowl-
edge: the belief base is revised by 19 keywords B ∗
(α,Belie f Degree) as discussed in Section 2.2. The
associated entrenchment degree for ds handheld (the
only common keyword with the belief base) is 0.58.
When the agent is adding this belief, it notices that the
user already has some knowledge about it of 0.1. The
agent then increases the related belief degree to 0.58.
A reasoning cycle runs, they are no contradictions
to resolve and no plans to fire.
6 CONCLUSION AND FUTURE
WORK
This work presented a new use of BDI agents in IR. In
the proposed framework, the beliefs of a BDI (Jason)
agent have been used to represent the user’s knowl-
edge. Besides, the beliefs can be gradual; their related
degrees reflect how entrenched is an agent’s belief
about the user’s knowledge regarding a specific topic.
The agent also can reason about the user’s knowledge,
derive new facts, and decide which belief(s) to hold in
case of inconsistency. The proposed gives the oppor-
tunity of usage in applications requiring personaliza-
tion and understanding of certain cognitive aspects of
the user.
Two of the possible applications of the framework
are (1) novelty, where the returned documents must
contain new information with respect to the user’s
knowledge and, (2) knowledge reinforcement, where
documents must contain information that is similar to
what the user already knows.
We have also presented an example as a proof of
concept of our proposal. We developed the cogni-
tive framework in Java, built the search index with
the Lucene library (luc, 2020), integrated it with Ja-
son’s extension (El Zein and da Costa Pereira, 2020b)
and finally tested it on a dataset of BBC short news
(Greene and Cunningham, 2006). The example de-
scribed a series of real interactions between the user
and the proposed framework: the user submits queries
to the system, the system responds with personalised
documents, the user selects one document to read and
possibly would issue another query, and so on. We
have also explained how the agent extracted the user’s
knowledge, represented it as beliefs, and finally used
it to “filter” the returned documents. Besides, by in-
terpreting the interaction’s result, we have shown how
the IR agent can acquire numerous beliefs about con-
cepts that the user is aware of, i.e., for a single doc-
ument of 500 words, 70 beliefs could be extracted.
Notice that those concepts are not equally known by
the user; this justifies the allocation of entrenchment
degree to each belief. The use case showed how the
agent’s belief set can “expand” when the user acquires
more knowledge (by reading more documents). Be-
sides, it showed how the degree of knowledge about
a concept/keyword can increase when the user reads
some information that he/she already knows.
Although the developed framework considered
the possibility of representing negated beliefs and re-
vising the belief set accordingly, the actual extraction
of negated knowledge is a challenging task. The prac-
tical research advancement to extract such informa-
tion from non-structured text remains an unresolved
issue in the literature (Blanco and Moldovan, 2011).
Therefore, the notion of belief revision could not be
tested in a real case scenario.
Another challenge was the calculation of the sim-
ilarity between the documents’ keywords and the set
of beliefs. The proposed framework assumes that a
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
474

Figure 4: The list of documents returned for q
2
before and after filtering.
keyword and a belief are “similar” only if they are lit-
erally the same. For example, “multiplayer gaming”
and “multi player gaming” are considered two differ-
ent keywords. We believe that this could be over-
come by applying some normalisation or standardisa-
tion techniques that are publicly available like NLTK
(Bird et al., 2009) and Stanford Core NLP (Manning
et al., 2014). Furthermore, the method used to ex-
tract the keywords does not take into account their se-
mantics, nor does the similarity formula which com-
pares all the keywords. This task might be more chal-
lenging as it requires the integration of some Natural
Language Processing techniques. For future work, we
plan to consider enhancing the developed framework
by extracting normalised keywords with the possibil-
ity of semantically comparing them.
REFERENCES
(2020). Apache lucene. https://lucene.apache.org/.
(2021). Jason agent programming. http://jason.sourceforge.
net/wp/.
Alchourr
´
on, C. E., G
¨
ardenfors, P., and Makinson, D.
(1985). On the logic of theory change: Partial meet
contraction and revision functions. The journal of
symbolic logic, 50(2):510–530.
Alechina, N., Bordini, R. H., H
¨
ubner, J. F., Jago, M., and
Logan, B. (2006). Belief revision for agentspeak
agents. In AAMAS, pages 1288–1290. ACM.
Alechina, N., Jago, M., and Logan, B. (2005). Resource-
bounded belief revision and contraction. In Interna-
tional Workshop on Declarative Agent Languages and
Technologies, pages 141–154. Springer.
Bakos, J. Y. (1997). Reducing buyer search costs: Impli-
cations for electronic marketplaces. Management sci-
ence, 43(12):1676–1692.
Bird, S., Klein, E., and Loper, E. (2009). Natural language
processing with Python: analyzing text with the natu-
ral language toolkit. ” O’Reilly Media, Inc.”.
Blanco, E. and Moldovan, D. (2011). Some issues on de-
tecting negation from text. In Twenty-Fourth Interna-
tional FLAIRS Conference.
Bordini, R. H., H
¨
ubner, J. F., and Wooldridge, M. (2007).
Programming Multi-Agent Systems in AgentSpeak Us-
ing Jason (Wiley Series in Agent Technology). John
Wiley & Sons, Inc., Hoboken, NJ, USA.
Carrillo-Ramos, A., Gensel, J., Villanova-Oliver, M., and
Martin, H. (2005). Pumas: a framework based on
ubiquitous agents for accessing web information sys-
tems through mobile devices. In Proceedings of the
2005 ACM symposium on Applied computing, pages
1003–1008.
Culpepper, J. S., Diaz, F., and Smucker, M. D. (2018). Re-
search frontiers in information retrieval: Report from
the third strategic workshop on information retrieval
in lorne (swirl 2018). In ACM SIGIR Forum, vol-
ume 52, pages 34–90. ACM New York, NY, USA.
da Costa M
´
ora, M., Lopes, J. G. P., Vicari, R. M., and
Coelho, H. (1998). Bdi models and systems: Bridging
the gap. In ATAL, pages 11–27.
El Zein, D. and da Costa Pereira, C. (2020a). A cognitive
agent framework in information retrieval: Using user
beliefs to customize results. In The 23rd International
Conference on Principles and Practice of Multi-Agent
Systems.
El Zein, D. and da Costa Pereira, C. (2020b). Graded be-
lief revision for jason: A rule-based approach. In In-
ternational Joint Conference on Web Intelligence and
Intelligent Agent Technology (WI-IAT’20).
Garcin, F., Zhou, K., Faltings, B., and Schickel, V. (2012).
Personalized news recommendation based on collabo-
rative filtering. In 2012 IEEE/WIC/ACM International
Conferences on Web Intelligence and Intelligent Agent
Technology, volume 1, pages 437–441. IEEE.
G
¨
ardenfors, P. and Makinson, D. (1988). Revisions of
knowledge systems using epistemic entrenchment. In
Proceedings of the 2nd conference on Theoretical as-
pects of reasoning about knowledge, pages 83–95.
Greene, D. and Cunningham, P. (2006). Practical solutions
to the problem of diagonal dominance in kernel docu-
ment clustering. volume 148, pages 377–384.
Guttman, R. H. and Maes, P. (1998). Agent-mediated in-
tegrative negotiation for retail electronic commerce.
In International Workshop on Agent-Mediated Elec-
tronic Trading, pages 70–90. Springer.
Jensen, A. S. and Villadsen, J. (2015). Plan-belief revision
in jason. In ICAART (1), pages 182–189. SciTePress.
Kurumatani, K. (2004). Multi-agent for mass user support.
Lecture Notes in Artificial Intelligence (LNAI), 3012.
Lau, R. Y., Bruza, P. D., and Song, D. (2004). Belief revi-
sion for adaptive information retrieval. In Proceedings
Jason Agents for Knowledge-aware Information Retrieval Filters
475

of the 27th annual international ACM SIGIR confer-
ence on Research and development in information re-
trieval, pages 130–137.
Manning, C. D., Surdeanu, M., Bauer, J., Finkel, J. R.,
Bethard, S., and McClosky, D. (2014). The stanford
corenlp natural language processing toolkit. In Pro-
ceedings of 52nd annual meeting of the association
for computational linguistics: system demonstrations,
pages 55–60.
Rao, A. and Georgeff, M. (2001). Modeling rational agents
within a bdi-architecture.
Ricci, F., Rokach, L., and Shapira, B. (2011). Introduction
to recommender systems handbook. In Recommender
systems handbook, pages 1–35. Springer.
Rose, S., Engel, D., Cramer, N., and Cowley, W. (2010).
Automatic keyword extraction from individual docu-
ments. Text mining: applications and theory, 1:1–20.
Williams, M.-A. (1995). Iterated theory base change: A
computational model. pages 1541–1549.
Yu, R., Tang, R., Rokicki, M., Gadiraju, U., and Dietze, S.
(2021). Topic-independent modeling of user knowl-
edge in informational search sessions. Information
Retrieval Journal, 24(3):240–268.
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
476
