
Towards an Interpretable Spanish Sign Language Recognizer
Itsaso Rodríguez-Moreno
a
, José María Martínez-Otzeta
b
, Izaro Goienetxea
c
and Basilio Sierra
d
Department of Computer Science and Artificial Intelligence, University of the Basque Country (UPV/EHU),
Donostia-San Sebastián, Spain
Keywords:
Gesture Recognition, Spanish Sign Language, Interpretability.
Abstract:
A significant part of the global population lives with hearing impairments, and the number of affected people
is expected to increase in the coming decades. People with hearing problems experience daily difficulties in
their interaction with non-deaf people, due to the lack of a widespread knowledge of sign languages by the
general public. In this paper we present a blueprint for a sign language recognizer that takes advantage of the
internal structure of the signs of the Spanish Sign Language (SSL). While the current dominant approaches
are those based in deep learning and training with lot of recorded examples, we propose a system in which the
signs are decomposed into constituents which are in turn recognized by a classical classifier and then assessed
if their combination is congruent with a regular expression associated with a whole sign. While the deep
learning with many examples approach works for every possible collection of signs, our suggestion is that
we could leverage the known structure of the sign language in order to create simpler and more interpretable
classifiers that could offer a good trade-off between accuracy and interpretability. This characteristic makes
this approach adequate for using the system as part of a tutor or to gain insight into the inner workings of the
recognizer.
1 INTRODUCTION
Sign languages are the main form of communica-
tion for a large proportion of people with hearing
impairments. There is a great diversity of sign lan-
guages, because its evolution shares similar charac-
teristics with spoken languages. While a significant
number of non-deaf people learn non-native spoken
languages out of necessity, or for professional or just
intellectual reasons, deaf people tend to feel isolated
even in its native communities due to the lack of in-
terest of the general public for the sign languages.
Sign languages are quite complex, with rich gram-
matical structures and regional and international di-
versity, which makes the task of translating them into
spoken languages very challenging. The signs are
performed mainly with the hands, but the body posi-
tion and the facial expression are also important. The
hand which performs the more complex movements
and moves the most is the dominant hand in the sign
generation, which usually is also the dominant hand
a
https://orcid.org/0000-0001-8471-9765
b
https://orcid.org/0000-0001-5015-1315
c
https://orcid.org/0000-0002-1959-131X
d
https://orcid.org/0000-0001-8062-9332
in the everyday life of the sign speaker (left for left-
handed, right for right-handed). A sign language rec-
ognizer should take into account hands, body and fa-
cial expression to perform its task correctly.
In order to favor the integration of sign language
speakers, technological solutions have been devised
to bridge the communication gap (Wadhawan and Ku-
mar, 2021; Cheok et al., 2019; Er-Rady et al., 2017;
Ong and Ranganath, 2005). The sign language recog-
nition task can be divided in two main phases; the data
acquisition and the classification. Regarding data ac-
quisition there are two different approaches:
• Non-vision based, which make use of different
sensors to get the information of the sign that is
being performed, such us IMU (Inertial Measure-
ment Unit) or WiFi.
• Vision based, where the acquired data are images
recorded by a camera.
In addition, some of these data acquisition systems
can be intrusive, for example when using data gloves,
body trackers, or even colored gloves to perform hand
segmentation. Depending on the captured data, dif-
ferent preprocessing and feature extraction methods
are used (segmentation, dimensionality reduction,...).
Concerning the classification, Hidden Markov Mod-
622
Rodríguez-Moreno, I., Martínez-Otzeta, J., Goienetxea, I. and Sierra, B.
Towards an Interpretable Spanish Sign Language Recognizer.
DOI: 10.5220/0010870700003122
In Proceedings of the 11th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2022), pages 622-629
ISBN: 978-989-758-549-4; ISSN: 2184-4313
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

els (HMM) and Neural Networks (NN) are widely
used. There is a difference between classifying static
or dynamic signs; if the signs are static, a single frame
has to be classified, while in dynamic signs, temporal
information should also be considered.
The studies published so far have mostly focused
on classifying isolated, static, one-handed signs cap-
tured by a camera and using a NN for classification,
being American Sign Language (ASL) the most stud-
ied language.
In relation to Spanish Sign Language, in (Parcheta
and Martínez-Hinarejos, 2017) the authors use
HMMs to recognize 91 different signs captured by
the Leap Motion sensor. The analyzed signs include
dynamic gestures and sentences. Different HMM
topologies are used, where the number of states is
changed. In (Vazquez-Enriquez et al., 2021) the
authors use two different architectures to perform
isolated sign language recognition: a 3D Convolu-
tional Neural Network (3D CNN) called S3D (Xie
et al., 2018) for RGB data and a skeleton-based ar-
chitecture called MS-G3D (Liu et al., 2020). In ad-
dition to two other datasets, they classify a subset
of the LSE_UVIGO (Docío-Fernández et al., 2020)
SSL dataset. The authors of (Martinez-Martin and
Morillas-Espejo, 2021) created a dataset with the
Spanish alphabet which includes static an motion ges-
tures, 18 letters and 12 letters respectively. The key-
points of the hands and arms extracted with Open-
Pose (Cao et al., 2019) are used to create the images
which are used to perform the classification. They
tried different CNN and Recurrent Neural Network
(RNN) architectures to classify signs, taking into ac-
count the importance of temporal information in signs
which require motion.
While many works have focused on providing
some sort of feedback for spoken language learners
(Pennington and Rogerson-Revell, 2019; Robertson
et al., 2018), very few are dedicated to gestures in
general (Banerjee et al., 2020), an even less to sign
language (Paudyal et al., 2019). The aim of the sys-
tem presented here is two-fold: to provide developers
of machine learning models a visual way of testing
and interpreting the predictions of their models, and
to provide sign test students a visual and textual feed-
back about their performance. As a first step, only
signs for which only a hand is needed are currently
considered. The signs are formalized as sequences of
hand configurations, where the sequence is defined as
a regular expression, and the hand configurations have
been learned from features derived from the spatial lo-
cation of the different parts of the hand. The compari-
son between the intended and the recognized action is
analyzed in two levels: hand configuration and sign.
The system is able to label the detected hand config-
uration and show the rationale of its prediction, and
also the comparison with the intended sign, if they
differ. With respect to the whole sign as a regular ex-
pression, where the underlying alphabet is the set of
hand configurations, an explanation is also provided.
The rest of the paper is organized as follows.
First, in Section 2 some basic concepts of Spanish
Sign Language are explained in order to introduce the
topic. In Section 3 the proposed approach is intro-
duced, explaining the process that has been carried
out. In Section 4 a discussion is presented and finally,
in Section 5 the conclusions extracted from this work
are presented and future work is pointed out.
2 SIGN LANGUAGE STRUCTURE
A sign is a combination of complex articulation po-
sitions and movements performed by a single hand
(one-handed) or both hands (two-handed). In one-
handed signs, the dominant or active hand is used
to perform the sign. However, in two-handed signs,
when the sign is symmetrical both hands act the same
way, but in non-symmetrical signs the dominant hand
moves while the passive hand serves as a base. Usu-
ally, the dominant or active hand is the right hand for
right-handed people and the left hand for left-handed
people.
Signs have four different elements (Blanco, 2009),
which are equivalent to the phonemes of oral lan-
guages, and together they compose the articulation of
the sign:
• Location (+ contact): the specific location where
signs are performed. If a sign is performed in a
corporal location, it can be in contact with that
body part (+ contact) or not.
• Configuration (shape): the shape of the hand
when performing the sign.
• Orientation: the orientation hands adopt when
performing a sign.
• Movement: the movement usually done from the
location when performing a sign.
In brief, to perform a sign, the dominant hand is
placed in a location, it adopts a certain configuration
and orientation in or on it, and usually performs a
movement starting from that location. Nevertheless,
in addition to these elements, there are some non-
manual components which are fundamental to define
a sign: the facial expression (eyebrows, eyes, cheeks,
nose, lips, tongue) and the position of the head, shoul-
ders or body.
Towards an Interpretable Spanish Sign Language Recognizer
623
As mentioned before, the shape of the hand
when performing a sign is defined as a configura-
tion. In SSL, there are three types of configurations:
phonological (queirema), dactylological and numeri-
cal. The phonological configurations obey a phono-
logical system, as the distinctive sounds in oral lan-
guages, and can be classified according to different
characteristics:
• Palm: extended or closed (fist).
• Fingers:
– Extended, flexed or closed.
– Glued or separated.
– Which fingers are involved: index; thumb; in-
dex and thumb; middle; middle and thumb;
index and middle; index, middle and thumb;
pinky; pinky and index; pinky and thumb.
– Thumb opposes the articulation of the others.
The dactylological configurations of SSL repre-
sent the letters of the Spanish alphabet. These are
used mostly when signing proper names. Lastly, the
numerical configurations symbolize the natural num-
bers, both in isolation and incorporated in another
sign.
In (Gutierrez-Sigut et al., 2016) a database of SSL
is presented, where each sign is defined with the ele-
ments mentioned above, including the configurations.
All the configuration and sign definitions in which
this research is based have been obtained from this
source.
3 PROPOSED APPROACH
In this section, the proposed approach and the fol-
lowed pipeline are explained step by step.
Data COLLECTION. Although different ele-
ments as hand configuration, position, orientation or
movement play a key role when recognizing a sign, as
a first approach, we based the sign recognition in the
recognition of different configurations and the move-
ment from one configuration to another.
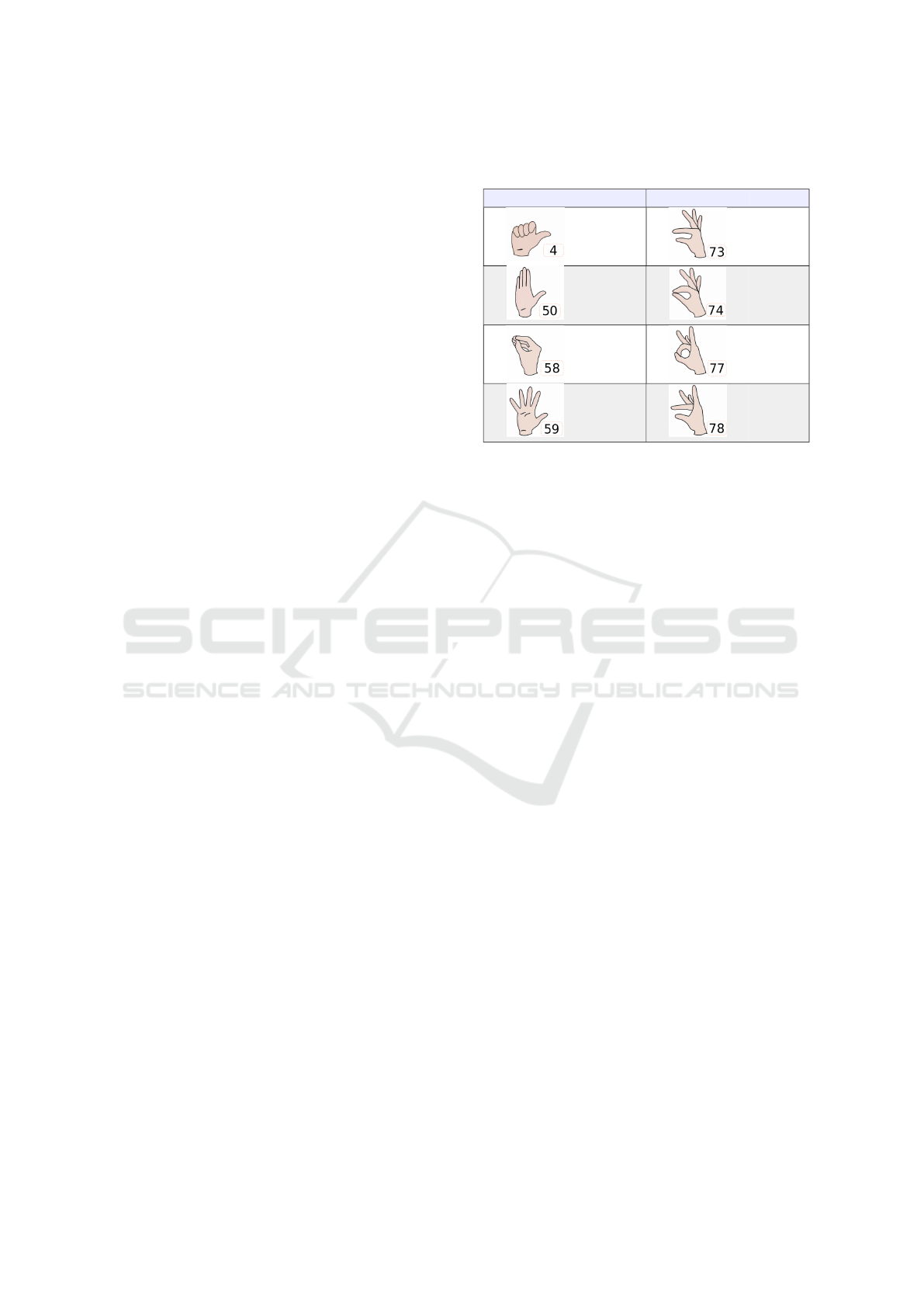
As a first approach, the eight different phonolog-
ical configurations shown in Table 1 have been se-
lected. These configurations are constituents of a
wide variety of Spanish Signs as indicated in Table
1.
In the same vein, five different signs of the SSL
have been chosen among the signs that use the pre-
viously selected configurations: well (bien), happy
(contento), woman (mujer), man (hombre) and lis-
Table 1: Presence of selected configurations as constituents
of SSL one-handed signs.
Configuration #Signs Configuration #Signs
124
19
189 29
55 23
235 24
tener (oyente). The definitions of the mentioned signs
are presented in Table 2.
A data set composed with images of the configura-
tions which form those signs has been created. There
are about 700 images for training each configuration.
These values are shown in Table 3.
Model GENERATION. In Figure 1, the followed
pipeline is shown graphically. Briefly, the method can
be divided into two parts. The former is focused on
the recognition of the configuration in static images,
while the latter predicts the signs performed in a video
using the previously trained configurations model as
basis. In order to facilitate the whole process and
make it easier to understand, a web app has been de-
veloped to both train new models and perform real
time classification.
Since, as a first approach, it has been decided to
use just the information of the hands to recognize the
sign that is being performed, MediaPipe (Lugaresi
et al., 2019) has been used to track the position of
the hand in both images and videos. Specifically,
MediaPipe Hands Tracking (Zhang et al., 2020) has
been used, which offers a real-time hand tracking so-
lution which includes 21 hand landmarks for each
hand. Each hand landmark is composed of three val-
ues (x, y, z), representing the coordinates of the key-
point. In the case of the videos, these 21 landmarks
are extracted for each frame.
After obtaining the landmarks for every image of
the configurations data set, the features that are go-
ing to be used for training the model have to be se-
lected. Apart from the already mentioned 21 hand-
landmarks, there is the option to add the distance be-
tween finger tips or the distance from finger tips to
thumb tip. These features can be selected all together,
ICPRAM 2022 - 11th International Conference on Pattern Recognition Applications and Methods
624

Table 2: Definitions of the selected signs.
SIGN
INITIAL
FACIAL/CORPORAL
LOCATION
FINAL
FACIAL/CORPORAL
LOCATION
INITIAL
HAND
CONFIGURATION
FINAL
HAND
CONFIGURATION
MOVEMENT PATH
Well Chin High neutral space Straight
Happy Under the chin Under the chin
Woman
Right side of the
neck
Under the right ear Straight
Man Close to the forehead Close to the forehead Straight
Listener Chin Chin Circular
Figure 1: Pipeline. Colours in step 3 refer to positions in step 6 (MCP: Metacarpophalangeal joint; PIP: Proximal Interpha-
langeal joint; DIP: Distal Interphalangeal joint; TIP: Fingertip).
Towards an Interpretable Spanish Sign Language Recognizer
625
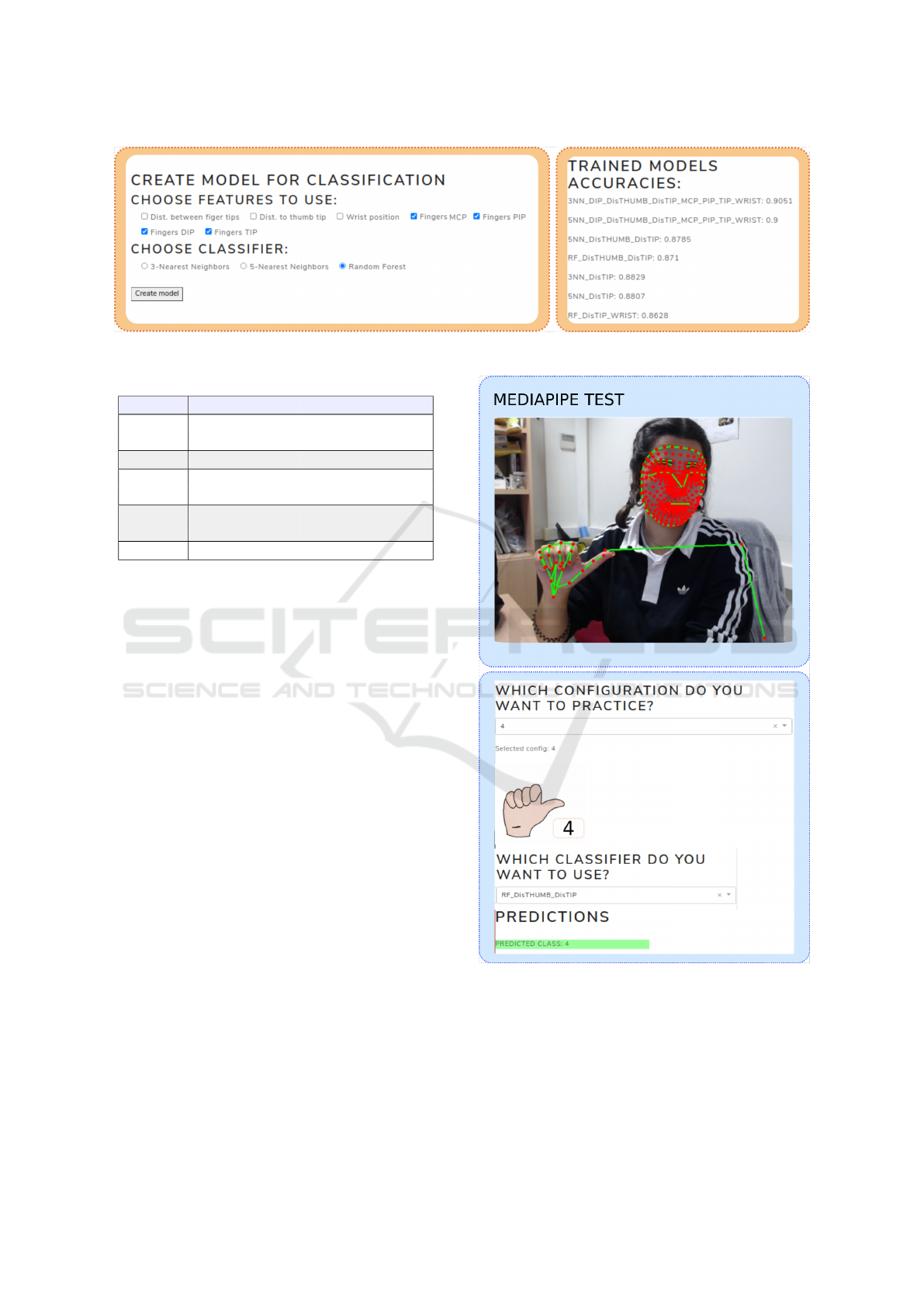
Figure 2: Training configuration model: choose features and classifier.
Table 3: Data-set.
Signs Configurations Number of images
58 747
Well
59 804
Man 4 700
73 732
Woman
74 743
77 668
Happy
78 681
Listener 50 585
one by one or in every possible combination. Apart
from that, Random Forest or K-Nearest Neighbors
(K = 3, 5) classifiers can be trained. In Figure 2 it
can be seen how the training process of the config-
urations model is done through the web app. The
accuracy values obtained for the training models are
displayed aside, which can be helpful when deciding
which model to use for new case predictions.
Prediction AND EXPLANATION. Once a model
is trained, the prediction of a new image of a configu-
ration can be done as it can be seen in Figure 3. As the
goal is to develop a tutor for SSL, there is the option to
choose which configuration do you want to practice.
This way, an image of the configuration is shown in
order to guide the user. Among all the trained models,
one has to be chosen to make the new predictions. So
as to decide which one to select, the accuracy values
shown above give a clue of the performance of each of
the trained models. If the predicted configuration cor-
responds to the one selected to practice, the prediction
text is displayed with green background. However, if
it does not match, a red background is set.
Sometimes, it is quite difficult to understand the
logic behind the predictions made by a model. If an
explanation of the predicted configuration is required
(Explain results button is pressed), the two graphical
items shown in Figure 4 are added, giving an expla-
nation for a frame prediction. On the one hand, a
3D-graph is created which shows the hand landmarks
Figure 3: Real-time configuration prediction.
obtained by MediaPipe. Although the output of Me-
diaPipe is also shown over the image the camera is
recording (see top side of Figure 3), this 3D-graph
mainly helps to verify if the obtained z-coordinates
are correct, because they are estimated by MediaPipe
from a 2D image. On the other hand, an explanation
of the given prediction is obtained by LIME (Ribeiro
ICPRAM 2022 - 11th International Conference on Pattern Recognition Applications and Methods
626
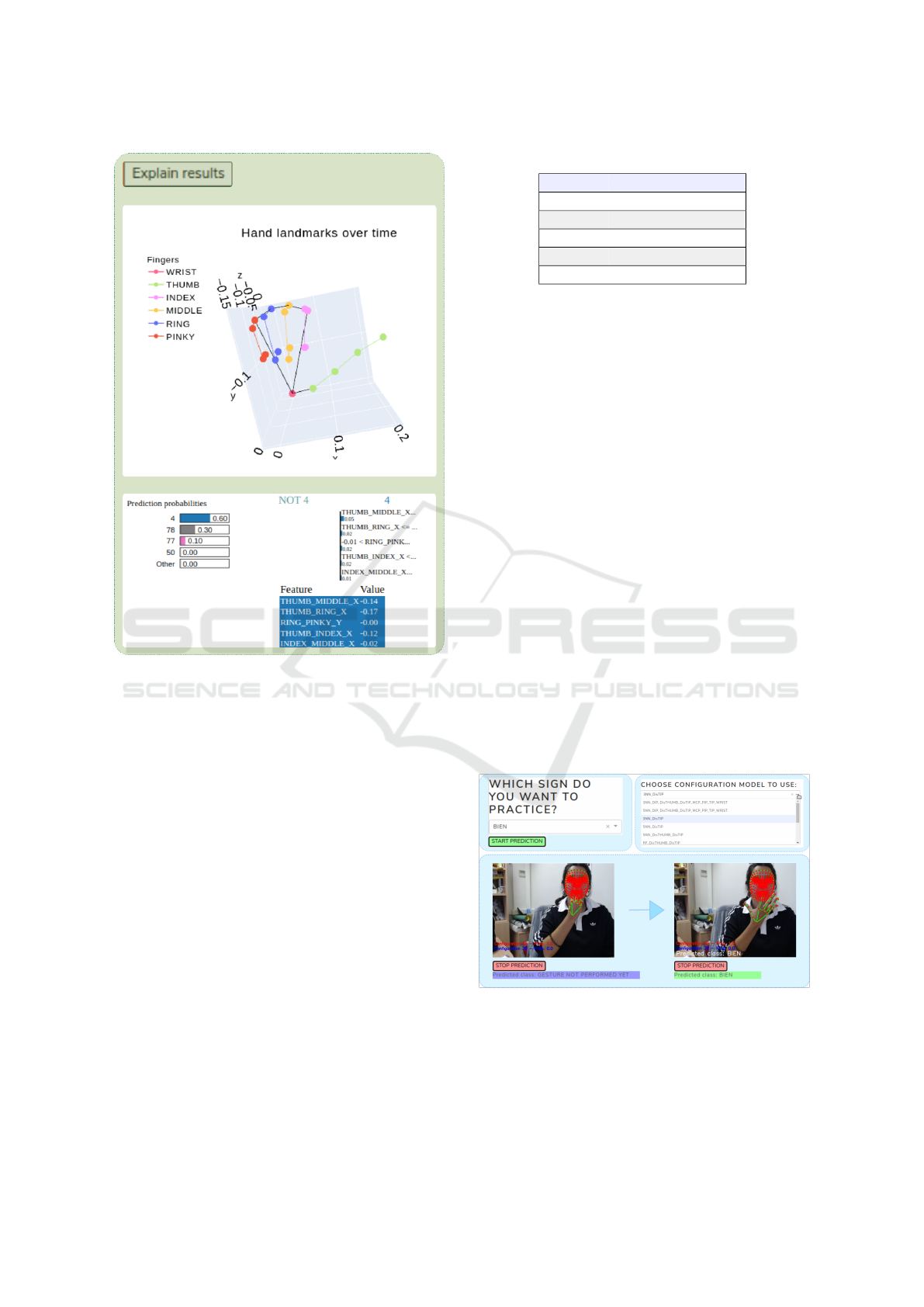
Figure 4: Explanation of the predicted configuration.
et al., 2016), a modular explanation technique which
learns a local interpretable model around the predic-
tion to give an explanation of predictions made with
any classifier. As it can be seen at the bottom of the
Figure 4, LIME offers several information. On the left
side, the probability value of each label is indicated
and, on the right side, the values of the most informa-
tive features are shown. These features might be the
most informative either because they help to confirm
the predicted class or because the values some of the
features take indicate that the class can not be the pre-
dicted one. This way, it can be known which features
have more impact when making a prediction.
Since each frame is labeled with a configuration
by the classifier, a video can be summarized in a series
of consecutive configuration names. Thus, a vector
of configurations is obtained, a value for each frame
of the video, and different regular expressions can be
used to evaluate these vectors and decide which sign
has been performed. The definition of the expressions
can be seen in Table 4, which match with the defini-
tions of the signs.
Using the definitions of the regular expressions,
the prediction of new gestures can be performed in
Table 4: Regular expressions for each sign.
Sign Regular expression
Well ‘(58)+(59)+’
Happy ‘(77)+(78)+’
Man ‘(4)+(4)+’
Woman ‘(73)+(74)+’
Listener ‘(50)+(50)+’
real time. It has been decided to establish a slid-
ing window of length 25 and step 1 to recognize a
tentative sign, being the final prediction the mode of
the last 10 predicted signs. In order to avoid the
noise of incorrectly predicted configurations in be-
tween, it has been decided to establish another slid-
ing window (within the sliding window of 25 frames)
of length 10 and step 1. For each window the mode
of the configurations belonging to that window is
achieved, thus obtaining an array of 16 configurations
(size_gesture − size_window + 1) which will be the
one evaluated with the regular expressions.
In the developed application, as with the config-
urations, it is requested to choose the gesture which
is being performed to be able to indicate whether it
is performed correctly or not. The models have to be
chosen among the trained ones. As it can be seen in
Figure 5, in addition to the predicted sign, the prob-
ability of the two most likely configurations are also
indicated in order to understand the prediction. As
long as a sign has not been performed (as mentioned
before, the gesture length is set to 25) there is no pre-
diction. Once a prediction can be made, a green back-
ground is established if the prediction coincides with
the chosen sign and red if it does not match with the
sign that was intended to reproduce.
Figure 5: Real-time sign recognition.
4 DISCUSSION
The main goal behind the presented approach is to de-
velop a tutor for learning Spanish Sign Language. Al-
Towards an Interpretable Spanish Sign Language Recognizer
627

though only the first steps are introduced, this system
opens the door to many useful applications.
Since the goal is to support people who are learn-
ing sign language, improving the explanation module
is crucial. The function of this module is to help to
understand the results predicted by the classifier, as
knowing what needs to be changed to get the desired
answer can be really helpful. If the prediction is the
one we expect, we can get the reason why the sign has
been well performed. However, if we get an incorrect
prediction, the explanation is used to indicate to the
user what is being wrongly performed and, this way,
the user can correct the aspects that make the sign an
incorrect replica of the real sign.
This application can be approached from two dif-
ferent perspectives, one from the expert’s side and the
other from the user’s side. In Table 5 the differences
between both perspectives are indicated.
Table 5: Differences between the explanation given to an
expert or a user.
Expert
- Knowledge: the learning process of the classifier.
- Explanation: LIME output.
- Action: changes in the definition of the classifier.
User
- Knowledge: the sign.
- Explanation: natural language.
- Action: changes in the performance of the sign.
While the expert has information about the learn-
ing process and the features that have been used to
train the classification model, the user just has the
visual information of the sign that he/she is learn-
ing. Hence, the information given by LIME has to
be translated to natural language for the user to un-
derstand. Once the information is given, the user has
the possibility to perform the sign again following the
indications given by the explanation module. In the
case of the expert, if the explanations received indi-
cate that the performance of the classifier is poor (the
wrong answers are due to a bad configuration of the
model and not due to the performance of the user),
some changes have to be done in the definition of the
classification model.
As in the developed web application the sign or
configuration to perform is indicated, it would be in-
teresting if this explanation module gave information
on both the chosen sign (or configuration) and the pre-
dicted one. Furthermore, although additional infor-
mation apart from the hands is not considered yet, for
information purposes a sentence could be added indi-
cating the part of the body on which the sign should
be performed (e.g. "Perform the sign under the chin").
5 CONCLUSION
In this paper the first steps towards a tutor application
for learning Spanish Sign Language is presented. In
the proposed approach the signs are decomposed in
constituents which are in turn recognized by a classi-
cal classifier and then assessed if their combination is
congruent with a regular expression associated with a
whole sign. This way, unlike other systems based in
deep learning, a simpler and more interpretable sys-
tem is proposed, making it adequate to use for tutor-
ing SSL and to better understand the performance of
the recognizer.
As further work, we plan to extend the range
of signs to recognize. Apart from the hand land-
marks, specific body keypoints and the distance be-
tween them should be added as features too. Specif-
ically in the signs used, presented in Table 2, the rel-
evant locations are the chin, the ear and the forehead.
For instance, adding the distances from the fingertips
to them could be useful to distinguish between dif-
ferent signs. In another vein, the explanations LIME
offers can be treated and displayed more clearly to the
users. Taking as basis the information given for every
feature, it can be translated to some sentences to in-
form the user what he/she should do to improve the
performance of each sign (e.g. "Locate your thumb
higher") as mentioned in Section 4.
ACKNOWLEDGEMENTS
This work has been partially funded by the Basque
Government, Spain, grant number IT900-16, and the
Spanish Ministry of Science (MCIU), the State Re-
search Agency (AEI), the European Regional De-
velopment Fund (FEDER), grant number RTI2018-
093337-B-I00 (MCIU/AEI/FEDER, UE) and the
Spanish Ministry of Science, Innovation and Univer-
sities (FPU18/04737 predoctoral grant). We grate-
fully acknowledge the support of NVIDIA Corpora-
tion with the donation of the Titan Xp GPU used for
this research.
REFERENCES
Banerjee, A., Lamrani, I., Hossain, S., Paudyal, P., and
Gupta, S. K. (2020). AI enabled tutor for accessible
training. In International Conference on Artificial In-
telligence in Education, pages 29–42. Springer.
Blanco, Á. L. H. (2009). Gramática didáctica de la lengua
de signos española (LSE). Sm.
Cao, Z., Hidalgo, G., Simon, T., Wei, S.-E., and Sheikh,
ICPRAM 2022 - 11th International Conference on Pattern Recognition Applications and Methods
628

Y. (2019). OpenPose: realtime multi-person 2D pose
estimation using Part Affinity Fields. IEEE transac-
tions on pattern analysis and machine intelligence,
43(1):172–186.
Cheok, M. J., Omar, Z., and Jaward, M. H. (2019). A re-
view of hand gesture and sign language recognition
techniques. International Journal of Machine Learn-
ing and Cybernetics, 10(1):131–153.
Docío-Fernández, L., Alba-Castro, J. L., Torres-Guijarro,
S., Rodríguez-Banga, E., Rey-Area, M., Pérez-Pérez,
A., Rico-Alonso, S., and Mateo, C. G. (2020).
LSE_UVIGO: A Multi-source Database for Spanish
Sign Language Recognition. In Proceedings of the
LREC2020 9th Workshop on the Representation and
Processing of Sign Languages: Sign Language Re-
sources in the Service of the Language Community,
Technological Challenges and Application Perspec-
tives, pages 45–52.
Er-Rady, A., Faizi, R., Thami, R. O. H., and Housni, H.
(2017). Automatic sign language recognition: A sur-
vey. In 2017 International Conference on Advanced
Technologies for Signal and Image Processing (AT-
SIP), pages 1–7. IEEE.
Gutierrez-Sigut, E., Costello, B., Baus, C., and Carreiras,
M. (2016). LSE-sign: A lexical database for Span-
ish sign language. Behavior Research Methods,
48(1):123–137.
Liu, Z., Zhang, H., Chen, Z., Wang, Z., and Ouyang, W.
(2020). Disentangling and unifying graph convolu-
tions for skeleton-based action recognition. In Pro-
ceedings of the IEEE/CVF conference on computer vi-
sion and pattern recognition, pages 143–152.
Lugaresi, C., Tang, J., Nash, H., McClanahan, C., Uboweja,
E., Hays, M., Zhang, F., Chang, C.-L., Yong, M. G.,
Lee, J., et al. (2019). Mediapipe: A framework
for building perception pipelines. arXiv preprint
arXiv:1906.08172.
Martinez-Martin, E. and Morillas-Espejo, F. (2021). Deep
Learning Techniques for Spanish Sign Language In-
terpretation. Computational Intelligence and Neuro-
science, 2021.
Ong, S. C. and Ranganath, S. (2005). Automatic sign lan-
guage analysis: A survey and the future beyond lexi-
cal meaning. IEEE Transactions on Pattern Analysis
& Machine Intelligence, 27(06):873–891.
Parcheta, Z. and Martínez-Hinarejos, C.-D. (2017). Sign
language gesture recognition using HMM. In Iberian
Conference on Pattern Recognition and Image Analy-
sis, pages 419–426. Springer.
Paudyal, P., Lee, J., Kamzin, A., Soudki, M., Banerjee, A.,
and Gupta, S. K. (2019). Learn2Sign: Explainable AI
for Sign Language Learning. In IUI Workshops.
Pennington, M. C. and Rogerson-Revell, P. (2019). Using
technology for pronunciation teaching, learning, and
assessment. In English pronunciation teaching and
research, pages 235–286. Springer.
Ribeiro, M. T., Singh, S., and Guestrin, C. (2016). "why
should I trust you?": Explaining the predictions of any
classifier. In Proceedings of the 22nd ACM SIGKDD
International Conference on Knowledge Discovery
and Data Mining, San Francisco, CA, USA, August
13-17, 2016, pages 1135–1144.
Robertson, S., Munteanu, C., and Penn, G. (2018). Design-
ing pronunciation learning tools: The case for interac-
tivity against over-engineering. In Proceedings of the
2018 CHI Conference on Human Factors in Comput-
ing Systems, pages 1–13.
Vazquez-Enriquez, M., Alba-Castro, J. L., Docio-
Fernandez, L., and Rodriguez-Banga, E. (2021). Iso-
lated Sign Language Recognition With Multi-Scale
Spatial-Temporal Graph Convolutional Networks. In
Proceedings of the IEEE/CVF Conference on Com-
puter Vision and Pattern Recognition, pages 3462–
3471.
Wadhawan, A. and Kumar, P. (2021). Sign language recog-
nition systems: A decade systematic literature review.
Archives of Computational Methods in Engineering,
28(3):785–813.
Xie, S., Sun, C., Huang, J., Tu, Z., and Murphy, K. (2018).
Rethinking spatiotemporal feature learning: Speed-
accuracy trade-offs in video classification. In Pro-
ceedings of the European conference on computer vi-
sion (ECCV), pages 305–321.
Zhang, F., Bazarevsky, V., Vakunov, A., Tkachenka, A.,
Sung, G., Chang, C.-L., and Grundmann, M. (2020).
Mediapipe hands: On-device real-time hand tracking.
arXiv preprint arXiv:2006.10214.
Towards an Interpretable Spanish Sign Language Recognizer
629
