
Generative Adversarial Examples for Sequential Text Recognition
Models with Artistic Text Style
Yanhong Liu
1
, Fengming Cao
2
and Yuqi Zhang
2
1
Mashang Consumer Finance, China
2
Pingan International Smart City, China
Keywords:
Sequential Text Recognition, Adversarial, Generative Adversarial Networks, Artistic Text Style.
Abstract:
The deep neural networks (DNNs) based sequential text recognition (STR) has made great progress in recent
years. Although highly related to security issues, STR has been paid rare attention on its weakness and
robustness. Most existing studies have generated adversarial examples for DNN models conducting non-
sequential prediction tasks such as classification, segmentation, object detection etc. Recently, research efforts
have shifted beyond the L
p
norm-bounded attack and generated realistic adversarial examples with semantic
meanings. We follow this trend and propose a general framework of generating novel adversarial text images
for STR models, based on the technique of artistic text style transfer. Experimental results show that our
crafted adversarial examples are highly stealthy and the attack success rates for fooling state-of-the-art STR
models can achieve up to 100%. Our framework is flexible to create natural adversarial artistic text images
with controllable stylistic degree to evaluate the robustness of STR models.
1 INTRODUCTION
The success of deep neural networks (DNNs) has
boosted the development of text recognition tasks
such as Optical Character Recognition and scene text
recognition in recent years. These tasks are typi-
cally applied in security-critical applications like hu-
man computer interaction, assistant reading and road
sign recognition etc. To robustly processing text im-
ages with various visual appearance and light condi-
tions, people have solved the text recognition tasks as
a sequence labeling problem, thus we denote such se-
quential recognition of text images by sequential text
recognition (STR).
Despite their wide applications, DNNs have been
shown to be vulnerable to adversarial examples (at-
tacks) with small crafted perturbations on normal im-
ages (Szegedy et al., 2014; Goodfellow et al., 2015;
Papernot et al., 2016). Most existing works generate
adversarial examples by limiting the L
p
norm (Carlini
and Wagner, 2017; Madry et al., 2018) of the pertur-
bations, which are useful for evaluating the weakness
of the learning models. However, L
p
-norm bounded
attacks have limited practical utility since the pertur-
bations in the pixel space cannot handle the underly-
ing real-word properties of image formation that lead
to them, such as translation,rotation and illumination
conditions etc. These perturbed adversarial examples
are often unnatural, not semantically meaningful and
can be easily detected since they are distinctly identi-
fied in the latent space.
Recently, researchers have moved forward to gen-
erate adversarial examples with semantic meanings.
Various techniques have been explored such as spa-
tial transformation (Xiao et al., 2018b), changes in
3D physical properties (Liu et al., 2019) that the im-
ages are rendered from, photo-realistic manipulation
of the color and texture of the images etc. The se-
mantic attributes of images are also manipulated by
perturbing the latent or feature space via the genera-
tive adversarial networks (GANs) (Zhao et al., 2018;
Song et al., 2018; Wang et al., 2020; Qiu et al., 2020).
Very recently, the technique of neural style transfer
is applied to generate realistic adversarial examples
(Duan et al., 2020) for physical-world attacks.
Existing works on adversarial examples mainly
focus on non-sequential vision tasks such as image
classification, object detection, face recognition etc.
People have rarely tried to attack STR models, which
presents a more difficult sequence-labeling problem.
As we know, the only few works for STR (Xu et al.,
2020a; Xu et al., 2020b) are generating adversarial
examples based on traditional L
p
-norm bounded at-
tack.
Liu, Y., Cao, F. and Zhang, Y.
Generative Adversarial Examples for Sequential Text Recognition Models with Artistic Text Style.
DOI: 10.5220/0010866800003122
In Proceedings of the 11th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2022), pages 71-79
ISBN: 978-989-758-549-4; ISSN: 2184-4313
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
71

In this paper, following the up-to-date trend of ad-
versarial attacks, we explore the possibility of gener-
ating adversarial examples for STR models based on
the technique of style transfer. Fortunately, there ex-
ists a line of work which transforms text images with
artistic style transfer (Yang et al., 2019b). By utiliz-
ing these techniques, we propose a general framework
of generating adversarial artistic text images for STR
models. As shown in Figure 1 (c) and (d), we hide
the adversarial perturbations in the style texture on
the target text body and its near neighborhood only,
while L
2
-norm bounded attack generates noise-like
perturbations spread over the image. Furthermore,
our framework allows the parametric control of the
stylistic degree in terms of the text shape deforma-
tion. Extensive experimental results show that our
approach generates highly natural adversarial artistic
text images and can successfully fool the state-of-the-
art STR models at a rate of up to 100%. The pro-
posed mechanism provides a new way of evaluating
the weakness of STR models, which can also be used
to protect the user privacy in STR scenarios from be-
ing recognized by automatic deep learning systems.
2 RELATED WORK
2.1 Adversarial Examples
Research efforts have been paid to generate adver-
sarial examples to fool the DNNs. Classic meth-
ods like Projected Gradient Descent (PGD) (Madry
et al., 2018) and Carlini & Wagner (C&W) (Carlini
and Wagner, 2017) craft the perturbations along the
direction of adversarial gradients, which are bounded
by a small L
p
norm ball k · k
p
≤ ε.
In recent years, there is a movement beyond L
p
norm-bounded attack, to generate perceptually real-
istic adversarial examples. Xiao et al. (Xiao et al.,
2018a) proposed a general framework of adversarial
GANs (AdvGAN) for this purpose. They also in-
troduced the geometric image formation model and
the perturbation of spatial transformation (Xiao et al.,
2018b). Liu et al. (Liu et al., 2019) proposed a
physically-based differentiable render that allows to
propagate pixel gradients to the parametric 3D space
of lighting and geometry. Bhattad et al. (Bhattad
et al., 2020) manipulated the color and texture of the
images to generate photo-realistic adversarial exam-
ples.
Semantically meaningful adversarialexamples are
also synthesized via GANs (Zhao et al., 2018; Song
et al., 2018), by searching over the latent space. The
semantic attributes of images are manipulated by per-
turbing disentangled latent codes (Wang et al., 2020)
or using attribution-based image editing based on
feature-space interpolation (Qiu et al., 2020). Seman-
tic adversarial objects are synthesized (Shetty et al.,
2020) by optimizing both appearance and positions
of the objects for detectors.
Very recently, the technique of neural style trans-
fer was explored for generating natural adversarial ex-
amples (Duan et al., 2020). We follow this line of
utilizing style transfer for generating adversarial ex-
amples. However, Duan et al. (Duan et al., 2020)
applied the traditional neural style transfer technique
and transferred the texture of a style image to a user-
specified region of the target image, where adversarial
perturbations appear on the whole region in the target
image. Instead of a global style transfer, we hide the
adversarial perturbations in style texture which is lim-
ited on the text body and the very near neighborhood
of the text. It is even more challenging for fooling the
sequential recognition task models.
2.2 Sequential Text Recognition
The STR problem has been studied extensively in
the area of scene text recognition. The state-of-the-
art models treat the text recognition task as a se-
quence learning problem, which can be divided into
four stages of consecutive operations (Baek et al.,
2019): transformation (rectifying arbitrary text ge-
ometries), feature extraction (mapping the input im-
age to a representation that focuses on the attributes
relevant for character recognition, while suppressing
irrelevant features such as font, color, size, and back-
ground), sequence modeling (capturing the contex-
tual information within a sequence of characters) and
prediction (estimating the output character sequence
from the identified features of an image). The con-
volution neural network (CNN) and recurrent neural
network (RNN) first encode the input image into a
feature sequence. In the prediction phase, the con-
nectionist temporal classification (CTC) or attention-
mechanism (Attn) is used to predict the linguistic
strings in the image, by constructing the alignment
between the input images and their corresponding la-
bel sequence.
The only few work on generating adversarial ex-
amples for STR models (Song and Shmatikov, 2018;
Xu et al., 2020a; Xu et al., 2020b) successfully at-
tacked the CTC-based and attention-based STR mod-
els, using gradient-based optimization of the L
p
norm
ball of the perturbation. However, in this paper we
explore a totally different attack mechanism, which
aims to obtain natural and semantically meaningful
adversarial examples for STR models.
ICPRAM 2022 - 11th International Conference on Pattern Recognition Applications and Methods
72

(a) normal (b) adversarial (c) our perturbations (d) perturbs. by L
2
attack
Figure 1: Examples of (a) normal and (b) adversarial artistic digit sequence text images at three deformation levels, with
the digits 0 to 9 in all the sequences recognized as 6,5,8,9,2,3,1,4,0,7 respectively, e.g. 146535 → 521393. Perturbations
(amplified by 5x) of (c) ours are compared with (d) those by a L
2
PGD attack.
2.3 Artistic Text Style Transfer
Evolving from the problem of image style transfer, a
series of work (Azadi et al., 2018; Yang et al., 2019a)
has been conducted to transfer the source texture style
to the target text glyph, forming a new text image
with artistic style. Recently, the-state-of-the-art work
(Yang et al., 2019b) along this line can stylize the text
with arbitrary texture effects and control the degree of
the glyph deformations with a parameterized fashion.
3 SCALE-CONTROLLABLE
ARTISTIC TEXT STYLE
TRANSFER
In this paper, we propose a framework for generat-
ing adversarial text images, based on the technique
of artistic text style transfer. We select the state-of-
the-art work by (Yang et al., 2019b), called Shape-
Matching GAN (SMG), since it can stylize the text
with arbitrary textures and enable controllable glyph
deformations, which shows promise for more applica-
tion scenarios. Note that our proposed framework can
also be extended for other artistic text style transfer
techniques based on GANs (Azadi et al., 2018; Yang
et al., 2019a).
In the following we briefly describe the concept of
SMG. The reader can refer to (Yang et al., 2019b) for
the full details. As shown in Figure 2, provided with
the reference style image Y and the set of text images
T, the work designs a stylizing process to render each
image t ∈ T with the texture of Y, where the defor-
mation degree of the text glyphs can be controlled by
a user-specified parameter l ∈ [0,1]. A larger value
of l indicates a greater deformation degree. The ren-
der process is separated into two successive stages:
structure transfer with the model G
S
which generates
text glyphs with controllable deformation degree, and
texture transfer with the model G
T
which renders the
style texture on the text glyphs.
%
*
濇濟濙濨濗濜澔
濁濣濘濩濠濙
濦瀇瀅瀈濶瀇瀈瀅濸
<
濦瀇瀌濿濸澳
濜瀀濴濺濸
瀀濴瀇瀇濼瀁濺
濦濾濸瀇濶濻瀌
濦瀇瀅瀈濶瀇瀈瀅濸
O
;
a
O
濦濾濸瀇濶濻瀌
濦瀇瀅瀈濶瀇瀈瀅濸
O
;
a
6
*
澻濠濭濤濜
濦瀇瀅瀈濶瀇瀈瀅濸
7
*
濈濙濬濨濩濦濙
<
濦瀇瀌濿濸澳濜瀀濴濺濸
7
'
濦瀂瀈瀅濶濸
濧濸瀋瀇
W
6
*
澻濠濭濤濜
;
O
W
濚濿瀌瀃濻
7
*
濈濙濬濨濩濦濙
O
O
VW\OH
/
*$1
/
UHF
/
瀇瀅濴濼瀁
瀇瀅濴濼瀁澳濴瀁濷澳瀇濸瀆瀇
瀇濸瀆瀇
;
;
Figure 2: The process flow of Shape-Matching GAN.
Glyph Network G
S
. To obtain the structure trans-
fer model G
S
, a sketch module G
B
is firstly trained
on the set of source text images T. A text image is
smoothed at various level l by maintaining the con-
tours of the text, after which the smoothed image is
used for training to map it back to the text domain to
learn the glyph characteristics.
The structure map X, which masks the shape of
the style image Y, can be obtained by the existing
image matting algorithms or Photoshop. A sketchy
shape of X at the coarse level l, denoted by
˜
X
l
, is then
obtained with the shape characteristics of the text, by
applying G
B
(previously trained on the source text im-
ages) to X.
The glyph network G
S
is trained to map
˜
X
l
to the
original structure map X, so that it can characterize
the shape features of X at the coarse level l. By ap-
plying G
S
to the source text image t, the shape style of
X is then transferred onto t and the structure transfer
result t
X
l
is obtained, showing text glyphs with defor-
mation degree of l.
Texture Network G
T
. As a generator component of
SMG, the texture transfer network G
T
is trained to
render the texture of style image Y onto the text glyph
image t
X
l
to obtain the artistic text image t
Y
l
, which is
analogical to rendering the style texture of Y onto its
structure map X to get Y.
The images of X and Y are randomly cropped to
obtain adequate training pairs {x,y}. It is separated
into two consecutive steps during each iteration of the
training. Firstly with G
T
fixed, a discriminator D
T
is
Generative Adversarial Examples for Sequential Text Recognition Models with Artistic Text Style
73

trained to maximize the difference between the ren-
dered G
T
(x) and the real image y. Then with D
T
fixed, the generator G
T
is trained to fool the discrim-
inator. The adversarial loss function for the GAN can
be restated with the formulation of Wasserstein GAN
as follows:
L
GAN
= E
x,y
[D
T
(x,y)] − E
x,y
[D
T
(x,G
T
(x))] (1)
A reconstruction loss L
rec
is also used to minimize
the difference between G
T
(x) and y in an L
1
sense:
L
rec
= E
x,y
[kG
T
(x) − yk
1
] (2)
A style loss L
style
proposed in neural style trans-
fer is also considered for the overall rendering perfor-
mance on the source text image t. The final objective
function for training the texture transfer network is
defined as:
L = min
G
T
max
D
T
{
λ
GAN
L
GAN
+ λ
rec
L
rec
+ λ
style
L
style
}
(3)
4 ADVERSARIAL ARTISTIC
TEXT GENERATION
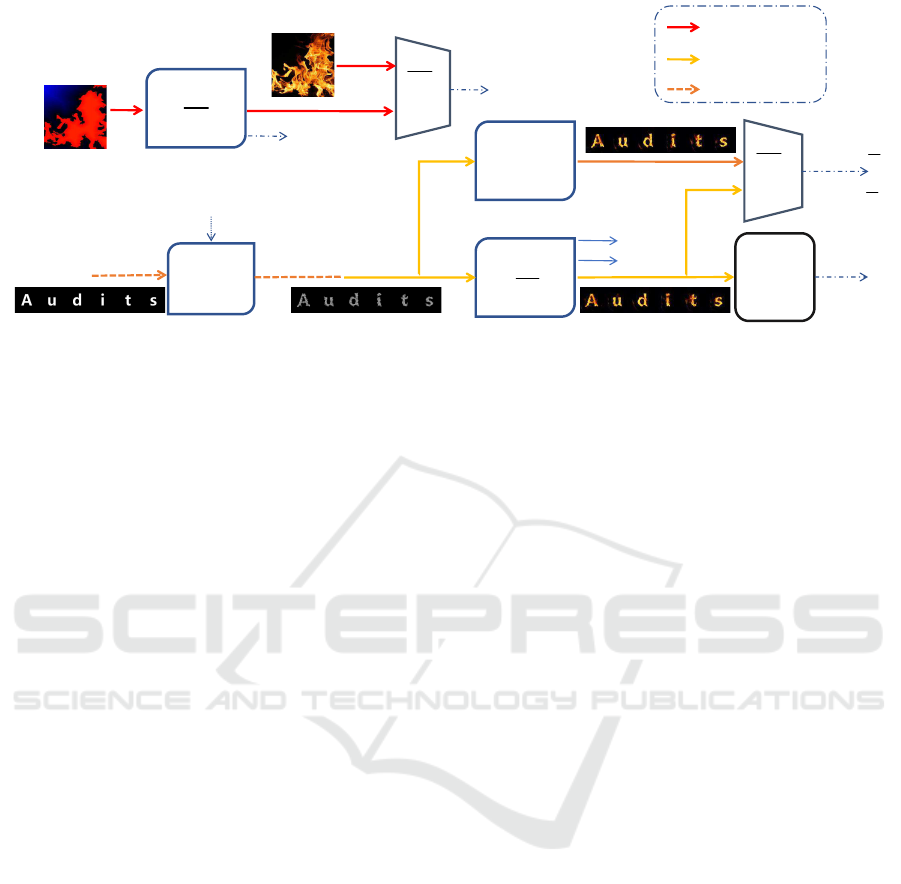
As shown in Figure 3, in this paper we propose
a framework for generating adversarial text images
with artistic texture style which can mislead the STR
models, by adapting the SMG technique presented
in the last section and the adversarial GAN frame-
work proposed in (Xiao et al., 2018a). We assume
that the sketch module G
B
and the glyph network
G
S
are already available, following the SMG process.
We also pre-train a normal texture network G
T
as a
reference model, which renders the texture of style
image Y on the text glyph images in a normal way.
Our framework focuses on generating adversarial ex-
amples from the output of the pretrained glyph net-
work G
S
(i.e. t
X
l
), and hiding the adversarial perturba-
tions in the style texture rendered on/around the text
glyphs. Note that it is not trivial to effectively gener-
ate style-based adversarial text examples without be-
ing perceived. We have to consider careful architec-
ture adaptation and manipulation of loss functions.
We retrain a new adversarial texture transfer net-
work
¯
G
T
, with the output of G
T
as the reference artis-
tic text image. The output of
¯
G
T
is fed into the STR
model f such that f is fooled. The work flow of our
framework is detailed as follows.
4.1 Preprocessing
There could be several potential scenarios to apply
our approach. For example, we may want to attack
a given set of text images that may be stylized. Or
we would just like to produce a graphic verification
code, a poster or advertising board containing titles,
brands, phone/address numbers etc., which we want
to protect from being recognized by automatic deep
learning systems.
Before we train the adversarial texture transfer
network, we need to preprocess the source text im-
ages to obtain the set of text glyph images. First of all,
we prepare the source text images as follows. Given
a set of target text images to be attacked, we may ap-
ply the technique of destylization (Yang et al., 2019a)
to remove the text effects, if any, from the existing
images and acquire the set of source images T with
only content features. Or else, we may just know the
text labels to create adversarial examples for. In this
case we prepare the images of individual characters
(digits) for a word (digit sequence number), and then
concatenate them to obtain the source image t.
Then, given the style image Y and the source text
images T, the process presented in Section 3 are then
followed to train the sketch module G
B
and the glyph
network G
S
. The text glyph image t
X
l
under different
deformation degrees, can be obtained by applying G
S
to the source image t ∈ T, with various pre-specified
values of l.
4.2 Adversarial Texture Style Transfer
Based on the preprocessed text glyph images with de-
formation degree of l, we would retrain a new tex-
ture style transfer network
¯
G
T
for generating adver-
sarial text images with the texture of the style image
Y. To enhance the stealthiness of the adversarial text
images, it is not enough to just distinguish between
the rendered style image
¯
G
T
(x) and its real one y like
that of SMG during the training.
Following the framework as shown in Figure 3,
each text glyph image t
X
l
is input into the normal tex-
ture network G
T
to render it with style texture of Y
without adversarial effects. The output of G
T
, i.e. t
Y
l
,
is used as the reference artistic text image. At the
same time, the adversarial texture transfer network
¯
G
T
renders the input glyph image t
X
l
with adversar-
ial style texture, the output of which is denoted by
¯
t
Y
l
. The new discriminator
¯
D
T
is also trained to dis-
tinguish between
¯
t
Y
l
and the normally rendered t
Y
l
.
The generated adversarial text image
¯
t
Y
l
is used
as the input of the target STR model f for recogni-
tion. We train the adversarial GAN including
¯
G
T
and
¯
D
T
such that the model f mis-recognizes the real text
content in
¯
t
Y
l
. We achieve this goal by manipulating
the loss functions based on the proposed framework.
Firstly, we keep the adversarial loss of the GAN
ICPRAM 2022 - 11th International Conference on Pattern Recognition Applications and Methods
74
濦瀂瀈瀅濶濸澳濧濸瀋瀇
W
6
*
澻濠濭濤濜
O
7
*
濈濙濬濨濩濦濙
VW\OH
/
7
*
濈濙濬濨濩濦濙
7
'
7
'
/
I
濇濈濆澔
濁濣濘濙濠
I
DGY
/
7
*
/
;
濦瀇瀅瀈濶瀇瀈瀅濸
7
*
濈濙濬濨濩濦濙
濦瀇瀌濿濸澳濜瀀濴濺濸
7
'
*$1
/
UHF
/
<
瀇瀅濴濼瀁
瀇瀅濴濼瀁澳濴瀁濷澳瀇濸瀆瀇
瀇濸瀆瀇
;
O
W
濚濿瀌瀃濻
P
/
Figure 3: Overview of our framework for generating adversarial text images with artistic texture style transfer.
(denoted by L
′
S
) and reconstruction loss (denoted by
L
′
rec
) for the style reference images {x, y}, as ex-
pressed in Eqns. (1) and (2), by replacing G
T
and D
T
with
¯
G
T
and
¯
D
T
respectively. Additionally, as we also
apply the discriminator
¯
D
T
on text images, we calcu-
late the adversarial loss of the GAN for the text im-
ages as follows:
L
′
T
= E
t
X
l
[
¯
D
T
(G
T
(t
X
l
))] − λ
¯
G
T
E
t
X
l
[
¯
D
T
(
¯
G
T
(t
X
l
))] (4)
The hyper-parameter λ
¯
G
T
is used to control how the
generated adversarial text image
¯
G
T
(t
X
l
) resembles
the reference one G
T
(t
X
l
).
Another adversarial loss is added to fool the target
STR model f:
L
f
adv
= E
¯
t
Y
l
F (
¯
t
Y
l
,
~
W) (5)
F is the original loss function (CTC loss or cross en-
tropy loss) for the target STR model. L
f
adv
aims to
fool the STR model f to incorrectly recognize the ren-
dered adversarial image
¯
t
Y
l
as the target sequence label
~
W.
Finally, we add a smoothness loss to reduce the
variance between adjacent pixels in the adversarial
text images:
L
m
=
∑
i, j
k
¯
t
Y
l
(i, j) −
¯
t
Y
l
(i+ 1, j) k
2
2
+
∑
i, j
k
¯
t
Y
l
(i, j) −
¯
t
Y
l
(i, j+ 1) k
2
2
(6)
where
¯
t
Y
l
(i, j) is the pixel value at coordinate (i,j) of
image
¯
t
Y
l
. The smoothness loss helps to enhance the
stealthiness and robustness of the adversarial images.
The total objective function for training the adver-
sarial texture style transfer network can then be sum-
marized as:
L
adv
= min
¯
G
T
max
¯
D
T
{
L
′
T
+ λ
f
adv
L
f
adv
+ λ
m
L
m
+
λ
style
L
style
+ λ
S
L
′
S
+ λ
rec
L
′
rec
}
(7)
5 EXPERIMENTAL RESULTS
5.1 Setup
Datasets. During the experimentation, we pre-
pared the datasets of the source text images as
follows. Based on the images of the 10 Arabic
digits, 26 capital and 26 small English letters that
are available at the open source website of SMG (
https://github.com/VITA-Group/ShapeMatchingGAN,
with MIT License), we generated two types of
datasets: one containing digit numbers and the other
containing English words only, which represent the
typical STR scenarios of a board containing ad-
dress/phone numbers and brands/titles respectively.
Note that our framework applies to other text shapes
as well, only if the technique of artistic text style
transfer works for. We may also apply a differentiable
augmentation (Zhao et al., 2020) module after the
texture transfer networks
¯
G
T
and G
T
shown in
Figure 3, to get even more diverse examples for the
STR model f. However, we concentrated on the
style transfer based attack mechanism and put such
augmentation out of the scope of this study.
For the digit dataset, we randomly generated 1000
six-digit numbers. The text image of a number was
obtained by concatenating the corresponding image
of each digit. The results of 1000 digit text images
were then split into 800 and 200 ones respectively for
the training and testing of the adversarial network.
For the word dataset, we sampled around 1800
English words of length 6 from the widely used syn-
thetic dataset MJSynth (Jaderberg et al., 2014) de-
signed for scene text recognition. The text image of
each word was then generated by concatenating the
corresponding image of each character. We split the
dataset into around 1600 and 200 ones respectively
Generative Adversarial Examples for Sequential Text Recognition Models with Artistic Text Style
75

for the training and testing of the adversarial network.
We also used the style images provided from the
website of SMG. All the digit/letter images down-
loaded from its website were resized to 256x256 pix-
els. Hence the created source text images of digit
numbers and English words are of size 1536x256 pix-
els. Note that we used the fixed length of 6 dig-
its/characters just for speeding up the training.
Target STR Models. We experimented with the
five state-of-the-art models as implemented by
(Baek et al., 2019), i.e. three CTC-based mod-
els: CRNN (None-VGG-BiLSTM-CTC), Rosetta
(None-ResNet-None-CTC), STAR-Net (TPS-
ResNet-BiLSTM-CTC) and two attention-based
ones: RARE (TPS-VGG-BiLSTM-Attn), TRBA
(TPS-ResNet-BiLSTM-Attn). These models cover
the different combinations of the four-stage opera-
tions of STR. Different DNN network architectures
of VGG and Resnet are applied for visual feature
extraction. The Bidirectional LSTM (Bi-LSTM)
is used as the (de-)selection in sequence modeling.
CTC and attention schemes are adopted for sequence
prediction. Although these models were originally
proposed for scene text recognition, we believe that
they are also good choices for general STR problems.
We pretrained the five STR models with datasets
of normal artistic text images. Firstly, we gener-
ated 1000/5000 text images for the source digit/word
dataset, following the way as described above for
dataset preparation. Then, following the process as
shown in Figure 2, we created the normal artistic text
datasets with different style images and glyph de-
formation degrees, which contain around 9000 and
45000 samples for the digit and word set respectively.
The STR models were then trained on the digit
and word datasets, so that they can recognize the
normal artistic text images (resized to 384x64 pix-
els). The recognition accuracy of the five STR mod-
els achieved 100% on the digit dataset, and 99.95%
(CRNN), 100.0% (Rosetta), 99.80% (STAR-Net),
99.93% (RARE), 100% (TRBA) respectively on the
word dataset.
Implementation Details. Our generation of the ad-
versarial artistic text examples was mainly based on
the implementations of SMG. Given a specific style
image, we adopted the pretrained glyph transfer net-
work G
S
and texture transfer network G
T
that is used
as the reference model for generating normal artis-
tic text images. We generated adversarial examples
at three coarse levels of l = 0.0, 0.6, 1.0 respectively,
representing the slight, moderate and heavy deforma-
tion degrees in the text glyphs.
For all experiments, we set λ
S
= 1.0, λ
rec
= 100
and λ
style
= 0.01, same as SMG. The number of
epochs for training adversarial models was set to 300.
Threat Model. Our framework allows the gener-
ation of adversarial text images with artistic style.
However, it is based on the training of a GAN struc-
ture and each digit or English character can be learned
to be targeted to a pre-specified one. The untargeted
attack for a text image can be naturally achieved by
just assigning a target sequence label
~
W (as specified
in Eqn. (5)) which is different to the whole or part of
the original digits/letters, so that the STR models in-
correctly predict the text labels of the adversarial im-
age. For the targeted attack case, the STR models are
expected to recognize the labels of an adversarial im-
age as the pre-specified ones. In practical use, we can
apply our framework for attacking a small source text
set where the target label for each digit/letter should
be uniform for all samples. An extended dataset of
moderate size (e.g. around 1000 and 1800 on digit
and word datasets respectively in our case), which
contains those digits/letters to be attacked, can be eas-
ily crafted for training the adversarial texture transfer
network.
During the experiments, we firstly assumed a
white-box scenario, where the network architecture
and weight parameters of the STR models are known.
Then we conducted a cross-model transfer attack,
where the examples generated for a STR model are
used to fool a different one.
5.2 Overall Results
Digit Dataset. During our experiments, we reshuf-
fled the 10 digits randomly and assigned each reshuf-
fled digit as the target label for its original one in
all the digit text images. We then trained the adver-
sarial network
¯
G
T
for each STR model on the digit
dataset as described previously. We set the parame-
ters λ
¯
G
T
= 0.1, λ
f
adv
= 1.0 and λ
m
= 0.001. The at-
tack success rates (ASRs), defined as the ratio of suc-
cessful generation of adversarial examples, achieved
100% for all the five models. Figure 1 compares a
few examples of the normal and adversarial artistic
digit text images from the first row to the bottom, at
the heavy, moderate and slight deformation levels re-
spectively. It also shows that the perturbations gener-
ated by our framework possess the semantic meanings
with style texture, compared to the noise-like pertur-
bations by a L
2
norm based PGD attack.
Word Dataset. We randomly reshuffled 52 English
letters and assigned the small capital version of each
ICPRAM 2022 - 11th International Conference on Pattern Recognition Applications and Methods
76

(a) normal (b) adversarial (c) our perturbations (d) perturbs. by L
2
attack
Figure 4: Examples of (a) normal and (b) adversarial artistic word sequence text images at three deformation degrees (rows
1/4, 2/5, 3/6 for heavy, moderate and slight one respectively), with a → w, e → h, i → f,d → a,t → c etc. Perturbations
(amplified by 5x) of (c) ours are compared with (d) those by a L
2
PGD attack.
reshuffled character as the target label for its origi-
nal one in all the word text images. The adversar-
ial model
¯
G
T
was trained on the word dataset so that
the generated adversarial examples can mislead the
STR models to predict each letter in a word as the
targeted label. It is a rather tough task since each
character in the word was attacked, while in the pre-
vious work for STR attack (Xu et al., 2020a) only
small edit distances were applied. Figure 4 shows
a few adversarial examples on the word dataset for
the five STR models at three deformation degrees. It
can be similarly observed that our generated adver-
sarial examples have better perception, compared to
the L
2
norm based PGD attack with noise-like pertur-
bations. Note that the state-of-the-art L
2
STR attack
by (Xu et al., 2020a) should exhibit similar noise-like
perturbations. Our focus is the naturalness of the ad-
versarial examples, and hence we did not bother with
experiments with the work of (Xu et al., 2020a) since
its source code is unavailable.
There should be a trade-off between the similar-
ity of a generated example with its reference normal
artistic text image, and its adversarial strength. We
conducted extensive experiments on the word dataset
by setting λ
¯
G
T
at various values to control how the ad-
versarial text images are similar to their reference nor-
mal ones, with the adversarial parameters λ
f
adv
and λ
m
fixed to be 10 and 0.001 respectively. Figure 5 shows
how the ASRs vary for the different settings of λ
¯
G
T
at three deformation degrees. It can be observed that
our approach has the potential to successfully attack
the STR models at a rate of up to 100%. The ASRs
generally decease as the similarity with the reference
images increases. The Rosetta model is the most vul-
nerable since it has no sequence modeling stage. The
CRNN model is the most difficult to attack due to the
CTC prediction scheme and the RNN sequence mod-
eling. The CTC prediction scheme shows more ro-
bustness than the Attn scheme, when coupled with the
RNN. It is different from the intuition that our gener-
ated examples show similar adversarial strengths at
different deformation levels. However, it indeed has
some effects on the two models using Attn scheme,
where TRBA is more robust than RARE to the exam-
ples at the moderate deformation degree.
Cross-model Transfer Attack. We also conducted
a cross-model transfer attack where the examples gen-
erated for one STR model is used to fool another
one. We selected three adversarial texture style trans-
fer models
¯
G
T
corresponding to the three deformation
degrees of l = 1.0, 0.6, 0.0 for each of the five STR
models, all of which were trained with the parame-
ter λ
¯
G
T
= 0.5. Table 1 shows the ASRs of the ex-
amples generated from each of the adversarial mod-
els trained for one STR model, while attacking the
other STR models. It can be observed that the CRNN
model obtains the highest average ASR scores, while
Generative Adversarial Examples for Sequential Text Recognition Models with Artistic Text Style
77
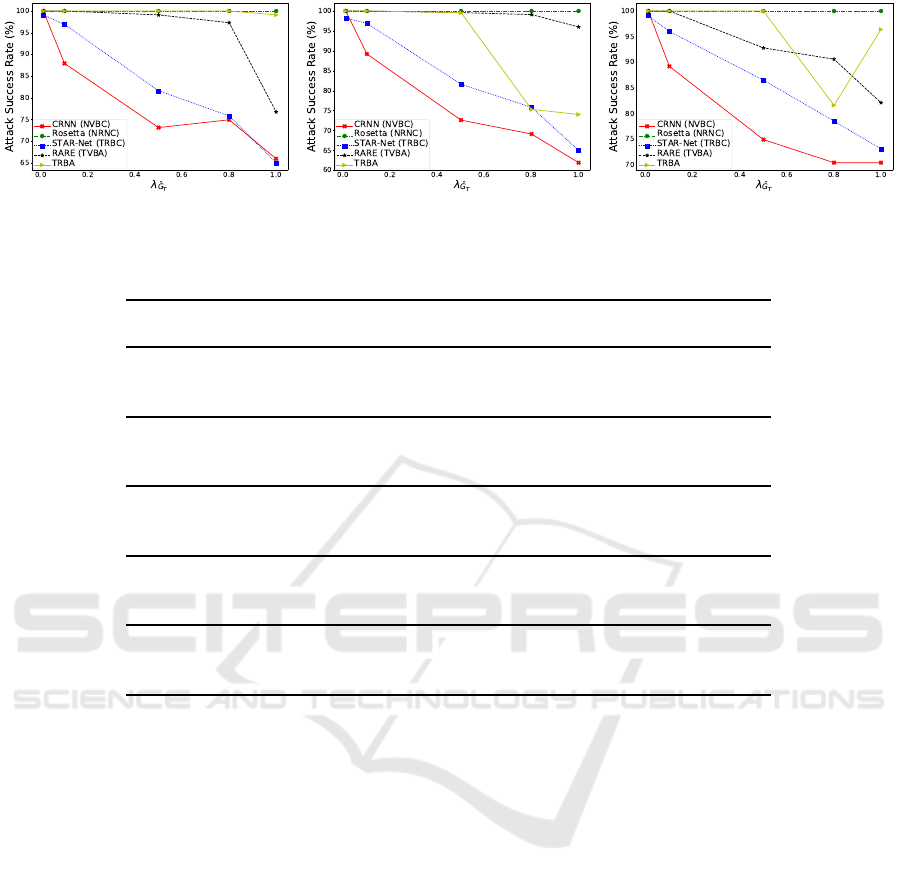
(a) heavy deformation (b) moderate deformation (c) slight deformation
Figure 5: Attack success rates at different settings of λ
¯
G
T
and deformation degrees on the word dataset.
Table 1: Results of cross-model transfer attack on the word dataset.
Models ASRs(%)
l CRNN Rosetta STAR-Net RARE TRBA Avg.
1.0 * 73.5 60.5 73.1 75.8 70.7
CRNN 0.6 * 100 69.1 85.7 98.7 88.4
0.0 * 100 55.2 76.7 76.7 77.2
1.0 7.2 * 27.8 30.0 57.4 30.6
Rosetta 0.6 3.6 * 64.1 38.1 42.2 37.0
0.0 4.9 * 58.3 32.7 44.8 35.2
1.0 1.8 71.7 * 56.5 79.4 52.4
STAR-Net 0.6 3.6 58.7 * 67.3 77.1 51.7
0.0 1.3 62.8 * 40.4 65.0 42.4
1.0 1.8 4.5 6.3 * 21.5 8.5
RARE 0.6 1.8 56.1 23.8 * 49.8 32.9
0.0 2.7 0.9 18.8 * 36.3 14.7
1.0 16.6 7.6 53.4 83.6 * 40.3
TRBA 0.6 10.8 70.4 46.2 55.6 * 45.8
0.0 23.3 73.5 62.3 78.9 * 59.5
the RARE model has the lowest scores. It indicates
the mixed effects of different visual feature extraction
(i.e. VGG and ResNet) and prediction schemes (i.e.
CTC and Attn) on the results of cross-model transfer
attack.
Human Perception Study. To quantify the percep-
tual realism of our generated adversarial artistic text
images, we conducted a user study (Zhao et al., 2018;
Song et al., 2018) to ask human participants to choose
the more visually realistic image from a pair of an ad-
versarial text image and its reference benign one gen-
erated with the normal texture transfer network. We
selected 100 adversarial text images at various coarse
levels from the results generated for the five state-of-
the-art STR models. During each trial, an adversarial
example is shown side-by-side with its reference one
for 2 seconds. The user was then asked to make a
decision.
In total, we collected around 1000 annotations
from 40 users. Our generated adversarial text images
were chosen as the more realistic in 49.60%± 4.26%
of the trials (50% represents that users are unable to
distinguish if an image is adversarial or not). This
indicates that our framework can generate adversar-
ial examples perceptually indistinguishable from their
reference ones. Note that it is especially challenging
to generate adversarial examples with high stealthi-
ness in our setup that the images have clean back-
ground.
6 CONCLUSION AND FUTURE
WORK
In this paper, we proposed a framework of generating
novel adversarial examples for state-of-the-art STR
models, based on the technique of artistic text style
transfer. Our framework is flexible in that it allows
users to control the stylistic degree and can achieve
the trade-off between the stealthiness and adversarial
strength of the examples. Extensive experiments vali-
dated the effectiveness of our approach in fooling the
STR models with visually realistic adversarial artistic
text images.
ICPRAM 2022 - 11th International Conference on Pattern Recognition Applications and Methods
78

Currently, our approach is dependent on the ca-
pability of the technique of artistic text style trans-
fer. In the future, we may incorporate differential
post-processing schemes (Zhan et al., 2019) into our
framework, to generate rich and varied adversarial
examples with real-world scenes. We may also ex-
plore to combine the techniques of manipulating la-
tent codes with style transfer, to further enhance the
generation process and the smoothness of the adver-
sarial style texture.
REFERENCES
Azadi, S., Fisher, M., Kim, V. G., Wang, Z., Shechtman,
E., and Darrell, T. (2018). Multi-content GAN for
few-shot font style transfer. In IEEE Conference on
Computer Vision and Pattern Recognition (CVPR).
Baek, J., Kim, G., Lee, J., Park, S., Han, D., Yun, S.,
Oh, S. J., and Lee, H. (2019). What is wrong with
scene text recognition model comparisons? dataset
and model analysis. In IEEE/CVF International Con-
ference on Computer Vision (ICCV).
Bhattad, A., Chong, M. J., Liang, K., Li, B., and Forsyth,
D. A. (2020). Unrestricted adversarial examples via
semantic manipulation. In International Conference
on Learning Representations (ICLR).
Carlini, N. and Wagner, D. (2017). Towards evaluating the
robustness of neural networks. In IEEE Symposium
on Security and Privacy (SP).
Duan, R., Ma, X., Wang, Y., Bailey, J., Qin, A. K.,
and Yang, Y. (2020). Adversarial camouflage: Hid-
ing physical-world attacks with natural styles. In
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR).
Goodfellow, I. J., Shlens, J., and Szegedy, C. (2015). Ex-
plaining and harnessing adversarial examples. In In-
ternational Conference on Learning Representations.
Jaderberg, M., Simonyan, K., Vedaldi, A., and Zisser-
man, A. (2014). Synthetic data and artificial neural
networks for natural scene text recognition. CoRR,
abs/1406.2227.
Liu, H. D., Tao, M., Li, C., Nowrouzezahrai, D., and Jacob-
son, A. (2019). Beyond pixel norm-balls: Paramet-
ric adversaries using an analytically differentiable ren-
derer. In International Conference on Learning Rep-
resentations (ICLR).
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and
Vladu, A. (2018). Towards deep learning models re-
sistant to adversarial attacks. In International Confer-
ence on Learning Representations.
Papernot, N., Mcdaniel, P., Jha, S., Fredrikson, M., Celik,
Z. B., and Swami, A. (2016). The limitations of deep
learning in adversarial settings. In IEEE Symposium
on Security and Privacy.
Qiu, H., Xiao, C., Yang, L., Yan, X., Lee, H., and Li, B.
(2020). Semanticadv: Generating adversarial exam-
ples via attribute-conditional image editing. In Euro-
pean Conference on Computer Vision (ECCV).
Shetty, R., Fritz, M., and Schiele, B. (2020). Towards au-
tomated testing and robustification by semantic adver-
sarial data generation. In Vedaldi, A., Bischof, H.,
Brox, T., and Frahm, J., editors, European Conference
on Computer Vision (ECCV).
Song, C. and Shmatikov, V. (2018). Fooling OCR systems
with adversarial text images. CoRR, abs/1802.05385.
Song, Y., Shu, R., Kushman, N., and Ermon, S. (2018).
Constructing unrestricted adversarial examples with
generative models. In Annual Conference on Neural
Information Processing Systems 2018 (NeurIPS).
Szegedy, H., Zaremba, W., Sutskever, I., Bruna, J., Erhan,
D., Goodfellow, I., and Fergus, R. (2014). Intriguing
properties of neural networks. In International Con-
ference on Learning Representations.
Wang, S., Chen, S., Chen, T., Nepal, S., Rudolph, C.,
and Grobler, M. (2020). Generating semantic ad-
versarial examples via feature manipulation. ArXiv,
abs/2001.02297.
Xiao, C., Li, B., Zhu, J., He, W., Liu, M., and Song, D.
(2018a). Generating adversarial examples with adver-
sarial networks. In International Joint Conference on
Artificial Intelligence (IJCAI).
Xiao, C., Zhu, J.-Y., Li, B., He, W., Liu, M., and Song, D.
(2018b). Spatially transformed adversarial examples.
In International Conference on Learning Representa-
tions.
Xu, X., Chen, J., Xiao, J., Gao, L., Shen, F., and Shen,
H. T. (2020a). What machines see is not what they
get: Fooling scene text recognition models with ad-
versarial text images. In IEEE/CVF Conference on
Computer Vision and Pattern Recognition (CVPR).
Xu, X., Chen, J., Xiao, J., Wang, Z., Yang, Y., and Shen,
H. T. (2020b). Learning optimization-based adversar-
ial perturbations for attacking sequential recognition
models. In International Conference on Multimedia.
Yang, S., Liu, J., Wang, W., and Guo, Z. (2019a). TET-
GAN: text effects transfer via stylization and destyl-
ization. In AAAI Conference on Artificial Intelligence,
pages 1238–1245.
Yang, S., Wang, Z., Wang, Z., Xu, N., Liu, J., and Guo,
Z. (2019b). Controllable artistic text style transfer
via shape-matching GAN. In IEEE/CVF International
Conference on Computer Vision (ICCV).
Zhan, F., Zhu, H., and Lu, S. (2019). Spatial fusion GAN
for image synthesis. In IEEE Conference on Computer
Vision and Pattern Recognition (CVPR).
Zhao, S., Liu, Z., Lin, J., Zhu, J., and Han, S. (2020). Dif-
ferentiable augmentation for data-efficient GAN train-
ing. In Annual Conference on Neural Information
Processing Systems (NeurIPS).
Zhao, Z., Dua, D., and Singh, S. (2018). Generating natural
adversarial examples. In International Conference on
Learning Representations (ICLR).
Generative Adversarial Examples for Sequential Text Recognition Models with Artistic Text Style
79
