
LiMoSeg: Real-time Bird’s Eye View based LiDAR Motion Segmentation
Sambit Mohapatra
1
, Mona Hodaei
1
, Senthil Yogamani
2
, Stefan Milz
3
, Heinrich Gotzig
1
,
Martin Simon
1,4
, Hazem Rashed
1
and Patrick Maeder
4
1
Valeo, Germany
2
Valeo, Ireland
3
Spleenlab.ai, Germany
4
TU Ilmenau, Germany
stefan.milz@spleenlab.ai, patrick.maeder@tu-ilmenau.de
Keywords:
Automated Driving, Point cloud processing, Motion Segmentation, Bird’s Eye View Algorithms.
Abstract:
Moving object detection and segmentation is an essential task in the Autonomous Driving pipeline. Detecting
and isolating static and moving components of a vehicle’s surroundings are particularly crucial in path planning
and localization tasks. This paper proposes a novel real-time architecture for motion segmentation of Light
Detection and Ranging (LiDAR) data. We use two successive scans of LiDAR data in 2D Bird’s Eye View
(BEV) representation to perform pixel-wise classification as static or moving. Furthermore, we propose a novel
data augmentation technique to reduce the significant class imbalance between static and moving objects. We
achieve this by artificially synthesizing moving objects by cutting and pasting static vehicles. We demonstrate
a low latency of 8 ms on a commonly used automotive embedded platform, namely Nvidia Jetson Xavier.
To the best of our knowledge, this is the first work directly performing motion segmentation in LiDAR BEV
space. We provide quantitative results on the challenging SemanticKITTI dataset, and qualitative results are
provided in https://youtu.be/2aJ-cL8b0LI.
1 INTRODUCTION
Autonomous Driving tasks such as perception which
involves object detection (Rashed et al., 2021), (Da-
hal et al., 2021b), (Hazem et al., 2020), soiling de-
tection (Uricar et al., 2021), (Das et al., 2020), road
edge detection (Dahal et al., 2021a), weather classi-
fication (Dhananjaya et al., 2021), depth prediction
(Varun et al., 2021b), (Ravi Kumar et al., 2018) is
challenging due to the highly dynamic and interac-
tive nature of surrounding objects in the automotive
scenarios (Houben et al., 2021). Identification of the
environmental objects as moving and static is cru-
cial to achieving safe motion planning and naviga-
tion. An autonomous vehicles’ route has to consider
future coordinates and velocities of surrounding mov-
ing objects. In addition, this information is a criti-
cal source for simultaneous localization and mapping
(SLAM) (Gallagher et al., 2021) and pose estima-
tion (Kumar et al., 2020). As the vehicle is in mo-
tion, it is difficult to distinguish between background
and other moving objects. Thus, motion segmenta-
tion requires estimation of the vehicle’s ego-motion
and compensation to extract other moving objects in
the scene. Motion cues can also be used to detect
generic moving objects like animals which are diffi-
cult to train based on appearance due to their rare ap-
pearance in driving scenes and due to their diversity.
Relative to appearance-based object detection and se-
mantic segmentation, CNN-based motion segmenta-
tion approaches are relatively less mature (Ravi Ku-
mar et al., 2021b), (Yahiaoui et al., 2019).
Autonomous vehicles are equipped with a variety
of sensors to generate an understanding of environ-
ments. The most common ones are cameras and Li-
DAR. Although cameras provide rich color informa-
tion, they face a lack of depth information and rely on
illumination, making them vulnerable to poor illumi-
nation conditions such as nights or rainy days and are
also prone to adversarial attacks (Sobh et al., 2021).
However, providing accurate 3D depth (Varun et al.,
2021a), (Varun et al., 2020) and geometric informa-
tion (Ravi Kumar et al., 2021a) of the environment
without dependency on weather and illumination is
possible with LiDAR (Kumar et al., 2018). Consid-
ering the benefits of LiDAR data, we focus our ef-
828
Mohapatra, S., Hodaei, M., Yogamani, S., Milz, S., Gotzig, H., Simon, M., Rashed, H. and Maeder, P.
LiMoSeg: Real-time Bird’s Eye View based LiDAR Motion Segmentation.
DOI: 10.5220/0010866000003124
In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2022) - Volume 5: VISAPP, pages
828-835
ISBN: 978-989-758-555-5; ISSN: 2184-4321
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

forts towards motion segmentation in LiDAR point
clouds, building upon the blocks presented in (Mo-
hapatra et al., 2021). A summary of the contributions
of this work are listed below:
• We propose a novel method to implement real-
time motion segmentation on LiDAR point
clouds. First, we convert LiDAR 3D point clouds
to 2D Bird’s Eye View (BEV), then we classify
each pixel of the BEV as static or motion. We
demonstrate real-time inference on an embedded
GPU platform.
• We introduce a novel residual computation layer
that directly leverages the motion across frames
to increase the disparity between pixel values for
static and moving parts of the BEV frames.
• We introduce a data augmentation technique to
simulate motion by selectively translating static
objects across successive frames. The technique
addresses the problem of significant class imbal-
ance present in the dataset.
2 RELATED WORK
A variety of approaches have been proposed for
moving semantic segmentation using vision (Barnes
et al., 2018) (Patil et al., 2020) (McManus et al.,
2013). Apart from vision-based methods, other ap-
proaches rely on the fusion of vision and LiDAR
sensors (Rashed et al., 2019) (El Madawi et al.,
2019) (Yan et al., 2014) (Postica et al., 2016). Us-
ing LiDAR sensors individually in order to perform
semantic segmentation tasks has been taken into con-
sideration recently (Cortinhal et al., 2020) (Li et al.,
2020) (Milioto et al., 2019).
Motion segmentation can be performed by
LiDAR-based methods based on clustering ap-
proaches such as (Dewan et al., 2016a) including
point motion prediction by RANSAC and clustering
objects. Vaquero et al. (Vaquero et al., 2017) per-
formed motion segmentation after clustering vehicles
points and matching objects in consecutive frames.
Steinhauser et al. (Steinhauser et al., 2008) have de-
vised another method to classify moving and non-
moving objects using RANSAC and extract features
from two sequential frames, although in some scenar-
ios like when a vehicle is surrounded by many moving
objects or dense trees, the RANSAC algorithm and
feature extraction have failed.
In other studies, Wang et al. (Wang et al., 2012)
have segmented objects that are able to move into dif-
ferent categories such as cars, bicycles, and pedestri-
ans in laser scans of urban senses. Consistent tem-
poral information of consecutive LiDAR scans has
been utilized with semantic classification and seman-
tic segmentation approaches (Dewan and Burgard,
2020) (Dewan et al., 2017) which are developed based
on motion vectors of rigid bodies that have been esti-
mated by a flow approach on LiDAR scans (Dewan
et al., 2016b). However, distinguishing scene flow
from noise in the case of slowly moving objects can
be a difficult task to perform. In urban scenarios, most
semantic segmentation methods are able to recog-
nize objects typically being in the pedestrians, bicy-
clists, and cars classes in point clouds (Alonso et al.,
2020) (Milioto et al., 2019) (Wu et al., 2019) (Wu
et al., 2018) (Biasutti et al., 2019) (Cortinhal et al.,
2020). However, none of them distinguish between
static and moving objects. There are some studies in
order to distinguish moving objects. Yoon et al. (Yoon
et al., 2019) propose a ray-tracing method including
a clustering step to detect moving objects in LiDAR
scans, which can, however, occasionally result in in-
complete detection of objects or detection of static ar-
eas. Shi et al. (Shi et al., 2020) introduce a method
based on utilizing sequential point clouds to achieve
the prediction of moving objects. However, most
of the used architectures were primarily developed
for semantic segmentation and have a relatively large
number of parameters.
3 PROPOSED METHOD
3.1 Input Data Prepration
Since a set of sequential point clouds is needed for
motion segmentation, we group each frame in the Se-
manticKITTI (Behley et al., 2019) dataset with its
past two frames (we use 2 past frames) in the se-
quence. The past frames are then motion compen-
sated using the pose matrices provided in the dataset
as described by the Eq. 1. The motivation behind us-
ing 2 past frames is to strike a balance between the
accuracy of predictions and network size and latency.
The number of encoders is directly proportional to the
number of input frames.
F
N
N−1
= P
−1
N
· (P
N−1
· F
N−1
) (1)
where
F
N
: f rame N
F
N−1
: f rame N − 1
P
N
: Pose matrix o f f rame N
P
N−1
: Pose matrix o f f rame N − 1
The set of motion-compensated frames are then
converted to 2D BEV using the same process as de-
LiMoSeg: Real-time Bird’s Eye View based LiDAR Motion Segmentation
829

Figure 1: Input 3 frames superimposed - red pixels are present frame (Left), Ground truth motion mask (Middle), Predicted
motion mask (Right).
scribed in (Mohapatra et al., 2021), and (Barrera et al.,
2020). We limit the x and y ranges to (0, 48) and (-16,
16) meters, respectively, for BEV creation. Using a
cell resolution (in BEV space) of 0.1 meters, we gen-
erate (480x320) sized BEV images for each LiDAR
frame.
Unlike (Chen et al., 2021), we do not use the range
image representation. Our reason is that range im-
ages are only better at short range due to their skewed
aspect ratio. Neighboring pixels in range representa-
tions disregard the metric distance from the underly-
ing points compared to BEV. Objects far away from
the car are barely visible in a range image. Further-
more, range images are affected by even partial oc-
clusion. BEV representation overcomes these prob-
lems to some extent (particularly for semi-occluded
objects) while presenting the benefits of 2D represen-
tation. Another key advantage of BEV representation
is that reconstruction of 3D points is a simple matter
of looking up the row and column indices of the pixels
and multiplying by the cell resolution. Furthermore,
most downstream applications such as motion plan-
ning are made on a grid-based BEV space, and hence
predictions available directly in BEV space reduce the
number of interconversions.
3.2 Data Augmentation
Due to the rather difficult and expensive process of
collecting and annotating LiDAR data, data augmen-
tation has been a key technique used to increase the
training set size and also allow better generalization
of the network to different scenarios. One of the most
commonly used techniques is sampling-based aug-
mentation or ground truth augmentation as described
in Second algorithm (Yan et al., 2018). The idea is to
copy objects from some frames and paste them into
others, increasing the number and type of objects. We
use this idea but modify it to fit our case of generating
artificially moving objects in frames.
For each frame (3D LiDAR) with no moving ob-
jects (no points marked as moving), we collect all the
points belonging to class cars. A uniform random
value then translates these points along x and y axes
for N successive frames, and the translations increase
along the x-axis in each frame to produce a notion of
motion. Experimentally, we found N=4 to perform
best. The transformed points are then concatenated
to the rest of the points, and their labels are marked
as moving cars. We do not apply this technique to
frames with motion objects to avoid clutter due to
overlap between the synthetic objects and the actual
objects in the frame. Though simple, this method en-
ables us to make better use of a sizeable portion of
the dataset that has no or very few numbers of LiDAR
points marked as moving objects.
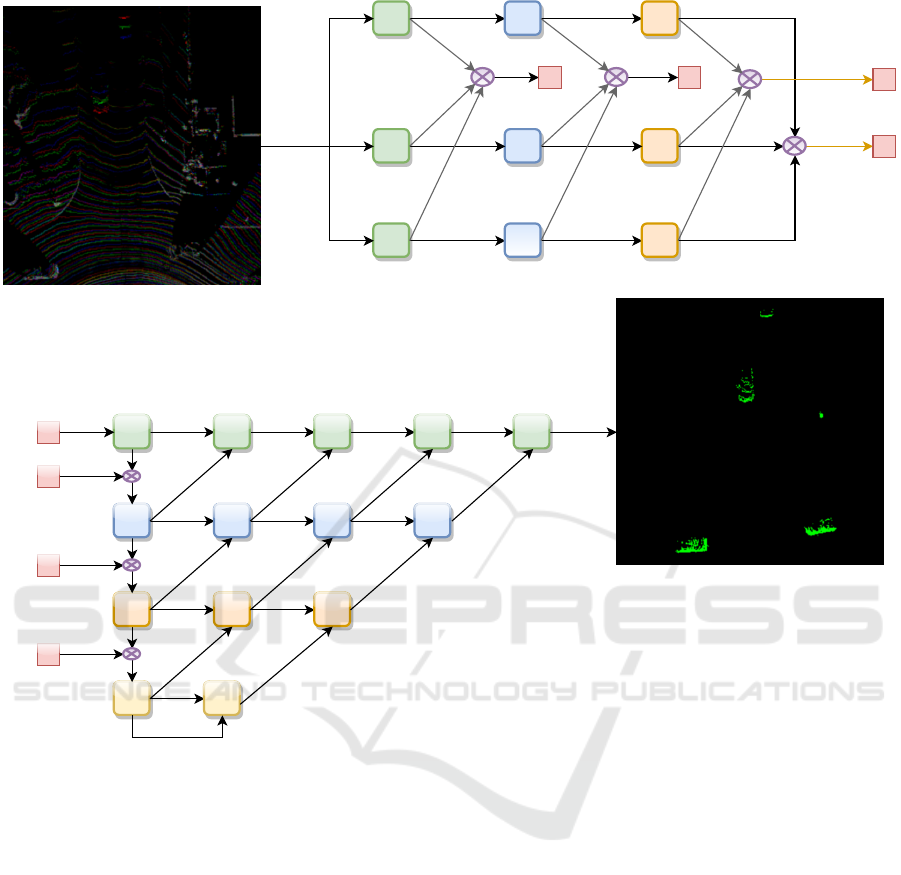
3.3 Network Architecture
Our goal is design a a pixel-wise prediction model
which operates in BEV space and it is also efficient
with very low latency. BEVDetNet (Mohapatra et al.,
2021) is a recent efficient model which operates on
BEV space. It produces outputs in the same spatial
resolution as input and has a head that does binary
keypoint classification. However, for predicting rela-
tive motion between frames and classifying each pixel
as moving or static, we adapt this architecture. We
inherit the building blocks from BEVDetNet (Moha-
patra et al., 2021) and build a multi-encoder joint-
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
830
DB1
32
DB2
64
DB3
128
DB1
32
DB2
64
DB3
128
DB2
64
DB1
32
DB3
128
A
B
CD
H/2xW/2 H/4xW/4 H/8xW/8
HxW H/2xW/2 H/4xW/4
H/8xW/8
H/4xW/4
H/2xW/2HxW
DB1
32
DB2
64
DB3
128
DB4
256
D
C
B
A
UB
UB UB
UB UB UB
UB UB UB UB
HxW
H/2xW/2
H/4xW/4
H/8xW/8
H/16xW/16
H/8xW/8
H/8xW/8H/8xW/8
H/4xW/4 H/4xW/4
H/4xW/4
H/2xW/2
H/4xW/4 H/4xW/4
H/2xW/2
H/2xW/2H/2xW/2
HxW HxW HxW HxW
Figure 2: Overall architecture of LiMoSeg with individual encoders (top) and joint encoder and decoder parts (bottom). The
three input BEV frames are superimposed as red-greed-blue channels. The red channel is the present frame and the green and
blue channels are past two frames in sequence.
decoder architecture as shown in Figure 2.
The feature extraction blocks are called Down-
sampling Blocks (DB), as seen in Figure 3. They
use 5 × 5 and 3 × 3 convolutions to capture features
at different scales and also successively reduce the
spatial resolution of input using a max-pooling op-
eration at the end. The Upsampling Blocks (UB), as
seen in Figure 3 are used to increase the spatial res-
olution of inputs and serve to produce final output at
the same spatial dimension as the input. It consists
of a transposed convolution followed by a single con-
volutional block. We use the ReLU activation func-
tion throughout the network. Since we have 3 input
BEV images (present frame and past 2 frames), we
have 3 individual encoders consisting of 3 DB blocks.
The individual encoders compute per-input features.
Features from multiple stages of the network are then
collected for all three encoders and then fused using
a concatenation and multiplication-based fusion ap-
proach. A joint feature computation chain consisting
of 4 DB blocks then computes joint features upon the
pre-computed individual features from each encoder.
The idea is, individual encoders compute features for
objects while the joint encoder computes features that
capture the interaction between objects from all three
streams. These are essentially the features that cap-
ture the relative displacement between objects due to
motion. While concatenation is used as a most com-
mon feature fusion approach, we augment it by ex-
plicitly multiplying features channel-wise from cor-
responding stages to compute a set of features that
forms a loose correlation between similar features
across the three channels. We then concatenate these
features to the rest of the concatenated features. We
LiMoSeg: Real-time Bird’s Eye View based LiDAR Motion Segmentation
831
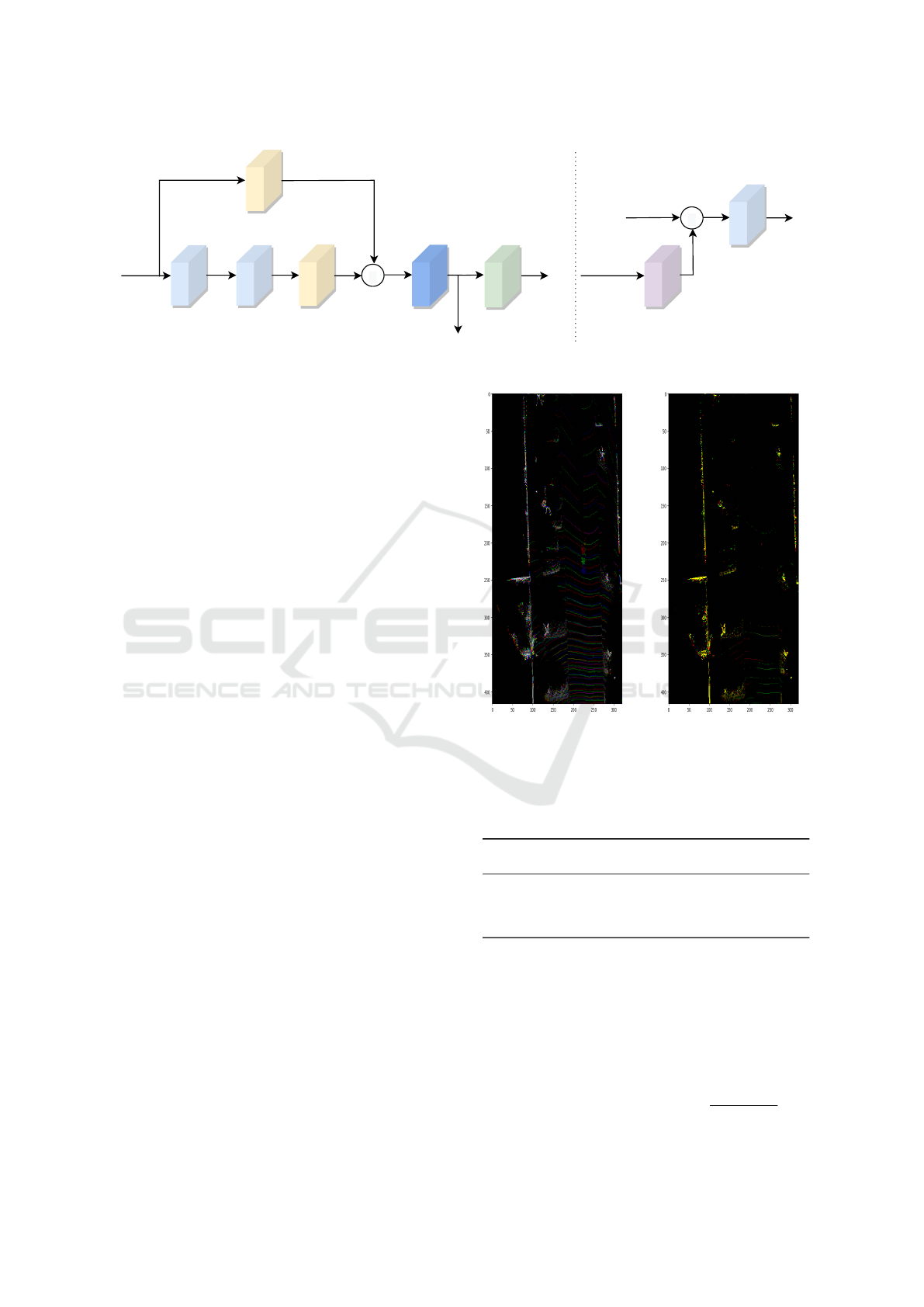
Conv 5×5
|ReLU|
BN
|ReLU|
BN
Max Pooling Layer
H, W, Cx
H, W, Cy
Conv 3×3
|ReLU|
BN
Conv 3×3
H/2, W/2, Cy
Conv 1×1
Transposed Convolutional
×
H, W, Cx
Conv 3×3
|ReLU|
BN
H, W, Cx
H/2, W/2, Cy
×
Figure 3: Downsampling Block (DB) (Left) and Upsampling Block (UB) (Right).
use only 3 DB blocks in the individual encoders since
their primary job is to compute the low-level features
that characterize objects. The joint encoder has 4 DB
blocks to allow computation of sufficiently complex
features to capture motion. Our motivation was to
limit the number of parameters as much as possible.
3.3.1 Residual Computation Layer
Residual layers have proven to improve motion seg-
mentation significantly as demonstrated by (Chen
et al., 2021). They compute the difference between
successive motion-compensated frames and then nor-
malize it. This produces a disparity map between the
moving and static parts of the two frames. However,
we multiply motion-compensated successive frames
to generate residuals. Since static objects will have
overlaps (some of the parts at least) across succes-
sive frames, the residual gets large values in such
parts. Moving objects occupy different spatial loca-
tions across successive frames (with some overlap de-
pending on the amount of motion). Therefore, such
locations become 0 due to the multiplication as seen
in Figure 4. This creates a much more significant dis-
parity in static and moving parts of the frame and pro-
vides a weak attention mechanism to the network. We
normalize again after residual computation.
4 RESULTS
We follow the standard training and validation split
for the semantic KITTI dataset and keep sequence 8
for validation. All other sequences between [00-10]
are converted into BEV, and the motion annotations
are also converted into BEV. It was experimentally
found that due to the significant class imbalance be-
tween frames with motion points and frames without
motion points, using all the frames affects the net-
work’s performance negatively by acting as a bias to-
wards classifying points as static more often. There-
Figure 4: Three successive frames show a moving object
at the center in red-green-blue (Left), Computed residuals
with static parts in bright, and mobile objects region in dark
at the center (Right).
Table 1: Comparison of accuracy and inference latency per
frame in BEV for motion segmentation.
Method
Inference
Latency (ms)
IoU
(moving class)
RangeNet++ (Chen et al., 2021) 45 39.5
MINet (Chen et al., 2021) 24 36.9
SalsaNext (Chen et al., 2021) 41 53.4
LiMoSeg (Ours) 8 52.6
fore, we only convert those frames to BEV, which
have at least 20 motion points in them. We train with
a batch size of 12 for only 30 epochs. Since this is
a segmentation task, we use weighted cross-entropy
loss as our loss function as described by equation 2,
where y
c
is the ground truth class and ˆy
c
is the pre-
dicted class for each pixel in the BEV.
L
motion
= −
C
∑
c=1
w
c
y
c
log ˆy
c
, w
c
=
1
log( f
c
+ ε)
(2)
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
832

Table 2: Ablation study of different architectural and resid-
ual computation settings.
Architecture
ch. wise
mul
ch. wise
sub
IoU
Single encoder
3 7 43.20
Single encoder
7 3 38.36
Single encoder
with semantics
3 7 39.23
Multiple encoders
3 7 43.45
Multiple encoders
with joint features
3 7 52.60
Table 3: Ablation study of inference models illustrating the
precision, accuracy and size.
Precision IoU Latency (ms) Size (MB)
FP32 52.60 8 35.0
FP16 51.40 3 15.3
INT8 48.07 2 8.0
For evaluating the performance, we use the
intersection-over-union (Everingham et al., 2010)
metric as is commonly used by similar methods such
as (Chen et al., 2021). The evaluation code is taken
directly from SemanticKITTI. We evaluate our model
in the BEV space since most of the algorithms down-
stream from the perception task, such as path plan-
ning, are carried out in the BEV space. We report
Intersection over Union (IoU) for moving class.
To prove the real-time capabilities of our proposed
architecture, we run the inference on an Nvidia Jetson
Xavier AGX development kit, a commonly used auto-
motive embedded systems platform for deep learning
applications. As is shown in Table 1, we achieve an
impressive inference latency of 8ms (inference speed
of 125 Frames Per Second (FPS)). In terms of ac-
curacy, we are slightly behind SalsaNext (Cortinhal
et al., 2020). We haven’t performed extensive hyper-
parameter tuning or data augmentation.
4.1 Ablation Study
We perform extensive ablation studies using different
modifications to our architecture and input data rep-
resentation. As can be seen in Table 2, we evaluate
using both a single encoder-decoder network as well
as with multiple encoders and joint decoder architec-
ture, which is more common in optical flow-based
approaches such as (Ilg et al., 2017). However, sur-
prisingly enough, the single encoder-decoder archi-
tecture achieves better accuracy than a multi-encoder
approach where joint features were not computed.
We explain that each encoder during training learns
features local to its input BEV frame for the multi-
encoder approach. However, due to the absence of
any DB blocks for joint feature learning, sufficient
joint features are not learned, which leads to a lower
representation of motion in feature space.
We also experiment with adding full semantic seg-
mentation masks to individual input BEVs. This,
however, does not seem to offer any benefits. The
network seems to be biased towards classifying all in-
stances of objects as positive for motion in this case.
This could be directly attributed to the full semantic
masks that do not differentiate between mobile and
static objects. Furthermore, we evaluate another com-
monly used residual computation approach like sub-
traction and find that the proposed approach to multi-
ply performs best.
We experiment with reduced precision inference
as shown in Table 3 at 16-bit floating point (FP16)
and 8-bit integer (INT8) and demonstrate that perfor-
mance is not degraded by a large amount even at re-
duced precision. This is directly relevant for real-time
embedded system based deployment.
5 CONCLUSION
In this paper, we demonstrated an algorithm that in-
crementally builds upon an existing network for ob-
ject detection to do motion segmentation so that it can
be added as an additional task in a multi-task learn-
ing framework. We proposed a residual computation
layer that exploits the disparity between the static and
mobile parts of two successive motion-compensated
frames. We also proposed a data augmentation tech-
nique that greatly improves the class imbalance be-
tween static and mobile points present in the Se-
manticKITTI dataset. We observed that motion seg-
mentation in BEV space is not a straightforward task
due to sparsity of the 3D points and a relatively small
cross-section of several traffic elements like pedestri-
ans and bicyclists.
ACKNOWLEDGEMENT
We are funded by the Electronic Components
and Systems for European Leadership Joint
Undertaking grant No 826655 receiving sup-
port from the European Union’s Horizon 2020
research and innovation programme. Further partial
funding is provided by the German Federal Ministry
of Education and Research.
LiMoSeg: Real-time Bird’s Eye View based LiDAR Motion Segmentation
833

REFERENCES
Alonso, I., Riazuelo, L., Montesano, L., and Murillo, A. C.
(2020). 3D-MiniNet: Learning a 2D Representation
from Point Clouds for Fast and Efficient 3D LIDAR
Semantic Segmentation. IEEE Robotics and Automa-
tion Letters, 5(4):5432–5439.
Barnes, D., Maddern, W., Pascoe, G., and Posner, I.
(2018). Driven to Distraction: Self-Supervised Dis-
tractor Learning for Robust Monocular Visual Odom-
etry in Urban Environments. In 2018 IEEE In-
ternational Conference on Robotics and Automation
(ICRA), pages 1894–1900. IEEE.
Barrera, A., Guindel, C., Beltr
´
an, J., and Garc
´
ıa, F. (2020).
BirdNet+: End-to-End 3D Object Detection in Li-
DAR Bird’s Eye View. In 2020 IEEE 23rd Interna-
tional Conference on Intelligent Transportation Sys-
tems (ITSC), pages 1–6. IEEE.
Behley, J., Garbade, M., Milioto, A., Quenzel, J., Behnke,
S., Stachniss, C., and Gall, J. (2019). SemanticKITTI:
A Dataset for Semantic Scene Understanding of Li-
DAR Sequences. In Proc. of the IEEE/CVF Interna-
tional Conf. on Computer Vision (ICCV).
Biasutti, P., Lepetit, V., Aujol, J.-F., Br
´
edif, M., and Bugeau,
A. (2019). LU-Net: An Efficient Network for 3D Li-
DAR Point Cloud Semantic Segmentation Based on
End-to-End-Learned 3D Features and U-Net. In Pro-
ceedings of the IEEE/CVF International Conference
on Computer Vision Workshops, pages 0–0.
Chen, X., Li, S., Mersch, B., Wiesmann, L., Gall, J., Behley,
J., and Stachniss, C. (2021). Moving Object Seg-
mentation in 3D LiDAR Data: A Learning-Based Ap-
proach Exploiting Sequential Data. arXiv preprint
arXiv:2105.08971.
Cortinhal, T., Tzelepis, G., and Aksoy, E. E. (2020). Sal-
saNext: Fast, Uncertainty-aware Semantic Segmenta-
tion of LiDAR Point Clouds for Autonomous Driving.
arXiv preprint arXiv:2003.03653.
Dahal, A., Golab, E., Garlapati, R., Ravi Kumar, V., and
Yogamani, S. (2021a). RoadEdgeNet: Road Edge De-
tection System Using Surround View Camera Images.
In Electronic Imaging.
Dahal, A., Kumar, V. R., Yogamani, S., and Eising, C.
(2021b). An online learning system for wireless
charging alignment using surround-view fisheye cam-
eras. arXiv preprint arXiv:2105.12763.
Das, A., K
ˇ
r
´
ı
ˇ
zek, P., Sistu, G., B
¨
urger, F., Madasamy,
S., U
ˇ
ri
ˇ
c
´
a
ˇ
r, M., Ravi Kumar, V., and Yogamani, S.
(2020). TiledSoilingNet: Tile-level Soiling Detection
on Automotive Surround-view Cameras Using Cover-
age Metric. In 2020 IEEE 23rd International Con-
ference on Intelligent Transportation Systems (ITSC),
pages 1–6. IEEE.
Dewan, A. and Burgard, W. (2020). DeepTemporalSeg:
Temporally Consistent Semantic Segmentation of 3D
LiDAR Scans. In 2020 IEEE International Con-
ference on Robotics and Automation (ICRA), pages
2624–2630. IEEE.
Dewan, A., Caselitz, T., Tipaldi, G. D., and Burgard, W.
(2016a). Motion-based detection and tracking in 3D
LiDAR scans. In 2016 IEEE international confer-
ence on robotics and automation (ICRA), pages 4508–
4513. IEEE.
Dewan, A., Caselitz, T., Tipaldi, G. D., and Burgard, W.
(2016b). Rigid scene flow for 3D LiDAR scans. In
2016 IEEE/RSJ International Conference on Intelli-
gent Robots and Systems (IROS), pages 1765–1770.
IEEE.
Dewan, A., Oliveira, G. L., and Burgard, W. (2017). Deep
Semantic Classification for 3D LiDAR Data. In
2017 IEEE/RSJ International Conference on Intelli-
gent Robots and Systems (IROS), pages 3544–3549.
IEEE.
Dhananjaya, M. M., Ravi Kumar, V., and Yogamani, S.
(2021). Weather and light level classification for au-
tonomous driving: Dataset, baseline and active learn-
ing. arXiv preprint arXiv:2104.14042.
El Madawi, K., Rashed, H., El Sallab, A., Nasr, O., Kamel,
H., and Yogamani, S. (2019). Rgb and lidar fusion
based 3d semantic segmentation for autonomous driv-
ing. In 2019 IEEE Intelligent Transportation Systems
Conference (ITSC), pages 7–12. IEEE.
Everingham, M., Van Gool, L., Williams, C. K., Winn, J.,
and Zisserman, A. (2010). The PASCAL Visual Ob-
ject Classes (VOC) Challenge. International journal
of computer vision, 88(2):303–338.
Gallagher, L., Kumar, V. R., Yogamani, S., and McDonald,
J. B. (2021). A hybrid sparse-dense monocular slam
system for autonomous driving. In Proc. of ECMR,
pages 1–8. IEEE.
Hazem, R., Mohamed, E., Sistu, Ganesh and, V. R. K.,
Eising, C., El-Sallab, A., and Yogamani, S. (2020).
FisheyeYOLO: Object Detection on Fisheye Cameras
for Autonomous Driving. Machine Learning for Au-
tonomous Driving NeurIPS 2020 Virtual Workshop.
Houben, S., Abrecht, S., Akila, M., B
¨
ar, A., et al. (2021).
Inspect, Understand, Overcome: A Survey of Practi-
cal Methods for AI Safety. CoRR, abs/2104.14235.
Ilg, E., Mayer, N., Saikia, T., Keuper, M., Dosovitskiy, A.,
and Brox, T. (2017). FlowNet 2.0: Evolution of Op-
tical Flow Estimation with Deep Networks. In Pro-
ceedings of the IEEE conference on computer vision
and pattern recognition, pages 2462–2470.
Kumar, V. R., Hiremath, S. A., Bach, M., Milz, S., Witt,
C., Pinard, C., Yogamani, S., and M
¨
ader, P. (2020).
Fisheyedistancenet: Self-supervised scale-aware dis-
tance estimation using monocular fisheye camera for
autonomous driving. In 2020 IEEE International Con-
ference on Robotics and Automation (ICRA), pages
574–581.
Kumar, V. R., Milz, S., Witt, C., Simon, M., Amende,
K., Petzold, J., Yogamani, S., and Pech, T. (2018).
Monocular fisheye camera depth estimation using
sparse lidar supervision. In 2018 21st Interna-
tional Conference on Intelligent Transportation Sys-
tems (ITSC), pages 2853–2858.
Li, S., Chen, X., Liu, Y., Dai, D., Stachniss, C., and Gall, J.
(2020). Multi-scale Interaction for Real-time LiDAR
Data Segmentation on an Embedded Platform. arXiv
preprint arXiv:2008.09162.
McManus, C., Churchill, W., Napier, A., Davis, B., and
Newman, P. (2013). Distraction suppression for
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
834

vision-based pose estimation at city scales. In 2013
IEEE international conference on robotics and au-
tomation, pages 3762–3769. IEEE.
Milioto, A., Vizzo, I., Behley, J., and Stachniss, C. (2019).
RangeNet ++: Fast and Accurate LiDAR Semantic
Segmentation. In 2019 IEEE/RSJ International Con-
ference on Intelligent Robots and Systems (IROS) ,
pages 4213–4220. IEEE.
Mohapatra, S., Yogamani, S., Gotzig, H., Milz, S., and
Mader, P. (2021). BEVDetNet: Bird’s Eye View Li-
DAR Point Cloud based Real-time 3D Object De-
tection for Autonomous Driving. arXiv preprint
arXiv:2104.10780.
Patil, P. W., Biradar, K. M., Dudhane, A., and Murala,
S. (2020). An End-to-End Edge Aggregation Net-
work for Moving Object Segmentation. In proceed-
ings of the IEEE/CVF conference on computer vision
and pattern recognition, pages 8149–8158.
Postica, G., Romanoni, A., and Matteucci, M. (2016). Ro-
bust Moving Objects Detection in Lidar Data Exploit-
ing Visual Cues. In 2016 IEEE/RSJ International
Conference on Intelligent Robots and Systems (IROS),
pages 1093–1098. IEEE.
Rashed, H., Mohamed, E., Sistu, G., Ravi Kumar, V., Eis-
ing, C., El-Sallab, A., and Yogamani, S. (2021). Gen-
eralized Object Detection on Fisheye Cameras for
Autonomous Driving: Dataset, Representations and
Baseline. In Proceedings of the Winter Conference on
Applications of Computer Vision, pages 2272–2280.
Rashed, H., Ramzy, M., Vaquero, V., El Sallab, A., Sistu,
G., and Yogamani, S. (2019). FuseMODNet: Real-
Time Camera and LiDAR based Moving Object De-
tection for robust low-light Autonomous Driving. In
Proceedings of the IEEE/CVF International Confer-
ence on Computer Vision Workshops, pages 0–0.
Ravi Kumar, V., Klingner, M., Yogamani, S., Milz, S., Fin-
gscheidt, T., and Mader, P. (2021a). Syndistnet: Self-
supervised monocular fisheye camera distance estima-
tion synergized with semantic segmentation for au-
tonomous driving. In Proceedings of the IEEE/CVF
Winter Conference on Applications of Computer Vi-
sion, pages 61–71.
Ravi Kumar, V., Milz, S., Witt, C., and Yogamani, S.
(2018). Near-field depth estimation using monocu-
lar fisheye camera: A semi-supervised learning ap-
proach using sparse LiDAR data. In Proceedings of
the IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR) Workshop, volume 7.
Ravi Kumar, V., Yogamani, S., Rashed, H., Sitsu, G., Witt,
C., Leang, I., Milz, S., and M
¨
ader, P. (2021b). Om-
nidet: Surround view cameras based multi-task visual
perception network for autonomous driving. IEEE
Robotics and Automation Letters, 6(2):2830–2837.
Shi, H., Lin, G., Wang, H., Hung, T.-Y., and Wang, Z.
(2020). SpSequenceNet: Semantic Segmentation Net-
work on 4D Point Clouds. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition, pages 4574–4583.
Sobh, I., Hamed, A., Kumar, V. R., and Yogamani, S.
(2021). Adversarial attacks on multi-task visual
perception for autonomous driving. arXiv preprint
arXiv:2107.07449.
Steinhauser, D., Ruepp, O., and Burschka, D. (2008). Mo-
tion segmentation and scene classification from 3D
LIDAR data. In 2008 IEEE intelligent vehicles sym-
posium, pages 398–403. IEEE.
Uricar, M., Sistu, G., Rashed, H., Vobecky, A., Ravi Kumar,
V., Krizek, P., Burger, F., and Yogamani, S. (2021).
Let’s get dirty: Gan based data augmentation for cam-
era lens soiling detection in autonomous driving. In
Proceedings of the IEEE/CVF Winter Conference on
Applications of Computer Vision, pages 766–775.
Vaquero, V., Del Pino, I., Moreno-Noguer, F., Sola, J., San-
feliu, A., and Andrade-Cetto, J. (2017). Deconvolu-
tional networks for point-cloud vehicle detection and
tracking in driving scenarios. In 2017 European Con-
ference on Mobile Robots (ECMR), pages 1–7. IEEE.
Varun, R. K., Klingner, M., Yogamani, S., Bach, M., Milz,
S., Fingscheidt, T., and M
¨
ader, P. (2021a). SVDist-
Net: Self-supervised near-field distance estimation on
surround view fisheye cameras. IEEE Transactions on
Intelligent Transportation Systems.
Varun, R. K., Yogamani, S., Bach, M., Witt, C., Milz,
S., and M
¨
ader, P. (2020). UnRectDepthNet: Self-
Supervised Monocular Depth Estimation using a
Generic Framework for Handling Common Camera
Distortion Models. In IEEE/RSJ International Con-
ference on Intelligent Robots and Systems, IROS.
Varun, R. K., Yogamani, S., Milz, S., and M
¨
ader, P. (2021b).
FisheyeDistanceNet++: Self-Supervised Fisheye Dis-
tance Estimation with Self-Attention, Robust Loss
Function and Camera View Generalization. In Elec-
tronic Imaging.
Wang, D. Z., Posner, I., and Newman, P. (2012). What could
move? Finding cars, pedestrians and bicyclists in 3D
laser data. In 2012 IEEE International Conference on
Robotics and Automation, pages 4038–4044. IEEE.
Wu, B., Wan, A., Yue, X., and Keutzer, K. (2018). Squeeze-
Seg: Convolutional Neural Nets with Recurrent CRF
for Real-Time Road-Object Segmentation from 3D
LiDAR Point Cloud. In 2018 IEEE International Con-
ference on Robotics and Automation (ICRA). IEEE.
Wu, B., Zhou, X., Zhao, S., Yue, X., and Keutzer, K. (2019).
SqueezeSegV2: Improved Model Structure and Un-
supervised Domain Adaptation for Road-Object Seg-
mentation from a LiDAR Point Cloud. In 2019 In-
ternational Conference on Robotics and Automation
(ICRA), pages 4376–4382. IEEE.
Yahiaoui, M., Rashed, H., Mariotti, L., Sistu, G., Clancy,
I., Yahiaoui, L., Ravi Kumar, V., and Yogamani, S.
(2019). FisheyeModNet: Moving object detection
on Surround-View Cameras for Autonomous Driving.
arXiv preprint arXiv:1908.11789.
Yan, J., Chen, D., Myeong, H., Shiratori, T., and Ma, Y.
(2014). Automatic Extraction of Moving Objects from
Image and LIDAR Sequences. In 2014 2nd Interna-
tional Conference on 3D Vision, volume 1. IEEE.
Yan, Y., Mao, Y., and Li, B. (2018). Second:
Sparsely embedded convolutional detection. Sensors,
18(10):3337.
Yoon, D., Tang, T., and Barfoot, T. (2019). Mapless On-
line Detection of Dynamic Objects in 3D Lidar. In
2019 16th Conference on Computer and Robot Vision
(CRV), pages 113–120. IEEE.
LiMoSeg: Real-time Bird’s Eye View based LiDAR Motion Segmentation
835
