
A Lexicon-based Collaborative Filtering Approach for Recommendation
Systems
Mara Deac-Petrus¸el
Faculty of Mathematics and Computer Science, Babes¸-Bolyai University, Cluj-Napoca, Romania
Keywords:
Recommendation Systems, Collaborative Filtering, K Nearest Neighbours, Vader Lexicon, Text-based
Reviews, Sentiment Score.
Abstract:
Users purchasing items from e-commerce websites are expressing their satisfaction and sentiment about their
acquisition using text-based reviews and numerical ratings. Traditional collaborative filtering techniques are
entirely dependent on the users’ scalar ratings, which are lacking any semantic explanation of the users’
preferences. This approach was designed to explore the text-based item evaluation using a Sentiment Anal-
ysis Lexicon. The proposed lexicon-based k nearest neighbors collaborative filtering technique replaces the
numerical rating with a computed sentiment rating in the neighborhood determination step. The conducted
experiments reveal that the resulting text-based recommendation system produces reliable values in terms of
mean absolute error and root mean square error and accurate recommendations for users.
1 INTRODUCTION
E-commerce websites are important sources of data
generation. People are buying items based on the
reviews of other peers. Users evaluate the pur-
chased items, expressing their satisfaction and opin-
ions through numerical ratings and text-based re-
views. Classic recommendation systems produce sug-
gestions for users using the given numerical ratings
for items. Scalar ratings are not able to offer a seman-
tic explanation about the users’ preferences. There-
fore, recommendation systems are facing the chal-
lenge of efficiently analyzing information in textual
form.
The proposed approach was designed to capture
the users’ interests from the text-based items’ reviews
to produce good rating predictions for items and ac-
curate generated recommendations for users. The
items’ descriptions are passed to a Sentiment Anal-
ysis Lexicon, which outputs a sentiment score indi-
cating the polarity of the text (positive, negative, or
neutral). Based on the sentiment score, a k-nearest
neighbor (kNN) user-based collaborative filtering al-
gorithm was applied. The recommendation system
uses solely the sentiment scores (called sentiment rat-
ings), instead of the numerical ratings. Results have
proven a positive impact of the text-based approach
on the performance of the recommendation system.
The original contributions of the papers are:
• Analysing the textual information of an item and
applying the Vader Sentiment Analysis Lexicon
(Hutto and Gilbert, 2014) to obtain the sentiment
rating;
• Integrate the lexicon-based data into the k nearest
neighbors user-based collaborative filtering algo-
rithm;
The rest of this paper is organized as follows. Chap-
ter two surveys the state-of-art approaches that in-
tegrate the rich information contained in text-based
items’ descriptions in the recommendation process.
The third chapter describes a detailed methodology
used to design this approach. The fourth chapter
presents the experimental setups conducted and gives
an overview of the selected data sets in terms of
their features and volume. Also, the evaluation met-
rics used in the textual recommendation system are
briefed and comparisons to other approaches are dis-
cussed. In the last chapter, the overall summary of
this work is presented, highlighting the main findings,
results, and future work plans.
2 RELATED WORK
This section offers an overview of several state-of-
the-art approaches where text-based reviews are ex-
plored and integrated into the collaborative filtering
Deac-Petru¸sel, M.
A Lexicon-based Collaborative Filtering Approach for Recommendation Systems.
DOI: 10.5220/0010801200003116
In Proceedings of the 14th International Conference on Agents and Artificial Intelligence (ICAART 2022) - Volume 3, pages 203-210
ISBN: 978-989-758-547-0; ISSN: 2184-433X
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
203

recommendation process to improve rating predic-
tion.
(Terzi et al., 2014) proposes a text-based user-
kNN algorithm that uses text-based reviews instead
of numerical ratings to compute the users’ similar-
ity. The idea is to determine the similarity between
two users by computing the similarity between re-
views’ words for every item reviewed by both users.
The text-based user-kNN is compared with several
approaches using numerical ratings in the rating pre-
diction step. For the numerical experiments, two data
sets are used: RottenTomatoes and an AudioCD from
AmazonProductReviews. Slightly better results are
obtained for root mean square error (RMSE) between
the actual and the predicted ratings in the text-based
user-kNN approach over the ratings-based ones.
(Poirier et al., 2010) determines sentiment scores
from text-based reviews using a Na
¨
ıve Bayes model.
As a first step, the text-based reviews are analyzed
and text mining techniques are applied in order to
build the user-item-rating matrix. Reviews are clas-
sified into two sentiment classes: positive and neg-
ative using the KHIOPS tool (Boull
´
e, 2007). Then,
the item-based collaborating filtering algorithm is ap-
plied to generate the recommendations. Experiments
are conducted using Flixter, Netflix, and IMDB data
sets. RMSE is used as an evaluation measure.
(Ma et al., 2017) designed an original user-
preference-based collaborative filtering (UPCF) ap-
proach to exploit free-text online reviews to retrieve
users’ preferences. Firstly, aspect-level opinions min-
ing techniques were applied to transform the free-text
reviews into structured aspect opinions. Next, the user
preferences were determined on one hand from the
aspect importance and, on the other hand, from the
aspect need. The aspect importance means that opin-
ions on important aspects are more influential to the
overall ratings than other aspects, and uses the sim-
ilarity between the opinions on one aspect and the
overall ratings. The aspect need is calculated as the
difference between the opinions of a user on an as-
pect and those of other users, which indicates the dif-
ferentiated needing level on this aspect with respect
to the user. Based on this, a user-based collaborative
filtering approach is designed so that the users’ aspect
preferences are integrated to calculate the similarities
between users.
(Musto et al., 2017) implemented a user and item-
based collaborative filtering approach that includes
aspect opinion data. For both user and item-based
use cases, aspect-based user/item distances are cal-
culated using the sentiment ratings extracted from the
reviews’ aspects. The similarity between users/items
is determined based on the inverse of the users/items
distances and ratings’ predictions are computed using
the collaborative filtering algorithm.
3 SYSTEM ARCHITECTURE
As exemplified in Chapter 2, the text-based items’
descriptions reveal more valuable information com-
pared to the plain numerical ratings for the recom-
mendation process. The focus of the proposed ap-
proach is to make use solely of the textual information
when building the recommendation system, regard-
less of the numerical ratings. The textual input is ex-
ploited using a lexicon-based technique to determine
the polarity score of a review. The resulted scores
are the sentiment ratings taken into consideration for
the user-based kNN collaborative filtering algorithm.
After the data collection phase, the text-based items’
reviews serve as input for a sentiment lexicon that de-
termines a sentiment rating for an item. The data set
enhanced with the computed sentiment rating is fur-
ther passed to a recommendation system.
3.1 Data Pre-processing
The proposed recommendation system handles tex-
tual information, therefore, a data cleansing process
was applied to the input data sets before being used
by the sentiment lexicon. The following techniques
have been applied:
• Removal of punctuation and stop words;
• Lower-casing;
• Removal of URLs;
• Stemming
3.2 Sentiment Lexicon
The proposed approach uses, for the sentiment anal-
ysis task, a sentiment lexicon, which was selected
based on the complex and thorough comparison pre-
sented in (Hutto and Gilbert, 2014). The Vader Sen-
timent Lexicon was compared to several ones from
literature (Linguistic Inquiry Word Count, General
Inquirer, Affective Norms for English Words, Sen-
tiWordNet, SenticNet, Word-Sense Disambiguation)
and produced,in most cases, the best results.
Vader (Valence Aware Dictionary and Sentiment
Reasoner) lexicon (Hutto and Gilbert, 2014) is a rule-
based sentiment analysis tool based on a dictionary
that maps words to positive, neutral, or negative sen-
timent scores. The sum of all these scores defines a
compound score which is normalized between -1 and
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
204

1. A value closer to -1 indicates a negative sentiment
for the item’s review, while a value closer to 1 a pos-
itive one. The sentiment score of a review is deter-
mined as follows:
score(review) =
n
∑
i=1
score(word
i
), (1)
where
• n is the number of words of a review.
• score(word
i
) is the sentiment score of the i
th
word, based on the Vader lexicon.
3.3 Recommendation Process
The data set containing in addition the reviews with
sentiment scores represents the input data for the rec-
ommendation system. The kNN collaborative fil-
tering algorithm is then applied as recommendation
technique, as follows (Petrusel and Limboi, 2019):
• The most similar k users (called neighbors) for
a target user are determined based on the calcu-
lated users’ similarity. Several similarity mea-
sures from literature can be used at this step.
• For not yet reviewed items of the target user, the
rating prediction is computed and top-n recom-
mendations are generated.
To determine the unknown rating prediction for an
item i and the target user a, the following formula is
used (Victor et al., 2011):
p
a,i
= ¯score
a
+
∑
u∈R
+
w
a,u
(score
u,i
− ¯score
u
)
∑
u∈R
+
w
a,u
(2)
where:
• ¯score
a
is the mean lexicon-based score rating
given by target user a for other items than i.
• ¯score
u
is the mean lexicon-based score given by
user u over all items.
• w
a,u
is the similarity between the two users.
• score
u,i
is the lexicon-based score determined for
item i and user u.
• R
+
is the set of users that rated item i positively.
3.4 Evaluation Process & Confidence
Intervals
The recommendation process is evaluated by comput-
ing the Mean Absolute Error (MAE) and Root Mean
Square Error (RMSE) (Isinkaye et al., 2015) for a user
u, based on the following formulas:
MAE(u) =
∑
N
r
i=1
|p
u,i
− score
u,i
|
N
r
(3)
and
RMSE(u) =
s
∑
N
r
i=1
|p
u,i
− score
u,i
|
N
r
(4)
where p
u,i
and score
u,i
are the predicted score, re-
spectively the actual score (determined via lexicon)
of user u for item i and N
r
is the number of recom-
mended items.
Moreover, 95% confidence intervals are deter-
mined to find out the value ranges for the model per-
formance. The confidence interval is a statistic in-
terval for measuring the uncertainty on an estimate.
It measures the range of values, from the given data,
that includes the true values for estimating good sug-
gestions. A smaller confidence interval means a more
precise estimation in comparison with a large one.
4 EXPERIMENTAL SETUP
To highlight the value-added by the proposed lexicon-
based K Nearest Neighbors collaborative filtering
approach in improving the rating prediction accu-
racy, several numerical experiments were conducted
on three data sets containing text-based reviews for
items.
For the neighborhood determination in the kNN,
various popular similarity measures from litera-
ture were applied: Pearson Correlation Coefficient
(PCC), Cosine (COS), Euclidean (EUC), Constrained
Pearson Coefficient (CPC), Spearman Rank Coeffi-
cient (SRC), Jaccard Similarity (JAC) (Agarwal and
Chauhan, 2017), (Sondur et al., 2016) and PIP (Ahn,
2008). Independent scenarios are designed for differ-
ent values of k (the neighbourhood size) and n (the
number of generated recommendations).
In the evaluation process, the MAE and RMSE
measures are computed to establish the accuracy of
the generated recommendations.
4.1 Data Sets
For the numerical experiments, three data sets are
used: Amazon Fashion (Yan et al., 2019), Rotten
Tomato Critic Reviews (Firmanto et al., 2018) and
Datafiniti Product Reviews (Zahid-samza595, 2020).
The Amazon Fashion data set contains 100 000 re-
views and several features, such as: review time, re-
viewer name, review text.
A Lexicon-based Collaborative Filtering Approach for Recommendation Systems
205

The Rotten Tomato Critic reviews has 50 000
movies & TV reviews. It is composed of features like
publisher name, review type, review content or review
date.
The Datafiniti Product Reviews has 3000 wine,
beer and liquor reviews described by the business
name, brand, category, review text, review date or
username.
4.2 Amazon Fashion Data Set Results
In tables 1, 2, 3, 4, 5 and 6 the results obtained for
several scenarios are presented. The best values for
MAE and RMSE for the lexicon-based collaborative
filtering are achieved using PIP similarity measure for
the neighborhood size k = 10 and number of recom-
mendations n = 3.
Moreover, the 95% confidence intervals were
calculated and the best results were obtained for the
scenario considering the neighborhood size k = 10
and number of recommendations n = 3 and are pre-
sented in table 7. Results show that MAE was at
x + / − y for 95% confidence interval, where x is the
lower bound of the interval and y is the upper bound.
4.3 Rotten Tomato Critic Reviews Data
Set Results
For the Rotten Tomato Critic Reviews data set (Fir-
manto et al., 2018), the results for all scenarios setups
are presented in tables 8, 9, 10, 11, 12 and 13. Best
values were achieved when using the PIP similarity
measure with neighbourhood size k = 10 and number
of generated recommendations n = 3.
Table 14 reveals the 95% confidence interval com-
puted for the best scenario with neighbourhood size
k = 10 and number of generated recommendations
n = 3.
4.4 Datafiniti Product Reviews Data Set
Results
Tables 15, 16, 17, 18, 19 and 20 showcase the results
obtained for all the test scenarios, for the Datafiniti
Product Reviews data set. Best values were achieved
when using the Spearman Rank Coefficient in the
lexicon-based kNN collaborative filtering approach
for the neighbourhood size k = 5 and number of gen-
erated recommendations n = 3.
Table 21 presents the 95% confidence interval for
the best scenario when using the neighbourhood size
k = 5 and number of generated recommendations n =
3.
4.5 Comparisons and Discussions
This section offers an overview of the MAE values ob-
tained for the best scenarios for each data set. When
comparing the results presented in figures 2, 3 and 4,
it can be observed that the best performance in terms
of MAE was achieved for the Datafiniti Product Re-
views (Zahid-samza595, 2020) using the Spearman
Rank Coefficient.
Moreover, the proposed lexicon-based approach is
compared to another text-based kNN collaborative fil-
tering approach described in (Terzi et al., 2014), in
terms of Root Mean Square Error performance mea-
sure. Both approaches use text-based reviews instead
of numerical ones and the experiments are conducted
on the Rotten Tomato Critic Reviews data set. Al-
though both approaches make use of textual items’
descriptions, there is a difference in the sentiment
score definition (substituting the numerical rating).
(Terzi et al., 2014) computes the distance between two
words based on the shortest distance between them,
while in the proposed approach the sentiment score is
obtained based on the information derived from the
Vader Lexicon (Hutto and Gilbert, 2014).
Results are presented in table 22. Even though
the quantitative results in (Terzi et al., 2014) are bet-
ter, the presented approach is different from a quali-
tative point of view, using a lexicon-based collabora-
tive filtering technique. The proposed technique has
value especially from the semantic point of view, con-
sidering words’ polarities (positive, negative, neutral)
compared to (Terzi et al., 2014), which is based on the
set of common words. Overall, this comparison high-
lights the fact that the presented approach generates
good and trustworthy results and confirms again that
text-based reviews indeed offer valuable information
for the recommendation process.
5 TABLES & FIGURES
Table 1: Amazon Fashion k=5 and n=3.
Similarity Measure MAE RMSE
PCC 0.45 0.67
COS 1.19 1.07
EUC 1.90 1.70
CPC 0.75 0.85
SRC 0.20 0.31
JAC 0.29 0.49
PIP 0.10 0.30
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
206

Table 2: Amazon Fashion k=5 and n=5.
Similarity Measure MAE RMSE
PCC 0.41 0.64
COS 1.04 1.002
EUC 1.90 1.70
CPC 0.86 0.91
SRC 0.20 0.30
JAC 0.29 0.49
PIP 0.10 0.31
Table 3: Amazon Fashion k=5 and n=10.
Similarity Measure MAE RMSE
PCC 0.34 0.58
COS 1.03 0.99
EUC 1.80 1.70
CPC 0.72 0.84
SRC 0.20 0.30
JAC 0.29 0.49
PIP 0.10 0.31
Table 4: Amazon Fashion k=10 and n=3.
Similarity Measure MAE RMSE
PCC 0.45 0.67
COS 0.70 0.82
EUC 0.77 0.66
CPC 0.73 0.84
SRC 0.13 0.27
JAC 0.29 0.48
PIP 0.10 0.19
Table 5: Amazon Fashion k=10 and n=5.
Similarity Measure MAE RMSE
PCC 0.42 0.64
COS 0.86 0.90
EUC 1.77 1.66
CPC 0.85 0.90
SRC 0.20 0.32
JAC 0.29 0.49
PIP 0.10 0.29
6 CONCLUSIONS & FUTURE
WORK
Recommendation systems are important tools for
defining suggestions for users. Lately, a lot of effort
was put into incorporating the text-based reviews in
the recommendation process. The scope was to en-
Table 6: Amazon Fashion k=10 and n=10.
Similarity Measure MAE RMSE
PCC 0.35 0.59
COS 0.83 0.89
EUC 1.77 1.66
CPC 0.72 0.84
SRC 0.20 0.32
JAC 0.29 0.49
PIP 0.10 0.29
Table 7: Amazon Fashion 95% CI.
Similarity Measure 95% CI
PCC (0.447,0.453)
COS (0.697,0.703)
EUC (0.767,0.773)
CPC (0.727,0.733)
SRC (0.128,0.132)
JAC (0.287,0.293)
PIP (0.098,0.102))
Table 8: Rotten Tomato Critic Reviews k=5 and n=3.
Similarity Measure MAE RMSE
PCC 0.78 0.77
COS 0.57 0.59
EUC 0.66 1.70
CPC 0.80 0.76
SRC 0.39 0.52
JAC 0.98 0.85
PIP 0.71 0.71
Table 9: Rotten Tomato Critic Reviews k=5 and n=5.
Similarity Measure MAE RMSE
PCC 0.85 0.82
COS 0.69 0.69
EUC 1.05 0.88
CPC 0.85 0.79
SRC 0.46 0.58
JAC 0.78 0.76
PIP 0.47 0.59
hance the classical collaborative filtering algorithms
and to explore the power of these descriptions. The
text-based reviews describe the user’s opinions and
feelings about items more accurately than a numeri-
cal value and, therefore, the text-based techniques can
produce accurate items’ rating predictions and rec-
ommendations. With this in mind, a recommenda-
tion system that incorporates the textual information
A Lexicon-based Collaborative Filtering Approach for Recommendation Systems
207

Table 10: Rotten Tomato Critic Reviews k=5 and n=10.
Similarity Measure MAE RMSE
PCC 0.68 0.71
COS 0.64 0.66
EUC 0.70 0.72
CPC 0.84 0.79
SRC 0.54 0.62
JAC 0.49 0.59
PIP 0.39 0.53
Table 11: Rotten Tomato Critic Reviews k=10 and n=3.
Similarity Measure MAE RMSE
PCC 0.72 0.71
COS 0.44 0.55
EUC 0.54 0.61
CPC 0.49 0.58
SRC 0.57 0.65
JAC 0.97 0.83
PIP 0.20 0.32
Table 12: Rotten Tomato Critic Reviews k=10 and n=5.
Similarity Measure MAE RMSE
PCC 0.62 0.67
COS 0.62 0.63
EUC 0.66 0.70
CPC 0.59 0.65
SRC 0.53 0.62
JAC 0.53 0.62
PIP 0.24 0.42
Table 13: Rotten Tomato Critic Reviews k=10 and n=10.
Similarity Measure MAE RMSE
PCC 0.64 0.68
COS 0.64 0.67
EUC 0.61 0.67
CPC 0.81 0.76
SRC 0.51 0.61
JAC 0.67 0.70
PIP 0.55 0.64
about an item by a user was proposed. In comparison
with the majority of approaches presented in 2 that
use machine learning algorithms, the proposed one
focuses on a lexicon-based kNN collaborative filter-
ing technique. The text-based review is processed by
the Vader Lexicon (Hutto and Gilbert, 2014), which
computes the sentiment rating. Then, the data set aug-
mented with the sentiment rating is used as input for
Table 14: Rotten Tomato Critic Reviews 95% CI.
Similarity Measure 95% CI
PCC (0.717,0.723)
COS (0.437,0.443)
EUC (0.537,0.543)
CPC (0.487,0.493)
SRC (0.567,0.573)
JAC (0.969,0.971)
PIP (0.198,0.202))
Table 15: Datafiniti Product Reviews k=5 and n=3.
Similarity Measure MAE RMSE
PCC 0.71 0.74
COS 1.73 1.22
EUC 1.66 1.61
CPC 1.21 1.01
SRC 0.04 0.09
JAC 0.74 0.82
PIP 0.06 0.17
Table 16: Datafiniti Product Reviews k=5 and n=5.
Similarity Measure MAE RMSE
PCC 0.98 0.82
COS 1.60 1.19
EUC 1.73 1.63
CPC 1.04 1.94
SRC 0.10 0.22
JAC 0.74 0.82
PIP 0.06 0.16
Table 17: Datafiniti Product Reviews k=5 and n=10.
Similarity Measure MAE RMSE
PCC 0.89 0.81
COS 1.63 1.20
EUC 1.73 1.63
CPC 1.05 1.94
SRC 0.10 0.22
JAC 0.74 0.82
PIP 0.06 0.16
the kNN collaborative filtering algorithm.
The results obtained in the conducted numerical
experiments show that the presented approach can be
successfully used to solve recommendation tasks, for
data sets containing text-based user reviews. As fu-
ture work, the approach could be extended to also
consider different types of review elements besides
words, such as review topics or aspect opinions.
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
208
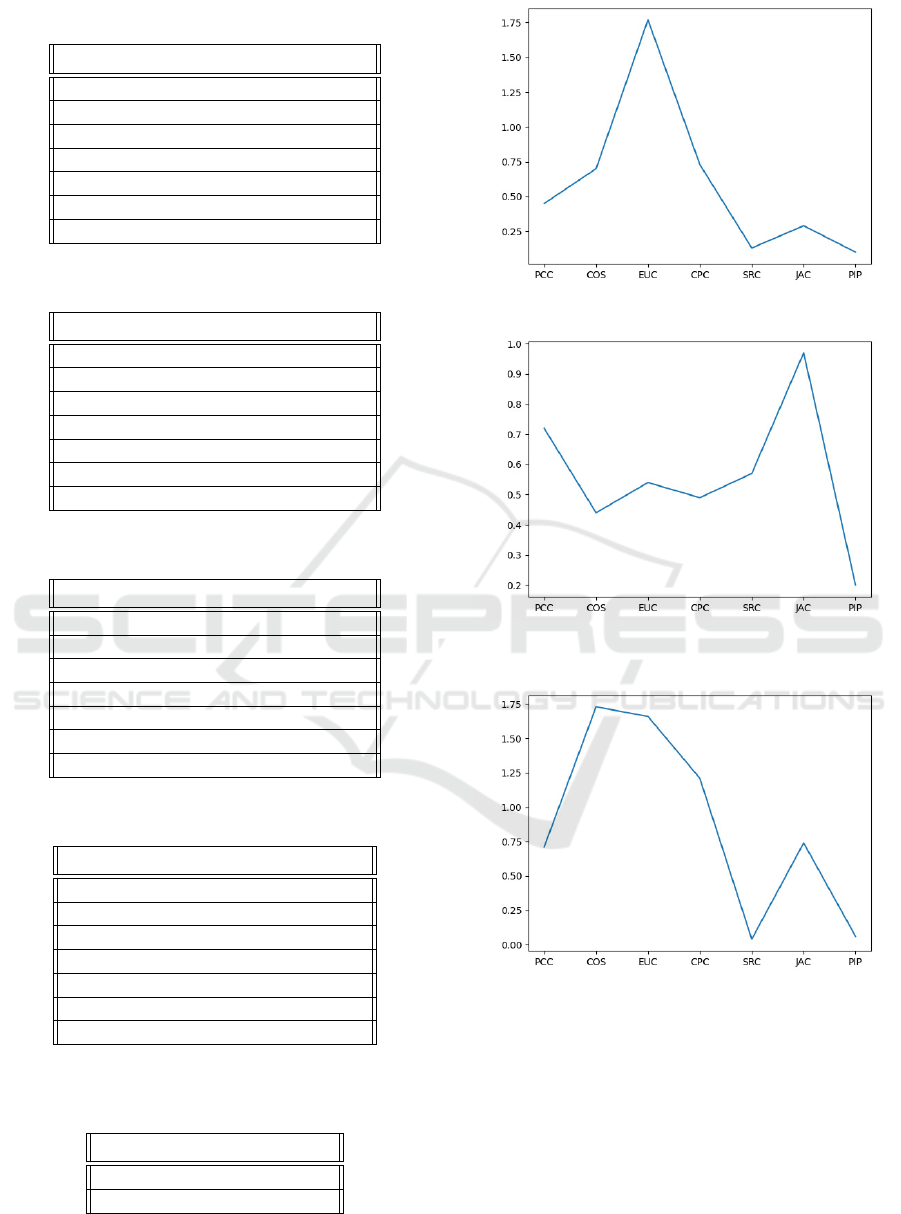
Table 18: Datafiniti Product Reviews k=10 and n=3.
Similarity Measure MAE RMSE
PCC 1.02 0.82
COS 1.57 1.76
EUC 1.40 1.52
CPC 0.88 0.87
SRC 0.08 0.21
JAC 0.58 0.70
PIP 0.09 0.24
Table 19: Datafiniti Product Reviews k=10 and n=5.
Similarity Measure MAE RMSE
PCC 1.01 0.82
COS 1.47 1.16
EUC 1.11 1.41
CPC 1.05 0.90
SRC 0.15 0.27
JAC 0.63 0.76
PIP 0.16 0.33
Table 20: Datafiniti Product Reviews k=10 and n=10.
Similarity Measure MAE RMSE
PCC 0.97 0.83
COS 1.69 1.23
EUC 1.12 1.42
CPC 1.05 0.94
SRC 0.15 0.27
JAC 0.63 0.75
PIP 0.16 0.34
Table 21: Datafiniti Product Reviews 95% CI.
Similarity Measure 95% CI
PCC (0.694,0.726)
COS (0.422,0.458)
EUC (0.522,0.558)
CPC (0.472,0.508)
SRC (0.552,0.588)
JAC (0.964,0.976)
PIP (0.186,0.214))
Table 22: Lexicon-based CF approach vs. (Terzi et al.,
2014) approach.
Approach RMSE
Lexicon-based CF 0.32
(Terzi et al., 2014) 0.14
Figure 1: MAE for Amazon Fashion, k=10 and n=3.
Figure 2: MAE for Rotten Tomato Critic Reviews, k=10
and n=3.
Figure 3: MAE for Datafiniti Product Reviews, k=5 and
n=3.
REFERENCES
Agarwal, A. and Chauhan, M. (2017). Similarity measures
used in recommender systems: a study. International
Journal of Engineering Technology Science and Re-
search IJETSR, ISSN, pages 2394–3386.
Ahn, H. J. (2008). A new similarity measure for collabo-
rative filtering to alleviate the new user cold-starting
problem. Information sciences, 178(1):37–51.
A Lexicon-based Collaborative Filtering Approach for Recommendation Systems
209

Boull
´
e, M. (2007). Compression-based averaging of selec-
tive naive bayes classifiers. The Journal of Machine
Learning Research, 8:1659–1685.
Firmanto, A., Sarno, R., et al. (2018). Prediction of movie
sentiment based on reviews and score on rotten toma-
toes using sentiwordnet. In 2018 International Semi-
nar on Application for Technology of Information and
Communication, pages 202–206. IEEE.
Hutto, C. and Gilbert, E. (2014). Vader: A parsimonious
rule-based model for sentiment analysis of social me-
dia text. In Proceedings of the International AAAI
Conference on Web and Social Media, volume 8.
Isinkaye, F. O., Folajimi, Y., and Ojokoh, B. A. (2015). Rec-
ommendation systems: Principles, methods and eval-
uation. Egyptian informatics journal, 16(3):261–273.
Ma, Y., Chen, G., and Wei, Q. (2017). Finding users pref-
erences from large-scale online reviews for person-
alized recommendation. Electronic Commerce Re-
search, 17(1):3–29.
Musto, C., de Gemmis, M., Semeraro, G., and Lops, P.
(2017). A multi-criteria recommender system exploit-
ing aspect-based sentiment analysis of users’ reviews.
In Proceedings of the eleventh ACM conference on
recommender systems, pages 321–325.
Petrusel, M.-R. and Limboi, S.-G. (2019). A restaurants
recommendation system: Improving rating predic-
tions using sentiment analysis. In 2019 21st Inter-
national Symposium on Symbolic and Numeric Al-
gorithms for Scientific Computing (SYNASC), pages
190–197. IEEE.
Poirier, D., Fessant, F., and Tellier, I. (2010). Re-
ducing the cold-start problem in content recom-
mendation through opinion classification. In 2010
IEEE/WIC/ACM International Conference on Web In-
telligence and Intelligent Agent Technology, volume 1,
pages 204–207. IEEE.
Sondur, M. S. D., Chigadani, M. A. P., and Nayak, S.
(2016). Similarity measures for recommender sys-
tems: a comparative study. Journal for Research, 2(3).
Terzi, M., Rowe, M., Ferrario, M.-A., and Whittle, J.
(2014). Text-based user-knn: Measuring user similar-
ity based on text reviews. In International Conference
on User Modeling, Adaptation, and Personalization,
pages 195–206. Springer.
Victor, P., Cornelis, C., De Cock, M., and Teredesai, A. M.
(2011). Trust-and distrust-based recommendations
for controversial reviews. IEEE Intelligent Systems,
(1):48–55.
Yan, C., Chen, Y., and Zhou, L. (2019). Differentiated fash-
ion recommendation using knowledge graph and data
augmentation. Ieee Access, 7:102239–102248.
Zahid-samza595, S. (2020). Sentiment analysis of hotel
reviews-performance evaluation of machine learning
algorithms.
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
210
