
Towards We-intentional Human-Robot Interaction using Theory of Mind
and Hierarchical Task Network
Maitreyee
a
and Michele Persiani
b
Department of Computing Science, Ume
˚
a University, Universitetstorget 4, Ume
˚
a, Sweden
Keywords:
We-intention, Joint Intention, Joint Activity, Human-Robot Interaction, We-mode, I-mode, Hierarchical Task
Network, Dialogue Interaction.
Abstract:
Joint activity between human and robot agent requires them to not only form joint intention and share a mutual
understanding about it but also to determine their type of commitment. Such commitment types allows robot
agent to select appropriate strategies based on what can be expected from others involved in performing the
given joint activity. This work proposes an architecture embedding commitments as we-intentional modes in
a belief-desire-intention (BDI) based Theory of Mind (ToM) model. Dialogue mediation gathers observations
facilitating ToM to infer the joint activity and hierarchical task network (HTN) plans the execution. The work
is ongoing and currently the proposed architecture is being implemented to be evaluated during human-robot
interaction studies.
1 INTRODUCTION
For successful joint activities, human and a robot
agent take a we-intentional stance (Tuomela and
Miller, 1988; Tuomela, 2005) aiming to act on a joint
intention. In a day-to-day scenario such interactions
about medication reminder, taking care of health and
finding objects in the house may require participants
to sometimes commit to a shared goal and other times
pursue their private ones.
An example of a prior case is when the human and
a robot agent deliberate by deciding on how to find an
object like newspaper, reading glasses or their cell-
phone, prepare a meal, or plan and clean the house
together. The instance for the latter case would be
when robot persuades human agent to take scheduled
medication or manage daily physical well-being by
rating any discomfort, taking some rest, or booking
an appointment to seek medical care.
The research has already discussed the content
required (Clodic et al., 2014; Levine and Williams,
2018; Vinanzi et al., 2021) for human-robot agent
joint actions. However, another factor that has not
received much attention is of the stance (Schweikard
and Schmid, 2020) an agent should have to perform
the joint activity (Grynszpan et al., 2019; van der Wel,
2015). A research question to ask for such a case is
a
https://orcid.org/0000-0002-3036-6519
b
https://orcid.org/0000-0001-5993-3292
How can agent’s stance be modeled for deliberation
and persuasion during a joint activity and what kind
of mediation will be required to achieve it?
To address the mentioned research gap we exam-
ine here different modes of we-intention (Tuomela
and Miller, 1988; Tuomela, 2006) determining the
stance of the agents with-in a theory of mind (ToM)
framework. Furthermore, we use dialogue communi-
cation to increase the information that the robot has
available when computing its ToM model. Finally,
through hierarchical task networks (Georgievski and
Aiello, 2015) we create probability distributions of
plans to be executed as legible or optimal depending
on the calculated information gain.
The proposed architecture requires a model of
shared cognition and mind (Thellman and Ziemke,
2019; Bianco and Ognibene, 2019) allowing robot
agent to attribute behavior to mental attitudes of hu-
mans or other artificial agents, similar to the con-
cept from Theory of Mind (ToM) (Scassellati, 2002).
In robotics ToM reasons the state of mind of other
involved agents at different dispositions, where two
most applicable ones’ are first and second order (Hell-
str
¨
om and Bensch, 2018). From Robot’s stand point
first order is robot’s reasoning of the human agent and
second order is robot’s reason of what human reasons
about the robot. Humans can be considered as ra-
tional agents with mental attitudes composed of their
knowledge about the world, the motivation and their
Maitreyee, . and Persiani, M.
Towards We-intentional Human-Robot Interaction using Theory of Mind and Hierarchical Task Network.
DOI: 10.5220/0010722200003060
In Proceedings of the 5th International Conference on Computer-Human Interaction Research and Applications (CHIRA 2021), pages 291-299
ISBN: 978-989-758-538-8; ISSN: 2184-3244
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
291

goals required to mediate in their complex and unpre-
dictable environment.
A belief-Desire-Intention (BDI) (Rao et al., 1995)
model can be used to represent agents with mental at-
titudes mentioned before. In this work, the agents are
represented as BDI models on which the robot agent
computes first and second order ToM. Interaction be-
tween robot and a human agent can be structured by
a shared task domain. For example, in a health-care
scenario a possible task is of taking pills where the
robot should bring pills and/or water to human owner.
It is therefore necessary that both human and robot
comply with a structure both in terms of tasks and in-
teractions that it allows. In this context we study how
a robot agent can form a we-intention (Tuomela and
Miller, 1988) with a human.
A we-intention is a type of aim intention, where
the agents share a set of actions to be performed aimed
by all the involved participants. We-intentional agents
form a joint intention to perform an action together,
namely, a joint action, in two different modalities
of; we-mode when the agents act as group members
“committed to collectively agreed upon goals” and
i-mode when agents are part of a group “committed
to their own private goal” (Tuomela, 2006; Tuomela,
2005). These two modes imply legible or optimal
mechanisms for joint activity. Our contribution im-
plies mechanisms for robot agent to create BDI based
ToM for executing joint activity with humans. Which
is realized by dialogue based observation gathering
and planning of shared task using hierarchical task
network.
Following Section 2 briefly introduces theory of
mind, motivates we-intentions for joint activity and
concludes with some related work. Then, Section 3
provides the formal architecture created for robots
BDI ToM, dialogue mediation, task execution and hi-
erarchical task network. The article concludes with
an illustrative example and ongoing work in Section 4
and Section 5.
2 BACKGROUND AND RELATED
WORK
This section provides relevant interpretation of The-
ory of Mind (ToM) and stance/commitment in We-
intention (Tuomela and Miller, 1988) for the purpose
of understanding this work.
2.1 Theory of Mind
A field recently being investigated to create models
for belief reasoning is theory of mind (ToM) (Scas-
sellati, 2002; Thellman and Ziemke, 2019). Theory of
mind relates to the ability of agents to attribute men-
tal states and beliefs to themselves or other agents,
and of creating a point of view of a situation in terms
of beliefs, goals and intentions that is different from
their own but rather belonging to others. A first or-
der theory of mind is expressed in the sentence “Bob
thinks that Alice thinks X”, or in other words Bob has
an estimate of Alice’s mental state, believing she’s
thinking X. Higher order theories deepen these levels
of reasoning by extending the thinking chain. A sec-
ond order reasoning would be “Carl thinks that [Bob
thinks that Alice thinks X]”—with parenthesis added
to highlight the recursion. In this case Carl holds an
estimate of Bob’s mental state. Arbitrary higher or-
ders of reasoning follow the same incremental struc-
ture.
Theory of mind is considered to be at the corner-
stone of shared intentionality (Tomasello et al., 2005).
Human beings are able to understand each other and
collaborate thanks to their innate will of sharing in-
tentions and psychological states.
2.2 We-intentional Stance
Intentions that agents’ mind create in order to per-
form actions and achieve goals as a collective can
be defined and studied under the umbrella term of
‘collective intentionality’. With explicit discussions
in Phenomenology, Existential Philosophy and Soci-
ological Theory collective intentionality gained atten-
tion in practical philosophy when introduced by Sel-
lars (Wilfrid, 1980) as ‘we-referential intentions’ or
simply called ‘we-intentions’. He argues we-intention
to have the following characteristics: (a) to be atti-
tudes of individuals, (b) to involve a non-parochial at-
titude towards group the individuals have, and (c) that
there are two types of intentions– primary i-intention
and we derivative i-intention to joint intention.
Joint intention can be expressed as a case
of performing joint actions by agents with joint
agency (Tuomela and Miller, 1988), we-intention and
a shared mutual belief. Central tenet of we-intention
entails a participation intention to perform a joint ac-
tion requiring agents to jointly intend to participate
action-ally, that is, contributing to performing of joint
actions. A we-intending agent has a rational belief
that it can perform its part of a joint action A with
some probability, and that it can perform A collec-
tively with other agents with some non-zero probabil-
ity.
Attitudes of we-intending agents allows joint in-
tention to exist in either– I-mode or we-mode for a
group as illustrated next.
Humanoid 2021 - Special Session on Interaction with Humanoid Robots
292

2.2.1 We-mode of We-intention
An agent in we-mode, functions as a group member
satisfying and committed to group’s goal g in the joint
intention by participating in joint action with the set
of requirements (Tuomela, 2006): (a) agent A
i
intends
to do his part of g (b) agent A
i
has a belief that other
agents in the group will perform their parts of g and
(c) that agent A
i
beliefs that there is a mutual belief
in the group that g will be effectuated to achieve the
joint intention.
2.2.2 I-mode of We-intention
An agent pursuing i-mode, functions as part of a
group satisfying the groups goal g being committed to
its private goal pg in the joint intention by participat-
ing in joint action with the set of requirements (Brat-
man, 1993): (a) agent A
i
intends to satisfy g, (b) agent
A
j
intends to satisfy g (c) A
i
and A
j
do so by meshing
up their sub-plans of their private goal pg and (d) they
have a mutual belief about (a), (b), and (c).
2.3 Joint Intention and We-intention in
Human Robot Interaction (HRI)
(Clodic et al., 2014) highlights the components re-
quired for joint activities between human and robot.
Their work discusses low level processing to infer in-
tentions of other agents, to jointly direct the attention
and to form a shared mutual belief about task in hand.
Some of the previous work (Rauenbusch and
Grosz, 2003; Kamar et al., 2009) proposed team ratio-
nality for building collaborative multi-agent systems,
for example, in (Rauenbusch and Grosz, 2003) the au-
thors used Shared Plan (Grosz and Kraus, 1996) and
Propose Trees to model collaboration as multi-agent
planning problem, where a rational team will perform
an action only if the benefits from performing an ac-
tion is less than its cost.
Authors in (Devin et al., 2017) illustrated a block
world scenario for human and robot agent to collab-
orate on a shared plan, with the focus on flexibility
and non-intrusiveness. Extension of HATP (Lalle-
ment et al., 2014) (a hierarchical task network plan-
ner for human robot agent shared planning) was pro-
posed with conflict resolution mechanism to account
for flexible plan interaction and minimal dialogue
interaction for non-intrusiveness. Pike (Levine and
Williams, 2018) was introduced for robot agent to
concurrently infer human intention and adapt to it.
The robot agent reasons on specific combinations of
controllable (actions that robot agent can choose to
do) and uncontrollable (actions performed by the hu-
man, environment or other agents in the environment)
possibilities for effective plans to jointly achieve a
task. The combinations are constrained by ordering of
actions, time constraint and unpredictable situations.
A temporal plan network generates real-time plans for
execution. Authors in (Vinanzi et al., 2021) assume
trust and intention recognition as essential to collab-
orative joint activities with mutual understanding, in-
teraction and coordination. Authors in this work dif-
fered from most of the research to determining robot
agent’s trust in human partner in performing joint ac-
tivities. Their work performs simulated evaluation
of learning and probabilistic cognitive architecture to
perform joint activity by robot agent estimating inten-
tion of and trust in human agent.
Literature suggests that most of the work con-
cerning joint activity in HRI models relate to inten-
tion recognition and human-aware planning, i.e., what
should the robot must do at perception and action
level without distinguishing the way in which a joint
activity could be pursued. Some work relating to such
modality has been investigated within the context of
agency. During joint activity between humans the au-
thor in (van der Wel, 2015) studies the effect of we-
mode processing of joint actions on the sense of con-
trol in participating human agents. The author stud-
ies dyads of human agents during a joint action with
different roles validating we-mode stance with a high
sense of control and performance of ones own as well
as of the other. However, online intention negotiation
reduced sense of control and shifted the stance of the
dyad to i-mode.
3 METHODOLOGY
We assume for the robot to be already have an aware-
ness of some of the goals that human might want to
pursue as a joint activity with the robot. In a day-to-
day health-care scenario human might want the robot
to; remind them about taking medication on time, to
help the human find objects such as newspaper, read-
ing glasses or their cell phone, to make human aware
of any persisting health issue they have been ignoring
and to discuss possible solutions. Either of the hu-
man or the robot may initiate a dialogue pursuing a
goal with a joint activity by first facing the prospec-
tive participant. The initiating agent then proposes
a joint intention which could be co-created by other
agent resulting into a we-/I-mode behavior or break-
downs because the other agent might be engaged in
or prioritizes another activity or lacks the knowledge
and/or functions to participate. To this end we only
Towards We-intentional Human-Robot Interaction using Theory of Mind and Hierarchical Task Network
293
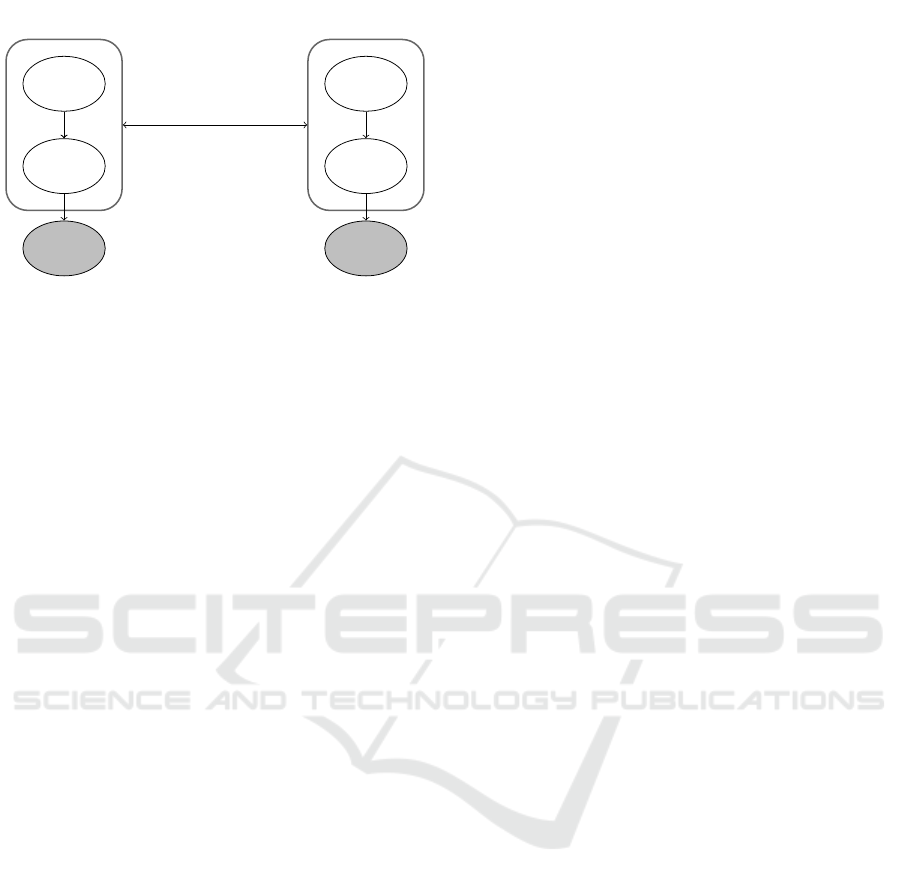
B
Π
O
P
R
(B, Π, O)
B
Π
O
P
H
R
(B, Π, O)
H (P
R
, P
H
R
|o)
Figure 1: Robot model and second-order theory of mind as
equivalent Bayesian Networks. The cross-entropy H mea-
sures the difference between robot’s and user’s estimated
state of mind a posteriori of the observations o gathered
through the dialogue with the user.
formulate co-creation of joint intention. Co-creation
of joint intention is realized with a ToM where, the
robot agent computes an information gain between its
own and human agent’s belief-desire-intention (BDI)
models. The information gain then directs the agent
to carryout the plan legibly or optimally.
Next sections illustrates the procedure robot uses
to (1) create its ToM model; (2) gather observations
by dialogue mediation; (3) regularize an HTN plan
constrained by human expectation; and (4) execute
the plan legibly or optimally.
The formal procedure in the text uses follow-
ing symbols: P
R
denotes probability distribution for
robot, P
H
R
is probability distribution on human com-
puted by the robot. b ∈ B denotes set of beliefs, G is
the goal and o ∈ O is the set of observations gathered
from the dialogue interaction. π ∈ Π denotes the set of
task networks. H is used here to denote cross-entropy
between human and robot’s intentions.
3.1 Theory of Mind- Human and Robot
as BDI Models
The general architecture to plan and executes joint
tasks in we-mode is shown in Figure 1. It is com-
posed of two Belief-Desire-Intention (BDI) models in
a configuration that describes a second-order theory
of mind between robot and human agent. On the left
side is the BDI model that the robot uses to plan the
interaction. Its joint distribution is:
P
R
(B, Π, O) = P
R
(O|Π)P
R
(Π|B)P
R
(B) (1)
where P
R
(B) is the probability distribution of be-
liefs and desires (here put together for simplicity).
Sampling from P
R
(B) yields a candidate belief and
desire of the robot, that it can use to compute its inten-
tion. P
R
(Π|B) is the intention model, that computes
intentions in the form of plans. Sampling P
R
(Π, B =
b) yields a candidate robot plan that is consistent with
b. Finally, P
R
(O|Π) is the observation model, that
provides the robot knowledge of how its intentions are
perceived, either in the form of a dialogue or physical
actions.
On the right side is instead the second-order the-
ory of mind of the human agent that the robot uses to
compute his expectations on the interaction. Again,
the theory of mind is a BDI model and defined as P
R
.
Its joint probability distribution is defined as:
P
H
R
(B, Π, O) = P
H
R
(O|Π)P
H
R
(Π|B)P
H
R
(B) (2)
For simplicity, we set P
R
and P
H
R
as equivalent
Bayesian networks. This relies on the assumption
of having a correct human agent model and that it
matches the model used by the robot, that can be
achieved by training the human agent before the inter-
actions. Notice that while the BDI models are struc-
turally the same, the random variables could be dif-
ferently distributed between them, allowing to model
uncertainty in the estimate of the human agent’s be-
liefs or intentions.
Crucial to the functioning of the proposed theory
of mind model is the distance measure H (P
R
, P
H
R
),
that the robot uses to compute the distance between its
own and the human agent’s probabilistic BDI models.
We refer to this degree of matching between the two
models as the general understanding that the human
agent has of the interaction (Hellstr
¨
om and Bensch,
2018).
A we-mode interaction implies that the human
agent is consistently understanding what’s happening
during the interaction i.e the state of mind of the in-
teraction. Therefore, to operate in we-mode from the
robot side, means to perform in a way that maintains
ToM to be “synchronized”. This can for example
be achieved by producing observations increasing the
understanding of the interaction. In this context, the
Information Gain (IG) that observations produce is:
IG(P
R
, P
H
R
|o) = H (P
R
, P
H
R
) − H (P
R
, P
H
R
|o) (3)
Information gain will be used to guide the exe-
cution of robot’s plan during the two main phases of
interactions, namely the dialogue phase, where robot
and human agent mediates the task (who will do what)
of their joint activity, and the execution phase, where
they jointly perform the agreed upon activity.
Humanoid 2021 - Special Session on Interaction with Humanoid Robots
294

3.2 Dialogue Interaction and Gathering
Observations
In order to mediate what they will do, human agent
and robot perform a dialogue to decide on a set of
commitments. These commitments are expressed in
the form of action frames that are used to constrain the
execution of the planner. Table 2 shows an example
dialogue and how utterances are associated through
action frames.
As proposed in previous research (Persiani and
Hellstr
¨
om, 2020), we utilize Semantic Role Label-
ing to classify action frame from utterances. For ex-
ample, an utterance “Can you remind me to take my
pills in fifteen minutes?” could get parsed into the se-
mantic frame verb: remind, object: pills, recipient:
me, while a classifier maps the semantic frames to
a corresponding task. For example, if the task do-
main defines an action frame remind ?agent ?recip-
ient ?object ?time, the classifier could map the ut-
terance to a partially specified action frame remind
robot0 human0 pills0 15minutes, where robot0 hu-
man0 pills0 15minutes are identifiers belonging to
the planning instance. Not all arguments of the action
frame are to be specified, and the missing ones are
found during the subsequent inference steps.
We utilize a finite state machine of dialogue acts
representing the utterances in each turn to model a di-
alogue scenario about medication as illustrated in 2.
A set of dialogue acts were selected for the purpose of
this work from (Harry et al., 2017)–Greeting, Good-
Bye, Question, Offer, CounterOffer, AcceptOffer, Re-
jectOffer, Inform. To organize the utterances such that
they fulfill the joint activity, Table 1 contains the ef-
fects of dialogue acts with respect to three sets: θ is
a set of questions, inform or offers R and O are re-
spectively the sets of rejected and accepted commit-
ments. Either of the agents can initiate a dialogue with
a greeting and end it with a goodbye, without any ef-
fects on commitments. A question or an inform in-
stantiates an action frame that one of the agent wants
to achieve during a joint activity. An offer provides
an agent with a possible action that can be performed
during the joint activity. A counter offer is an action
a
1
not accepted and an alternative a
2
is instead pro-
posed. An Accept and Reject can be used to accept or
reject proposed commitments.
At the end of the dialogue the set o = {a
0
, ..., a
n
}
identifies the action frames accepted through the di-
alogue. This set is utilized to constrain the planning
procedure as we will next describe.
3.3 Task Execution: Legibly or
Optimally
After the dialogue the set of mediated action frames
are utilized for constraining inference using the theory
of mind architecture. Two main type of inference are
required for obtaining a we-mode interaction: intent
recognition, that from the action frames finds the most
likely intention being expressed; and legible behavior,
which uses the found intention to change the original
robot plan toward more legible versions.
Intent recognition is performed by solving the fol-
lowing equation:
g
H
, π
H
= argmax
b∈B,π∈Π
P
H
R
(b, π|o) ∝ P
H
R
(b, π, o) (4)
that corresponds to finding the most likely goal
and plan that the second-order theory of mind yields
while being constrained by o. In other words, the hu-
man agent intention is found by simulating its model
under the constraints.
Legible behavior is obtained by making the robot
plan consistent to human agent’s intention. This is
expressed by the following equation:
b
R
, π
R
= argmax
b∈B,π∈Π
P
R
(π|o) + αH (P
H
R
(b
H
, π
H
)
k P
R
(b, π))
(5)
The right part regularizes the planner towards inten-
tions that are expected by the human agent model, ie.
similar to g
H
and π
H
.
3.4 Implementation through
Hierarchical Task Network
We implemented the BDI models P
R
(O, Π, B) and
P
H
R
(O, Π, B) by specifying planning instances using
the Hierarchical Task Network formalism (HTN). A
planning instance for the robot is obtained by spec-
ifying the tuple hP
R
, T
R
, M
R
, A
R
, I
R
, G
R
, O
R
i. Where
I
R
is the set of ground predicates in the initial state,
G
R
the goal task to be decomposed into primitive ac-
tions, O
R
is the set of objects available to ground the
available predicates P
R
, T
R
is the set of tasks available
to the planner, M
R
the set of methods to decompose
tasks in sub-tasks, A
R
the set of available primitive
actions. Refer to (Bercher et al., 2014) for a com-
plete description of HTN formalism. Similarly, the
second order theory of mind model has components
hP
H
R
, T
H
R
, M
H
R
, A
H
R
, I
H
R
, G
H
R
, O
H
R
i.
To implement the equivalent Bayesian networks
if Figure 1 we set the descriptive components of the
planning instances of robot and theory of mind to be
Towards We-intentional Human-Robot Interaction using Theory of Mind and Hierarchical Task Network
295
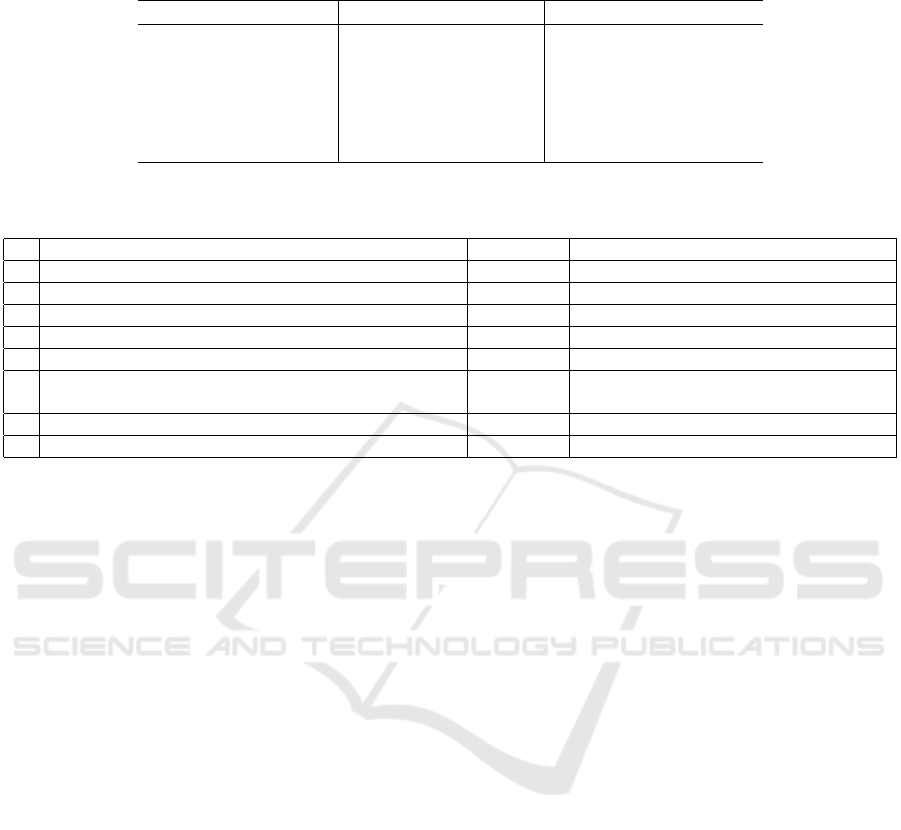
Table 1: Dialogue acts for the SDS that allows mediation of actions and goals with respect to the sets of offered, rejected and
accepted commitments.
Dialogue Act Precondition Effect
Question, x, ˆg
/
0 g = ˆg
Offer, x, a a 6∈ θ ∧ a 6∈ R ∧ a 6∈ R a ∈ θ
CounterOffer, x, a
1
, a
2
a
1
∈ θ a
2
6∈ R ∧ a
2
6∈ O a
1
6∈ θ ∧ a
2
∈ θ
Accept, x, a a ∈ θ a 6∈ θ ∧ a ∈ O
Reject, x, a a ∈ θ a 6∈ θ ∧ a ∈ R
Inform, x, a
1
...a
n
a
1
...a
n
∈ θ a
1
...a
n
6∈ θ ∧ a
1
...a
n
∈ O
Table 2: Robot and human mediating joint intention about medication committed to mutually agreed upon group goal (we-
mode).
Sentence Speech act Action frame
H Hello Robo Greeting
H Can you remind me to take my pills in fifteen minutes? Question remind robot0 human0 pills 15minutes
R Yes sure! Accept
R Do you want me to bring you some water as well? Offer bring robot0 human0 water ?when
H Yes, that would be great. Accept
R Okay! I will remind you to take pills in fifteen minutes
and bring you some water. Inform
H Thanks a lot! GoodBye
R No problem! GoodBye
equivalent. ie. P
R
= P
H
R
, T
R
= T
H
R
, M
R
= M
H
R
, A
R
=
A
H
R
and O
R
= O
H
R
, with the only probabilitic parts be-
ing I
R
, G
R
, I
H
R
and G
H
R
. We can realize the probability
distribution over the possible HTN instances describ-
ing the robot state through a combination of Bernoulli
distribution for the beliefs I
R
, and a categorical distri-
bution for the possible goals G
R
(the same for I
H
R
and
G
H
R
respectively).
P
R
(B) = P
R
(I)P
R
(G) (6)
P
R
(I; θ
R
) = Π
i
P(p
i
∈ I
R
;θ
p
i
) (7)
P(p
i
∈ I
R
) = θ
i
P
R
(G;θ
R
) = P(G|{g
0
, ..., g
m
}) (8)
P(G = hG
R
i|{g
0
, ..., g
m
}) = θ
j
∑
j
θ
j
= 1
Sampling a belief from P
R
(B) yields a initial state
and a goal task for the HTN planner. The plan-
ning model P
R
(Π|B) is implemented by a planner
of choice compatible with the underlying HTN re-
quirements. For our experiments we are using the
PANDA(Bercher et al., 2014) planner.
As also commonly proposed in research on plan-
ning, we model the human agent as expecting ratio-
nal behavior from the robot ie. by associating higher
probabilities to cheap plans. Therefore, the probabil-
ity of a plan P
R
(Π = π|B = b) is defined as a function
of rationality:
P
R
(Π = π|B = b) = αexp{τ(|π
opt,b
| − |π|)} (9)
where |π
opt,b
| is the length of an optimal plan for a be-
lief b, while |π| the length of the considered plan. α
is a normalizing constant, τ a temperature parameter.
Eq. 9 gives high likelihood to plans with lower cost,
with maximum likelihood associated to the plans of
the same cost of the optimal plan. Sampling from the
planning model can for example be done through Di-
verse Planning techniques (Katz and Sohrabi, 2020).
P
H
R
(B) and P
H
R
(Π|B) are similarly defined.
4 ILLUSTRATIVE EXAMPLE
AND ONGOING WORK
To better show the functioning of the proposed archi-
tecture we present an illustrative scenario with Ex-
amples 3 and 4. We assume a household scenario,
where a robot agent cohabits with human support-
ing him in daily tasks. Among these tasks, the robot
could be asked to perform the joint activity of clean-
ing the house, where they plan and execute the tasks
to; clean windows, mirrors and other surfaces, vac-
uum the floor, or organize the house.
Depending on human’s expectation from the
robot, the proposed scenario can unfold into follow-
Humanoid 2021 - Special Session on Interaction with Humanoid Robots
296
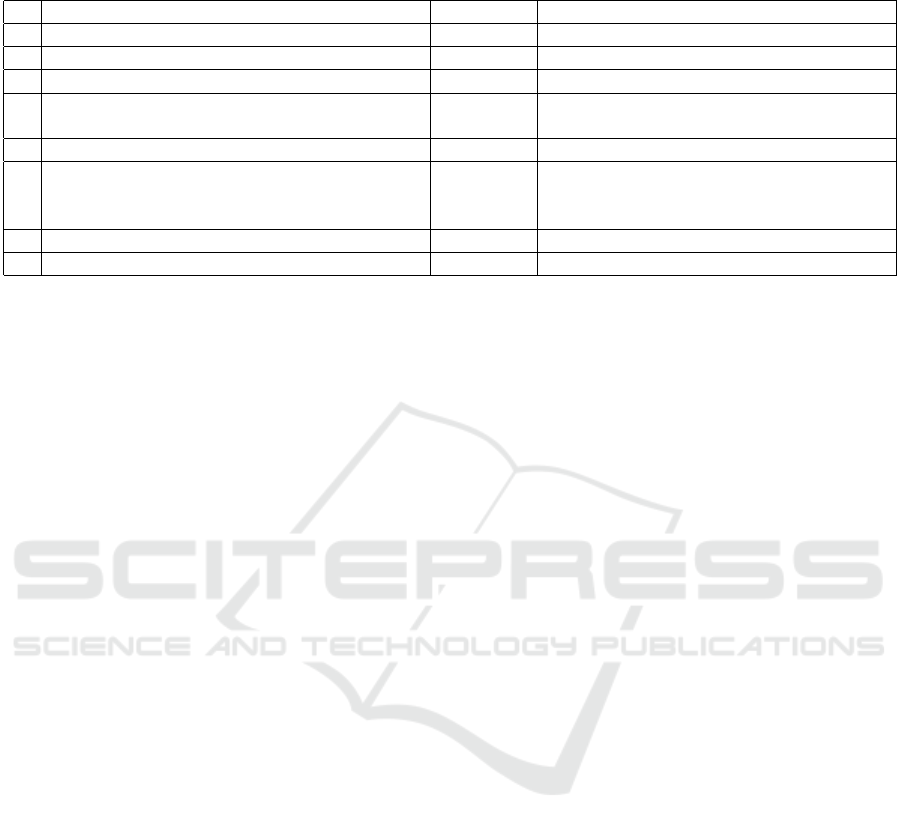
Table 3: Robot and human mediating joint intention about cleaning the house committed to mutually agreed upon group goal
(We-intention in we-mode)
Sentence Speech act Action frame
H Hello Greeting
H Can you help me with cleaning the house now? Question clean robot0 house0 now
R Yes sure! What would you like me to do? Accept
H I would like you to go and vacuum
the room once I have dusted their surfaces. Offer vacuum robot0 room0 floor afterDusting
R Okay! Accept
R I will vacuum the floors once
you have finished dusting the room. Inform
Is that correct? Question
H Yes, Thanks. Accept
R No Problem. GoodBye
ing two dialogues shown in Table 3 and Table 4.
Where, in the first one human asks the robot to help
him clean the house by performing one task of vacu-
uming the rooms given the condition that robot should
vacuum each room after human has cleaned the sur-
faces of that room. In the second case, human in-
structs the robot to perform the tasks of cleaning sur-
faces and vacuuming the two rooms (living and guest
room) in the house on its own, while he could clean
the other rooms. A set of commitments for the corre-
sponding joint activity (cleaning the house) is created
using the action frames for vacuum action in Exam-
ple 3 and, vacuum and clean surface actions in Ex-
ample 4. Depending on the dialogue scenario that hu-
man chose, action frames will be used to guide the
execution of the joint activity in the following ways:
firstly, as constraints while computing the intention
of the human. The human’s intention is computed to
know what the human expects (we-mode in Exam-
ple 3 and i-mode in Example 4) from the joint activ-
ity. Since in the example dialogues the human uses
Offer speech act to set the goal task, what remains to
compute is the plan part of the intention. To do so the
human model P
H
R
is simulated giving the set of action
frames as constraints (Eq. 4) ie. only intention con-
taining the mentioned action frames are considered.
After finding the human intention the robot should
compute its own intention. It can perform the activity
either in I-mode or in we-mode. Robot computes opti-
mal plan for operating in I-mode for the dialogue Ex-
ample 4 while the plan is regularized to match the ex-
pectation of the human in dialogue Example 3. Such
plans for this work is created using HTN as illustrated
in the previous Section 3.4.
This work reports on ongoing research and cur-
rently we are implementing the different compo-
nents for realizing the proposed architecture from
Activity Theoretical perspective (Vygotsky, 1978;
Kaptelinin and Nardi, 2006; Leontiev, 1978). Ac-
tivity theory facilities the study of human activity
at the intersection of human psychology, social re-
lationships and institutions (Roth, 2014). We mod-
ify the proposed BDI model in our architecture with
elements–(subject, object, tool, division of labor,
rules, and community) from Engestr
¨
om’s Activity
System Model (ASM) (Engestr
¨
om, 1999), for dia-
logues between robots and humans in a health-care
setting. As a first step of validation, a qualitative
study was conducted with 20 human participants, who
watched recordings of human and robot interacting in
a Wizard of Oz setup. The study aimed to understand
how human’s perceived HRI interactions for joint ac-
tivity in we-/I-mode of we-intention. Qualitative re-
sults highlighted that behavior, role, relationship and
dialogue strategies were perceived as intuitive, intelli-
gent and human-like, however, the robot was expected
to adapt and improve to have more empathetic behav-
ior. The results from our qualitative study will now be
used to inform the development of our architecture.
5 CONCLUSIONS
With this position paper we proposed a theory-of-
mind architecture for joint human-robot activities.
Joint activities are first mediated through a dialogue,
allowing human and robot to specify what will be
their commitments inside the joint activity. Then,
from the robot’s perspective, a joint activity can be
executed in I-mode or we-mode respectively. While
operating in I-mode, the robot committed towards its
private goal executes the joint activity in the most op-
timal way given its capabilities, and without consid-
ering the fact that it is collaborating with a human.
This can be desirable is some scenarios, such as when
robot and human are committed to the same goal op-
erating in we-mode instead, a legibility requirement
is introduced to make the robot plan similar to the hu-
Towards We-intentional Human-Robot Interaction using Theory of Mind and Hierarchical Task Network
297

Table 4: Robot and human mediating joint intention about cleaning the house committed to their own private goals (we-
intention in i-mode).
Sentence Speech act Action frame
H Hi, Can you help me with cleaning the house now? Greeting and Question clean robot0 human0 house now
R Yes sure! What would you like me to do? Accept
H I would like you to dust the surfaces dust,vacuum robot0
and vacuum floors of the living room and guest room, Offer room0 living room1 guest
while.
R Yes sure! Accept
R I will clean the living and guest room. Offer
H Thanks, that would be great. Accept
R No problem! GoodBye
man’s expectations.
We proposed the formalization of the architec-
ture, together with an illustrative example showing its
function in a simple scenario where human and robot
mediate the task of bringing the human medications.
Future work will conduct Human Robot Interaction
(HRI) studies to evaluate the proposed architecture.
REFERENCES
Bercher, P., Keen, S., and Biundo, S. (2014). Hy-
brid planning heuristics based on task decomposition
graphs. In Seventh Annual Symposium on Combinato-
rial Search.
Bianco, F. and Ognibene, D. (2019). Transferring adaptive
theory of mind to social robots: Insights from devel-
opmental psychology to robotics. In Social Robotics,
pages 77–87. Springer International Publishing.
Bratman, M. E. (1993). Shared intention. Ethics,
104(1):97–113.
Clodic, A., Alami, R., and Chatila, R. (2014). Key elements
for joint human-robot action. In Robo-Philosophy,
volume 273 of Sociable Robots and the Future of So-
cial Relations, pages 23–33, Aarhus, Denmark. IOS
Press Ebooks.
Devin, S., Clodic, A., and Alami, R. (2017). About de-
cisions during human-robot shared plan achievement:
Who should act and how? In Social Robotics, pages
453–463, Cham. Springer International Publishing.
Engestr
¨
om, Y. (1999). Activity theory and individual and
social transformation. Perspectives on activity theory,
19(38):19–38.
Georgievski, I. and Aiello, M. (2015). Htn planning:
Overview, comparison, and beyond. Artificial Intel-
ligence, 222:124–156.
Grosz, B. and Kraus, S. (1996). Collaborative plans for
complex group action. Artificial Intelligence.
Grynszpan, O., Saha
¨
ı, A., Hamidi, N., Pacherie, E., Berbe-
rian, B., Roche, L., and Saint-Bauzel, L. (2019). The
sense of agency in human-human vs human-robot
joint action. Consciousness and cognition, 75:102820.
Harry, B., Volha, P., David, T., and Jan, A. (2017). Dialogue
Act Annotation with the ISO 24617-2 Standard, pages
109–135. Springer International Publishing.
Hellstr
¨
om, T. and Bensch, S. (2018). Understandable robots
- what, why, and how. Paladyn, Journal of Behavioral
Robotics, 9(1):110–123.
Kamar, E., Gal, Y., and Grosz, B. J. (2009). Incorporating
helpful behavior into collaborative planning. In Pro-
ceedings of The 8th International Conference on Au-
tonomous Agents and Multiagent Systems (AAMAS).
Springer Verlag.
Kaptelinin, V. and Nardi, B. A. (2006). Acting with Tech-
nology: Activity Theory and Interaction Design. The
MIT Press, USA.
Katz, M. and Sohrabi, S. (2020). Reshaping diverse plan-
ning. In AAAI, pages 9892–9899.
Lallement, R., de Silva1, L., and Alam, R. (2014). Hatp:
An htn planner for robotics. In Planning and Robotics
(PlanRob), ICAPS Workshop, volume 2, page 8,
Portsmouth, USA. AAAI Press.
Leontiev, A. N. (1978). Activity, consciousness, and per-
sonality. Prentice-Hall, Moscow, Russia.
Levine, S. J. and Williams, B. C. (2018). Watching and act-
ing together: Concurrent plan recognition and adap-
tation for human-robot teams. J. Artif. Int. Res.,
63(1):281–359.
Persiani, M. and Hellstr
¨
om, T. (2020). Intent recognition
from speech and plan recognition. In International
Conference on Practical Applications of Agents and
Multi-Agent Systems, pages 212–223. Springer.
Rao, A. S., Georgeff, M. P., et al. (1995). Bdi agents: from
theory to practice. In ICMAS, volume 95, pages 312–
319, USA. MIT Press.
Rauenbusch, T. W. and Grosz, B. J. (2003). A decision
making procedure for collaborative planning. In Pro-
ceedings of the Second International Joint Conference
on Autonomous Agents and Multiagent Systems, AA-
MAS ’03, page 1106–1107. Association for Comput-
ing Machinery.
Roth, W.-M. (2014). Activity Theory, pages 25–31.
Springer New York, New York, NY.
Scassellati, B. (2002). Theory of mind for a humanoid
robot. Autonomous Robots, 12:13–24.
Schweikard, D. P. and Schmid, H. B. (2020). Collective In-
tentionality. In Zalta, E. N., editor, The Stanford En-
cyclopedia of Philosophy. Metaphysics Research Lab,
Stanford University, Winter 2020 edition.
Thellman, S. and Ziemke, T. (2019). The intentional
stance toward robots: conceptual and methodologi-
cal considerations. In The 41st Annual Conference of
Humanoid 2021 - Special Session on Interaction with Humanoid Robots
298

the Cognitive Science Society, July 24-26, Montreal,
Canada, pages 1097–1103.
Tomasello, M., Carpenter, M., Call, J., Behne, T., and Moll,
H. (2005). Understanding and sharing intentions: The
origins of cultural cognition. Behavioral and Brain
Sciences, 28(5):675–691.
Tuomela, R. (2005). We-intentions revisited. Philosophical
Studies, 125(3):327–369.
Tuomela, R. (2006). Joint intention, we-mode and i-mode.
Midwest Studies In Philosophy, 30(1):35–58.
Tuomela, R. and Miller, K. (1988). We-intentions. Philo-
sophical Studies, 53(3):367–389.
van der Wel, R. P. (2015). Me and we: Metacognition and
performance evaluation of joint actions. Cognition,
140:49–59.
Vinanzi, S., Cangelosi, A., and Goerick, C. (2021). The col-
laborative mind: intention reading and trust in human-
robot interaction. iScience, 24(2):102130.
Vygotsky, L. S. (1978). Mind in society: The development
of higher mental processes (e. rice, ed. & trans.).
Wilfrid, S. (1980). On reasoning about values. In American
Philosophical Quarterly, volume 17, page 81–101.
JSTOR.
Towards We-intentional Human-Robot Interaction using Theory of Mind and Hierarchical Task Network
299
