
Which Is More Helpful in Finding Scientific Papers to Be Top-cited in the
Future: Content or Citations? Case Analysis in the Field of Solar Cells
2009
Masanao Ochi
1 a
, Masanori Shiro
2
, Jun’ichiro Mori
1
and Ichiro Sakata
1
1
Department of Technology Management for Innovation, Graduate School of Engineering, The University of Tokyo,
Hongo 7-3-1, Bunkyo, Tokyo, Japan
2
HIRI, National Institute of Advanced Industrial Science and Technology, Umezono 1-1-1, Tsukuba, Ibaraki, Japan
Keywords:
Citation Analysis, Scientific Impact, Graph Neural Network, BERT.
Abstract:
With the increasing digital publication of scientific literature and the fragmentation of research, it is becoming
more and more difficult to find promising papers. Of course, we can examine the contents of a large number of
papers, but it is easier to look at the references cited. Therefore, we want to know whether a paper is promising
or not based only on its content and citation information. This paper proposes a method of extracting and
clustering the content and citations of papers as distributed representations and comparing them using the
same criteria. This method clarifies whether the future promising papers will be biased toward content or
citations. We evaluated the proposed method by comparing the distribution of the papers that would become
the top-cited papers three years later among the papers published in 2009. As a result, we found that the
citation information is 39.9% easier to identify the papers that will be the top-cited papers in the future than
the content information. This analysis will provide a basis for developing more general models for early
prediction of the impact of various scientific researches and trends in science and technology.
1 INTRODUCTION
In order to identify research worthy of investment, it
is essential to identify promising research at an early
stage. In addition, with the increase in the digital pub-
lication of scientific literature and the increasing frag-
mentation of research, there is a need to automatically
develop techniques to predict future research trends.
Previous research on predicting the impact of scien-
tific research has been conducted using specially de-
signed features for each indicator. On the other hand,
recent advances in deep learning technology have fa-
cilitated integrating different individual models and
constructing more general-purpose models. However,
the possibility of using deep learning techniques to
predict the impact indicators of scientific research has
not been sufficiently explored. In this paper, we ex-
tracted the number of citations after publication, one
of the typical impact indicators of scientific research,
and the corresponding information in the academic
literature as a distributed representation. We analyzed
the possibility of identifying papers with high impact.
a
https://orcid.org/0000-0002-6661-6735
The analysis results show that the linguistic informa-
tion of academic literature and the distributed rep-
resentation using network information are different.
The results of this paper may provide a fundamental
analysis for the development of a more general model
for early prediction of the impact of various scientific
researches and the prediction of trends in science and
technology.
2 RELATED WORKS
Research on the impact of science and technology has
focused on developing indicators and their future pro-
jections. The development of indices mainly aims at
quantifying the influence of an individual subject. For
example, the number of citations for papers, the h-
index(Hirsch, 2005) for authors, the Journal Impact
Factor (JIF) (Garfield and Sher, 1963) for journals,
and the Nature Index (NI) for research institutions are
typical examples. Of course, various other indices
have been developed, but most of them focus on pa-
pers and authors. On the other hand, some studies
360
Ochi, M., Shiro, M., Mori, J. and Sakata, I.
Which Is More Helpful in Finding Scientific Papers to Be Top-cited in the Future: Content or Citations? Case Analysis in the Field of Solar Cells 2009.
DOI: 10.5220/0010689100003058
In Proceedings of the 17th International Conference on Web Information Systems and Technologies (WEBIST 2021), pages 360-364
ISBN: 978-989-758-536-4; ISSN: 2184-3252
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

Table 1: Rank of the number of citations of the papers in the dataset (published in 2009) until 2012.
Ranking
@2012
Authors Title Journal
Citation
@2012
1 Park, S. H., et al.
Bulk heterojunction solar cells
with internal quantum efficiency approaching 100%.
Nature Photonics 1,126
2 Chen, H. Y., et al.
Polymer solar cells
with enhanced open-circuit voltage and efficiency.
Nature Photonics 930
3 Dennler, G., et al.
Polymer-fullerene bulk-heterojunction solar cells.
Advanced materials 747
4 Krebs, F. C., et al.
Fabrication and processing of polymer solar cells:
A review of printing and coating techniques.
Solar energy materials
and solar cells
495
5 Gr
¨
atzel, M., et al.
Recent advances in sensitized mesoscopic solar cells.
Accounts of
chemical research
465
have reported predicting these indices. Some studies
predict the h-index of future researchers(Ayaz et al.,
2018; Mir
´
o et al., 2017; Schreiber, 2013; Acuna et al.,
2012), studies that predict the number of citations af-
ter publication(Bai et al., 2019; Sasaki et al., 2016;
Stegehuis et al., 2015; Cao et al., 2016). Among
these, the difference is that Stegehuis et al.. and Cao
et al.. consider the number of citations one to three
years after publication and predict the number of cita-
tions in the reasonably distant future. In comparison,
Sasaki et al.. predict the number of citations three
years later without using citations after publication.
Recently, the application of deep learning tech-
niques to academic literature data has been promoted.
The SPECTER model(Cohan et al., 2020), trained on
the SciDocs dataset, is a representative example of ap-
plying text data in academic literature. However, the
SPECTER model uses the citation information of the
articles, and it does not simply obtain the distributed
representation of each article based on linguistic in-
formation alone. In this study, we used the learned
Sentence-BERT model(Reimers and Gurevych, 2019)
trained by the SNLI corpus(Bowman et al., 2015) as
a method to obtain the distributed representation for
each article.
On the other hand, there is an attempt to cap-
ture the citation information of academic literature
data as one huge graph and use it for task evalua-
tion such as link prediction. The SEAL model(Zhang
and Chen, 2018) is the top-ranked model on #ogbl-
citation2, for the citation prediction task in the aca-
demic literature dataset of the Open Graph Bench-
mark (OGB)(Weihua Hu, 2020), one of the bench-
mark datasets for graph data, as of February 2021
1
.
The SEAL model learns by sampling a pair of nodes
in a graph and using a subgraph containing the two
nodes to predict a link between the sampled nodes.
The SEAL model does not use the entire graph as
input but rather a large number of small subgraphs,
1
OGB:Leaderboards for Link Property Prediction:
https ogb
˙
stanford
˙
edudocsleader linkprop#ogbl-citation2
which has the advantage of being relatively easy to
apply to parallelization and large graphs.
3 METHODOLOGY
The purpose of this paper is to analyze the possibil-
ity of identifying papers with high impact by extract-
ing the number of citations after publication, which
is one of the representative impact indicators of sci-
entific research, and the corresponding information
on academic literature as a distributed representation.
In order to analyze the possibility of identifying pa-
pers with high impact, we use two methods to obtain
the distributed representation for each paper: one is
for linguistic information (title and abstract), and the
other is for citation information. We compare the dis-
tribution of the papers with the highest citations after
three years of the publication on the obtained variance
representation. The likelihood of identifying such pa-
pers is high if the papers with the highest citations are
skewed within a particular region and low otherwise.
This paper compares the likelihood of identifying the
papers with the highest citations by the method using
linguistic information and the method using citation
information for a relatively small dataset.
The method of comparison is as follows. Ob-
tain the distributed representation of each article by
two methods: one is the embedding method for lin-
guistic information, and the other is the embedding
method for citation information. After obtaining these
two distributed representations, we apply a clustering
method under the same number clusters k. Further-
more, we calculate the entropy of the entire dataset
with the percentage of papers in the same cluster that
will be the most cited papers in n years after publica-
tion. The following formula calculates the entropy.
H(P
t
) = −
∑
c∈C
P
t
(c)lnP
t
(c) (1)
However, the symbols in the equation are as follows:
Which Is More Helpful in Finding Scientific Papers to Be Top-cited in the Future: Content or Citations? Case Analysis in the Field of Solar
Cells 2009
361

N(c): Number of papers belonging to the cluster c
N
t
(c): Number of papers in the cluster c that are
among the top cited papers in the cluster
P
t
(c) =
N
t
(c)
N(c)
: Percentage of papers with the highest
citations in the cluster c
The lower value of entropy, the more likely the pa-
pers with the highest number of citations concentrate
in a particular cluster.
4 EXPERIMENT
In this section, we describe the experiment. First,
we describe the scientific and technical literature data
used in the experiment. Next, we explain the param-
eters and conditions we set for the extraction of the
variance representation. Here includes how we visu-
alized the data in two dimensions.
4.1 Scientific and Technical Literature
Dataset
We received the data from Elsevier, one of the inter-
national publishers of many journals. They ran the
query “(TITLE-ABS-KEY(nano AND carbon) OR
TITLE-ABS-KEY(gan) OR TITLE-ABS-KEY(solar
AND cell) OR TITLE-ABS-KEY(complex AND net-
works)) AND PUBYEAR AFT 2006” on Scopus and
obtained the results of the data retrieval.
In this paper, we focus on the 57,935 papers pub-
lished between 2006 and 2009 that have abstract in-
formation, and the top-cited papers are the 66 papers
published in 2009 that have been cited more than 100
times by 2012(n = 3). We show some of the top-cited
papers in Table 1.
For the method based on linguistic information,
we combine the title and abstract of each paper as in-
put. For the method based on citation information, we
create an undirected graph using the citation informa-
tion of the period, where the nodes are the papers and
the edges are the citation relations. This graph has
921,454 nodes and 1,348,424 edges.
4.2 Conditions for Distributed
Representation Extraction
For the method using linguistic information, we
use the Sentence-BERT(Reimers and Gurevych,
2019) trained model, “nli-bert-large”. We use the
SEAL(Zhang and Chen, 2018) for the method using
citation information and use the created network as in-
put. We set the parameter h = 1 to represent the sam-
pling range of nodes to create the subgraph. However,
10% of the edges are used as test data to evaluate the
accuracy of the trained model. The distributed repre-
sentation acquisition by SEAL learns the presence or
absence of an edge between two sampled nodes. For
this purpose, we obtain the distributed representation
of the target node from the output layer of the MLP
layer. We then average with the variance representa-
tion of the target node and the neighbouring nodes.
We apply the K-means method for clustering the
extracted distributed representations, and we set the
number of clusters to k = 20. For visualization, we
use the UMAP method(McInnes et al., 2018) to re-
duce the dimensionality to two dimensions.
5 RESULTS
In this section, we explain the results of our experi-
ments. In the experiment, we use a pre-trained model
for embedding linguistic information, while we need
to train the model for embedding citation information
using a dataset. For this reason, we explain the train-
ing results of the SEAL model that we selected as the
method using citation information. After we confirm
that both models have been sufficiently trained, we fi-
nally show the comparison results of the distributions
of the top-cited papers.
5.1 Training Results of SEAL Model
We show the Precision-Recall curves of the link pre-
diction results for the test data in Figure 1, and we
show the Precision and Recall at the threshold where
the F-value is the maximum in Table 2. We observe
that the Precision-Recall curve has a stable shape and
that the model is not sensitive to the output thresh-
old. In addition, the F-value is 0.835 at the threshold
P
th
= 0.960 when the F-value is maximum, indicating
that the learned model has high accuracy on the test
data.
Table 2: Accuracy of Link Prediction.
Precision Recall F-value(Max) P
th
0.916 0.768 0.835 0.960
Table 3: Distribution results of the top-cited papers by En-
tropy.
Model Entropy
Sentence-Bert 2.900
SEAL 1.742
WEBIST 2021 - 17th International Conference on Web Information Systems and Technologies
362
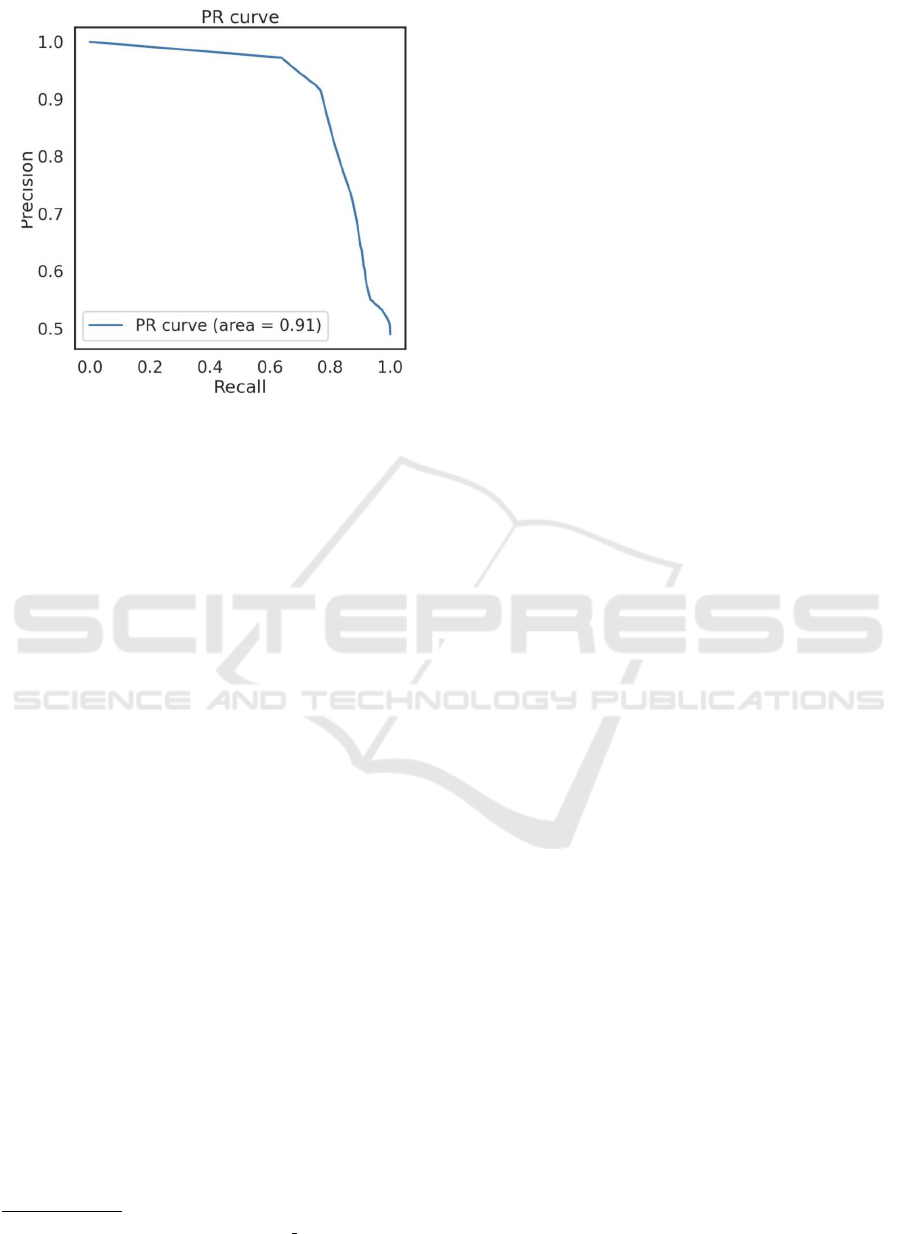
Figure 1: The Result of Precision-Recall curve for link pre-
diction.
5.2 Results of the Distribution of the
Top-cited Papers
We show the visualization results of the extracted dis-
tributed representations and the distributions of the
top-cited papers by the UMAP method in Figure 2.
We show the entropies of the distributions of the
top-cited papers in the clusters in Table 3. In the
visualization result shown in Figure 2, the colour-
coding indicates the result of clustering. The red plots
sparsely shown with the titles of the papers are the
top-cited papers. Comparing the visualization results
of Sentence-BERT and SEAL, we can observe that
the top-cited papers are more concentrated in SEAL.
Table 3 shows that the entropy of the top-cited pa-
pers is 2.900 for the Sentence-BERT model, while it
is 1.742 for SEAL. In other words, the SEAL model is
more biased than the Sentence-BERT model by more
than 1.1 points in terms of the number of papers with
the highest citations.
6 DISCUSSION
In this section, we discuss the results presented in the
5 section.
First, the SEAL model shows an MRR (Mean
Reciprocal Rank) of 0.8767 for the OGB (#ogbl-
citation2) leaderboard
2
. The result indicates that the
target node is the 1.1th candidate on average. Al-
though the learning results of the link prediction are
2
https://ogb.stanford.edu/docs/leader linkprop/#ogbl-
citation2
not as accurate as this, the learning results are compa-
rable to those of the network in this experiment with a
smaller size than the #ogbl-citation2 network, which
indicates that the learning result is sufficient.
Next, the bias of the papers with the highest ci-
tations is more skewed in SEAL than in Sentence-
BERT, indicating that the papers are concentrated in
specific clusters. This result indicates that the citation
relationship is more likely to concentrate the papers
whose citations are more likely to increase than the
content of the title or abstract. The effect of citations
on SEAL learning is limited since the present analysis
only covers the papers published in 2009 and marks
the top-cited papers after three years.
7 CONCLUSION
In this paper, we conducted an identifiability anal-
ysis using distributed representation extracted from
academic literature information for predicting the im-
pact of scientific research. Specifically, we used the
trained Sentence-BERT model, a method for obtain-
ing distributed representation for linguistic informa-
tion, and the SEAL model, which is a method for
obtaining distributed representation for citation infor-
mation. We apply these models to identify the top-
cited papers three years after publication using only
linguistic information and citation information at the
time of publication. We evaluate the results by apply-
ing the entropy index.
The results show that the SEAL model is more
likely than the Sentence-BERT model to bias the top-
cited papers to a specific cluster by about 1.1 points.
This result indicates that the citation information is
more likely to identify the top-cited papers three years
after publication than the linguistic information.
On the other hand, there are some limitations to
our results. The trained Sentence-BERT model used
in this study does not use the academic literature data
as training data. It may show different results if the
model is trained only on academic literature corpus.
In addition, the analysis is a case in a technological
field related to solar cells. In addition, we have used
the technological field related to solar cells as a case
study for 2009. In this study, we analyzed the data
as of 2009, using the technology field related to solar
cells as a case study. This result may be because solar
cells are a highly specialized field or a phenomenon
specific to a particular year. In the future, we could
obtain different results if the analysis is carried out
for different periods in different fields, especially in
fields that develop in an interdisciplinary manner.
We will need to discuss further the possibility of
Which Is More Helpful in Finding Scientific Papers to Be Top-cited in the Future: Content or Citations? Case Analysis in the Field of Solar
Cells 2009
363

Sentence-BERT
SEAL
Figure 2: Visualization results of the acquired distributed representation. Color coding is the result of the K-means method.
identifying studies that will be heavily cited in the fu-
ture by analyzing more models and examples.
ACKNOWLEDGEMENT
This article is based on results obtained from a
project, JPNP20006, commissioned by the New En-
ergy and Industrial Technology Development Organi-
zation (NEDO).
REFERENCES
Acuna, D. E., Allesina, S., and Kording, K. P. (2012). Pre-
dicting scientific success. Nature, 489(7415):201–
202.
Ayaz, S., Masood, N., and Islam, M. A. (2018). Predict-
ing scientific impact based on h-index. Scientomet-
rics, 114(3):993–1010.
Bai, X., Zhang, F., and Lee, I. (2019). Predicting the ci-
tations of scholarly paper. Journal of Informetrics,
13(1):407 – 418.
Bowman, S. R., Angeli, G., Potts, C., and Manning, C. D.
(2015). A large annotated corpus for learning natural
language inference. In Proceedings of the 2015 Con-
ference on Empirical Methods in Natural Language
Processing (EMNLP). Association for Computational
Linguistics.
Cao, X., Chen, Y., and Liu, K. R. (2016). A data analytic
approach to quantifying scientific impact. Journal of
Informetrics, 10(2):471 – 484.
Cohan, A., Feldman, S., Beltagy, I., Downey, D., and Weld,
D. S. (2020). Specter: Document-level representa-
tion learning using citation-informed transformers. In
ACL.
Garfield, E. and Sher, I. H. (1963). New factors in the evalu-
ation of scientific literature through citation indexing.
American Documentation, 14(3):195–201.
Hirsch, J. E. (2005). An index to quantify an individual’s
scientific research output. Proceedings of the National
Academy of Sciences, 102(46):16569–16572.
McInnes, L., Healy, J., Saul, N., and Grossberger, L. (2018).
Umap: Uniform manifold approximation and projec-
tion. The Journal of Open Source Software, 3(29):861.
Mir
´
o,
`
O., Burbano, P., Graham, C. A., Cone, D. C.,
Ducharme, J., Brown, A. F. T., and Mart
´
ın-S
´
anchez,
F. J. (2017). Analysis of h-index and other bibliomet-
ric markers of productivity and repercussion of a se-
lected sample of worldwide emergency medicine re-
searchers. Emergency Medicine Journal, 34(3):175–
181.
Reimers, N. and Gurevych, I. (2019). Sentence-bert: Sen-
tence embeddings using siamese bert-networks. In
Proceedings of the 2019 Conference on Empirical
Methods in Natural Language Processing. Associa-
tion for Computational Linguistics.
Sasaki, H., Hara, T., and Sakata, I. (2016). Identifying
emerging research related to solar cells field using a
machine learning approach. Journal of Sustainable
Development of Energy, Water and Environment Sys-
tems, 4:418–429.
Schreiber, M. (2013). How relevant is the predictive power
of the h-index? a case study of the time-dependent
hirsch index. Journal of Informetrics, 7(2):325 – 329.
Stegehuis, C., Litvak, N., and Waltman, L. (2015). Pre-
dicting the long-term citation impact of recent publi-
cations. Journal of Informetrics, 9.
Weihua Hu, Matthias Fey, M. Z. Y. D. H. R. B. L. M. C. J. L.
(2020). Open graph benchmark: Datasets for machine
learning on graphs. arXiv preprint arXiv:2005.00687.
Zhang, M. and Chen, Y. (2018). Link prediction based on
graph neural networks. In Advances in Neural Infor-
mation Processing Systems, pages 5165–5175.
WEBIST 2021 - 17th International Conference on Web Information Systems and Technologies
364
