
Towards Fast and Automatic Map Initialization for Monocular SLAM
Systems
Blake Troutman
a
and Mihran Tuceryan
b
Department of Computer and Information Science, Indiana University - Purdue University Indianapolis,
Indianapolis, U.S.A.
Keywords:
Simultaneous Localization and Mapping (SLAM), Structure From Motion, Map Initialization, Model
Selection, Monocular Vision, Stereo Vision.
Abstract:
Simultaneous localization and mapping (SLAM) is a widely adopted approach for estimating the pose of a
sensor with 6 degrees of freedom. SLAM works by using sensor measurements to initialize and build a virtual
map of the environment, while simultaneously matching succeeding sensor measurements to entries in the
map to perform robust pose estimation of the sensor on each measurement cycle. Markerless, single-camera
systems that utilize SLAM usually involve initializing the map by applying one of a few structure-from-motion
approaches to two frames taken by the system at different points in time. However, knowing when the feature
matches between two frames will yield enough disparity, parallax, and/or structure for a good initialization
to take place remains an open problem. To make this determination, we train a number of logistic regression
models on summarized correspondence data for 927 stereo image pairs. Our results show that these models
classify with significantly higher precision than the current state-of-the-art approach in addition to remaining
computationally inexpensive.
1 INTRODUCTION
Simultaneous localization and mapping (SLAM) has
become a popular approach for estimating the pose
of a sensor with respect to its environment in real
time, while simultaneously building and improving
the map. The SLAM process begins by using mea-
surements from a sensor to initialize a virtual map
of the observed environment. After the map is ini-
tialized, SLAM systems use the virtual map in cor-
respondence with the sensor measurements to repeat-
edly estimate the pose of the sensor at regular inter-
vals. This pose can either be used in conjunction with
sensor measurements to continually increase the de-
tail of the virtual map or it can be forwarded to an
external system that needs to know the current sen-
sor’s pose. This process of pose estimation is neces-
sary for both virtual reality (VR) and augmented re-
ality (AR) systems, in which a user moves a device
(often a head-mounted display or a view finder) and
expects to see a virtual world or virtual objects trans-
formed appropriately, in real time, based on the user’s
motion. The camera pose is also useful in robotics,
a
https://orcid.org/0000-0002-3809-3180
b
https://orcid.org/0000-0003-3828-6123
as it can be used as a method to localize a robot in its
environment.
This paper addresses the problem of automatically
determining the best pair of image frames to be used
in initializing the visual SLAM process. The means
of map initialization depends on the SLAM system’s
sensor configuration and whether or not markers are
used in the environment. SLAM systems that uti-
lize depth-sensing cameras or calibrated stereo cam-
era systems can initialize their virtual maps in a
markerless environment relatively quickly and easily
compared to markerless monocular (single-camera)
SLAM systems. Markerless monocular SLAM sys-
tems typically initialize their maps by sampling two
image frames at different points in time and matching
salient image features between the two images to de-
velop a set of point correspondences. After this, these
correspondences can be used to estimate the funda-
mental matrix, the essential matrix, or a homography
between the camera poses of these two images (Hart-
ley and Zisserman, 2004). These matrices can be used
to extract the camera pose of the second frame with
respect to the first, and then the correspondences can
be used with this pose estimate to triangulate the first
set of 3D map points.
22
Troutman, B. and Tuceryan, M.
Towards Fast and Automatic Map Initialization for Monocular SLAM Systems.
DOI: 10.5220/0010640600003061
In Proceedings of the 2nd International Conference on Robotics, Computer Vision and Intelligent Systems (ROBOVIS 2021), pages 22-30
ISBN: 978-989-758-537-1
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

Many of the steps of this monocular map initial-
ization process are well known; however, fast auto-
matic selection of the image pairs to use for the ini-
tialization process still remains an open problem. If
the image pairs do not have a sufficient translation
component in the camera movement or if the corre-
spondences are not sufficiently spread across the im-
ages, then the pose estimate is likely to be inaccurate
and the map initialization will cause the SLAM sys-
tem to immediately fail. This work presents a fast
approach for automatically determining if an image
pair is likely to result in an accurate reconstruction
by extracting various information from the collection
of correspondences and feeding that information to
trained logistic regression models.
1.1 Contribution
Given the problem of selecting appropriate im-
age pairs from a video sequence for visual SLAM
map initialization, previous works are too slow for
resource-limited platforms, lack robustness, only
work for non-planar scenes, or struggle in their
decision-making when observing pure rotations. This
work contributes a solution that attempts to address
all of these issues. Namely, this work contributes an
algorithm for selecting good image pairs from a video
sequence for visual SLAM map initialization that:
• is fast enough to be practical for real time use on
resource-limited platforms,
• provides decisions for both planar and non-planar
scenes,
• accurately rejects image pairs that demonstrate
pure rotational movement,
• and yields higher precision than the current state-
of-the-art approach.
2 RELATED WORK
There are a number of visual SLAM systems for real
time use that have been developed over the past sev-
eral years. MonoSLAM (Davidson et al., 2007) is the
first successful application of purely visual monocu-
lar SLAM, but its map initialization is aided by the
use of a known fiducial marker. During initialization,
markers can be used to act as a pre-existing map with
known 3D point locations. This enables the system to
accurately estimate the camera pose each frame be-
fore the system has sufficient baseline length to trian-
gulate new points into the map. Markers also enable
the system to register an accurate scale for their map
points during initialization, as demonstrated in (Xiao
et al., 2017). The use of markers is further expanded
upon in systems such as (Korah et al., 2011), (Maidi
et al., 2011), (Ufkes and Fiala, 2013), (Kobayashi
et al., 2013), and (Arth et al., 2015) which utilize fidu-
cials for pose estimation throughout the entire runtime
of the system, rather than just using them for map ini-
tialization.
Though the use of markers often makes camera
pose estimation more reliable and straightforward, it
also makes pose estimation systems less versatile, as
the systems will break down and have no reference
points to measure if the fiducial markers fall out of
frame. (Berenguer et al., 2017) proposes a SLAM
system that heavily utilizes global image descriptors
to perform localization, which frees the system from
any use of fiducial markers. However, the global im-
age descriptors used in the aforementioned work de-
pend on omnidirectional imaging and can take more
than half of a second to perform localization, mak-
ing them unsuitable for systems that require rapid,
real time tracking (such as in AR/VR systems or in
autonomous automobiles). Faster and more robust
pose estimation systems exclude the need for markers
by tracking somewhat arbitrary patches of the image
frame, without any predefined knowledge of what the
patches look like or where they should be located in
3D space (Klein and Murray, 2007), (Klein and Mur-
ray, 2009), (Sun et al., 2015), (Mur-Artal et al., 2015),
(Fujimoto et al., 2016), and (Qin et al., 2018).
Without knowledge of the 3D locations of the
tracked points, structure-from-motion (SfM) algo-
rithms are often used to aid in triangulating virtual 3D
locations for these points. For example, the PTAM
system (Klein and Murray, 2007), (Klein and Mur-
ray, 2009) is a real time visual SLAM system that
initializes its map by having the user manually se-
lect two frames (from different points in time), match-
ing FAST features (Rosten and Drummond, 2006)
between the two frames, estimating the pose differ-
ence between the frames with the 5-point algorithm
(Stewenius et al., 2006) or with a homography de-
composition (Faugeras and Lustman, 1988), and fi-
nally using the estimated pose to triangulate the point
matches into a virtual 3D map. (Sun et al., 2015)
adopts the PTAM framework for its map initialization
as well. The clear drawback of this approach is that
it is not automatic; it requires the user to select the
frames that should be used for initialization. (Huang
et al., 2017) presents an approach for map initializa-
tion that can initialize the map in a single frame with-
out user intervention, but it requires that the system
is operating inside of a typical indoor room and can
only initialize map points that coincide with the walls
of the room.
Towards Fast and Automatic Map Initialization for Monocular SLAM Systems
23

ORB-SLAM (Mur-Artal et al., 2015) also utilizes
SfM techniques to initialize its map, but it addition-
ally implements an automated approach for select-
ing the frames to use for initialization while main-
taining comparable versatility to PTAM. ORB-SLAM
achieves this automatic frame selection by estimat-
ing both a homography and a fundamental matrix for
the current frame against the initial frame using the
normalized DLT algorithm and the 8-point algorithm,
respectively, both of which are explained in (Hart-
ley and Zisserman, 2004). It then uses a heuristic
to assess the success of each model estimate— if the
heuristic indicates that neither model estimate is ac-
curate, then the system repeats this process on subse-
quent frames until at least one of the models appears
to provide an accurate pose estimate. This approach,
however, is computationally expensive and unsuitable
for resource-limited platforms such as mobile phones.
There are modified versions of ORB-SLAM, some of
which aim to revise the map initialization process (Fu-
jimoto et al., 2016), but stray from monocular SLAM
by requiring RGB-D data.
Given the high computational cost of ORB-
SLAM’s approach to automatic frame selection, it
would be desirable for a SLAM system to include
some algorithm that can select an appropriate pair
of frames for its SfM-based map initialization much
more quickly. There are relatively few works that
have presented such an algorithm. A work by Tomono
(Tomono, 2005), which predates many of the visual
SLAM systems in the literature, presents an approach
for detecting degeneracy in a potential fundamental
matrix estimate before a system would need to per-
form the 8-point algorithm. However, this approach
is only applied to fundamental matrix estimates, it
does not distinguish between degeneracy caused by
insufficient translation and degeneracy caused by pla-
nar scenes (which could still be useful for a homog-
raphy estimate), and the threshold parameter used is
dependent upon the number of correspondences, mak-
ing this approach less robust for real use. VINS-Mono
(Qin et al., 2018), a visual-inertial SLAM system, uti-
lizes a simpler frame selection approach in which the
system chooses to attempt initialization with a pair of
frames if it is able to track more than 30 features be-
tween them with each correspondence yielding a dis-
parity of at least 20 pixels. A later SLAM system
(Butt et al., 2020) implements a similar approach to
that used in VINS-Mono, but utilizes the median and
standard deviation of correspondence pixel disparities
to additionally select whether a homography estimate
is appropriate or if a fundamental matrix estimate is
appropriate. However, both of these systems are still
dependent on an evaluation of the estimated model
accuracy to reject erroneous initial estimates and they
also give an incorrect decision under pure rotational
movements.
3 METHODS
3.1 Structure-from-Motion (SfM)
Approaches
The goal of stereo SfM methods is to both derive
the transformation between two camera poses and to
project image data back into 3 space using the derived
pose transformation. The cameras are modeled using
a pinhole camera model,
x = K[R|t]X (1)
where x is a homogeneous 2D projection of the
homogeneous 3D point X, R is the 3×3 rotation ma-
trix of the viewing camera, t is column vector of the
translation of the viewing camera, and K is the cam-
era intrinsics matrix, defined by
K =
f s c
x
0 f c
y
0 0 1
(2)
where f is the camera’s focal length, s is the
skew (zero in our implementation), and c
x
and c
y
are
the image center coordinates. It is assumed that the
first camera is at the origin with no rotation, [I|0],
so [R|t] represents the extrinsic camera parameters of
the second viewing camera, i.e., the transformation of
the pose from the first camera to the second camera.
These extrinsic parameters are derived by estimating
the fundamental matrix, the essential matrix, or a ho-
mography between the two views.
Given two views of the same scene from differ-
ent camera viewpoints, epipolar geometry can be used
to determine the transformation from the first cam-
era’s pose to the second camera’s pose. Epipolar ge-
ometry refers to the property of stereo image projec-
tion in which 3D points observed in one view can
be constrained to unique epipolar planes in 3 space,
each of which intersects with the baseline of the cam-
eras. These planes can then be projected into the other
view as epipolar lines. Each of these lines intersects
with the corresponding projection of the respective
3D point that was observed in the first view. The fun-
damental matrix of two views is a 3×3 matrix which
encodes this constraint for all points projected in the
two views. Specifically, this constraint takes the form
of
ROBOVIS 2021 - 2nd International Conference on Robotics, Computer Vision and Intelligent Systems
24

x
0T
Fx = 0 (3)
where F is the 3×3 fundamental matrix of the two
views, and x and x
0
are homogeneous 3×1 column
vectors of the projections of a 3D point in the first
view and second view, respectively.
If the intrinsic camera parameters are known for
both views, then the fundamental matrix can be trans-
formed into the corresponding essential matrix with
E = K
0T
FK (4)
where K and K
0
are the camera intrinsic matrices
for the first view and second view, respectively.
The extrinsic camera parameters [R|t] of the sec-
ond view are extracted from the essential matrix by
using the singular value decomposition of E and a
single correspondence pair to test for cheirality (the
constraint that dictates that points viewed by a cam-
era must fall in front of the camera). This process is
explained in detail in (Hartley and Zisserman, 2004).
The fundamental matrix is solved with eight or
more image point matches by re-formulating the con-
straint in Equation 3 into a set of linear equations.
This approach is known as the 8-point algorithm. The
essential matrix is solved using a more complex ap-
proach known as the 5-point algorithm, described in
(Nist
´
er, 2003).
Additionally, the transformation from one pose
to another can be described with a homography, H,
which is a 3×3 matrix that represents the projective
transformation from one image point to its projection
in another image. Namely, a homography is a matrix
for a pair of views such that
Hx = x
0
(5)
where x and x
0
are homogeneous vectors repre-
senting 3D points in the first view and second view,
respectively. A homography between two views is es-
timated with four or more image matches using the di-
rect linear transformation method, explained in (Hart-
ley and Zisserman, 2004). The extrinsic camera pa-
rameters are then extracted from the homography us-
ing the approach described in (Faugeras and Lustman,
1988).
Visual SLAM systems often estimate either the
fundamental matrix, the essential matrix, or a homog-
raphy between two frames of the video feed to initial-
ize their maps. The 8-point algorithm can accurately
estimate the fundamental matrix in image pairs where
there is complex structure in the corresponding fea-
ture points; however, the 8-point algorithm struggles
when the projected points are coplanar in 3 space. In
contrast, homographies can be estimated with copla-
nar points to yield highly-accurate poses, but their ac-
curacy degrades if the points are not coplanar. The
5-point algorithm that estimates the essential matrix
can be accurate for both coplanar points and non-
coplanar points, but it often yields poses that are less
precise than those that are achieved with the 8-point
algorithm or 4-point DLT algorithm. To utilize these
SfM approaches, we use the corresponding OpenCV
(Bradski, 2000) implementations for each algorithm.
3.2 Model Configuration
This approach utilizes four logistic regression models
for decision-making. Each model takes in correspon-
dence data as input and answers a different question
regarding the data’s likelihood of resulting in a good
map initialization. Specifically, the models aim to an-
swer the following questions:
• Model F: Would estimating the fundamental ma-
trix (via 8-point algorithm) be a good approach for
initializing the SLAM map with this correspon-
dence data?
• Model E: Would estimating the essential matrix
(via 5-point algorithm) be a good approach for ini-
tializing the SLAM map with this correspondence
data?
• Model H: Would estimating a homography (via 4-
point DLT algorithm) be a good approach for ini-
tializing the SLAM map with this correspondence
data?
• Model R: Is this correspondence data the result
of a pure rotation (no translation in camera move-
ment)?
Each model provides an output of 1 if the answer
to its respective question is “yes” and 0 if the an-
swer is “no.” In practice, a SLAM system could uti-
lize these models for map initialization in real time
by continuously evaluating each frame against a ref-
erence frame taken at a previous point in time. For
example, the first frame that is registered upon the
system’s activation could be considered the reference
frame, and then, each frame afterward could be paired
with this reference frame and the pair could be tested
against these models. When at least one of the models
predicts that the two frames in question are sufficient
for SfM estimation, the corresponding SfM approach
is used to initialize the map with the related corre-
spondences.
Additionally, all four models take the same 23 fea-
tures as inputs. The features consist of data pertaining
to the correspondences between the image pairs be-
ing evaluated. A correspondence is defined as a 2D-
to-2D keypoint match between two images and con-
sists of two image points, defined as p
0
= (x
0
, y
0
) and
p
1
= (x
1
, y
1
), where p
0
is a point in the first image
Towards Fast and Automatic Map Initialization for Monocular SLAM Systems
25

and p
1
is its matching location in the second image.
We define the pixel disparity of a correspondence as
the euclidean distance between its p
0
and p
1
values.
Specifically, the features used include the num-
ber of correspondences, the mean and standard devia-
tion of the pixel disparities, the minimum and max-
imum values of each component of the correspon-
dences (x
0
, x
1
, y
0
, and y
1
), and the range of each com-
ponent of the correspondences. Additionally, we in-
clude eight features that each represents the propor-
tion of correspondences that approximately yield a
specific angle. We calculate a correspondence’s an-
gle, θ, as
θ = arctan
y
1
− y
0
x
1
− x
0
(6)
where (x
0
, y
0
) is the point in the first image and
(x
1
, y
1
) is the corresponding point in the second im-
age. The angles included in these eight features sim-
ply cover 8 evenly distributed angles between 0°and
360°.
3.3 Model Training
Models are trained on data that is derived from
the fr3/structure texture far RGB-D dataset from the
Technical University of Munich (Sturm et al., 2012).
This dataset consists of an RGB video of textured pa-
pers on the ground with a poster sitting upright behind
the papers, bent in a zig-zag fashion to produce struc-
ture. Throughout the video, the camera demonstrates
both rotational and translational movements, mostly
moving to the left and rotating to keep the objects in
frame. For model training, the video is split up into
batches of 90-frame sequences. For each batch, ev-
ery frame is paired with the first frame in the batch
to form a stereo image pair. We use the KLT optical
flow algorithm (Shi and Tomasi, 1994), (Lucas and
Kanade, 1981) to track approximately 150 to 300 fea-
tures each frame. This optical flow approach allows
the resulting correspondences to be free of significant
outliers. After collecting these correspondences on
each stereo image pair, we estimate the pose of the
second camera with respect to the first using the 8-
point algorithm, 5-point algorithm, and 4-point DLT
algorithm. This provides us with three different pose
estimates, each of which is used to judge the success
of the respective approach on the stereo image pair
by using the ground truth pose data provided in the
dataset.
We find that two error metrics are good descriptors
of successful pose estimates. These metrics include
the normalized translational chordal distance and the
median scaled reconstruction error. The normalized
translational chordal distance, E
t
, is defined by
E
t
= kt
g
− t
e
k
F
(7)
where t
g
and t
e
are the normalized translation vec-
tors of the ground truth pose and the estimated pose,
respectively, and E
t
is the Frobenius norm of their dif-
ference. The median scaled reconstruction error, E
R
,
is defined by
E
R
=
∑
n
i
kP
g
i
− sP
e
i
k
F
n
(8)
where P
g
is a 3D ground truth point, P
e
is the cor-
responding 3D point that was triangulated from the
estimated pose, and n is the number of correspon-
dences. Additionally, this metric includes a scale fac-
tor, s, which is defined by
s =
kP
g
0
− P
g
1
k
F
kP
e
0
− P
e
1
k
F
(9)
where s can be described as the ratio of the dis-
tance between the first two points of the ground truth
to the distance between the corresponding triangu-
lated points. This scale factor allows us to correct for
scale ambiguity in the map generation.
These error metrics are used to aid in generating
labels for the training data. As the baseline between
the cameras increases in these tests, both of these er-
ror metrics show a rapidly decreasing error followed
by a plateau at some baseline length on most of the
batches, as shown in Figure 1. Using this trend,
thresholds for each error metric are selected empir-
ically. We determine that a pose estimate could be
considered suitable for SLAM initialization if its nor-
malized translational chordal distance was less than
0.8 and its median scaled reconstruction error is less
than 1. This results in the following labelling criteria:
label(I) =
(
1 E
t
< 0.8 and E
R
< 1
0 otherwise
(10)
where I is a set of correspondences for a stereo
image pair.
For Model R, the classifier that predicts when cor-
respondences are the result of a pure rotation, we sim-
ply use the ground truth data to determine the baseline
length and consider the label to be 0 when the baseline
length exceeds 0.05 and 1 otherwise.
In total, the training data consists of the correspon-
dence data from 927 different stereo image pairs.
ROBOVIS 2021 - 2nd International Conference on Robotics, Computer Vision and Intelligent Systems
26
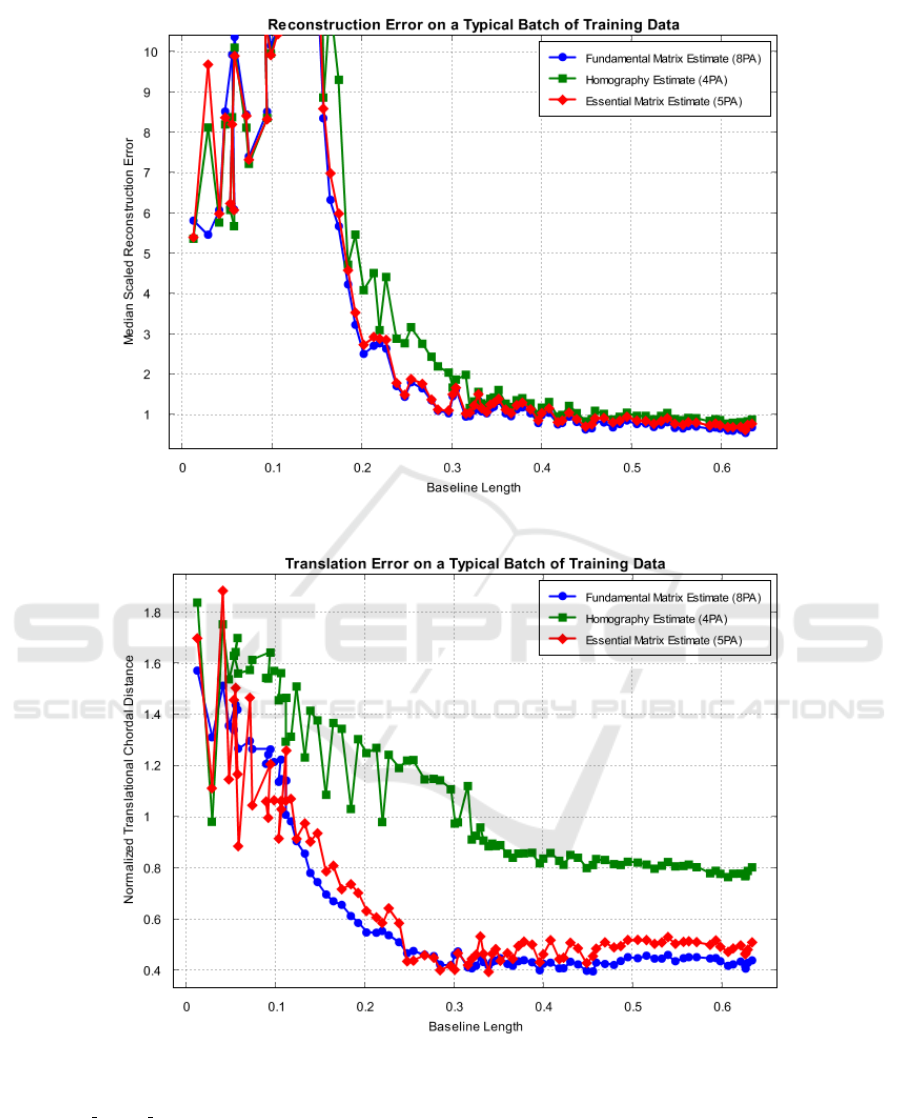
(a) Median Scaled Reconstruction Error
(b) Normalized Translational Chordal Distance
Figure 1: Error metrics for pose estimates of SfM approaches on a typical batch of training data generated from
fr3/structure texture far. (a) is the median scaled reconstruction error as the baseline increases throughout the batch. (b)
is the normalized translational chordal distance as the baseline increases throughout the batch. As the ground truth baseline
increases, both error metrics show a rapid decrease followed approximately by a plateau on each SfM approach. Correspon-
dence sets are considered sufficient for SLAM initialization with a given SfM approach if both errors fall on the plateaus.
Note that the median scaled reconstruction error in (a) is unstable at low baselines and may have an error upwards of 10
3
(which is cut off here to show the more general pattern).
Towards Fast and Automatic Map Initialization for Monocular SLAM Systems
27

4 EXPERIMENTAL RESULTS
To evaluate model performance, we construct a test
set from the fr3/structure texture near dataset, also
provided by (Sturm et al., 2012). This dataset is sim-
ilar to the fr3/structure texture far dataset, as it is a
video of the same scene; however, it is a much more
challenging dataset for SfM as the camera is closer to
the objects. This causes keypoints to move off-frame
more quickly and also leads to a far less homogeneous
distribution of keypoints in many parts of the video.
The test set is derived in the same fashion as the train-
ing set, where the video is split into several batches
and each frame is paired with the first frame of its re-
spective batch. Due to keypoints moving off-frame
more quickly in this set, we only use batches of 30
frames instead of 90. The resulting test set consists of
correspondence data for 1,062 different stereo image
pairs.
Each classifier is able to run inference on the en-
tire test set in approximately 1 millisecond, which
demonstrates the high speed of this approach and
its real time viability, even for resource-limited plat-
forms. The accuracy, precision, recall, and F1 score
for each of the classifiers is shown in Table 2.
For comparison, we also evaluate the current state-
of-the-art approach, which involves purely evaluating
the mean/median and standard deviation of pixel dis-
parities in the correspondences to make the classifi-
cation. In this comparison, we utilize the thresholds
used in (Butt et al., 2020), where the correspondences
are considered suitable for homography estimation if
the median disparity is above 50 pixels and are con-
sidered suitable for fundamental matrix estimation if,
additionally, the standard deviation of the disparities
is above 15 pixels. The results for the state-of-the-art
approach are shown in Table 1.
The precision of the classifiers is the most im-
portant metric here, as false positives would lead to
a SLAM system attempting to initialize under poor
conditions and may cause the system to perform a
high amount of wasted computation and/or initialize
with a corrupted map. The logistic regression models
for the fundamental matrix approach and homography
approach both yield higher precision than the current
state-of-the-art classification algorithm. Specifically,
the precision for the fundamental matrix approach in-
creased from 0.0811 in the state-of-the-art approach
to 0.3639 in the logistic regression model, and the pre-
cision for the homography approach increased from
0.2852 in the state-of-the-art approach to 0.3725 in
the logistic regression model. The logistic regres-
sion model for the homography approach has a signif-
icantly worse recall than the state-of-the-art approach
(dropping from 0.4601 to 0.1166), though this is less
crucial as it indicates a higher proportion of false neg-
atives rather than false positives.
Additionally, we evaluate the models’ perfor-
mance after filtering the samples with the pure rota-
tion classifier (Model R). When a sample is detected
to be the result of a pure rotation, its label is automat-
ically set to 0, i.e., unsuitable for map initialization.
Otherwise, the sample is passed on to the other mod-
els for prediction. The results of this approach are
displayed in Table 3.
Using the rotation classifier as a preliminary
model to immediately reject samples that do not yield
sufficient baseline increases the precision of Model F
from 0.3639 to 0.4370 and increases the precision of
Model E from 0.4290 to 0.5041. This approach also
decreases the precision of Model H from 0.3725 to
0.3600. In practice, however, this approach of using
the rotation classifier for early rejection does not need
to be used for all models—it can be utilized for only
Model F and Model E if those are the only models
that are improved by this alteration.
5 CONCLUSIONS AND FUTURE
WORK
In this paper, we have presented an approach for
quickly predicting the success of SfM techniques
on an arbitrary set of image point correspondences
through the use of logistic regression models. The
models used in this paper yield significantly higher
precision than the current state-of-the-art approach
without having to perform the computationally-
expensive SfM techniques before making their deter-
minations. The model features used are also very
quick to calculate, making this approach viable for
real time performance on resource-limited platforms.
This work may further be validated by implement-
ing it in a real time visual SLAM system and evalu-
ating the system’s stability. Additionally, the models
may be improved by labelling the training data us-
ing a more robust evaluation criterion. Rather than
using empirical thresholds for the normalized transla-
tional chordal distance and median scaled reconstruc-
tion error, perhaps ORB-SLAM’s (Mur-Artal et al.,
2015) heuristic approach could provide a more ac-
curate scheme for labelling the training/testing data.
The models’ performance may also be improved if
they are expanded into neural networks and trained
on more scenes.
ROBOVIS 2021 - 2nd International Conference on Robotics, Computer Vision and Intelligent Systems
28
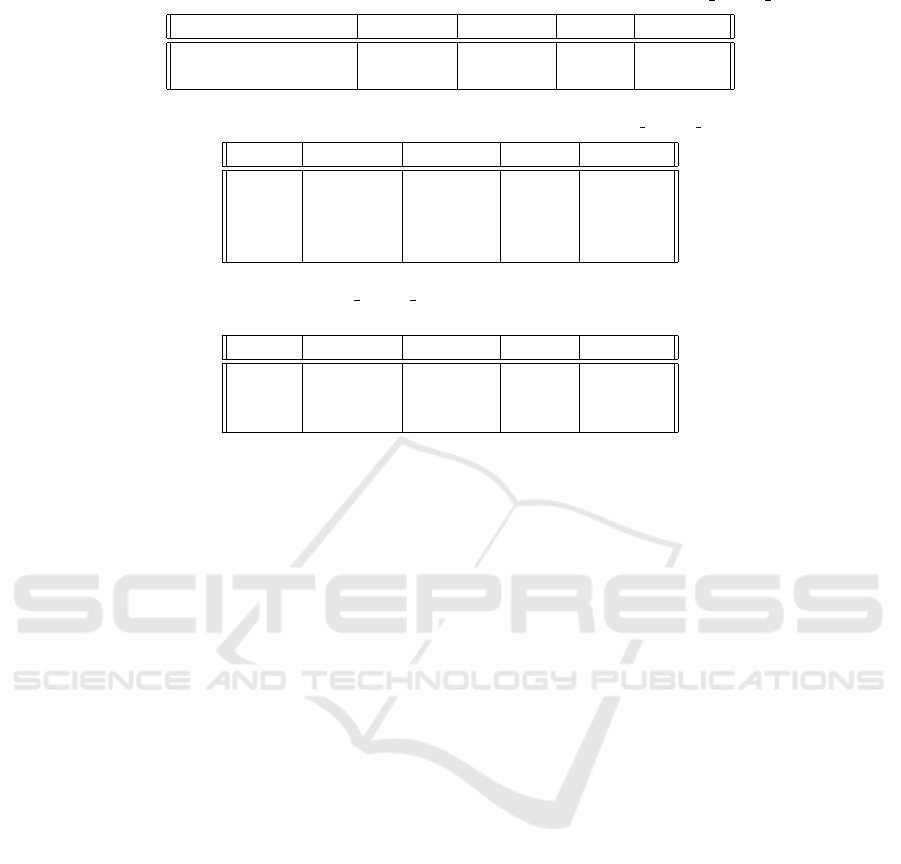
Table 1: Performance of the current state-of-the-art classification approach on the fr3/structure texture near test data.
Classification Accuracy Precision Recall F1 Score
Fundamental Matrix 0.7589 0.0811 0.0133 0.0229
Homography 0.7401 0.2852 0.4601 0.3521
Table 2: Performance of each logistic regression model on the fr3/structure texture near test data.
Model Accuracy Precision Recall F1 Score
F 0.6959 0.3639 0.5822 0.4479
E 0.7326 0.4290 0.6453 0.5154
H 0.8343 0.3725 0.1166 0.1776
R 0.8380 0.6091 0.9302 0.7362
Table 3: Model performance on the fr3/structure texture near test data after using Model R as a preliminary classifier to aid
in classification.
Model Accuracy Precision Recall F1 Score
F 0.7598 0.4370 0.4622 0.4492
E 0.7815 0.5041 0.5256 0.5146
H 0.8399 0.3600 0.0552 0.0957
REFERENCES
Arth, C., Pirchheim, C., Ventura, J., Schmalstieg, D.,
and Lepetit, V. (2015). Instant Outdoor Localiza-
tion and SLAM Initialization from 2.5D Maps. IEEE
Transactions on Visualization and Computer Graph-
ics, 21(11):1309–1318.
Berenguer, Y., Pay
´
a, L., Peidr
´
o, A., and Reinoso, O. (2017).
Slam algorithm by using global appearance of omnidi-
rectional images. In Proceedings of the 14th Interna-
tional Conference on Informatics in Control, Automa-
tion and Robotics - Volume 2: ICINCO,, pages 382–
388. INSTICC, SciTePress.
Bradski, G. (2000). The OpenCV Library. Dr. Dobb’s Jour-
nal of Software Tools.
Butt, M. M., Zhang, H., Qiu, X. C., and Ge, B. (2020).
Monocular SLAM Initialization Using Epipolar and
Homography Model. 2020 5th International Confer-
ence on Control and Robotics Engineering, ICCRE
2020, pages 177–182.
Davidson, A. J., Reid, I. D., Molton, N. D., and Stasse,
O. (2007). MonoSLAM: Real-Time Single Camera
SLAM. IEEE Transactions on Pattern Analysis and
Machine Intelligence, 29(6):1052–1067.
Faugeras, O. and Lustman, F. (1988). Motion and Struc-
ture From Motion in a Piecewise Planar Environment.
International Journal of Pattern Recognition and Ar-
tificial Intelligence, 02.
Fujimoto, S., Hu, Z., Chapuis, R., and Aufr
`
ere, R. (2016).
Orb slam map initialization improvement using depth.
2016 IEEE International Conference on Image Pro-
cessing (ICIP), pages 261–265.
Hartley, R. and Zisserman, A. (2004). Multiple View Geom-
etry in Computer Vision. Cambridge University Press,
2 edition.
Huang, J., Liu, R., Zhang, J., and Chen, S. (2017). Fast
initialization method for monocular slam based on in-
door model. In 2017 IEEE International Conference
on Robotics and Biomimetics (ROBIO), pages 2360–
2365.
Klein, G. and Murray, D. (2007). Parallel Tracking and
Mapping for Small AR Workspaces. 2007 6th IEEE
and ACM International Symposium on Mixed and
Augmented Reality, pages 225–234.
Klein, G. and Murray, D. (2009). Parallel tracking and map-
ping on a camera phone. 2009 8th IEEE International
Symposium on Mixed and Augmented Reality, pages
83–86.
Kobayashi, T., Kato, H., and Yanagihara, H. (2013). Novel
keypoint registration for fast and robust pose detec-
tion on mobile phones. Proceedings - 2nd IAPR
Asian Conference on Pattern Recognition, ACPR
2013, pages 266–271.
Korah, T., Wither, J., Tsai, Y. T., and Azuma, R. (2011).
Mobile augmented reality at the hollywood walk of
fame. 2011 IEEE Virtual Reality Conference, pages
183–186.
Lucas, B. D. and Kanade, T. (1981). An iterative image
registration technique with an application to stereo vi-
sion. In Proceedings of the 7th International Joint
Conference on Artificial Intelligence - Volume 2, IJ-
CAI’81, page 674–679, San Francisco, CA, USA.
Morgan Kaufmann Publishers Inc.
Maidi, M., Preda, M., and Le, V. H. (2011). Markerless
tracking for mobile augmented reality. 2011 IEEE In-
ternational Conference on Signal and Image Process-
ing Applications, ICSIPA 2011, pages 301–306.
Mur-Artal, R., Montiel, J. M., and Tardos, J. D. (2015).
ORB-SLAM: A Versatile and Accurate Monocular
SLAM System. IEEE Transactions on Robotics,
31(5):1147–1163.
Towards Fast and Automatic Map Initialization for Monocular SLAM Systems
29

Nist
´
er, D. (2003). An Efficient Solution to the Five-Point
Relative Pose Problem. 2003 IEEE Computer Society
Conference on Computer Vision and Pattern Recogni-
tion, 2003. Proceedings., 2:II–195.
Qin, T., Li, P., and Shen, S. (2018). VINS-Mono: A Ro-
bust and Versatile Monocular Visual-Inertial State Es-
timator. IEEE Transactions on Robotics, 34(4):1004–
1020.
Rosten, E. and Drummond, T. (2006). Machine learning
for high-speed corner detection. Computer Vision –
ECCV 2006, pages 430–443.
Shi, J. and Tomasi, C. (1994). Good Features to Track. 1994
Proceedings of IEEE Conference on Computer Vision
and Pattern Recognition.
Stewenius, H., Engels, C., and Nister, D. (2006). Re-
cent Developments on Direct Relative Orientation. IS-
PRS Journal of Photogrammetry and Remote Sensing,
60:284–294.
Sturm, J., Engelhard, N., Endres, F., Burgard, W., and Cre-
mers, D. (2012). A benchmark for the evaluation of
rgb-d slam systems. In Proc. of the International Con-
ference on Intelligent Robot Systems (IROS).
Sun, L., Du, J., and Qin, W. (2015). Research on combi-
nation positioning based on natural features and gyro-
scopes for AR on mobile phones. Proceedings - 2015
International Conference on Virtual Reality and Visu-
alization, ICVRV 2015, pages 301–307.
Tomono, M. (2005). 3-D localization and mapping using
a single camera based on structure-from-motion with
automatic baseline selection. Proceedings - IEEE In-
ternational Conference on Robotics and Automation,
pages 3342–3347.
Ufkes, A. and Fiala, M. (2013). A markerless augmented
reality system for mobile devices. Proceedings - 2013
International Conference on Computer and Robot Vi-
sion, CRV 2013, pages 226–233.
Xiao, Z., Wang, X., Wang, J., and Wu, Z. (2017). Monocu-
lar ORB SLAM based on initialization by marker pose
estimation. 2017 IEEE International Conference on
Information and Automation, ICIA 2017, (July):678–
682.
ROBOVIS 2021 - 2nd International Conference on Robotics, Computer Vision and Intelligent Systems
30
