
Sarcasm Detection from Social Media Posts using Machine-learning
Techniques: A Comparative Analysis
Mariya Siddiqui, Rajnish Pandey, Shobhit Srivastava, Ramapati Mishra, Nalini Singh
IET, Dr RLAU Ayodhya, UP, India
Keywords: Social Media, Sarcasm, Hinglish, Feelings and Machine learning classifiers.
Abstract: Social media is a platform where everyone from each age group is interested in posting their daily activities.
A customer, post reviews about a product he bought, a person who is a victim of some natural disasters, post
their current situations, and in other scenarios too, the people use these social media platforms to post their
feelings. Getting the correct sentiments of these posts is one of the most challenging tasks ever. The
presence of a sarcastic tweet may hinder the texts' actual meaning. In this paper, we have collected sarcastic
tweets from Twitter and validated this Dataset with the help of different conventional machine learning
classifiers. The support vector machine performed better and achieved an F1-score of 0.84.
1 INTRODUCTION
In recent years, social media such as Twitter,
Facebook, Instagram, etc., have been used widely
across the world. People digitally meet and share
their thoughts, opinions, places and are immersed in
several debates [20]. For several uses, such as
sentiment analysis, assessing the authors' content,
these data must be analysed. Many more are
essential to understand the writer's emotions that
complement details on platforms mentioned above
as these data will inspire the crowd.
Emotions are polymorphic, fluctuating from
confounding to annoying to disgusting or unfocused.
Studying people's feelings and their sources is a
study among psychologists. Moods have a critical
influence on one's actions that would affect not only
their lives but also others. Mindsets refer to
emotions and concentrate mainly on decision and
thinking. That is why opinions are reluctant about
being intimate. Many people refer to emotions as a
standard way of responding to desire, need, pain,
and dislike. The sentiment is a feeling that
influenced by a decision or thought. There are
several online forms, ranging from short character
data such as tweets to long character data such as
debates. Producing trillions of tweets and re-tweets,
Twitter, a trending social network, provides a vast
amount of data to grasp the meaning of Sarcasm. In
sentiment analysis, Sarcasm plays a vital role, and
researchers are using this attitude these days to
understand an individual's emotions.
Sarcasm is not used only for jokes but also for
criticizing other people, opinions, concepts, etc. As a
motive of which irony is very much on Twitter. For
example, -' I loved being ignored.' Here, in adverse
settings, "love" displaces a pleasant emotion. This
tweet is, therefore, denoted as sarcastic. It's also
complicated to evaluate sarcastic tweets. This paper
discusses the various machine learning methods for
identifying sarcastic sentences posted by Twitter
users in English messages, their characteristics,
measures, data set generation, and scope . The
following work will be carried out by us in this
study and summarized in the following sections:
- For sarcasm identification, we are studying
various traditional classification techniques.
- Output judgement of each conventional sarcasm
detection classifier.
- Sarcasm Detection Analysis in English Sentences
and Findings.
Various traditional machine learning classifiers
such as Support Vector Machine (SVM), Random
Forest (RF), Decision Tree (DT), K-Nearest
Neighbour (KNN), Logistic Regression (LR), Naïve
Bayes (NB) and Gradient Boosting (GB) for textual
Dataset sarcasm detection will be highly cooperative
throughout this effort. The remaining sections of this
paper are arranged as follows: the related work is
summarized in Section II; Section III defines Dataset
along with the proposed approach. Section IV
28
Siddiqui, M., Pandey, R., Srivastava, S., Mishra, R. and Singh, N.
Sarcasm Detection from Social Media Posts using Machine-learning Techniques: A Comparative Analysis.
DOI: 10.5220/0010561900003161
In Proceedings of the 3rd International Conference on Advanced Computing and Software Engineering (ICACSE 2021), pages 28-33
ISBN: 978-989-758-544-9
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

decrypt results for sarcasm detection, and Section V
dictates the discussion portion and, Section VI
concludes with the framework of future reports.
2 RELATED WORK
Sarcasm is one of the foremost well-liked types of
act opinions and thoughts on social media. In the
past, several folds have been inhabited by the
amount of satirical material on well-liked social
networking platforms such as Twitter and Facebook.
It's a crucial result of sentiment analysis; however, it
is usually left because of its challenging nature.
Heaps of research has been occurring, and several
many other models are planned to detect sarcasm.
Jain et al. thought of Sarcasm as a contrast
between optimistic emotions and adverse
circumstances. They used a special bootstrapping
algorithmic rule for companies for positive and
negative sentences. They used tweets containing
'#sarcasm' for the machine learning-based classifier
training and applied them to Naïve Bayes SVM and
achieved an accuracy of 83.1 %. Lunando et al. have
taken into account one in every of the foremost
severe downside in sentiment analysis. They found
that individuals prefer to criticize the one-factor use
of Sarcasm as the expected issue on social media.
The characteristics are the data on negativity and the
set of terms for interjection. The sentiment grouping
extensively used translated SentiWordNetAll the
classification was carried out with algorithms for
machine learning.
The experimental results showed that the extra
features are very realistic in sarcasm detection. A
pattern-based approach to Sarcasm notification on
the Twitter dataset is suggested by Bouazizi et al..
They present four sets of options covering the cowl's
various forms of irony. To define tweets as sarcastic
and non-sarcastic, they use those choices. Their
proposed solution achieves an accuracy of 83.1 %
with an accuracy equivalent to 91 %. Bouazizi et al.
are our methodology products until all the features
are used. The precision and accuracy are greater than
90 % each during cross-validation. The accuracy
obtained reaches 72 %, with precision more
significant than 73 % before the enrichment of the
patterns. The enrichment method augmented the
methodology with a lot of promise and greatly
improved the classification accuracy. Compared
there, the accuracy was also improved though not
enrichment.
On the other hand, a lower value is included in
Recall but still higher than before enrichment. This
indicates that most of the sarcastic tweets are not
very well categorised. Parmar et al.identified that
sarcasm detection might be difficult because of no
predefined structure present. By offering various
algorithms, researchers are improving the accuracy
of sarcasm detection. To detect Sarcasm, he planned
algorithms that combine lexical and hyperbole
characteristics and recognize three forms of irony I
Conflict between the negative state of affairs and
positive feelings (ii) Conflict between favourable
circumstance and negative emotion (iii) occurrence
of words of interjection. He proposes an algorithm
that also considers punctuation-related features to
boost pre-punctuation.
Various authors consider different elements and
approaches to enhance the method's consistency.
Two ways are mainly available: (1) Machine
learning (2) Rule-based technique. Machine learning
may be a research technique that forms a model that
predicts, prepares, or classifies information through
the statistical method. Meanwhile, in any language,
such as phrase pattern, lexical, and hyperbole
attributes, a rule-based approach can be a technique
that utilizes textual, syntactic, and rhetorical
properties of sentences to evaluate a sentence's
feelings. Tweets that have been pre-processed and
tokenized to derive frequency and emotion-based
features are used by Kanwar et al. These features are
used to define Sarcasm using the classifier voted.
The suggested approach's F1-score is 0.807, and the
top-ranking method developed has a 0.037 F1-score.
Dave et al. attempted to classify supervised
classification methods primarily to identify Sarcasm
and its characteristics. The classification techniques
were also evaluated on textual datasets accessible on
review-related social media sites in different
languages. Besides, the selection procedure used for
each tool studied includes features. He also
performed preliminary experiments to classify
sarcastic sentences in the language of "English"
With basic Bag-Of-Words as characteristics and TF-
IDF as a frequency measure. He trained the SVM
classifier with 10X validation. He found that 50 %
of sarcastic sentences was graded by this simple
model based on "bag-of-words" feature precision.
Saha et al.used sarcasm detection and analysis of
Twitter, providing an opinion about public pot, the
polarity of tweets used RapidMiner. A total of 2,250
tweets were used to calculate the accuracy by Naïve
Bayes and SVM, which produced an accuracy of
65.2% and 60.1%, respectively. Thus, relative to the
SVM classifier, Naïve Bayes has more precision.
Gupta et al. used an approach, and with the Support
Vector Machine (SVM) algorithm, which is
Sarcasm Detection from Social Media Posts using Machine-learning Techniques: A Comparative Analysis
29

equivalent to 74.59 %, the highest accuracy is
achieved. In the second method, the voting classifier
reaches the highest accuracy, and it raises the
accuracy to 83.53 %.
Table: 1 Some potential work on Sarcasm
S.NO AUTHOR FEATURES MODEL PER.
1. Jain et al.
[1]
N-gram SVM Acc-
83.1%
2. Lunando et
al. [2]
Unigram
Negation
Word Context
Negativity
SVM Acc-
77.4%
3. Bouazizi et
al. [3]
N-gram SVM Acc-
83.1%
4. Bouazizi et
al. [4]
N-gram Naïve
Bayes
SVM
Acc-
87.00%
5. Parmar et al.
[5]
Lexical
Hyperbole
SVM Acc-
82.8%
6. Kanwar et
al. [6]
Tf-idf SVM
LR
F1-score
.037
7. Dave et al.
[7]
Tf-idf SVM Acc-
50.0%
8. Saha et al.
[8]
Uni-gram
Bi-gram
N-gram
Naïve
Bayes
SVM
Acc-
65.2%
9. Gupta et al.
[9]
Tf-idf SVM Acc-
74.59%
3 DATASET
3.1 Data Collection
To collect sarcastic tweets, we tend to extract tweets
containing hashtags #sarcasm and #irony using the
Twitter hand tool API and manually choose English
code-mixed tweets from them. We tend to use
alternative keywords like 'Bollywood', 'cricket' and
'politics' to gather sarcastic tweets from these
domains. Out of those collected tweets, sarcastic and
non-sarcastic tweets square measure additional
manually separated. To gather additional non-
sarcastic tweets, we tend to extract tweets with
keywords like 'Bollywood', 'cricket' and 'politics'
that don't contain hashtags #sarcasm #irony.
Additional English code-mixed tweets are manually
selected from them. Having solely sarcastic or only
non-sarcastic tweets from an existing domain might
result in an associate degree unbiased system, so we
tend to certify that their square measure each
sarcastic and non-sarcastic tweets from every
profession.
3.2 Data Processing and Annotation
Tweets are annotated by a group of persons fluent in
English. Every tweet is manually annotated for the
presence of Sarcasm. Tweets are then tokenized, and
each token is annotated with a manually verified
language.
3.3 Sarcasm Annotation
Each tweet is manually annotated for the presence of
Sarcasm using the tags' YES' and 'NO'. Tweets with
the hashtags #sarcasm and #irony are many
possibilities to contain irony. Tweets that do not
contain these hashtags are manually verified to
contain Sarcasm.
An example of a tweet that contains Sarcasm:
Tweet: I loved being ignored!! #Sarcasm !!YES
Tweet: "When you don't win games, yeah, you lose
confidence. That's normal."!! #Sarcastic !!NO
3.4 Data Description
We have collected 13,882 tweets from different
users posted in the previous six months (May 2020
to October 2020). Out of that, 6382 tweets are
levelled as sarcastic, and 7500 tweets are levelled as
non-sarcastic; the detailed description of this Dataset
can we have seen from the table:2
Table: 2 Dataset description
Class User collected Dataset
Sarcastic 6,382
Non- Sarcastic 7,500
Total 13,882
3.5 Sarcasm Detection
The system we present a baseline classification
system for sarcasm detection in English code-mixed
tweets using various word-based and character-
based features. We tend to run and compare multiple
machine learning models that use these features to
detect Sarcasm.
ICACSE 2021 - International Conference on Advanced Computing and Software Engineering
30
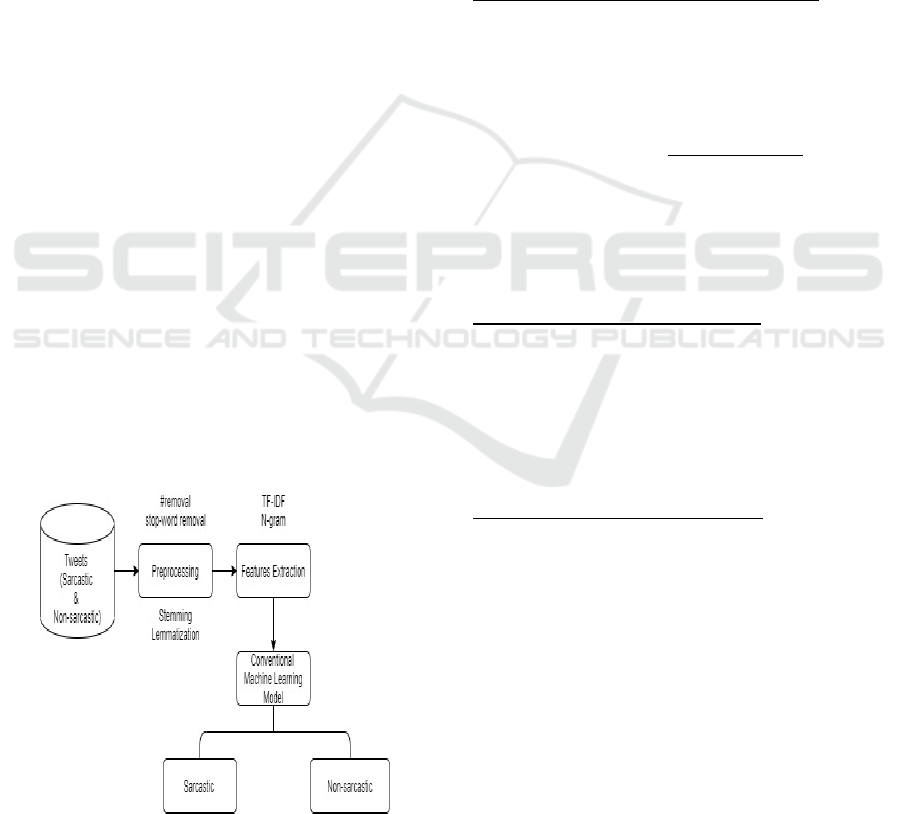
3.6 Pre-processing
It is typical to follow social media to use even-toed
ungulate cases, whereas writing hashtags. Therefore,
we tend to extract the hashtags from every tweet and
extract separate tokens from it by removing the '#'
and employing a hashtag decomposition approach,
assumptive it is written in an even-toed ungulate
case. As an example, we can get 'I', 'Am', and
'Sarcastic' from '#IAmSarcastic'. URLs, mentions,
stop words, and punctuations are removed from
tweets for more process.
4 FEATURES
4.1 Word N-Grams
Word n-gram refers to the presence or absence of a
sequence of n-word or tokens during a tweet. Word
n-grams have evidence to be helpful features for
sarcasm detection in previous experiments. We tend
to think about all n-grams for values of n starting
from 1 to 5. We tend to think about solely those n-
grams for features that occur a minimum of 10 times
within the corpus to prune the feature space.
4.2 Classification Approach
We have used entirely different machine learning
techniques such as Support Vector Machine,
Random Forest classifier, Naïve Bayes, Decision
Tree, k-Nearest Neighbor, Gradient Boosting, and
Logistic Regression classifiers. We tend to use sci-
kit-learn implementation of these methods for
sarcasm detection.
Figure 1: Diagram of Tweets (Sarcastic and Non-sarcastic)
5 RESULT
We used the F-score measure to evaluate our
system's performance because the range of sarcastic
tweets may be smaller than the number of non-
sarcastic tweets. Therefore, the system analysis's
exploitation only accuracy may not be a decent
metric. F-score is outlined because of the mean
value of precision and Recall.
5.1 Accuracy
It is the stability of correct responses in the sample
and can be identified using equation
Accuracy
sarcastic
. .
.
5.2 F1-score
It is Precisions and Recall's harmonic means. It can be
calculated using equation
F1-score(sarcastic)=
5.3 Precision
It is the stability of True Positive versus all positive
answers.
Precision(sarcastic)=
.
.
5.4 Recall
It is the real positive's stability against all the accurate
results.
Recall(sarcastic)=
.
.
On doing intensive experiments on the collected
Dataset, it's found that the Support Vector Machine
classifier achieved a weighted F1- Score of 0.84.
The Random Forest classifier achieved an F1- score
of 0.64, and also the Decision Tree classifier
achieved an F1- score of 0.77. Whereas k-Nearest
Neighbour score a weighted F1- Score of 0.65,
Logistic Regression got a weighted F1- Score of
0.80. When the extracted dataset is analysed in
detail, Gradient Boosting claimed a weighted F1-
Score of 0.75, and Naïve Bayes classifier gained a
weighted F1- Score of 0.77.
Sarcasm Detection from Social Media Posts using Machine-learning Techniques: A Comparative Analysis
31

Table: 3 Machine Learning Classifiers
Sarcasm dataset
Models Class Precision Recall F1-
Score
SVM
Sarcastic 0.85 0.92 0.88
Non-
sarcastic
0.84 0.71 0.77
Weighted 0.84 0.84 0.84
RF
Sarcastic 0.68 0.99 0.81
Non-
sarcastic
0.93 0.21 0.34
Weighted 0.77 0.70 0.64
DT
Sarcastic 0.82 0.81 0.81
Non-
sarcastic
0.68 0.69 0.68
Weighted 0.77 0.77 0.77
KNN
Sarcastic 0.69 0.99 0.82
Non-
sarcastic
0.96 0.23 0.37
Weighted 0.79 0.71 0.65
LR
Sarcastic 0.82 0.90 0.85
Non-
sarcastic
0.79 0.65 0.71
Weighted 0.80 0.81 0.80
GB
Sarcastic 0.75 0.93 0.83
Non-
sarcastic
0.80 0.48 0.60
Weighted 0.77 0.76 0.75
NB
Sarcastic 0.77 0.94 0.84
Non-
sarcastic
0.82 0.52 0.63
Weighted 0.79 0.78 0.77
6 DISCUSASION AND
LIMITATIONS
The significant finding of this research is that the
proposed analysis of predictable Machine Learning
classifiers is analyzed for identifying Sarcasm in the
case of user-created data set. From the result table
no, it is evident that the support vector machine
(SVM) is performing well compared to other
remaining conventional machine learning classifiers.
The support vector machine achieves an F1-score of
0.84. Whereas in the case in KNN classifier, it
achieves an F1-score of 0.65 that is worst among all
conventional machine learning classifier. The Recall
of 0.84 for the sarcastic class means that the support
vector machine (SVM) can identify sarcastic to 87
cases out of sarcastic tweets. Several similar works
are also reported for identifying sarcastic sentences
from Twitter.
Klema et al. projected a random forest model
using the TF-IDF feature and acquired an associate
accuracy of 69% using the Twitter dataset. Jansi et
al. proposed a new model Unigram-SVM during
which uses the TF-IDF feature and gained an F1-
score of 81%. Al-Ghadhban et al. evaluated these f-
score naïve Bayes measurements that gave 0.676
value; severally, these results are high, particularly
when it involves Arabic using the Twitter dataset.
One of the limitations of this work that is we
have only used English Language sentences to train
our model. However, on social media, several
sarcastic messages are also posted in regional
languages. Hinglish a unique language where
statements are in Hindi and English mixed from
India. Another limitation of this work is that we
have only used textual content from the tweets to
identify the sarcastic sentences. Social media post
also contains emoji, hyperlinks, images, and videos,
which are not considered in the current research.
7 CONCLUSION AND FUTURE
SCOPE OF RESEARCH
One of the difficult challenges in the natural
language processing sector is distinguishing Sarcasm
from textual content. The sarcasm statement affects
the extraction of correct sentiment from the social
media text as Sarcasm can detect all the sentences'
polarity. The support vector machine (SVM)
performance outperforms several conventional
machine learning classifiers. The current research
can also be extended to include the other modalities
present in social media posts, such as images,
videos, and audio clips. The inclusion of emoji and
other hyperlinks presents social media post can also
be validated
REFERENCES
A. D. Dave and N. P. Desai, "A comprehensive study of
classification techniques for sarcasm detection on
textual data," 2016 International Conference on
Electrical, Electronics, and Optimization Techniques
(ICEEOT), Chennai, 2016, pp. 1985-1991, DOI:
10.1109/ICEEOT.2016.7755036.
Bamman, D. and Smith, N., 2015, April. Contextualized
sarcasm detection on Twitter. In Proceedings of the
ICACSE 2021 - International Conference on Advanced Computing and Software Engineering
32

International AAAI Conference on Web and Social
Media (Vol. 9, No. 1).
Berthon, P.R., Pitt, L.F., Plangger, K. and Shapiro, D.,
2012. Marketing meets Web 2.0, social media, and
creative consumers: Implications for international
marketing strategy. Business Horizons, 55(3), pp.261-
271.
Bouazizi, Mondher, and TomoakiOtsukiOhtsuki. "A
pattern-based approach for sarcasm detection on
Twitter." IEEE Access 4 (2016): 5477-5488.
Constantinides, E. and Fountain, S.J., 2008. Web 2.0:
Conceptual foundations and marketing issues. Journal
of direct, data and digital marketing practice, 9(3),
pp.231-244.
D. Al-Ghadhban, E. Alnkhilan, L. Tatwany and M.
Alrazgan, "Arabic sarcasm detection in Twitter," 2017
International Conference on Engineering & MIS
(ICEMIS), Monastir, 2017, pp. 1-7, DOI:
10.1109/ICEMIS.2017.8272990.
E. Lunando and A. Purwarianti, "Indonesian social media
sentiment analysis with sarcasm detection," 2013
International Conference on Advanced Computer
Science and Information Systems (ICACSIS), Bali,
2013, pp. 195-198, DOI:
10.1109/ICACSIS.2013.6761575.
Fleiss, Joseph L., and Jacob Cohen. "The equivalence of
weighted kappa and the intraclass correlation
coefficient as measures of reliability." Educational and
psychological measurement, 33, no. 3 (1973): 613-619
Gainous, Jason, and Kevin M. Wagner. Tweeting to
Power: The social media revolution in American
politics. Oxford University Press,
Islam, M.R., Kabir, M.A., Ahmed, A. et al. Depression
detection from social network data using machine
learning techniques. Health InfSciSyst 6, 8 (2018).
https://doi.org/10.1007/s13755-018-0046-0
Jansi, K. R., Pranit Rao Sajja, and PriyanshuGoyal. "An
extensive Survey on Sarcasm Detection Using Various
Classifiers." International Journal of Pure and Applied
Mathematics 119, no. 12 (2018): 13183-13187.
K. Parmar, N. Limbasiya and M. Dhamecha, "Feature-
based Composite Approach for Sarcasm Detection
using MapReduce," 2018 Second International
Conference on Computing Methodologies and
Communication (ICCMC), Erode, 2018, pp. 587-591,
DOI: 10.1109/ICCMC.2018.8488096.
Kanwar, Nikita, Rajesh Kumar Mundotiya, Megha
Agarwal, and Chandradeep Singh. "Emotion-based
voted classifier for Arabic irony tweet identification."
(2019).
Klema, Jiri, and Ahmad Almonayyes. "Automatic
categorization of fanatic texts using random forests."
Kuwait journal of science and engineering 33, no. 2
(2006): 1.
M. Bouazizi and T. OtsukiOhtsuki, "A Pattern-Based
Approach for Sarcasm Detection on Twitter," in IEEE
Access, vol. 4, pp. 5477-5488, 2016, DOI:
10.1109/ACCESS.2016.2594194.
M. M. Tadesse, H. Lin, B. Xu and L. Yang, "Detection of
Depression-Related Posts in Reddit Social Media
Forum," in IEEE Access, vol. 7, pp. 44883-44893,
2019, doi: 10.1109/ACCESS.2019.2909180.
Make Use of Sarcasm to Enhance Sentiment Analysis. In
Proceedings of the 2015 IEEE/ACM International
Conference on Advances in Social Networks Analysis
and Mining 2015 (ASONAM '15). Association for
Computing Machinery, New York, NY, USA, 1594–
1597. DOI: https://doi.org/10.1145/2808797.2809350
MondherBouazizi and TomoakiOhtsuki. 2015. Opinion
Mining in Twitter How to
Nadeem, Moin. "Identifying depression on Twitter." arXiv
preprint arXiv:1607.07384 (2016).
arXiv:1607.07384v1 [cs. S.I.]
Ptáček, Tomáš, Ivan Habernal, and Jun Hong. "Sarcasm
detection on Czech and English Twitter." In
Proceedings of COLING 2014, the 25th international
conference on computational linguistics: Technical
papers, pp. 213-223. 2014.
R. Gupta, J. Kumar, H. Agrawal and Kunal, "A Statistical
Approach for Sarcasm Detection Using Twitter Data,"
2020 4th International Conference on Intelligent
Computing and Control Systems (ICICCS), Madurai,
India, 2020, pp. 633-638, DOI:
10.1109/ICICCS48265.2020.9120917.
Rajeswari, K. and ShanthiBala, P., 2018. Recognization of
sarcastic emotions of individuals on the social
network. International Journal of Pure and Applied
Mathematics, 18(7), pp.253-259.
Saha, Shubhodip, Jainath Yadav, and PrabhatRanjan.
"Proposed approach for sarcasm detection in Twitter."
Indian Journal of Science and Technology 10, no. 25
(2017): 1-8.
Swami, Sahil, AnkushKhandelwal, Vinay Singh, Syed
Sarfaraz Akhtar, and Manish Shrivastava. "A corpus
of English-Hindi code-mixed tweets for sarcasm
detection." arXiv preprint arXiv:1805.11869 (2018).
arXiv:1805.11869v1 [cs.CL]
T. Jain, N. Agrawal, G. Goyal and N. Aggrawal, "Sarcasm
detection of tweets: A comparative study," 2017 Tenth
International Conference on Contemporary Computing
(IC3), Noida, 2017, pp. 1-6, DOI:
10.1109/IC3.2017.8284317.
Thelwall, M., Buckley, K., &Paltoglou, G. (2012).
Sentiment strength detection for the social web.
Journal of the American Society for Information
Science and Technology, 63(1), 163-173.
Sarcasm Detection from Social Media Posts using Machine-learning Techniques: A Comparative Analysis
33
