
Multi-document Arabic Text Summarization based on Thematic
Annotation
Amina Merniz, Anja Habacha Chaibi and Henda Hajjami Ben Gh
´
ezala
National School of Computer Science, University of Manouba, Tunisia
Keywords:
Text Summarization, Multi-document Summarization, Pagerank Algorithm, Thematic Annotation.
Abstract:
Reduce document(s) by keeping keys and significant sentences from a set of data is called text summarization.
It has been around for a long time in natural language processing research, it is improving over the years due
to a considerable number of methods and research in this area. The paper suggests Arabic multi-document text
summarization. The originality of the approach is that the summary based on thematic annotation such as input
documents are analyzed and segmented using LDA. Then segments of each topic are represented by a separate
graph because of the redundancy problem in multi-document summarization. In the last step, the proposed
approach applies a modified pagerank algorithm that utilizes cosine similarity measure as a weight between
edges. Vertices that have high scores are essential. Therefore, they construct the final summary. To evaluate
summary systems, researchers develop serval metrics divided into three categories, namely: automatic, semi-
automatic and manual. This study research chooses automatic evaluation methods for text summarization,
mainly Rouge measure (Rouge-1, Rouge-2, Rouge-L, and Rouge-SU4).
1 INTRODUCTION
The quantity of data on the internet is growing con-
tinuously, which increases the appearance of redun-
dant and unnecessary documents (data). At the time,
a user is searching for accurate and relevant informa-
tion (news, papers). Automatic document text sum-
marization has become one of the active tasks in this
field. It is considered a real challenge in NLP (Nat-
ural Language Processing) (even in Text mining). It
serves in several scopes such as social media market-
ing, newsletters, email overload, and medical cases. It
allows the production of a short version from the input
text(s), containing the main ideas and the relevant in-
formation. Automatic document text summarization
can be abstractive or extractive. The abstractive sum-
mary involves a detailed analysis of the document. It
may include a new sentence not present in the ini-
tial text. However, the extractive one depends on the
identification and extraction of the most frequent units
of the source text to be integrated into the generated
summary. A summary can also be a multi-document
or mono-document, the multi-document generates the
summary from the collection of documents, whereas
a mono-document summarizes one document in the
input. Concerning the language, text summarization
can be classified into multilingual, monolingual or
cross-lingual. Despite the researcher’s efforts and the
considered number of approaches that have been de-
veloped until our days in this field, multi-document
text summarization studies in the Arabic language
are still limited. (Conroy et al., 2013) produced text
summarization in Arabic using latent semantic analy-
sis method (LSA) as well as Latent Dirichlet Alloca-
tion (LDA), also (Azmi and Al-Thanyyan, 2012) pro-
posed an Arabic summary for single document based
on Lexical cohesion, (El-Haj and Rayson, 2013) in-
troduced statistical measures to produce mono and
multi-document text summarization in both Arabic
and English languages, however, (Fejer and N.Omar,
2014) based on machine learning to propose an ex-
tractive Arabic summary. In this article, we sug-
gest a new approach for Arabic (multilingual), multi-
document text summarization. Based on thematic an-
notation (segmentation and topic identification) us-
ing the combination of Latent Semantic Analysis ap-
proach (LSA) and latent dirichlet allocation (LDA),
then the presentation of segments of each topic in
graphs to eliminate the inter-redundancy problem also
to avoid the loss of phrases (sentences) belong to a
specific topic. The modified pagerank algorithm is
applied to reduce the graphs built and keep only the
most important sentences in the final summary. The
paper organization is described as section 2 identifies
text summarization related works based on topic iden-
Merniz, A., Chaibi, A. and Ben Ghézala, H.
Multi-document Arabic Text Summarization based on Thematic Annotation.
DOI: 10.5220/0010557906390644
In Proceedings of the 16th International Conference on Software Technologies (ICSOFT 2021), pages 639-644
ISBN: 978-989-758-523-4
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
639

tification as well as based graph approaches, section
3 presents research goal, section 4 describes the pro-
posed approach for multi-document Arabic summa-
rization, section 5 is dedicated to evaluating proposed
approach also to discussing results, the conclusion is
presented in section 6.
2 RELATED WORK
There are various automatic text summarization
techniques, statistical-based approaches, machine
learning-based approaches, linear programming-
based approaches, graph-based approaches, and oth-
ers that combine different techniques to summarize.
This section focuses on graph-based approaches as
well as topic identification based methods.
Topic identification based approach: (Hennig,
2009) considered a new method for multi-documents
summarization to present sentences and queries like
probability distributions over latent topics. This ap-
proach merges query focused and thematic features
computed in the latent topic space to estimate the
summary relevance of sentences.
(Hammo et al., 2011) present a hybrid approach
for automatic Arabic summarization based on iden-
tifying the thematic structure of the input text using
a classifier and conceptual thesaurus to select proper
sentences gathered from the statistical analysis pro-
cess.
(Harabagiu and Lacatusu, 2005) proposed a new
model for multi-documents summarization based on
topic themes using semantic information supplied by
semantic parsers. The themes are represented by de-
termining both coherence and cohesion relations that
improve the general summary quality.
Graph-based approach:
Extractive Arabic Text summarization of (El-
barougy et al., 2020) bases on graph representation
using a pagerank algorithm with a few modifications.
Such as the weight of edges between nodes is com-
puted by cosine similarity; also, each node’s rank is
fixed to the noun number in the sentence; contrary to
pagerank, all nodes’ rank is equal and fixed to 1/N.
(Mallick et al., 2019) present a summary using
modified TexRank algorithm by applying inverse sen-
tence frequency modified cosine similarity To cover
the importance of words in sentences also sentences
in the document.
(Khan et al., 2018) built a semantic graph for
abstractive multi-document summarization such as
the nodes represent the predicate-argument structures
whereas the edges denote similarity weight. An im-
proved ranking algorithm derives from PageRank is
applied to keep only the top-ranked sentences.
(Uc¸kan and Karcı, 2020) introduce a new method
for multi-document summarization based on KUSH
algorithm. That prepares data to be presented in graph
such as nodes represent sentences and edges are com-
mon words. The approach focuses on the concept
of removing maximum independent sentences in the
graph to preserve only the main nodes in the sum-
mary.
3 RESEARCH GOAL
Text summarization is a vast area in Natural Language
Processing (NLP). It isn’t straightforward to produce
a summary system that simultaneously combines sev-
eral features, especially multi-document, multilingual
abstractive text summarization. Besides, when lan-
guages are of variable complexity. This research pro-
poses multi-document Arabic text summarization, us-
ing a graph to make it flexible in other languages. The
graph is independent of the language because graph-
based approaches demonstrate an excellent efficiency
in automatic text summarization.
4 PROPOSED APPROACH
This paper proposes a hybrid approach for multi-
lingual Arabic multi-document text summarization.
Through three phases thematic annotation of docu-
ments, graphs representation, graphs reduction and
summary construction as shown in algorithm.
Step 1. (Thematic Annotation of Documents): to
exploit the thematic aspect of the text, thus facili-
tating the task of the next phase (graphs representa-
tion). In this step, the segmented documents of(Naili
et al., 2017) are used who proposed a multilingual an-
alyzer for segmentation and topic identification us-
ing semantic knowledge-based on Latent Semantic
Analysis(LSA) also (LDA) Latent Dirichlet Alloca-
tion. Documents are segmented such as each segment
is labeled by its minor and significant topics, in this
article, we are interested in essential topics. A docu-
ment may include several topics, as shown in the fig-
ure 1. That represents two segments of text such as the
first one identifies topic 4 (Science) as shown in ma-
jor topic field, whereas the second segement belongs
to topic 1 (Health).
Step 2. (Graphs Representation): this phase aims to
avoid the inter-redundancy problem known in multi-
document text summarization also to cover the seg-
ments of all topics identified in the input docu-
ICSOFT 2021 - 16th International Conference on Software Technologies
640

Figure 1: Example of thematic annotation of document in arabic.
ments.Segments of each topic are represented by a
graph as shown in figure 2 where the vertices define
the sentences in Arabic, whereas the edges represent
the adjacency relations between sentences.
Step 3. (Graphs Reduction): at the end, a modi-
fied pagerank algorithm is applied to the graphs built
to reduce them and keep only the most important
sentences included in the final summary. PageRank
(Page et al., 1999) The pagerank algorithm imple-
mented at stanford university by (Page et al., 1999)
and utilized by the search engine of google to deter-
mine the significance of webpage using the graph rep-
resentation. It has different application fields mainly
application in search, browsing, and traffic estima-
tion. The concept of pagerank is that a webpage has
a high rank if the sum of the ranks of its back-links is
high. The formal definition of this algorithm is shown
in equation 1. With d is damping factor fixed at 0.85,
damping factor, A: the webpage, C (A): is the number
of outgoing links of the page A;
PR(A) = (1 − d) + dx
PR(T
1
)
C (T
1
)
+ ... +
PR(T
n
)
C (T
n
)
(1)
In our case, the graphs are oriented as specified
in figure 2, such as the vertices represent the sen-
tences in arabic. In contrast, the arcs represent the
adjacency relations between these sentences. After
the algorithm’s execution with number of iterations
(N=100), a score will be carried out to each node that
describes the power of this node in the graphs, only
nodes related to a high score will be included in the
summary.
Modified PageRank Algorithm: The pagerank al-
gorithm is modified, such as the pages are replaced
with document sentences. Also, weight is added be-
tween edges. It indicates the cosine similarity among
sentences. Cosine similarity metric (Han et al., 2012)
measures similarity between vectors that represent
term or (phrase) frequency in the document. Let x
and y, be two vectors for comparison, cosine similar-
ity formula of x, y is:
cos
sim
=
x.y
k
x
kk
y
k
´
(2)
Where
k
x
k
, and
k
y
k
:
are euclidean norm of vectors x, y respectively de-
fined as
q
x
2
1
+ x
2
2
+ . . . +x
2
n
.
The application of mentioned modifications gives
the following PageRank formula:
PR
M
= (1 −d)+d ×
∑
j∈In(V
i
)
PR
M
(V
j
) × cos
sim
(V
i
, V
j
)
Out(V
j
)
(3)
Algorithm 1: Proposed approach algorithm.
Input: multi-document multi-topic;
Output: Summary for each topic;
thematic annotation of documents;
ForEach Topic (Major-topic) from D do
Create a Graph -Topic (V, E);
ForEach Graph Topic do
Calculate Weight W, using Cosine Similarity between
sentences (Sentence-A, Sentence-B);
Update Graph-Topic by adding weight between edges
such as G’ (V, E, W);
Apply Modified PageRank (MPR) on G’ with number
of iterations (N) ;
Extract Summary for each topic;
Multi-document Arabic Text Summarization based on Thematic Annotation
641

Figure 2: Representation of topic4 (sciences) segments in a graph.
5 EXPERIMENTAL RESULTS
AND EVALUATION
5.1 Evaluation Metrics
Summary evaluation is an essential task in measur-
ing and enhancing the results of the summary gen-
erated. For this purpose, researchers have devel-
oped a variant of metrics that differ according to
their mode of application: automatic, semi-automatic,
manual also according to their mode of evaluation
intrinsic or extrinsic. The extrinsic evaluation con-
cerns the impact assessment of the summary quality
on the other tasks such as text classification, infor-
mation retrieval. Simultaneously, the intrinsic evalu-
ation consists of determining the quality and the in-
formativeness of summary based on reference sum-
maries using automatic metrics or semi-automatic
methods. Automatic metrics (Rouge (Lin, 2004) ,
QARLA (Amig
´
o et al., 2005) , AutoSummENG (Gi-
annakopoulos et al., 2008) ) do not involve human
annotations, while semi-automatic methods such as
relative utility (Radev and Tam, 2003) , factoid score
(Teufel and Halteren, 2004), Pyramid (Nenkova and
Passonneau, 2004) method involve some of the hu-
man annotations.
ROUGE: Recall Oriented Understudy for Gist-
ing Evaluation proposed by (Lin, 2004) to automat-
ically measure the summary quality. It computes the
number of units (n-grams, word sequences, and word
pairs) common between the summary produced by a
machine and a list of reference summaries. ROUGE
defines four measures, namely: ROUGE-N, ROUGE-
L, ROUGE-W, and ROUGE-S.
Rouge-N: determines the common n-grams be-
tween the automatic summary and a list of reference
summaries. Rouge-1 for 1-gram, Rouge-2 for bi-
grams.
Rouge
N
=
∑
S∈
{
Re f Sum
}
∑
gram
n
∈
{
S
}
Count
match
(gram
n
)
∑
S∈
{
Re f Sum
}
∑
gram
n
∈
{
S
}
Count
match
(gram
n
)
(4)
Rouge-L: calculates the maximum length of com-
mon sequences (LCS) namely X and Y. such as X rep-
resents a collection of sequences from reference sum-
maries whereas Y is a set of sentences of the system
summary. (Lin and F.J. Och, 2004) proposes using
LCS-based F-measure to estimate the similarity be-
tween X and Y of length m and n respectively, where
β =
Rouge
L
(P)
Rouge
L
(R)
according to Eqs :
Rouge
L
(R) =
LCS(X, Y )
m
(5)
Rouge
L
(P) =
LCS(X, Y )
n
(6)
Rouge
L
(F) =
(1 + β
2
)Rouge
L
(R)Rouge
L
(P)
Rouge
L
(R) + β
2
Rouge
L
(P)
(7)
Rouge-SU4: ROUGE-S: (Skip-Bi-gram Co-
Occurrence Statistics) computes the overlap of skip
ICSOFT 2021 - 16th International Conference on Software Technologies
642
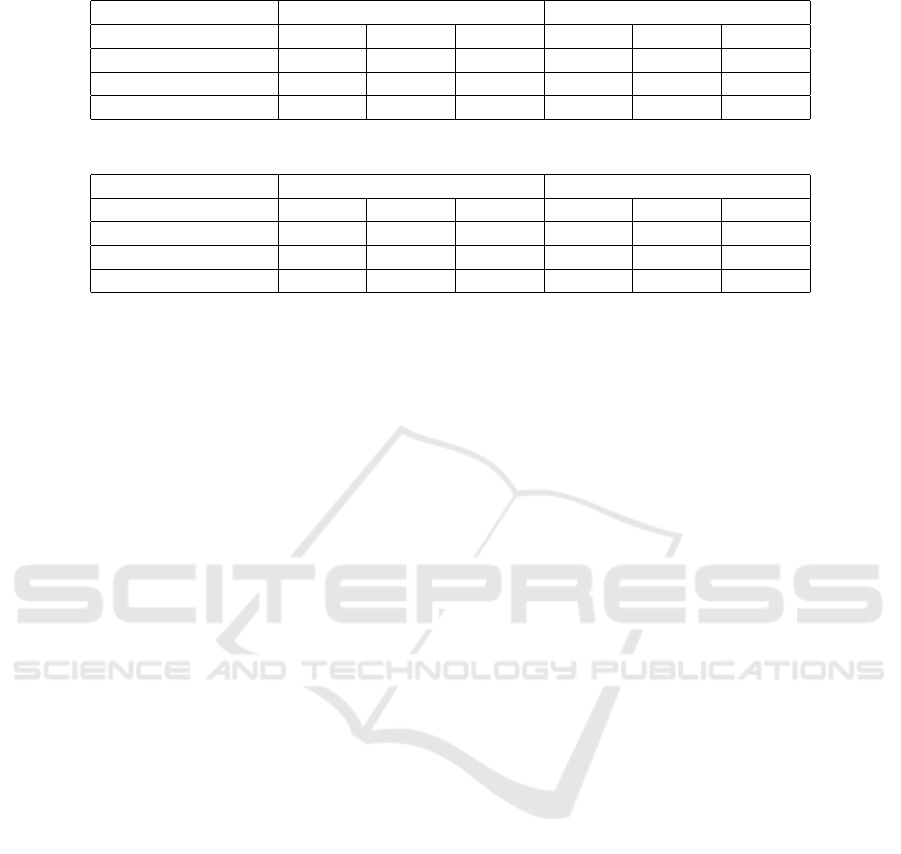
Table 1: rouge-L, rouge-1 evaluation results of the proposed algorithm.
Rouge-L Rouge-1
R P F R P F
Topic 1 (economics) 0,21126 0,15175 0,17663 0,57128 0,37169 0,45036
Topic 2 (health) 0,14743 0,11429 0,12876 0,59024 0,37109 0,45568
Topic 3 (politics) 0,13760 0,28634 0,18587 0,26943 0,52174 0,35535
Table 2: rouge-2, rouge-SU4 evaluation results of the proposed algorithm.
Rouge-2 Rouge-SU4
R P F R P F
Topic 1 (economics) 0,35310 0,21996 0,27106 0,39250 0,23860 0,29678
Topic 2 (health) 0,36019 0,21690 0,27076 0,42045 0,24400 0,30879
Topic 3 (politics) 0,12578 0,23393 0,16360 0,15952 0,28675 0,20500
bi-grams between a given summary and its set of ref-
erences. Skip Bi-gram of a sentence is defined as
the couple of words following their same order in the
sentence with random gaps. This version has been
extended by adding 1-gram as a counting unit to en-
hance the primary method.
5.2 Corpus
The proposed approach is tested on al sulaiti corpus
proposed by (Al-Sulaiti and Atwell, 2006) that con-
tains documents in Arabic divided into several cate-
gories(Autobiography, Short Stories, Children’s Sto-
ries, Economics, Education, Health and Medicine, In-
terviews, Politics, Recipes, Religion, Sociology, Sci-
ence, Sports, Tourist, Travel). This study interests in
the following subjects: health, politics, economic, and
sciences. At the end, each topic obtains its summary
system.
5.3 Results Discussion
Tables (1,2) show the summary results of rouge met-
rics: rouge-L, rouge-1, rouge-2, and rouge-SU4, for
each topic. We notice that the results of topics 1 (eco-
nomics) and 2 (health) are almost similar in rouge-1,
rouge-2, and rouge-SU4, with values approximately
close to 0.58, 0.36, and 0.41, respectively. How-
ever, values of topic 3 (politics) vary between 0.12
in rouge-2 and 0.27 in rouge-1. The proposed ap-
proach aims to test the impact of segmented docu-
ments combing with the pagerank algorithm on multi-
document summarization. It differs from Elbarougy’s
system and existing studies in the following aspects:
first (Elbarougy et al., 2020) suggests arabic summary
for single document whereas our approach presents
arabic summarization for multi-document. Second
the proposed system represents each topic in doc-
uments by a graph in order to eliminate the inter-
reduncy problem also it combines a both thematic an-
notation and pagerank algorithm to produce the sum-
mary. (Elbarougy et al., 2020) does not apply an-
notated documents. Several works highlight graph-
based methods, including pagerank (Page et al., 1999)
, textrank (Mihalcea and Tarau, 2004) , or lexrank
(Erkan and Radev, 2004) algorithms, which have
shown excellent efficiency, but those who combine ei-
ther segmented and Modified pagerank algorithms are
limited. Also, we don’t use the same corpus. There-
fore, we cannot compare to them in this article.
6 CONCLUSION AND FUTURE
WORK
Document text summarization is a varied field, rich
in characteristics. This paper has introduced the ba-
sics definitions of an automatic summary and differ-
ent related works to text summarization. We pro-
posed Arabic multi-document text summarization ap-
praoch based on segmented multi-topic documents.
Separation of each topic in the graph to minimize
redundancy also applies to the modified PageRank
by adding a cosine similarity measure to the initial
PageRank formula. Results of the proposed approach
are considerable, with 0.59 (rouge-1) as a high value.
For future work, we modify input documents using
non-segmented documents to extract the segmenta-
tion and topic identification aspect’s contribution. We
enrich the graph semantically by applying other sim-
ilarity measures to enhance the quality of the sum-
mary system. We make the proposed algorithm mul-
tilingual by testing it on different languages such as
English, French.
Multi-document Arabic Text Summarization based on Thematic Annotation
643

REFERENCES
Al-Sulaiti, L. and Atwell, E. (2006). The design of a cor-
pus of contemporary arabic. International Journal of
Corpus Linguistics, 11(2):135–171.
Amig
´
o, E., Gonzalo, J., Penas, A., and Verdejo, F. (2005).
Qarla: a framework for the evaluation of text sum-
marization systems. In Proceedings of the 43rd An-
nual Meeting of the Association for Computational
Linguistics (ACL’05), pages 280–289.
Azmi, A. and Al-Thanyyan, S. (2012). A text summarizer
for arabic. Computer Speech & Language, 26(4):260–
273.
Conroy, J., Davis, S., Kubina, J., Liu, Y., O’leary, D., and
Schlesinger, J. (2013). Multilingual summarization:
Dimensionality reduction and a step towards optimal
term coverage. In Proceedings of the MultiLing 2013
Workshop on Multilingual Multi-document Summa-
rization, pages 55–63.
El-Haj, M. and Rayson, P. (2013). Using a keyness metric
for single and multi document summarisation. In Pro-
ceedings of the MultiLing 2013 Workshop on Multilin-
gual Multi-document Summarization, pages 64–71.
Elbarougy, R., Behery, G., and Khatib, A. E. (2020).
Extractive arabic text summarization using modified
pagerank algorithm. Egyptian Informatics Journal,
21(2):73–81.
Erkan, G. and Radev, D. (2004). Lexrank: Graph-based lex-
ical centrality as salience in text summarization. Jour-
nal of artificial intelligence research, 22:457–479.
Fejer, H. and N.Omar (2014). Automatic arabic text sum-
marization using clustering and keyphrase extraction.
In Proceedings of the 6th International Conference on
Information Technology and Multimedi, pages 293–
298. IEEE.
Giannakopoulos, G., Karkaletsis, V., Vouros, G., and Stam-
atopoulos, P. (2008). Summarization system evalua-
tion revisited: N-gram graphs. ACM Transactions on
Speech and Language Processing (TSLP), 5(3):1–39.
Hammo, B., Bassam, H., h. Abu-Salem, and Evens, M.
(2011). A hybrid arabic text summarization technique
based on text structure and topic identification. In-
ternational Journal of Computer Processing of Lan-
guages, 23(01):39–65.
Han, J., Kamber, M., and Pei, J. (2012). 13-data mining
trends and research frontiers. Data Mining (Third Edi-
tion), ed Boston: Morgan Kaufmann, pages 585–631.
Harabagiu, S. and Lacatusu, F. (2005). Topic themes for
multi-document summarization. In Proceedings of the
28th annual international ACM SIGIR conference on
Research and development in information retrieval,
pages 202–209.
Hennig, L. (2009). Topic-based multi-document summa-
rization with probabilistic latent semantic analysis. In
Proceedings of the International Conference RANLP-
2009, pages 144–149.
Khan, A., Salim, N., Farman, H., Khan, M., Jan, B., Ah-
mad, A., Ahmed, I., and Paul, A. (2018). Abstractive
text summarization based on improved semantic graph
approach. International Journal of Parallel Program-
ming, 46(5):992–1016.
Lin, C. (2004). Rouge: A package for automatic evaluation
of summaries. In Text summarization branches out,
pages 74–81.
Lin, C. and F.J. Och, F. (2004). Automatic evaluation of ma-
chine translation quality using longest common subse-
quence and skip-bigram statistics. In Proceedings of
the 42nd Annual Meeting of the Association for Com-
putational Linguistics (ACL-04), pages 605–612.
Mallick, C., Das, A., Dutta, M., Das, A., and Sarkar, A.
(2019). Graph-based text summarization using mod-
ified textrank. In Soft computing in data analytic,
pages 137–146. Springer.
Mihalcea, R. and Tarau, P. (2004). Textrank: Bringing or-
der into text. In Proceedings of the 2004 conference
on empirical methods in natural language processing,
pages 404–411.
Naili, M., Chaibi, A., and Gh
´
ezala, H. (2017). Arabic topic
identification based on empirical studies of topic mod-
els. Revue Africaine de la Recherche en Informatique
et Math
´
ematiques Appliqu
´
ees, 27.
Nenkova, A. and Passonneau, R. (2004). Evaluating content
selection in summarization: The pyramid method. In
Proceedings of the human language technology con-
ference of the north american chapter of the associ-
ation for computational linguistics: Hlt-naacl 2004,
pages 145–152.
Page, L., Brin, S., Motwani, R., and Winograd, T. (1999).
The pagerank citation ranking: Bringing order to the
web. Technical report, Stanford InfoLab.
Radev, D. and Tam, D. (2003). Summarization evaluation
using relative utility. In Proceedings of the twelfth in-
ternational conference on Information and knowledge
management, pages 508–511.
Teufel, S. and Halteren, H. (2004). Evaluating information
content by factoid analysis: human annotation and sta-
bility.
Uc¸kan, T. and Karcı, A. (2020). Extractive multi-document
text summarization based on graph independent sets.
Egyptian Informatics Journal, 21(3):145–157.
ICSOFT 2021 - 16th International Conference on Software Technologies
644
