
Design of Scalable and Resilient Applications
using Microservice Architecture in PaaS Cloud
David Gesvindr, Jaroslav Davidek and Barbora Buhnova
Lab of Software Architectures and Information Systems,
Faculty of Informatics, Masaryk University, Brno, Czech Republic
Keywords:
Cloud Computing, Microservices, Architecture Design.
Abstract:
With the increasing adoption of microservice architecture and popularity of Platform as a Service (PaaS)
cloud, software architecture design is in many domains leaning towards composition of loosely interconnected
services hosted in the PaaS cloud, which in comparison to traditional multitier applications introduces new
design challenges that software architects need to face when aiming at high scalability and resilience. In
this paper, we study the key design decisions made during microservice architecture design and deployment
in PaaS cloud. We identify major challenges of microservice architecture design in the context of the PaaS
cloud, and examine the effects of architectural tactics and design patterns in addressing them. We apply
selected tactics on a sample e-commerce application, constituting of microservices operated by Azure Service
Fabric and utilizing other supportive PaaS cloud services within Microsoft Azure. The impact of the examined
design decisions on the throughput, response time and scalability of the analyzed application is evaluated and
discussed.
1 INTRODUCTION
Microservice architecture is becoming a dominant ar-
chitectural style in the service-oriented software in-
dustry (Alshuqayran et al., 2016). In contrast to tra-
ditional multitier applications where the role of soft-
ware components is played mainly by software li-
braries deployed and executed in a single process to-
gether with the main application, in microservice ar-
chitecture, individual components become truly au-
tonomous services (Fowler, 2014). There are multi-
ple advantages of this approach—change in a single
component does not require the entire application to
be redeployed, communication interfaces become ex-
plicit, and components become more decoupled and
independent of each other, as illustrated in Figure 1.
Separation of services into functions that can in-
teract via interfaces is not new, same as methods
to implement such separation in the framework of
service-oriented architecture (Sill, 2016). But as
emphasized by Sill (Sill, 2016), recent implementa-
tions of microservices in cloud settings take service-
oriented architecture to new limits. Possibilities of
rapid scalability and use of rich PaaS (Platform as a
Service) cloud services open new design possibilities
for microservices but also bring new threats for soft-
ware architects, with increasing difficulty to navigate
among the enormous number of available design op-
tions. This creates the need to examine the impact of
applicable design patterns in the context of microser-
vices and PaaS cloud.
Although some guidance on the microservice im-
plementation in the cloud exists, systematic support
for software architects interconnecting microservices
with other available PaaS cloud services (such as stor-
age and communication services) is not available,
leaving them to rely on shared experience with typ-
ically a single application scenario, without consider-
ing other strategies or alternative designs.
In this paper, we study different architectural deci-
sions which are being considered during microservice
architecture design in connection with the PaaS cloud.
As a contribution of this work, we elaborate on both
Deployed Multitier Architecture
Presentation
Tier
Application
Tier
Data
Tier
UI
Compo
-nent
UI
Compo
-nent
UI
Compo
-nent
Compo
-nent
Compo
-nent
Compo
-nent
Shared Database
Deployed Microservice Architecture
Deployed
Service A
Presentation
Tier
Application
Tier
Service
Storage
Deployed
Service C
Presentation
Tier
Application
Tier
Service
Storage
Deployed
Service B
Presentation
Tier
Application
Tier
Service
Storage
Figure 1: Separation of components and their deployments
in a traditional multitier architecture and in microservice ar-
chitecture.
Gesvindr, D., Davidek, J. and Buhnova, B.
Design of Scalable and Resilient Applications using Microservice Architecture in PaaS Cloud.
DOI: 10.5220/0007842906190630
In Proceedings of the 14th International Conference on Software Technologies (ICSOFT 2019), pages 619-630
ISBN: 978-989-758-379-7
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
619

documented and undocumented design practices and
solutions, and study their effects, including identifi-
cation of several surprising takeaways. As part of this
paper, we have designed and implemented a highly
configurable e-commerce application (an e-shop solu-
tion), which is designed in a way that its architecture
can be easily reconfigured to support thorough evalua-
tion of the impact of various design decisions on mul-
tiple performance related quality attributes (through-
put, response time and scalability). When designing
this application, we paid special attention to the se-
lection of real use cases and realistic architecture de-
sign, being overall as close as possible to a produc-
tion version of such an application. The highly con-
figurable architecture of this application gives us a
unique opportunity to provide comparison of multiple
versions of the same application using microservice
architecture to evaluate and isolate impact of differ-
ent design decisions, which is rarely seen in existing
work. Software architects can benefit from our work
while designing their own applications when facing
the same design decisions. With the help of this work
they shall now be able to make better-informed deci-
sions and choose the right architectural patterns lead-
ing to desired quality of the application, or avoid un-
documented problems caused by chosen architecture
or used PaaS cloud services.
For the purpose of effective benchmark execution,
we also implemented an automated client application
that can reconfigure the deployed application, initial-
ize sample data seeding on the server based on user
requirements, execute any mix of workload, display
key performance metrics and export detailed perfor-
mance counters in JSON format. This application was
used for our benchmarks discussed in this paper.
For the implementation of the sample application,
we have decided to use Microsoft technologies and
cloud services. The application is developed in .NET
framework using Azure Service Fabric (Mic, 2018),
which is an open-source application platform for sim-
plified management and deployment of microservices
that can run in Microsoft Azure cloud, on-premise in-
frastructure and any other cloud infrastructure. This
platform was chosen because of its robustness (Mi-
crosoft uses internally this technology to operate large
scale services in Microsoft Azure, eg. Azure SQL
Database, Cosmos DB and others), and rich platform
services, which simplify microservice development.
On the other hand, the features that we used can be
manually implemented in other frameworks and the
same results can be obtained by hosting small web ap-
plications communicating with each other via REST
APIs, hosted in Docker and orchestrated by Kuber-
netes. Overall our results are generally valid indepen-
dently of the platform as the used patterns are plat-
form independent and can be applied also to differ-
ent cloud provider (Amazon, Google Cloud) offer-
ing container hosting services and managed NoSQL
databases.
Overall, we have evaluated 105 different bench-
mark scenarios using 4 cluster configurations (5, 10,
15, 20 nodes cluster) involving 4 different storage ser-
vices in the PaaS cloud, 2 communication strategies
(synchronous and asynchronous) and 11 design pat-
terns.
The paper is structured as follows. After the dis-
cussion of related work in Section 2, outline of the
background in Section 3, and outline of key architec-
tural decisions that influenced the separation of ser-
vices in Sections 4, Sections 5, 6 and 7 are dedi-
cated to the presentation and evaluation of architec-
tural concerned with service storage, communication
between microservices and application resilience. We
conclude the paper in Section 8.
2 RELATED WORK
When designing microservice architectures, software
architects are currently often relying on known de-
sign patterns and tactics (Gamma et al., 1995; Fowler,
2002), which are however not validated in the con-
text of microservices or PaaS cloud. Alderado et
al. point to an absence of repeatable empirical re-
search on the design and development of microser-
vice applications (Aderaldo et al., 2017). New design
guidelines for microservice architectures are emerg-
ing (Sill, 2016; Wolff, 2016; Nadareishvili et al.,
2016; Newman, 2015), which however do not con-
tain evaluated performance impacts of recommended
patterns on realistic implementations. At the same
time catalogs of design patterns for the design of PaaS
cloud applications are becoming available (Erl et al.,
2013; Wilder, 2012; Homer et al., 2014; Mic, 2017),
but without measured impacts of their combinations
and their use in a context of microservices. Vali-
dations of microservice architecture design patterns
are published by companies that have deployed mi-
croservices (Richardson, 2017; Net, 2015) and want
to share their experience with transition to microser-
vice design but not mentioning PaaS cloud deploy-
ment. Instead they focus on their currently deployed
architecture, its behavior and sometimes related per-
formance characteristics rather than transferable take-
aways. Due to the size of their projects, they cannot
afford to implement multiple variants of their applica-
tion using different design patterns and compare per-
formance of those to isolate the impact of used de-
ICSOFT 2019 - 14th International Conference on Software Technologies
620

sign patterns. This is where our work complements
the current state of the art via offering more guidance
for the actual decision making. A case-study eval-
uating the impact of transition from multi-tiered ar-
chitecture to microservice architecture on throughput
and operation costs is described in (Villamizar et al.,
2015), but not in the context of PaaS cloud, as it is de-
ployed to IaaS virtual machines. Challenges related
to transaction processing and data consistency across
multiple microservices are described in (Mihinduku-
lasooriya et al., 2016; Pardon et al., 2018). Criteria
for microservice benchmarks and a list of sample ap-
plications are presented in (Aderaldo et al., 2017), but
without optimization for PaaS cloud and its services.
3 MICROSERVICES IN PaaS
CLOUD
An indisputable advantage of operating microservices
in the PaaS cloud is the availability of a rich set
of complex ready-to-use services, providing software
architects with complex functionality, high service
quality (hight scalability and availability guaranteed
by SLA), low-effort deployment, and thus easy in-
tegration within the developed application. More-
over, multiple services are not even available for on-
premise deployment, or are costly to deploy and op-
erate with the same quality of service.
Microservices hosted in the PaaS cloud can bene-
fit very well from cloud elasticity and measured ser-
vice (Mell and Grance, 2011), which allows us to eas-
ily scale individual services by allocating new com-
pute resources and pay only for the time when the
service instance is running. As part of low-effort de-
ployment of microservices, we can take advantage of
container orchestration as a service, which are ser-
vices provided by majority of the cloud providers,
used to manage and orchestrate applications deployed
in form of containers. Very often, it is a preconfigured
and fully managed Kubernetes cluster. And for ex-
ample in Microsoft Azure, the Azure Container Ser-
vice is not even billed. One needs to pay only for
the compute resources used to host the containers it-
self. To support rapid scalability, we do not need to
allocate virtual machines with the Kubernetes cluster
to host containerized applications. Instead, we can
take advantage of PaaS cloud container-hosting ser-
vices (e.g. Azure Container Istances), which is a fully
managed service providing per-second billing based
on the number of created instances, the memory and
cores selected for the instances, and the number of
seconds those instances are run. Such a rapid elastic-
ity allows us to scale microservices almost instantly
with very effective operation costs.
Microsoft Azure used for our implementation pro-
vides us also with the possibility to host Azure Ser-
vice Fabric cluster in form of a fully managed ser-
vice with very low deployment and maintenance ef-
fort. The cluster itself is deployed and operated at no
cost, we are only billed for virtual machines used to
host our services. New virtual machines can be easily
provisioned and released based on the overall utiliza-
tion of the cluster, to take advantage of cloud elasticity
and to optimize operation costs.
Despite all mentioned advantages of microservice
deployment to the PaaS cloud, there are associated
threats related to missing guidance on how to design
microservices in the PaaS cloud context. As there is
a very rich set of PaaS cloud services currently avail-
able that can be utilized by the microservice appli-
cation (storage, messaging, etc.) and have a direct
impact on the quality of the service, it becomes very
complex for a software architect to design the mi-
croservice application so that it meets all given quality
criteria. In this paper we compare and discuss mul-
tiple design choices and their impacts learned from
running over 100 experiments with variable software
architecture of our microservice application.
4 SERVICE DECOMPOSITION
DECISIONS
This section describes the key design decisions that
shaped the overall architecture of the designed appli-
cation and led to separation of the application into a
set of interconnected microservices, refined from the
initial set of domain entities, identified using the Do-
main Driven Design principles (Evans, 2003).
4.1 Bounded Context
To split an application with a single data model into
a set of microservices, the Bounded Context design
principle suggests the division of large data model
into a set of smaller models with explicitly defined
relationships. Proper application of the bounded con-
text principle is one of the major challenges when
designing a microservice architecture, as it becomes
very difficult to find the right balance between very
small microservices having a single data entity, and
services handling multiple entities that tend to ulti-
mately end up being too complex.
The following points characterize the advantages
of setting the bounded context small (Fowler, 2014):
explicit service dependencies, independent scalability
and high-availability.
Design of Scalable and Resilient Applications using Microservice Architecture in PaaS Cloud
621

On the other hand, the problems that arise with the
utilization of small bounded contexts are:
• Data integrity enforcement – Referential integrity
of entities stored at a single microservice can be
easily enforced at the storage level, but when re-
ferring entities are stored in different microser-
vices, it becomes very complex to guarantee that
the referenced entity exists.
• Cross-service queries – When the user wants to
access data that is distributed among multiple mi-
croservices, it is necessary to query all services
participating in the query and then combine re-
lated data, which is a complex operation and may
have negative impact on service response time as
shown in Section 5.6.
• Cross-service transactions – Distributed transac-
tions are generally complex to implement and
when transaction modifies data across multiple
microservices, it requires the developer to im-
plement additional logic to ensure that transac-
tions on all services are either all committed or
all rolled back.
• Data Duplication – To overcome issues related
to cross-service queries, transactions and integrity
enforcement, frequently referenced entities can be
stored in multiple copies as part of multiple ser-
vices for the price of additional consistency man-
agement.
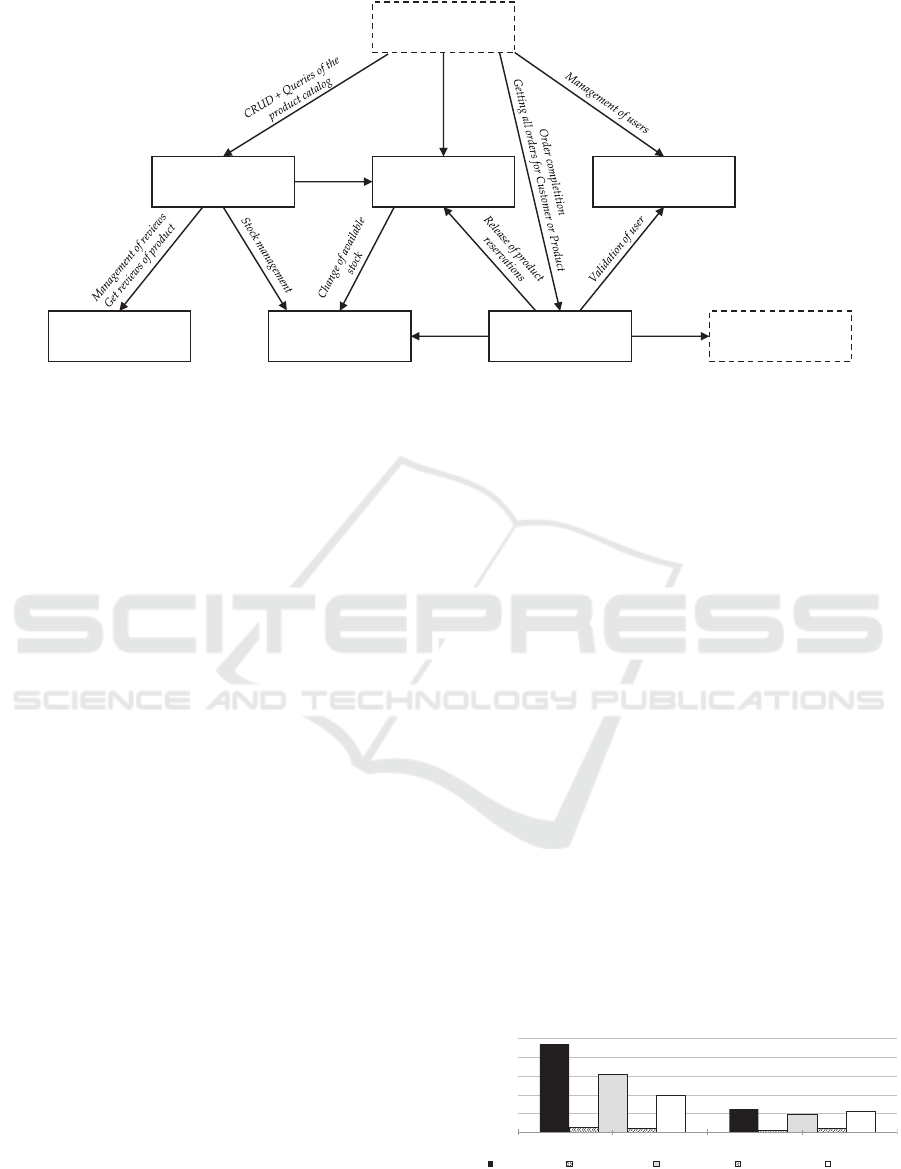
Our sample application consists of 7 microser-
vices (6 stateful, 1 stateless) depicted in Figure 2. We
designed every service to manage and store a single
domain entity. There are two exceptions we would
like to explain here:
• Product Service – manages product catalog,
which persists Product and Category entities.
We considered separation of these closely coupled
entities into isolated microservices, but because
they are referencing each other very often and at
the same time Categories are only referenced by
Products, we decided to store them in a single mi-
croservice.
• Sales Service – manages stored Orders (headers
with embedded items) for a specific user and at
the same stores a list of OrderItems for a specific
product. We decided to store sales data in a du-
plicate manner due to limits exposed by applied
partitioning.
4.2 Partitioning
Partioning is very often associated with the storage
layer (Homer et al., 2014) but in the context of mi-
croservices, partitioning can be propagated up to the
service interface depending on the storage technology
used. If the microservices are stateful, the use of the
partitioning at the storage level is highly advisable, so
that every node hosting the service only stores a spe-
cific portion of data based on the partition key. Selec-
tion of the partition key must be done very carefully
as the key will be then required by most of the service
methods to be able to determine which instance can
process the request, as depicted in Figure 3. At the
same time, requesting data across multiple partitions
becomes a very complex operation, as illustrated in
Figure 4, which needs to be minimized by design.
4.3 Summary of Recommendations
Data model of the application must be split into mul-
tiple microservices with adequate level of granular-
ity. Because of better consistency enforcement and
higher communication efficiency closely coupled en-
tities should be in the same microservice. An impor-
tant point to emphasize is that microservices should
also be separated at the storage level. Storage shared
by multiple microservices should be strictly avoided
by design, as it hinders independent scalability of mi-
croservices. The storage becomes a single point of
failure, with high risk of becoming a performance bot-
tleneck. To design highly scalable microservies, par-
titioning at the storage and compute level should be
applied.
4.4 Evaluation
The impacts of our partitioning strategy on scalability
of the designed application can be observed in Fig-
ure 9, which shows throughput of the REST API de-
pending on the size of the compute cluster and con-
firms that applied partitioning strategy leads to design
of a scalable microservice application.
5 STORAGE DESIGN DECISIONS
Selection of a storage technology or storage ser-
vice in the PaaS cloud has a significant impact
on the throughput and scalability of the applica-
tion (Gesvindr and Buhnova, 2016a). As we expect
that even in case of microservice architecture the stor-
age tier of stateful service will significantly influence
performance metrics of the service, we decided to
evaluate four different storage technologies that can
be utilized by our application, to assess how they will
limit service scalability and what the overall through-
put of the service in different scenarios will be. This
ICSOFT 2019 - 14th International Conference on Software Technologies
622
Stock Service
Checkout Service
Stock
Checkout Item
Review Service
Product Review
Reservation Service
Reservation
User Service
User
Address
Product Service
Category
Product
Sales Service
Order Item
Order
1
1
1
1
1
1
1
*
*
*
*
*
*
Partition by ProductID
Partition by UserID
Partition by CategoryID
Partition by ProductID
Partition by ProductID
Partition by ProductID
Partition by Email
Figure 2: Separation of data model into different microservices.
shall provide software architects with additional guid-
ance for selecting storage technology and design of
the storage layer. We evaluate only NoSQL storage
services, as it was demonstrated in (Gesvindr and
Buhnova, 2016a) that in the PaaS cloud they signif-
icantly outperform classical relational databases.
5.1 Storage Abstractions
Individual microservices in our application were im-
plemented without dependency on any storage tech-
nology or service, which is still fairly unique while
advisable approach, which allowed us to isolate and
measure the impact of used storage technology. We
designed our own abstraction layer comprised of stor-
age independent repositories and adapters for specific
storages. Queries defined to retrieve data from the
storage in the application are defined in C# in a form
of our own composite predicates, which should be de-
scriptive enough to meet all querying needs of the ap-
plication. Our storage abstraction layer parses them
and generates native queries for given storage tech-
nology. Moreover, to define a repository, we only
define storage-independent domain entity as a class
in C# and all necessary storage structures are auto-
matically created and optimized for a given set of
queries, which is most important in case of the key-
value storage with limited querying support. This ab-
straction layer allows us to easily reconfigure what
storage technology is used without the need to rede-
ploy the application, making the benchmarking pro-
cess more effective.
5.2 Key-value NoSQL Database
The first type of storage we decided to evaluate is
a key-value NoSQL database as it is provided in a
form of PaaS cloud service by every major cloud
provider and offers very high throughput, nearly un-
limited scalability and low operation costs at the cost
of limited querying support which can be partially
mitigated by proper data access tier design.
The representative key-value NoSQL database we
evaluated is Azure Table Storage which is a fully
managed key-value NoSQL database with almost un-
limited scalability when data partitioning is properly
used, but it comes at the cost of very limited query
support, which needs to be taken into account by
the architect. Data is stored in tables without any
fixed structure (every row can have a different set of
columns), where every row must be uniquely identi-
fied by a pair of partition key and row key. Data with
the same partition key is stored at the same server,
therefore it is important to generate the partition key
for stored rows in such a way that the rows are dis-
tributed across multiple servers, which leads to high
scalability of this storage. It is important to be aware
of limited querying support as data can be efficiently
filtered only based on partition and row key, not by
other columns, which are not indexed. The fastest
queries are those accessing the data from a single par-
tition with an exact match of a row key. When query is
executed to retrieve data across multiple partitions, its
response time significantly increases. The service is
billed based on the amount of used storage and num-
ber of transactions. There are no performance tiers or
billing based on performance.
To effectively retrieve data from Azure Table Stor-
age, it is necessary to store the same table in duplicate
copies but with different set of partition row keys, as
illustrated in Table 1 for the list of products in a cat-
alog. Data is partitioned by CategoryID, as we are
always displaying the list of products in a single cat-
egory and stored sorted in an ascending order based
on a different row key, which supports filtering and
sorting based on that column (e.g. in the table: Name,
EAN Code and Price).
Design of Scalable and Resilient Applications using Microservice Architecture in PaaS Cloud
623

Table 1: Tables generated to store duplicate data in Azure Table Storage for effective querying.
Table name PartitionKey RowKey
Product CategoryID CategoryID ProductID
Product Name CategoryID Name ProductID
Product Name DSC CategoryID Name(inverted) ProductID
Product EANCode CategoryID EANCode
Product EANCode DSC CategoryID EANCode(inverted)
Product Price CategoryID Price ProductID
Product Price DSC CategoryID Price(inverted) ProductID
We took an experimental approach where for
some queries with unpredictable performance, we
take advantage of low transaction costs and high scal-
ability of Azure Table Storage and execute multiple
variants of the query leading to the same result using
different tables. Only the fastest query returns data.
5.3 Document NoSQL Database
The second type of storage service we want to evalu-
ate is a NoSQL document database, which in compar-
ison to key-value storages provides complex query-
ing support by internal indexing of stored documents,
which decreases complexity of effective implementa-
tion for the developer.
As a representative within MS Azure, we eval-
uated Azure Cosmos DB, which is a multi-model
NoSQL database as a service, built by Microsoft es-
pecially for a highly distributed cloud environment. It
supports data in multiple different data models—key-
value storage with a client protocol compatible with
Azure Table Storage, document storage using either
its own protocol or it offers support for MongoDB
clients, columnar families with support for Apache
Cassandra clients, graph data with support for Grem-
lin clients.
Microsoft provides SLA on performance of this
service—Azure Cosmos DB guarantees less than 10
ms latencies on reads and less than 15 ms latencies
on (indexed) writes at the 99th percentile. Through-
put is influenced by the number of reserved Request
Units (RU), and based on the amount of storage and
reserved RU the service is billed.
Our application implements adapters for both the
document storage and also for the key-value stor-
age as we wanted to compare their performance in
terms of a single service. Despite the fact, that key-
value storage was evaluated using Azure Table Stor-
age, CosmosDB does not share its limitations related
to limited query support. Azure Cosmos DB automat-
ically indexes all columns in the table, so that we do
not have to store data with high duplicity to be able
to query them efficiently. In the document mode, we
store collections of complex entities and same as for
the key-value storage, all properties are indexed, so
we can efficiently load data based on complex queries.
Results of this experiment are even more interest-
ing when we also compare pricing models and related
costs of used storage services, as Azure CosmosDB
requires us to reserve performance in form of costly
Request Units (RU) and every operation costs certain
amount of RU based on operation complexity known
prior its execution and when all RU are consumed by
queries, new operations are rejected with an error. So
the client does not utilize the full potential of the ser-
vice’s hardware, but is logically limited so that perfor-
mance SLA can be guaranteed. Azure Table Storage
exposes very cheap transaction fee and provides max-
imum performance of the service without any need to
prepay certain performance tier but without any per-
formance guarantees.
5.4 Reliable In-memory Storage at
Compute Nodes
The last type of storage we wanted to compare in our
sample application is a distributed storage using reli-
able in-memory collections, which are locally present
at the compute nodes of the cluster.
Stateful services in Azure Service Fabric have
their own unique storage called Azure Service Fabric
Reliable Collections, so such a hosted microservice
does not have to use external storage services. The
main goal is to collocate compute resources and the
storage on the same node in the cluster to minimize
communication latency. The storage itself is provided
in form of Reliable Collections, which is an evolu-
tion of classical .NET framework collections, but it
provides the developer with a persistent storage with
a multi-node high availability achieved through repli-
cation (one active replica, multiple passive replicas)
and high scalability achieved via data partitioning.
There are three types of supported collections: Re-
liable Dictionary, Reliable Queue and Reliable Con-
current Queue.
To distribute data and workload across the Ser-
vice Fabric cluster, it is advisable that every stateful
ICSOFT 2019 - 14th International Conference on Software Technologies
624
REST API
Service
1. Get products in
category
Product Service
Partition 0
Active Replica
Product Service
Partition 1
Active Replica
Product Service
Partition 2
Active Replica
2. Get partition reference
3. Connect and
execute service method
Product Service
Partition 0
Secondary Replica
Product Service
Partition 1
Secondary Replica
Product Service
Partition 2
Secondary Replica
Figure 3: Accessing partitioned data stored in Azure Ser-
vice Fabric stateful services.
service implements data partitioning and stores data
based on a partition key in separate partitions. When
the service is requested to load the data, Service Fab-
ric provides very simple API, which based on the par-
tition key opens connection to an instance of the ser-
vice that stores the partition and executes our code of
the microservice that loads data from the local stor-
age of the service partition as depicted in Figure 3.
A problem arises when we need to access data across
multiple partitions. Then the request is sent to a ran-
dom service partition, it loads local data and over net-
work requests data from other service partitions as de-
picted in Figure 4. This leads to delays in responses.
Efficient partitioning is a key to the design of highly
scalable and efficient storage using Reliable Collec-
tions. Partitioning keys we applied on our data model
are depicted in Figure 2.
REST API
Service
1. Get products
Product Service
Partition 0
Active Replica
Product Service
Partition 1
Active Replica
Product Service
Partition 2
Active Replica
2. Select random partition
3. Connect and
execute service method
Product Service
Partition 0
Secondary Replica
Product Service
Partition 1
Secondary Replica
Product Service
Partition 2
Secondary Replica
4. Connect to other partitions
and execute methods
Figure 4: Separation of data model into different microser-
vices.
5.5 Summary of Recommendations
Our experiments confirm strong dependency of ap-
plication’s throughput on used storage technology.
None of the used storage technologies outperformed
others in all scenarios, therefore selection of stor-
age technology should be accompanied with bench-
marks of implemented microservices to determine if
selected technology meets required performance cri-
teria. Use of in-memory storage collocated to com-
pute resources (Reliable Collections) leads to great
scalability and lowest operation costs. Due to high
communication overhead observable in complex sce-
narios, we would recommend the use of microservice
architecture for scenarios where microservices do not
have to communicate frequently with each other.
5.6 Evaluation
We have evaluated the use of the four different stor-
age technologies with our microservice application.
The results of benchmark evaluating throughput of
microservices hosted on 5-node cluster (Azure Ser-
vice Fabric 6.0.232, node hosted on Azure Virtual
Machines D11 V2 2 cores, 14GB RAM, 100GB SSD
cache) depending on the used storage technology are
depicted in Figure 5. We evaluated five different
workloads because we expected that various storage
services will have different performance characteris-
tics depending on the type of the workload. The most
surprising and important result is that there is indeed
no single storage service that would outperform all the
others in all scenarios. Another fact is that throughput
of complex operations is very low due to high over-
head of cross-service communication, which is one
of the disadvantages of microservice architecture.
235
14
154
10
98
140
7
52
6
54
323
1
89
11
141
226
7
157
19
127
0
50
100
150
200
250
300
350
Simple read-only Complex read-only Simple write-only Complex write-
only
All scenarios
Average throughput (requests
per second)
Reliable Collections
Azure Table Storage
Azure Cosmos DB (Key-Value)
Azure Cosmos DB (Document)
Figure 5: Throughput of REST API hosted on 5-node clus-
ter with different storage services using synchronous com-
munication for different scenarios.
86
151
48
301
243
547
1326
19
534
753
31
654
32
261
162
73
221
74
277
167
0
200
400
600
800
1000
1200
1400
Simple read-only Complex read-only Simple write-only Complex write-
only
All scenarios
Average response time (ms)
Reliable Collections
Azure Table Storage
Azure Cosmos DB (Key-Value)
Azure Cosmos DB (Document)
Figure 6: Response time of REST API hosted on 5-node
cluster with different storage services using synchronous
communication for different scenarios.
To assess scalability of the evaluated storage ser-
vices, we deployed the same application on 20-node
cluster. The results of the benchmarks are depicted in
Figure 7. The benchmarks confirm that our service is
scalable and its scalability is significantly influenced
by the used storage service as the throughput increase
does not have the same ratio for all storage services
and scenarios. We also learned that the use of Azure
Cosmos DB is despite its high throughput very tricky,
because one needs to pay for reserved storage per-
formance (Request Units) and it is challenging to ad-
just performance of individual collections to achieve
best service performance without wasting allocated
request units.
Design of Scalable and Resilient Applications using Microservice Architecture in PaaS Cloud
625
One can see from our experiments that a single
service instance of the stateless Public API Service,
which resends client requests to individual services,
was not overloaded even for 20-node cluster, which
may be a sign of the used ASP.NET Core framework
efficiency.
776
116
280
29
256
525
40
154
63
192
703
12
199
25
394
784
43
582
51
415
0
200
400
600
800
1000
Simple read-only Complex read-only Simple write-only Complex write-
only
All scenarios
Average throughput (requests
per second)
Reliable Collections
Azure Table Storage
Azure Cosmos DB (Key-Value)
Azure Cosmos DB (Document)
Figure 7: Throughput of REST API hosted 20-node cluster
with different storage services using synchronous commu-
nication for different scenarios.
56
87
53
104
101
80
201
204
142
185
31
449
559
265
335
76
132
47
117
268
0
100
200
300
400
500
600
Simple read-only Complex read-only Simple write-only Complex write-
only
All scenarios
Average response time (ms)
Reliable Collections
Azure Table Storage
Azure Cosmos DB (Key-Value)
Azure Cosmos DB (Document)
Figure 8: Response time of REST API hosted on 20-node
cluster with different storage services using synchronous
communication for different scenarios.
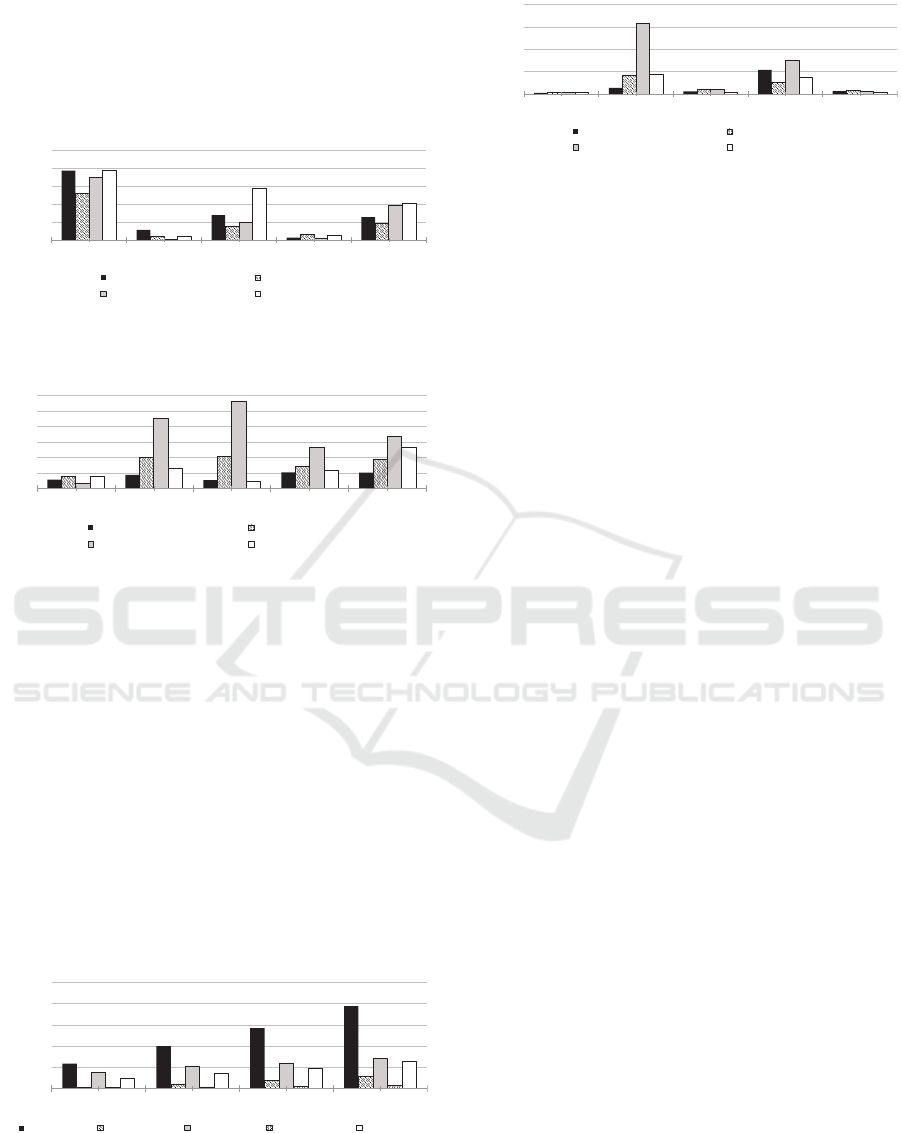
We were further interested in the performance of
Reliable Collections because they are hosted as an in-
tegral part of Azure Service Fabric without any ad-
ditional costs. From the benchmarks we can confirm
that performance of Reliable Collections is strongly
dependent on the size of the cluster as the workload
is evenly distributed on multiple nodes using parti-
tioning, as depicted in Figure 9. On the 20-node
cluster (Figure 7), read operations are outperforming
even very expensive Azure Cosmos DB (cost compar-
ison per request is depicted in Figure 10), especially
in complex scenarios. Unfortunately, the write op-
erations are slower due to complex data replication
among nodes to provide data redundancy.
235
398
570
776
14
44
74
116
154
207
241
280
10
16
23
29
98
143
186
256
0
200
400
600
800
1000
5 10 15 20
Average throughput (requests
per second)
Number of nodes in the cluster
Simple read-only Complex read-only
Simple write-only Complex write-only
All scenarios
Figure 9: Throughput of REST API hosted on 5, 10, 15
and 20 node cluster with reliable collections storage using
synchronous communication for different scenarios.
2,0
13,4
5,5
53,4
6,1
3,0
40,6
10,1
26,4
8,3
2,7
159,0
9,6
76,3
4,8
2,5
44,7
3,3
37,7
4,6
0,0
50,0
100,0
150,0
200,0
Simple read-only Complex read-only Simple write-only Complex write-
only
All scenarios
Cost per 1 million requests
[USD]
Reliable Collections
Azure Table Storage
Azure Cosmos DB (Key-Value)
Azure Cosmos DB (Document)
Figure 10: Cost per 1 million REST API requests hosted on
20 node cluster with different storage services using syn-
chronous communication for different scenarios.
6 COMMUNICATION STRATEGY
DESIGN DECISIONS
When handling communication between individual
services, there are two major strategies that can be
applied when microservices communicate with each
other:
• Synchronous – The service requests a response
from another microservice and waits for the re-
sponse before it continues in an execution.
• Asynchronous – the service send a request (mes-
sage) to another service using messaging service
and does not actively wait for the response. When
the response is generated, it is delivered through
the messaging service back to the original service.
Impacts of asynchronous messaging on multiple qual-
ity attributes of the application are well described
in (Taylor et al., 2009) and specifically for the PaaS
cloud environment in (Homer et al., 2014; Gesvindr
and Buhnova, 2016a). Due to different complexity
and frequency of communication between microser-
vices, we find it to be desirable to validate impacts
of both communication strategies on throughput, re-
sponse time and scalability of the application. To this
end we implemented our sample application in such
a way that the communication strategy can be easily
switched thanks to adequate abstractions in its archi-
tecture.
6.1 Synchronous Communication
Strategy
The client application communicates with REST API
service, which redirects requests received via publicly
available REST API to individual microservices run-
ning in the Azure Service Fabric cluster. To discover
and communicate with services running in the cluster,
the following steps need to happen:
1. The location of the service needs to be resolved
– The service instance can be migrated between
different nodes of the cluster and can be running
ICSOFT 2019 - 14th International Conference on Software Technologies
626
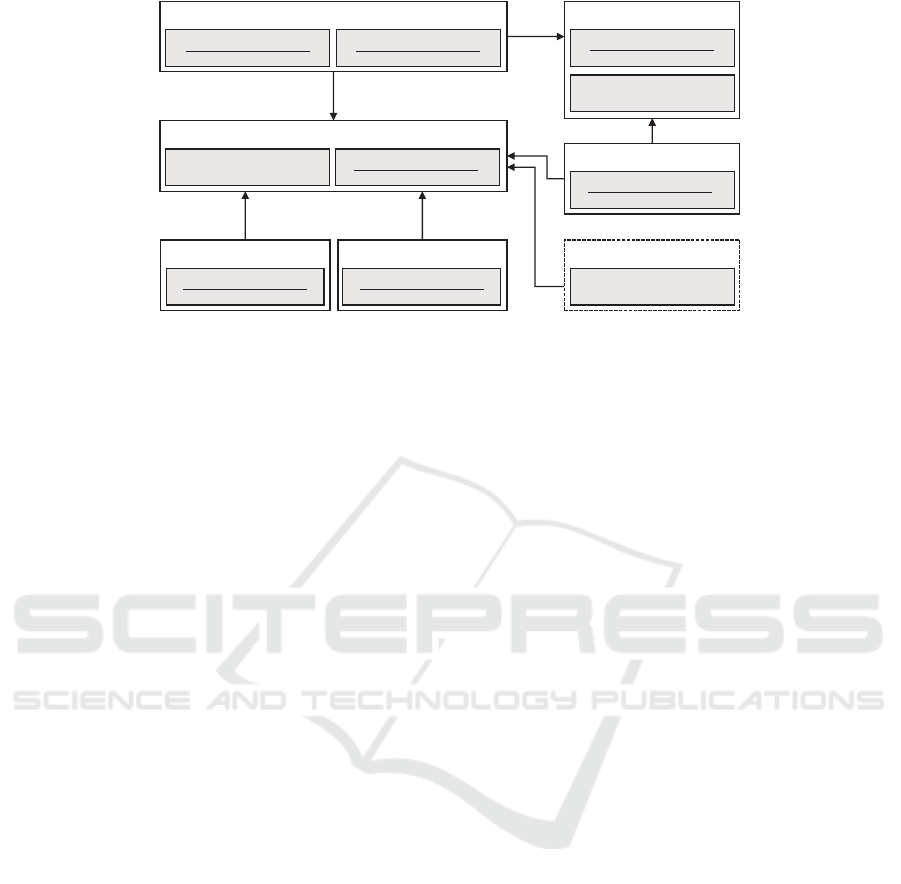
Public Signal R
API Service
Review Service
Product Service
Stock Service
Reservation
Service
User Service
Sales Service
Checkout Service
Product
availability
check
Product
reservation
Product
price
computation
Change of
available
stock
Figure 11: Diagram of service interactions.
in multiple instances. If the service is stateless,
requests can be evenly distributed. If the service is
stateful, then the service partition should receive
only requests for which it does have locally stored
data.
2. Connection to the service – When the location of
the service is resolved by reverse proxy, which is
a service running in Azure Service Fabric cluster,
a direct connection can be opened between two
services hosted in the cluster and requested oper-
ation can be executed. When the connection fails,
there is a retry logic implemented as part of Azure
Service Fabric infrastructure.
Interactions between individual microservices and
types of requests are depicted in Figure 11.
6.2 Asynchronous Communication
Strategy
An alternative communication strategy does not open
direct connections between microservices hosted in
the cluster, but the service sends a request (message)
to another service using messaging service. When the
message is delivered, the request is processed and the
response is sent back to the messaging service and
is delivered to the service waiting for the response.
The advantage of this approach is a looser coupling
of the microservices as they do not rely on a defined
communication interface but only on the format of re-
quest and response messages. The disadvantage is the
higher implementation complexity, thus higher imple-
mentation costs.
Messaging service is not part of Azure Ser-
vice Fabric, therefore we use the ServiceFab-
ric.PubSubActors library, which hosts a new mi-
croservice that works as a reliable messaging stateful
service internally using Reliable Queue as the storage
for messages. Other services then can subscribe to
receive messages of specified type, which are unfor-
tunately broadcasted across all service partitions if it
has more than one.
6.3 Summary of recommendations
Based on the results of the experiments, it is advisable
to use synchronous communication as a primary com-
munication pattern due to significantly lower over-
head, higher throughput and faster response time.
Asynchronous communication is desirable for long
running operations or operations that need to be com-
pleted reliably (e.g. corrective actions described in
Section 7.1).
6.4 Evaluation
We implemented both communication strategies in
our sample application, which provided us with an
opportunity to evaluate and compare the behavior of
both communication strategies, which is rarely seen
in experience reports form industry on the same appli-
cation, as having both implementations is costly and
not suitable for large production applications.
235
62
14
6
154
49
10 10
98
57
0
50
100
150
200
250
Synchronous communication Asynchronous communication
Average throughput
(requests per second)
Simple read-only Complex read-only
Simple write-only Complex write-only
All scenarios
Figure 12: Throughput of REST API hosted on 5-node
cluster using synchronous and asynchronous communica-
tion with reliable collections storage for different scenarios.
Design of Scalable and Resilient Applications using Microservice Architecture in PaaS Cloud
627

86
7058
151
15971
48
5174
301
11465
243
5891
0
5000
10000
15000
20000
Synchronous communication Asynchronous communication
Average response time (ms)
Simple read-only Complex read-only
Simple write-only Complex write-only
All scenarios
Figure 13: Response time of REST API hosted on 5-node
cluster using synchronous and asynchronous communica-
tion with reliable collections storage for different scenarios.
The results of the benchmark are depicted in Fig-
ure 13. Despite the fact that synchronous calls are
considered harmful (Fowler, 2014) it is very sur-
prising how significantly synchronous service com-
munication outperforms its asynchronous alternative,
which uses messaging as a form of reliable commu-
nication between services. The use of reliable mes-
saging services leads to increased availability as very
short outages of individual services are not propa-
gated to the client but based on our implementa-
tion and tests, this communication strategy for sim-
ple scenarios has four times worse throughput than
synchronous calls. In case of the complex scenarios,
the difference is significantly lower, by which one can
conclude that asynchronous messaging is worth con-
sidering for long lasting complex operations where
high throughput is not required and reliability is more
important. Similar conclusions for PaaS cloud appli-
cations (not in context of microservices) are also men-
tioned in (Gesvindr and Buhnova, 2016a).
7 RESILIENCE DESIGN
DECISIONS
When designing a microservice architecture, one of
the biggest challenges is to enforce data consistency
across multiple services, and to manage cross-service
transactions. Software architects are nowadays pro-
vided with hardly any guidance on addressing these
design challenges in microservice architecture, we
therefore came with our own implementation, which
is a modified version of the compensation transaction
pattern (Homer et al., 2014) combined with an event
sourcing pattern (Homer et al., 2014) to handle re-
liable cross-service compensations. Our implemen-
tation does not increase complexity of successfully
executed operations, i.e. there were no performance
impacts found during benchmarks.
7.1 Cross-service Transactions
To deal with the mentioned issues, we implemented
a component called Event Sequence Source. This
component is used to describe a complex transaction
across multiple services, but the transaction itself is
split into multiple atomic blocks—the internal block
executes operations inside the service, the external
block wraps communication with another service. As
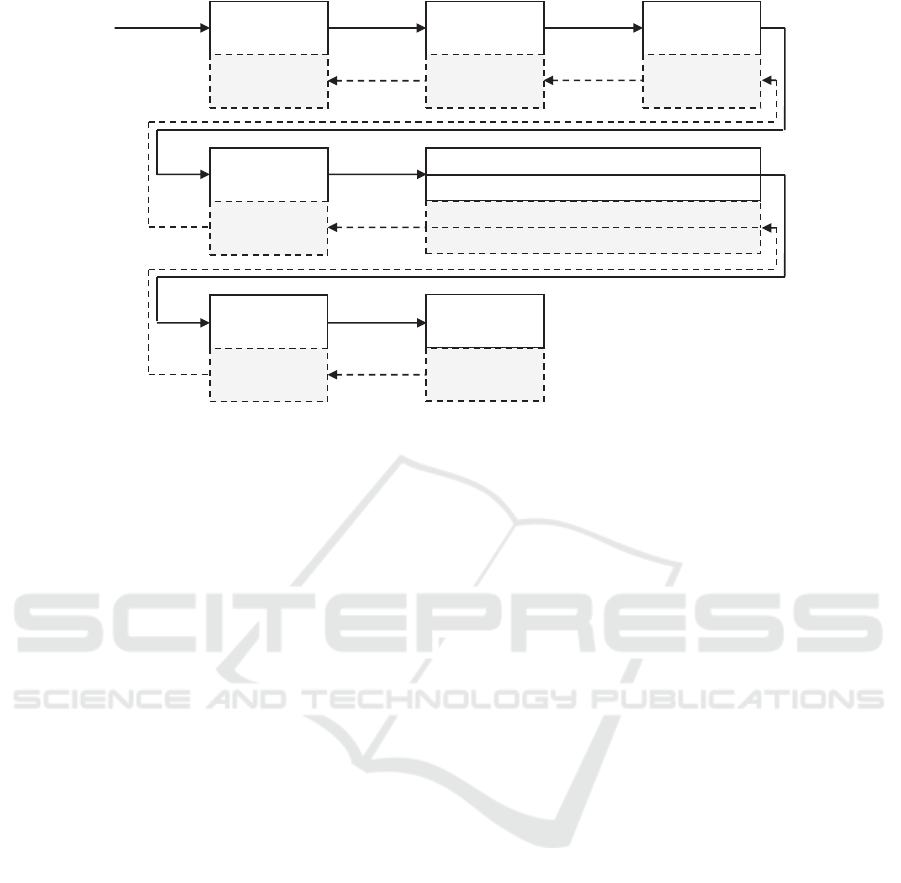
depicted in Figure 14, in the atomic block there are
actions to be executed and also pair actions to revert
changes if the transaction fails on any of the blocks.
This sequence of operations is executed exactly in the
order of their definition. We discovered that data vali-
dation should be executed as the initial action because
when this fails, no corrective actions are needed. As
no data integrity is enforced by the storage across ser-
vices, we run all necessary validations as part of the
transaction. When any of the operations fails, an ex-
ecution of corrective actions is initiated. Corrective
actions are implemented as always-succeed actions,
which means that they are stored in a highly reliable
queue to ensure that the action is repeatedly executed
until it succeeds. With this approach, the corrective
action overcomes even temporary service failures.
Our implementation of cross-service transactions
does not ensure as high level of consistency and atom-
icity as known from relational databases but it pro-
vides us with structured transaction description and
sufficient guarantees for the purpose of our business
transactions with minimum performance impact.
7.2 Constraints Enforcement
Since the data is stored across multiple microservices
with isolated storages, it is not possible to enforce ref-
erential integrity at the storage level. Therefore this
needs to be enforced with transactions. Every transac-
tion as described in the previous section runs its own
data validation, during which it validates the existence
of referenced entities in different services.
Another issue we have addressed was how to gen-
erate unique identifiers of stored entities, because in
many current applications the identifier of a record
(primary key) is generated by a relational database,
which cannot be followed in our project, and not
all storage services offer support for generation of a
unique identifier of a record. Therefore, we gener-
ate globally unique identifier using service code when
new entity is created in sour service code before it
is persisted. The uniqueness of the value is then en-
forced by the storage.
Data validation operations are implemented as a
part of the service code, mostly in a constructor of
an entity to prevent invalid entity from being instanti-
ated.
ICSOFT 2019 - 14th International Conference on Software Technologies
628
on failure
on failure
on success
on failure
on success
Check if user
exists
Confirm order
Check if
reserved
products exist
Calculate total
price
Persist order
No correction
action
No correction
action
No correction
action
on success
Delete order
Persist Order Items
Decrease Stock Level
Delete Order Items
Increase Stock Level
For each order item:
Release
customer
reservations
No correction
action
Log success
No correction
action
on success
on success
on success
on failure
on failure
on failure
Figure 14: Transaction workflow using Event Sequence Source.
7.3 Handling Transient Errors
It is very important in the PaaS cloud to properly han-
dle transient faults (Gesvindr and Buhnova, 2016b) by
implementing a retry strategy so that when a cloud re-
source is not currently available, an error is not propa-
gated to the client, but instead the operation is retried
multiple times with an increasing delay. This is al-
ready implemented in majority of client libraries and
it just needs to be enabled.
7.4 Recoverability
To increase recoverability of the application in the
PaaS cloud, it is advisable to implement the Circuit
Breaker Pattern (Homer et al., 2014). This applies
also to microservice architecture as the pattern pre-
vents an application repeatedly trying to execute an
operation that is likely to fail without wasting re-
sources. It detects if the fault has been resolved and
then it gradually increases the load as more and more
requests are permitted to execute.
7.5 Summary of Recommendations
Cloud computing services frequently deal with very
short outages in duration of few seconds, therefore
adequate transient error handling policies in a form of
retry strategy needs to be implemented. Especially for
microservices, these outages could lead to costly roll-
back of cross-service transactions. Validity of data
must be enforced mostly at the application level, as
due to the use of isolated storage services constraints
enforcement cannot be applied at the storage level.
7.6 Evaluation
Based on our observations, none of the presented re-
siliency design decision has a measurable impact on
application performance for successful requests, as no
additional actions need to be executed. Thus the eval-
uation of these strategies with respect to the perfor-
mance metrics studied in this paper is not relevant.
However it might be interesting to study their effects
on resilience-motivated quality attributes, which are
out of scope of this paper.
8 CONCLUSION
In this paper, we have identified, discussed and eval-
uated a set of design principles that influence service
decomposition, storage, communication strategy and
resilience in microservice architecture deployed in
PaaS cloud. On the sample application, we measured
their impact and presented numerous findings, which
support the observation that microservice architec-
ture leads to high scalability, but brings new design
challenges further amplified by operation in the PaaS
cloud and richness of design choices that the archi-
tects have. Decomposition of the services needs to be
carefully validated, selection of the storage provider
cannot be done without knowledge of a specific work-
load and benchmarks, synchronous communication
strategy was found to perform way better despite rec-
ommendations in literature. Additional effort shall be
invested in extension of the studied design principles
and patterns for microservice design in the context of
the PaaS cloud.
Design of Scalable and Resilient Applications using Microservice Architecture in PaaS Cloud
629

ACKNOWLEDGEMENT
This research was supported by ERDF ”Cy-
berSecurity, CyberCrime and Critical Informa-
tion Infrastructures Center of Excellence” (No.
CZ.02.1.01/0.0/0.0/16 019/0000822).
REFERENCES
(2015). Why you can’t talk about microservices without
mentioning netflix. https://smartbear.com/blog/deve-
lop/why-you-cant-talk-about-microservices-without-
ment/.
(2017). Cloud design patterns. https://docs.microsoft.com
/en-us/azure/architecture/patterns/.
(2018). Microsoft service fabric. https://github.com/micro-
soft/service-fabric.
Aderaldo, C. M., Mendonc¸a, N. C., Pahl, C., and Jamshidi,
P. (2017). Benchmark requirements for microservices
architecture research. In Proceedings of the 1st Inter-
national Workshop on Establishing the Community-
Wide Infrastructure for Architecture-Based Software
Engineering, ECASE ’17, pages 8–13, Piscataway,
NJ, USA. IEEE Press.
Alshuqayran, N., Ali, N., and Evans, R. (2016). A system-
atic mapping study in microservice architecture. In
2016 IEEE 9th International Conference on Service-
Oriented Computing and Applications (SOCA), pages
44–51.
Erl, T., Puttini, R., and Mahmood, Z. (2013). Cloud Com-
puting: Concepts, Technology & Architecture. Pren-
tice Hall Press, Upper Saddle River, NJ, USA, 1st edi-
tion.
Evans, E. (2003). Domain-Driven Design: Tackling Com-
plexity in the Heart of Software. Addison-Wesley.
Fowler, M. (2002). Patterns of Enterprise Application Ar-
chitecture. Addison-Wesley Longman Publishing Co.,
Inc., Boston, MA, USA.
Fowler, M. (2014). Microservices a definition of this new
architectural term.
Gamma, E., Helm, R., Johnson, R., and Vlissides, J.
(1995). Design Patterns: Elements of Reusable
Object-oriented Software. Addison-Wesley Longman
Publishing Co., Inc., Boston, MA, USA.
Gesvindr, D. and Buhnova, B. (2016a). Architectural tac-
tics for the design of efficient PaaS cloud applications.
In 2016 13th Working IEEE/IFIP Conference on Soft-
ware Architecture (WICSA).
Gesvindr, D. and Buhnova, B. (2016b). Performance chal-
lenges, current bad practices, and hints in PaaS cloud
application design. SIGMETRICS Perform. Eval. Rev.,
43(4).
Homer, A., Sharp, J., Brader, L., Narumoto, M., and Swan-
son, T. (2014). Cloud Design Patterns: Prescriptive
Architecture Guidance for Cloud Applications. Mi-
crosoft patterns & practices.
Mell, P. and Grance, T. (2011). The NIST definition of
cloud computing.
Mihindukulasooriya, N., Garc
´
ıa-Castro, R., Esteban-
Guti
´
errez, M., and G
´
omez-P
´
erez, A. (2016). A survey
of restful transaction models: One model does not fit
all. J. Web Eng., 15(1-2):130–169.
Nadareishvili, I., Mitra, R., McLarty, M., and Amundsen,
M. (2016). Microservice Architecture: aligning prin-
ciples, practices and culture. O’Reilly Media, Inc.,
1st edition.
Newman, S. (2015). Building Microservices. O’Reilly Me-
dia, Inc., 1st edition.
Pardon, G., Pautasso, C., and Zimmermann, O. (2018).
Consistent disaster recovery for microservices: the
BAC theorem. IEEE Cloud Computing, 5(1):49–59.
Richardson, C. (2017). Who is using microservices?
Sill, A. (2016). The design and architecture of microser-
vices. IEEE Cloud Computing, 3(5):76–80.
Taylor, R. N., Medvidovic, N., and Dashofy, E. M. (2009).
Software architecture: foundations, theory, and prac-
tice. Wiley Publishing.
Villamizar, M., Garcs, O., Castro, H., Verano, M., Sala-
manca, L., Casallas, R., and Gil, S. (2015). Evaluating
the monolithic and the microservice architecture pat-
tern to deploy web applications in the cloud. In 2015
10th Computing Colombian Conference (10CCC),
pages 583–590.
Wilder, B. (2012). Cloud Architecture Patterns. O’Reilly
Media, 1st edition.
Wolff, E. (2016). Microservices: Flexible Software Archi-
tectures. CreateSpace Independent Publishing Plat-
form.
ICSOFT 2019 - 14th International Conference on Software Technologies
630
